↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current multimodal large language models (MLLMs) often rely on a single vision encoder, limiting their ability to understand diverse image content. For example, CLIP excels in general image understanding but struggles with documents or charts. This reliance on a single encoder creates inherent biases, hindering the MLLMs’ generalization across various tasks. This paper addresses this issue by proposing MoVA.
MoVA tackles this limitation by introducing an adaptive routing and fusion mechanism that dynamically selects and combines multiple task-specific vision experts. This “coarse-to-fine” approach, facilitated by the strong understanding capabilities of LLMs, significantly enhances generalization. Extensive experiments show MoVA achieving state-of-the-art performance across various benchmarks, demonstrating the effectiveness of its adaptive expert management strategy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal large language models (MLLMs) as it addresses the limitations of existing vision encoders, improving MLLM generalization and performance across diverse tasks. Its innovative approach of adaptively routing and fusing task-specific vision experts opens exciting new avenues for research, potentially leading to more robust and versatile MLLMs.
Visual Insights#
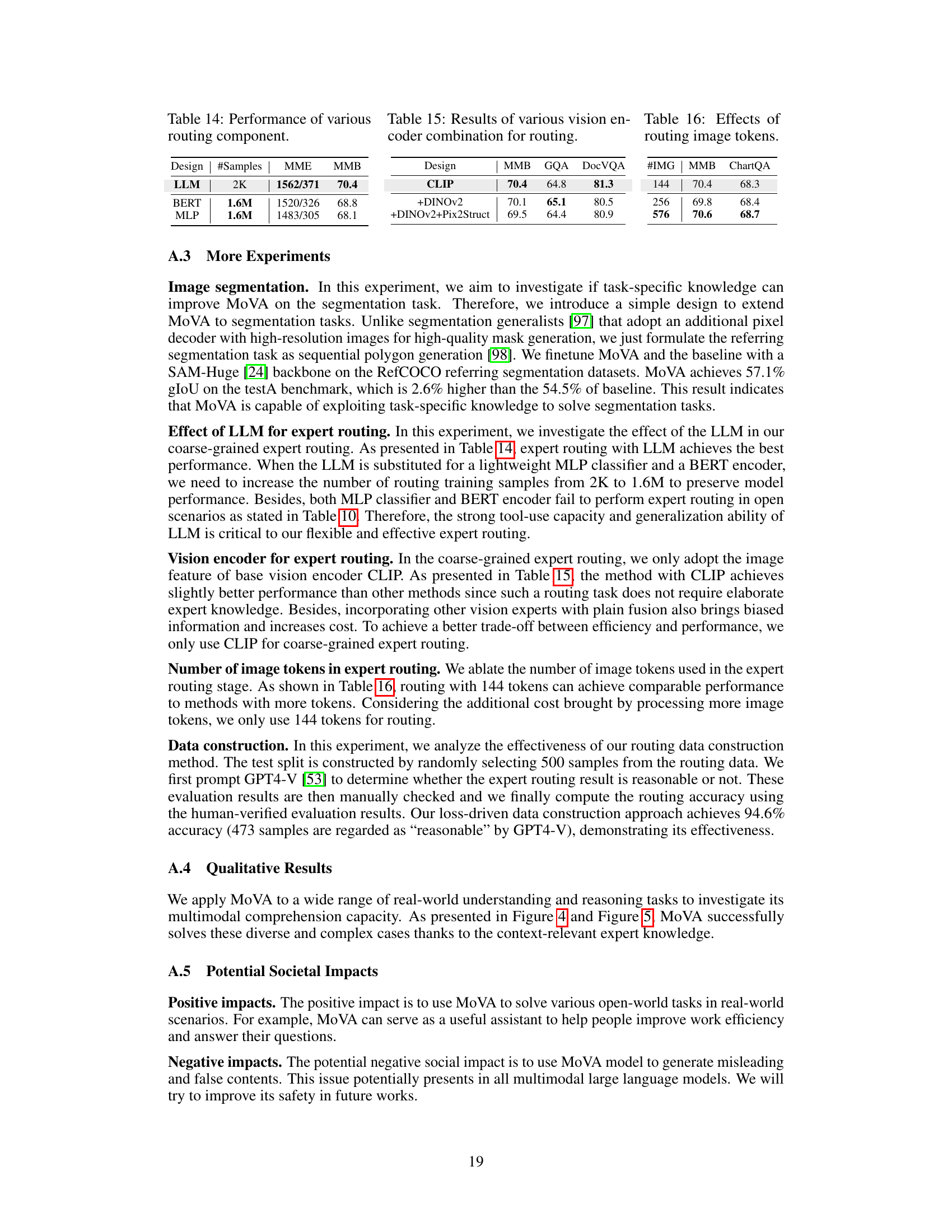
The figure illustrates the two-stage pipeline of MoVA, a multimodal large language model. Stage 1 involves context-aware expert routing, where a large language model (LLM) selects the most relevant vision experts based on user input (question and image). Stage 2 uses a Mixture-of-Vision-Expert Adapter (MoV-Adapter) for fine-grained fusion, combining task-specific knowledge from selected experts to enhance the base vision encoder’s output. The final output is fed to the LLM to produce a response.
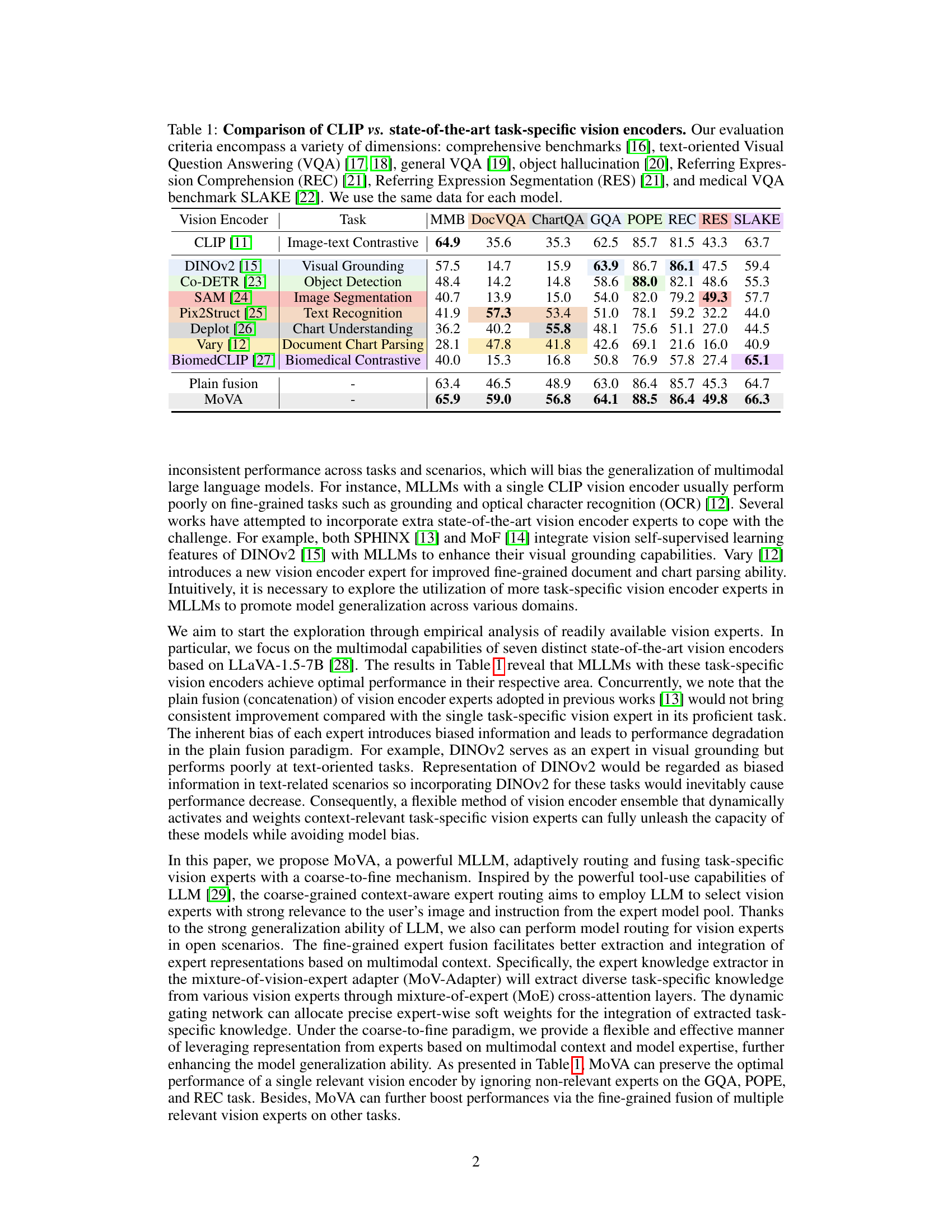
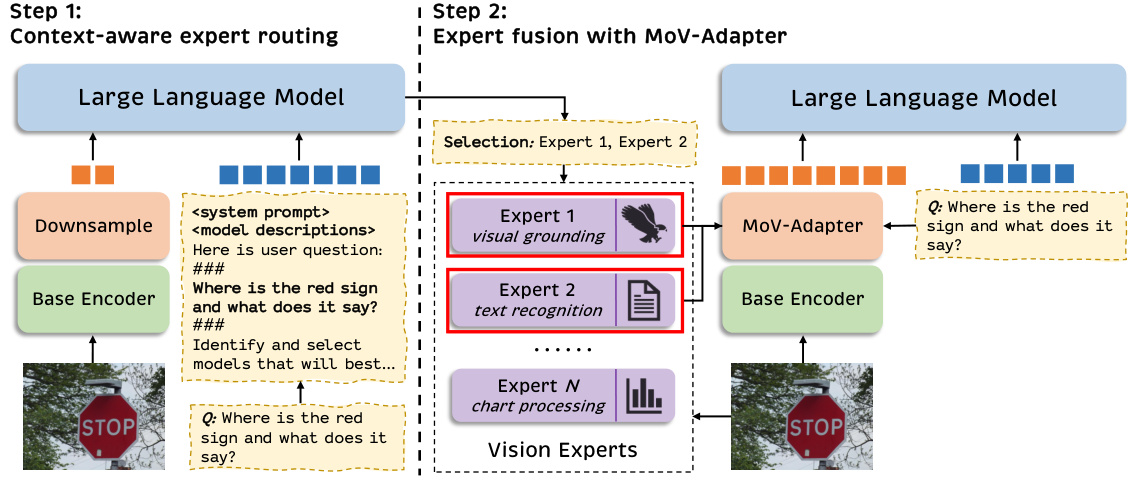
This table compares the performance of CLIP, a general-purpose vision encoder, against several state-of-the-art task-specific vision encoders across a range of tasks and benchmarks. The benchmarks cover various aspects of visual understanding, including image-text matching, visual grounding, object detection, image segmentation, text recognition, chart understanding, document parsing, and medical image understanding. The table highlights that while CLIP excels in general image understanding, task-specific encoders often outperform it on more specialized tasks. This demonstrates the need for adaptive and task-aware vision encoding in multimodal large language models.
In-depth insights#
MoVA: Multimodal Fusion#
MoVA, signifying Multimodal Vision Adapter, presents a novel approach to multimodal fusion. Its core innovation lies in the adaptive routing and fusion of task-specific vision experts, leveraging the strengths of different pre-trained models rather than relying on a single, potentially biased encoder. This adaptive mechanism dynamically selects relevant vision experts based on the input image and user instructions, improving generalization across diverse tasks. A crucial component is the MoV-Adapter, which performs fine-grained fusion of expert knowledge, ensuring that task-specific information is effectively integrated. The coarse-to-fine strategy, combining context-aware routing and the MoV-Adapter, allows MoVA to enhance the model’s ability to handle complex image contexts and various tasks effectively. This approach contrasts with simpler fusion methods (e.g., concatenation) that may suffer from biased information and suboptimal performance. The effectiveness of MoVA is validated through extensive experiments across multiple benchmarks, demonstrating improvements over existing state-of-the-art models in visual question answering, visual grounding and other multimodal tasks.
Adaptive Expert Routing#
Adaptive expert routing, in the context of multimodal large language models, is a crucial mechanism for enhancing efficiency and accuracy. It dynamically selects the most appropriate vision encoder experts for a given task, avoiding the limitations of relying on a single, general-purpose encoder. This adaptive selection process significantly improves model generalization by leveraging the unique strengths of specialized experts tailored to various image content types (e.g., documents, charts, general images). The core idea lies in leveraging the LLM’s powerful understanding of the task and input context to make informed routing decisions. This makes the process context-aware and data-driven. A key benefit is the avoidance of biased information from unsuitable experts, thereby preventing performance degradation on fine-grained tasks or specific domains. The adaptive selection can be implemented using a variety of methods, ranging from simple rule-based approaches to complex neural network-based routing strategies. Ultimately, adaptive expert routing represents a paradigm shift in multimodal understanding, offering a more flexible and efficient approach compared to traditional methods that rely on fixed or static vision encoders.
MoV-Adapter: Fine Tuning#
The MoV-Adapter’s fine-tuning strategy is a crucial aspect of the overall MoVA model. It focuses on enhancing the model’s ability to extract and integrate task-specific knowledge from multiple vision experts. This is achieved through a mixture-of-experts (MoE) cross-attention mechanism, which allows the model to selectively attend to relevant information from each expert. The dynamic gating network is another key component that assigns soft weights to the extracted knowledge, ensuring that the most relevant information from various experts is effectively fused. This fine-grained approach, in conjunction with the coarse-grained context-aware expert routing, enables MoVA to leverage diverse visual representations for improved generalization across various multimodal tasks. Effective fine-tuning of the MoV-Adapter, therefore, is essential for MoVA to achieve state-of-the-art performance in multimodal benchmarks. The training process, involving both pretraining and supervised finetuning stages, plays a vital role in optimizing the MoV-Adapter’s parameters and maximizing its effectiveness.
Benchmark Evaluations#
A robust ‘Benchmark Evaluations’ section is crucial for establishing the credibility and impact of a research paper. It should present a comprehensive analysis of the proposed model’s performance across a diverse range of established benchmarks, comparing its results to existing state-of-the-art approaches. Transparency is key; the evaluation methodology should be meticulously described, including datasets used, metrics employed, and any preprocessing steps. The selection of benchmarks should be justified, demonstrating their relevance to the problem being addressed. Statistical significance should be evaluated, and potential limitations of the benchmarks themselves should be acknowledged. Finally, a discussion of both strengths and weaknesses of the model, as revealed by the benchmark results, would strengthen the conclusions and offer valuable insights for future research. A well-executed evaluation provides strong evidence supporting the paper’s claims and contributes significantly to the advancement of the field.
Future Research#
Future research directions for multimodal large language models (MLLMs) like MoVA should prioritize addressing inherent biases. Improving the robustness and generalizability of MLLMs across diverse visual domains is crucial, possibly by exploring more sophisticated expert selection mechanisms beyond the current coarse-to-fine approach. The hallucination problem, a significant limitation of powerful LLMs, needs focused attention. Further research could investigate the integration of external knowledge bases and incorporate stronger evaluation metrics assessing factual accuracy and avoiding biases. Investigating the ethical implications of increasingly powerful MLLMs is also critical, particularly concerning potential misuse in generating misleading information or perpetuating harmful stereotypes. Finally, exploring more efficient training methods that reduce both computational costs and environmental impact is essential for scaling MLLMs to even larger sizes and capabilities.
More visual insights#
More on figures

This figure illustrates the two-stage process of MoVA, a multimodal large language model. The first stage involves coarse-grained context-aware expert routing, where the LLM selects the most relevant vision experts based on the input image, user question, and expert descriptions. The second stage is a fine-grained expert fusion using the MoV-Adapter, which extracts task-specific knowledge from the selected experts and fuses it with the base vision encoder’s representation. This combined representation is then fed to the LLM to generate a response.
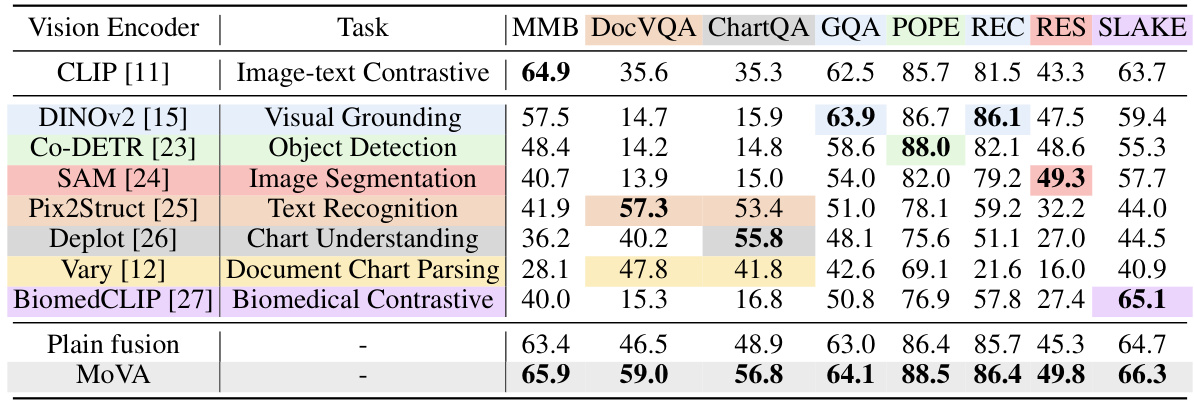
This figure illustrates the two-stage training process of the MoVA model. Stage 1 focuses on pretraining, enhancing the model’s ability to extract task-specific knowledge. Stage 2 involves supervised finetuning, aiming to improve the model’s overall multimodal capabilities. The diagram visually represents the flow of data and information through the model’s components (LLM, Vision Experts, MoV-Adapter, Base Encoder) during both stages, highlighting the different supervision strategies employed.
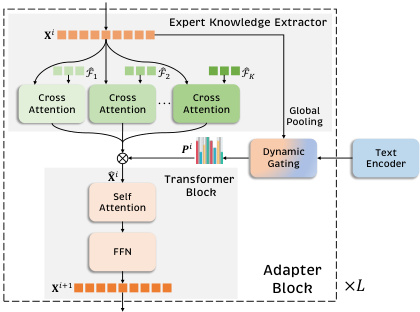
The MoV-Adapter consists of multiple adapter blocks and a text encoder. Each block contains an expert knowledge extractor, a dynamic gating network, and a transformer block. The expert knowledge extractor uses cross-attention layers to extract task-specific knowledge from selected vision experts. The dynamic gating network generates expert-wise soft weights based on multimodal context. The transformer block processes the fused visual representation. The text encoder extracts language context information from user instructions.

This figure illustrates the two-stage process of MoVA. The first stage, context-aware expert routing, uses the LLM to choose the best vision experts based on the input image and question. The second stage, fine-grained expert fusion with MoV-Adapter, then uses those selected experts to refine the visual representation before the LLM generates a final response. This process combines coarse-grained and fine-grained approaches to leverage the strengths of various vision experts.

The figure illustrates the two-stage process of MoVA: 1) Coarse-grained Context-Aware Expert Routing: The LLM selects context-relevant vision experts from a pool based on the user’s question and image. 2) Fine-grained Expert Fusion with MoV-Adapter: The MoV-Adapter extracts and fuses task-specific knowledge from the selected experts, enhancing the final visual representation before feeding it to the LLM for response generation. This coarse-to-fine approach leverages expert knowledge based on multimodal context and model expertise, improving generalization.
More on tables
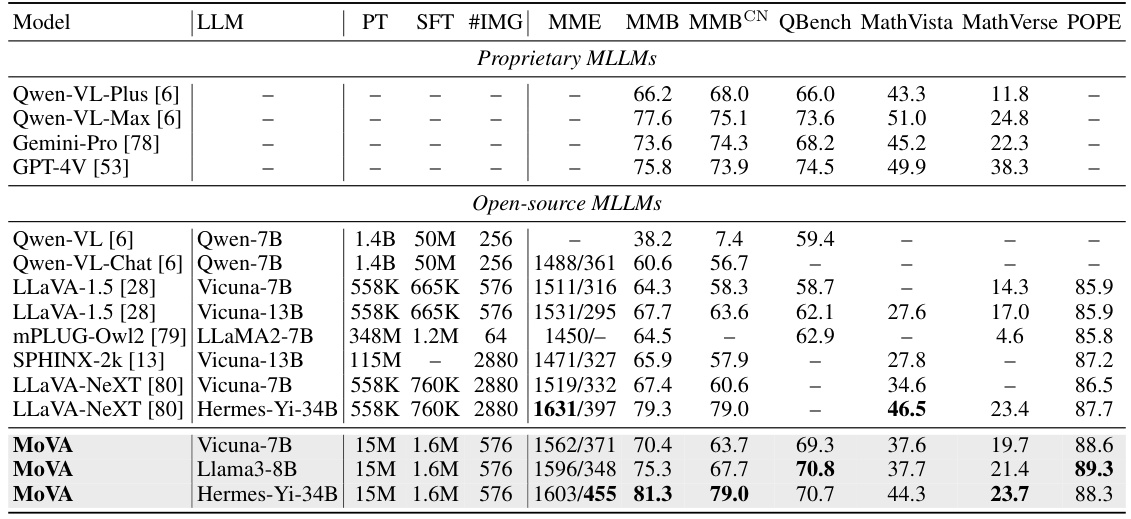
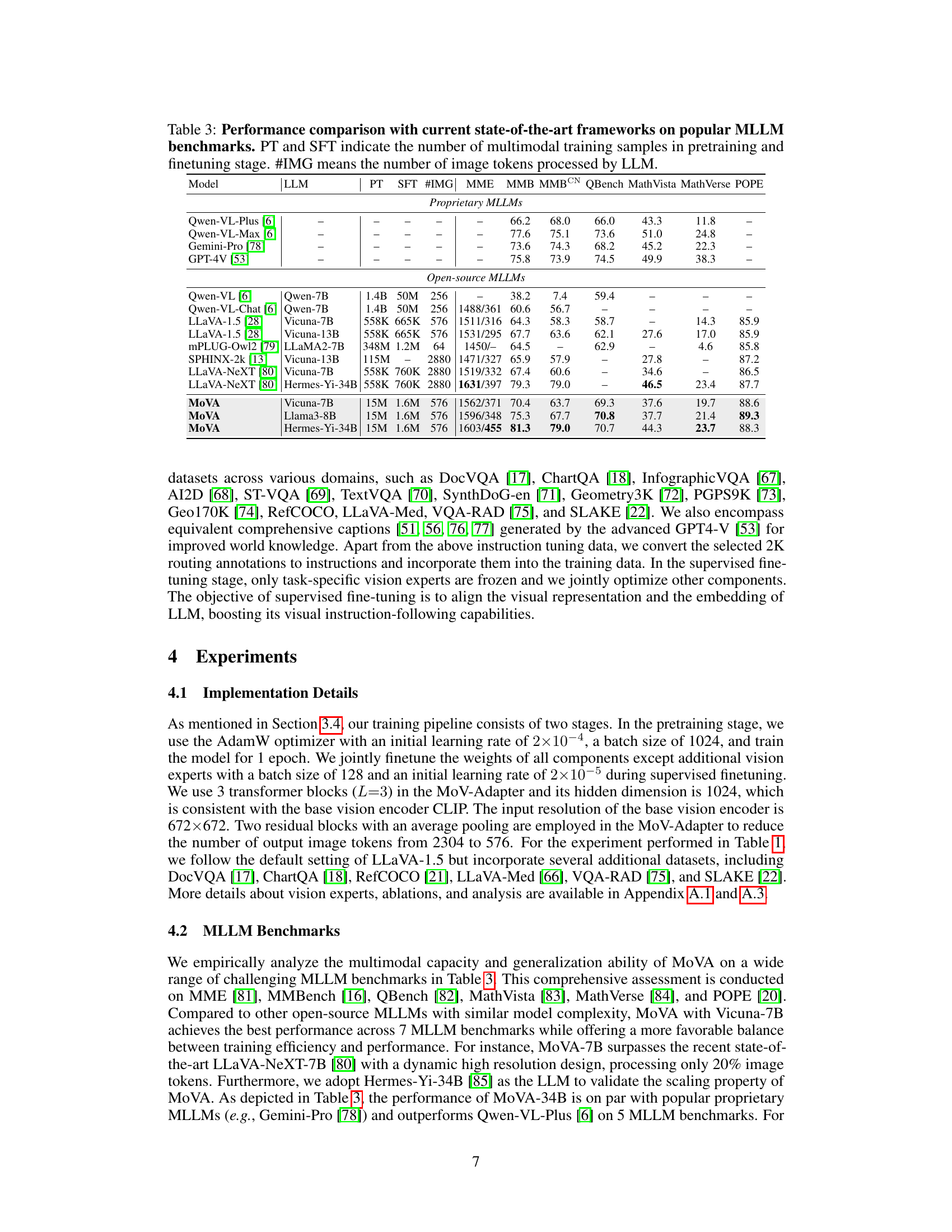
This table compares the performance of MoVA against other state-of-the-art multimodal large language models (MLLMs) across several benchmark datasets. The benchmarks cover a range of tasks, and the table shows various metrics including performance scores on each benchmark. The table also includes details about the language models used (LLM), the number of training samples used in both the pretraining and finetuning stages, and the number of image tokens processed by each model. This allows for a comparison of MoVA’s performance based on different LLMs and training scales.
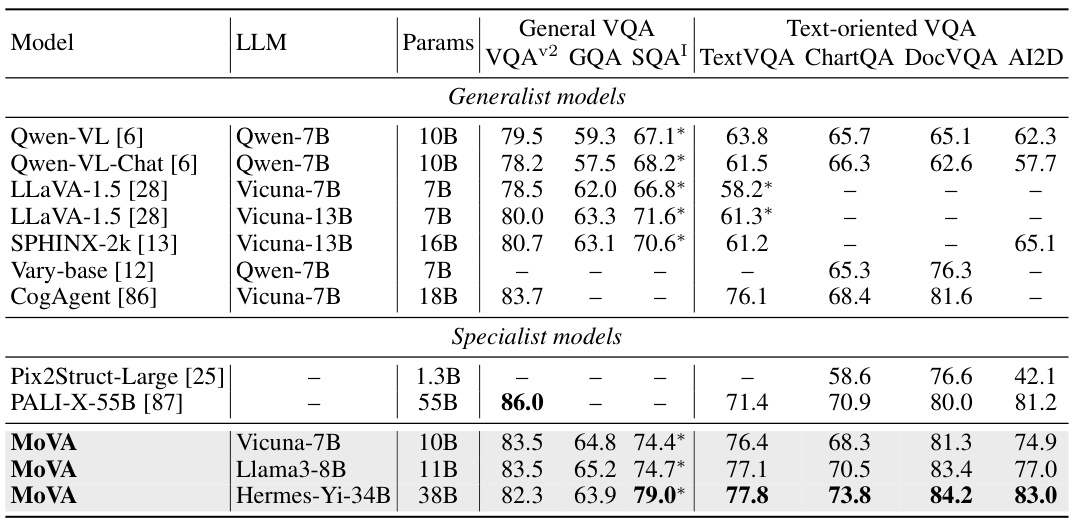
This table compares the performance of MoVA against other state-of-the-art multimodal large language models (MLLMs) across various benchmarks. It shows the model used (LLM), the number of parameters, the number of training samples used in pre-training (PT) and fine-tuning (SFT), the number of image tokens processed, and the performance scores on several benchmark tasks (MME, MMB, MMBCN, QBench, MathVista, MathVerse, POPE). The results highlight MoVA’s competitive performance, particularly its ability to achieve significant gains in challenging tasks.

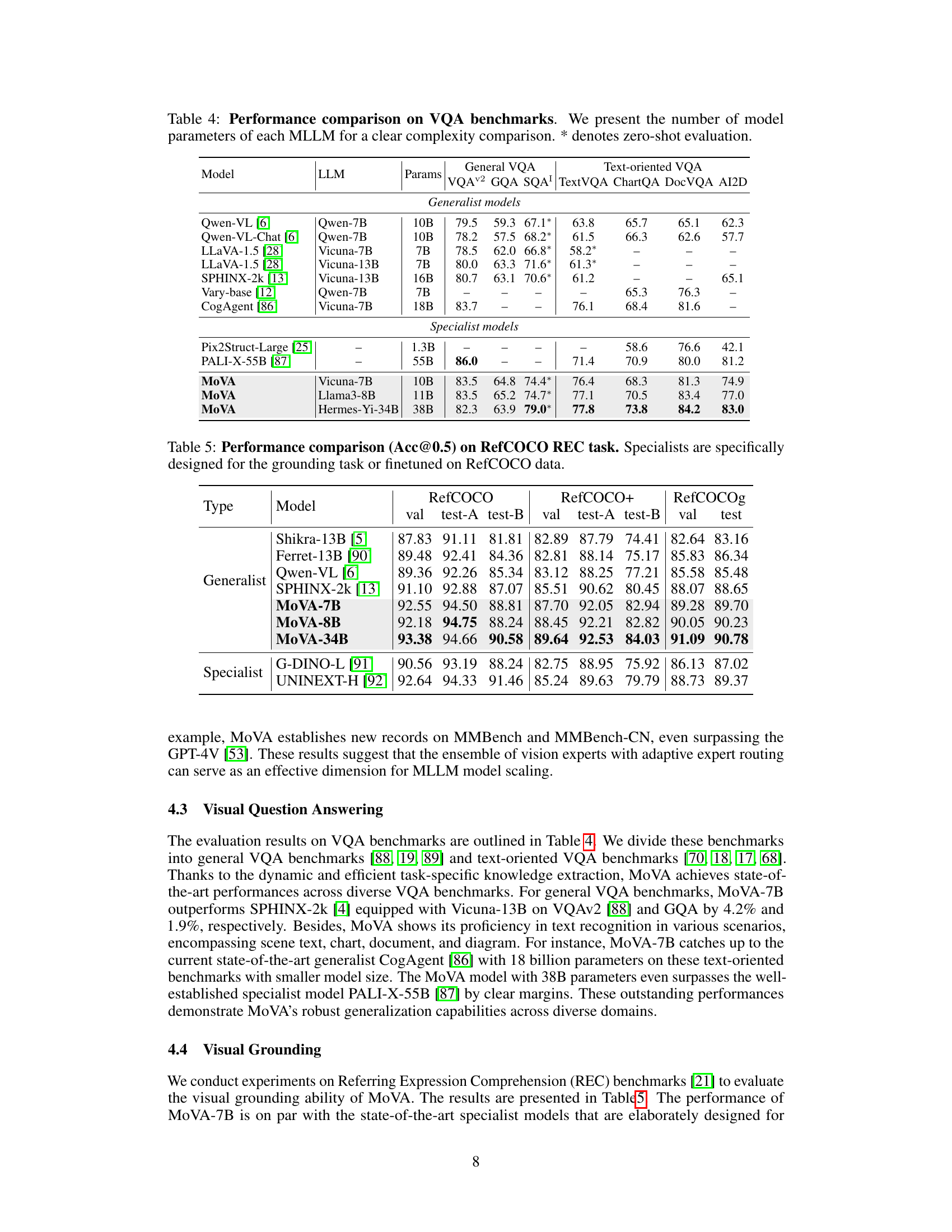
This table compares the performance of various models on the RefCOCO Referring Expression Comprehension (REC) task. The accuracy (Acc@0.5) is reported for three variations of the RefCOCO dataset (val, test-A, test-B). The models are categorized as either ‘Generalist’ (models with general-purpose capabilities) or ‘Specialist’ (models specifically designed for grounding tasks or finetuned on the RefCOCO dataset). The table aims to demonstrate MoVA’s performance relative to other generalist and specialist models, showcasing its effectiveness in a visual grounding task.
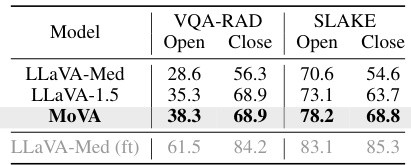
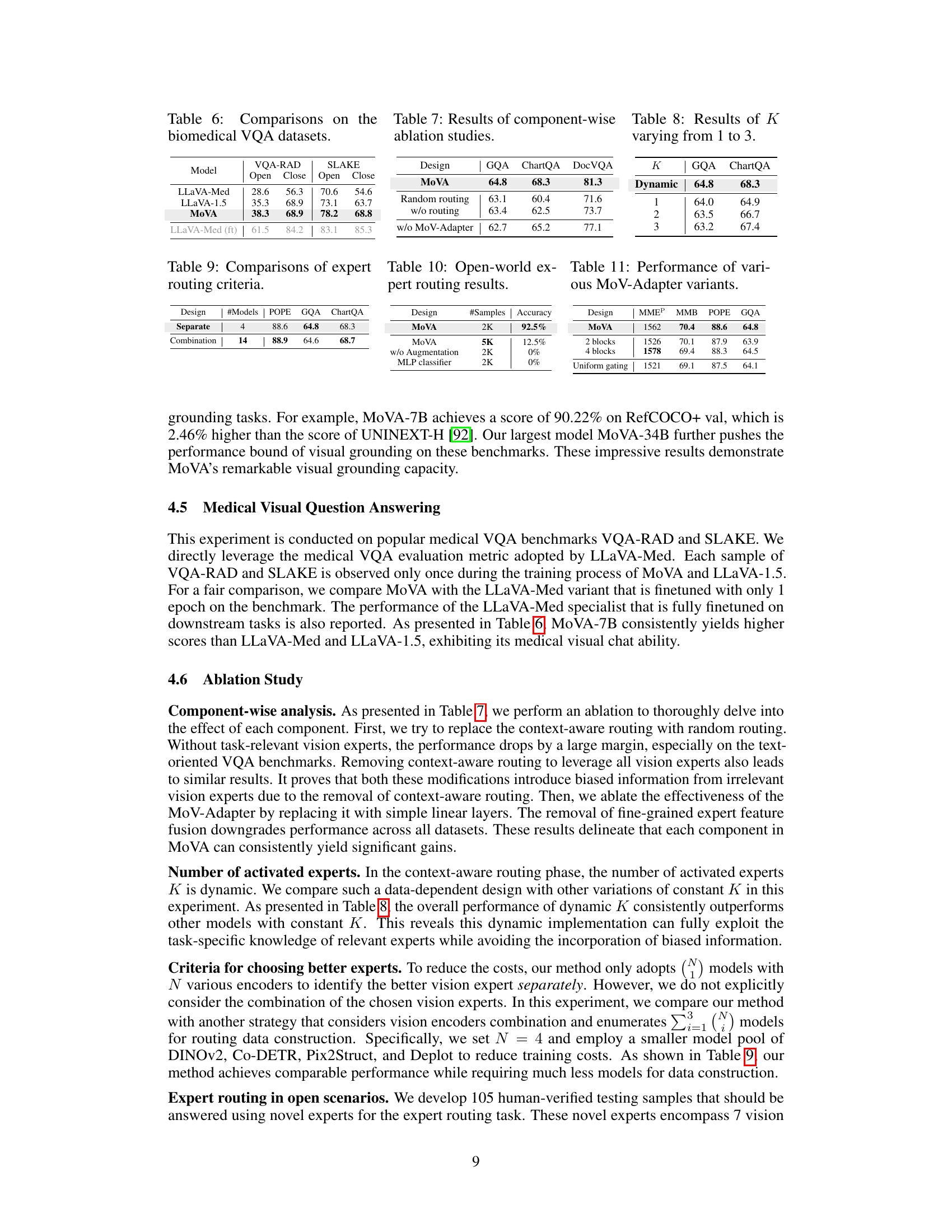
This table compares the performance of MoVA against LLaVA-Med and LLaVA-1.5 on two biomedical visual question answering (VQA) benchmark datasets: VQA-RAD and SLAKE. The results are broken down by whether the evaluation was open-set (Open) or closed-set (Close). LLaVA-Med (ft) represents the performance of LLaVA-Med after full finetuning on the benchmarks. MoVA shows improvements in both open- and closed-set settings, indicating its ability to generalize and perform well on unseen data.
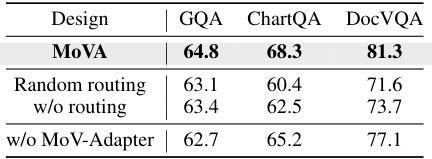
This table presents the results of ablation experiments conducted on the MoVA model. It shows the performance of MoVA compared to variations where key components are removed or replaced. Specifically, it examines the effect of removing the context-aware expert routing, removing the MoV-Adapter, and using random routing instead of context-aware routing. The results are presented in terms of accuracy on the GQA, ChartQA, and DocVQA benchmarks, highlighting the contribution of each component to the overall model performance.

This table presents the performance comparison of MoVA with different numbers of activated experts (K). The results are shown for two tasks: GQA and ChartQA. A dynamic selection of experts is compared against scenarios where a fixed number (1, 2, or 3) of experts are used. This helps illustrate the effectiveness of the model’s adaptive expert routing strategy.
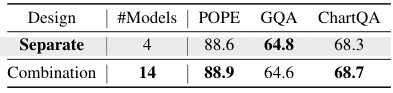
This table presents the results of ablation studies conducted on MoVA’s components. It shows the performance of MoVA on GQA, ChartQA, and DocVQA when using various configurations: The original MoVA design, a version with random routing instead of context-aware routing, a version without the routing mechanism entirely, and finally, a version without the MoV-Adapter. By comparing these configurations, the table helps to assess the contribution of each component of MoVA and determine the impact of the coarse-to-fine expert routing and fusion strategy.

This table presents the results of open-world experiments evaluating the performance of MoVA’s expert routing in scenarios with novel vision experts. It compares MoVA’s performance (measured by accuracy) against baselines using different numbers of training samples (2K vs. 5K) and alternative routing designs (removing data augmentation, using an MLP classifier instead of an LLM). The results demonstrate MoVA’s robustness and generalization ability in open scenarios.

This table details the configurations of the various vision experts used in the MoVA model. It shows the number of parameters (Params), the input resolution, width, depth, and the shape of the output feature map for each expert. The asterisk (*) indicates that a convolution layer is used to compress the output feature for that specific expert.

This table compares the performance of MoVA against other state-of-the-art Multimodal Large Language Models (MLLMs) across several popular benchmarks. It shows the performance (measured by different metrics depending on the benchmark) of various models, including different versions of MoVA using various LLMs (Vicuna-7B, Llama3-8B, and Hermes-Yi-34B). The table also provides information on the number of training samples used (both in pre-training and supervised fine-tuning stages) and the number of image tokens processed by the LLM for each model. This allows for a comparison of MoVA’s performance relative to other models, considering both model size and training data.
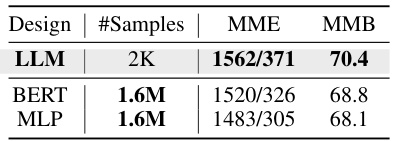
This table compares the performance of MoVA against other state-of-the-art multimodal large language models (MLLMs) across various benchmarks. It shows the model used (LLM), the number of training samples used in the pre-training (PT) and supervised fine-tuning (SFT) stages, the number of image tokens processed by the language model (#IMG), and the performance scores on several MLLM benchmarks: MME, MMB, MMBCN, QBench, MathVista, MathVerse, and POPE. The table helps demonstrate MoVA’s competitive performance against other models, especially considering its efficiency in processing a relatively smaller number of image tokens.

This table compares the performance of MoVA against other state-of-the-art multimodal large language models (MLLMs) on several popular benchmarks. It shows that MoVA achieves significant performance gains, particularly when using larger language models like Hermes-Yi-34B. The table also provides details on the number of training samples used for pretraining (PT) and finetuning (SFT), as well as the number of image tokens processed by the language model (#IMG). This demonstrates MoVA’s efficiency and effectiveness.
Full paper#