↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multi-modal large language models (MLLMs) process visual information and language understanding sequentially. This sequential method is inefficient and doesn’t fully leverage the potential of parallel visual recognition processing, which is much faster and more effective. The sequential approach also fails to fully replicate the brain’s natural parallel-then-sequential information processing.
The paper introduces “Octopus,” a new MLLM that addresses these limitations. Octopus uses a parallel processing method (object queries in bottom LLM layers) for visual recognition and a sequential process for high-level understanding (in top layers). This new method is empirically shown to improve accuracy on standard MLLM tasks and significantly increase speed (up to 5x faster on visual grounding tasks). The results support the claim that a parallel-sequential framework is a more suitable architecture for MLLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-modal large language models (MLLMs) because it challenges the prevailing sequential processing paradigm, proposing a more efficient and accurate parallel-sequential framework. The findings offer significant improvements in speed and accuracy, along with a novel architecture that could inspire further research into brain-inspired cognitive hierarchies within LLMs. This work is relevant to the current trends focusing on improving MLLM efficiency and bridging the gap between visual recognition and high-level language understanding.
Visual Insights#

This figure compares the sequential processing in previous Multimodal Large Language Models (MLLMs) with the proposed Octopus model. Prior MLLMs process visual recognition and understanding sequentially within the LLM head, generating responses token-by-token. This is slow, especially for tasks needing precise object location. Octopus, conversely, uses parallel recognition in lower LLM layers (via object queries, a DETR mechanism) before sequentially processing in the upper layers. The upper layers select previously detected objects, making the overall process much faster. The entire Octopus LLM head is trained end-to-end.
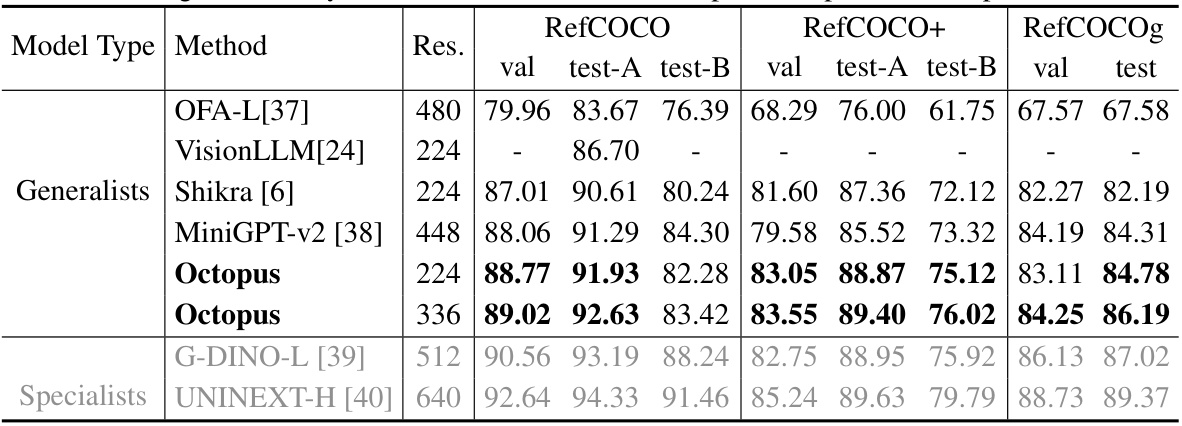
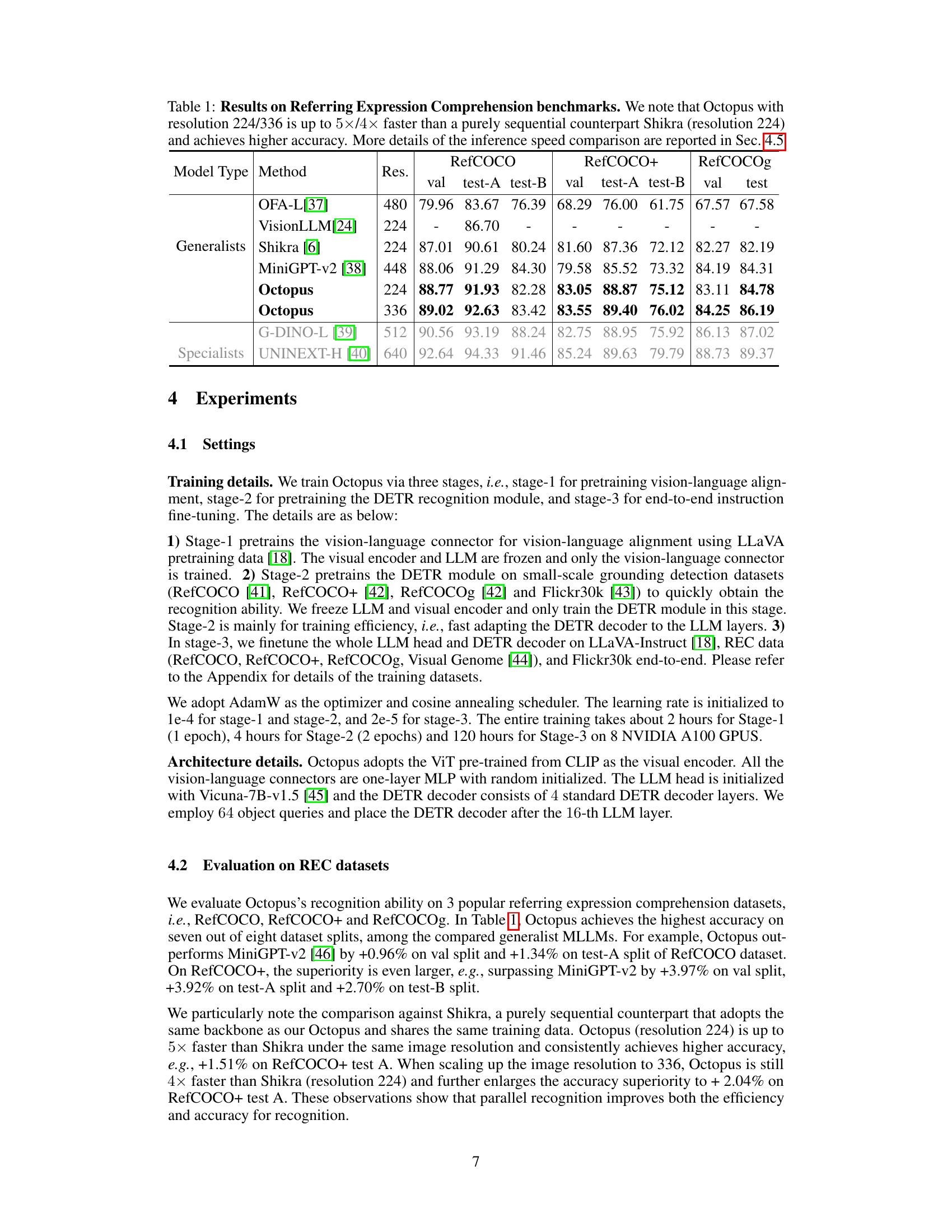
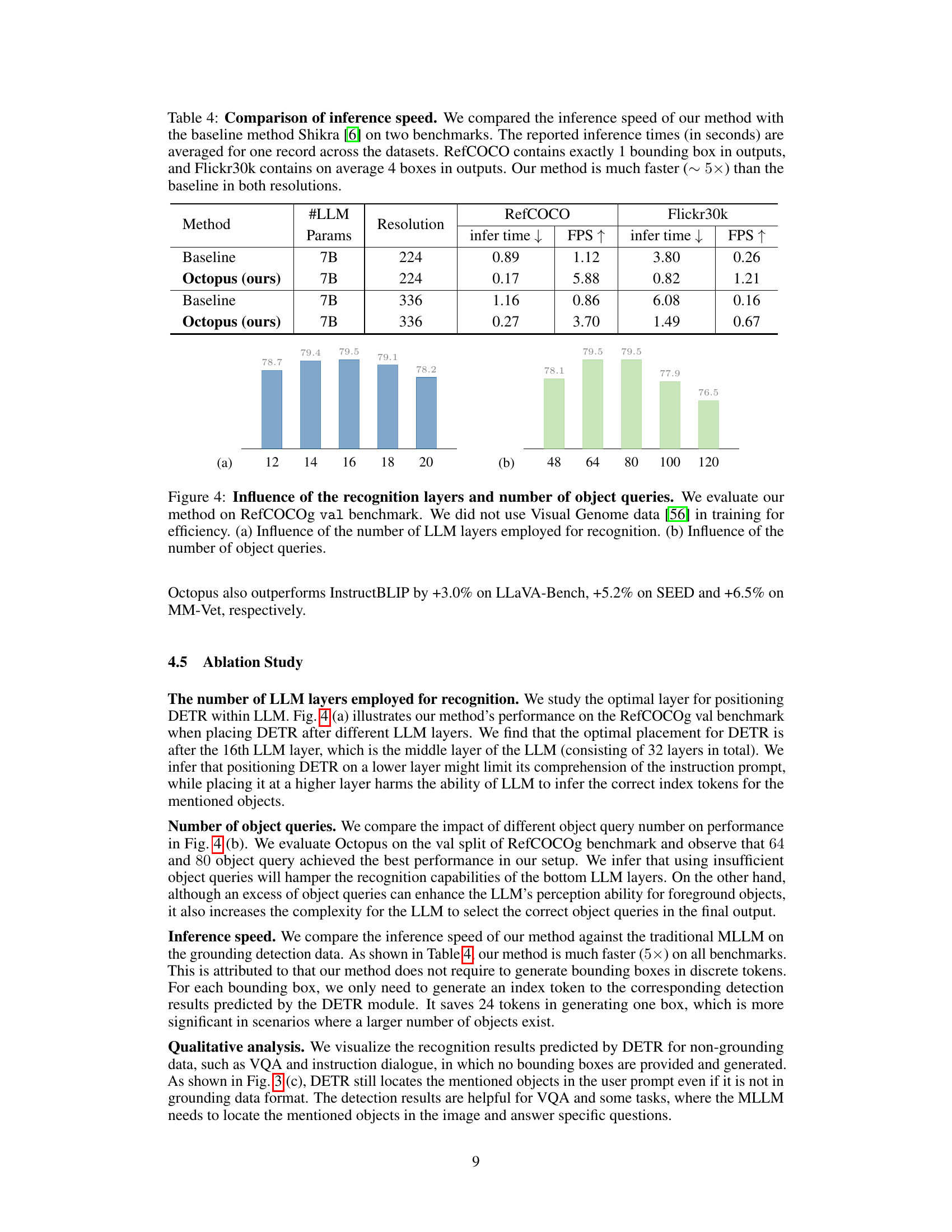
This table presents the results of the Octopus model and several other models on the Referring Expression Comprehension (REC) benchmark. The benchmark measures the ability of a model to identify an object in an image based on a textual description. The table shows that Octopus achieves higher accuracy and is significantly faster than Shikra, a comparable purely sequential model. The speed improvement is particularly noticeable at higher resolutions.
In-depth insights#
Parallel Cognition#
The concept of ‘Parallel Cognition’ suggests the brain’s capacity for simultaneous processing of information, unlike traditional sequential models. This contrasts with the sequential nature of language processing found in many Large Language Models (LLMs). Octopus, as described in the paper, attempts to bridge this gap by incorporating a parallel processing stage for visual recognition using object queries in a DETR framework, before feeding these results to a sequential language understanding component. This parallel recognition followed by sequential understanding approach mimics human visual processing more closely. The core argument is that parallel processing improves visual recognition efficiency and quality, with the resulting information informing higher-level cognitive tasks more effectively. The success of Octopus, as demonstrated by experimental results, validates the potential benefits of integrating parallel processing into LLMs, particularly for multi-modal tasks that involve visual input, and offers a significant advancement in MLLM architecture.
DETR Integration#
The integration of DETR (DEtection TRansformer) within the Octopus multi-modal LLM framework is a key innovation, enabling parallel object recognition. Instead of the sequential, token-by-token approach common in prior MLLMs, Octopus leverages DETR’s object queries to process visual information in parallel. This parallelization significantly boosts efficiency, demonstrated by a 5x speed improvement on visual grounding tasks. The integration harmonizes well with the LLM’s architecture, feeding detection results into higher-level layers for sequential understanding. This design reflects a hierarchical processing model, mimicking human cognition where lower-level recognition informs higher-level interpretation. While DETR’s versatility supports various recognition modalities, the specific implementation within Octopus showcases its potential for enhancing visual understanding in MLLMs.
MLLM Efficiency#
Multi-modal Large Language Models (MLLMs) present a unique challenge in balancing the complexity of multimodal understanding with computational efficiency. Sequential processing, where visual recognition and language understanding occur step-by-step, is a common approach but suffers from significant speed limitations, particularly in tasks like visual grounding. The paper introduces a novel architecture that leverages parallel processing in the early stages of visual recognition to drastically improve efficiency. By separating these processes and optimizing for parallelism, the authors demonstrate a significant reduction in inference time. This enhanced efficiency is a key contribution, offering practical advantages for real-world applications where speed is critical, without compromising accuracy on various benchmark tasks. The proposed framework highlights the potential of architectural innovations in addressing the computational bottleneck of MLLMs, paving the way for more efficient and scalable multimodal AI systems.
Octopus Framework#
The Octopus framework presents a novel approach to multi-modal large language models (MLLMs) by decoupling visual recognition and understanding into parallel and sequential processes, respectively. This parallel-sequential design directly addresses the inherent inefficiency of traditional sequential MLLM architectures, which process both recognition and understanding tasks token-by-token. Octopus leverages object queries within the lower LLM layers to perform parallel visual recognition via a DETR-like decoder. This allows for simultaneous object detection, significantly speeding up the process, especially in visual grounding tasks. The recognition results are then efficiently relayed to the upper LLM layers for sequential understanding, allowing the higher-level cognitive processes to benefit from pre-computed visual information. The framework demonstrates a significant speed improvement (up to 5x faster) on tasks involving visual grounding, while also showing promising accuracy gains on various MLLM benchmark tasks. The design is inspired by the human cognitive hierarchy, suggesting a biologically plausible approach to MLLM architecture, with inherent advantages in efficiency and accuracy.
Future of MLLMs#
The future of Multimodal Large Language Models (MLLMs) is bright, but also complex. Improved efficiency will be key, as current sequential processing of visual and language information creates a bottleneck. Models like the Octopus, which employ parallel recognition strategies, represent a significant advancement towards addressing this. Seamless integration of visual and linguistic information remains a significant challenge. Future progress likely depends on more sophisticated approaches that go beyond simply concatenating visual and textual data, perhaps using more biologically inspired hierarchical processing. Enhanced adaptability to varied tasks and user instructions is crucial. The ability of models like Octopus to dynamically switch between recognition modes demonstrates the potential of this, but further work will be needed to generalize this capability. Finally, addressing concerns around bias, fairness, and ethical implications associated with the development and deployment of ever more powerful MLLMs will be paramount.
More visual insights#
More on figures

This figure illustrates the training process of the Octopus model. It shows how multiple object queries are processed in parallel by the lower LLM layers and a DETR decoder, resulting in object recognition (which can adapt to different tasks like grounding or segmentation based on user input). These results are then fed into the upper LLM layers for sequential understanding. A key feature is the use of index tokens, such as
, to link the detected objects to the final LLM output.

This figure compares the sequential inference method used by prior Multi-modal Large Language Models (MLLMs) with the parallel recognition and sequential understanding approach of the Octopus model. The left side shows the sequential approach where the LLM head generates the response token-by-token, including object positions. The right side depicts Octopus’s method. Octopus uses bottom LLM layers for parallel object recognition using object queries. The recognition results are then sent to the top LLM layers for sequential understanding, eliminating the need to infer object positions again in the top layers. This parallel processing is more efficient, particularly in visual grounding tasks.

This figure compares the sequential approach of prior Multimodal Large Language Models (MLLMs) with the proposed Octopus model. Prior MLLMs process visual recognition and understanding sequentially, token-by-token. Octopus, in contrast, uses parallel recognition (in lower LLM layers) to identify objects and then relays the results to the upper LLM layers for sequential understanding. This parallel approach is faster and more efficient.

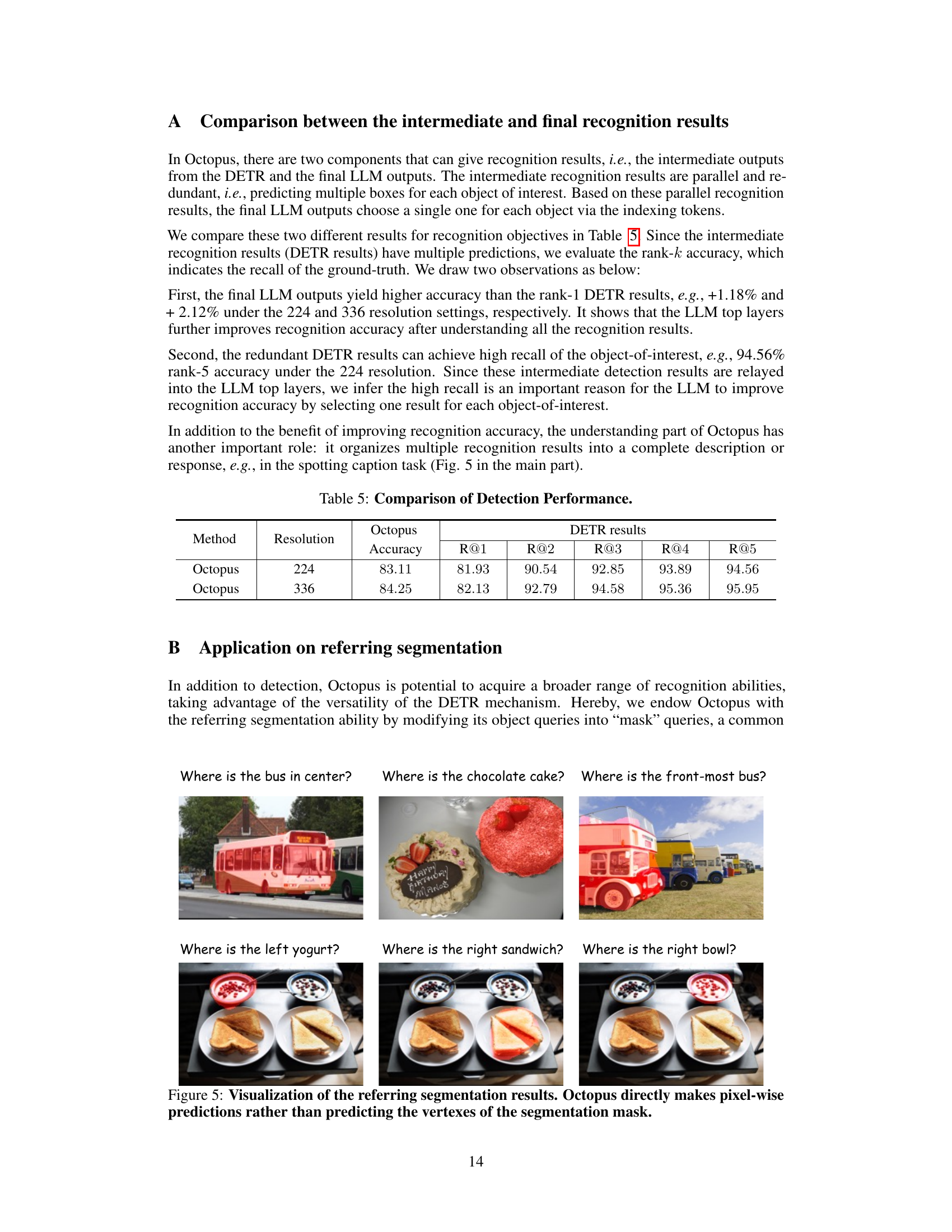
This figure demonstrates Octopus’s referring segmentation capabilities. Instead of predicting bounding boxes, Octopus directly predicts pixel-wise segmentation masks, providing a more nuanced and detailed result. The images show example queries and the resulting segmentations.
More on tables
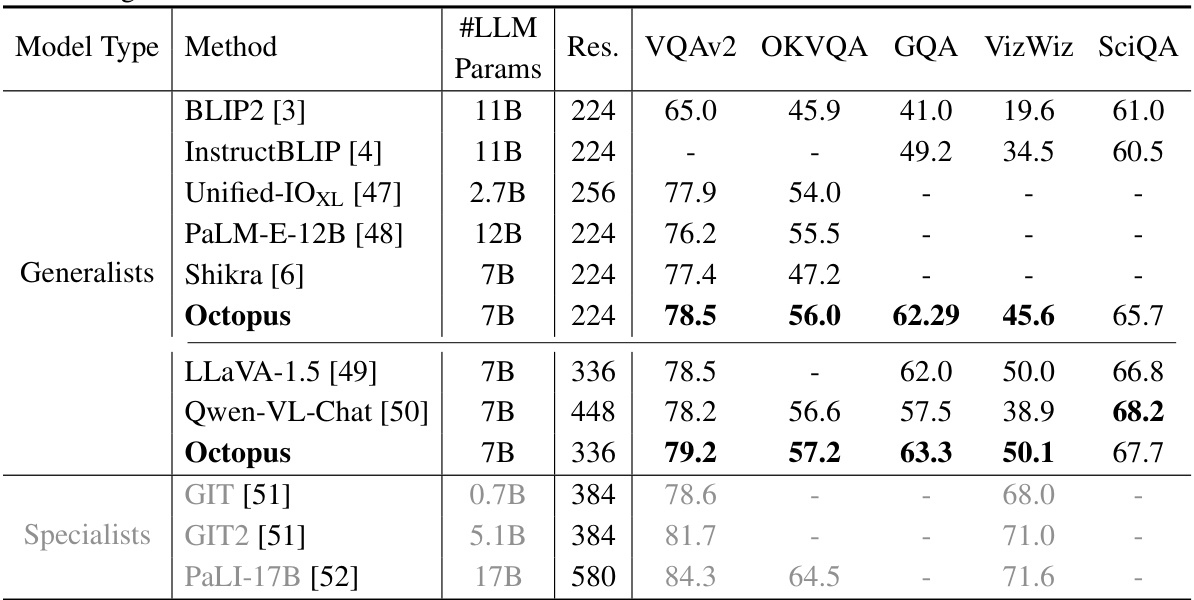
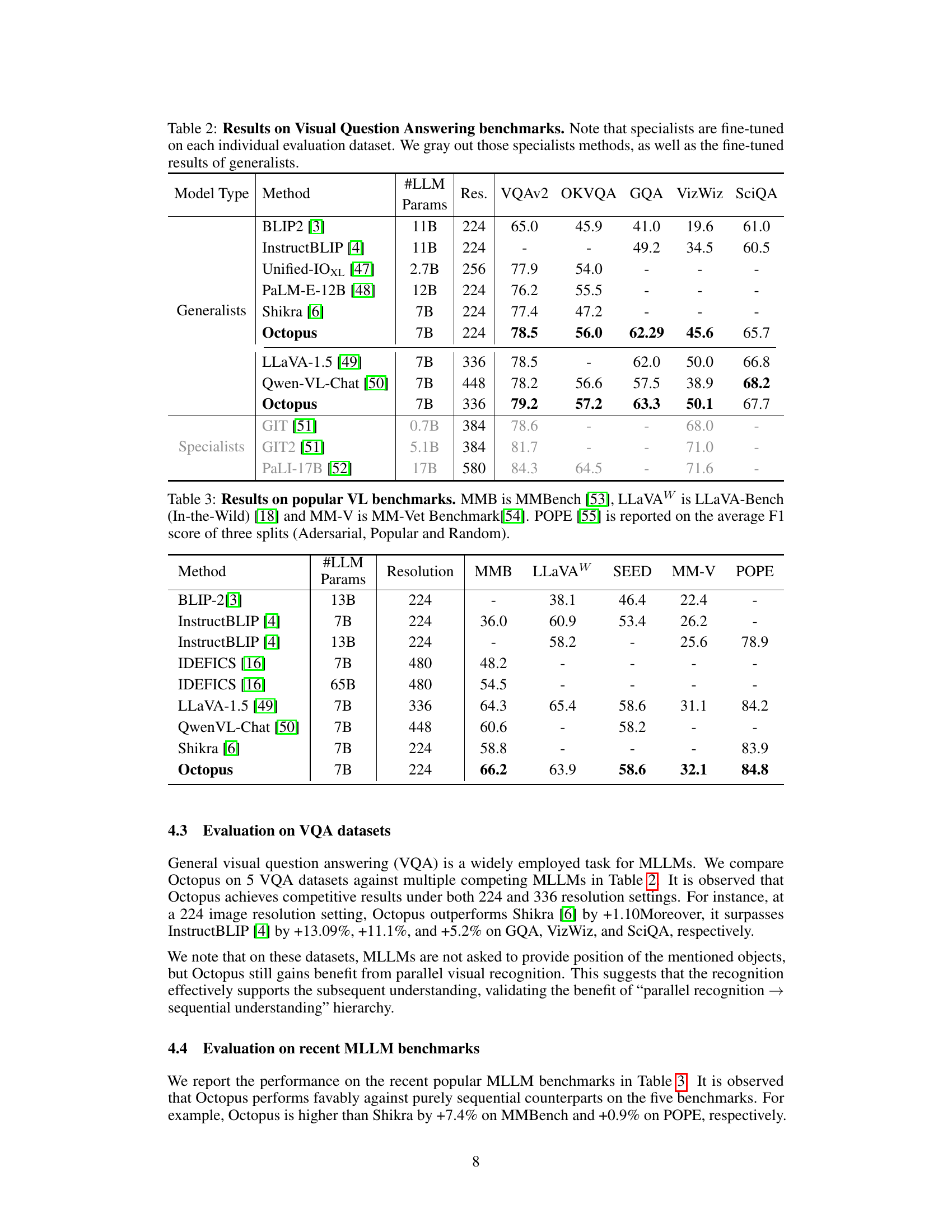
This table presents the results of several multi-modal large language models (MLLMs) on five visual question answering (VQA) benchmark datasets. It compares the performance of generalist models (trained on multiple datasets) and specialist models (fine-tuned on individual datasets). The table shows the number of parameters (#LLM Params) in each model, image resolution (Res.), and accuracy scores (VQAv2, OKVQA, GQA, VizWiz, and SciQA) for each model on each dataset. The generalist models are directly comparable, while specialist models are grayed out to highlight that their scores are not directly comparable to the generalist models due to their specialized training.
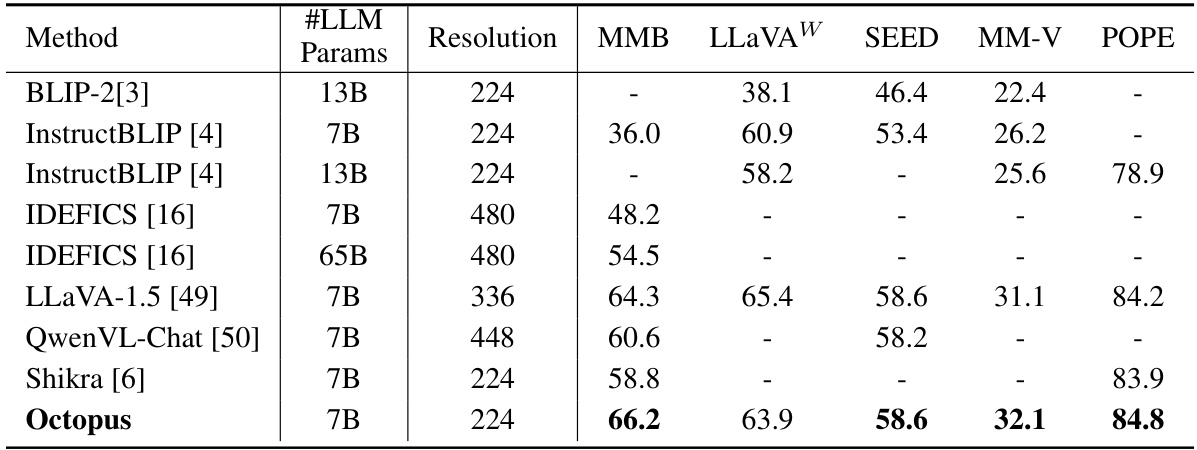
This table compares the performance of Octopus against other state-of-the-art multi-modal large language models (MLLMs) on several popular vision-language benchmarks. The benchmarks evaluated include MMBench (MMB), LLaVA-Bench (In-the-Wild) (LLaVAW), SEED, MM-Vet (MM-V), and POPE. The table shows the number of parameters (#LLM Params), resolution, and the scores achieved by each model on each benchmark. POPE scores are averages across three splits.

This table compares the accuracy of object detection between the final Octopus model results and the intermediate detection results from the DETR component. It shows that the final Octopus model achieves higher accuracy than relying solely on the top-ranked DETR detection, and highlights the improved recall achieved with the top-k ranked DETR detections.

This table presents the quantitative evaluation of the referring segmentation performance on the RefCOCO benchmark using cIoU. The results show the performance of the Octopus model on the validation set and test sets (testA and testB) using a resolution of 224. The relatively low cIoU scores are attributed to the use of low-resolution CLIP-ViT features (224x224) and the smaller size of the input images for the task. The authors suggest that increasing the input size and the training data would likely improve performance.
Full paper#