TL;DR#
Large language models (LLMs) demand significant computing power, hindering their deployment on resource-limited devices. Current methods process each token equally, despite varying importance. This inefficiency leads to unnecessary resource consumption and limits accessibility.
D-LLM addresses this by dynamically adjusting resource allocation during token processing. A decision module determines whether each transformer layer should execute, skipping layers for less crucial tokens. An effective eviction policy manages KV-cache efficiently. Experimental results demonstrate substantial performance improvements, achieving up to a 50% reduction in computational cost and memory usage across various tasks without compromising accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to optimize large language model inference, addressing a critical challenge in deploying LLMs on resource-constrained platforms. It offers a significant advancement in parameter and resource efficiency, opening new avenues for research into dynamic inference paradigms and adaptive resource allocation.
Visual Insights#

🔼 This figure illustrates the framework of D-LLMs, a dynamic inference mechanism for large language models. It shows three parts: (a) overall architecture with dynamic decision modules before each transformer layer, (b) the structure of a dynamic decision module, and (c) how the KV-cache eviction mask works with the causal mask in the self-attention module. The dynamic decision module determines whether a transformer layer should be executed or skipped based on input features. The KV-cache eviction strategy optimizes memory usage by excluding skipped layers from subsequent attention calculations.
read the caption
Figure 1: The framework the proposed D-LLMs. The inference paradigm of dynamic decisions for transformer layers is shown in Fig. 1a. The design of dynamic execution decision modules is shown in Fig. 1b. The mask in multi-head self-attention with eviction strategy is shown in Fig. 1c.
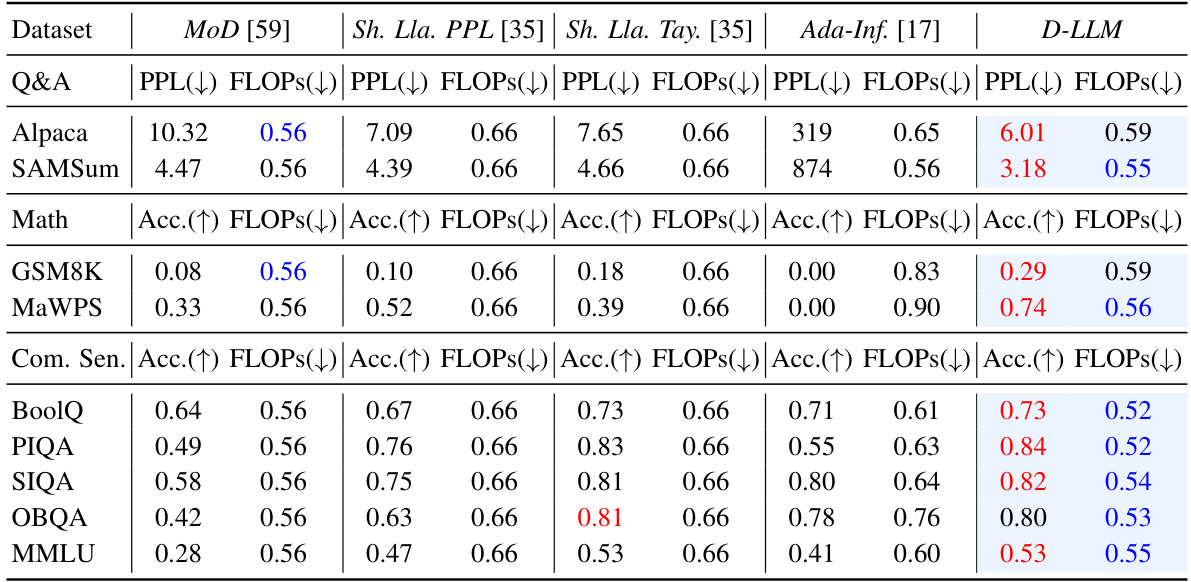
🔼 This table compares the performance of D-LLM against other state-of-the-art methods on various tasks using the LLaMA2-7B model. It shows the perplexity (PPL) or accuracy (Acc.) achieved by each method, along with the fraction of FLOPs (floating-point operations) used relative to a baseline. Lower PPL and higher Acc. indicate better performance, while lower FLOPs indicate better efficiency. The best performance and lowest computational cost are highlighted in red and blue, respectively. Abbreviations used are explained in the caption.
read the caption
Table 1: Performance Comparison on different tasks under Few-shot Settings based on LLaMA2-7B. Sh. Lla. PPL refers to Shortened-LLaMA applying PPL metric. Sh. Lla. Tay. refers to Shortened-LLaMA applying Taylor metric. Ada-Inf. refers to Ada-Infer. For convenience, we mark the best performance in red and the lowest computational cost in blue.
In-depth insights#
Adaptive Inference#
Adaptive inference, in the context of large language models (LLMs), represents a paradigm shift from traditional static inference methods. Instead of processing every token with the same computational resources, adaptive inference dynamically adjusts resource allocation based on the inherent characteristics of each token. This approach is particularly attractive because LLMs are computationally expensive. By identifying and prioritizing critical information (e.g., key words, complex grammatical structures), adaptive inference strategies such as the one presented in the D-LLM paper significantly reduce computational costs and memory overhead without sacrificing performance. The key is to design intelligent decision-making modules to decide which transformer layers are necessary for specific tokens. While this offers substantial benefits, the challenge lies in maintaining compatibility with existing LLM architectures and efficiently managing the KV cache. Strategies like dynamic eviction of unneeded KV embeddings are essential for practical deployment. The success of this approach hinges on both the effectiveness of the decision-making module and the efficient implementation of the proposed modifications to existing LLMs, avoiding retraining or substantial architectural changes.
Dynamic KV-Cache#
A dynamic KV-cache cleverly addresses the challenge of efficiently managing key-value (KV) pairs in large language models (LLMs) during inference, especially when employing techniques like layer skipping. Traditional KV-caches store all KVs for each token, leading to wasted storage when layers are skipped. A dynamic approach, in contrast, adaptively updates the cache based on the execution decisions of each layer. This means that when a layer is skipped, its associated KVs aren’t stored or are immediately evicted. This reduces memory footprint significantly. An eviction policy is crucial here to determine which KVs to keep and which to discard, balancing computational savings with the need to maintain sufficient context for accurate processing of subsequent tokens. Effective eviction strategies will likely involve heuristics based on token importance or layer significance to minimize performance impact while maximizing storage efficiency. The optimal design of such a dynamic KV-cache is a complex optimization problem balancing speed, memory usage, and model accuracy, requiring careful consideration of both algorithmic efficiency and practical implementation details.
Acceleration Rate#
The concept of ‘acceleration rate’ in the context of optimizing large language model (LLM) inference is crucial. It represents the degree to which the model’s computational cost is reduced without significant performance degradation. A higher acceleration rate signifies greater efficiency, allowing for faster processing and deployment on resource-constrained platforms. The paper likely explores different strategies to achieve this, such as adaptive resource allocation and layer skipping, quantifying the trade-offs between acceleration and accuracy. Customizability of the acceleration rate is a key aspect, enabling users to tailor the speed-accuracy balance to their specific needs. The effectiveness of this customization hinges on precisely controlling the execution of individual layers based on token importance. Therefore, a detailed analysis of the acceleration rate should delve into how it is calculated and how factors like token significance and layer complexity influence it, revealing the delicate balance between efficiency gains and potential accuracy loss. Ultimately, the effectiveness of the acceleration rate becomes a key indicator of the feasibility and scalability of adaptive inference techniques for LLMs.
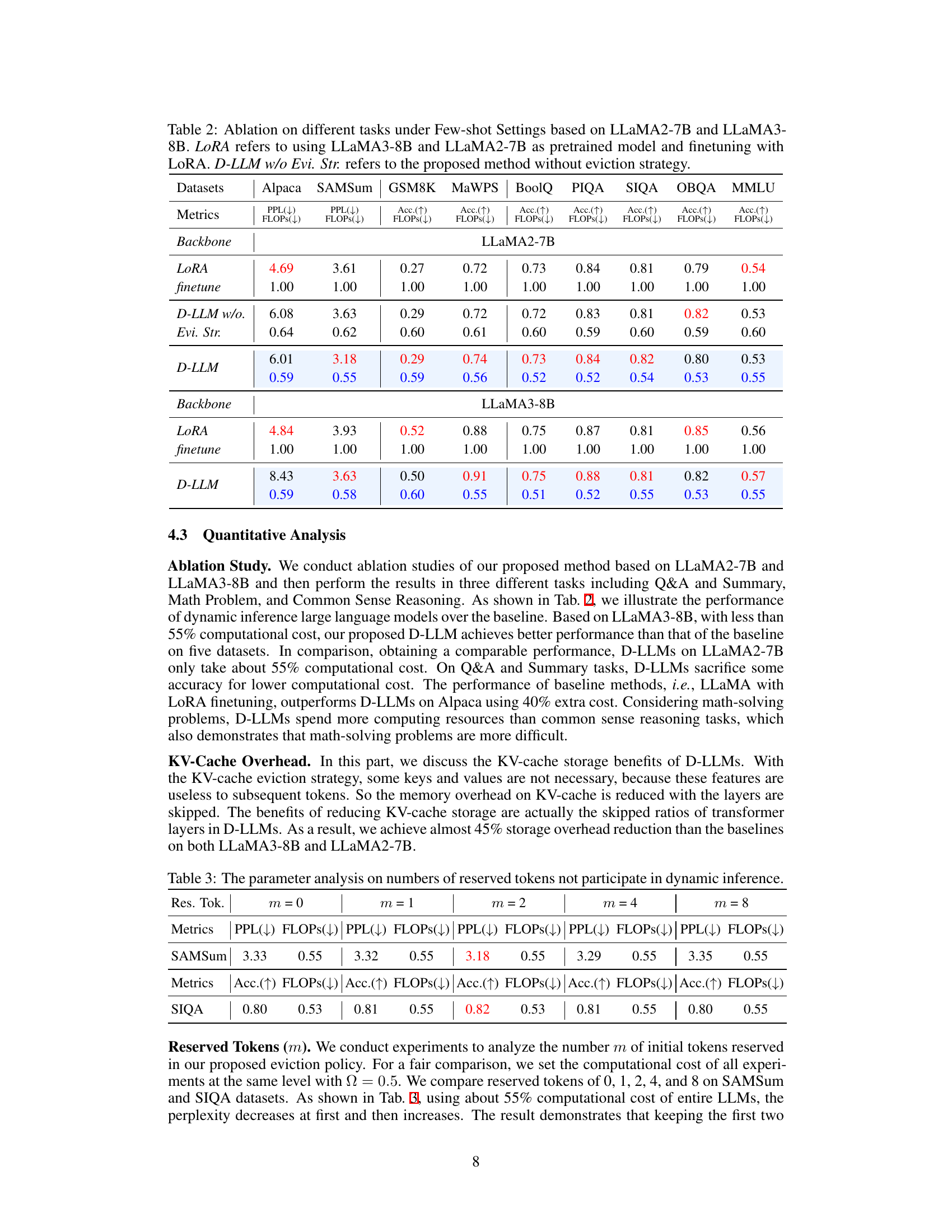
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a large language model (LLM) like the one described, this might involve selectively disabling different modules (e.g., the dynamic decision module, the KV-cache eviction strategy) or varying hyperparameters. The goal is to isolate the impact of each component on overall performance and resource utilization. A well-designed ablation study clarifies which parts are crucial for the model’s efficiency and accuracy, and which aspects contribute to potential limitations. By removing or altering key aspects such as the dynamic execution decision or the eviction strategy, researchers can quantify their individual effects on computational cost and accuracy. The findings from such an analysis would be crucial in demonstrating the model’s design choices and justifying the effectiveness of its resource-adaptive approach. For example, removing the eviction strategy would demonstrate its role in optimizing KV-cache usage. Conversely, isolating the effect of the dynamic decision module highlights how much it contributes to reducing computational costs and whether that impacts overall performance. Successfully conducted ablation studies would provide strong evidence supporting the core claims made in the paper. This is a rigorous validation of the approach and allows for a more nuanced understanding of the model’s strengths and weaknesses.
Future Research#
Future research directions stemming from this work on D-LLMs could explore several key areas. Improving the dynamic decision module is crucial; more sophisticated mechanisms could be developed, perhaps incorporating learned representations of task difficulty or token importance. This could lead to even greater efficiency and accuracy. Investigating the impact of different eviction strategies on the KV cache is another promising avenue. Exploring alternative architectures beyond the transformer could reveal further performance gains, particularly given the potential for specialized hardware acceleration. The research could also examine the application of D-LLMs to a broader range of tasks and larger language models. Extensive experimentation on diverse domains and datasets, alongside rigorous benchmarking, would strengthen the claims made about the model’s adaptability and efficiency. Finally, investigating the trade-offs between computational cost reduction and potential accuracy loss is essential. This would enable better design choices for various deployment scenarios. Overall, significant advancements in parameter-efficient fine-tuning are achievable with further exploration of the discussed areas.
More visual insights#
More on figures

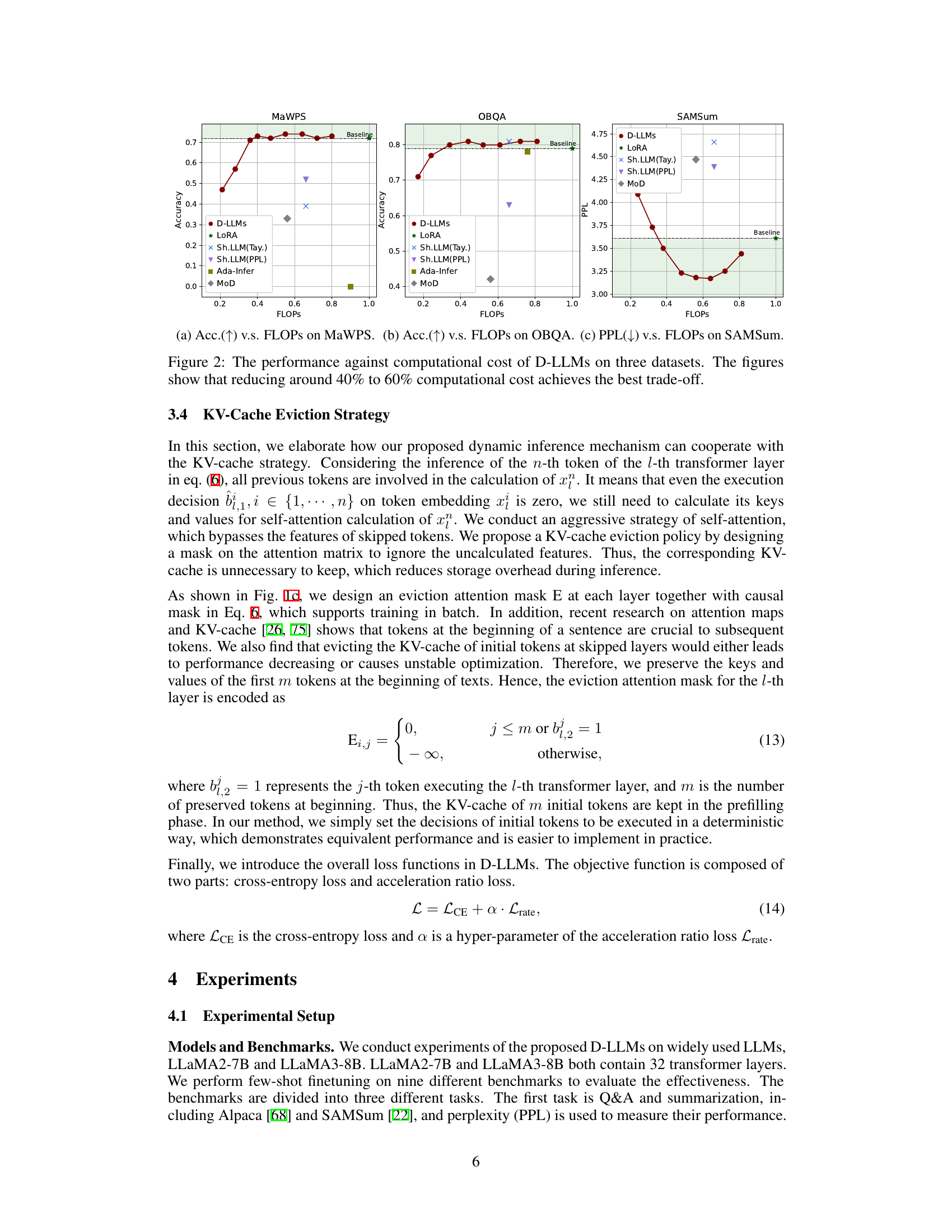
🔼 This figure compares the performance (accuracy or perplexity) against computational cost (FLOPs) for three different datasets (MaWPS, OBQA, and SAMSum) using D-LLMs and other methods (LoRA, Shortened-LLaMA, Ada-Infer, MoD). It demonstrates that D-LLMs achieve a good balance between performance and reduced computational cost, showing superior performance with around 40-60% less FLOPs compared to the baseline.
read the caption
Figure 2: The performance against computational cost of D-LLMs on three datasets. The figures show that reducing around 40% to 60% computational cost achieves the best trade-off.

🔼 This figure visualizes the execution ratios of different grammatical terms across various layers of the D-LLM model. Each subplot represents a different layer, showing the distribution of execution ratios for number/math symbols (blue), subject terms (red), and modal verbs (green). The distance from the center of each circle indicates the execution ratio, with points closer to the edge having a higher execution ratio. The overall distribution of execution ratios for each grammatical category provides insights into the role of different layers in processing various linguistic elements.
read the caption
Figure 3: Execution ratios on different layers of three grammatical terms. Blue dots refer to number and math symbols, e.g., '1, +, ×'. Red dots refer to subject terms, e.g., 'She, He, They'. Green dots refer to modal verbs, e.g., ‘may, should, might'. The distance of a dot to the center represents executing ratio. The red circle is probability of 100% and the blue circle is the average ratios.
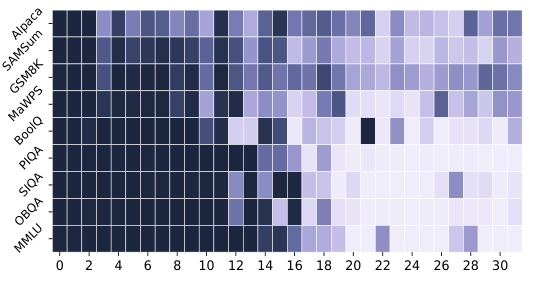
🔼 This figure visualizes the execution ratios of different layers in the D-LLM model for various tasks and questions. Panel (a) shows a heatmap illustrating the average execution ratios across layers for different benchmark datasets. Warmer colors indicate higher execution ratios, suggesting that certain layers are used more frequently for specific tasks. Panel (b) presents line graphs showing the execution ratios across layers for six example questions from the MMLU benchmark. The lines reveal how the utilization of different layers varies depending on the specific question, reflecting task complexity and information content.
read the caption
Figure 4: The execution ratios of different layers visualizations on Benchmarks and Questions. Fig. 4a shows the execution ratios of different benchmarks on respective layers. A deeper color refers to a higher execution ratios. Fig. 4b shows six standard questions' execution ratios over layers from MMLU. The Y-axis is the execution ratios and X-axis is the layer index.
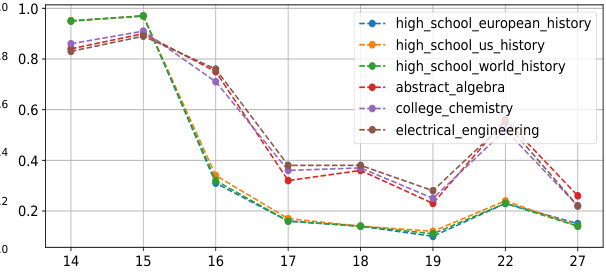
🔼 This figure visualizes the execution ratios of different layers in the D-LLM model for various tasks and questions. Panel (a) shows the execution ratios across layers for different benchmark datasets, revealing that different types of tasks (e.g., Q&A, summarization, common sense reasoning) utilize different layers to varying degrees. Panel (b) further illustrates this point by showing the execution ratios for individual questions from the MMLU benchmark, highlighting that similar questions tend to have similar layer usage patterns. This demonstrates the adaptive nature of the D-LLM’s resource allocation strategy.
read the caption
Figure 4: The execution ratios of different layers visualizations on Benchmarks and Questions. Fig. 4a shows the execution ratios of different benchmarks on respective layers. A deeper color refers to a higher execution ratios. Fig. 4b shows six standard questions' execution ratios over layers from MMLU. The Y-axis is the execution ratios and X-axis is the layer index.
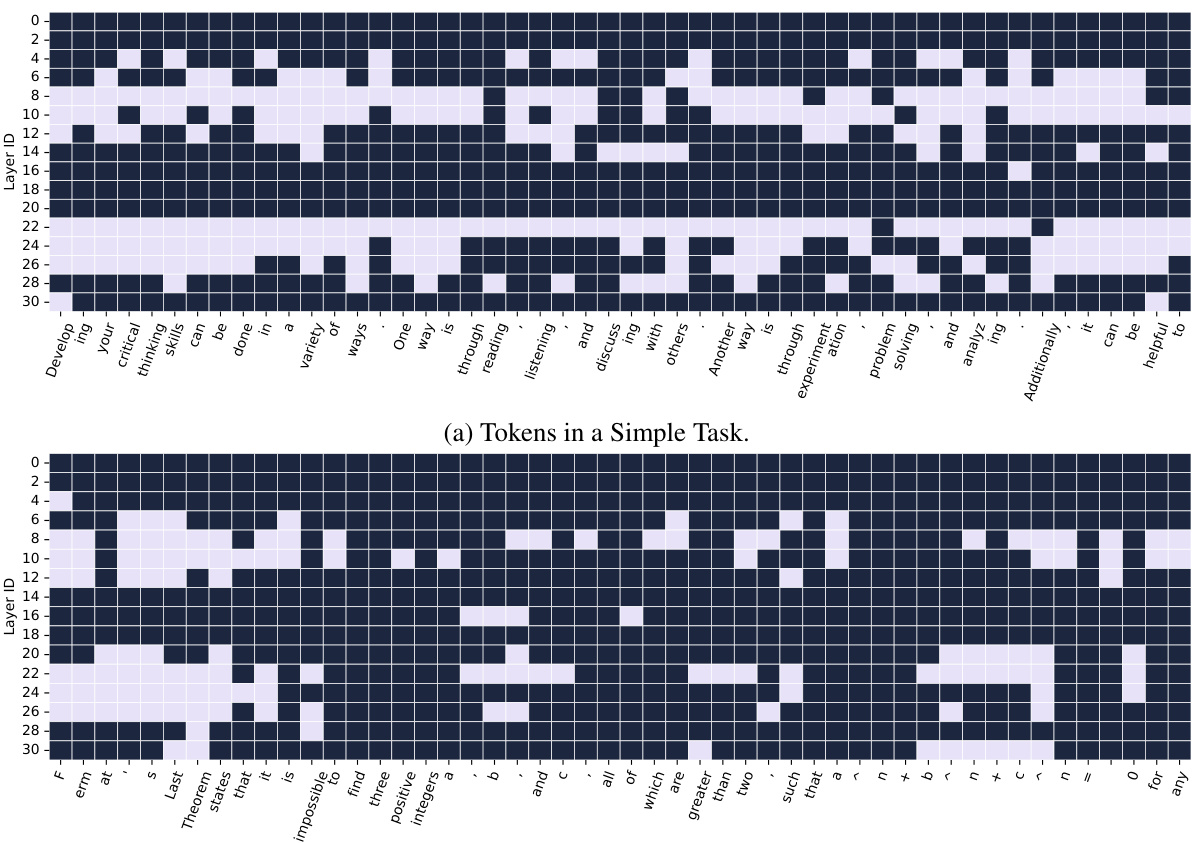
🔼 This figure visualizes the difference in layer execution patterns between simple and complex tasks using the D-LLM model. The top half shows the execution pattern for the question, ‘How can I develop my critical thinking skills?’, while the bottom half shows the pattern for the more complex question, ‘Can you explain Fermat’s Last Theorem?’ The figure uses a heatmap to represent layer execution decisions for each token, where filled blocks indicate that a layer was executed for that token, and empty blocks indicate that it was skipped. The difference in execution patterns highlights the adaptive nature of D-LLM, showing how it utilizes more layers for more complex tasks.
read the caption
Figure 5: The transformer layers to be executed for tasks of different difficulties in D-LLMs. fig. 5a is the execution decisions, when D-LLM answers 'How can I develop my critical thinking skills?'. fig. 5b is the execution decisions, when D-LLM answers 'Can you explain Fermat's Last Theorem?'. The second question is more difficulty than the first one, therefore, utilizing more transformer layers. A filled block refers to a token executing the corresponding layer, while an empty block refers to a token skipping the corresponding layer.

🔼 This figure visualizes the execution ratios of layers under different computational costs for the MaWPS and OBQA datasets. The vertical axis represents the computational cost (ranging from 27% to 80%), and the horizontal axis represents the layer indices (from 2 to 30). Each cell in the heatmap displays the execution ratio of a specific layer at a given computational cost. Darker colors indicate that a higher proportion of tokens execute that layer at that cost, while lighter colors indicate that a smaller proportion of tokens execute that layer.
read the caption
Figure 6: Execution Decisions over Layers under different ratios on MaWPS and OBQA. The vertical coordinate is the computational cost. The horizontal coordinate is the indices of layers. A dark color refers to most tokens execute the layer, while a light color refers to most tokens skip the layer.
More on tables
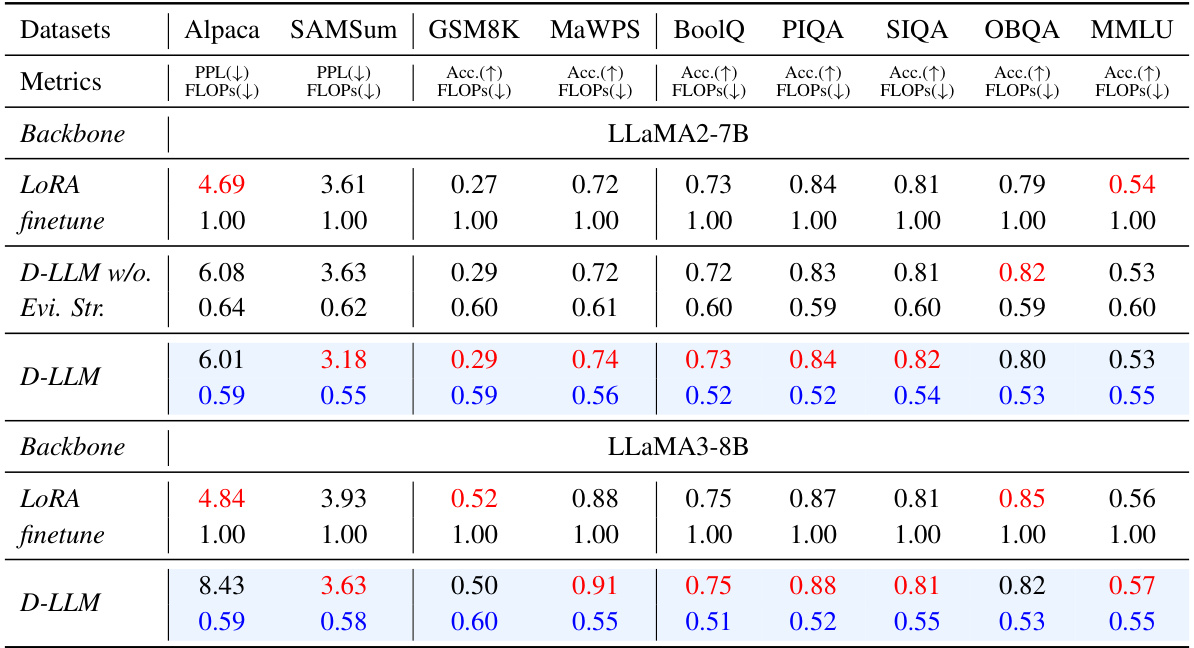
🔼 This table compares the performance of D-LLM against other methods (MoD, Shortened-LLaMA with PPL and Taylor metrics, Ada-Infer) on various tasks (Q&A, Math, Common Sense Reasoning) using the LLaMA2-7B model. It shows the perplexity (PPL) or accuracy (Acc.) and FLOPs (floating-point operations) for each method across multiple datasets. The best performance and lowest computational cost are highlighted for each dataset.
read the caption
Table 1: Performance Comparison on different tasks under Few-shot Settings based on LLaMA2-7B. Sh. Lla. PPL refers to Shortened-LLaMA applying PPL metric. Sh. Lla. Tay. refers to Shortened-LLaMA applying Taylor metric. Ada-Inf. refers to Ada-Infer. For convenience, we mark the best performance in red and the lowest computational cost in blue.
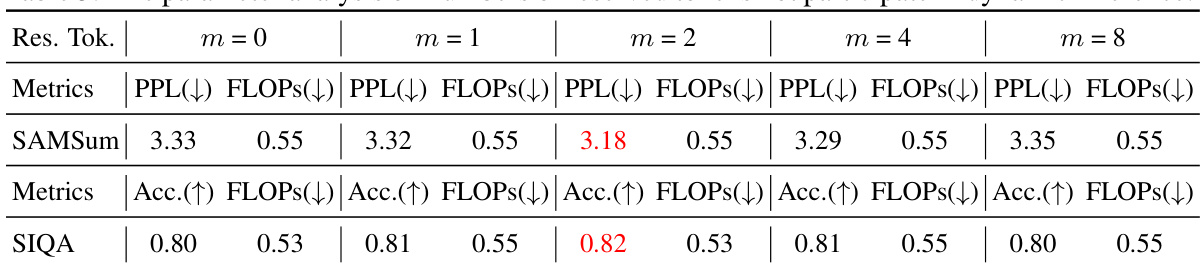
🔼 This table presents the results of ablation studies conducted to determine the optimal number of reserved tokens (m) in the D-LLMs’ KV-cache eviction strategy. The experiments measure the impact of varying the number of reserved tokens (m = 0, 1, 2, 4, 8) on perplexity (PPL) for the SAMSum task and accuracy (Acc.) for the SIQA task, while maintaining a consistent computational cost (FLOPs). The optimal value of m is selected based on the best performance (lowest PPL and highest Acc.) observed for each task.
read the caption
Table 3: The parameter analysis on numbers of reserved tokens not participate in dynamic inference.

🔼 This table presents the accuracy and perplexity results for three different benchmarks (MaWPS, OBQA, and SAMSum) under various levels of computational cost (expressed as a fraction of FLOPs). It shows the trade-off between model accuracy/perplexity and computational resource usage, demonstrating the effectiveness of the D-LLMs approach in achieving high accuracy/low perplexity with reduced computational cost. The results illustrate that D-LLMs can significantly reduce computational cost while maintaining competitive performance compared to a baseline model.
read the caption
Table 4: The accuracy against computational cost on MaWPS, OBQA, and SAMSum datasets.
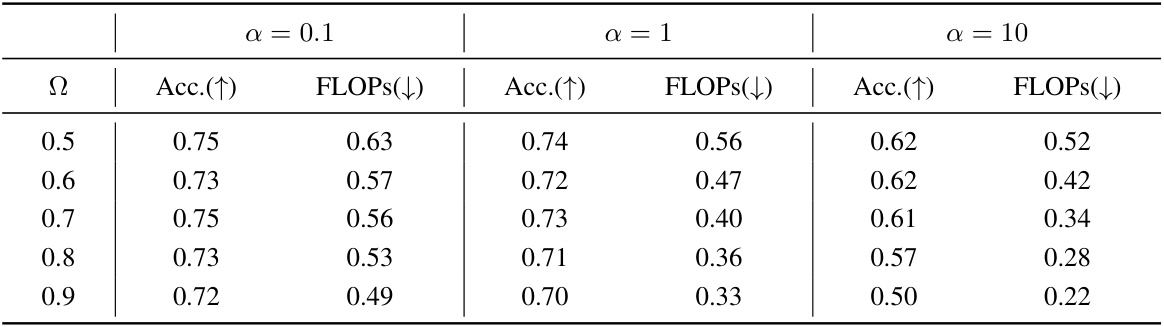
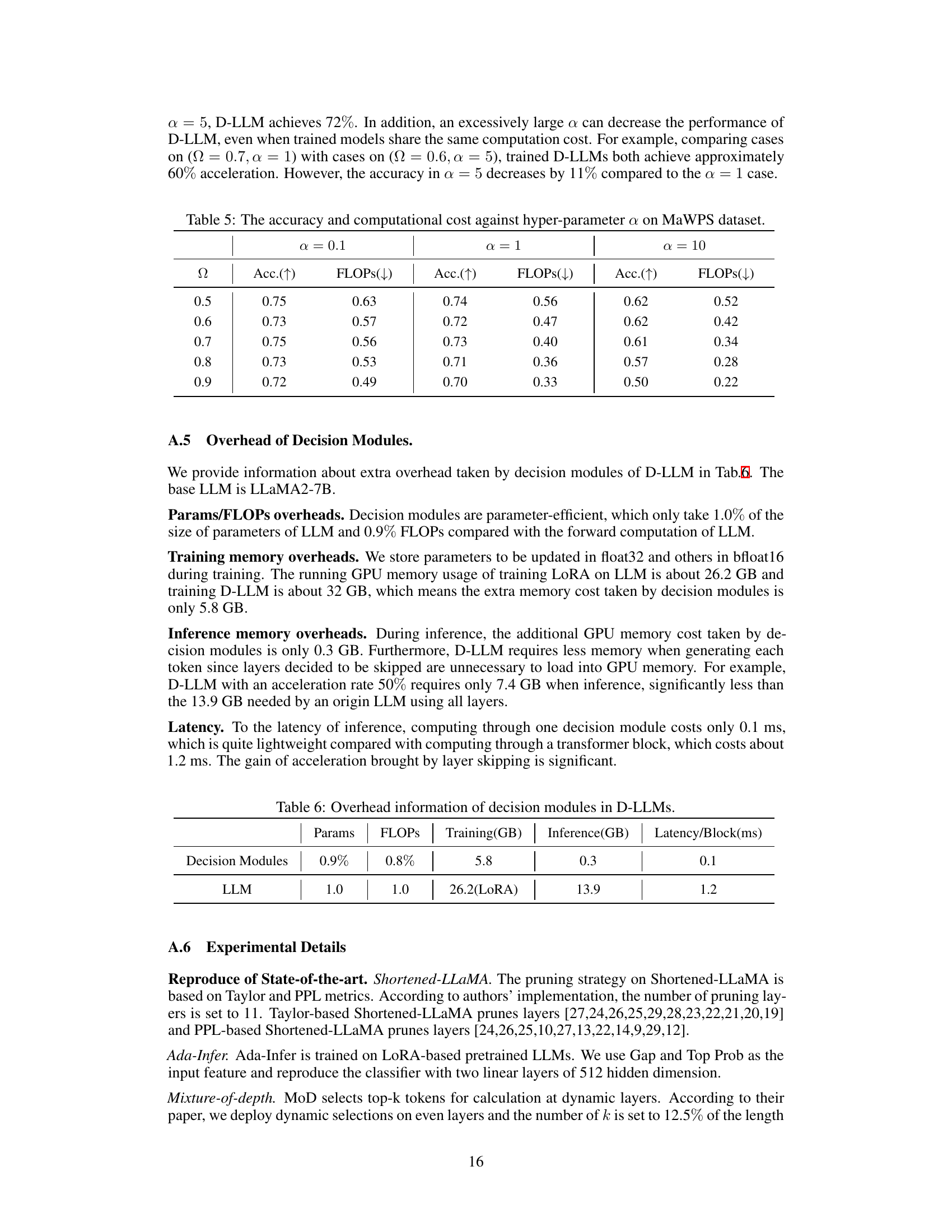
🔼 This table shows the accuracy and computational cost (represented by FLOPs) obtained by D-LLMs on the MaWPS dataset under different values of hyperparameter α (0.1, 1, and 10). The target acceleration ratio (Ω) is varied from 0.5 to 0.9. It demonstrates the effect of this hyperparameter on the model’s performance and resource consumption.
read the caption
Table 5: The accuracy and computational cost against hyper-parameter α on MaWPS dataset.

🔼 This table presents a comparison of the overhead introduced by the decision modules in D-LLMs against the base LLM. It shows that the decision modules are parameter-efficient, adding only a small percentage to the total parameters and FLOPs of the LLM. The table also details the increases in training and inference memory usage, as well as the additional latency introduced per block.
read the caption
Table 6: Overhead information of decision modules in D-LLMs.
Full paper#