TL;DR#
Current LLM agents often lack a unified framework integrating crucial components like memory, tools, and expert consultation, resulting in suboptimal performance on complex tasks. Existing benchmarks also fail to comprehensively evaluate these integrated capabilities.
The AGILE framework addresses these issues by unifying these components within a reinforcement learning paradigm. Experiments demonstrate significant performance improvements over state-of-the-art models on various question-answering benchmarks, highlighting the importance of the integrated components. The introduction of a new benchmark, ProductQA, further enhances the evaluation of LLM agent capabilities. AGILE’s end-to-end training methodology and superior performance make it a significant advancement in the field.
Key Takeaways#
Why does it matter?#
This paper is highly important because it introduces a novel framework for LLM agents, addresses limitations of existing benchmarks, and proposes a new challenging dataset. It also offers a comprehensive evaluation of this framework using multiple datasets and baselines and presents a detailed analysis of the framework’s components and training methods. These contributions are highly relevant to current research trends and can open up several avenues for future investigation, especially in areas like reinforcement learning, LLM applications, and question-answering systems.
Visual Insights#

🔼 This figure illustrates the architecture of the AGILE agent system, which comprises four main modules: Large Language Model (LLM), Memory, Tools, and Executor. The LLM acts as the policy model, generating actions (tokens) that are interpreted and executed by the Executor. The Executor interacts with the environment (including user and expert), Memory and Tools to execute the agent’s actions and manage the system state. The (b) part shows a running example in a customer service scenario, showcasing how the different modules interact in a question-answering context. The agent uses memory, consults an expert, and updates its knowledge base through reflection and updates to memory.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This table lists the functions used by the customer service QA agent. Each function is designed to execute a set of operations, including memory I/O, tool usage, and interaction with the environment. The functions are invoked by the LLM agent by predicting their names. The executor then interprets these instructions to activate the corresponding modules. The table shows the function name and implementation details for a total of nine functions.
read the caption
Table 1: Functions for an exemplary customer service QA agent. Among them, [Reflection] and [PredictAnswer] are trivial functions, as the executor passes control immediately back to the LLM to start generating result tokens.
In-depth insights#
LLM Agent Framework#
The LLM Agent Framework section of this research paper likely details the architecture and methodology for creating and training large language model (LLM) agents. It likely emphasizes the integration of multiple components, such as LLMs, memory modules, tool usage, and human-expert interaction, to enable the agents to perform complex tasks. The framework probably proposes a structured approach for the agent’s decision-making process, possibly using a reinforcement learning (RL) paradigm to optimize agent behavior. Key aspects may include the design of state and action spaces within an RL framework, the reward function for guiding learning, and an evaluation methodology for assessing the agent’s performance. The paper likely also explores various training techniques and the benefits of incorporating human feedback into the training process, potentially improving the agent’s accuracy and adaptability. The discussion may also involve a comparison between agents trained using different RL algorithms, highlighting the strengths and weaknesses of each approach. Overall, the framework’s design is likely aimed at creating more sophisticated and capable LLM agents with enhanced reasoning capabilities compared to traditional LLMs used in isolation.
RL in LLM Agents#
Reinforcement learning (RL) offers a powerful paradigm for training large language models (LLMs) to act as agents. Directly optimizing LLM parameters via RL is challenging due to the high dimensionality of the parameter space and the computational cost. However, recent work explores various techniques, such as reward shaping and proximal policy optimization (PPO), to make RL training of LLMs more tractable. The key is to define a clear reward function that guides the LLM towards desirable behaviors in its interactions with the environment. Careful consideration of the reward function is critical, as poorly designed rewards can lead to unintended and undesirable agent behavior. Memory and tools significantly enhance RL-trained LLM agents, enabling more complex and sophisticated actions. The inclusion of memory allows agents to learn from past experiences, while tools provide access to external resources and capabilities that extend the agent’s inherent knowledge. The integration of these elements forms a robust framework for training powerful and effective LLM agents. Combining RL with other methods, like supervised fine-tuning, provides a hybrid approach that can leverage the strengths of both techniques. Research continues to push the boundaries of applying RL to LLMs, exploring novel architectures and training strategies for increasingly complex and nuanced agent behaviors. This area is at the forefront of AI, with the potential to unlock significant advancements in robotics, natural language processing, and decision-making.
ProductQA Dataset#
The ProductQA dataset is a novel benchmark designed for a comprehensive evaluation of LLM agents, specifically focusing on complex question-answering tasks within the context of online shopping. Its key strength lies in its realism, drawing from real Amazon user queries and encompassing diverse question types including fact-based, reasoning, and recommendation queries. Unlike existing datasets which focus on specific subsets of capabilities, ProductQA challenges agents to simultaneously utilize various components such as memory, tools (e.g., product search), reflection, and the ability to seek advice from human experts. This holistic approach allows for a nuanced assessment of the agent’s overall performance, going beyond a simple accuracy metric to capture its adaptability and resourcefulness. The dataset’s design, including a clear split between training and testing datasets, is carefully structured to evaluate generalization capabilities. By offering a more holistic and realistic evaluation, ProductQA helps to advance the field by pushing the boundaries of what is expected of LLM agents and fostering the development of more robust and versatile models.
Ablation Study#
An ablation study systematically removes individual components or features of a model or system to assess their relative contribution to the overall performance. In the context of a research paper on Large Language Models (LLMs), an ablation study might involve removing or disabling functionalities like memory access, tool usage, reflection capabilities, or the ability to consult external experts. By observing the performance drop associated with each removal, researchers can quantify the importance of each component and highlight crucial elements for the strong performance of their LLM agent. For example, a significant decline in accuracy after removing the memory module indicates a crucial role of memory in the agent’s decision-making process. This method is crucial for understanding the design choices, and for providing evidence supporting claims about the system’s architecture and effectiveness. The results of an ablation study should demonstrate the indispensability of key features, offering valuable insights into future research directions and improvements.
Future Work#
The authors outline several promising avenues for future research. Expanding AGILE to larger LLMs is a key priority, anticipating significant performance gains, especially in complex reasoning and planning tasks. Improving the ProductQA dataset is also highlighted, suggesting the need for a more diverse set of product categories and a larger number of QA pairs. This would enhance the robustness and generalizability of AGILE agents and potentially reveal further insights into the capabilities of LLM agents in real-world applications. Furthermore, exploring additional tool integration is considered vital, especially for incorporating multimodal capabilities, which could significantly expand the agent’s problem-solving skills and extend to physical interactions. Finally, delving deeper into the interplay between RL training and human feedback promises further improvements, potentially enabling more efficient and accurate knowledge acquisition and refinement in the agent’s learning process. Addressing these areas of future work would likely lead to more sophisticated and capable LLM agents.
More visual insights#
More on figures

🔼 This figure shows the accuracy and advice rate of different agents over 200 sessions. The seeking advice cost (c) is set to 0.3. It demonstrates the trend of the advice rate decreasing over time, indicating the agent’s learning and increasing independence. The accuracy of agile-vic13b-ppo consistently outperforms other agents.
read the caption
Figure 2: Accuracy and advice rate over the following 200 sessions (c = 0.3).

🔼 This figure shows the relationship between the seeking advice cost (c) and the resulting advice rate and accuracy on the ProductQA dataset. As the cost (c) decreases, both the advice rate and accuracy increase. This indicates that when the cost of seeking advice is lower, the agent is more likely to seek advice and, consequently, achieve higher accuracy. The figure visually demonstrates the trade-off between the cost of seeking advice and the accuracy achieved.
read the caption
Figure 3: Advice rate, accuracy along with seeking advice cost c on ProductQA.

🔼 This figure displays the trend of advice rate over sessions in the ProductQA experiment, with a seeking advice cost (c) set to 0.3. It shows a consistent decrease in the advice rate of the agile-vic13b-ppo agent as more sessions are added to the trajectory. This is because the agent progressively accumulates knowledge and becomes more independent. The figure also shows that disabling reinforcement learning (RL) training or reflection leads to a significant increase in the advice rate, highlighting the importance of these components for reducing human costs.
read the caption
Figure 4: Advice rate over the following 200 sessions on ProductQA (c = 0.3).

🔼 This figure shows two curves plotting the reward and value function loss during the Proximal Policy Optimization (PPO) training process on the ProductQA dataset. The reward curve generally increases over the training steps, indicating that the agent’s performance is improving. The value function loss curve initially decreases significantly, implying that the value function is being learned effectively, and then plateaus, suggesting convergence. Both trends suggest that the PPO training is successful in optimizing the agent’s policy.
read the caption
Figure 5: Reward and value function loss curves during the PPO training process on ProductQA.

🔼 This figure shows the architecture of the AGILE agent system, which consists of four main modules: the Large Language Model (LLM), memory, tools, and an executor. The LLM is responsible for generating actions (tokens) based on the context, which includes information from memory and tools. The executor interacts with the environment (users or experts), retrieves information from memory and tools as instructed by the LLM, and updates the memory based on LLM’s instructions. The figure also presents a running example of the AGILE agent in a customer service question-answering scenario, illustrating the flow of information and actions within the system.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This figure shows the architecture of the AGILE agent system, which consists of four modules: Large Language Model (LLM), memory, tools, and executor. The LLM acts as the main decision-maker, generating instructions and processing responses. The executor then interprets these instructions and interacts with the memory, tools, and environment. Part (b) gives a running example of the system in a customer service question-answering scenario. The flow of information and actions is visualized, highlighting the interactions between the LLM and the executor, as well as the use of memory and external tools.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This figure shows the architecture of the AGILE agent system which consists of four modules: LLM, memory, tools, and executor. The LLM is the core component generating instructions and processing responses. The executor interprets the instructions and activates the corresponding modules. Memory stores and retrieves information. Tools perform actions like searching. The (b) part shows a running example of the system in a customer service QA setting, illustrating the flow of information and actions between the modules and the user.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 Figure 1(a) shows the architecture of the AGILE agent system which comprises four modules: LLM, memory, tools, and executor. The LLM is responsible for generating instructions and processing responses. The executor interprets the LLM instructions and interacts with the other modules (memory and tools) and the environment. Figure 1(b) illustrates a running example of the AGILE agent system in a customer service QA scenario, showing how the agent interacts with the user and utilizes different modules to answer questions. The tokens (actions) generated by the LLM are highlighted in orange, while the tokens appended by the executor are highlighted in blue.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This figure shows the architecture of the AGILE agent system, which consists of four main modules: LLM, memory, tools, and executor. The LLM acts as the policy model, generating actions (tokens) that are interpreted and executed by the executor. The executor interacts with the environment (e.g., user, expert, tools), retrieving information and updating memory. The running example illustrates a conversational QA scenario where the agent uses memory, tools and seeks advice from an expert to answer the user’s question.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This figure illustrates the architecture of the AGILE agent system, which consists of four key modules: the Large Language Model (LLM), memory, tools, and an executor. The LLM is the core of the system, generating instructions and processing responses. The executor orchestrates interactions between the LLM and other components, including memory and tools, as well as human experts and users. The figure also shows a running example demonstrating how the various components work together during a question-answering task in a customer service context. Orange tokens represent actions generated by the LLM, while blue tokens are those appended by the executor.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.
🔼 This figure shows the architecture of the AGILE agent system, which consists of four main modules: LLM, memory, tools, and executor. The LLM serves as the core policy model, generating actions (tokens) which are then processed by the executor to interact with the environment (including users and experts), memory, and tools. The diagram also illustrates a running example of the AGILE agent performing a customer service question-answering task, highlighting the flow of information between the modules and the use of different actions.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.

🔼 This figure shows the architecture of the AGILE agent system, which consists of four main modules: Language Model (LLM), memory, tools, and an executor. The LLM acts as the policy model, generating instructions for the executor to carry out actions such as retrieving information from memory, using tools, or interacting with users and experts. The running example illustrates a typical interaction between the AGILE agent and a user in a customer service QA scenario. The agent uses several modules and interacts with an expert to answer a question.
read the caption
Figure 1: (a) Architecture of our agent system, including LLM, memory, tools, and executor. (b) A running example of AGILE in a customer service QA environment. The tokens (actions) generated by the LLM are in orange color and the tokens appended by the executor are in blue color.
More on tables

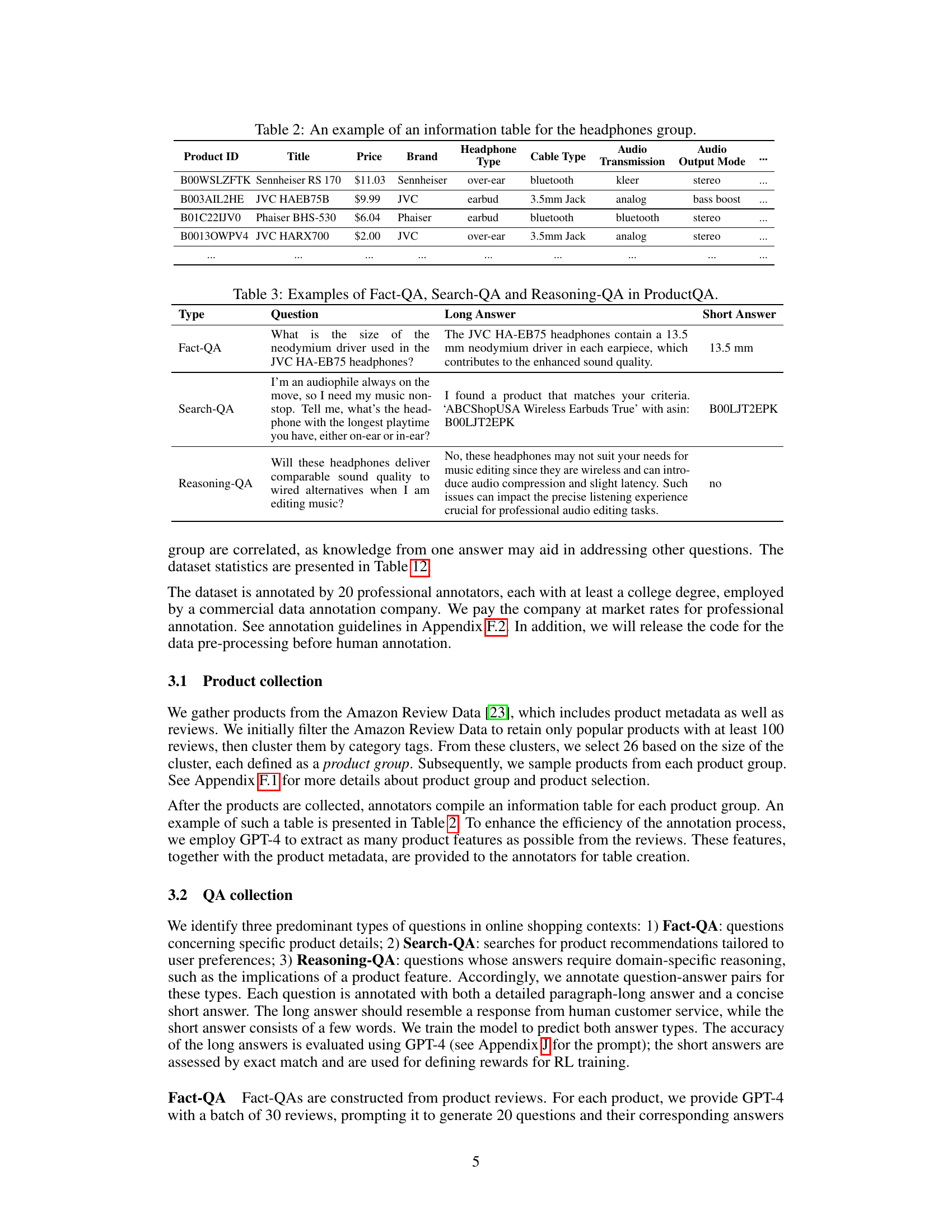
🔼 This table shows an example of the information table that is created for each product group in the ProductQA dataset. Each row represents a single product, listing its ID, title, price, brand, headphone type, cable type, audio transmission method, and audio output mode. This table demonstrates the type of structured product data used to generate questions for the ProductQA benchmark. The full table includes information for multiple products in the headphone group.
read the caption
Table 2: An example of an information table for the headphones group.

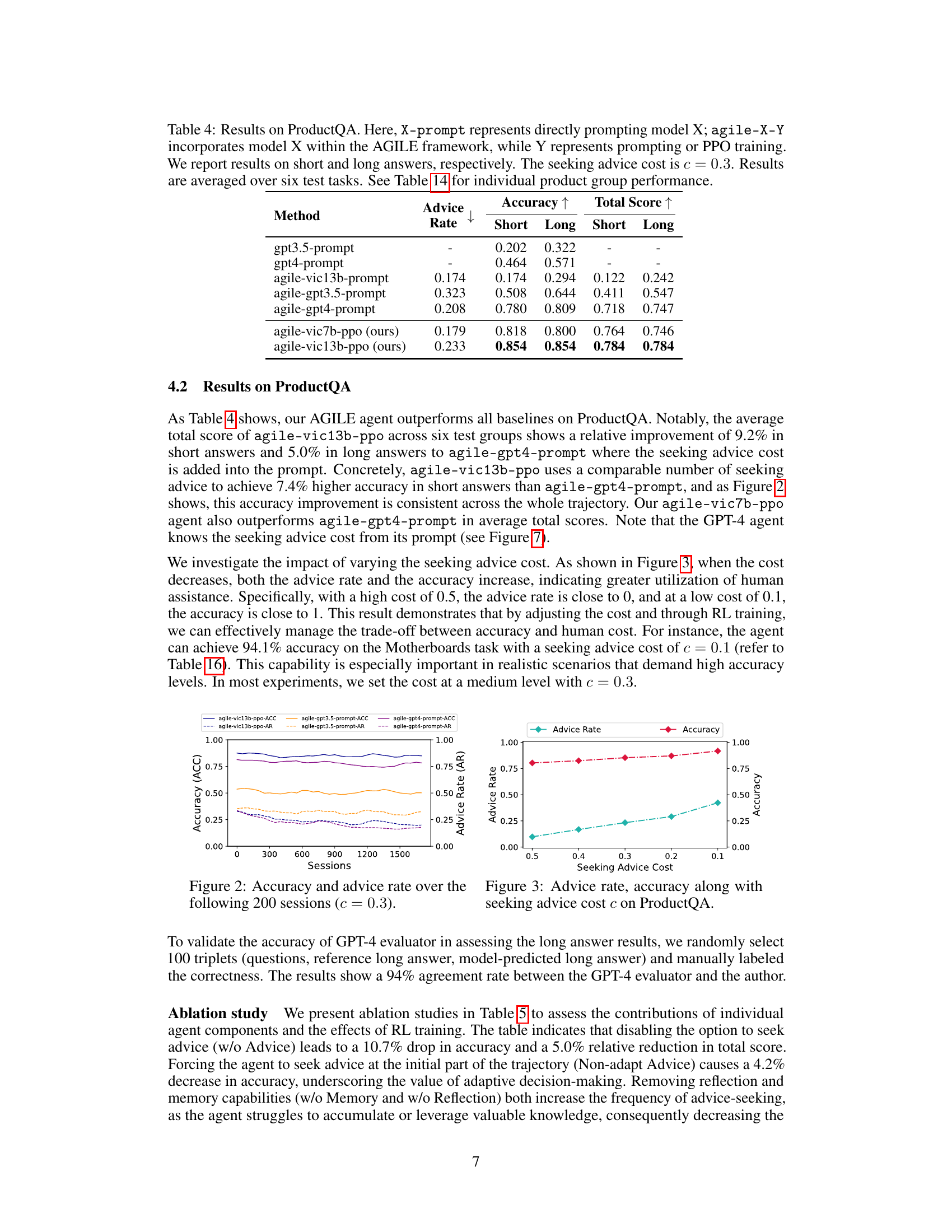
🔼 This table exemplifies the different question types included in the ProductQA dataset. Fact-QA involves straightforward factual questions about product features. Search-QA requires the agent to find suitable products based on user needs. Reasoning-QA demands more complex reasoning to answer questions, showcasing the dataset’s comprehensive evaluation of diverse LLM agent capabilities.
read the caption
Table 3: Examples of Fact-QA, Search-QA and Reasoning-QA in ProductQA.
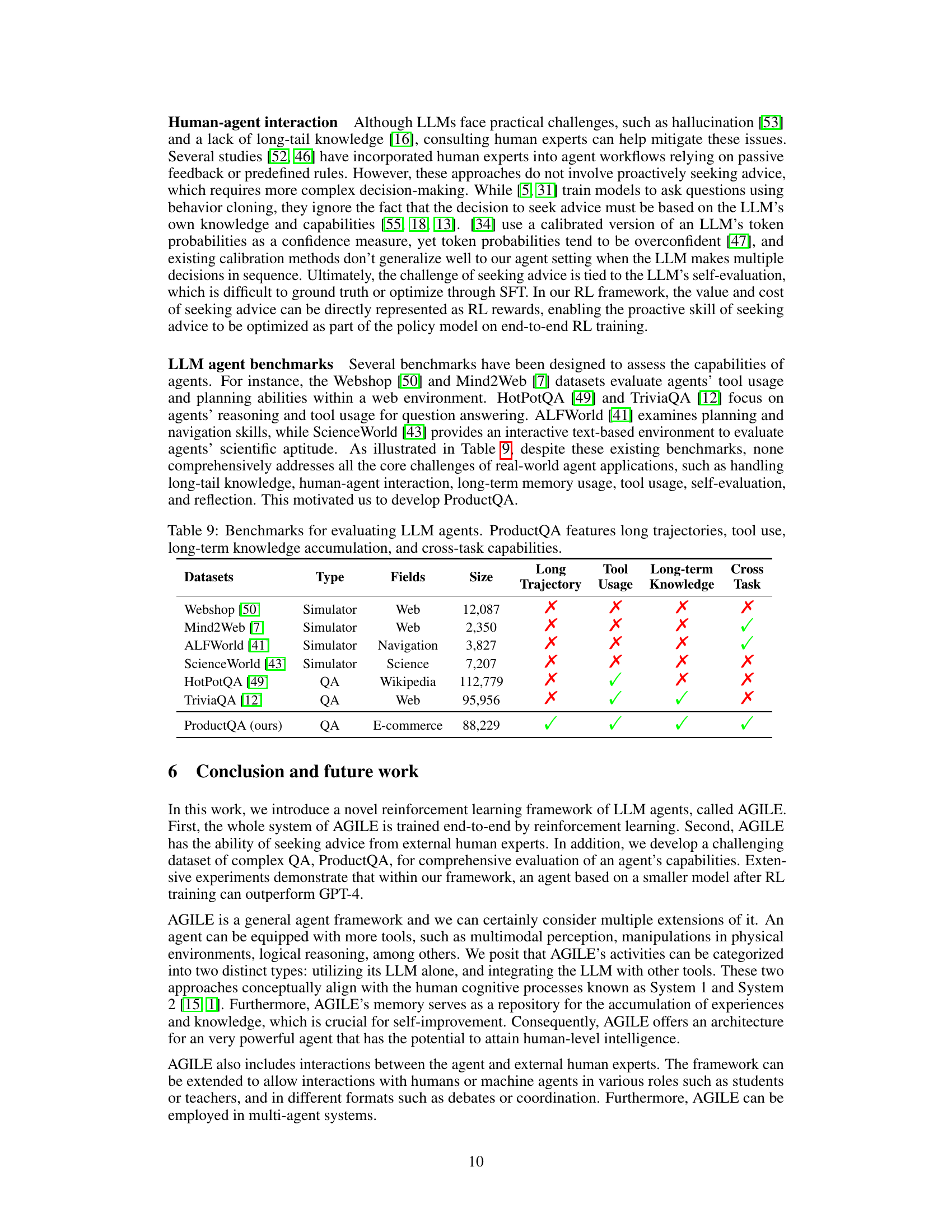
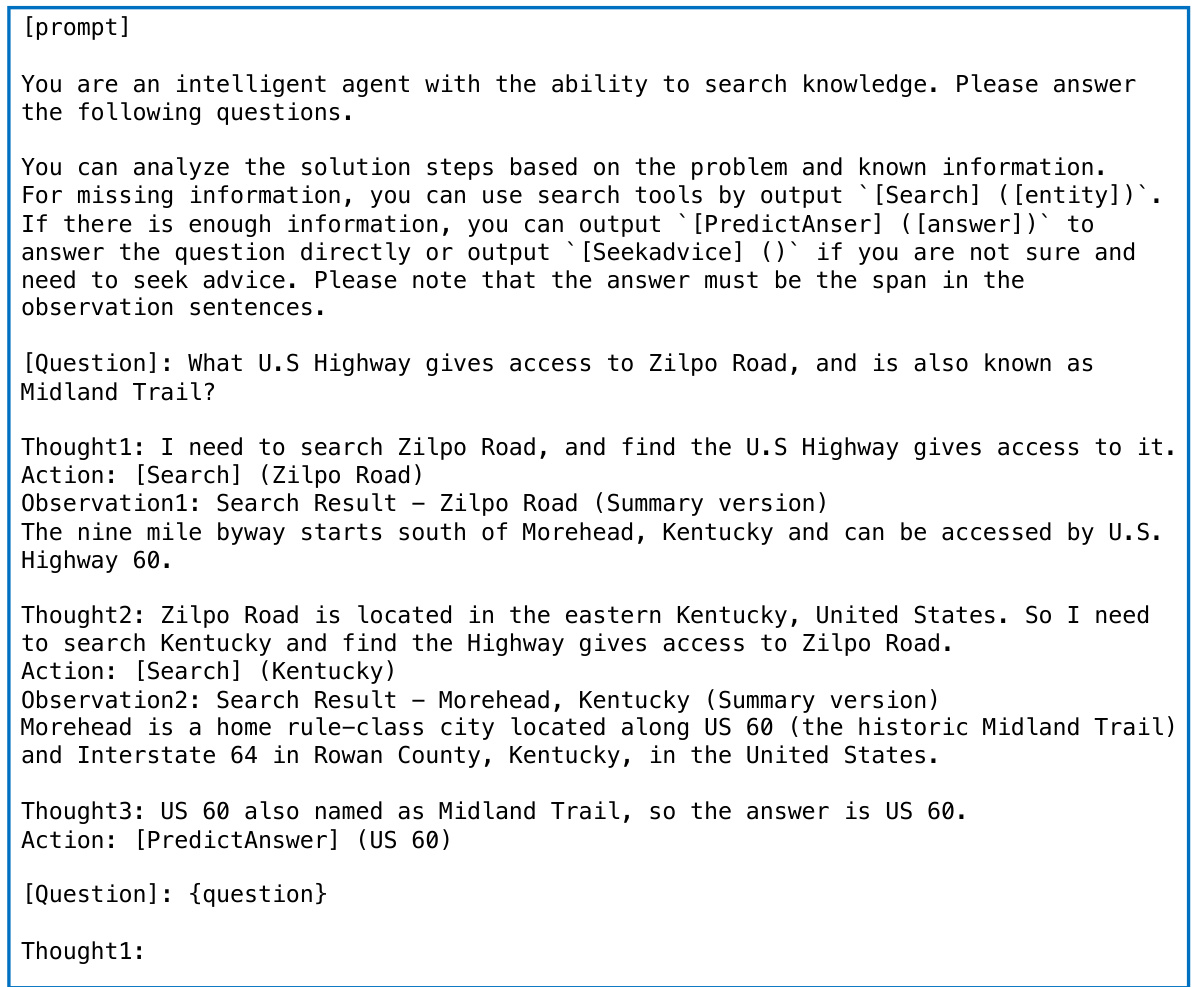
🔼 This table presents the results of experiments conducted on the ProductQA dataset. It compares the performance of several methods: directly prompting GPT-3.5 and GPT-4, and using the AGILE framework with different LLMs (Vicuna) and training methods (prompting and PPO). The table shows the advice rate, accuracy (on both short and long answers), and total score for each method. The results are averaged across six test tasks from the ProductQA dataset, and detailed results for each task are available in another table. The seeking advice cost is set to 0.3.
read the caption
Table 4: Results on ProductQA. Here, X-prompt represents directly prompting model X; agile-X-Y incorporates model X within the AGILE framework, while Y represents prompting or PPO training. We report results on short and long answers, respectively. The seeking advice cost is c = 0.3. Results are averaged over six test tasks. See Table 14 for individual product group performance.

🔼 This table presents the results of ablation studies conducted to evaluate the impact of individual components (reflection, memory, seeking advice, tool use) and RL training on the overall performance of the AGILE agent. The ’non-adapt-advice’ condition forces the agent to seek advice for a specific number of initial sessions (the same number as the full model used the advice-seeking function), testing whether adaptive advice seeking is beneficial. The results are shown as the advice rate, accuracy, and total score, highlighting the relative importance of each component.
read the caption
Table 5: Ablation studies for disabling reflection, memory, seeking advice, tool use, or RL training. Here, non-adapt-advice means that seeking advice is invoked for the first K sessions of the trajectory, where K equals to the number of [SeekAdvice] performed by agile-vic13b-ppo. See Table 15 for ablation results on individual product groups.
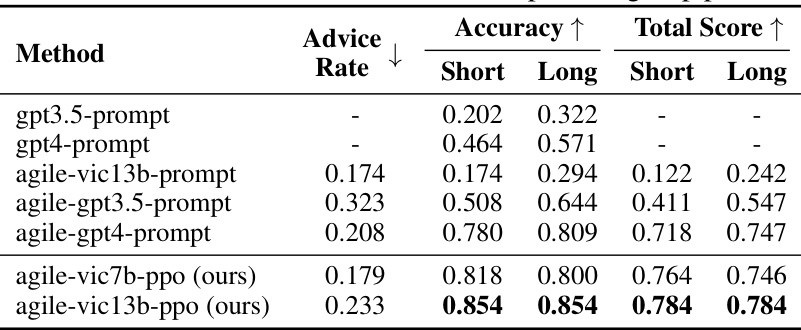
🔼 This table presents the results of the MedMCQA experiment. It compares the performance of different models, including prompting GPT-3.5 and GPT-4 directly versus incorporating them into the AGILE framework with different components (reflection, memory, seeking advice) enabled or disabled. The ‘seeking advice cost’ (c) is set to 0.4. The table shows the advice rate (percentage of times the agent sought advice), accuracy (percentage of correct answers), and total score (a combined metric of accuracy and advice cost). The table highlights the improved performance of the AGILE framework, particularly when using PPO training and all components.
read the caption
Table 6: Results on the MedMCQA dev dataset. X-prompt represents directly prompting the model X; agile-X-Y represents incorporating the model X within the AGILE framework, while Y represents prompting, ablation studies or standard PPO training. The seeking advice cost is c = 0.4.
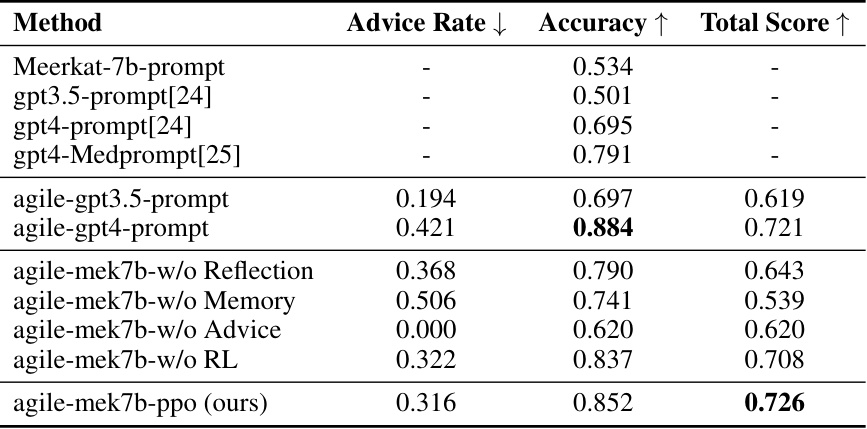
🔼 This table presents the results of the AGILE model and several baselines on the HotPotQA dataset. It compares the performance of prompting GPT-4 directly (ReAct-gpt4-prompt) and the AGILE agent using Vicuna-13B as the LLM (agile-vic13b-ppo), with and without different components (advice-seeking and RL training). The table shows advice rate, accuracy (using both exact match and GPT-4 evaluation), and the total score, demonstrating the effectiveness of the AGILE framework.
read the caption
Table 7: Results on the HotPotQA full dev dataset. X-prompt represents directly prompting the model X; agile-X-Y represents incorporating the model X within the AGILE framework, while Y represents prompting, ablation studies or standard PPO training. The seeking advice cost is c = 0.3.
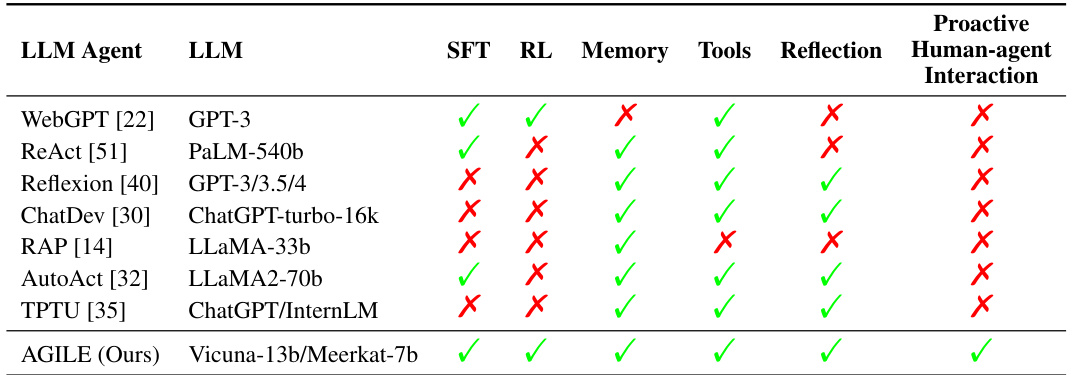
🔼 This table compares AGILE with other related works on Large Language Model (LLM) agents. It highlights key features such as the specific LLM used, whether Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) were employed, the use of memory and tools, reflection capabilities, and the presence of proactive human-agent interaction. The table shows that AGILE is unique in its end-to-end reinforcement learning approach and its incorporation of proactive human advice-seeking.
read the caption
Table 8: Related work on LLM agents. AGILE stands out as the pioneering work that trains the entire agent using reinforcement learning, incorporating proactive human advice-seeking.
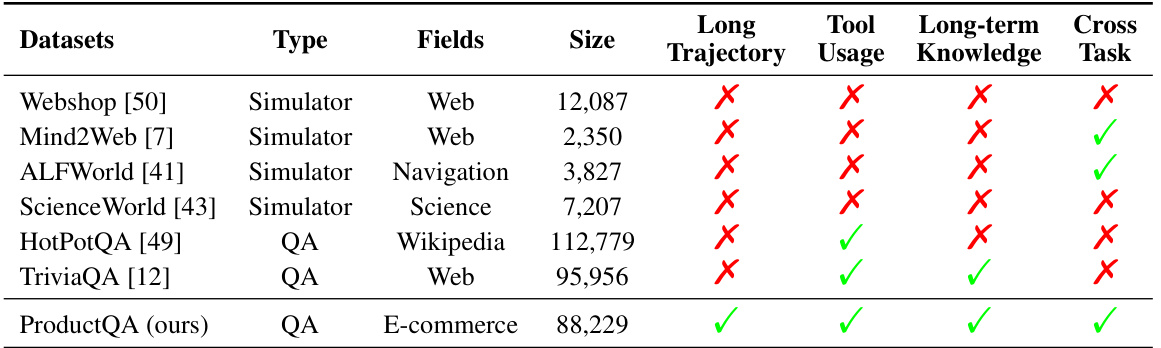
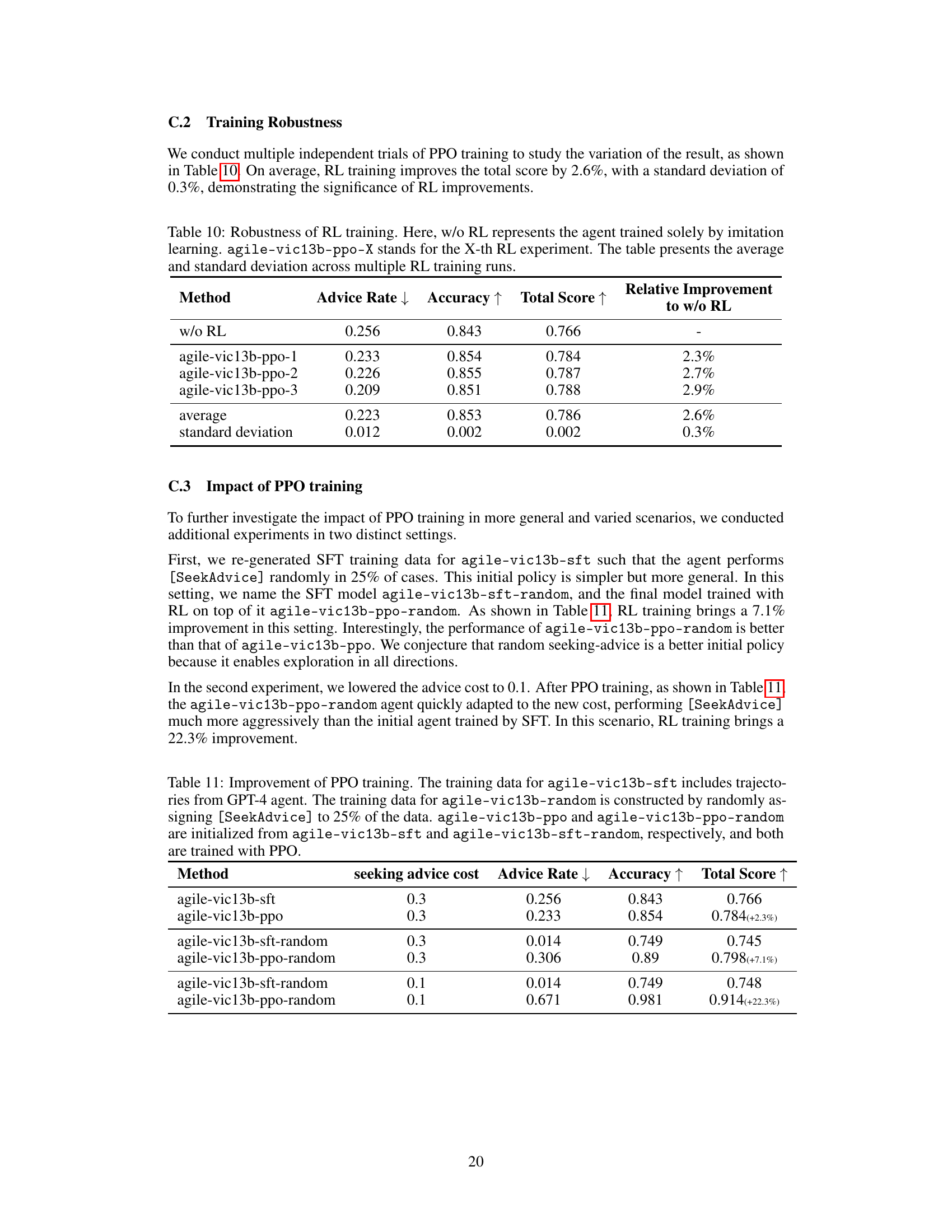
🔼 This table compares various existing benchmarks for evaluating LLM agents against the newly proposed ProductQA benchmark. It highlights the unique features of ProductQA, such as its ability to evaluate agents’ performance across long trajectories, tool usage, long-term knowledge retention, and multiple tasks. The table shows that while existing benchmarks assess some of these capabilities, none comprehensively evaluates all of them, underscoring ProductQA’s novel contributions.
read the caption
Table 9: Benchmarks for evaluating LLM agents. ProductQA features long trajectories, tool use, long-term knowledge accumulation, and cross-task capabilities.
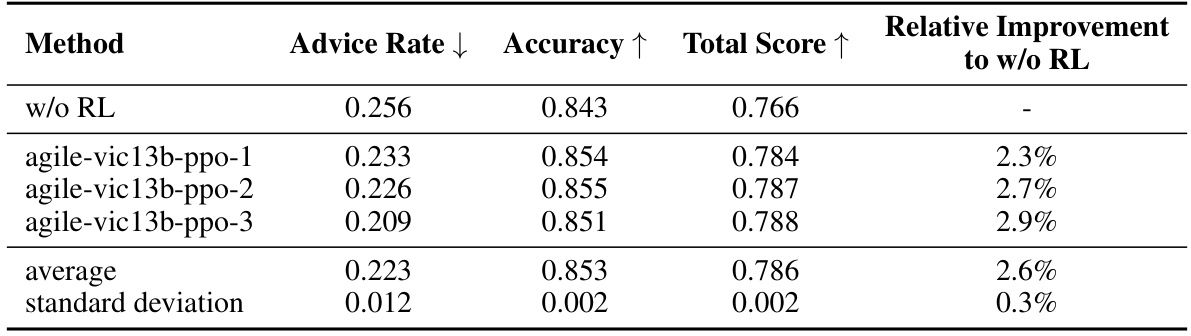
🔼 This table shows the results of multiple independent trials of Proximal Policy Optimization (PPO) training to evaluate the robustness of reinforcement learning (RL) in improving the agent’s performance. The ‘w/o RL’ row represents the agent trained only using imitation learning, serving as a baseline. The other rows show the results of three separate PPO training runs (agile-vic13b-ppo-1, -2, -3). The table reports the average advice rate, accuracy, and total score across these runs, along with the standard deviation for each metric. The final column shows the relative improvement in the total score achieved by RL compared to the imitation-learning-only baseline.
read the caption
Table 10: Robustness of RL training. Here, w/o RL represents the agent trained solely by imitation learning. agile-vic13b-ppo-X stands for the X-th RL experiment. The table presents the average and standard deviation across multiple RL training runs.
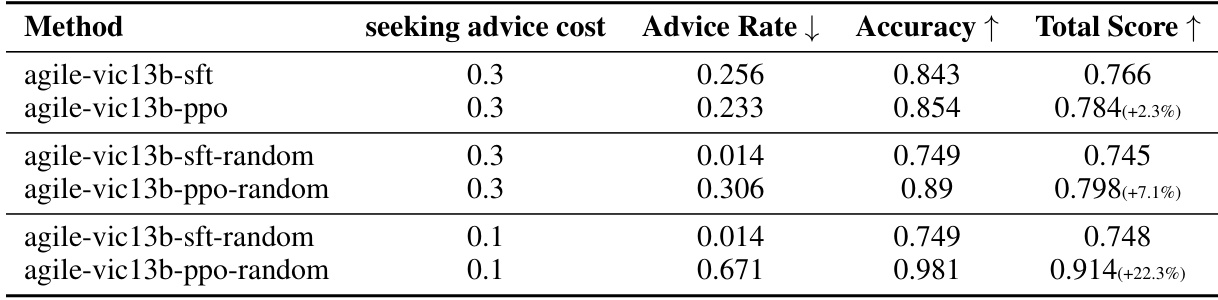
🔼 This table shows the results of experiments that investigate the impact of PPO training on the AGILE agent’s performance under different scenarios. The first two rows represent the baseline model trained with supervised fine-tuning (SFT) and then further optimized with PPO. The next two rows show results where the initial SFT training data includes a 25% random introduction of advice-seeking actions, demonstrating the model’s ability to learn in more general scenarios. The last two rows demonstrate the impact of adjusting the cost of advice-seeking, revealing the agent’s adaptive capabilities.
read the caption
Table 11: Improvement of PPO training. The training data for agile-vic13b-sft includes trajectories from GPT-4 agent. The training data for agile-vic13b-random is constructed by randomly assigning [SeekAdvice] to 25% of the data. agile-vic13b-ppo and agile-vic13b-ppo-random are initialized from agile-vic13b-sft and agile-vic13b-sft-random, respectively, and both are trained with PPO.

🔼 This table presents the statistical distribution of the ProductQA dataset. It breaks down the dataset into 26 different product categories, indicating the number of products within each category and the count of questions categorized as Fact-QA (factual questions), Search-QA (questions requiring searches), and Reasoning-QA (questions that require higher-level reasoning). This provides insights into the dataset’s composition and complexity.
read the caption
Table 12: Statistics of the ProductQA dataset. # Products indicates the number of products within each group. # Fact-QA, # Search-QA and # Reasoning-QA display the respective numbers of QA pairs categorized as Fact-QA, Search-QA, and Reasoning-QA.

🔼 This table presents the training time and computational resources used for the three tasks: ProductQA, MedMCQA, and HotPotQA. It shows the number of NVIDIA H800 GPUs used and the training time for both supervised fine-tuning (SFT) and reinforcement learning (RL) for each task. The information is valuable in understanding the computational cost and scaling aspects of the AGILE framework.
read the caption
Table 13: Training statistics for each experiment.
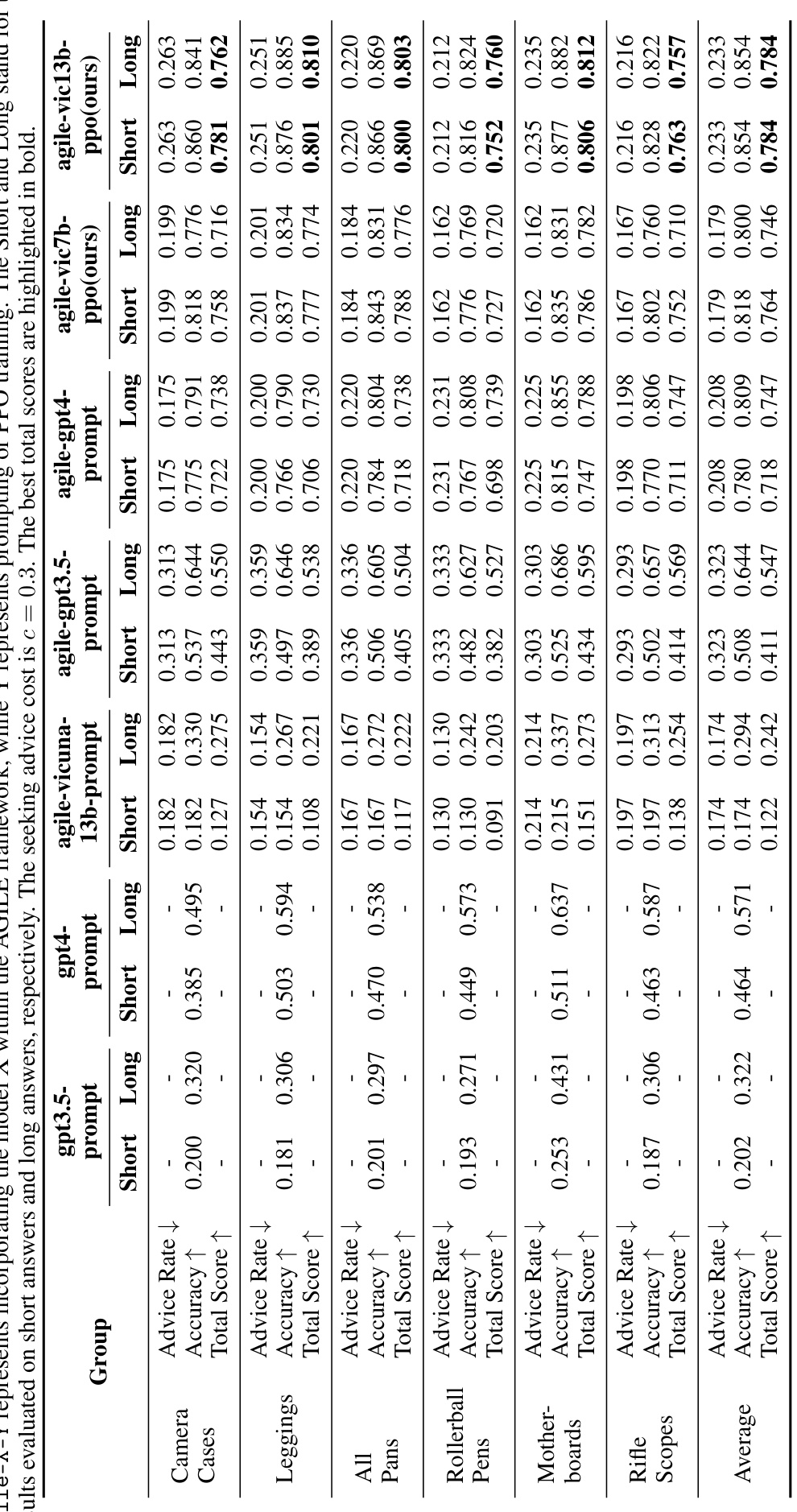
🔼 This table provides a detailed comparison of the performance of various methods (direct prompting of GPT-3.5 and GPT-4, AGILE framework with GPT-3.5 and GPT-4, and AGILE framework with Vicuna-7B and Vicuna-13B using PPO) across six product categories within the ProductQA dataset. The metrics used for comparison include advice rate, accuracy (for both short and long answers), and total score, with the best total score for each product category highlighted. The seeking advice cost was set to 0.3 for all experiments.
read the caption
Table 14: Detail performance of our methods and other baselines on six test product groups of ProductQA. X-prompt represents directly prompting the model X; agile-X-Y represents incorporating the model X within the AGILE framework, while Y represents prompting or PPO training. The Short and Long stand for the results evaluated on short answers and long answers, respectively. The seeking advice cost is c = 0.3. The best total scores are highlighted in bold.
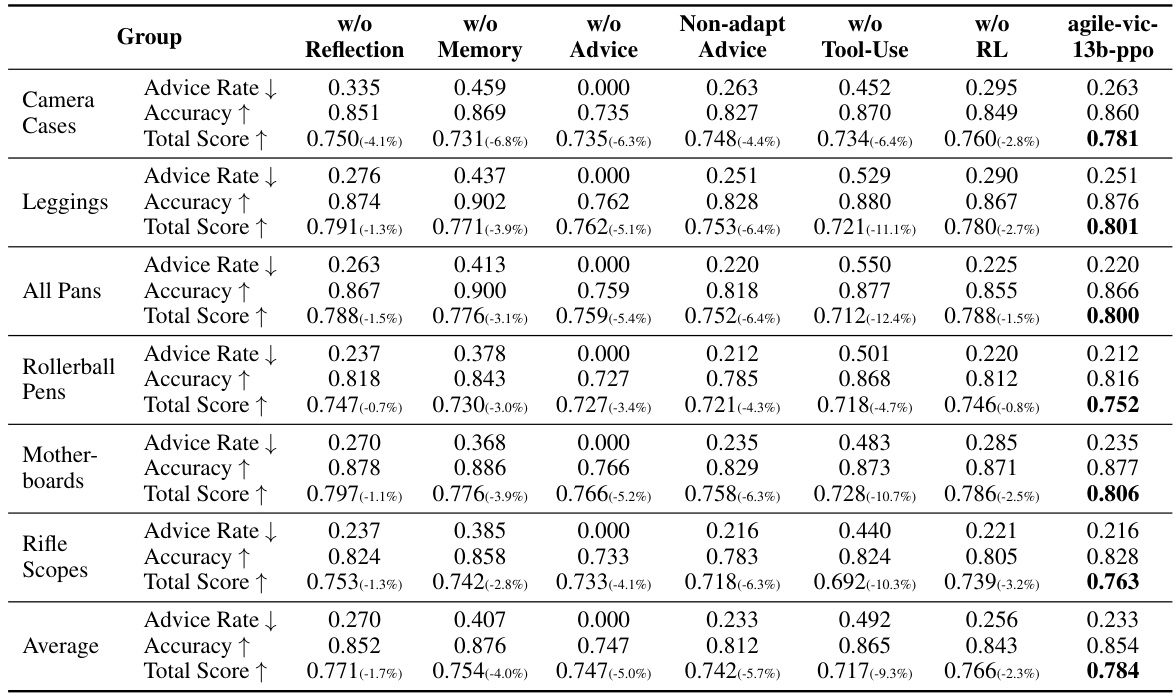
🔼 This table presents the ablation study results for the AGILE model. It shows the impact of removing individual components (reflection, memory, advice-seeking, tools, and RL training) on the model’s performance. The ‘Non-adapt advice’ row shows the results when advice-seeking is forced for only the first K sessions (where K is the number of advice-seeking actions taken by the full model). The results are given in terms of advice rate, accuracy, and total score for six product groups. The table highlights the importance of each component for achieving strong performance. Comparing the results for the full model to the ablation results shows the individual contributions of each module.
read the caption
Table 5: Ablation studies for disabling reflection, memory, seeking advice, tool use, or RL training. Here, non-adapt-advice means that seeking advice is invoked for the first K sessions of the trajectory, where K equals to the number of [SeekAdvice] performed by agile-vic13b-ppo. See Table 15 for ablation results on individual product groups.

🔼 This table shows the performance of the agile-vic13b-ppo model on ProductQA with different seeking advice costs (0.5, 0.4, 0.3, 0.2, and 0.1). For each cost, it presents the advice rate (the percentage of times the agent sought advice) and the accuracy (the percentage of correct answers). The results are broken down by product group (Camera Cases, Leggings, All Pans, Rollerball Pens, Motherboards, Rifle Scopes) and averaged across all groups.
read the caption
Table 16: Performance of the model (agile-vic13b-ppo) trained on different seeking advice cost settings.

🔼 This table presents a detailed comparison of the performance of different methods (including the proposed AGILE framework and several baselines) on six product categories from the ProductQA dataset. It shows the advice rate (percentage of times the agent sought advice), accuracy (percentage of correct answers), and the total score for both short and long answers. The comparison helps to evaluate the effectiveness of the proposed approach relative to baselines and the impact of various components (prompting, RL training, etc.).
read the caption
Table 14: Detail performance of our methods and other baselines on six test product groups of ProductQA. X-prompt represents directly prompting the model X; agile-X-Y represents incorporating the model X within the AGILE framework, while Y represents prompting or PPO training. The Short and Long stand for the results evaluated on short answers and long answers, respectively. The seeking advice cost is c = 0.3. The best total scores are highlighted in bold.

🔼 This table presents a detailed comparison of the performance of different methods (direct prompting with GPT-3.5 and GPT-4, AGILE framework with GPT-3.5 and GPT-4, and AGILE with Vicuna-7B and Vicuna-13B) across six product categories from the ProductQA dataset. It shows the advice rate, accuracy (for short and long answers), and overall total score for each method. The best total scores are highlighted to easily identify the top-performing approach within each product category.
read the caption
Table 14: Detail performance of our methods and other baselines on six test product groups of ProductQA. X-prompt represents directly prompting the model X; agile-X-Y represents incorporating the model X within the AGILE framework, while Y represents prompting or PPO training. The Short and Long stand for the results evaluated on short answers and long answers, respectively. The seeking advice cost is c = 0.3. The best total scores are highlighted in bold.

🔼 This table presents the statistical information of the ProductQA dataset. It shows the distribution of the data across different product categories, providing the number of products in each category, as well as the number of question-answer pairs that fall under Fact-QA, Search-QA, and Reasoning-QA. This breakdown helps to understand the composition and complexity of the ProductQA dataset, useful for evaluating different aspects of question-answering capabilities.
read the caption
Table 12: Statistics of the ProductQA dataset. # Products indicates the number of products within each group. # Fact-QA, # Search-QA and # Reasoning-QA display the respective numbers of QA pairs categorized as Fact-QA, Search-QA, and Reasoning-QA.
Full paper#