↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality, long videos from text remains a challenge in AI. Existing methods often rely on autoregressive techniques or chunked generation, but these can be computationally expensive and lead to temporal inconsistencies. Furthermore, existing methods generally require further training on longer video clips to generate quality long videos.
FIFO-Diffusion offers a solution by using a pretrained diffusion model and an innovative inference technique called diagonal denoising. This approach iteratively processes frames, simultaneously denoising and adding noise in a queue-like manner. Techniques like latent partitioning and lookahead denoising mitigate issues arising from this approach, resulting in efficient, high-quality video generation of arbitrary length. This approach requires constant memory usage, regardless of the target video length.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FIFO-Diffusion, a novel method for generating infinitely long videos from text descriptions without requiring additional training. This addresses a significant limitation of existing video generation models, which typically struggle with generating long, coherent videos. The method’s efficiency and scalability, achieved through diagonal denoising and latent partitioning, open up exciting new avenues for research in long-form video generation and related applications like video editing and special effects.
Visual Insights#

This figure shows three examples of 10,000-frame videos generated using FIFO-Diffusion. Each example demonstrates the model’s ability to maintain video quality and semantic consistency over a long sequence of frames, even though the model was only trained on short video clips (16 frames). The number on the top-left corner of each frame represents the frame index.

This table compares the Fréchet Video Distance (FVD) and Inception Score (IS) of FIFO-Diffusion against other video generation methods on the UCF-101 dataset. Lower FVD indicates better quality, while higher IS indicates better diversity and quality. FIFO-Diffusion uses the Latte model as a baseline and incorporates latent partitioning and lookahead denoising. The results show that FIFO-Diffusion achieves competitive or superior performance compared to existing methods.
In-depth insights#
FIFO-Diffusion Intro#
FIFO-Diffusion is introduced as a novel inference technique for generating long videos from text without requiring additional training. This is achieved through iterative diagonal denoising, processing consecutive frames with increasing noise levels in a queue. A fully denoised frame is dequeued at the head, while a new random noise frame is enqueued at the tail. The key innovation lies in its ability to generate arbitrarily long videos using only a pretrained diffusion model trained on shorter video clips, thereby overcoming the computational limitations of existing approaches that process videos frame-by-frame or in small chunks. The method cleverly addresses the inherent challenge of diagonal denoising by introducing latent partitioning to reduce the training-inference gap and lookahead denoising to leverage forward referencing. These techniques not only improve video generation quality but also allow for parallelization on multiple GPUs, making it computationally efficient. Overall, FIFO-Diffusion presents a significant advancement in text-to-video generation by efficiently creating long, high-quality videos using a constant memory footprint regardless of the target video length.
Diagonal Denoising#
Diagonal denoising, a core technique in FIFO-Diffusion, processes a series of video frames simultaneously. It leverages a queue of frames with increasing noise levels, iteratively denoising them in a diagonal manner. This clever approach allows noisier frames to benefit from cleaner, previously processed frames, leading to improved quality and coherence, especially in long video generation. However, this method introduces a training-inference gap because the model is trained on frames with uniform noise levels, unlike the varying noise levels encountered during inference. This gap is mitigated in FIFO-Diffusion using additional techniques like latent partitioning and lookahead denoising, which refine the diagonal denoising process. Essentially, diagonal denoising’s strength lies in efficiently utilizing the contextual information from preceding frames, creating a fluent, consistent video. But its inherent challenge necessitates complementary strategies to achieve optimal results and bridge the training and inference disparity.
Latent Partitioning#
Latent partitioning addresses a critical challenge in FIFO-Diffusion: the training-inference gap arising from diagonal denoising. Diagonal denoising, while enabling efficient long video generation, introduces a discrepancy because the model is trained on uniformly noised frames, unlike the varying noise levels encountered during inference. Latent partitioning mitigates this by dividing the queue of frames into multiple blocks, each processed independently. This reduces the range of noise levels within each block, thereby narrowing the training-inference gap and improving the accuracy of denoising. Parallel processing of these blocks across multiple GPUs also becomes feasible, significantly accelerating inference. Essentially, latent partitioning acts as a bridge, smoothing the transition between training and inference and thereby enhancing the quality and efficiency of generated long videos.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex system. In the context of a research paper on video generation, an ablation study would likely examine the impact of removing or altering specific modules or techniques on the overall video quality, generation speed, and memory usage. Key aspects to analyze would include the effects of removing diagonal denoising, latent partitioning, and lookahead denoising, comparing the results against the complete model and highlighting the trade-offs between performance metrics. For instance, removing latent partitioning might simplify the computational process but reduce the quality of longer videos. Removing lookahead denoising may reduce the accuracy of the frames generated. A well-designed ablation study should clearly demonstrate the importance of each component and provide insights into the design choices made by the researchers. The results will typically be presented as quantitative measures (e.g., FID scores, generation time) and qualitative analysis (e.g., visual comparisons of generated videos), showing the effect of each ablation on multiple aspects of the video generation process.
Future Work#
The authors suggest several promising avenues for future research. Extending FIFO-Diffusion’s training phase to incorporate diagonal denoising is a key area. This could significantly reduce the training-inference gap, leading to even higher-quality video generation. Exploring alternative queue management strategies beyond the FIFO approach could also improve performance. Different queue structures or prioritization methods might enhance temporal coherence or enable more efficient parallel processing. Investigating the impact of model architecture choices on FIFO-Diffusion’s efficacy warrants further exploration. Different baseline models might show varying degrees of success with this inference technique. Finally, applying FIFO-Diffusion to other generative models beyond video is a worthwhile pursuit. This could lead to breakthroughs in generating long sequences of other data modalities, such as audio or 3D point clouds.
More visual insights#
More on figures

This figure illustrates the FIFO-Diffusion process. A queue of frames is maintained, each with a different level of noise (timesteps). At each step, a frame is denoised, starting with the least noisy (top-right), removed from the queue, and a new, fully noisy frame is added to the queue (bottom-left). This diagonal processing allows the model to generate a continuous video sequence.

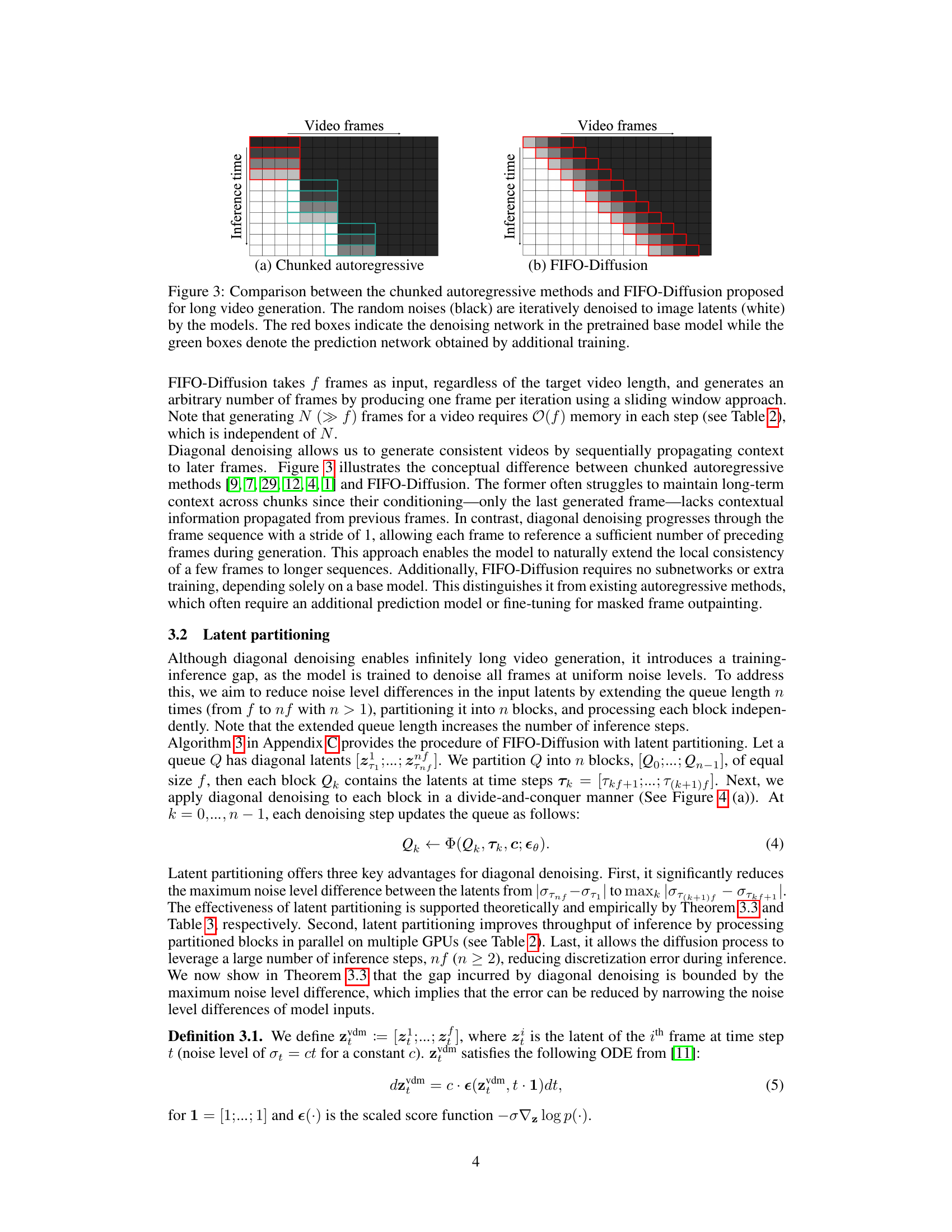
This figure compares the chunked autoregressive methods and FIFO-Diffusion methods. The chunked autoregressive approach processes small chunks of frames at a time, requiring additional training for each chunk to maintain consistency. In contrast, FIFO-Diffusion processes frames in a queue, allowing each frame to refer to preceding frames with lower noise levels. This results in an ability to generate arbitrarily long videos without requiring additional training for each frame.
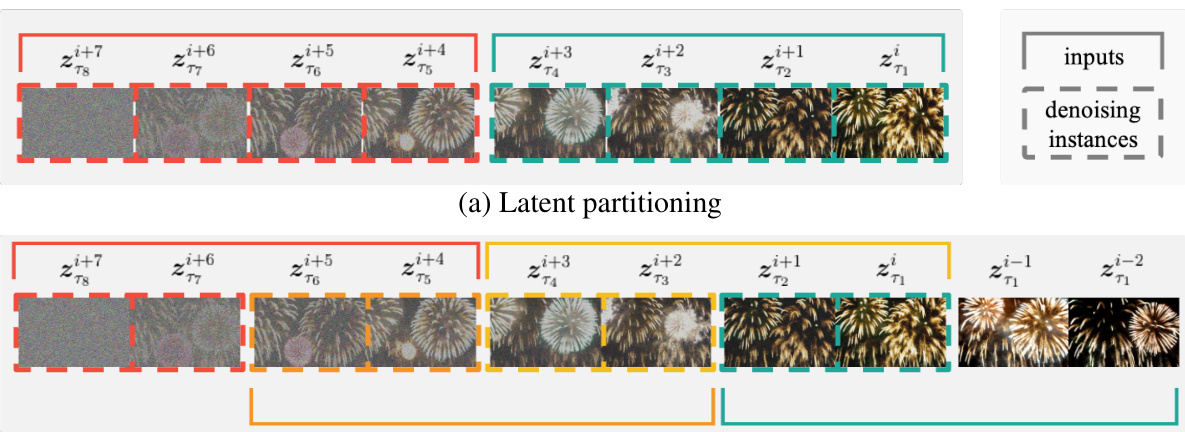
This figure illustrates the concepts of latent partitioning and lookahead denoising. Latent partitioning divides the frames into blocks to reduce the noise level difference between frames. Lookahead denoising leverages cleaner frames to improve denoising accuracy, but increases computational cost.
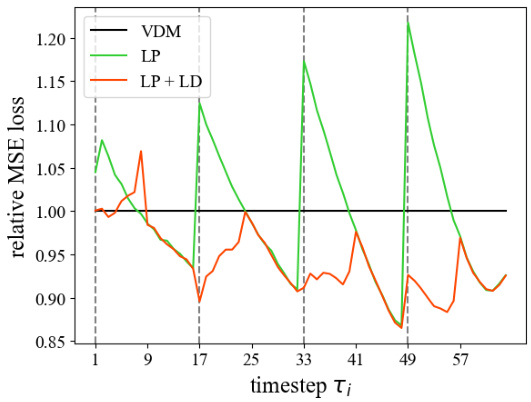
This figure shows the relative mean squared error (MSE) loss in noise prediction for different methods. The x-axis represents the timestep during the denoising process, and the y-axis shows the relative MSE loss. Three lines are plotted: VDM (original denoising), LP (latent partitioning), and LP+LD (latent partitioning with lookahead denoising). The plot demonstrates the effectiveness of latent partitioning and lookahead denoising in reducing the MSE loss compared to the baseline VDM method. Dashed vertical lines separate the different latent partitions.

This figure shows three example videos generated by the FIFO-Diffusion method. Each video is 10,000 frames long and based on a single text prompt. The top-left corner of each frame displays the frame index. The results demonstrate FIFO-Diffusion’s ability to generate long, high-quality videos from a model trained on much shorter video clips.

This figure compares the video generation quality of four different methods: FIFO-Diffusion, FreeNoise, Gen-L-Video, and LaVie+SEINE, all using the VideoCrafter2 model. It showcases a sample video generated by each method using the same prompt, illustrating differences in visual quality, motion smoothness, and overall coherence.
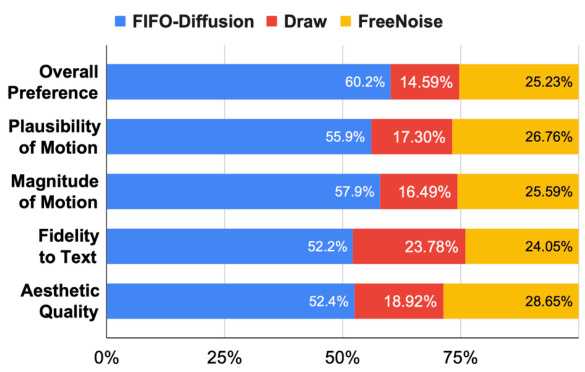
The figure shows the results of a user study comparing FIFO-Diffusion and FreeNoise across five criteria: Overall Preference, Plausibility of Motion, Magnitude of Motion, Fidelity to Text, and Aesthetic Quality. FIFO-Diffusion significantly outperforms FreeNoise in all criteria, demonstrating its superior performance in generating long videos.

This figure presents an ablation study comparing three versions of FIFO-Diffusion: one using only diagonal denoising (DD), another adding latent partitioning (DD+LP), and a third version incorporating both latent partitioning and lookahead denoising (DD+LP+LD). The goal is to show the impact of these components on the visual quality of the generated videos. Each row shows a different video generated using the same prompt but with a different version of the FIFO-Diffusion method. The number in the upper-left corner of each frame indicates the frame index.

This figure shows six video examples generated by FIFO-Diffusion using the VideoCrafter2 model. Each example is a 80-frame video clip, showcasing a different scene, and the caption provides a textual description of each video.

This figure shows several video frames generated using the FIFO-Diffusion method with the VideoCrafter2 model. Each row represents a different video, generated from a corresponding text prompt. The numbers in the top left corner of each frame indicate the frame index, demonstrating the ability of FIFO-Diffusion to generate long videos (over 80 frames shown per video).

This figure shows seven video examples generated using the FIFO-Diffusion method with the VideoCrafter2 model. Each example showcases a different scene, demonstrating the model’s ability to generate diverse and detailed videos based on text prompts. The numbers in the top left corner of each frame indicate the frame index, allowing for tracking of video progression.

This figure shows eight example videos generated using the FIFO-Diffusion method with the VideoCrafter1 model. Each video is accompanied by a text prompt describing its content (e.g., ‘A kayaker navigating through rapids, photorealistic, 4K, high quality.’). The numbered frames illustrate the temporal progression within each generated video sequence. The figure demonstrates the model’s ability to produce visually appealing and semantically coherent long videos.

This figure shows three examples of 10,000-frame videos generated by the FIFO-Diffusion method. Each video is based on a different text prompt, and the top-left corner of each frame displays its index in the sequence. The results demonstrate FIFO-Diffusion’s ability to produce long videos from a model initially trained only on much shorter (16-frame) video clips, maintaining high quality and consistent visual dynamics.

This figure shows three examples of 10,000-frame videos generated by the FIFO-Diffusion method. Each video is based on a text prompt, and the top-left corner of each frame shows the frame number. The examples demonstrate the method’s ability to generate very long videos from a model trained on much shorter videos (16 frames) without loss of quality or coherence.

This figure shows three examples of videos generated using FIFO-Diffusion with three different prompts sequentially given to the model. Each row represents a different video, where the prompts change during generation. The first video shows Ironman changing his actions in order of running, standing, and flying. The second is of a tiger walking, standing, and resting. The final video is a teddy bear walking, standing and dancing. The numbers in the top left corner show the frame index.

This figure shows three examples of 10,000-frame videos generated using the FIFO-Diffusion method. Each video is generated from a text prompt, and the top-left corner of each frame displays its index number. The results demonstrate that the FIFO-Diffusion method produces high-quality, long videos without any noticeable degradation, even though it uses a model trained only on short videos of 16 frames.

This figure shows three examples of 10,000-frame videos generated using the FIFO-Diffusion method. Each video is generated from a text prompt describing a scene (fireworks over Sydney Harbour, an astronaut on the moon, penguins on Antarctic ice). The top-left corner of each frame shows its index. The figure demonstrates the method’s ability to generate very long videos from a model trained on much shorter video clips (16 frames), without losing visual quality or the semantic meaning of the scene.

This figure shows three examples of 10,000-frame videos generated using FIFO-Diffusion. Each video is based on a different text prompt and uses a pretrained VideoCrafter2 model. The top-left corner of each frame displays its frame index, illustrating the long video generation capability. The results demonstrate that FIFO-Diffusion maintains high quality over the 10,000 frames, despite being trained on much shorter videos (only 16 frames).

This figure shows four examples of videos generated using FIFO-Diffusion with two prompts. Each row represents a different video, with the caption describing the content. The numbers at the top left of each frame indicate the frame index, providing a visual representation of the temporal progression of the video. The videos showcase the method’s ability to smoothly transition between different actions or scenes as specified in the prompts.

This figure compares the video generation quality of FIFO-Diffusion against other methods such as FreeNoise, Gen-L-Video, and LaVie+SEINE. The comparison uses two example video prompts: a vibrant underwater scene and a panoramic view of a peaceful Zen garden. The results show that FIFO-Diffusion produces videos with better visual quality and coherence than the other methods.

This figure compares the video generation results of four different methods: FIFO-Diffusion, FreeNoise, Gen-L-Video, and LaVie+SEINE, all using the VideoCrafter2 model. Each method generates a video based on the prompt ‘An astronaut floating in space, high quality, 4K resolution.’ The figure allows for a visual comparison of the video quality, motion smoothness, and overall fidelity to the prompt across the different methods.

This figure compares the video generation results of FIFO-Diffusion with three other methods: FreeNoise, Gen-L-Video, and LaVie+SEINE. Two example video clips are shown, each generated from the same prompt by all four methods. The comparison highlights the differences in video quality, motion smoothness, and overall fidelity to the text prompt.
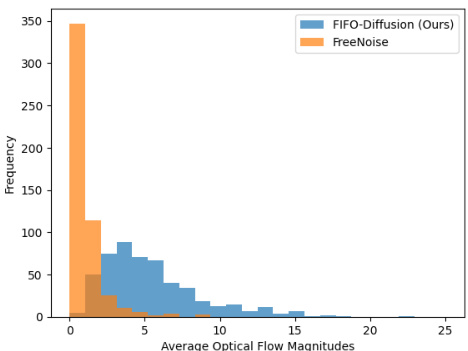
This histogram compares the average optical flow magnitudes for videos generated by FIFO-Diffusion and FreeNoise. The x-axis represents the average optical flow magnitude, indicating the amount of motion in the video. The y-axis shows the frequency of videos with that particular average optical flow magnitude. The graph shows that FIFO-Diffusion generates videos with a much broader range of motion compared to FreeNoise, which tends to produce videos with significantly less movement.

This figure shows the ablation study of FIFO-Diffusion. Three versions of the model are compared: only diagonal denoising (DD), diagonal denoising + latent partitioning (DD+LP), and diagonal denoising + latent partitioning + lookahead denoising (DD+LP+LD). The results show that latent partitioning and lookahead denoising significantly improve the quality and temporal consistency of the generated videos.

This figure shows the ablation study of the FIFO-Diffusion method. It compares the results of FIFO-Diffusion with only diagonal denoising (DD), with the addition of latent partitioning with n=4 (DD+LP), and with lookahead denoising (DD+LP+LD). Three different prompts were used to generate videos. The top row shows the results with diagonal denoising only, the middle row shows the results with diagonal denoising and latent partitioning, and the bottom row shows the results with all three components of the FIFO-Diffusion method. The number on the top-left corner of each frame indicates the frame index.

This figure shows the ablation study of the FIFO-Diffusion model. Three different versions of the model are compared: one using only diagonal denoising (DD), one with diagonal denoising and latent partitioning (DD+LP), and one with diagonal denoising, latent partitioning, and lookahead denoising (DD+LP+LD). The results for each model are displayed for the same video, and show the impact of latent partitioning and lookahead denoising on the quality of generated video frames.

This figure shows the results of an ablation study on the FIFO-Diffusion model, comparing the effects of diagonal denoising (DD), latent partitioning (LP), and lookahead denoising (LD). The top row shows the results using only diagonal denoising, the middle row shows the results with the addition of latent partitioning, and the bottom row shows the results with all three techniques. The image shows a close-up of a blooming rose and a tarantula for each ablation setting. The numbers on the top-left corners indicate the frame indices within each generated sequence. The figure helps to visually demonstrate the impact of each technique on the quality and temporal consistency of the generated videos.

This figure shows the ablation study results comparing three versions of FIFO-Diffusion: only diagonal denoising (DD), diagonal denoising + latent partitioning (DD+LP), and diagonal denoising + latent partitioning + lookahead denoising (DD+LP+LD). The results are visually presented for two different video prompts: a close-up of a tarantula walking and a detailed macro shot of a blooming rose. Each frame shows a different timestep of the diffusion process. The goal is to show how each component affects the final generated video quality and temporal consistency.
More on tables

This table compares the memory usage and inference time per frame for four different long video generation methods: FreeNoise, Gen-L-Video, and FIFO-Diffusion (using both 1 and 8 GPUs). The results are shown for videos of varying lengths (128, 256, and 512 frames). It highlights the memory efficiency of FIFO-Diffusion, demonstrating that its memory usage remains constant regardless of video length, unlike the other methods. The table also shows the significant speedup achieved by using multiple GPUs with FIFO-Diffusion.

This table compares the Fréchet Video Distance (FVD) and Inception Score (IS) on the UCF-101 dataset for several video generation methods. The scores measure the quality and diversity of generated videos. It shows that the proposed FIFO-Diffusion method with latent partitioning and lookahead denoising achieves state-of-the-art performance compared to other methods.

This table compares the memory usage and inference time per frame for different long video generation methods. It shows that FIFO-Diffusion maintains a constant memory usage regardless of video length, unlike other methods, making it more efficient for generating very long videos. The use of latent partitioning and lookahead denoising in FIFO-Diffusion are also highlighted, demonstrating their impact on performance and memory usage, especially when using multiple GPUs for parallel processing.
Full paper#