↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Camera-LiDAR fusion models enhance autonomous driving perception but suffer from high computational costs due to redundant features from separately trained single-modal backbones. Existing pruning methods struggle with these fusion models because they don’t account for the interaction between modalities.
AlterMOMA, a novel pruning framework, tackles this problem. It uses an “alternative modality masking” approach. One modality’s parameters are masked, forcing the model to reactivate redundant features from the other. This reactivation process identifies these redundant features, which are then pruned using an importance score evaluation function (AlterEva). Extensive experiments show AlterMOMA outperforms existing methods across multiple datasets and tasks, achieving state-of-the-art performance.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in autonomous driving: the high computational cost of camera-LiDAR fusion models. By introducing an effective pruning method, it enables the development of more efficient and resource-friendly perception systems, paving the way for wider adoption of autonomous driving technology. The proposed AlterMOMA framework offers a novel approach to pruning, which can inspire further research in the field of model compression and multi-modal fusion.
Visual Insights#
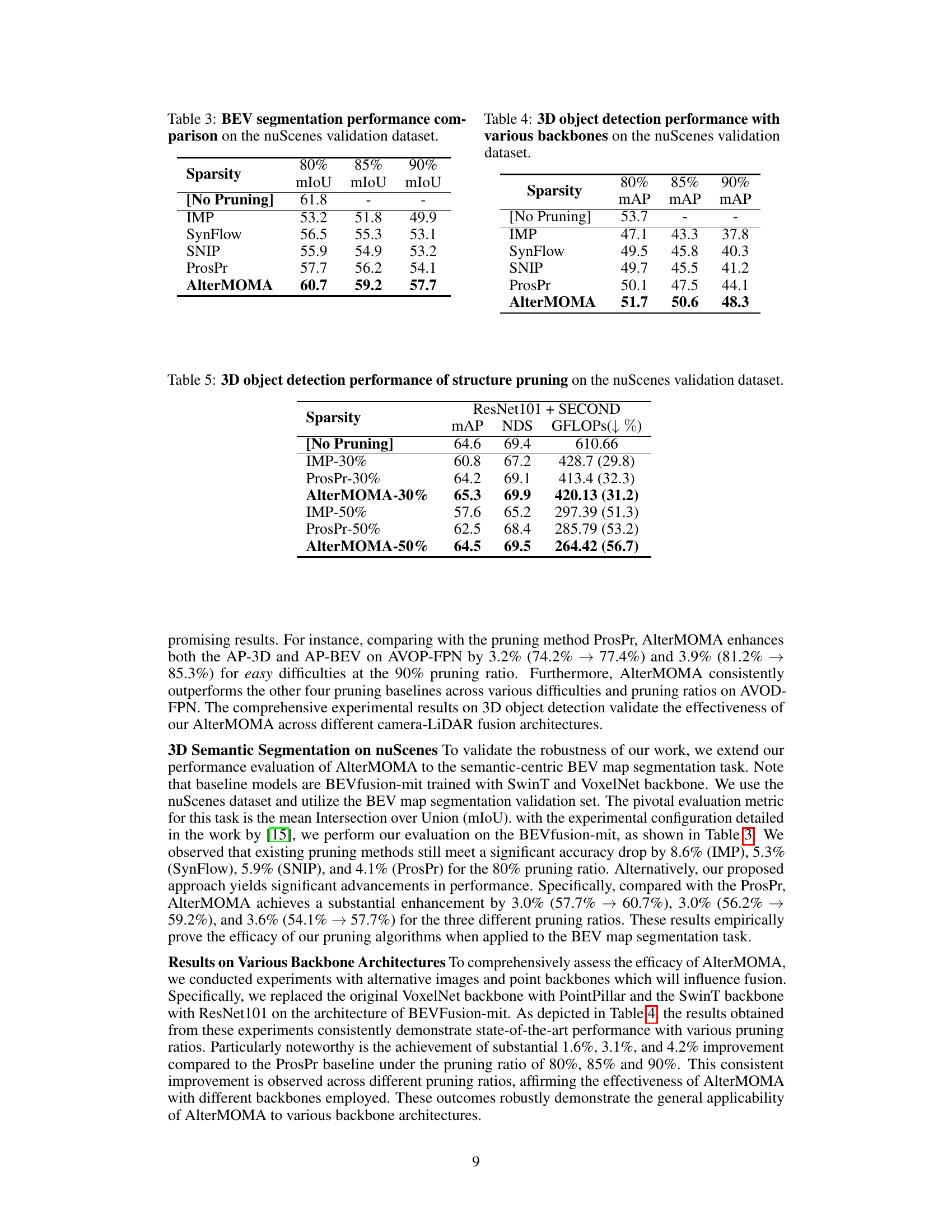
This figure illustrates the redundancy in features extracted by pre-trained single-modality backbones when used in a camera-LiDAR fusion model for 3D object detection. By comparing the gradients during backpropagation with only the camera branch active versus both camera and LiDAR branches active, the authors show that some camera backbone parameters become redundant when LiDAR information is added. This is because both modalities extract similar features, leading to duplicated information in the fusion model.
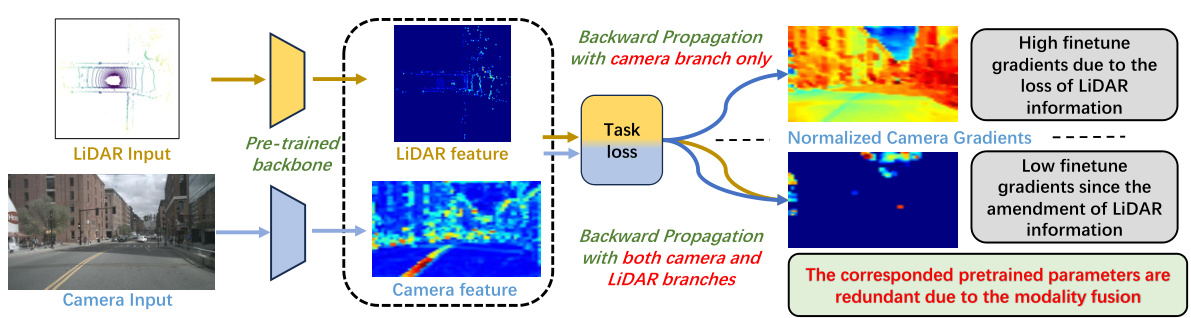
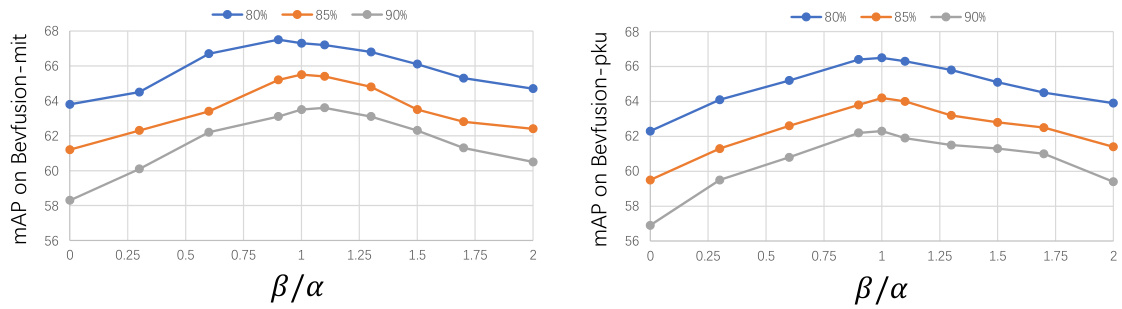
This table presents a comparison of 3D object detection performance using different pruning methods on the nuScenes validation dataset. It shows the mean Average Precision (mAP) and NuScenes Detection Score (NDS) for models pruned at 80%, 85%, and 90% sparsity levels. Two baseline models (BEVfusion-mit and BEVfusion-pku) are included, each trained with different backbones (SwinT and VoxelNet). The table allows for a comparison of AlterMOMA’s performance against other state-of-the-art pruning techniques (IMP, SynFlow, SNIP, ProsPr).
In-depth insights#
Fusion Redundancy#
The concept of “Fusion Redundancy” in camera-LiDAR fusion models centers on the overlap in information extracted by individual sensors. Pre-trained single-modality backbones, while efficient, often lead to redundant feature representations. This redundancy arises because both camera and LiDAR networks independently learn to extract similar features (e.g., geometry). The fusion mechanism then selectively utilizes these features, making some information redundant within the combined model. Identifying and removing this redundancy through pruning is crucial for optimizing model efficiency and resource utilization, while retaining performance. The challenge lies in effectively distinguishing between truly redundant and essential features, as simply removing parameters could negatively impact accuracy. This is why a sophisticated pruning method such as AlterMOMA is needed, focusing on discerning and eliminating fusion-redundant parameters to optimize performance. Alternative modality masking is key to this process, helping reveal the parameters that are only necessary due to the absence of information from the masked branch. This strategy elegantly exposes redundancy otherwise hidden in a standard feature fusion approach.
AlterMOMA Framework#
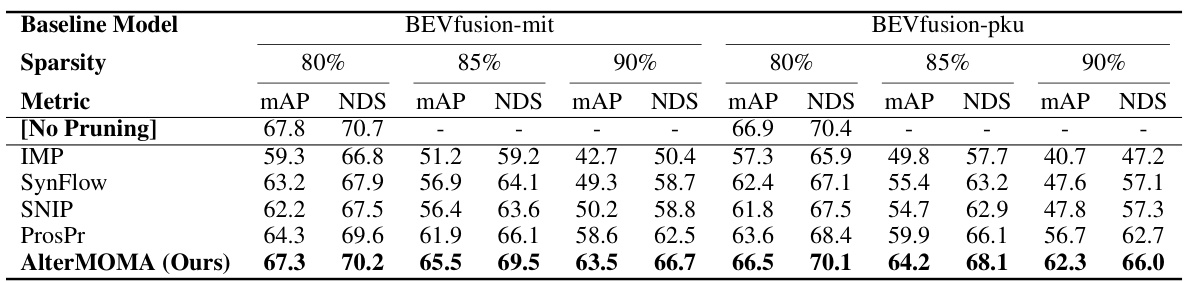
The AlterMOMA framework tackles the challenge of redundancy in camera-LiDAR fusion models by employing a novel pruning strategy. It leverages an alternative modality masking approach, where either the camera or LiDAR backbone is temporarily deactivated. This forces the model to compensate by reactivating redundant features from the other modality, effectively highlighting these redundant components for targeted pruning. The framework then uses an importance score evaluation function (AlterEva) that considers both the contribution of features when active and the change in model performance upon deactivation, leading to a more precise identification and removal of truly redundant parameters. The result is a more efficient camera-LiDAR fusion model with minimal performance loss, demonstrating that AlterMOMA offers a significant improvement over traditional single-modality pruning methods. Its strength lies in its understanding of the inter-modality dependencies within fusion architectures, allowing it to prune more intelligently and effectively.
Unstructured Pruning#
Unstructured pruning, unlike its structured counterpart, offers a more flexible approach to network compression by removing individual weights or neurons rather than entire filters or layers. This method’s flexibility allows for potentially greater compression ratios while preserving model accuracy, as it can adapt to the specific architecture and importance of different parts of the network. However, the lack of structure also presents challenges. For example, it can lead to sparsity patterns that are not easily implemented in hardware, resulting in limited efficiency gains. The choice of pruning criterion becomes particularly crucial, as a poorly chosen method may lead to performance degradation. Techniques like magnitude-based pruning, which removes less important weights, often show promise. Another challenge lies in the computational cost of identifying the best weights to remove. Effective unstructured pruning often requires sophisticated algorithms that take into account the network’s architecture, training data, and desired performance. Fine-tuning is frequently necessary after pruning to restore the model’s performance, potentially offsetting initial efficiency gains.
Multi-modal Fusion#
Multi-modal fusion, in the context of autonomous driving, aims to synergistically combine data from diverse sensors like cameras and LiDAR to achieve perception performance exceeding individual sensor capabilities. Early fusion integrates raw sensor data, while late fusion combines processed data, and intermediate fusion operates on intermediate feature representations. The choice of fusion method significantly impacts computational cost and performance. Effective fusion strategies must account for differences in sensor modalities, address data inconsistencies, and efficiently leverage complementary strengths while mitigating weaknesses. Challenges include aligning data from different coordinate systems, handling data sparsity, and ensuring robustness to noisy or incomplete data. Successful multi-modal fusion hinges on both effective feature extraction and sophisticated fusion architectures, often employing attention mechanisms or deep learning techniques to learn optimal data integration strategies. Research continually explores novel fusion approaches to improve both accuracy and efficiency in autonomous driving systems. Ultimately, optimal multi-modal fusion remains an active area of research aiming for robust, real-time perception in complex driving environments.
Future Research#
Future research directions stemming from this work on fusion redundancy pruning could explore extending the methodology to other multi-modal fusion models beyond camera-LiDAR, such as vision-language models. This would require careful consideration of the unique fusion mechanisms and feature representations in those different modalities. Investigating the impact of different backbone architectures and fusion strategies on the effectiveness of the proposed pruning framework is another important avenue for future research. The current work focuses primarily on image and point cloud data, so evaluating performance with other sensor modalities (e.g. radar) would enhance the generalizability of the findings. Finally, more in-depth analysis of the interplay between the Deactivated Contribution Indicator (DeCI) and Reactivated Redundancy Indicator (ReRI) could lead to improved parameter importance score evaluation. Developing more sophisticated evaluation metrics that account for different aspects of feature contribution could further optimize pruning performance. Additionally, exploring the potential for combining this pruning technique with other model compression methods (e.g., quantization) could lead to even greater efficiency gains.
More visual insights#
More on figures
This figure illustrates the workflow of the AlterMOMA framework. It starts by masking one of the backbones (either LiDAR or Camera) and then iteratively reactivates redundant features by training with batches. The importance scores of parameters are updated with the AlterEva function using two indicators: Deactivated Contribution Indicator (DeCI) and Reactivated Redundancy Indicator (ReRI). Finally, parameters with low importance scores are pruned, and the model is fine-tuned.

This figure visualizes the features from LiDAR, camera, and their fusion at different stages of the AlterMOMA pruning process. It shows how redundant depth features in the camera branch are reactivated when LiDAR features are masked, and then how these redundant features are ultimately pruned by AlterMOMA.
This figure visualizes how features from LiDAR and camera are processed in three stages: original, reactivated, and pruned. The original features show both LiDAR and camera features fused together. The reactivated features show only camera features because LiDAR features are masked, forcing the model to reactivate redundant camera features. The pruned features show the result after AlterMOMA prunes redundant features, leaving only the essential features.
More on tables
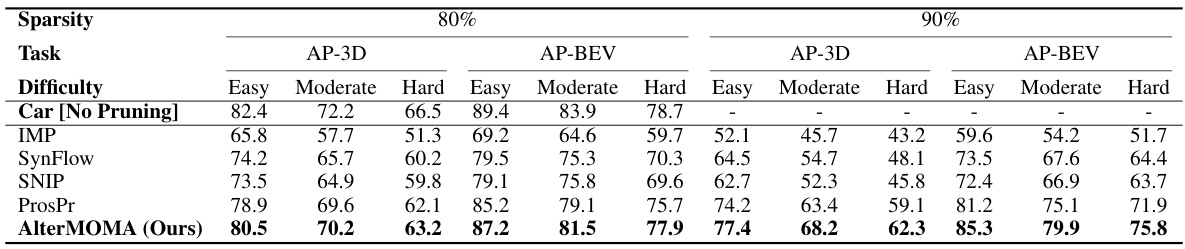
This table compares the performance of different pruning methods on the KITTI dataset for 3D object detection of cars. It shows the AP-3D and AP-BEV (average precision in 3D and bird’s eye view) for different pruning ratios (80% and 90%) and difficulty levels (easy, moderate, hard). The baseline model used is AVOD-FPN.

This table presents a comparison of the BEV segmentation performance (mIoU) achieved by different pruning methods on the nuScenes validation dataset. It shows the mIoU scores for three different sparsity levels (80%, 85%, and 90%) for each method, including a baseline model with no pruning and several other state-of-the-art pruning techniques (IMP, SynFlow, SNIP, ProsPr). The table highlights the performance of the proposed AlterMOMA method relative to these baselines.

This table compares the performance of different pruning methods (IMP, SynFlow, SNIP, ProsPr, and AlterMOMA) on 3D object detection task using various backbones (ResNet and PointPillars) on the nuScenes validation dataset. The table shows the mean Average Precision (mAP) achieved at different sparsity levels (80%, 85%, and 90%). It demonstrates the effectiveness of AlterMOMA compared to other methods in maintaining high accuracy even with significant parameter reduction.
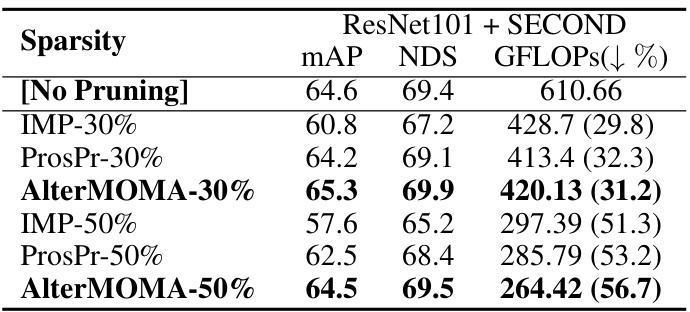
This table presents the results of structure pruning experiments conducted on the nuScenes validation dataset using the 3D object detection task. It compares the performance of different pruning methods (IMP, ProsPr, and AlterMOMA) at two different sparsity levels (30% and 50%). The performance metrics reported include mean Average Precision (mAP), NuScenes Detection Score (NDS), and the reduction in GFLOPs (giga floating-point operations). The table shows that AlterMOMA achieves better performance compared to other methods at both sparsity levels while simultaneously offering significant computational savings.

This table compares the performance of different pruning methods on the nuScenes dataset for 3D object detection. It shows the mean Average Precision (mAP) and NuScenes Detection Score (NDS) for models pruned at 80%, 85%, and 90% sparsity levels. Two baseline models (trained with Swin Transformer and VoxelNet backbones) are included for comparison.
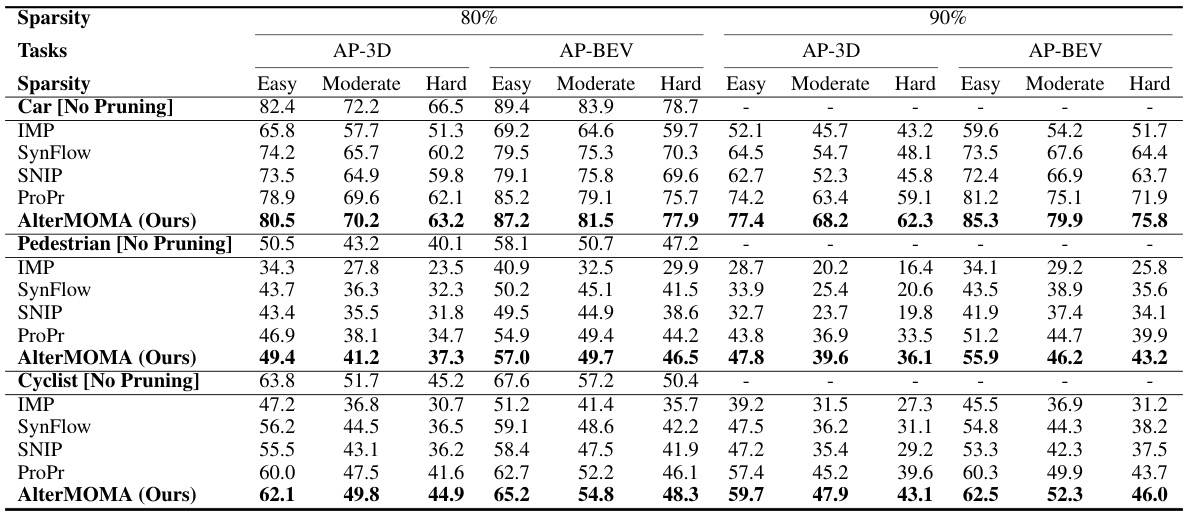
This table compares the performance of different pruning methods (IMP, SynFlow, SNIP, ProsPr, and AlterMOMA) on the KITTI dataset for 3D object detection, specifically focusing on the ‘car’ class. It shows the Average Precision (AP) in 3D, BEV, and across different difficulty levels (Easy, Moderate, Hard) for 80% and 90% sparsity levels. The baseline results (without pruning) are also provided for comparison.
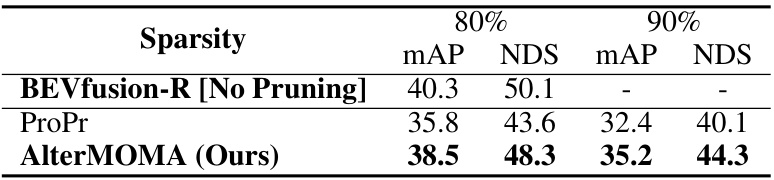
This table compares the performance of different pruning methods on a camera-radar fusion model for 3D object detection using the nuScenes validation dataset. The baseline model uses ResNet and PointPillars backbones. The table shows the mean Average Precision (mAP) and NuScenes Detection Score (NDS) for models pruned at 80% and 90% sparsity levels, comparing the performance of AlterMOMA against the ProPr baseline method.

This table compares the performance of different pruning methods on the task of 3D multi-object tracking using the nuScenes dataset. It shows the AMOTA (Average Multi-Object Tracking Accuracy) scores for models pruned at 80% and 90% sparsity levels. The baseline model uses SwinT and VoxelNet backbones. The table helps to demonstrate the effectiveness of AlterMOMA in maintaining high tracking accuracy even with significant model compression.

This table presents a comparison of 3D object detection performance and inference speed for different pruning methods on the nuScenes validation dataset. The baseline model used is BEVfusion-mit, with ResNet101 and SECOND backbones. The results show the mAP, NDS, GFLOPs (with percentage reduction), and inference time (in milliseconds) for the baseline model and two versions of the AlterMOMA method (with 30% and 50% pruning). The table highlights the trade-off between accuracy and efficiency achieved by the AlterMOMA approach.
Full paper#