TL;DR#
Deep learning models heavily rely on large, high-quality datasets for optimal performance. Acquiring such datasets is often expensive and time-consuming. Existing data augmentation techniques either introduce limited diversity (transformation-based) or risk distribution shifts (synthesis-based), hindering model performance. This necessitates the development of new methods that can efficiently and effectively expand datasets while maintaining data quality.
This paper introduces DistDiff, a training-free data augmentation framework. DistDiff uses a novel distribution-aware diffusion model that leverages hierarchical prototypes to approximate the true data distribution. This approach generates high-quality, diverse synthetic samples that are consistent with the original data distribution. Experiments show that DistDiff significantly outperforms existing techniques, improving model accuracy across multiple datasets and architectural frameworks. Its training-free nature and compatibility with other augmentation methods further enhance its practical value.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep learning and computer vision due to its novel approach to data augmentation. It offers a training-free method for expanding datasets, addressing a critical limitation in many deep learning applications. The proposed technique’s effectiveness across diverse datasets and architectures makes it highly relevant to current research trends and opens doors for further exploration in data augmentation strategies.
Visual Insights#

🔼 This figure compares conventional data expansion methods with the proposed DistDiff method. Conventional methods either directly optimize or filter the final generated data points (zT) in the diffusion process, while ignoring intermediate denoising steps (zt). In contrast, DistDiff introduces an innovative distribution-aware diffusion framework that incorporates hierarchical clustering to approximate the real data distribution and utilizes multi-step energy guidance to refine intermediate predicted data points (zt), improving the quality and consistency of generated samples.
read the caption
Figure 1: A comparison unveils distinctions between conventional data expansion methods and our innovative distribution-aware diffusion framework, benefiting from hierarchical clustering and multi-step energy guidance.

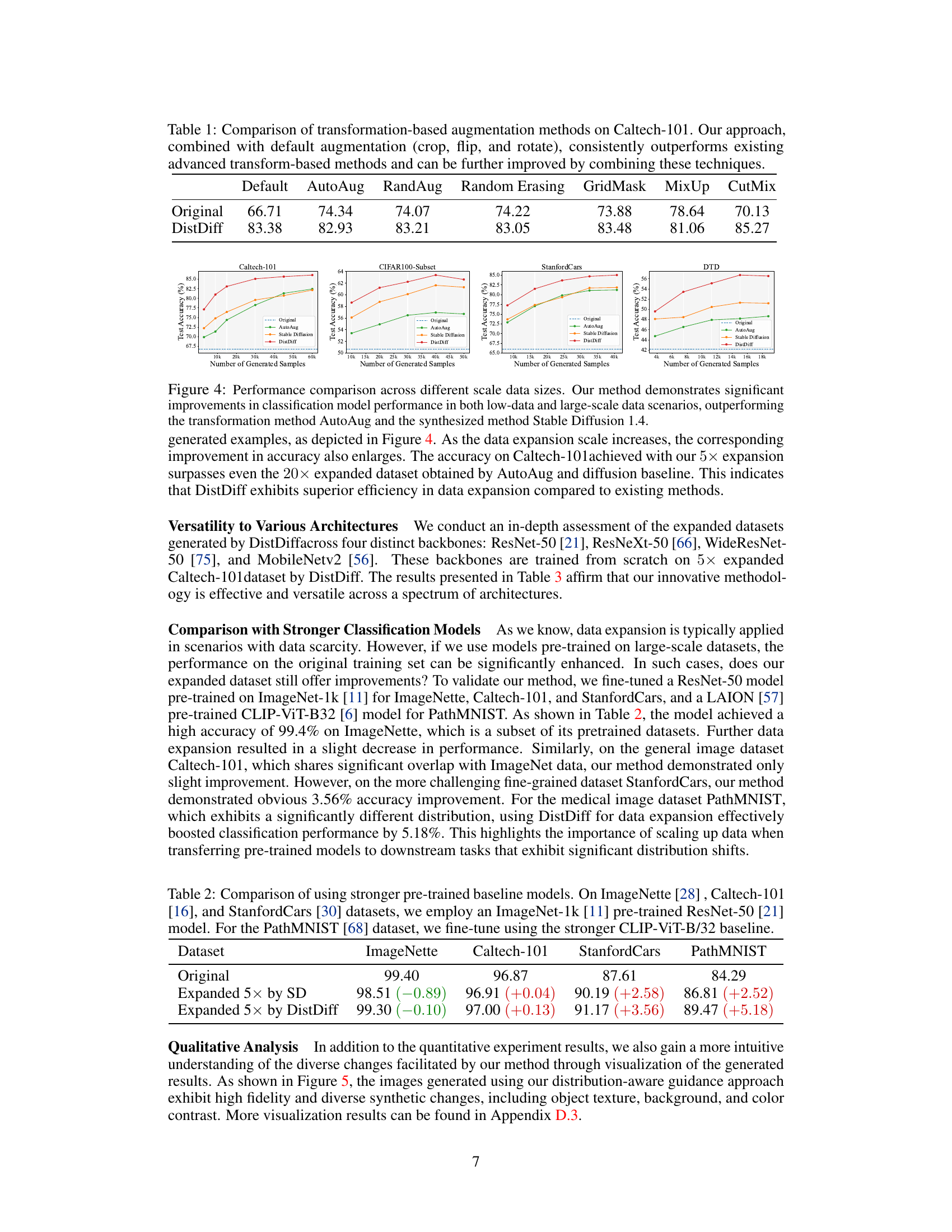
🔼 This table compares the performance of DistDiff with several traditional transformation-based data augmentation methods on the Caltech-101 dataset. It shows that DistDiff consistently outperforms these methods, even when combined with default augmentations like cropping, flipping, and rotation. The results suggest that DistDiff’s ability to generate more diverse and informative samples leads to significant improvements in classification accuracy.
read the caption
Table 1: Comparison of transformation-based augmentation methods on Caltech-101. Our approach, combined with default augmentation (crop, flip, and rotate), consistently outperforms existing advanced transform-based methods and can be further improved by combining these techniques.
In-depth insights#
DistDiff: Overview#
DistDiff, as a training-free data expansion framework, leverages a distribution-aware diffusion model to generate high-quality synthetic data samples. Its core innovation lies in the hierarchical prototype approximation, constructing both class-level and group-level prototypes to accurately capture the data distribution. These prototypes then guide the diffusion process using hierarchical energy guidance. This mechanism ensures that the generated samples are not only diverse but also distributionally consistent with the original data, mitigating the risk of out-of-distribution samples degrading model performance. Unlike existing methods that focus solely on the final generated samples, DistDiff optimizes intermediate steps during the diffusion sampling process, refining the latent data points iteratively. This multi-step optimization, combined with hierarchical energy guidance, yields high-quality synthetic data that significantly improve data expansion tasks and downstream model performance across diverse datasets and architectural frameworks. The training-free nature of DistDiff is a significant advantage, avoiding the computational cost and potential overfitting associated with fine-tuning pre-trained diffusion models.
Hierarchical Prototypes#
The concept of “Hierarchical Prototypes” in data augmentation is a powerful technique for generating synthetic data that closely resembles the original data distribution. It leverages a hierarchical structure, typically a two-level hierarchy in the described approach, to capture both fine-grained (group-level) and coarse-grained (class-level) information about the underlying data distribution. Class-level prototypes represent the average feature vector for each class, providing a general representation of the class’s characteristics. Group-level prototypes, on the other hand, are obtained by further partitioning the data within each class into clusters and averaging the feature vectors within these clusters. This two-level hierarchy allows for a more nuanced representation of the data distribution. It provides both a high-level summary (class-level) and a detailed description (group-level) of the data’s features, thus producing higher quality and more diverse synthetic data. The effectiveness of this approach relies on the accurate estimation of these prototypes, as they directly guide the generation process.
Energy Guidance#
The concept of ‘Energy Guidance’ in the context of a data expansion framework using diffusion models is a crucial innovation. It elegantly addresses the challenge of generating synthetic data that aligns closely with the real data distribution, preventing distribution drift which can harm model performance. The use of hierarchical prototypes (class and group level) offers a sophisticated method to approximate the true distribution. These prototypes act as guides, shaping the diffusion process and ensuring distribution consistency. The energy guidance functions, likely based on distance metrics between generated samples and these prototypes, provide a feedback mechanism to steer the diffusion model towards generating data points that are in alignment with the original data distribution. This approach provides flexibility by incorporating both high-level class information and lower-level group structure, thus fostering both diversity and fidelity in the generated data. Ultimately, energy guidance enables a training-free data expansion method that significantly improves performance across multiple datasets and architectures without the computational cost of model fine-tuning. The effectiveness is critically dependent upon the design and calculation of the energy functions and quality of prototype representation.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex model. In this context, it would dissect the proposed data expansion method, likely isolating elements such as the hierarchical prototypes (class-level and group-level), the distribution-aware energy guidance, and the residual multiplicative transformation. By removing or altering these parts one by one, and observing the performance changes on downstream tasks (e.g., image classification accuracy), the study would aim to determine which components are most crucial for success and where the model’s strengths and weaknesses lie. Quantifiable results showing performance differences after the removal of each component would be presented, offering insight into the effectiveness of each part in enhancing data expansion and downstream model performance. The ablation study is a critical part of validating and interpreting the model’s design, helping the authors make claims about the necessity and contribution of its various modules. The findings would likely reinforce the paper’s core arguments by demonstrating the critical role each module plays.
Future Works#
Future work could explore several promising avenues. Improving the efficiency of the hierarchical prototype construction is crucial; more sophisticated clustering techniques could reduce computational overhead and improve distribution approximation. Exploring alternative diffusion models and samplers beyond Stable Diffusion could potentially yield higher quality or more diverse generated data. Investigating different energy guidance functions, perhaps incorporating adversarial training or other methods, could further refine the balance between fidelity and diversity. A thorough analysis of the sensitivity of DistDiff to the choice of hyperparameters is also needed to make the method more robust and user-friendly. Finally, extending DistDiff to other data modalities beyond images, such as text or audio, would significantly expand its applicability and demonstrate its broader potential for data augmentation.
More visual insights#
More on figures
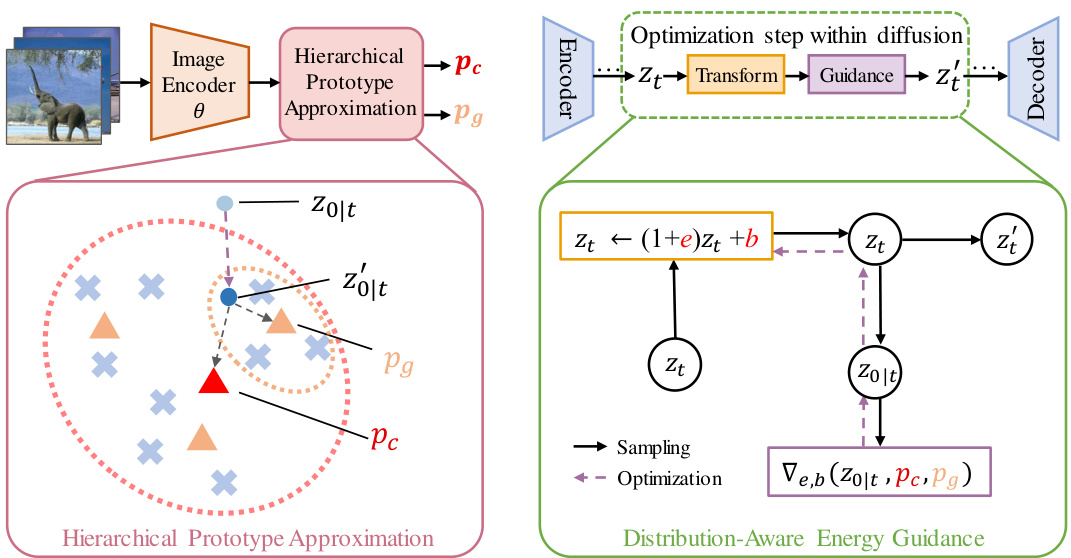
🔼 This figure shows the pipeline of DistDiff, a data expansion framework. It uses hierarchical prototypes (pc and pg) to approximate the data distribution. These prototypes guide the sampling process within a diffusion model via distribution-aware energy. The generated sample (z’) is refined to better match the real distribution.
read the caption
Figure 2: Overview of the DistDiff pipeline. DistDiff enhances the generation process in diffusion models with distribution-aware optimization. It approximates the real data distribution using hierarchical prototypes pc and pg, optimizing the sampling process through distribution-aware energy guidance. Subsequently, original generated data point zł is refined for improved alignment with the real distribution.
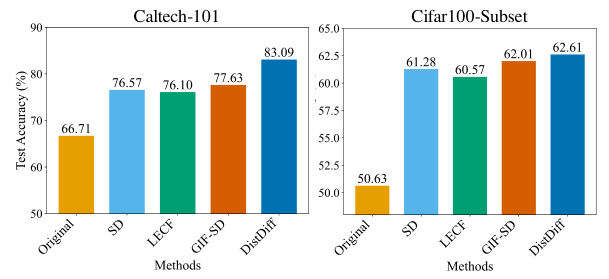
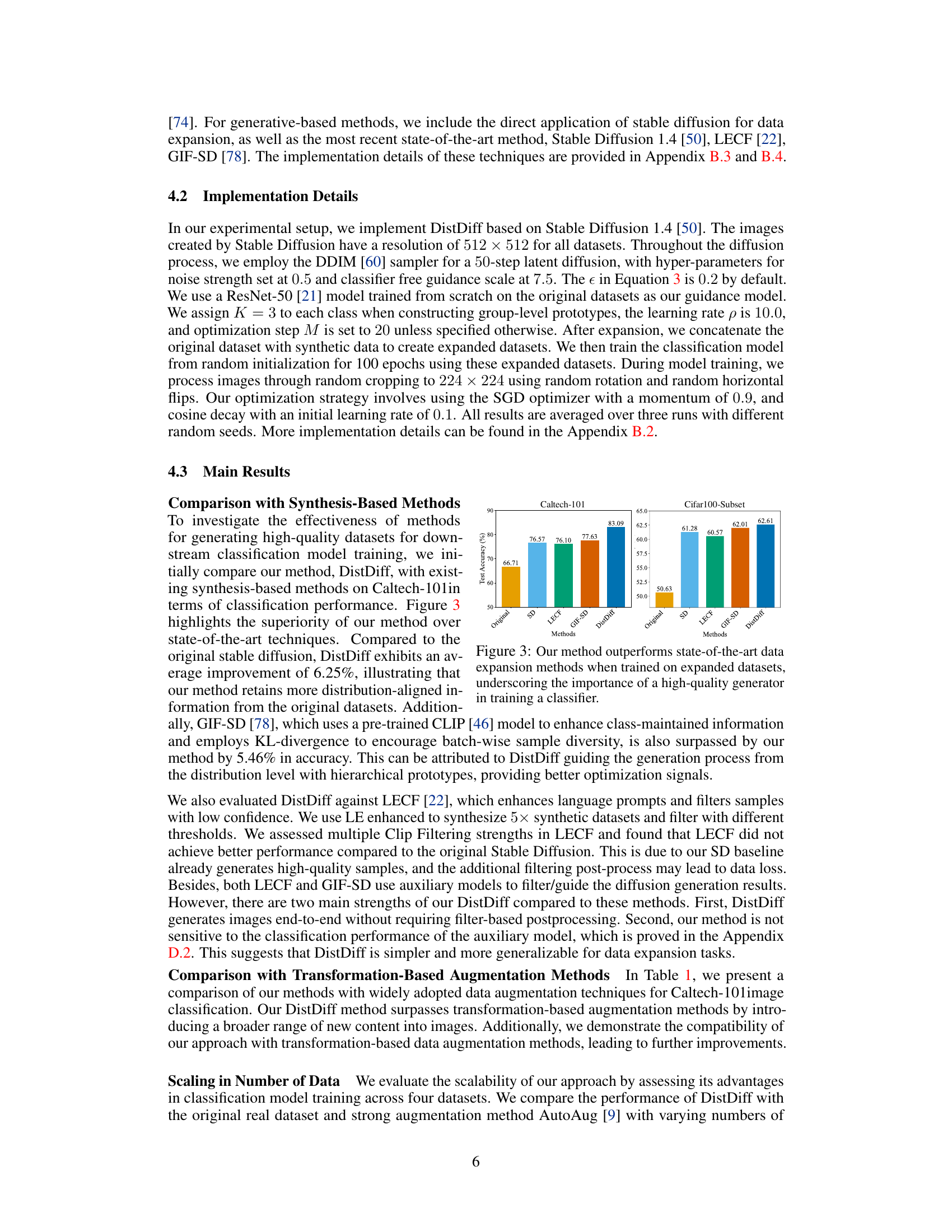
🔼 This figure compares the classification accuracy of different data expansion methods on the Caltech-101 and CIFAR100-Subset datasets. The ‘Original’ bars represent the accuracy of models trained only on the original datasets. The other bars show the improvement in accuracy gained by augmenting the original data with synthetic samples generated using various methods: Stable Diffusion (SD), LECF, GIF-SD, and the authors’ proposed DistDiff method. DistDiff consistently outperforms the other methods, highlighting its ability to generate high-quality, distribution-consistent samples that significantly improve downstream model performance.
read the caption
Figure 3: Our method outperforms state-of-the-art data expansion methods when trained on expanded datasets, underscoring the importance of a high-quality generator in training a classifier.

🔼 This figure compares the performance of DistDiff against AutoAug and Stable Diffusion 1.4 across various dataset sizes for image classification. The results demonstrate that DistDiff consistently outperforms these other methods across all dataset scales, indicating its effectiveness in improving data augmentation efficiency in various data regimes.
read the caption
Figure 4: Performance comparison across different scale data sizes. Our method demonstrates significant improvements in classification model performance in both low-data and large-scale data scenarios, outperforming the transformation method AutoAug and the synthesized method Stable Diffusion 1.4.

🔼 This figure shows a comparison between original images from various categories (helicopter, rooster, seahorse, gramophone, pizza, rhinoceros) and their corresponding synthetic counterparts generated using the proposed DistDiff method. The synthetic images exhibit high fidelity, meaning they closely resemble their real counterparts, and high diversity, showing variations in pose, angle, background, and lighting. The alignment with the original data distribution implies that the generated images maintain the statistical properties of the real data, reducing distribution shift. This demonstrates that the DistDiff method effectively generates high-quality and distribution-consistent synthetic data.
read the caption
Figure 5: The visualization of synthetic samples generated by our method, showcasing high fidelity, diversity, and alignment with the original data distribution.
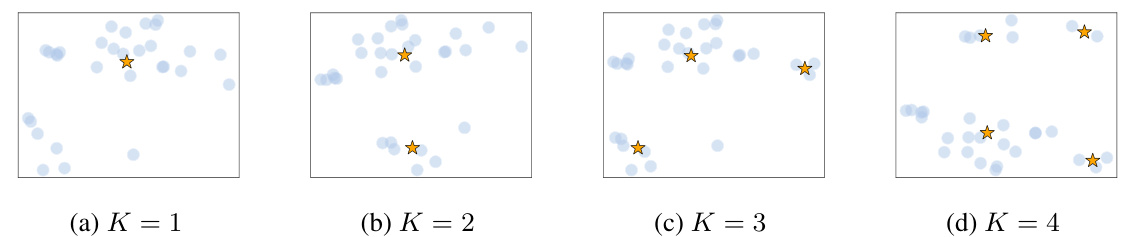
🔼 This figure shows how hierarchical prototypes approximate the real data distribution. It illustrates the effect of varying the number of group-level prototypes (K) on the representation of the data distribution. For each value of K, the figure shows the original data points as light blue circles and the group prototypes as orange stars. As K increases, the prototypes better capture the structure and spread of the data, providing a more accurate representation of the underlying distribution.
read the caption
Figure 6: The visualization of group-level prototypes alongside original sample features. Here • is the sample point and ☆ is group-level prototype. By selecting an appropriate number K, these prototypes effectively span the feature space, providing an approximation of the real data distribution.
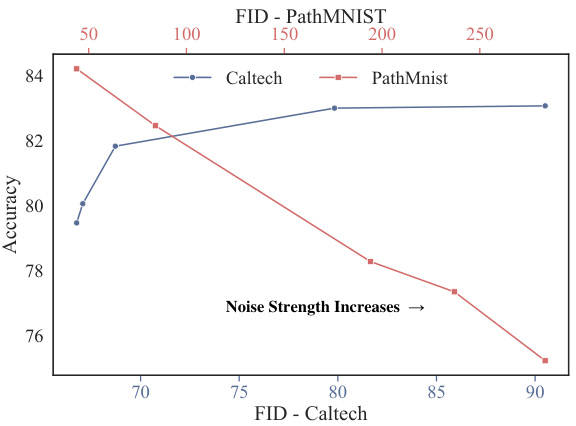
🔼 This figure shows the trade-off between fidelity and diversity in the data expansion task. The x-axis represents the FID score (Fréchet Inception Distance), a metric that measures the similarity between the generated and real data distributions. A lower FID score indicates higher fidelity. The y-axis shows the accuracy of a classifier trained on the expanded dataset. The plot shows two lines, one for Caltech-101 and one for PathMNIST datasets. As the noise strength increases, diversity increases (lower FID score), but accuracy may decrease, indicating that an optimal noise level is needed to balance fidelity and diversity for effective model training. For PathMNIST, a higher noise strength leads to a significant drop in accuracy. For Caltech-101, this drop is less drastic.
read the caption
Figure 7: Comparison with FID and accuracy across varying noise strengths.

🔼 This figure provides a visual comparison of images generated using Stable Diffusion 1.4 and the proposed DistDiff method. It shows that DistDiff produces images that are visually similar to those of Stable Diffusion 1.4, but with subtle differences in details and style variations. These differences demonstrate DistDiff’s ability to generate high-fidelity images while also exhibiting the diversity that is needed for good data augmentation.
read the caption
Figure 8: Comparison of visualizations between original Stable Diffusion 1.4 and our DistDiff.

🔼 This figure shows a grid of images generated by the DistDiff method for six different datasets: Caltech-101, CIFAR100-Subset, StanfordCars, DTD, ImageNette, and PathMNIST. Each dataset is represented by a 6x6 grid of images, showing the diversity and quality of the generated images. The figure visually demonstrates the effectiveness of the DistDiff method in producing high-quality synthetic images that closely resemble the distribution of the original datasets.
read the caption
Figure 9: Visualization of synthetic images produced by our method.
More on tables

🔼 This table compares the performance of using stronger pre-trained models (ResNet-50 pre-trained on ImageNet-1k and CLIP-ViT-B/32 pre-trained on LAION) on four datasets (ImageNette, Caltech-101, StanfordCars, and PathMNIST) with and without DistDiff data augmentation. It shows that DistDiff consistently improves or maintains accuracy compared to the original dataset and models expanded with Stable Diffusion, especially showcasing significant improvements on datasets with greater distribution shifts, such as StanfordCars and PathMNIST.
read the caption
Table 2: Comparison of using stronger pre-trained baseline models. On ImageNette [28], Caltech-101 [16], and StanfordCars [30] datasets, we employ an ImageNet-1k [11] pre-trained ResNet-50 [21] model. For the PathMNIST [68] dataset, we fine-tune using the stronger CLIP-ViT-B/32 baseline.

🔼 This table presents a comparison of the performance of different convolutional neural network backbones trained on the original Caltech-101 dataset and the same dataset expanded five times using the DistDiff method. The backbones compared are ResNet-50, ResNeXt-50, WideResNet-50, and MobileNetV2. The table shows that using the DistDiff method for data expansion significantly improves the performance of all four backbones on the Caltech-101 dataset.
read the caption
Table 3: Performance comparison of models trained on original Caltech-101 datasets and 5x expanded datasets by DistDiff.

🔼 This table shows the impact of using hierarchical prototypes (class-level prototypes (pc) and group-level prototypes (pg)) on the performance of the DistDiff model. The experiment involves expanding the Caltech-101 dataset by a factor of 5. The table reports the accuracy and Fréchet Inception Distance (FID) scores. The results demonstrate that using both class-level and group-level prototypes significantly improves both accuracy and FID scores compared to using only one or neither type of prototype. Lower FID scores indicate better alignment between the generated data distribution and the real data distribution.
read the caption
Table 4: Comparison of accuracy and FID in expanding Caltech-101 by 5×, with and without hierarchical prototypes in DistDiff.
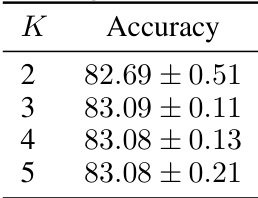
🔼 This table shows the ablation study on the number of group-level prototypes (K) used in the DistDiff model. It demonstrates that using 3 group-level prototypes provides the best accuracy. Using fewer prototypes may result in insufficient characterization of the real distribution, and using more prototypes may lead to overfitting on noisy sample points.
read the caption
Table 6: Ablation of the number K of pg in DistDiff.
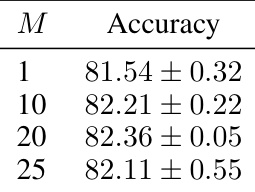
🔼 This table presents the results of an ablation study on the optimization step (M) in the DistDiff algorithm. It shows the accuracy achieved with different values of M, demonstrating the impact of optimizing at different stages of the diffusion sampling process on the final performance. The optimal performance is observed at M=20, indicating that optimizing at an intermediate stage (semantic stage) is crucial for achieving better performance. Optimizing too early (M=1) or too late (M=25) leads to suboptimal results.
read the caption
Table 5: Comparison of optimization in different phases.
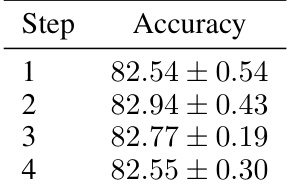
🔼 This table presents the results of an ablation study investigating the impact of varying the number of optimization steps (M) in the DistDiff algorithm on the model’s accuracy in image classification. The results show that increasing the number of optimization steps within a certain range can improve performance; however, excessive optimization can lead to a decline in accuracy, likely due to overfitting or over-optimization.
read the caption
Table 7: Results of introducing more optimization steps.

🔼 This table presents the details of the six datasets used in the experiments. It includes the name of each dataset, the number of classes, the size of the training and testing sets, and a brief description of the dataset content (e.g., recognition of generic objects, fine-grained classification of cars, texture classification, recognition of colon pathology images). The datasets vary in size and complexity, covering different image classification tasks.
read the caption
Table 8: Summary of our six experimental datasets.

🔼 This table lists the text prompts used for generating synthetic images for each of the six datasets used in the experiments. The prompts are designed to guide the Stable Diffusion model in generating images consistent with the class labels. The bracketed
[CLASS]is a placeholder that is replaced with the actual class label when generating an image.read the caption
Table 9: Text templates for six experimental datasets.

🔼 This table compares the performance of two different guidance models (a weak model trained from scratch and a strong pre-trained model) in a downstream classification task on the Caltech-101 dataset. It shows the accuracy of each guidance model itself and the accuracy of a classifier trained using data expanded by DistDiff with each of the guidance models. The results demonstrate that DistDiff’s performance is robust across different guidance models.
read the caption
Table 10: Comparison of guidance models on Caltech-101 dataset. We compared the accuracy of two guidance models on the original Caltech-101 dataset. Additionally, we evaluated the performance of a downstream classifier trained on the 5× expanded dataset using corresponding guide model.

🔼 This table presents the results of an ablation study on the effect of different learning rates (ρ) on the accuracy of the model. It shows that a learning rate of 10.0 yields the highest accuracy, while rates that are too low or too high result in lower accuracy.
read the caption
Table 11: Comparison of different learning rate ρ.

🔼 This table presents the results of an ablation study on the effect of varying the gradient weight (λg) applied to the group-level prototypes (pg) in the DistDiff model. Different values of λg were tested to determine the optimal balance between the contributions of class-level and group-level prototypes for data expansion. The results show that a value of λg = 0.9 yields the highest accuracy on the Caltech-101 dataset.
read the caption
Table 12: Comparison of different gradient weights λg.

🔼 This table compares the inference time of different data expansion methods on the Caltech-101 dataset. It shows that DistDiff is comparable to Stable Diffusion in terms of inference speed, significantly faster than LECF due to the additional filtering step required by LECF. All methods were evaluated on a single GeForce RTX 3090 GPU.
read the caption
Table 13: Inference Efficiency comparison with existing methods on Caltech-101 dataset. * denotes that the actual time required of LECF to derive one sample after filter post-processing. Evaluation processes are conducted on a single GeForce RTX 3090 GPU.

🔼 This table compares the accuracy of three different data augmentation methods on the Caltech-101 dataset. The dataset was expanded by a factor of 5. The methods compared are DA-Fusion, DiffuseMix, and the proposed DistDiff method. The table shows that the DistDiff method achieves the highest accuracy, outperforming both DA-Fusion and DiffuseMix.
read the caption
Table 14: Comparison of accuracy in expanding Caltech-101 by 5x.
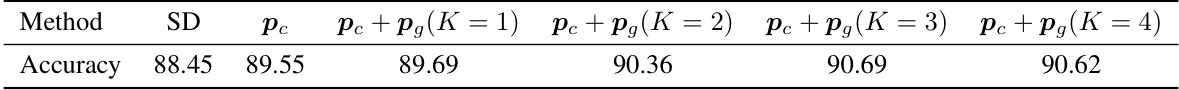
🔼 This table presents the results of an ablation study on the StanfordCars dataset, comparing the accuracy of different combinations of class-level (pc) and group-level (pg) prototypes used in DistDiff. It shows that the best performance is achieved with both class and group-level prototypes, indicating that combining both levels provides the best representation of the data distribution for this dataset.
read the caption
Table 15: Prototypes comparison of accuracy in expanding StanfordCars by 2×. We trained ResNet50 with a 448 × 448 resolution for 128 epochs.

🔼 This table presents a comparison of the accuracy achieved on the ImageNet dataset after expanding it by 0.2x using three different methods: the original dataset, Stable Diffusion (SD), and the proposed DistDiff method. ResNet18 was used as the classifier, trained for 90 epochs with 224x224 resolution images. The table shows that DistDiff outperforms both the original and the SD-only expanded datasets.
read the caption
Table 16: Comparison of accuracy in expanding ImageNet by 0.2×. We trained ResNet18 with a 224 × 224 resolution for 90 epochs.
Full paper#