TL;DR#
Current contrastive vision-language models (VLMs) suffer from a significant bias due to the over-representation of English and Western-centric data in their training sets. This bias leads to poor performance on data from non-Western regions and underrepresented communities, hindering their ability to understand and respond to diverse cultural contexts. This is problematic because it undermines the fairness and inclusivity of these powerful AI systems, limiting their real-world applications.
This research paper investigates this issue systematically. The researchers used a range of benchmark datasets and evaluation metrics to demonstrate the extent of the bias. They introduce a novel metric, geo-localization, for evaluating cultural diversity. More importantly, the study reveals that pre-training VLMs with diverse, global data before fine-tuning on English data significantly improves their performance on culturally diverse benchmarks while maintaining competitive performance on standard benchmarks. This provides a practical solution to mitigate bias and build more inclusive and equitable multimodal AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models because it highlights the significant impact of data bias on model performance and cultural diversity. It introduces novel evaluation metrics and proposes effective strategies to mitigate bias, directly addressing a critical limitation in current multimodal systems. This research opens new avenues for developing more inclusive and globally representative AI systems. The findings are especially relevant given the growing focus on fairness and ethical considerations in AI.
Visual Insights#
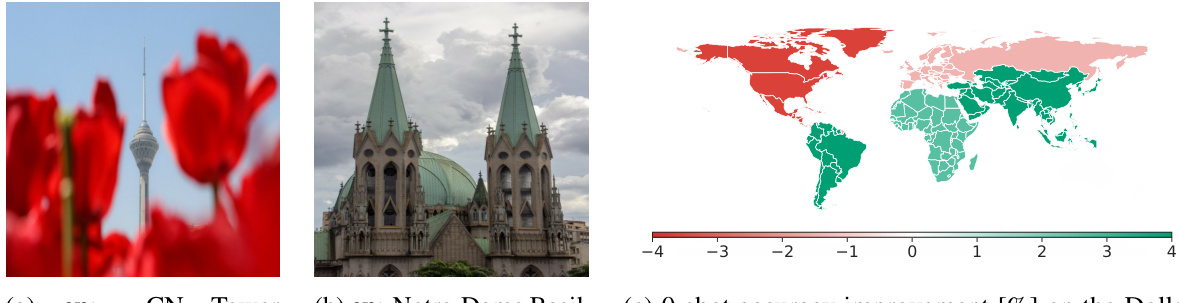
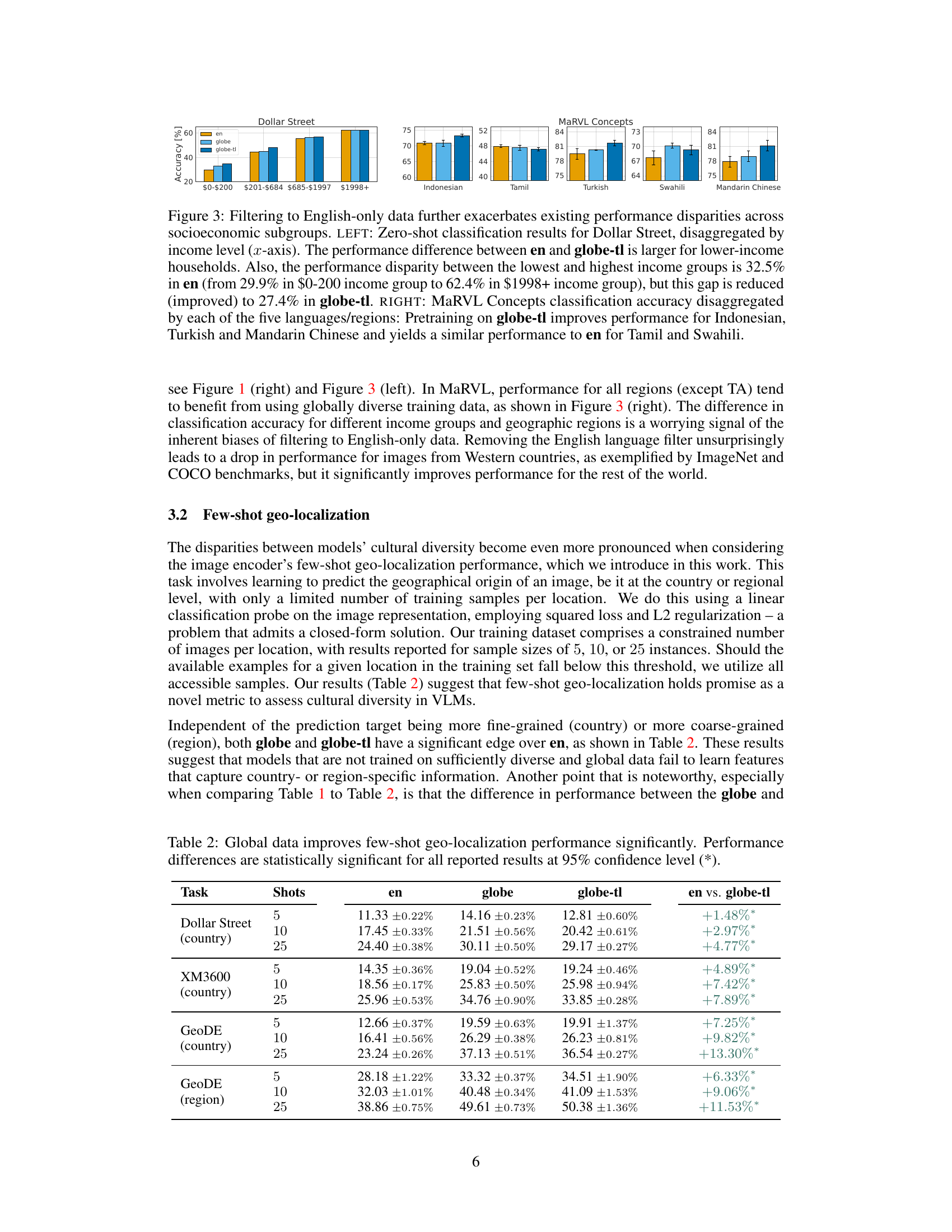
🔼 This figure shows the limitations of models trained only on English image-text pairs. When evaluating these models on images from various regions worldwide, they frequently misclassify landmarks, often confusing them with visually similar landmarks located in Western countries. This highlights a bias towards Western perspectives and demonstrates the lack of cultural diversity in models trained on limited data.
read the caption
Figure 1: Models trained on English image-text pairs exhibit a lack of diversity when evaluated on images from other regions, sometimes confusing landmarks with similar ones located in the West.
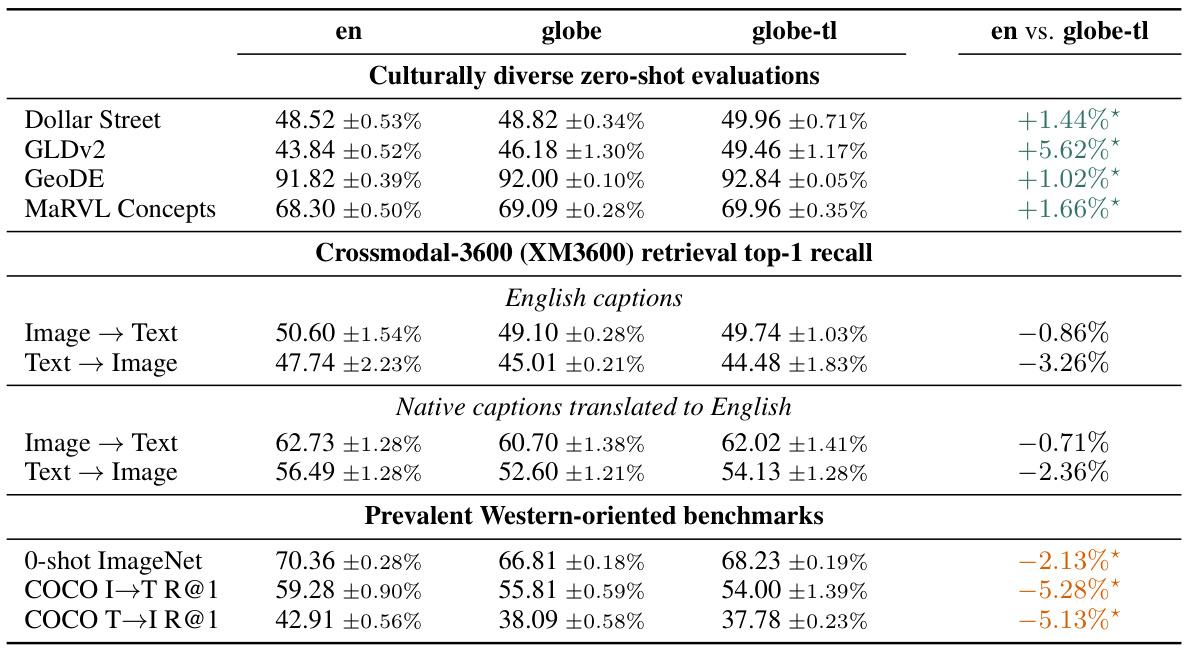
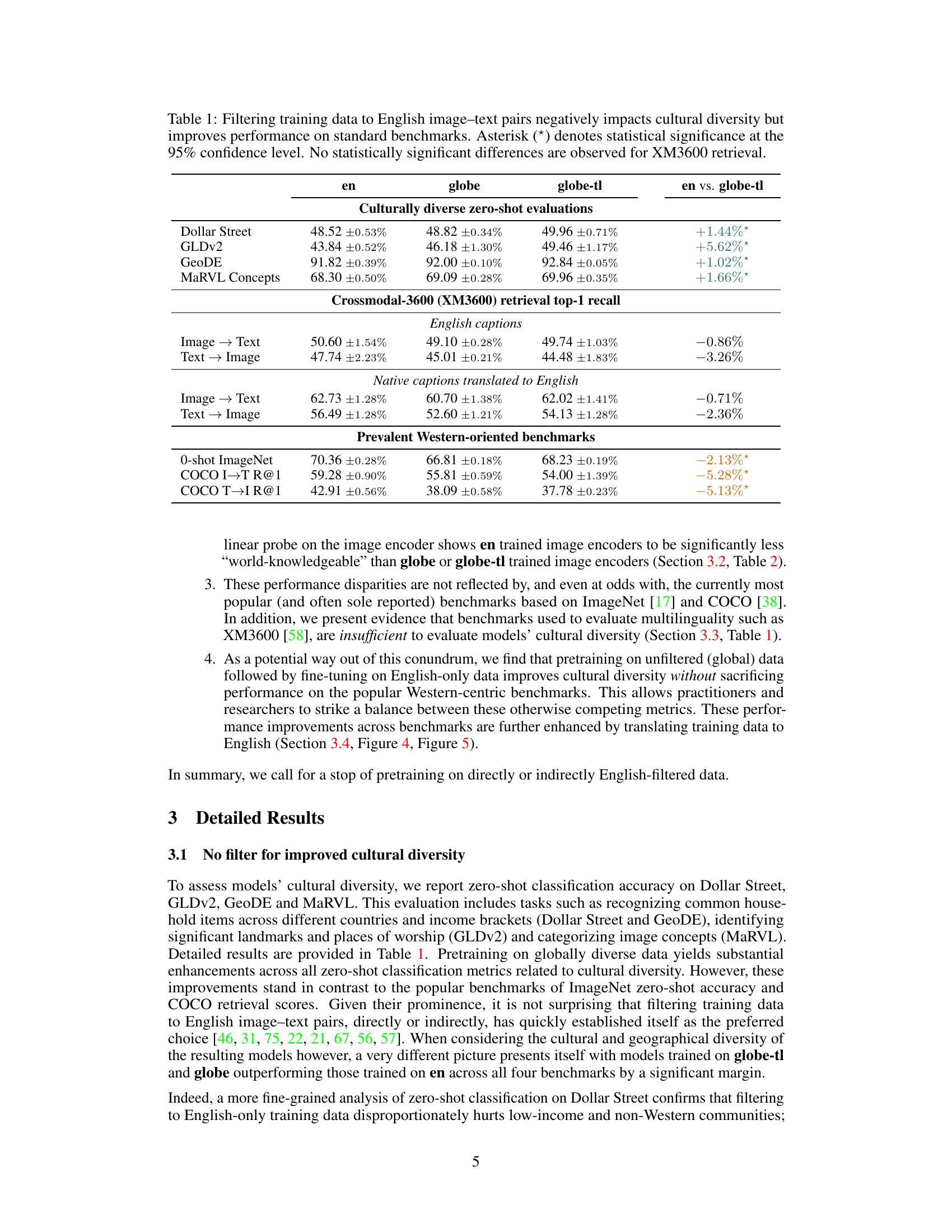
🔼 This table presents a comparison of the performance of contrastive vision-language models (VLMs) trained on different datasets. The ’en’ column shows results for models trained solely on English image-text pairs, while ‘globe’ represents models trained on unfiltered global data, and ‘globe-tl’ represents models trained on globally diverse data with English translations. The table evaluates performance across various metrics categorized into three groups: culturally diverse zero-shot evaluations (Dollar Street, GLDv2, GeoDE, MaRVL), Crossmodal-3600 retrieval recall (with both English and translated captions), and prevalent Western-oriented benchmarks (ImageNet zero-shot, COCO image-text retrieval). The ’en vs. globe-tl’ column highlights the performance differences between the English-only trained model and the globally diverse model with translations. Statistical significance is indicated with an asterisk.
read the caption
Table 1: Filtering training data to English image-text pairs negatively impacts cultural diversity but improves performance on standard benchmarks. Asterisk (*) denotes statistical significance at the 95% confidence level. No statistically significant differences are observed for XM3600 retrieval.
In-depth insights#
VLM Cultural Bias#
Analysis of “VLM Cultural Bias” reveals that contrastive vision-language models (VLMs) exhibit significant cultural biases, largely stemming from the disproportionate representation of Western cultures in training data. This bias negatively impacts the performance of VLMs on tasks involving non-Western cultural contexts, highlighting a critical need for more diverse and inclusive training datasets. The research underscores that reliance on English-centric data exacerbates existing socioeconomic disparities. Furthermore, the study introduces novel evaluation metrics, such as geo-localization, to better assess cultural diversity in VLMs and demonstrates that pretraining with global, unfiltered data before fine-tuning on English content can significantly improve cultural understanding without sacrificing performance on standard benchmarks. Addressing VLM cultural bias requires a multifaceted approach, involving data diversification, improved evaluation metrics, and careful consideration of the potential for bias amplification.
Global Data Gains#
The concept of “Global Data Gains” in the context of a research paper likely refers to the advantages obtained by training AI models on diverse, globally sourced datasets. A key insight is that models trained exclusively on Western-centric data underperform when faced with data from other cultures or socioeconomic backgrounds. This limitation arises because such datasets lack the diversity needed for robust and inclusive AI systems. The paper probably demonstrates how expanding the training data to include a global perspective leads to significant performance improvements in tasks related to cultural understanding, such as landmark recognition or object classification across various regions. This improvement is not at the cost of accuracy on standard Western benchmarks, showing that global data does not necessarily compromise performance but enhances overall model capability. The inclusion of global data also likely addresses biases inherent in Western-centric data, improving fairness and promoting more equitable applications of AI. The research might even propose novel metrics, beyond standard benchmarks, to specifically evaluate cultural understanding and diversity within these models.
Geo-localization#
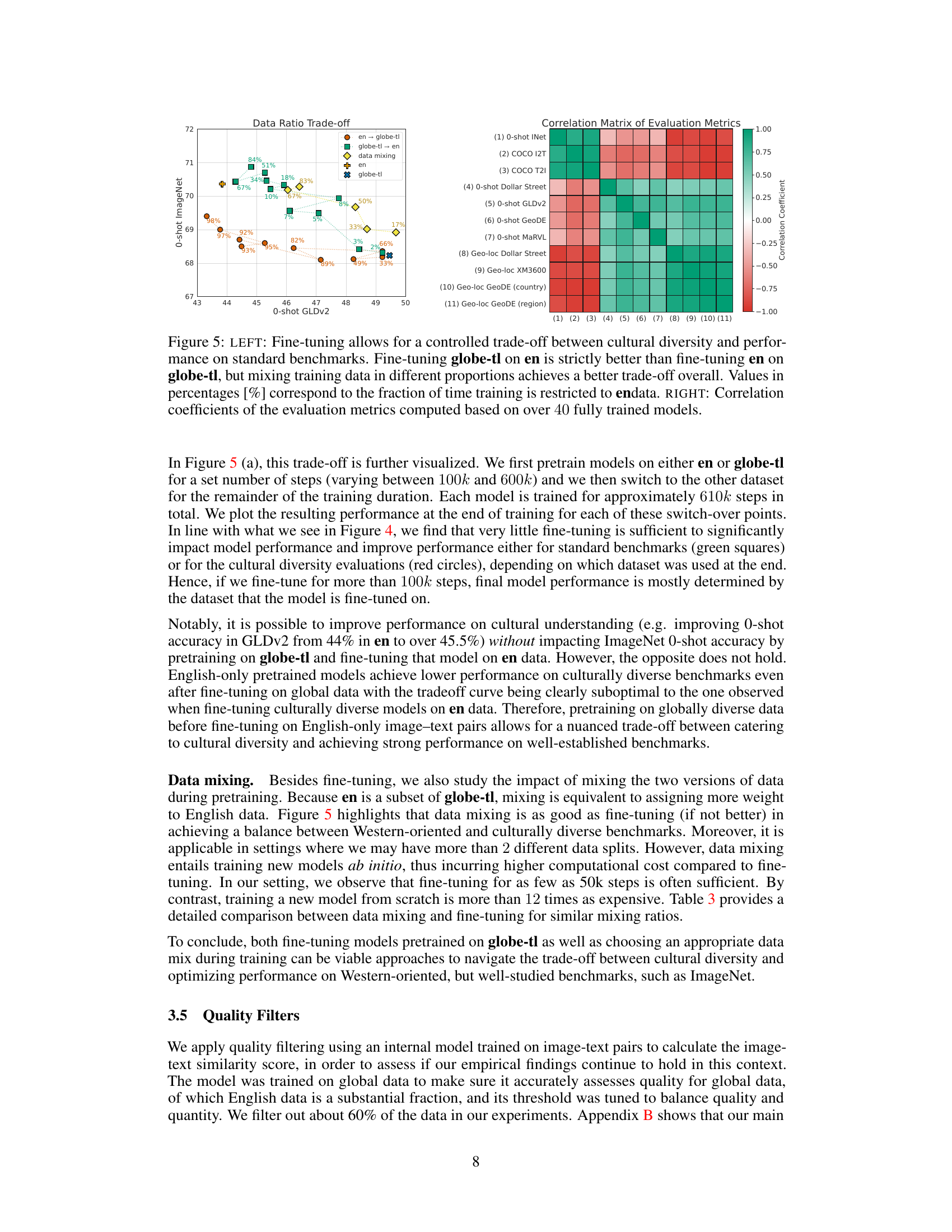
The concept of ‘geo-localization’ in the context of evaluating cultural diversity within vision-language models (VLMs) offers a novel and insightful approach. It moves beyond traditional, often Western-centric benchmarks by directly assessing the models’ ability to identify the geographical origin of images. This is a crucial advancement, as it allows for a more nuanced evaluation of how well the models understand and represent diverse cultural contexts. Unlike existing metrics focused on object classification or image-text retrieval, geo-localization directly measures the VLM’s understanding of the visual and cultural nuances associated with specific geographic regions. Successful geo-localization requires the model to learn visual features beyond simple object recognition, encompassing cultural elements, architectural styles, environments, and even subtle visual cues reflecting local customs and traditions. Therefore, the incorporation of geo-localization as a benchmark provides a powerful means to quantify and address the issue of cultural bias in VLMs, promoting the development of more inclusive and globally representative AI systems. Its strength lies in its ability to expose biases not readily apparent in standard benchmark tests. However, challenges remain in terms of data availability and the need for appropriately diverse, high-quality datasets for effective and unbiased evaluation.
Benchmark Imbalance#
The concept of “Benchmark Imbalance” in the context of a research paper likely refers to the disproportionate emphasis on certain benchmark datasets over others, leading to skewed evaluations and potentially hindering the development of truly robust and generalizable models. Western-centric benchmarks, such as ImageNet and COCO, have historically dominated the field, creating an imbalance where models are primarily evaluated on datasets representing primarily Western cultures and contexts. This focus can mask performance disparities in models when applied to datasets from other cultures or socioeconomic backgrounds. Consequently, the dominant benchmarks may overlook crucial aspects of model capabilities and limitations in diverse settings. Addressing this requires a more balanced approach, incorporating a broader range of benchmark datasets that represent global diversity, to foster the development of truly inclusive and equitable AI systems. Expanding the benchmark suite to include geographically and culturally diverse datasets will lead to more comprehensive evaluations, revealing strengths and weaknesses across various contexts and promoting the creation of fairer and more widely beneficial AI. The inherent biases in existing benchmarks must be acknowledged and mitigated by focusing on evaluating performance across multiple, carefully selected, benchmarks that adequately reflect global diversity. This holistic approach is crucial for advancing AI research and development towards a fairer and more equitable future.
Future Directions#
Future research should prioritize expanding the scope of cultural and socioeconomic diversity assessment in vision-language models (VLMs). Benchmark datasets need to move beyond Western-centric viewpoints, incorporating more diverse geographical regions, languages, and socioeconomic contexts. Developing new evaluation metrics that are sensitive to cultural nuances, beyond simple accuracy scores, is crucial. Furthermore, research should investigate techniques to mitigate biases in training data and improve the fairness and inclusivity of VLMs. This might involve exploring innovative data augmentation methods, new model architectures, or training strategies that explicitly address biases. Finally, it’s vital to investigate the interplay between cultural diversity and other aspects of fairness, such as gender, race, and age, to create truly inclusive multimodal systems. The implications of these advancements extend beyond the immediate field, impacting various AI applications and promoting responsible and equitable technology development.
More visual insights#
More on figures
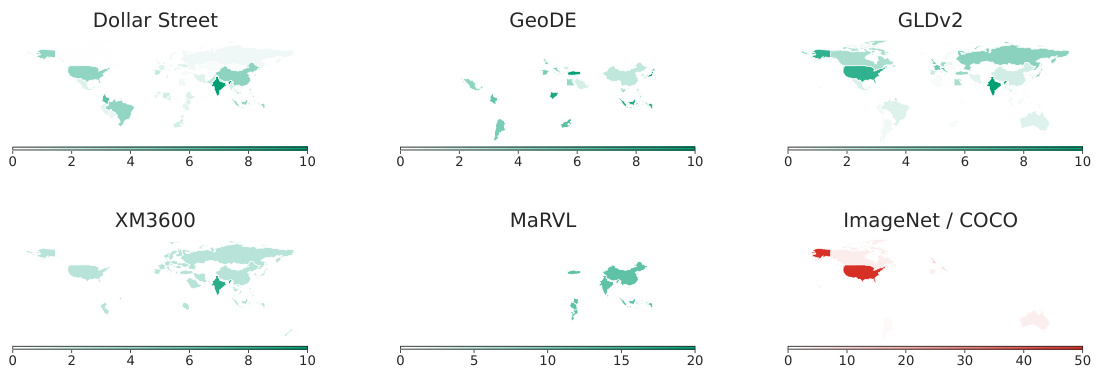
🔼 This figure shows the geographical distribution of images in six different datasets used to evaluate the cultural diversity of vision-language models. The datasets include Dollar Street, GeoDE, GLDv2, XM3600, MaRVL, ImageNet, and COCO. The figure highlights the significant geographical bias in ImageNet and COCO datasets, which are predominantly composed of images from Western countries, in contrast to the other datasets which exhibit greater geographical diversity.
read the caption
Figure 2: Data distribution [%] for each of the evaluation datasets, only approximate in MaRVL [39] based on the 5 languages collected in the dataset. Dollar Street [49], GeoDE [47], GLDv2 [66] and XM3600 [20] are geographically diverse. MaRVL is included because it focuses on underrepresented regions, such as Asia and East Africa. By comparison, ImageNet examples are mostly from a few Western countries (see for instance [53]). COCO has a nearly identical distribution to ImageNet [16].
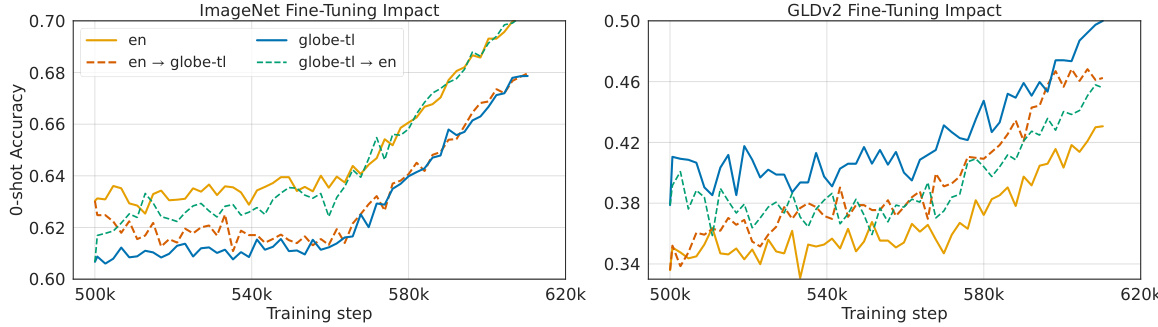
🔼 This figure shows the impact of fine-tuning on two different models, one trained on English-only data (en) and one trained on global data (globe-tl). The left panel displays the zero-shot classification accuracy on ImageNet, while the right panel shows the accuracy on GLDv2. Fine-tuning the globe-tl model on English data improves its performance on ImageNet, almost reaching the level of the English-only model. However, fine-tuning the English-only model on global data does not lead to a similar improvement on GLDv2, highlighting the difficulty in improving performance on culturally diverse benchmarks.
read the caption
Figure 4: Fine-tuning globe-tl on en quickly catches up with en for ImageNet zero-shot evaluation while also performing better on GLDv2. Conversely, fine-tuning en on globe-tl does not suffice to close the gap in performance on culturally diverse benchmarks.
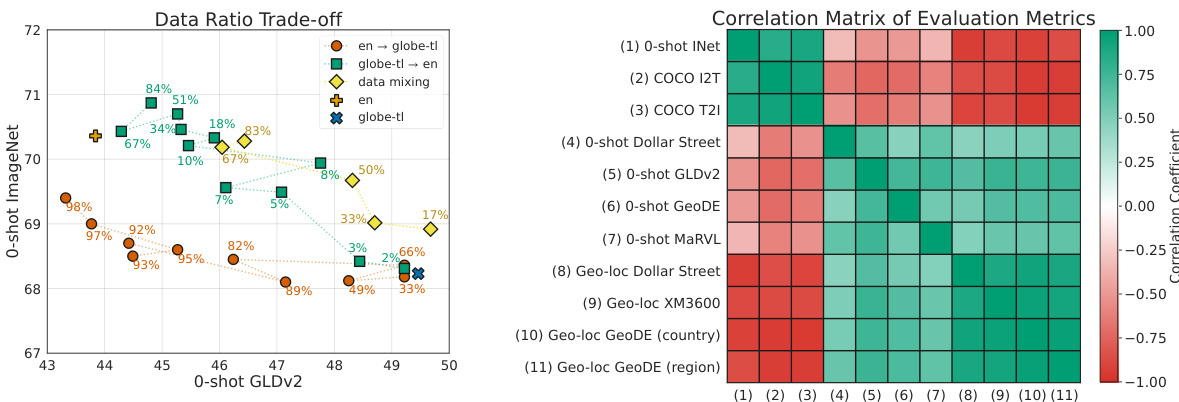
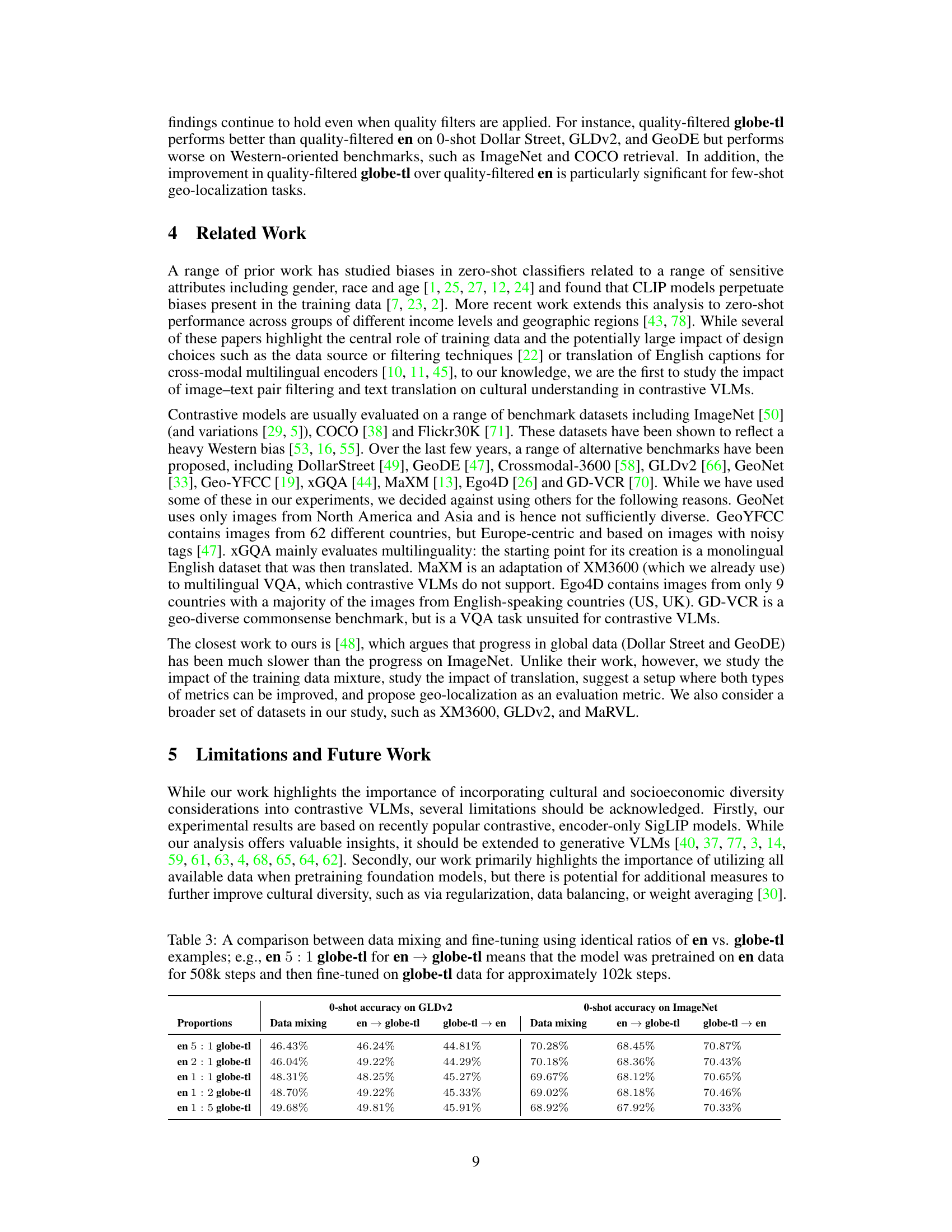
🔼 This figure presents two key findings. The left panel shows the impact of fine-tuning models pretrained on either English-only (en) or globally diverse (globe-tl) data on ImageNet and GLDv2. It demonstrates a trade-off between performance on standard benchmarks (ImageNet) and cultural diversity (GLDv2). Fine-tuning globe-tl models on English data quickly improves ImageNet performance, while maintaining better GLDv2 results than fine-tuning English models on global data. Data mixing provides a comparable yet more efficient alternative for achieving this balance. The right panel displays a correlation matrix showing the relationships between various evaluation metrics (zero-shot classification on different datasets and few-shot geo-localization), further highlighting the interdependency of performance across cultural diversity and standard benchmarks.
read the caption
Figure 5: LEFT: Fine-tuning allows for a controlled trade-off between cultural diversity and performance on standard benchmarks. Fine-tuning globe-tl on en is strictly better than fine-tuning en on globe-tl, but mixing training data in different proportions achieves a better trade-off overall. Values in percentages [%] correspond to the fraction of time training is restricted to endata. RIGHT: Correlation coefficients of the evaluation metrics computed based on over 40 fully trained models.
More on tables
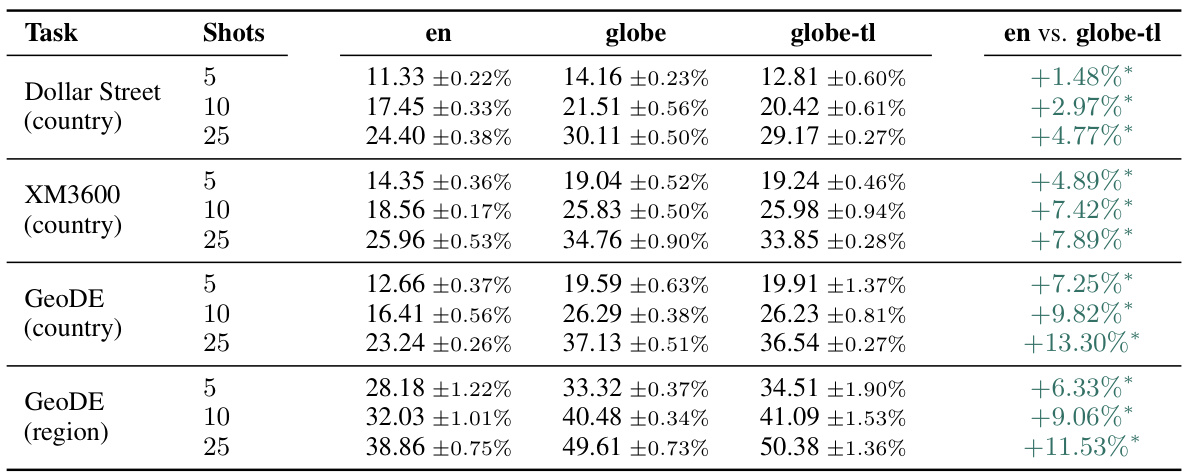
🔼 This table presents a comparison of the performance of contrastive vision-language models (VLMs) trained on different datasets across various evaluation metrics. It shows how filtering training data to only English image-text pairs negatively affects cultural diversity benchmarks while improving performance on standard Western-centric benchmarks like ImageNet and COCO. The table highlights the trade-off between performance on standard benchmarks and performance on culturally diverse datasets.
read the caption
Table 1: Filtering training data to English image-text pairs negatively impacts cultural diversity but improves performance on standard benchmarks. Asterisk (*) denotes statistical significance at the 95% confidence level. No statistically significant differences are observed for XM3600 retrieval.

🔼 This table compares the performance of three SigLIP models trained on different datasets: English-only (en), global multilingual (globe), and global multilingual with English translation (globe-tl). It evaluates zero-shot classification accuracy on culturally diverse datasets (Dollar Street, GLDv2, GeoDE, MaRVL) and standard benchmarks (ImageNet, COCO). The results show that while the English-only model performs best on standard benchmarks, the global models significantly outperform it on culturally diverse datasets. The globe-tl model, which uses machine translation to convert non-English text to English, provides a balance between these two performance metrics.
read the caption
Table 1: Filtering training data to English image-text pairs negatively impacts cultural diversity but improves performance on standard benchmarks. Asterisk (*) denotes statistical significance at the 95% confidence level. No statistically significant differences are observed for XM3600 retrieval.

🔼 This table presents a comparison of the performance of vision-language models (VLMs) trained on different datasets on various benchmark tasks. The datasets include culturally diverse datasets and standard Western-centric benchmarks like ImageNet and COCO. The table shows that filtering training data to only English image-text pairs improves performance on Western benchmarks but negatively impacts cultural diversity evaluations. The results are presented for three model variants: one trained on English-only data, one trained on global unfiltered data, and another pretrained on global data then fine-tuned on English data. Statistical significance is indicated where applicable.
read the caption
Table 1: Filtering training data to English image-text pairs negatively impacts cultural diversity but improves performance on standard benchmarks. Asterisk (*) denotes statistical significance at the 95% confidence level. No statistically significant differences are observed for XM3600 retrieval.
Full paper#