TL;DR#
Transformer-based models, while powerful, are vulnerable to adversarial attacks, which can easily fool them by making small modifications to input data. Existing defenses often have limitations such as high computational costs or reliance on specific domains. This makes developing robust and reliable transformer models crucial for the advancement of AI.
This research introduces ProTransformer, a novel robust attention mechanism. ProTransformer is designed to improve the resilience of transformers by incorporating a plug-and-play layer that doesn’t require additional training or fine-tuning. Extensive experiments demonstrate ProTransformer’s effectiveness across numerous tasks, attack types, architectures, and datasets. The findings show consistent improvement in model robustness without impacting their accuracy significantly. This approach holds immense promise for enhancing the security and reliability of transformer models in various applications.
Key Takeaways#
Why does it matter?#
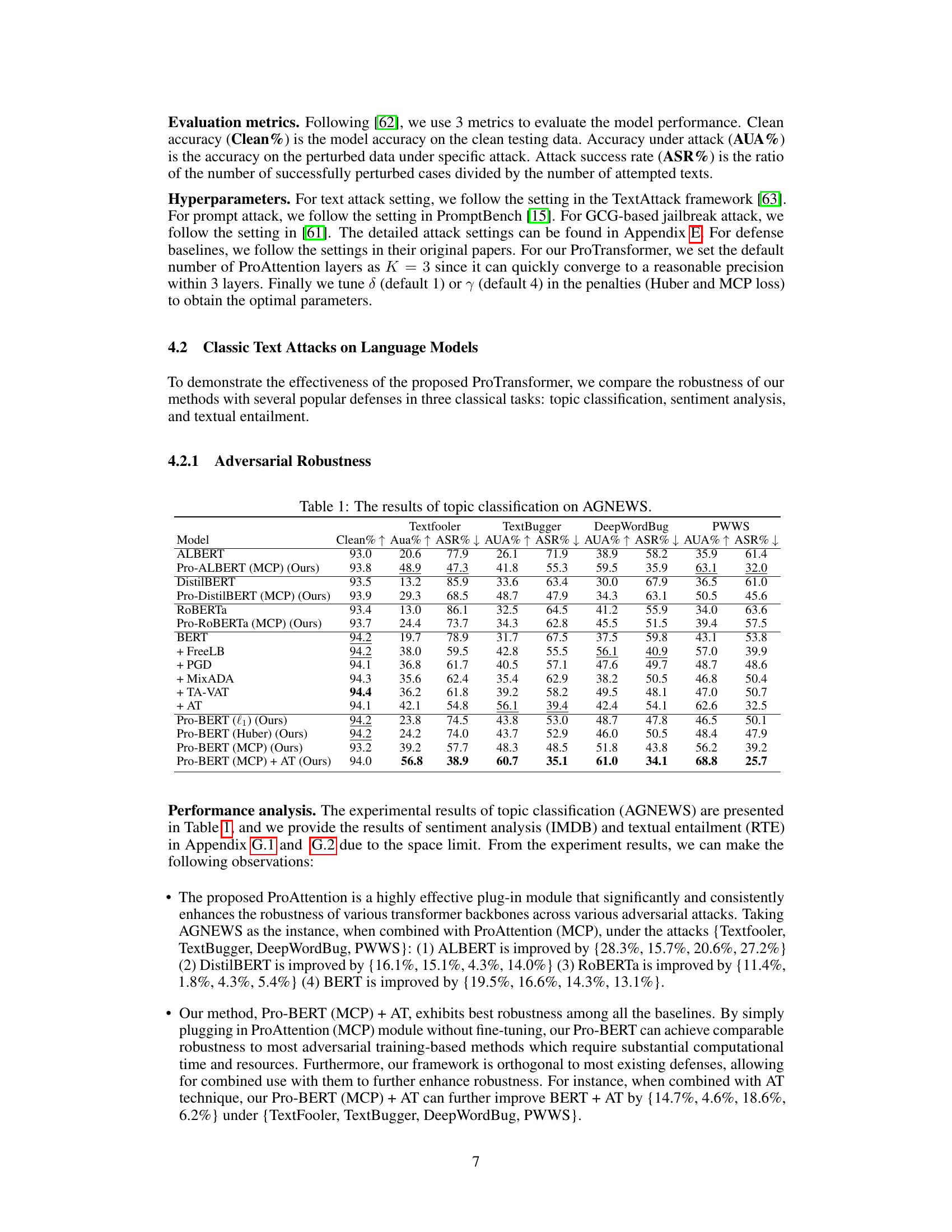
This paper is crucial because it introduces a novel plug-and-play robust attention mechanism, ProTransformer, that significantly improves the robustness of transformer models across various tasks and domains without needing additional training. This addresses a major challenge in the field, paving the way for more reliable and secure AI systems. Its versatility and efficiency make it highly relevant to the broader AI research community.
Visual Insights#

🔼 This figure showcases three main types of attacks against language models: classic text attacks, prompt attacks, and jailbreaks. Classic text attacks involve subtle modifications to the input text (e.g., typos or synonyms) to change the model’s prediction. Prompt attacks manipulate the prompt itself to elicit a different response. Jailbreaks append seemingly innocuous phrases to prompts that trick the model into generating unsafe or unexpected outputs.
read the caption
Figure 1: Various attack mechanisms on language models. Classic text attacks modify the input content using typos or synonyms; Prompt attacks perturb the prompt template within the input; and Jailbreaks append adversarial, non-semantic suffixes to manipulate the model into producing malicious outputs.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of the proposed ProTransformer against several baseline methods (ALBERT, DistilBERT, RoBERTa, BERT) and defense mechanisms (FreeLB, PGD, MixADA, TA-VAT, AT) under various text attack methods (TextFooler, TextBugger, DeepWordBug, PWWS). The table showcases the clean accuracy, accuracy under attack, and attack success rate for each model and attack combination, highlighting the effectiveness of ProTransformer in improving robustness against adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.
In-depth insights#
Plug-and-Play Robustness#
The concept of ‘Plug-and-Play Robustness’ in the context of transformer models refers to methods that enhance model robustness against adversarial attacks without requiring extensive retraining or model architecture changes. This is achieved by adding a new module or layer that improves the model’s resilience, similar to plugging in a new component. The advantages are significant; it offers a more practical and efficient solution than traditional methods such as adversarial training that are often computationally expensive. A key focus would be on designing this ‘plug-in’ module to be universal and effective across diverse transformer architectures and tasks. The plug-and-play aspect simplifies deployment and adaptation, making it a valuable tool for improving the reliability of AI systems in real-world settings. Generalizability is a critical factor for such a method to be truly impactful; it should work effectively irrespective of the original model’s training data or specific architecture. Finally, any limitations such as computational overhead introduced by the new module, need to be carefully considered and addressed to ensure that the improvement in robustness outweighs the added cost.
ProAttention Mechanism#
The ProAttention mechanism, as described in the research paper, presents a novel approach to enhance the robustness of transformer-based architectures. It leverages a weighted least squares (WLS) estimation perspective, reinterpreting the standard attention mechanism to understand its vulnerability to adversarial attacks. This vulnerability stems from the sensitivity of the WLS estimator to outlier data points. ProAttention introduces robust token estimators, modifying the WLS problem to mitigate the influence of these outliers. This is achieved through the incorporation of robust loss functions such as Huber and Minimax Concave Penalty (MCP) losses. An efficient Newton-IRLS algorithm is then used to solve the resulting non-convex optimization problem, offering a practical and efficient approach for implementation within transformer models. The plug-and-play nature of ProAttention is a key feature, allowing seamless integration into existing architectures without requiring retraining. This universality and ease of implementation are crucial for broader adoption across various domains and model types.
Newton-IRLS Algorithm#
The heading ‘Newton-IRLS Algorithm’ suggests a method for efficiently solving a complex optimization problem within the context of a robust attention mechanism. The name implies a hybrid approach, combining the speed and convergence properties of Newton’s method with the robustness of Iteratively Reweighted Least Squares (IRLS). This suggests the algorithm iteratively refines a solution by weighting data points, giving less importance to outliers or noisy data that can skew the result. The Newton component likely provides a second-order approximation which accelerates convergence compared to a purely iterative IRLS approach. Overall, the Newton-IRLS algorithm is likely designed to be computationally efficient while maintaining robustness against adversarial examples, a crucial aspect in the context of attention mechanisms and deep learning models prone to adversarial attacks.
LLM Robustness#
Large language model (LLM) robustness is a critical area of research, focusing on how well LLMs withstand adversarial attacks and unexpected inputs. Robustness is crucial for deploying LLMs safely and reliably in real-world applications. Current research explores various attack methods, such as adversarial examples designed to fool the model, and evaluates defenses, including data augmentation and adversarial training. However, these methods often come with substantial computational costs and may not generalize well to different LLMs and tasks. A key challenge is balancing robustness with accuracy and efficiency, particularly in resource-constrained environments. Future research should focus on developing more cost-effective and generalizable defense mechanisms that enhance the resilience of LLMs across various domains and attack strategies. The ideal solution would be a plug-and-play approach that easily improves LLM robustness without requiring extensive retraining or sacrificing performance.
Vision & Graph Results#
A hypothetical ‘Vision & Graph Results’ section would delve into the performance of the ProTransformer model on visual and graph-structured data. For vision tasks, it would likely detail results on benchmark datasets like CIFAR-10 or ImageNet, showcasing improved robustness against adversarial attacks (e.g., FGSM, PGD) compared to standard vision transformers. Key metrics would include clean accuracy and accuracy under attack, demonstrating the model’s resilience to image perturbations. Similarly, graph-based experiments would involve datasets such as Cora or Citeseer, measuring performance on node classification tasks and highlighting how ProTransformer’s robust attention mechanism improved the model’s robustness against adversarial attacks tailored to graph data (e.g., node or edge attacks). The discussion would likely analyze the generalizability of ProTransformer’s robustness across different data modalities, showcasing the plug-and-play architecture’s broad applicability, and possibly comparing the computational cost and efficiency relative to existing robust graph neural networks and vision transformers.
More visual insights#
More on figures
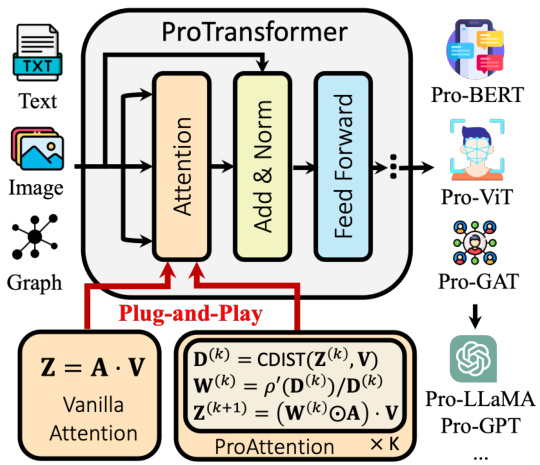
🔼 This figure illustrates the architecture of ProTransformer, highlighting its plug-and-play nature. ProAttention, a novel robust attention mechanism, is integrated into existing transformer models (BERT, ViT, GAT, LLaMA, GPT, etc.) without requiring additional training or fine-tuning. The diagram shows how ProAttention improves upon vanilla attention by incorporating a robust token estimation process, enhancing the resilience of transformers to various attacks across multiple data domains (text, image, graph). The iterative nature of ProAttention is shown with the ‘x K’ indicating multiple iterations of the process.
read the caption
Figure 2: Overview of ProTransformer. ProAttention can be plugged into pretrained transformers without additional training. The ProTransformer is versatile and can be applied across various domains, including language, image, and graph.
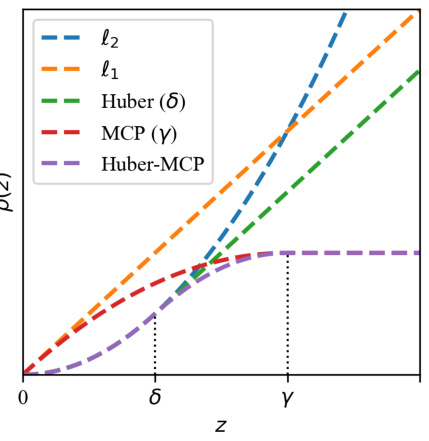
🔼 This figure shows different penalty functions used in robust weighted least squares token estimators. The x-axis represents the residual, while the y-axis represents the penalty. The figure illustrates the quadratic loss (l2), the absolute loss (l1), the Huber loss, the Minimax Concave Penalty (MCP), and the Huber-MCP loss. Each function is plotted to show how it handles outliers (large residuals). The Huber, MCP and Huber-MCP are robust loss functions.
read the caption
Figure 3: Different p(z).
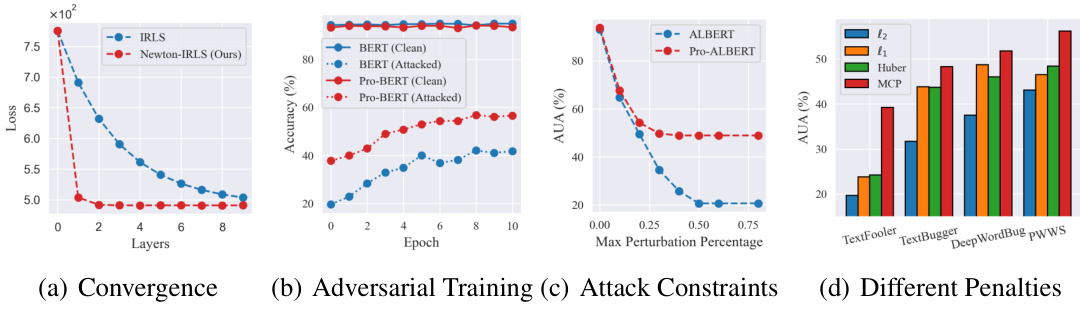
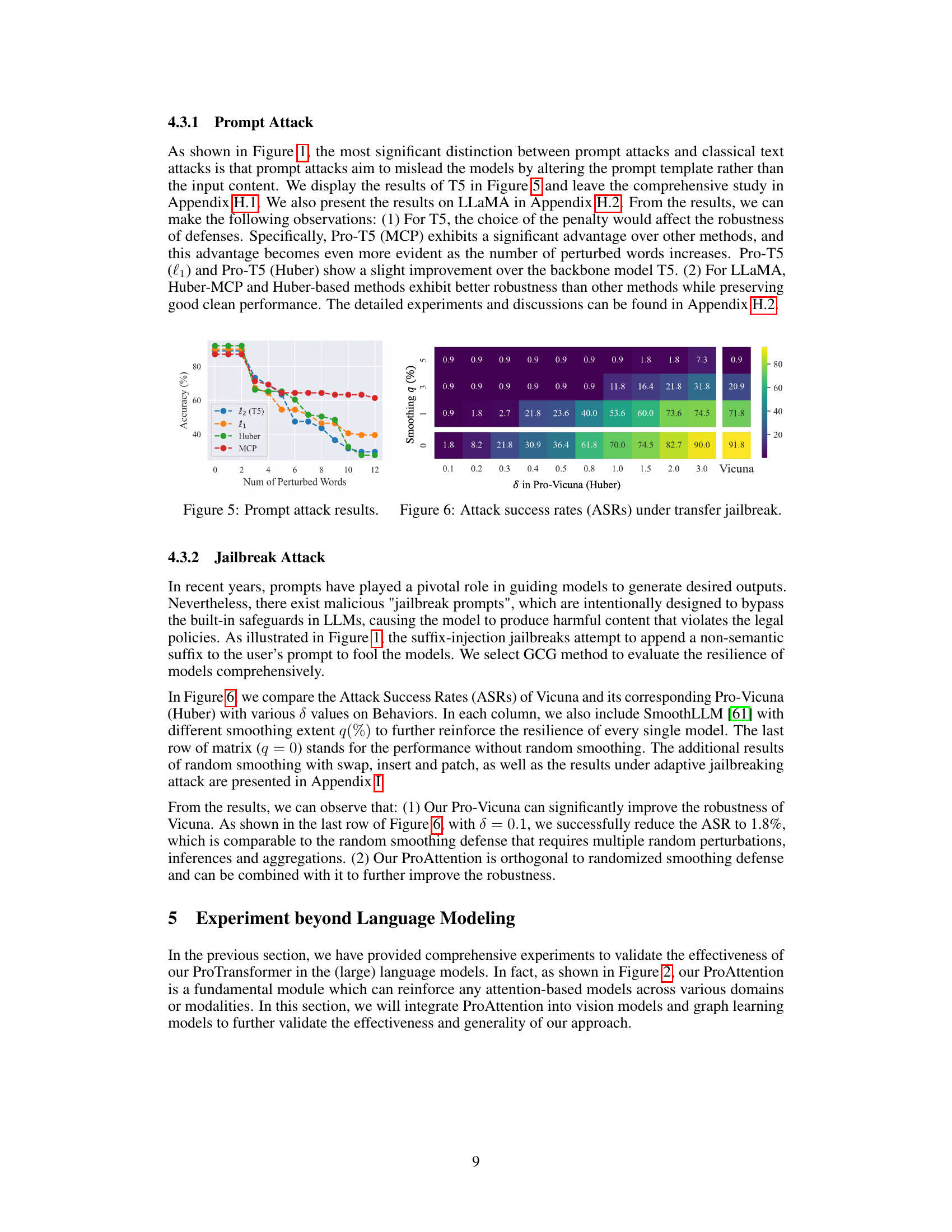
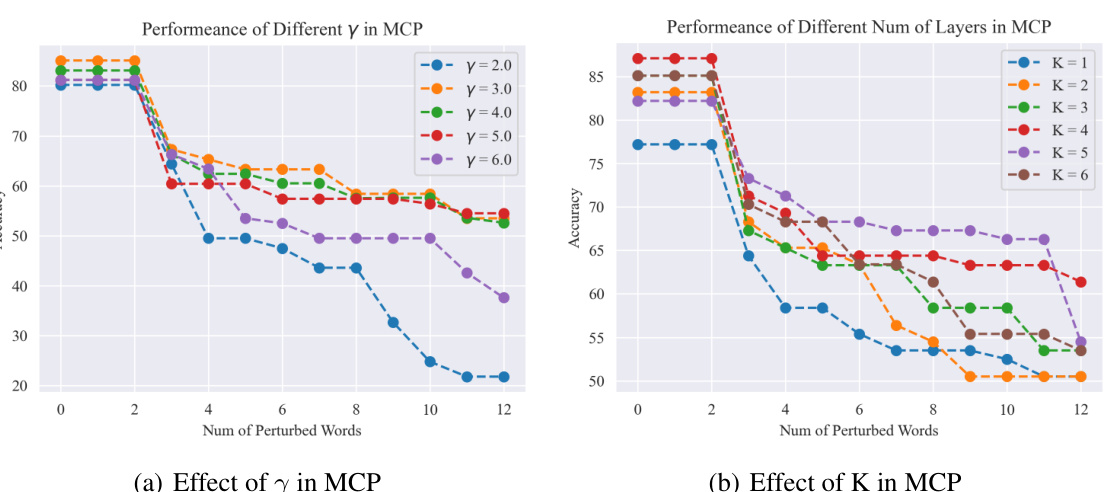
🔼 Four ablation studies are presented to support the claims of the paper. (a) Convergence: The convergence speed of the proposed Newton-IRLS algorithm is compared to the first-order method. (b) Adversarial Training: The training curves of adversarial fine-tuning under TextFooler attack are presented. (c) Attack Constraints: The performance of the proposed algorithm under various attack constraints (maximum perturbation percentage) is presented. (d) Different Penalties: The performance of the proposed algorithm under different penalties (l2, l1, Huber, MCP) is presented.
read the caption
Figure 4: Ablation studies.
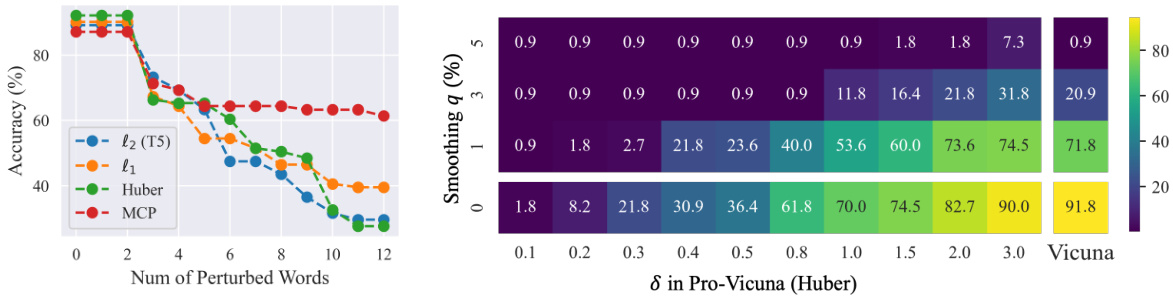
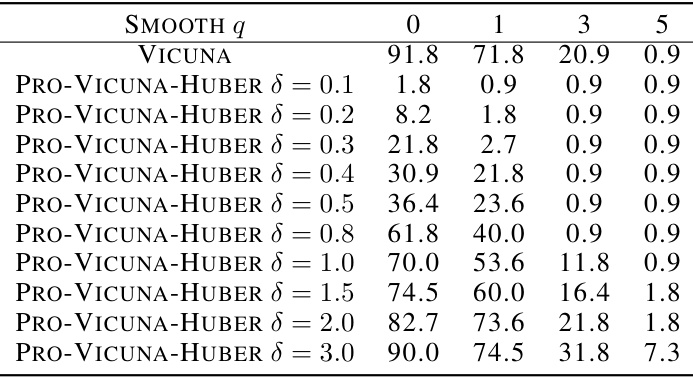
🔼 This figure shows the attack success rates (ASRs) under transfer jailbreak attacks. The heatmap displays ASRs for the Vicuna model and its Pro-Vicuna (Huber) variant, across various values of the smoothing parameter (q) and the Huber loss parameter (δ). The results demonstrate the effectiveness of the Pro-Vicuna model in reducing ASRs, particularly at lower smoothing values. The data highlights that the effectiveness of the Pro-Vicuna model is comparatively good even without random smoothing (q=0).
read the caption
Figure 6: Attack success rates (ASRs) under transfer jailbreak.

🔼 The figure shows the loss curves of the proposed Newton-IRLS algorithm with different penalty functions (l1, MCP, and Huber). The x-axis represents the number of layers, and the y-axis represents the loss value. The plots demonstrate that the algorithm converges quickly to the optimal solution within a few iterations, regardless of the penalty function used.
read the caption
Figure 7: Loss Curve of Algorithms

🔼 This figure visualizes the trajectories of the updated vectors in a 2D plane during the optimization process. It uses L1 penalty and shows how the updated vectors (Trajectory-1, Trajectory-2, Trajectory-3) converge towards their respective ground truth values (Ground-Truth-1, Ground-Truth-2, Ground-Truth-3) within just three steps. This demonstrates the efficient and effective convergence of the Newton-IRLS algorithm.
read the caption
Figure 8: Optimization trajectory.

🔼 The figure visualizes different estimators’ performance in the presence of outliers. It uses synthetic data with varying percentages of outliers (15%, 30%, 45%). The plot compares the performance of the least squares estimator (l2), the least absolute deviations estimator (l1), and the minimax concave penalty estimator (MCP) against the ground truth mean. The results demonstrate the robustness of l1 and MCP, particularly MCP, against outliers, showcasing their ability to accurately estimate the mean even with a significant number of contaminating data points.
read the caption
Figure 9: Different estimators in simulations.

🔼 This figure presents four ablation studies to demonstrate the effectiveness of the proposed ProTransformer. (a) Convergence: Shows the convergence behavior of Newton-IRLS, comparing it to a first-order method. (b) Adversarial Training: Illustrates the effect of adversarial training on model robustness, showcasing how Pro-BERT improves upon standard BERT with TextFooler attacks. (c) Attack Constraints: Demonstrates the impact of various attack constraints (maximum perturbation, minimum cosine similarity, sentence similarity threshold) on model performance for the TextFooler attack. (d) Different Penalties: Compares the performance using different robust penalties (L1, Huber, MCP, Huber-MCP) for the ProTransformer model, highlighting the superior robustness of the MCP penalty.
read the caption
Figure 4: Ablation studies.
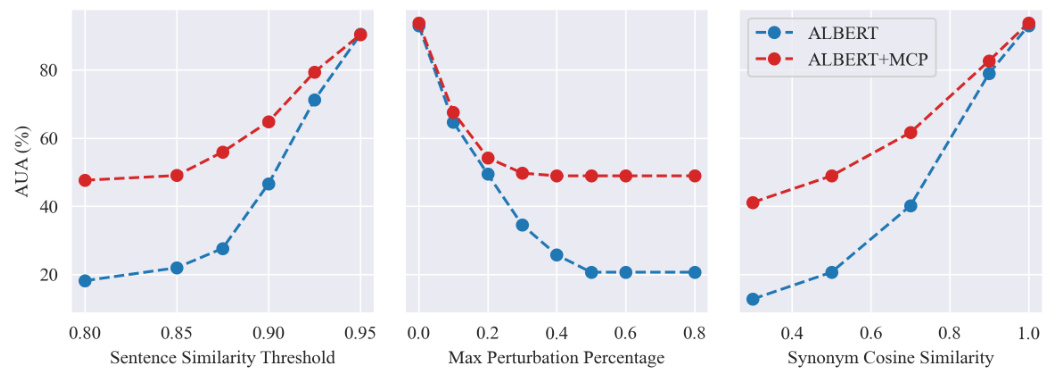
🔼 This figure presents ablation studies on three attack constraints: sentence similarity threshold, maximum perturbation percentage, and synonym cosine similarity. The studies were performed on the AGNEWS dataset using the TextFooler attack with the ALBERT model as the backbone. The results demonstrate the consistent improvement of the proposed method (ALBERT+MCP) over the baseline model (ALBERT) across various settings of the constraints.
read the caption
Figure 11: Ablation studies on attack constraints.
🔼 This figure illustrates the ProTransformer architecture, which involves integrating the ProAttention module into various pre-trained transformer models. It highlights the plug-and-play nature of ProAttention, its adaptability to different domains (language, image, graph), and its ability to enhance the robustness of transformer models without requiring additional training or fine-tuning.
read the caption
Figure 2: Overview of ProTransformer. ProAttention can be plugged into pretrained transformers without additional training. The ProTransformer is versatile and can be applied across various domains, including language, image, and graph.

🔼 This figure presents several ablation studies conducted to validate the effectiveness of the proposed method. Subfigure (a) shows the convergence analysis of the Newton-IRLS algorithm compared to the standard IRLS method. Subfigure (b) compares the effectiveness of adversarial fine-tuning. Subfigure (c) shows how the performance of the model changes under different attack constraints. Finally, subfigure (d) compares the performance of the model with different penalty functions.
read the caption
Figure 4: Ablation studies.

🔼 This figure presents four ablation studies. (a) shows the convergence comparison between the first-order method and the proposed Newton-IRLS algorithm, demonstrating the superior efficiency of the latter. (b) illustrates the impact of adversarial fine-tuning on model robustness. (c) analyzes the influence of different attack constraints on model performance, highlighting the effectiveness of the proposed method under various constraints. Finally, (d) compares the performance of the proposed method with different penalties (l1, Huber, MCP, Huber-MCP) on the AGNEWS dataset.
read the caption
Figure 4: Ablation studies.

🔼 This figure presents the results of several ablation studies conducted to analyze the impact of different factors on the performance of the proposed ProTransformer. (a) Convergence: This plot illustrates the convergence behavior of the Newton-IRLS algorithm used in ProAttention, comparing it against a standard first-order method. (b) Adversarial Training: This shows the effect of adversarial training on model robustness, comparing ProTransformer with standard BERT. (c) Attack Constraints: This demonstrates the influence of various attack parameters (like the maximum perturbation percentage) on the model’s robustness. (d) Different Penalties: This illustrates the impact of different penalty functions (L1, Huber, MCP) within ProAttention on the model’s robustness.
read the caption
Figure 4: Ablation studies.
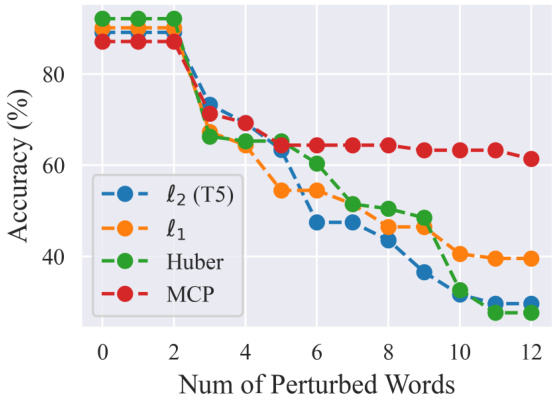
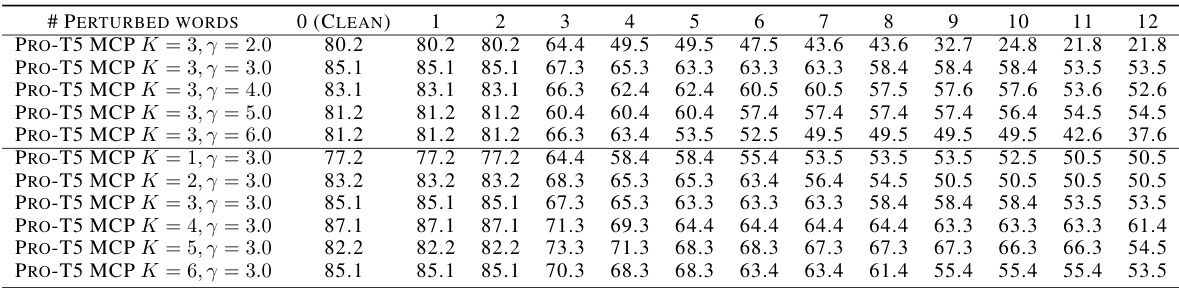
🔼 The figure shows the accuracy of different robust attention mechanisms under prompt attack using TextFooler on the SST2 dataset. The x-axis represents the number of perturbed words in the prompt, and the y-axis represents the accuracy. The results show that the proposed ProTransformer with MCP loss consistently outperforms other methods, especially with a larger number of perturbed words, demonstrating its improved robustness against prompt attacks.
read the caption
Figure 17: Accuracy (%) under prompt attack on SST2 (TextFooler, T5)
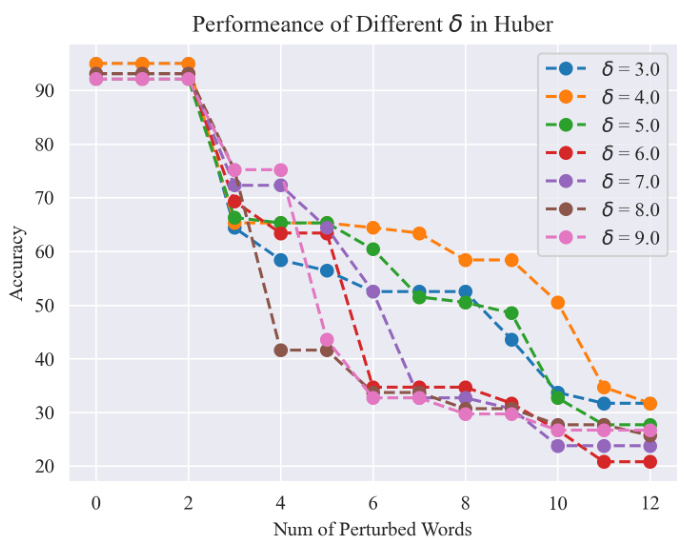
🔼 This ablation study explores the effect of different delta values (δ) on the performance of the Huber-based Pro-T5 model against the TextFooler attack on the SST2 dataset. The x-axis represents the number of perturbed words, and the y-axis shows the accuracy. The figure shows how different values of delta affect the robustness of the model against adversarial attacks with varying intensity. The optimal delta value is found to provide the best balance between robustness and clean accuracy.
read the caption
Figure 17: Ablation study on Huber on T5
🔼 This figure presents several ablation studies on the proposed ProTransformer. Specifically, it includes (a) Convergence: showing the loss descent curves for the Newton-IRLS algorithm, (b) Adversarial Training: visualizing the training curves of adversarial fine-tuning, (c) Attack Constraints: presenting the performance under different attack constraints such as maximum perturbation, minimum cosine similarity, and sentence similarity, and (d) Different Penalties: comparing the performance using different penalties (l2, l1, Huber, MCP). These results provide insights into various aspects of the ProTransformer and its robustness.
read the caption
Figure 4: Ablation studies.

🔼 This figure illustrates three main types of adversarial attacks against language models: classic text attacks, prompt attacks, and jailbreaks. Classic text attacks involve subtle modifications to the input text, such as typos or synonym replacements, to cause misclassification. Prompt attacks focus on manipulating the prompt or instructions given to the model, leading to unintended or harmful outputs. Finally, jailbreaks use adversarial suffixes added to the input to elicit malicious behavior from the model, bypassing safety mechanisms.
read the caption
Figure 1: Various attack mechanisms on language models. Classic text attacks modify the input content using typos or synonyms; Prompt attacks perturb the prompt template within the input; and Jailbreaks append adversarial, non-semantic suffixes to manipulate the model into producing malicious outputs.
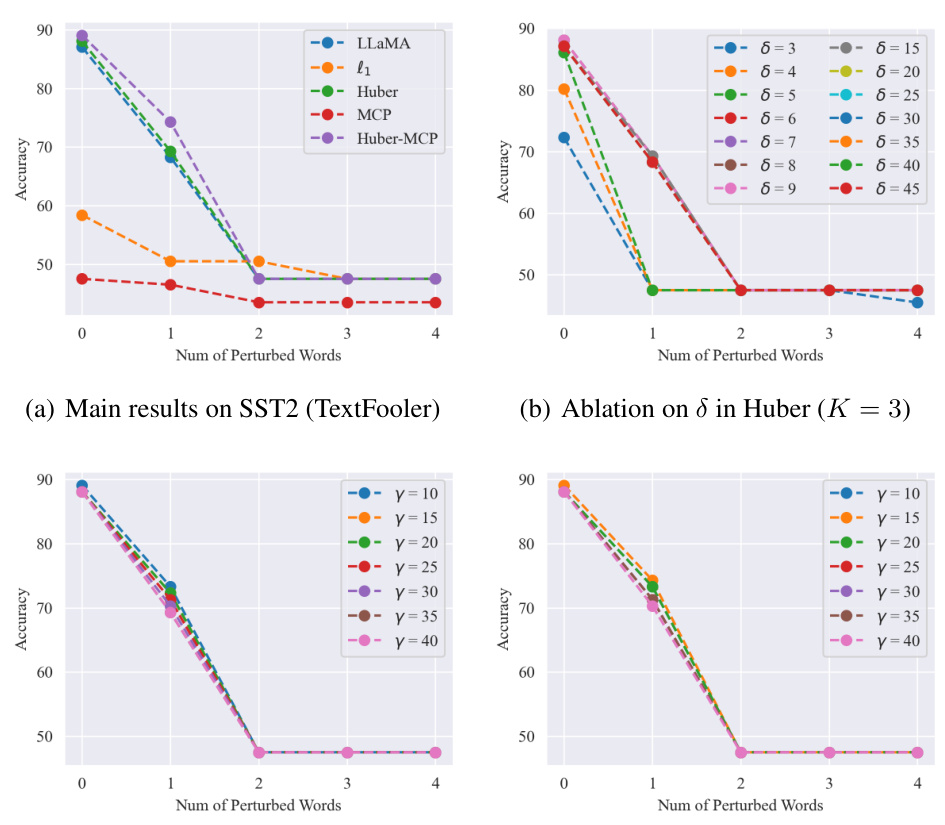
🔼 This figure shows the results of the TextFooler attack on the LLaMA model. Subfigures (a) through (d) present the main results and ablation studies on the hyperparameters of Huber and Huber-MCP loss functions. The results demonstrate that Pro-LLaMA with the Huber-MCP loss function offers improved robustness against TextFooler attacks, especially when compared to other methods (l1, MCP, Huber) under various attack budgets.
read the caption
Figure 20: LLaMA (Textfooler)

🔼 This figure shows the results of the textual entailment task on the SST2 dataset under the TextFooler attack for the LLaMA model. The left-hand plot shows the main results comparing the performance of the baseline LLaMA model against versions incorporating different robust penalties (l1, Huber, MCP, and Huber-MCP). The right-hand plots show ablation studies for the Huber and Huber-MCP robust penalty functions, varying the parameters delta (δ) and gamma (γ), respectively, to analyze their impact on model accuracy under the TextFooler attack.
read the caption
Figure 20: LLaMA (Textfooler)

🔼 This figure presents the results of textual entailment on SST2 under the TextFooler attack for the LLaMA model. It compares the performance of the baseline LLaMA model against versions enhanced with different robust attention mechanisms (l1, Huber, MCP, and Huber-MCP). Subplots (a) shows the main results, while (b), (c), and (d) show ablation studies on the hyperparameters (δ and γ) of the Huber and Huber-MCP methods respectively. The results demonstrate that l1 and MCP-based models suffer from significant performance drops, while the Huber and Huber-MCP methods achieve better robustness.
read the caption
Figure 20: LLaMA (Textfooler)
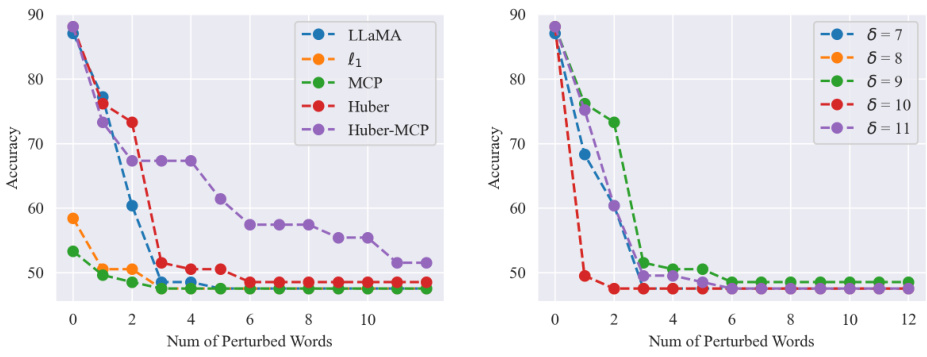
🔼 This figure presents the results of textual entailment experiments on the SST2 dataset using the TextFooler attack against the LLaMA language model. It compares the performance of the original LLaMA model against various robust versions using different penalty functions (l1, Huber, MCP, and Huber-MCP). The subfigures (a) to (d) show the main results and ablation studies on the delta and gamma parameters of the Huber and Huber-MCP penalty functions respectively. The results demonstrate the impact of different penalty functions on the model’s robustness under different attack strengths, represented by the number of perturbed words.
read the caption
Figure 20: LLaMA (Textfooler)
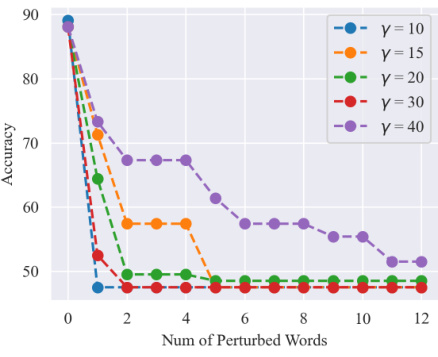
🔼 This figure displays the results of textual entailment on SST2 under TextFooler attack for LLaMA model. It presents the main results, and ablation studies on delta and gamma in Huber and Huber-MCP respectively. The results show that l1 and MCP-based methods sacrifice performance, while Pro-LLaMA (Huber) outperforms other baselines.
read the caption
Figure 20: LLaMA (Textfooler)
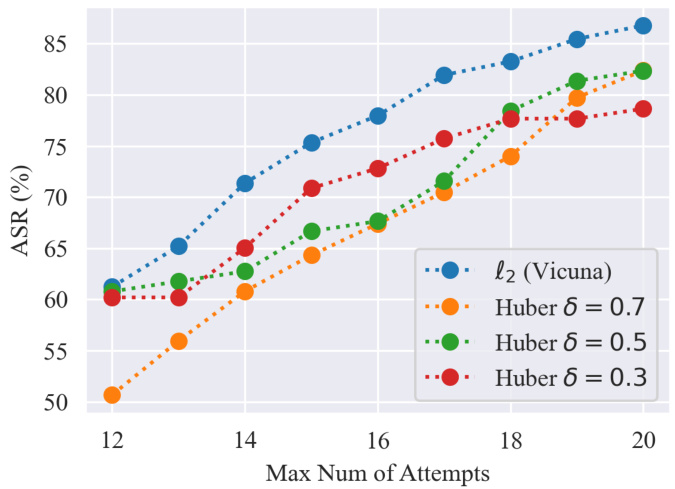
🔼 This figure shows the attack success rates (ASRs) of Vicuna and Pro-Vicuna under adaptive jailbreaking attacks on the Behaviors dataset. It demonstrates the effectiveness of Pro-Vicuna in mitigating these attacks, showing a significant improvement in robustness compared to the baseline Vicuna model, even with varying numbers of attack attempts. The different lines represent different values of the delta parameter (δ) in the Huber loss function used in Pro-Vicuna, demonstrating the impact of this parameter on the model’s robustness.
read the caption
Figure 23: Adaptive JailBreak
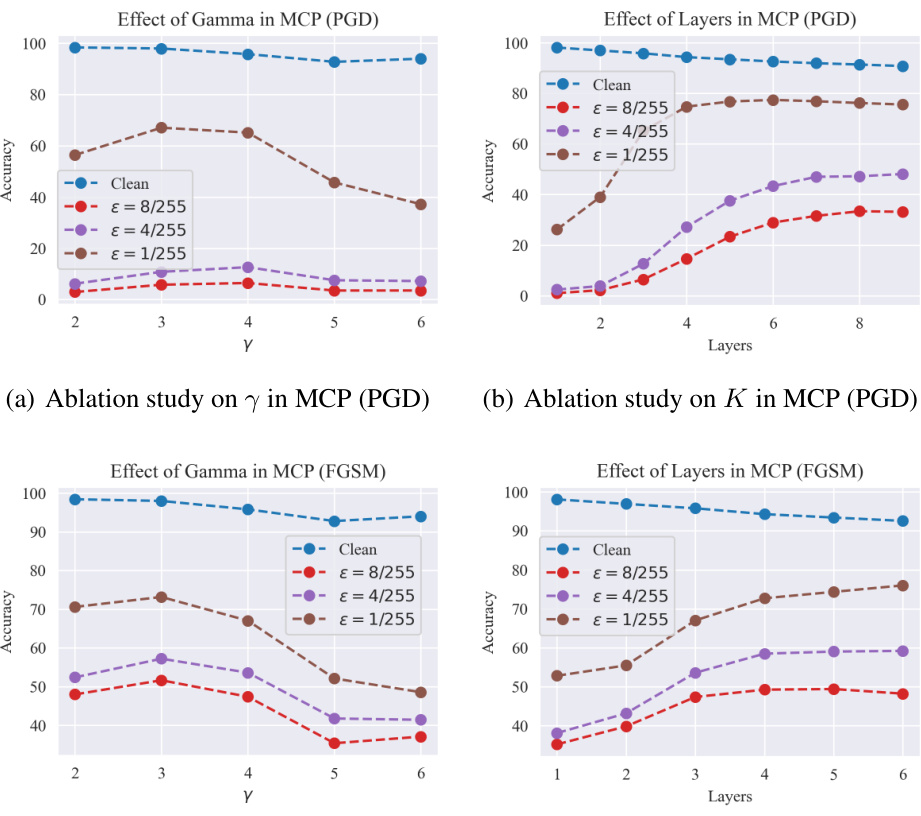
🔼 This figure presents the results of several ablation studies conducted to evaluate the effectiveness of the proposed ProTransformer model. The studies explore different aspects of the model, including its convergence properties, the effects of adversarial fine-tuning, the impact of attack constraints, and the influence of different penalty functions used in the robust token estimators. Subfigure (a) shows convergence curves, (b) illustrates the impact of adversarial training on model robustness, (c) analyzes the effect of attack constraints, and (d) compares the performance of different penalty functions.
read the caption
Figure 4: Ablation studies.
More on tables
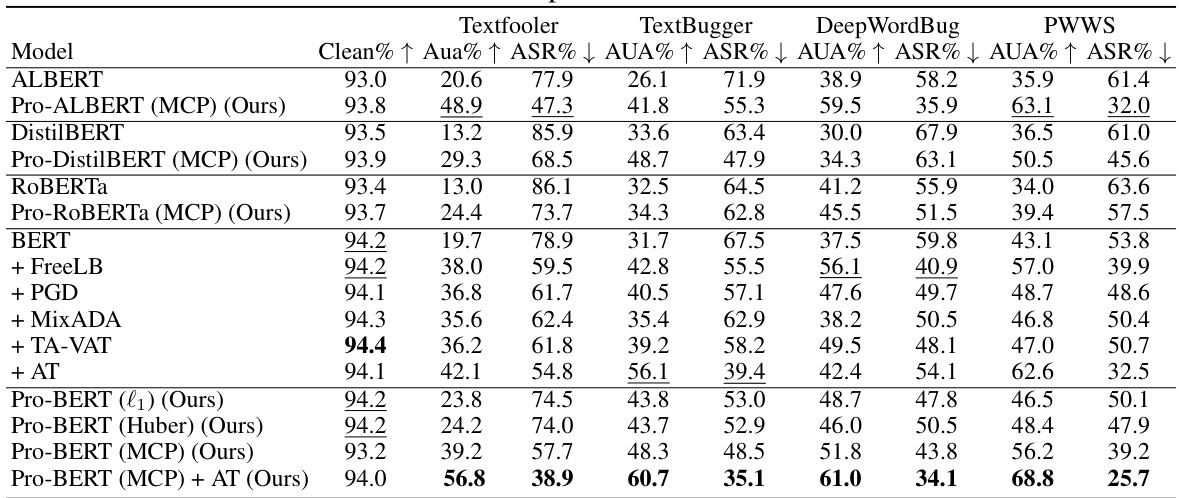
🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and Pro-BERT with various loss functions and combined with Adversarial Training) across four different attack methods (TextFooler, TextBugger, DeepWordBug, PWWS). For each model and attack, the table shows the clean accuracy (Clean%), the accuracy under attack (AUA%), and the attack success rate (ASR%). The results highlight the effectiveness of the proposed ProTransformer in improving the robustness of various transformer models against different attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models under various text-based adversarial attacks (TextFooler, TextBugger, DeepWordBug, PWWS) and defense methods. The table shows the clean accuracy, accuracy under attack (AUA%), attack success rate (ASR%), and the number of queries for each model. The results highlight the effectiveness of the proposed ProTransformer in improving robustness against these attacks, especially when combined with adversarial training.
read the caption
Table 1: The results of topic classification on AGNEWS.
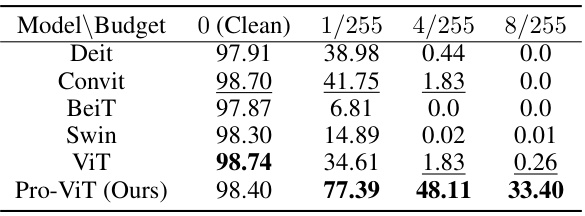
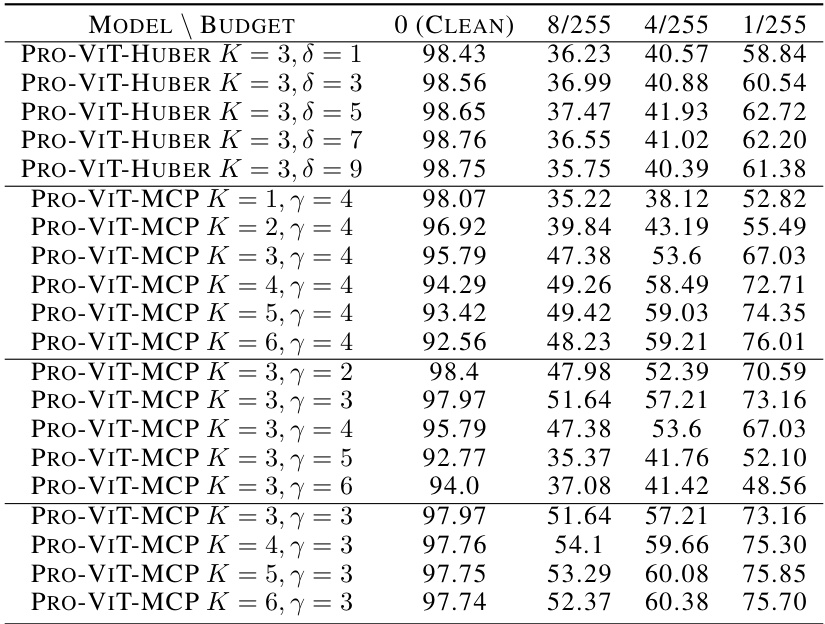
🔼 This table shows the adversarial robustness of various vision transformer models (DeiT, ConViT, BeiT, Swin, ViT) and the proposed Pro-ViT model under the Projected Gradient Descent (PGD) attack. The results are presented as the accuracy under attack (%) at different perturbation budgets (1/255, 4/255, 8/255). The clean accuracy is also included as a baseline.
read the caption
Table 3: Adversarial robustness under PGD.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), ROBERTa, Pro-ROBERTa (MCP), BERT, and several defense baselines (FreeLB, PGD, MixADA, TA-VAT, AT, Pro-BERT (l1), Pro-BERT (Huber), and Pro-BERT (MCP), Pro-BERT (MCP) + AT)) under various classic text-based attacks (TextFooler, TextBugger, DeepWordBug, and PWWS). The metrics used for evaluation include Clean Accuracy, Accuracy under Attack (AUA), and Attack Success Rate (ASR). The table showcases the improvement in robustness achieved by the proposed ProTransformer (Pro- versions of the models) compared to standard models and existing defense methods.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted using the AGNEWS dataset. It compares the performance of various models, including ALBERT, DistilBERT, RoBERTa, and BERT, both with and without the ProTransformer (using different penalty functions). It also compares these models to several baseline defense methods, such as FreeLB, PGD, MixADA, TA-VAT, and Adversarial Training (AT). The performance is measured under various text attack methods: TextFooler, TextBugger, DeepWordBug, and PWWS. The metrics displayed for each model and attack include clean accuracy, accuracy under attack, and attack success rate. This allows for a comprehensive comparison of the robustness of different models and defense strategies.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments using the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, BERT + FreeLB, BERT + PGD, BERT + MixADA, BERT + TA-VAT, BERT + AT, Pro-BERT (l1), Pro-BERT (Huber), Pro-BERT (MCP), and Pro-BERT (MCP) + AT) under various classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The metrics used are Clean Accuracy (Clean%), Accuracy under Attack (AUA%), and Attack Success Rate (ASR%). The results showcase the effectiveness of the proposed ProTransformer in improving the robustness of transformer models.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments performed on the AGNEWS dataset. It compares the performance of various models (ALBERT, Pro-ALBERT, DistilBERT, Pro-DistilBERT, RoBERTa, Pro-RoBERTa, BERT, and Pro-BERT) under different classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The table also includes results for several defense baselines (FreeLB, PGD, MixADA, TA-VAT, AT) and shows the clean accuracy for each model. The metrics used are clean accuracy, accuracy under attack (AUA), and attack success rate (ASR). The goal is to demonstrate the effectiveness of the proposed ProTransformer in improving the robustness of transformer-based models against adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification on the AGNEWS dataset. It compares the performance of several models (ALBERT, DistilBERT, RoBERTa, and BERT) with and without the proposed ProTransformer, under various classic text attacks (TextFooler, TextBugger, DeepWordBug, and PWWS). The table shows clean accuracy, accuracy under attack, and attack success rate for each model and attack, allowing for a comprehensive comparison of the robustness improvements achieved by ProTransformer.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments using the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and Pro-BERT (MCP)) under various classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The results show the clean accuracy (Clean%), accuracy under attack (AUA%), and attack success rate (ASR%). It also includes results for several defense baselines (FreeLB, PGD, MixADA, TA-VAT, AT, Pro-BERT (l1), Pro-BERT (Huber)) for comparison. The table demonstrates the effectiveness of the proposed ProTransformer (using the MCP penalty) in improving the robustness of different transformer models.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and various defense methods (FreeLB, PGD, MixADA, TA-VAT, AT) against several text attack methods (TextFooler, TextBugger, DeepWordBug, PWWS). The metrics used are clean accuracy, accuracy under attack, and attack success rate.
read the caption
Table 1: The results of topic classification on AGNEWS.
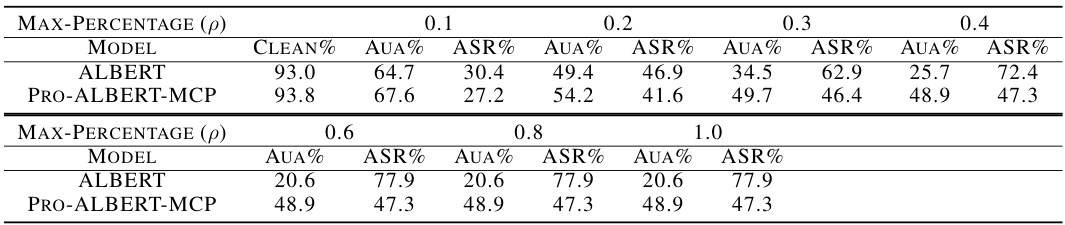
🔼 This table presents the results of topic classification on the AGNEWS dataset. It compares the performance of several models (ALBERT, DistilBERT, RoBERTa, and BERT) with and without the proposed ProTransformer under various text-based adversarial attacks (TextFooler, TextBugger, DeepWordBug, and PWWS). It also includes the performance of several existing defense methods for comparison.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models (ALBERT, DistilBERT, RoBERTa, BERT) against various text-based adversarial attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The table also shows the performance of the proposed ProTransformer method and several defense baselines (FreeLB, PGD-Adv, MixADA, TA-VAT, Adversarial Training) to highlight the effectiveness of ProTransformer in improving model robustness against adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models, including the baseline ALBERT, DistilBERT, RoBERTa, and BERT models, and their corresponding ProTransformer versions enhanced with the MCP penalty. The models’ performance is evaluated under various text-based attacks (TextFooler, TextBugger, DeepWordBug, PWWS) and defense baselines (FreeLB, PGD, MixADA, TA-VAT, Adversarial Training). The metrics used are Clean accuracy (Clean%), Accuracy under Attack (AUA%), and Attack Success Rate (ASR%). This allows for a comprehensive comparison of the proposed ProTransformer’s robustness against different attacks and in comparison to other defense mechanisms.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification on the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), ROBERTA, Pro-ROBERTa (MCP), BERT, and several defense baselines (FreeLB, PGD, MixADA, TA-VAT, AT)) under different text-based adversarial attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The metrics shown are clean accuracy, accuracy under attack (AUA), and attack success rate (ASR). It demonstrates the effectiveness of ProTransformer (MCP) in enhancing the robustness of transformer models against these attacks, showing improvements in AUA and reductions in ASR compared to baselines, both independently and when combined with adversarial training.
read the caption
Table 1: The results of topic classification on AGNEWS.
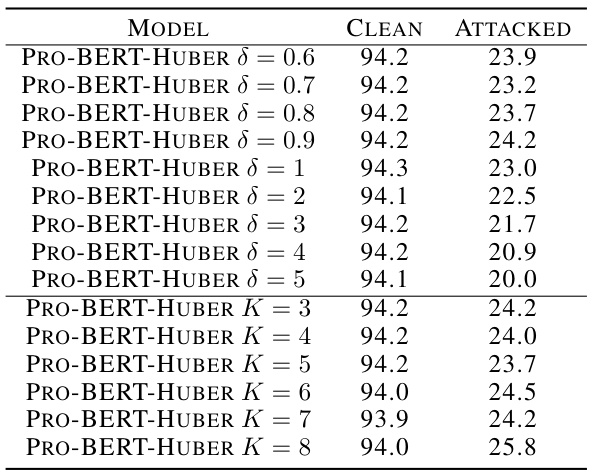
🔼 This table presents the results of topic classification experiments using the AGNEWS dataset. It compares the performance of several models, including vanilla transformers (ALBERT, DistilBERT, RoBERTa, BERT) and their ProTransformer counterparts, under various classic text attacks. The performance metrics include clean accuracy, accuracy under attack, and attack success rate. The table also provides a comparison with several existing defense methods (FreeLB, PGD, MixADA, TA-VAT, and AT). This allows for a comprehensive evaluation of ProTransformer’s robustness and effectiveness against adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted using the AGNEWS dataset. It compares the performance (clean accuracy, accuracy under attack, and attack success rate) of several models, including ALBERT, DistilBERT, RoBERTa, and BERT, both with and without the ProTransformer (with MCP penalty). It also includes results from several baseline defense methods: FreeLB, PGD, MixADA, TA-VAT, and Adversarial Training (AT). The goal is to demonstrate the effectiveness and generalizability of ProTransformer in enhancing the robustness of different transformer architectures against various adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of a topic classification experiment using the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and Pro-BERT (with various loss functions and including adversarial training)) under various classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The table shows the clean accuracy, accuracy under attack, and attack success rate for each model and attack method, demonstrating the effectiveness of the proposed ProTransformer in improving model robustness.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification on the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and Pro-BERT (with various penalty functions) under different text attack methods (TextFooler, TextBugger, DeepWordBug, PWWS). The metrics used are clean accuracy, accuracy under attack, and attack success rate. It allows for a comparison of the vanilla transformer models against ProTransformer models and various other defense baselines.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification on the AGNEWS dataset using various models and attack methods. It compares the clean accuracy, accuracy under attack (AUA), and attack success rate (ASR) for different models, including ALBERT, DistilBERT, RoBERTa, BERT, and their ProTransformer counterparts using MCP and Huber losses. Several defense baselines like FreeLB, PGD, MixADA, TA-VAT, and AT are included for comparison, allowing for a comprehensive assessment of the ProTransformer’s effectiveness.
read the caption
Table 1: The results of topic classification on AGNEWS.
🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several transformer models (ALBERT, DistilBERT, RoBERTa, and BERT) with and without the ProTransformer enhancement. The comparison is made across four different types of classic text attacks (TextFooler, TextBugger, DeepWordBug, and PWWS). For each model and attack, the table shows the clean accuracy (Clean%), accuracy under attack (AUA%), and attack success rate (ASR%). Several defense baselines (FreeLB, PGD, MixADA, TA-VAT, and Adversarial Training) are also included for comparison.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models, including the proposed ProTransformer, under various classic text-based adversarial attacks (TextFooler, TextBugger, DeepWordBug, PWWS). The table shows the clean accuracy, accuracy under attack, and attack success rate for each model and attack. It also includes results for several defense baselines for comparison.
read the caption
Table 1: The results of topic classification on AGNEWS.
🔼 This table presents the results of topic classification experiments conducted on the AG’s News dataset. The performance of several models (ALBERT, DistilBERT, RoBERTa, BERT) is evaluated under various classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). For each model and attack, the clean accuracy, accuracy under attack (AUA%), and attack success rate (ASR%) are reported. Additionally, the performance of several defense baselines (FreeLB, PGD-Adv, MixADA, TA-VAT, Adversarial Training) are provided for comparison, along with the proposed ProTransformer using different penalties (L1, Huber, MCP).
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification on the AGNEWS dataset using different models and attack methods. It compares the performance of several models (ALBERT, DistilBERT, RoBERTa, BERT) against various text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). It also shows the performance improvement achieved by the proposed ProTransformer, with and without additional adversarial training, and compares it to several existing defense methods (FreeLB, PGD, MixADA, TA-VAT, AT). The metrics used are Clean Accuracy (Clean%), Accuracy Under Attack (AUA%), and Attack Success Rate (ASR%).
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments using the AGNEWS dataset. It compares the performance of several models (ALBERT, DistilBERT, RoBERTa, BERT) against various classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). For each model and attack, the table shows the clean accuracy (Clean%), accuracy under attack (AUA%), and attack success rate (ASR%). It also includes results from several defense baselines (FreeLB, PGD, MixADA, TA-VAT, AT) and ProTransformer models, illustrating the improvements in robustness achieved by the proposed ProTransformer.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models: ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), RoBERTa, Pro-RoBERTa (MCP), BERT, and Pro-BERT (with different penalty functions and with/without adversarial training). The performance is evaluated under different classic text attacks (TextFooler, TextBugger, DeepWordBug, PWWS). For each model and attack, the clean accuracy (Clean%), accuracy under attack (AUA%), and attack success rate (ASR%) are reported. This allows for a comparison of the baseline model’s robustness versus the improvements achieved by the proposed ProTransformer with different configurations.
read the caption
Table 1: The results of topic classification on AGNEWS.
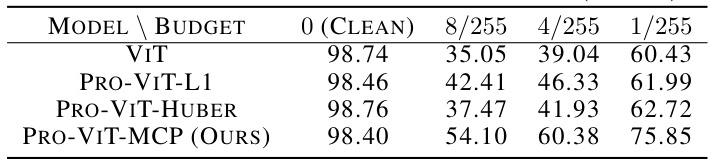
🔼 This table presents the results of adversarial robustness experiments conducted on various vision transformers (ViT, BeiT, ConViT, DeiT, and Swin) using the Projected Gradient Descent (PGD) attack method on the CIFAR-10 dataset. The table shows the clean accuracy (0 budget) and the accuracy under attack at different perturbation budgets (1/255, 4/255, 8/255). The performance of Pro-ViT (the proposed method) is compared against the baseline models, demonstrating its improved robustness against adversarial attacks.
read the caption
Table 3: Adversarial robustness under PGD.

🔼 This table presents the results of adversarial robustness experiments under the Projected Gradient Descent (PGD) attack. The experiments were conducted on the CIFAR-10 dataset using several vision transformer models: ViT, DeiT, ConViT, BeiT, and Swin. The table shows the clean accuracy and the accuracy under attack for different perturbation budgets (1/255, 4/255, 8/255). The results demonstrate the effectiveness of Pro-ViT in improving the robustness of the vision transformer models against adversarial attacks.
read the caption
Table 3: Adversarial robustness under PGD.

🔼 This table presents the results of a topic classification experiment using the AGNEWS dataset. It compares the performance of several models (ALBERT, Pro-ALBERT (MCP), DistilBERT, Pro-DistilBERT (MCP), ROBERTa, Pro-ROBERTa (MCP), BERT, and Pro-BERT with different loss functions and combined with adversarial training) under four different classic text attack methods (TextFooler, TextBugger, DeepWordBug, PWWS). The metrics presented are Clean Accuracy (Clean%), Accuracy Under Attack (AUA%), and Attack Success Rate (ASR%). The results highlight how ProTransformer consistently enhances robustness compared to the base models and other defense methods.
read the caption
Table 1: The results of topic classification on AGNEWS.
🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset. It compares the performance of several models, including ALBERT, DistilBERT, RoBERTa, and BERT, both with and without the ProTransformer (using different penalty functions). The table shows clean accuracy, accuracy under attack, and attack success rate (ASR) across four different classic text attacks: TextFooler, TextBugger, DeepWordBug, and PWWS. It also includes results for several defense baselines for comparison. The results demonstrate the effectiveness of ProTransformer in improving the robustness of different transformer architectures under various text attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.

🔼 This table presents the results of topic classification experiments using the AGNEWS dataset. It compares the performance of several models, including ALBERT, DistilBERT, RoBERTa, and BERT, both with and without the proposed ProTransformer. The results are shown for different attack methods (TextFooler, TextBugger, DeepWordBug, PWWS), indicating the clean accuracy, accuracy under attack (AUA), and attack success rate (ASR). It also includes the results of other defense methods for comparison.
read the caption
Table 1: The results of topic classification on AGNEWS.
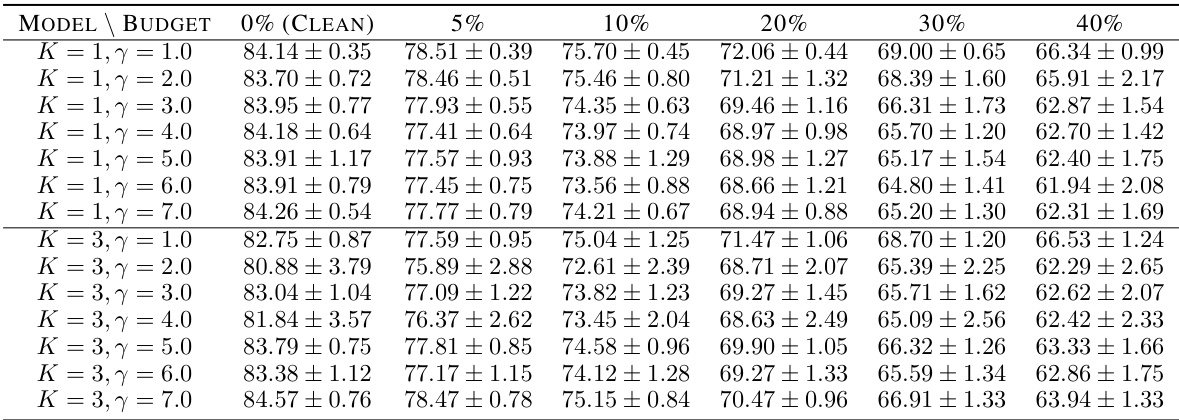
🔼 This table presents the results of topic classification experiments conducted on the AGNEWS dataset using various models. It compares the performance of the proposed ProTransformer method against several baseline methods across different attack scenarios (TextFooler, TextBugger, DeepWordBug, PWWS). The table shows the clean accuracy, accuracy under attack, and attack success rate for each model and attack. This allows for a comparison of the robustness of different models and the effectiveness of the proposed ProTransformer in improving model resilience to adversarial attacks.
read the caption
Table 1: The results of topic classification on AGNEWS.
Full paper#