TL;DR#
Multi-modal domain generalization (MMDG) aims to build models that generalize well across unseen domains with the same modality set. Existing methods like sharpness-aware minimization (SAM) have limitations in MMDG due to modality competition (modalities compete for resources, hindering generalization) and discrepant uni-modal flatness (modalities have inconsistent flat minima, making it hard to find a good solution for all). This paper identifies these challenges as major roadblocks to effective MMDG.
To overcome these, the paper proposes Cross-Modal Representation Flattening (CMRF). CMRF optimizes the representation-space loss landscape instead of the parameter space, building connections directly between modalities. It uses a novel method to flatten high-loss regions between minima from different modalities by creating and optimizing interpolated representations, assigning different weights based on generalization capabilities. Extensive experiments on benchmark datasets showcase the effectiveness of CMRF under various settings, proving that it outperforms existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-modal domain generalization. It pinpoints key limitations of existing methods, proposing a novel solution (CMRF) that significantly enhances generalization performance. The open-sourced code and extensive experiments make it readily accessible and reproducible, paving the way for further advancements in this critical area.
Visual Insights#
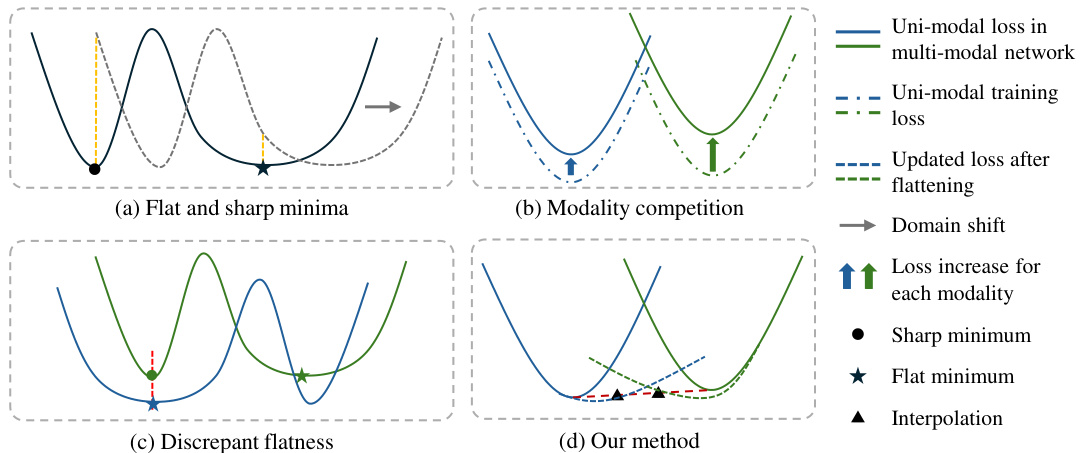
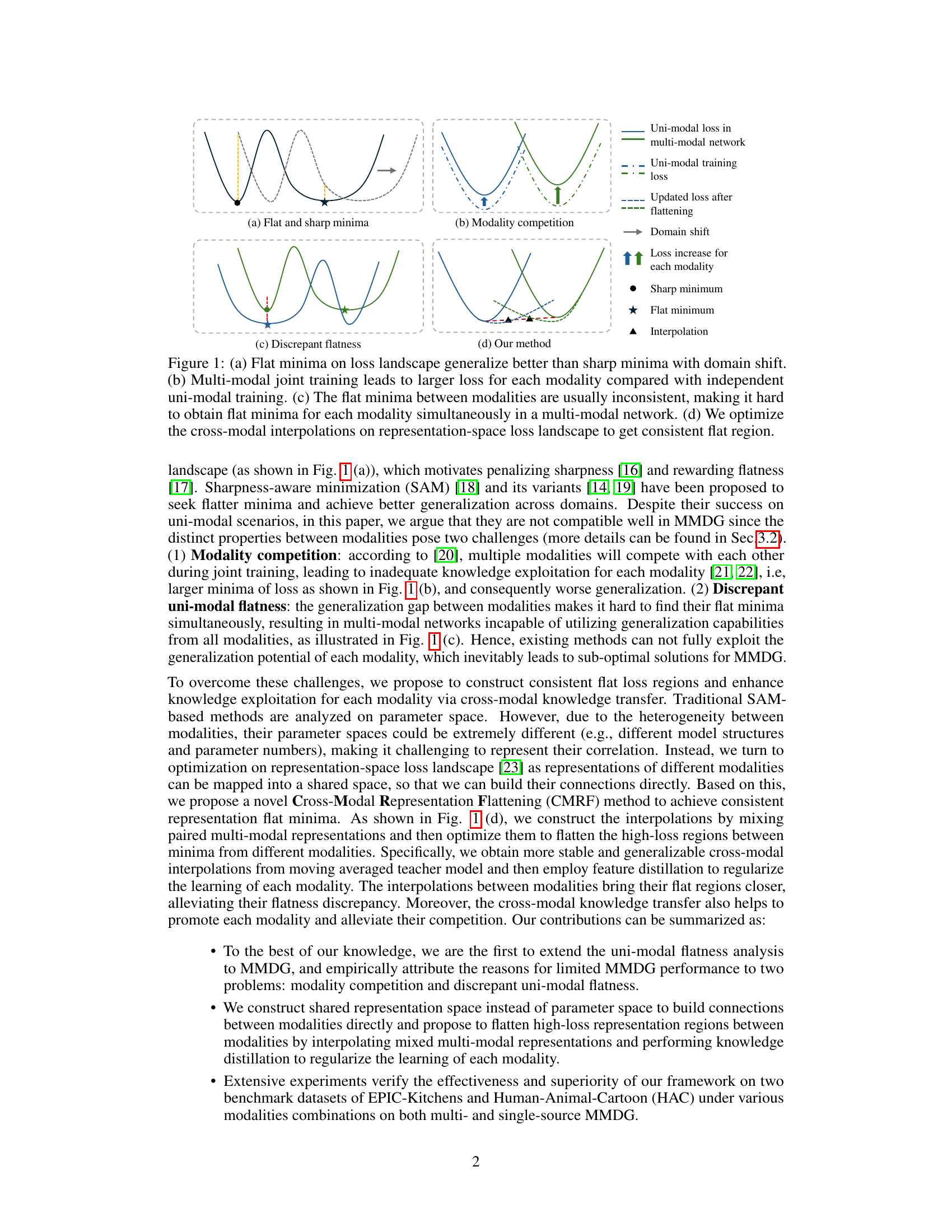
🔼 This figure illustrates the key concepts and challenges in multi-modal domain generalization (MMDG). (a) Shows the advantage of flat minima in generalization over sharp minima when domain shift occurs. (b) Highlights the problem of modality competition where joint training leads to increased loss for each modality compared to independent training. (c) Depicts the issue of discrepant flatness where inconsistent flat minima across modalities hinder effective generalization. (d) Presents the proposed solution, which optimizes cross-modal interpolations in representation space to create consistent flat loss regions and improve generalization.
read the caption
Figure 1: (a) Flat minima on loss landscape generalize better than sharp minima with domain shift. (b) Multi-modal joint training leads to larger loss for each modality compared with independent uni-modal training. (c) The flat minima between modalities are usually inconsistent, making it hard to obtain flat minima for each modality simultaneously in a multi-modal network. (d) We optimize the cross-modal interpolations on representation-space loss landscape to get consistent flat region.
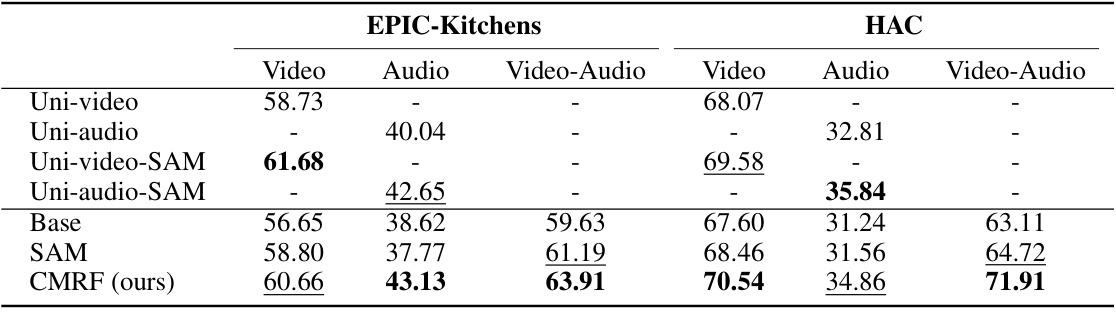
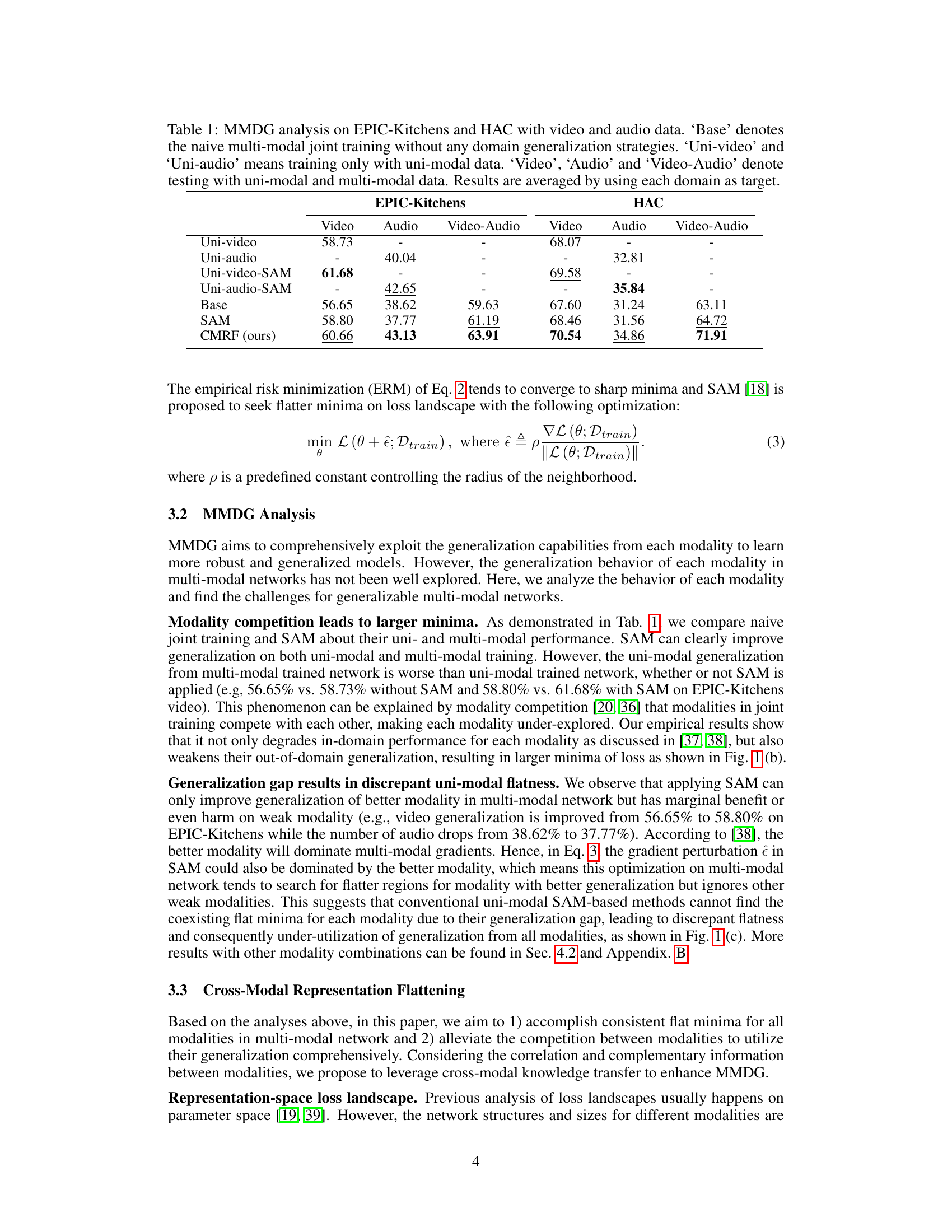
🔼 This table presents the results of a multi-modal domain generalization (MMDG) analysis conducted on two benchmark datasets: EPIC-Kitchens and HAC. The analysis compares different training methods on their ability to generalize to unseen target domains using video and audio modalities. The methods include naive multi-modal training (‘Base’), uni-modal training with and without Sharpness-Aware Minimization (SAM), and the proposed Cross-Modal Representation Flattening (CMRF) method. The table shows the performance (accuracy) for each method on uni-modal and multi-modal data, with results averaged across multiple target domains.
read the caption
Table 1: MMDG analysis on EPIC-Kitchens and HAC with video and audio data. ‘Base’ denotes the naive multi-modal joint training without any domain generalization strategies. ‘Uni-video’ and ‘Uni-audio’ means training only with uni-modal data. ‘Video’, ‘Audio’ and ‘Video-Audio’ denote testing with uni-modal and multi-modal data. Results are averaged by using each domain as target.
In-depth insights#
MMDG Challenges#
Multi-modal domain generalization (MMDG) presents unique challenges compared to its uni-modal counterpart. Modality competition, where different modalities interfere with each other during joint training, hindering the learning process for each modality, is a significant hurdle. This leads to suboptimal solutions and prevents the model from fully exploiting the generalization potential of each modality. Further complicating MMDG is discrepant uni-modal flatness, where the flatness of minima in the loss landscape varies across different modalities. This inconsistency makes it difficult to find a setting that simultaneously optimizes the generalization capabilities of all modalities. Cross-modal knowledge transfer becomes crucial in addressing these issues but existing methods often struggle to effectively connect and harmonize heterogeneous modalities, primarily due to differences in their parameter spaces and representation structures. Therefore, techniques that focus on aligning representation spaces and fostering consistent flat minima across modalities are needed to successfully overcome MMDG’s unique challenges.
CMRF Framework#
The Cross-Modal Representation Flattening (CMRF) framework tackles the challenges of multi-modal domain generalization by focusing on representation space rather than traditional parameter space. This allows for the direct comparison and manipulation of representations from different modalities, even with differing structures and dimensions. CMRF constructs consistent flat loss regions by interpolating mixed multi-modal representations, using a moving average teacher model to generate stable and generalizable interpolations. The framework further employs feature distillation to regularize the learning of each modality, aligning flat minima and promoting cross-modal knowledge transfer. Adaptive weights are assigned to modalities, considering their varying generalization capabilities, to achieve more balanced and robust generalization performance. This method directly addresses the issues of modality competition and discrepant uni-modal flatness, leading to superior results in multi-modal domain generalization tasks.
Multi-modal Flatness#
The concept of “Multi-modal Flatness” in the context of a research paper likely refers to the geometry of the loss landscape when training a multi-modal model. It builds upon the idea of “flat minima” in uni-modal domain generalization, suggesting that a model generalizes better if its optimal parameters reside within a broad, flat region of the loss surface, rather than a sharp, narrow minimum. In a multi-modal setting, flatness becomes more complex. The paper likely investigates whether each modality’s loss landscape exhibits flatness independently, and if there’s any interaction or interdependence between the flatness of different modalities. Inconsistencies in flatness across modalities might hinder generalization. The authors probably propose methods to encourage consistent, multi-modal flatness, perhaps by aligning the loss landscapes of different modalities or by promoting a shared flat region. This could involve novel optimization techniques, loss functions, or architectural modifications to improve the robustness and adaptability of multi-modal models to unseen data.
Cross-modal Transfer#
Cross-modal transfer, in the context of multi-modal learning, focuses on leveraging information from one modality to improve the understanding and performance of another. Effective cross-modal transfer is crucial for handling scenarios with missing or incomplete modalities, improving robustness, and reducing reliance on any single data source. Successful strategies often involve aligning representations across modalities, learning shared latent spaces, or utilizing knowledge distillation techniques. Challenges include addressing modality discrepancies in terms of data type, dimensionality, and semantic content. Careful consideration of alignment methods is necessary, as poorly chosen approaches may lead to negative transfer or suboptimal performance. A key aspect is evaluating the generalizability of the learned cross-modal relationships to unseen data. The most promising approaches often incorporate a combination of feature extraction, representation learning, and transfer learning techniques, dynamically weighting modalities based on their individual strengths and addressing issues such as bias and noise. Ultimately, successful cross-modal transfer significantly enhances the overall capabilities of multi-modal systems.
Future of MMDG#
The future of multi-modal domain generalization (MMDG) is bright, but challenging. Addressing the limitations of current methods—such as modality competition, discrepant flatness, and limited knowledge transfer—will be crucial. Future research should explore more sophisticated techniques for aligning and integrating information from multiple modalities, perhaps using advanced representation learning or generative models. Incorporating uncertainty quantification into MMDG models is another promising area, enabling the models to handle noisy or incomplete data more effectively. Furthermore, developing efficient algorithms and scalable architectures will be necessary for wider adoption of MMDG in real-world applications. Investigating new evaluation metrics that capture the nuances of multi-modal generalization will also be necessary. Ultimately, the success of MMDG will rely on collaboration between different research communities to create robust datasets, develop powerful models and establish standardized benchmarks.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the proposed Cross-Modal Representation Flattening (CMRF) method. It shows two networks: a student network and a teacher network. The student network consists of modality-specific feature extractors, projectors mapping features into a shared representation space, modality-specific classifiers, and a fusion and classification layer. The teacher network is a moving average of the student network and generates mixed representations by interpolating representations from different modalities. These mixed representations are then used to distill knowledge into the student network, helping to flatten the loss landscape and improve generalization. The figure also highlights the use of contrastive loss to reduce the gap between modalities.
read the caption
Figure 2: The overall framework of our method. The projectors map features with different dimensions to the same representation space. The teacher model is moving averaged from online model and generates cross-modal mixed representations as interpolations to distill the student representations. Uni-modal classifier is used to lower the loss of distilled features for each modality and a contrastive loss aims to alleviate gap between modalities. Only the online student model back propagates gradients. The teacher model is used for evaluation finally.

🔼 This figure shows the performance of the proposed CMRF method and the baseline method on the HAC dataset with video and audio modalities, under the A, C → H setting. The x-axis represents different values for the hyperparameters λ1, λ2, and λ3 which control the weight of the distillation loss, uni-modal classification loss, and contrastive loss, respectively. The y-axis represents the accuracy. The figure demonstrates the impact of each hyperparameter on the model’s performance and highlights the robustness of CMRF across a range of hyperparameter values.
read the caption
Figure 3: Parameter sensitivity analysis on HAC with video and audio data under A, C → H.
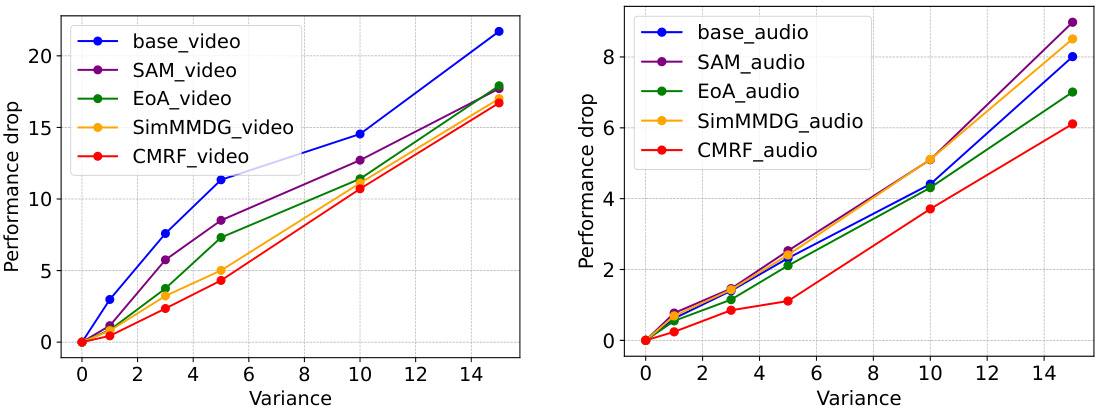
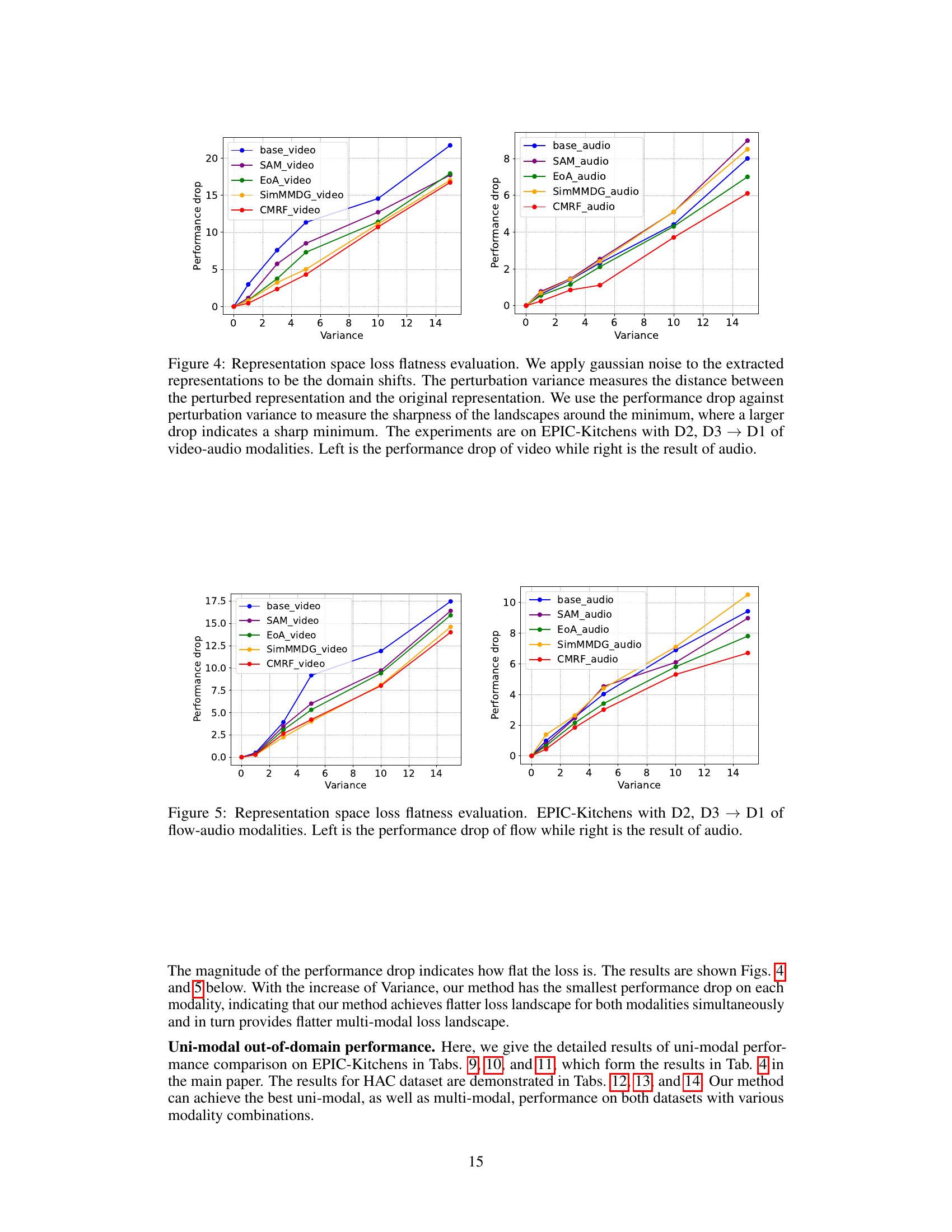
🔼 This figure shows the representation space loss flatness evaluation. Gaussian noise is applied to the extracted representations to simulate domain shifts. The performance drop against perturbation variance is used to measure the sharpness of loss landscapes. Larger drops indicate sharper minima. The experiments involve EPIC-Kitchens dataset, specifically using domains D2 and D3 to test on domain D1 with video and audio modalities. The left subplot shows results for video, and the right subplot for audio.
read the caption
Figure 4: Representation space loss flatness evaluation. We apply gaussian noise to the extracted representations to be the domain shifts. The perturbation variance measures the distance between the perturbed representation and the original representation. We use the performance drop against perturbation variance to measure the sharpness of the landscapes around the minimum, where a larger drop indicates a sharp minimum. The experiments are on EPIC-Kitchens with D2, D3 → D1 of video-audio modalities. Left is the performance drop of video while right is the result of audio.
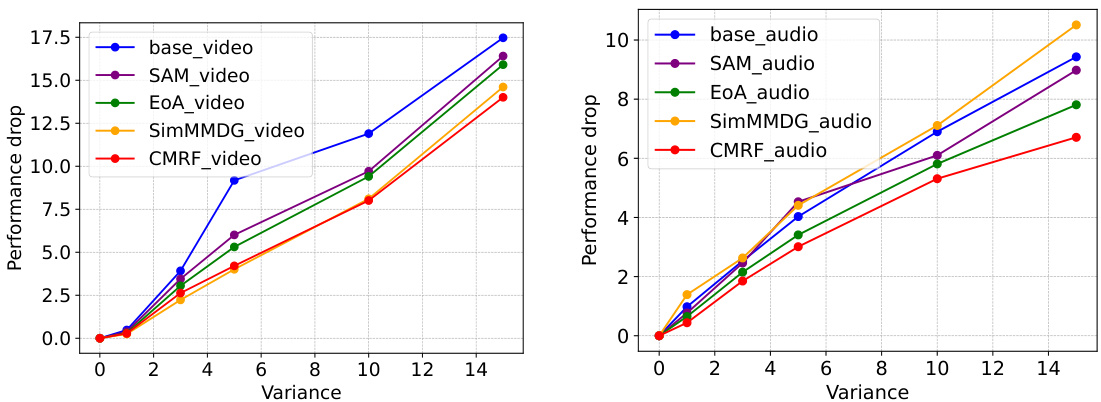
🔼 This figure shows the results of representation space loss flatness evaluation. Gaussian noise with varying variance was applied to the extracted representations to simulate domain shifts. The performance drop relative to the variance is plotted for both video and audio modalities, separately, on EPIC-Kitchens dataset using the D2, D3 → D1 setup (where the model is trained on domains D2 and D3, and tested on domain D1). A larger performance drop with increasing variance indicates a sharper minimum, revealing that the proposed CMRF method achieves flatter minima compared to the baselines.
read the caption
Figure 4: Representation space loss flatness evaluation. We apply gaussian noise to the extracted representations to be the domain shifts. The perturbation variance measures the distance between the perturbed representation and the original representation. We use the performance drop against perturbation variance to measure the sharpness of the landscapes around the minimum, where a larger drop indicates a sharp minimum. The experiments are on EPIC-Kitchens with D2, D3 → D1 of video-audio modalities. Left is the performance drop of video while right is the result of audio.
More on tables
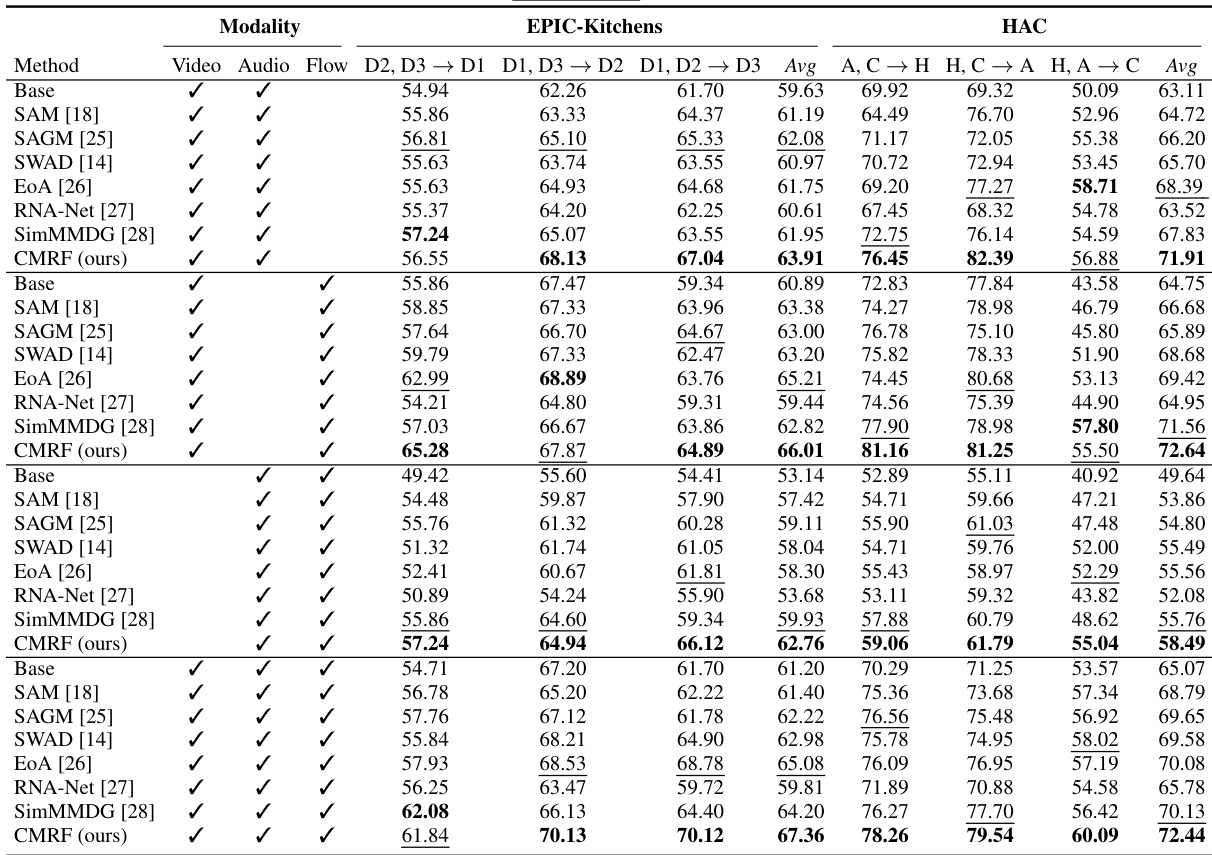
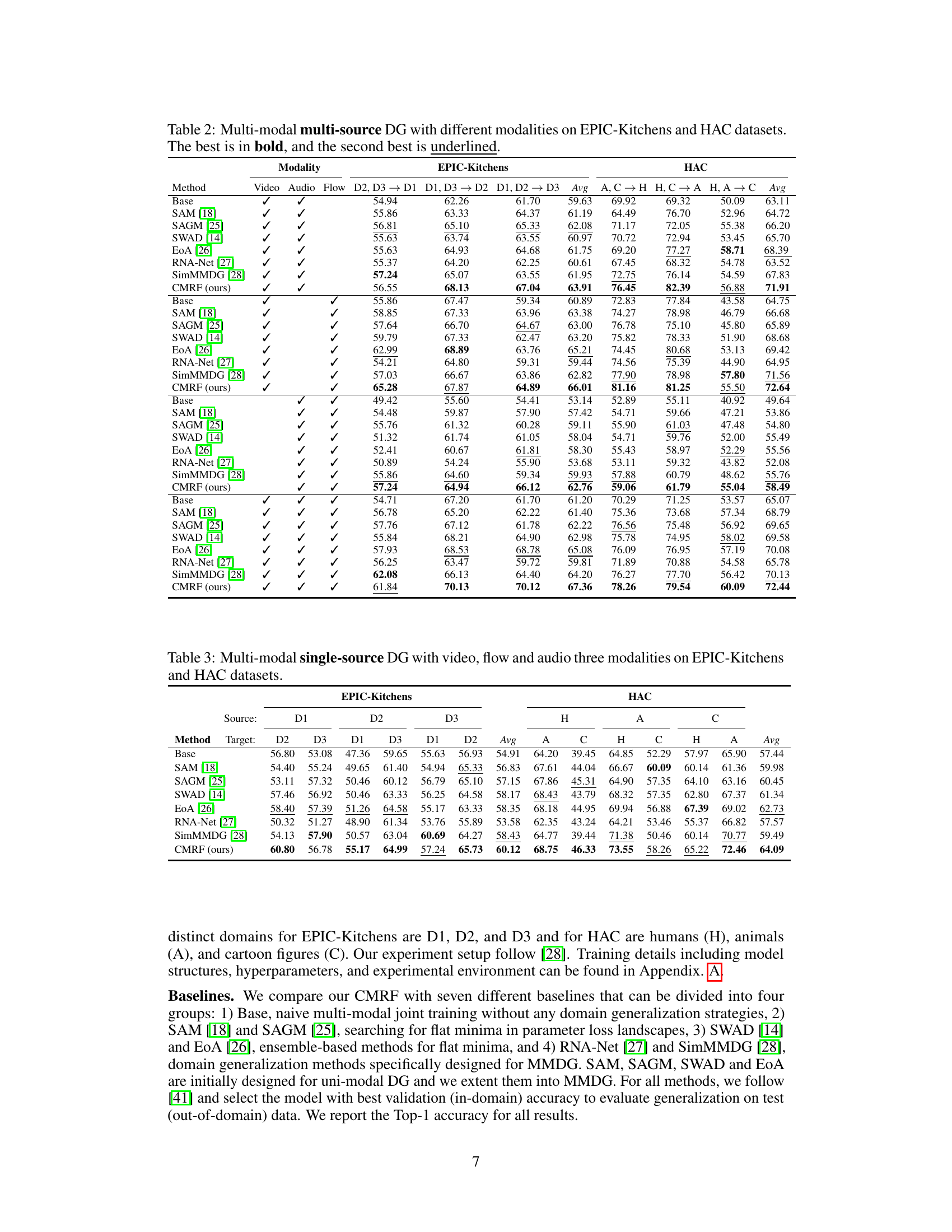
🔼 This table presents the results of a multi-modal multi-source domain generalization experiment conducted on two datasets: EPIC-Kitchens and HAC. The experiment compares the performance of several methods, including the proposed Cross-Modal Representation Flattening (CMRF) method, across various combinations of modalities (video, audio, flow) and source domains. The best performing method for each combination is highlighted in bold, while the second-best is underlined. The table provides a quantitative comparison of the effectiveness of different methods in handling multi-modal domain generalization.
read the caption
Table 2: Multi-modal multi-source DG with different modalities on EPIC-Kitchens and HAC datasets. The best is in bold, and the second best is underlined.
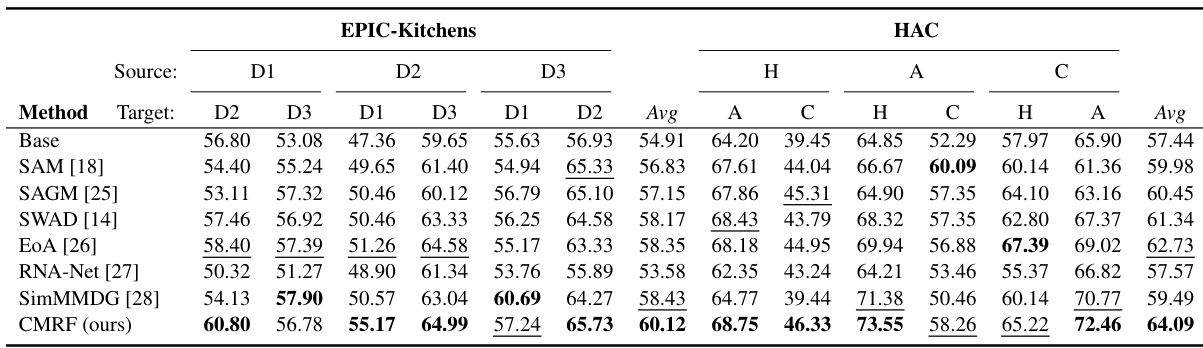
🔼 This table presents the results of a multi-modal multi-source domain generalization experiment conducted on two benchmark datasets, EPIC-Kitchens and HAC. Multiple methods (Base, SAM, SAGM, SWAD, EoA, RNA-Net, SimMMDG, and the proposed CMRF) are compared using various combinations of modalities (Video, Audio, Flow). The table shows the average accuracy across multiple source domains, highlighting the superior performance of the proposed CMRF method.
read the caption
Table 2: Multi-modal multi-source DG with different modalities on EPIC-Kitchens and HAC datasets. The best is in bold, and the second best is underlined.

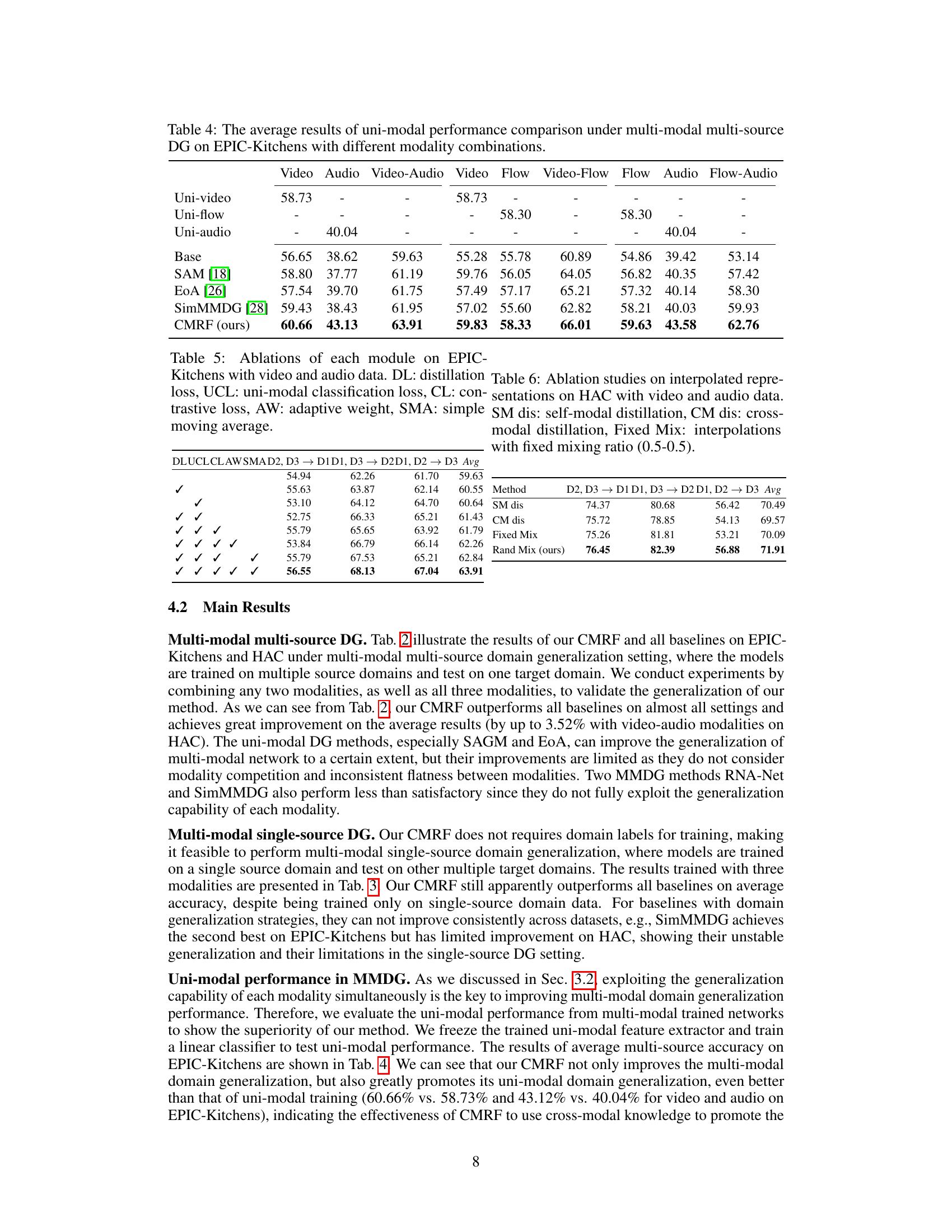
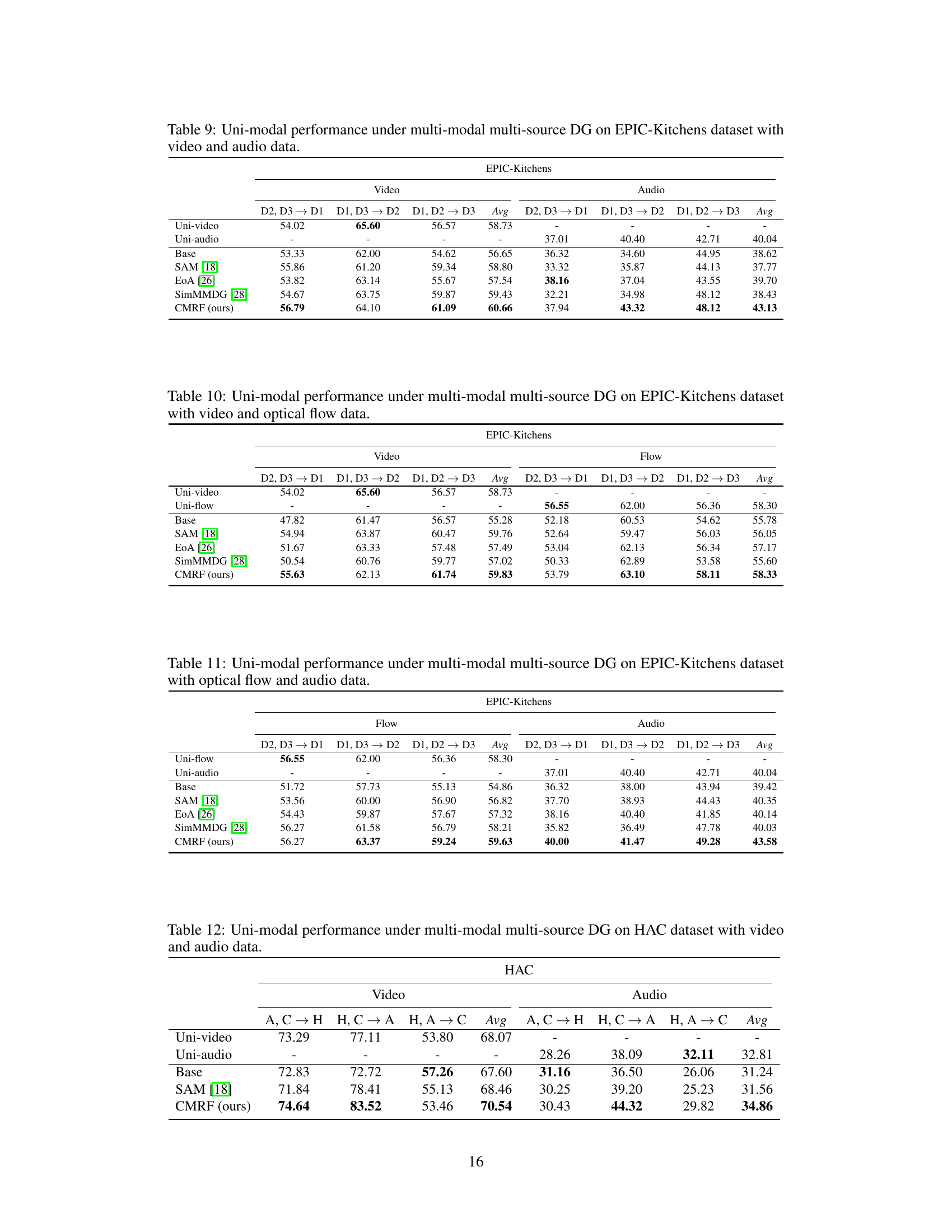
🔼 This table presents a comparison of uni-modal performance results under multi-modal, multi-source domain generalization settings on the EPIC-Kitchens dataset. Different modality combinations (video, audio, flow, and their combinations) are evaluated using various methods (Base, SAM, EoA, SimMMDG, and the proposed CMRF). Uni-modal performance is assessed for each modality (video, audio, flow) individually to understand the impact of multi-modal training on each modality’s generalization capacity. The results illustrate how the proposed CMRF improves uni-modal performance in comparison to other baseline methods.
read the caption
Table 4: The average results of uni-modal performance comparison under multi-modal multi-source DG on EPIC-Kitchens with different modality combinations.

🔼 This table presents the results of a multi-modal multi-source domain generalization experiment conducted on two benchmark datasets: EPIC-Kitchens and HAC. The experiment evaluated the performance of various methods in different modality combinations (video, audio, flow) across multiple source and target domains. The table shows the average accuracy achieved by different methods, including baselines and the proposed method (CMRF), with the best performance highlighted in bold and the second best underlined. This allows for a comparison of different approaches in handling multi-modal data and their generalization capabilities across different domains.
read the caption
Table 2: Multi-modal multi-source DG with different modalities on EPIC-Kitchens and HAC datasets. The best is in bold, and the second best is underlined.
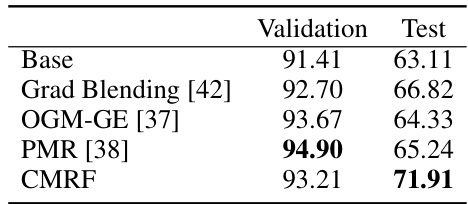
🔼 This table compares the performance of the proposed CMRF method against several baselines designed to address modality competition in multi-modal domain generalization. The comparison is conducted using the HAC dataset with video and audio modalities in a multi-source domain generalization setting. The results show the validation and test accuracy for each method. The CMRF method outperforms the baselines on the test accuracy, demonstrating its effectiveness in mitigating modality competition and improving generalization.
read the caption
Table 7: The average results compared with methods designed for modality competition on HAC with video and audio data under multi-source DG.

🔼 This table presents the uni-modal performance results for video and audio modalities under multi-modal, multi-source domain generalization settings on the EPIC-Kitchens dataset. It compares the average accuracy across different source domains (D1, D2, D3) for each modality under different methods: Uni-modal (training only on that modality), Base (naive multi-modal training), SAM, EoA, SimMMDG, and the proposed CMRF method. This allows for assessing the impact of multi-modal training and the effectiveness of the CMRF approach on individual modality generalization.
read the caption
Table 9: Uni-modal performance under multi-modal multi-source DG on EPIC-Kitchens dataset with video and audio data.
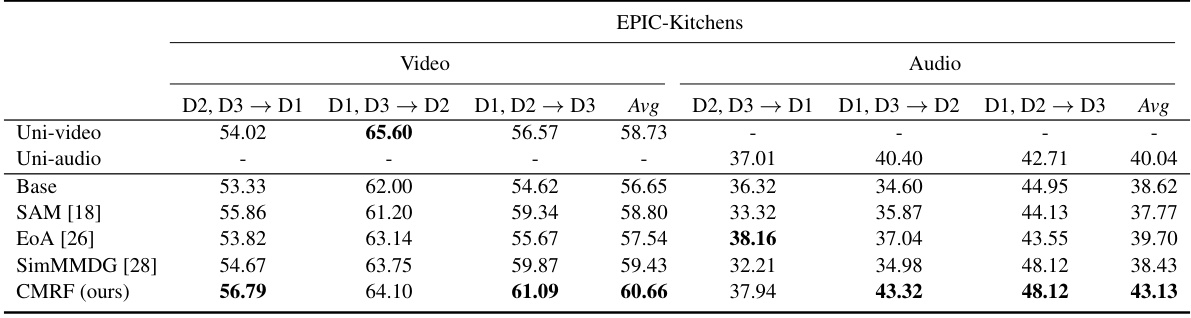
🔼 This table presents the uni-modal performance results of different methods on the EPIC-Kitchens dataset, focusing on video and audio modalities. It shows the average performance across various domain combinations (D2, D3 → D1, D1, D3 → D2, D1, D2 → D3) for each method, including the baseline (Base), SAM, EoA, SimMMDG, and the proposed CMRF method. The results highlight the improvement in uni-modal performance achieved by the proposed CMRF, showcasing its efficacy in handling the complexities of multi-modal multi-source domain generalization.
read the caption
Table 9: Uni-modal performance under multi-modal multi-source DG on EPIC-Kitchens dataset with video and audio data.
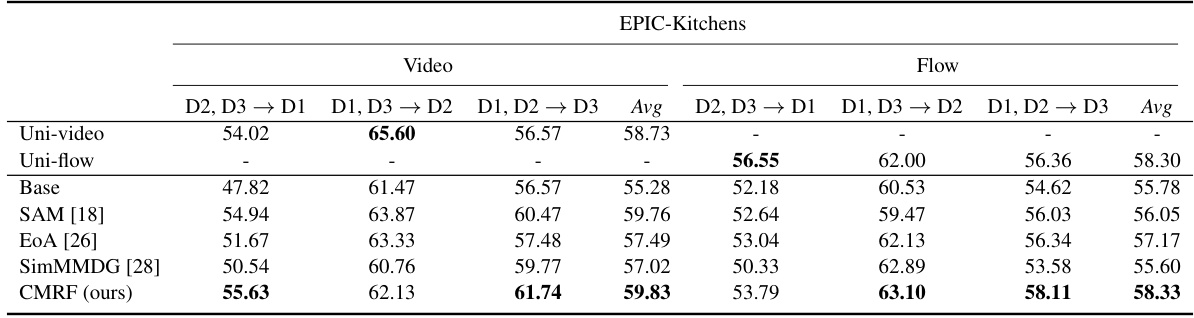
🔼 This table presents the results of a multi-modal single-source domain generalization experiment. The models were trained on a single source domain and tested on multiple target domains using three modalities (video, flow, and audio). The table compares the performance of the proposed CMRF method against several baseline methods across different source and target domain combinations for both the EPIC-Kitchens and HAC datasets. The ‘Avg’ column represents the average performance across all target domains.
read the caption
Table 3: Multi-modal single-source DG with video, flow and audio three modalities on EPIC-Kitchens and HAC datasets.

🔼 This table presents the results of a multi-modal single-source domain generalization experiment. The models were trained on a single source domain and tested on multiple target domains. Three modalities (video, flow, and audio) were used. The table compares the performance of the proposed CMRF method against several baseline methods across various source and target domain combinations on two benchmark datasets (EPIC-Kitchens and HAC). The results are presented as Top-1 accuracy.
read the caption
Table 3: Multi-modal single-source DG with video, flow and audio three modalities on EPIC-Kitchens and HAC datasets.

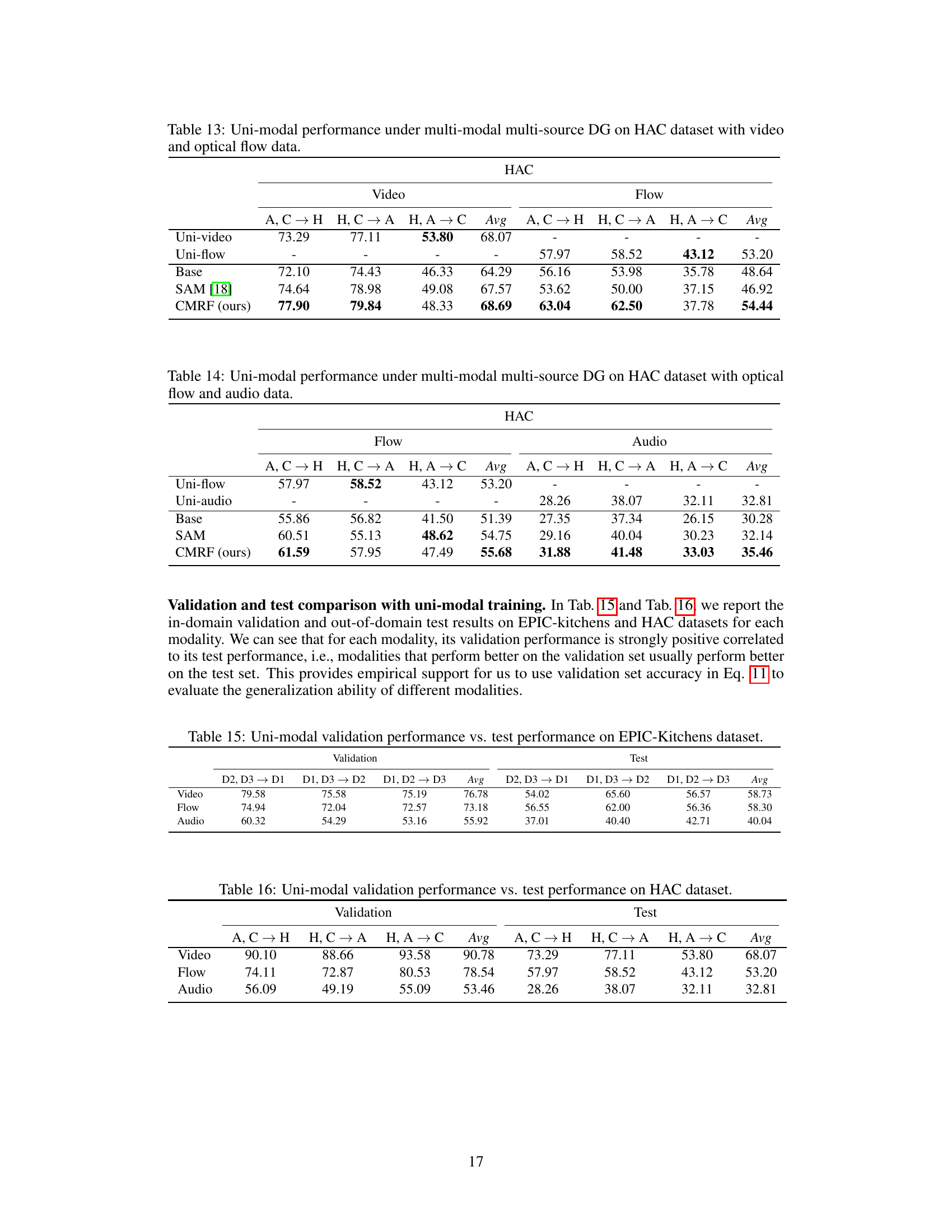
🔼 This table presents the results of a multi-modal, multi-source domain generalization experiment on the Human-Animal-Cartoon (HAC) dataset using video and audio modalities. It shows the performance of various methods (Base, SAM, and the proposed CMRF) when testing each modality (video and audio) individually, on each of three target domains (A, C, and H). The results highlight the improvement achieved by the proposed CMRF method compared to baseline and other uni-modal methods.
read the caption
Table 12: Uni-modal performance under multi-modal multi-source DG on HAC dataset with video and audio data.
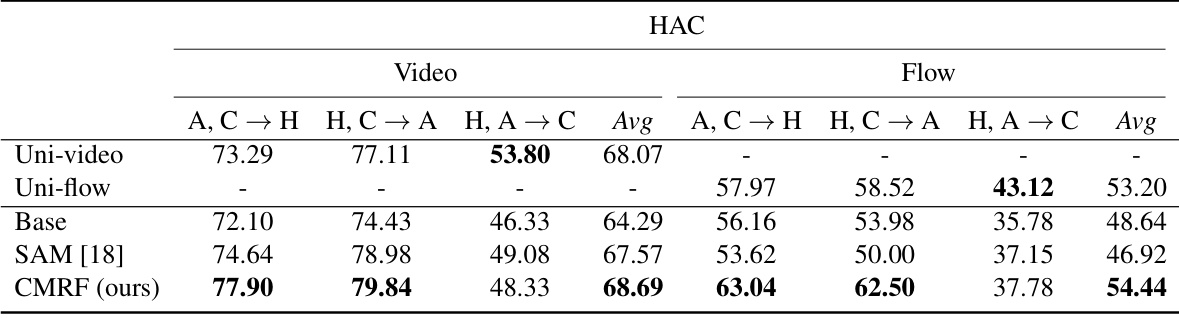
🔼 This table presents the uni-modal performance results on the HAC dataset when using a multi-modal multi-source domain generalization (MMDG) approach. It shows the average accuracy for each modality (video and audio) across various source domain combinations. The goal is to evaluate how well each modality generalizes when trained with multiple modalities.
read the caption
Table 12: Uni-modal performance under multi-modal multi-source DG on HAC dataset with video and audio data.
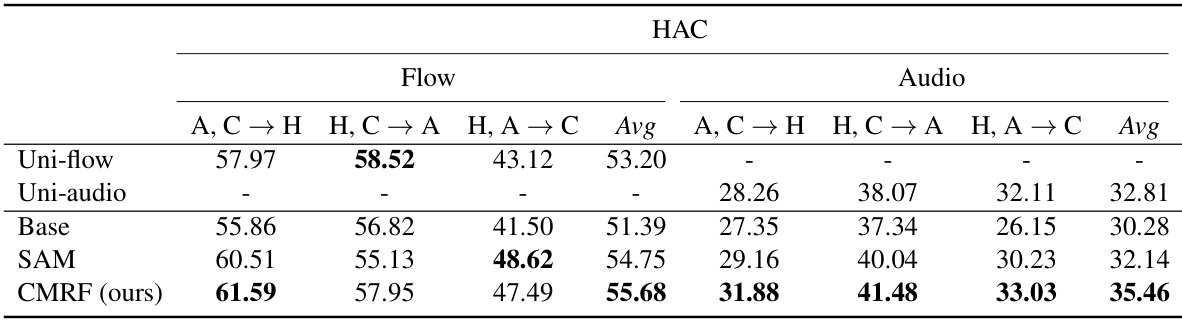
🔼 This table presents the results of uni-modal performance evaluation under multi-modal multi-source domain generalization (MMDG) settings on the Human-Animal-Cartoon (HAC) dataset using video and audio modalities. It shows the average accuracy for each modality (video and audio) across different source domain combinations, comparing the performance of the proposed CMRF method to baseline methods such as Base, SAM, and SimMMDG. Each entry represents the average accuracy across various test domains.
read the caption
Table 12: Uni-modal performance under multi-modal multi-source DG on HAC dataset with video and audio data.

🔼 This table presents the uni-modal performance results obtained from a multi-modal multi-source domain generalization experiment on the EPIC-Kitchens dataset. Specifically, it shows the performance of each modality (video and audio) when trained and tested under different domain combinations, indicating how well each modality generalizes when trained within a multi-modal context. The results are separated into in-domain (validation) and out-of-domain (test) performances. This allows for a detailed comparison of the individual generalization capabilities of video and audio modalities within a multi-modal model.
read the caption
Table 9: Uni-modal performance under multi-modal multi-source DG on EPIC-Kitchens dataset with video and audio data.

🔼 This table presents the uni-modal performance results on the HAC dataset for video and audio modalities under multi-modal multi-source domain generalization settings. The results are broken down by source domains (A, C → H, H, C → A, H, A → C), showing the performance of each modality (video, audio) when trained in a multi-modal setting.
read the caption
Table 12: Uni-modal performance under multi-modal multi-source DG on HAC dataset with video and audio data.
Full paper#