TL;DR#
Generating egocentric videos (first-person view) from exocentric videos (third-person view) is crucial for applications like augmented reality and AI assistants, but it is challenging due to significant differences in viewpoints and the complexity of real-world scenes. Existing methods struggle with this task, especially when dealing with daily life activities and sparse viewpoints. They either require many input views or oversimplify the problem.
This paper introduces Exo2Ego-V, a novel approach that tackles this challenge using diffusion-based video generation. Exo2Ego-V employs a multi-view exocentric encoder to extract rich features from multiple exocentric cameras, a view translation prior to provide spatially aligned egocentric features, and temporal attention layers to improve temporal consistency. Experimental results show that Exo2Ego-V significantly outperforms state-of-the-art methods on a challenging benchmark, demonstrating its effectiveness in generating high-quality, realistic egocentric videos.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and AI due to its novel approach to exocentric-to-egocentric video generation, addressing a significant challenge in visual learning and augmented reality. The large-scale dataset used and the significant performance improvements over existing methods make it highly relevant and impactful. The research opens up new avenues for exploration in multi-view video understanding and cross-modal translation.
Visual Insights#

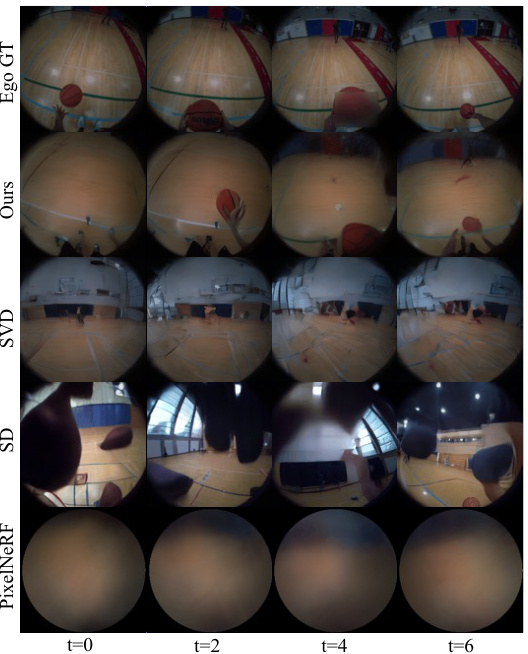
🔼 This figure shows the input to and output from the Exo2Ego-V model. The top row shows four exocentric views (Exo-1 through Exo-4) of someone playing basketball, taken from cameras placed 360 degrees around the scene. The bottom row shows a similar example of someone performing CPR. In each case, Exo2Ego-V generates a realistic egocentric view (‘Ours’) that convincingly recreates what the person in the activity would see. The ‘Ground Truth’ column provides the actual egocentric recording for comparison.
read the caption
Figure 1: Given sparse 4 exocentric videos configured 360° around daily-life skilled human activities such as playing basketball (upper), CPR training (lower), our Exo2Ego-V can generate corresponding egocentric videos with the same activity and environment as the exocentric videos. We encourage readers to click and play the video clips in this figure using Adobe Acrobat.
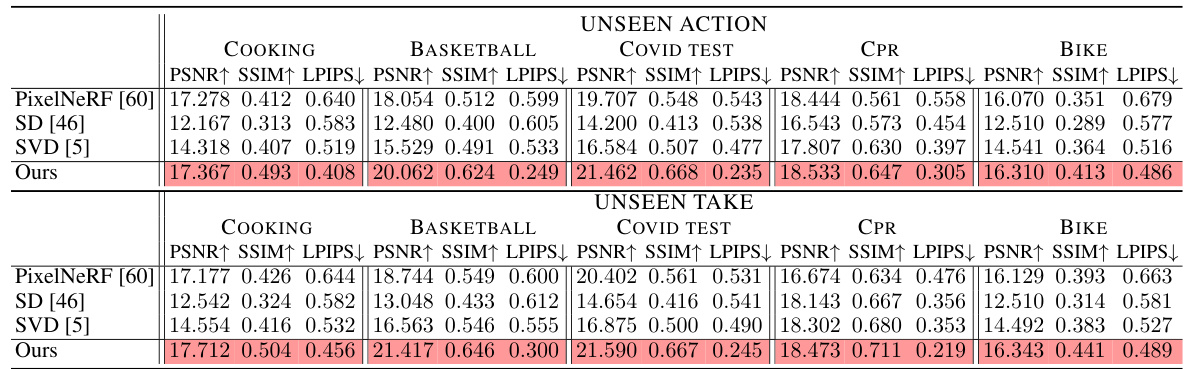
🔼 This table presents a quantitative comparison of the proposed Exo2Ego-V model against several state-of-the-art baselines across five different categories of daily-life activities from the Ego-Exo4D dataset. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The table shows the average performance across three different experimental setups: unseen actions, unseen takes, and unseen scenes. The color coding helps to quickly identify the best-performing method for each metric and category.
read the caption
Table 1: Averaged quantitative evaluation on different categories. We color code each cell as best.
In-depth insights#
Exo-Ego Diffusion#
The concept of “Exo-Ego Diffusion” blends exocentric (external view) and egocentric (first-person view) perspectives within a diffusion model framework. This approach is particularly powerful for video generation, bridging the gap between these distinct viewpoints. A key advantage lies in leveraging the richness of exocentric data to guide the generation of egocentric videos. This is especially useful for scenarios where obtaining sufficient egocentric data is challenging or expensive, such as capturing sports or complex activities. The diffusion process allows for the generation of realistic and temporally consistent egocentric video outputs, by progressively refining noisy data towards a coherent egocentric representation. This approach tackles the inherent challenges in cross-viewpoint translation by using the rich contextual information from multiple exocentric viewpoints to constrain and guide the generation process, resulting in more accurate and realistic egocentric outputs. Furthermore, the diffusion model’s ability to handle noise and uncertainty allows it to be robust to variations in viewpoint and environmental conditions. Therefore, Exo-Ego Diffusion offers a novel and efficient way to synthesize highly detailed and realistic egocentric videos from sparse exocentric observations.
Multi-view Encoding#
Multi-view encoding in video generation is crucial for tasks like exocentric-to-egocentric view translation, as it allows the model to leverage information from multiple viewpoints to synthesize a realistic egocentric view. A successful multi-view encoding scheme should effectively capture both the spatial relationships and temporal dynamics across different camera perspectives. Challenges include handling viewpoint variations, occlusions, and the complexity of real-world scenes. Techniques like attention mechanisms, which can weigh the importance of different views based on their relevance to the target egocentric view, are essential. Furthermore, the encoding should be computationally efficient to allow for real-time or near real-time video generation. The choice of the encoding method will depend on several factors, such as the available computational resources and the desired level of realism in the generated video. Advanced techniques may incorporate 3D scene understanding or relative camera pose information to further improve the quality of the resulting egocentric video. A robust multi-view encoding strategy is key to unlocking the potential of multi-camera video data for novel video synthesis applications.
View Translation#
View translation, in the context of this research paper, likely focuses on the transformation of visual data between different viewpoints or perspectives. This could involve converting from an exocentric (third-person) view to an egocentric (first-person) view, or vice versa, which is a common task in computer vision and robotics. The core challenge involves addressing the differences in perspective, occlusion, and motion dynamics present in each type of view. A successful view translation method would require robust techniques for feature extraction, alignment, and generation to accurately and realistically synthesize the translated view. This could involve deep learning models, potentially leveraging techniques from diffusion models or neural radiance fields, to learn the complex mappings between the source and target viewpoints. The performance of such a method would likely be evaluated based on metrics like structural similarity, perceptual similarity (LPIPS), and visual fidelity. Furthermore, the ability to handle dynamic scenes and real-world complexities adds a significant layer of difficulty to the problem, demanding more sophisticated and computationally expensive solutions.
Temporal Dynamics#
Analyzing temporal dynamics in video generation is crucial for creating realistic and engaging content. The challenge lies in capturing and modeling the complex, time-dependent relationships between visual elements within a video sequence. This requires a deep understanding of not just individual frames but also the transitions and interactions across frames. A successful approach necessitates methods that go beyond simple frame-by-frame processing and address challenges like motion consistency, temporal coherence, and the handling of dynamic events. This might involve leveraging advanced techniques such as recurrent neural networks, transformers, or diffusion models with specialized temporal attention mechanisms. Proper temporal modeling is key to preventing artifacts and creating smoother, more believable video sequences. Furthermore, evaluating the temporal quality of generated videos requires specific metrics that quantify the fidelity of motion, the consistency of actions, and the overall temporal coherence. The ultimate goal of researching temporal dynamics is the generation of videos that are indistinguishable from real-world recordings.
Future of Exo2Ego#
The “Future of Exo2Ego” hinges on addressing current limitations and exploring new avenues. Improving the quality and temporal consistency of generated egocentric videos remains crucial. This could involve refining the diffusion model architecture, incorporating more sophisticated temporal modeling techniques, or leveraging additional modalities like audio or depth information for improved context. Expanding the scope to encompass a wider range of activities and environments beyond the current dataset is essential for broader applicability. This necessitates larger and more diverse datasets, possibly incorporating user-generated content. Furthermore, exploring more efficient training methods is vital to reduce computational costs and enable wider access. Finally, investigating novel applications built upon Exo2Ego, such as improved AI assistants or augmented reality experiences, will help establish its practical value and drive further research.
More visual insights#
More on figures
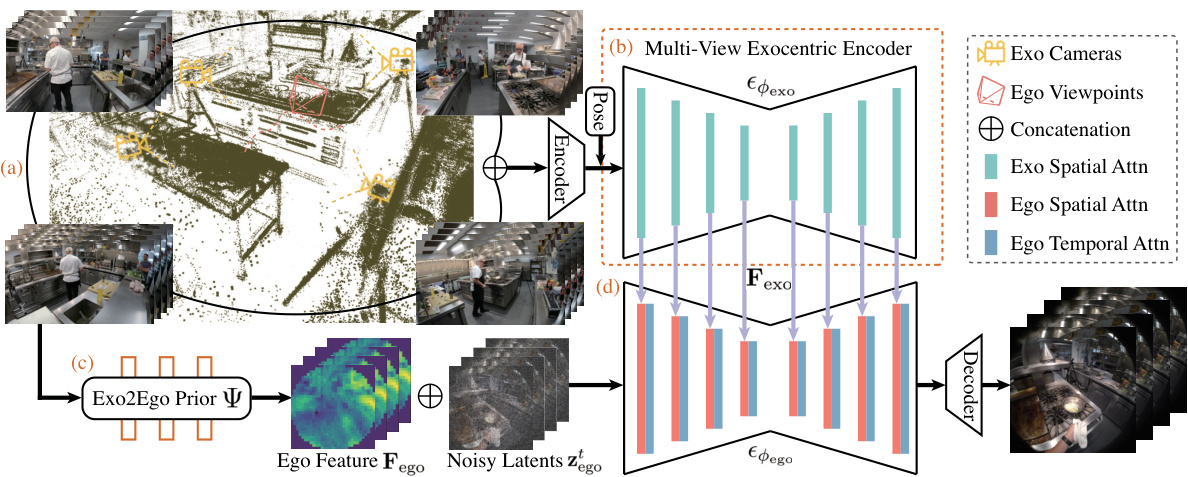
🔼 This figure illustrates the Exo2Ego-V framework, showing how it generates egocentric videos from exocentric inputs. It breaks down the process into four key stages: (a) Input: Four exocentric videos (360° view) showing a daily-life activity (e.g., cooking). (b) Multi-View Exocentric Encoder: This component processes the exocentric videos to extract multi-scale features that capture appearance and context. (c) Exo2Ego View Translation Prior: This prior generates spatially aligned egocentric features from the exocentric inputs as guidance for video generation. (d) Egocentric Video Diffusion Pipeline: This combines the features from stages (b) and (c) with noisy egocentric latents to generate the final egocentric video.
read the caption
Figure 2: Overview of Exo2Ego-V. Given 4 exocentric videos configured 360° around daily-life skilled human activities such as cooking (a), our multi-view exocentric encoder (b) extracts the multi-scale exocentric features as the appearance conditions for egocentric video generation, and our Exo2Ego view translation prior (c) predicts the egocentric features as the concatenation guidance for the egocentric noisy latents input. With these information, our egocentric video diffusion pipeline (d) generates the egocentric videos with the same activity and environment as the exocentric videos.
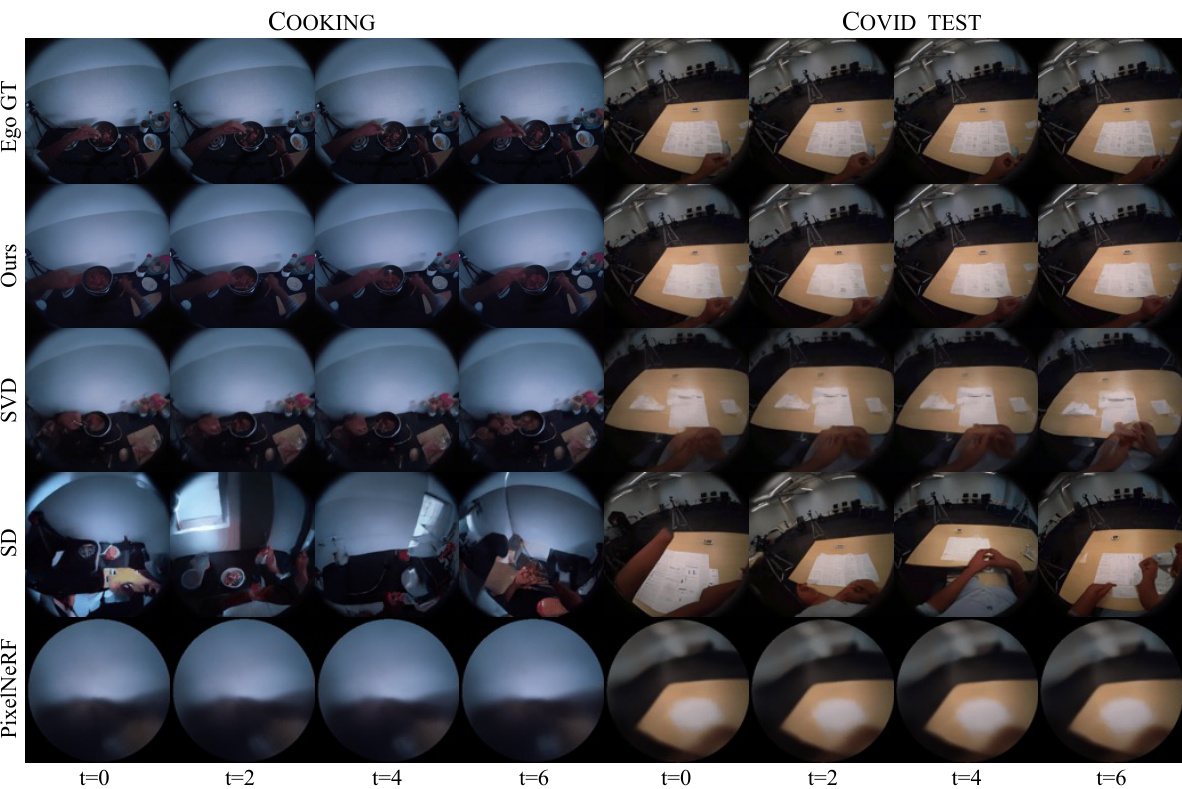
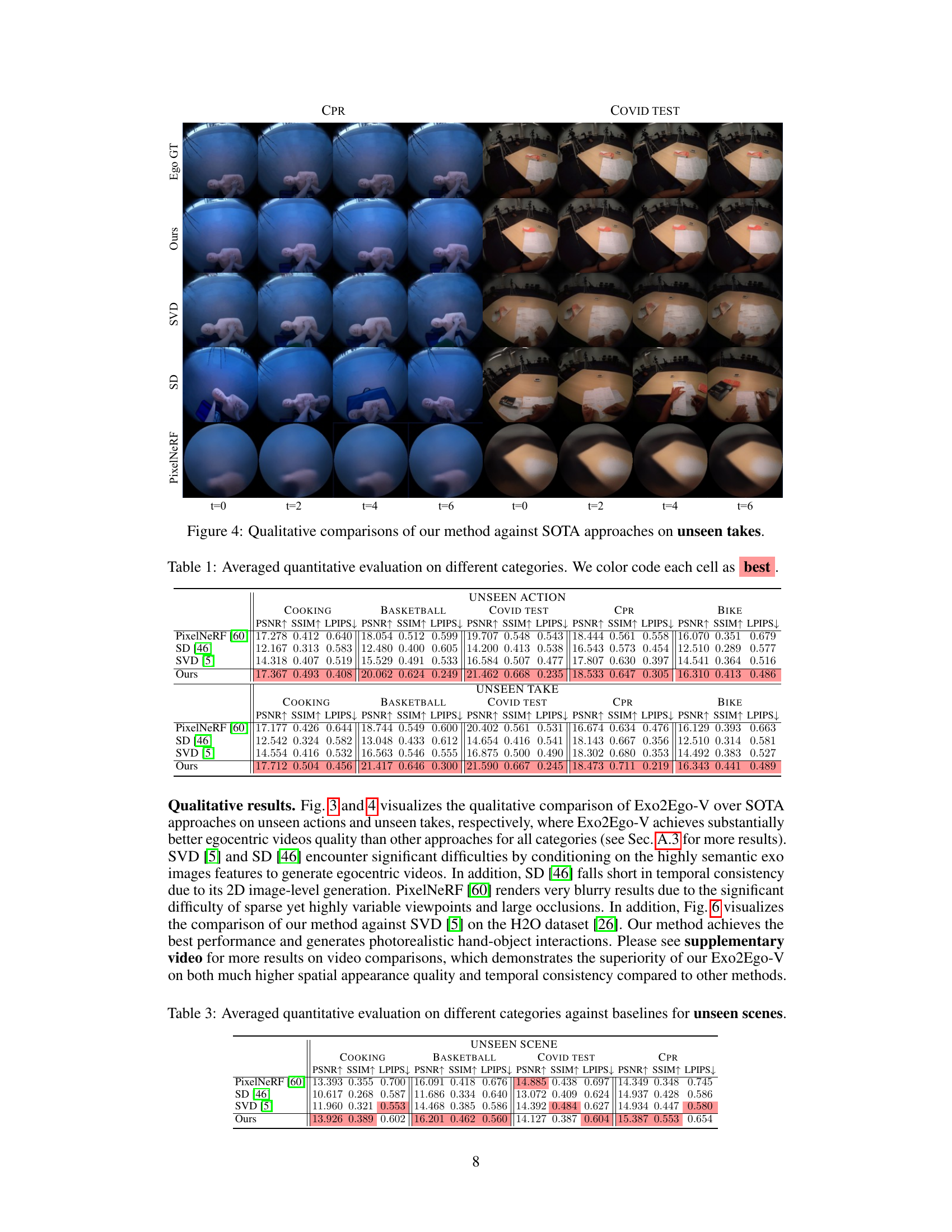
🔼 This figure provides a qualitative comparison of the proposed Exo2Ego-V model against state-of-the-art (SOTA) approaches on unseen actions. It displays example frames (t=0, t=2, t=4, t=6) of generated egocentric videos for two action categories, ‘Cooking’ and ‘COVID Test.’ The results from Exo2Ego-V, Stable Video Diffusion (SVD), Stable Diffusion (SD), and PixelNeRF are shown, along with the ground truth egocentric video (Ego GT). This visual comparison allows for an assessment of the visual quality and fidelity of the different approaches in handling unseen action sequences.
read the caption
Figure 3: Qualitative comparisons of our method against SOTA approaches on unseen actions.
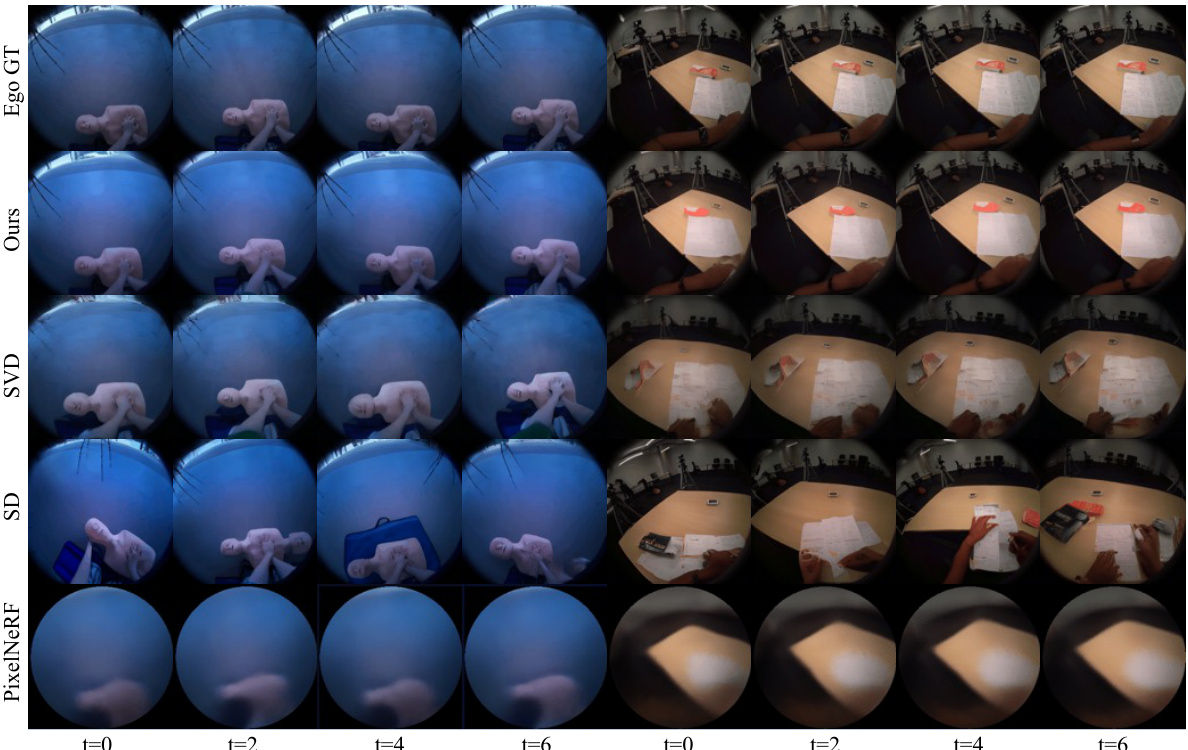
🔼 This figure displays a qualitative comparison of the proposed Exo2Ego-V model’s performance against state-of-the-art (SOTA) approaches on unseen actions from the Cooking and COVID Test categories of the Ego-Exo4D dataset. The comparison includes the ground truth (Ego GT), the proposed method (Ours), Stable Video Diffusion (SVD), Stable Diffusion (SD), and PixelNeRF. Each row represents a different method, and the columns show the generated egocentric video frames (t=0, t=2, t=4, t=6) for a given unseen action. The results visually showcase the superiority of Exo2Ego-V in generating realistic and detailed egocentric videos compared to the other methods.
read the caption
Figure 3: Qualitative comparisons of our method against SOTA approaches on unseen actions.
🔼 This figure provides a qualitative comparison of the proposed Exo2Ego-V model against several state-of-the-art (SOTA) approaches on unseen actions from the Ego-Exo4D dataset. It showcases the generated egocentric videos (t=0, t=2, t=4, t=6) for the ‘Cooking’ and ‘COVID Test’ categories, comparing Exo2Ego-V’s output to the ground truth (Ego GT) and the results of Stable Video Diffusion (SVD), Stable Diffusion (SD), and PixelNeRF baselines. The comparison allows for a visual assessment of the quality and realism of the generated egocentric videos produced by each method.
read the caption
Figure 3: Qualitative comparisons of our method against SOTA approaches on unseen actions.

🔼 This figure shows a qualitative comparison of the proposed Exo2Ego-V method against three state-of-the-art (SOTA) approaches on the H2O dataset. The H2O dataset contains synchronized egocentric and exocentric videos of desktop activities. The figure displays generated egocentric video frames for two different activities at various timesteps (t=0, t=2, t=4, t=6) for each method. The ground truth egocentric videos (EgoGT) are shown for comparison. The goal is to assess the visual quality and accuracy of the generated videos compared to the ground truth.
read the caption
Figure 6: Qualitative comparisons of our method against SOTA approaches on H2O dataset.
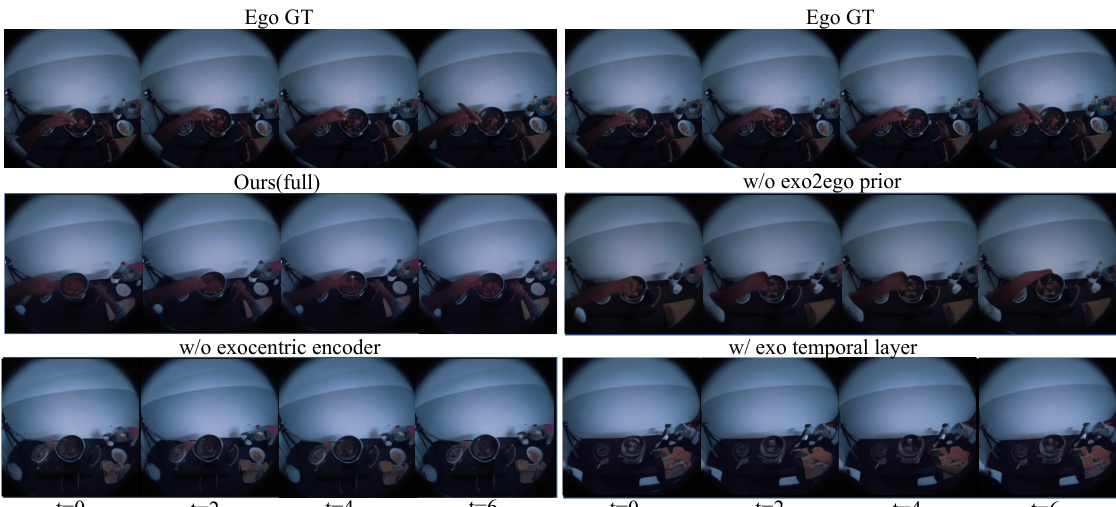
🔼 This figure presents a qualitative comparison of the results obtained using the full Exo2Ego-V model against several ablated versions. The ablation studies involve removing key components such as the exocentric encoder, the Exo2Ego prior, and the exo temporal layer. The results demonstrate the contribution of each component to the overall performance in terms of generating realistic and temporally coherent egocentric videos from exocentric inputs. Each row shows the ground truth egocentric video and the corresponding results for a different ablation.
read the caption
Figure 7: Qualitative ablation results of our method for cooking category on unseen actions.

🔼 This figure shows ablation study results on the cooking category from the Ego-Exo4D dataset. It shows the impact of different components of the proposed method, such as using different numbers of exocentric views (4, 3, 2, 1), replacing the exocentric feature encoder with CLIP features, and removing the temporal-spatial modules. The results demonstrate the effectiveness of the proposed multi-view exocentric encoder and the temporal-spatial modules in improving the quality of the generated egocentric videos.
read the caption
Figure 8: More ablation results of our method for cooking category on unseen actions.

🔼 This figure shows a comparison between generated egocentric videos from the Exo2Ego-V model and ground truth egocentric videos for two different activities: basketball and CPR. The top row shows the basketball example and the bottom row demonstrates CPR. For each activity, there are four input exocentric videos (Exo-1 to Exo-4) arranged at 360 degrees around the activity. Following these are the model’s generated egocentric view (Ours) and the ground truth egocentric video (Ground Truth). The figure visually demonstrates the model’s ability to generate realistic and coherent egocentric views from limited input exocentric videos.
read the caption
Figure 1: Given sparse 4 exocentric videos configured 360° around daily-life skilled human activities such as playing basketball (upper), CPR training (lower), our Exo2Ego-V can generate corresponding egocentric videos with the same activity and environment as the exocentric videos. We encourage readers to click and play the video clips in this figure using Adobe Acrobat.
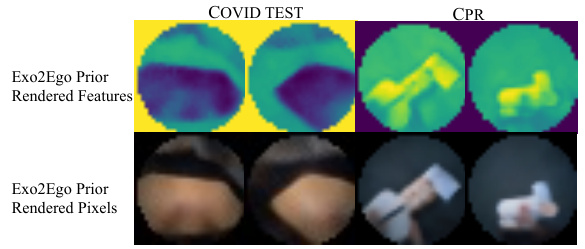
🔼 This figure visualizes the features rendered by the Exo2Ego prior for two different actions: COVID Test and CPR. The top row shows the rendered features, while the bottom row shows the rendered pixels. The visualization demonstrates the prior’s ability to extract and transmit relevant information from egocentric views to the multi-view exocentric encoder, which is crucial for guiding the egocentric video generation process.
read the caption
Figure 11: Exo2Ego prior feature visualization.
More on tables

🔼 This table presents a quantitative comparison of the proposed Exo2Ego-V model against three baseline models (PixelNeRF, Stable Diffusion, and Stable Video Diffusion) across five activity categories (Cooking, Basketball, COVID Test, CPR, and Bike) on unseen scenes. The evaluation metrics used are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher PSNR and SSIM values indicate better image quality, while a lower LPIPS score suggests greater perceptual similarity to the ground truth. The table highlights the superior performance of Exo2Ego-V across all metrics and categories.
read the caption
Table 3: Averaged quantitative evaluation on different categories against baselines for unseen scenes.
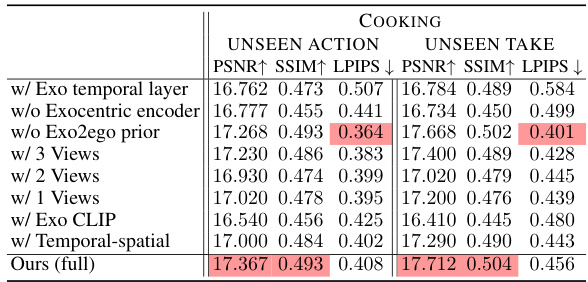
🔼 This table presents the ablation study results for the proposed Exo2Ego-V model on the Cooking category of the Ego-Exo4D dataset. It shows the performance of the model with different components removed or modified, allowing for an evaluation of their individual contributions. Metrics include PSNR, SSIM, and LPIPS, measuring the quality of generated videos compared to ground truth. The variations include removing the exocentric encoder, removing the Exo2Ego prior, using different numbers of exocentric views, replacing the exocentric feature encoder with a CLIP feature extractor, and using a different spatial-temporal attention configuration.
read the caption
Table 4: Ablation results of our method.
🔼 This table presents a quantitative comparison of the proposed Exo2Ego-V model against state-of-the-art (SOTA) methods across five categories of daily-life skilled human activities from the Ego-Exo4D dataset. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The results are averaged across three different test scenarios: unseen actions, unseen takes, and unseen scenes. The color-coding helps to quickly identify the best-performing method in each category for each metric.
read the caption
Table 1: Averaged quantitative evaluation on different categories. We color code each cell as best

🔼 This table presents a comparison of the inference time required by the proposed Exo2Ego-V model and three baseline methods (Stable Video Diffusion [5], Stable Diffusion [46], and PixelNeRF [60]) to generate an 8-frame egocentric video. The inference time is presented in seconds. The purpose is to show that the proposed method’s inference time is comparable to those of established baselines.
read the caption
Table 5: Inference time of our method in comparison with baselines.
Full paper#