↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality 3D models from just one image is a long-standing challenge in computer vision. Existing methods either produce poor geometry, inconsistent results, or are computationally expensive. Many methods based on Score Distillation Sampling (SDS) are slow and produce inconsistent results. Other approaches, which finetune multi-view diffusion models or train fast feed-forward models, lack intricate textures and complex geometry.
Unique3D tackles these limitations by using a novel framework that combines a multi-view diffusion model and a normal diffusion model to generate multi-view images with their normal maps. This is followed by a multi-level upscale process to improve resolution. Finally, an instant and consistent mesh reconstruction algorithm (ISOMER) integrates color and geometric priors into the final mesh. The results demonstrate that Unique3D significantly outperforms other state-of-the-art methods in terms of geometric and textural details, achieving high fidelity, consistency, and efficiency in single image to 3D mesh generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Unique3D, a novel and efficient framework for generating high-quality 3D meshes from a single image. This addresses a crucial challenge in 3D computer vision, impacting various applications. The method’s speed and accuracy, exceeding existing methods, makes it highly relevant to current trends in AI-driven 3D content creation and opens avenues for research in high-fidelity image-to-3D generation, multi-view consistency, and efficient mesh reconstruction.
Visual Insights#

🔼 This figure shows a gallery of 3D models generated by the Unique3D model. Each model was generated from a single, unconstrained image in under 30 seconds, demonstrating the model’s speed and ability to generate high-fidelity, detailed meshes with diverse textures.
read the caption
Figure 1: Gallery of Unique3D. High-fidelity and diverse textured mesh generated by Unique3D from single-view wild images within 30 seconds.
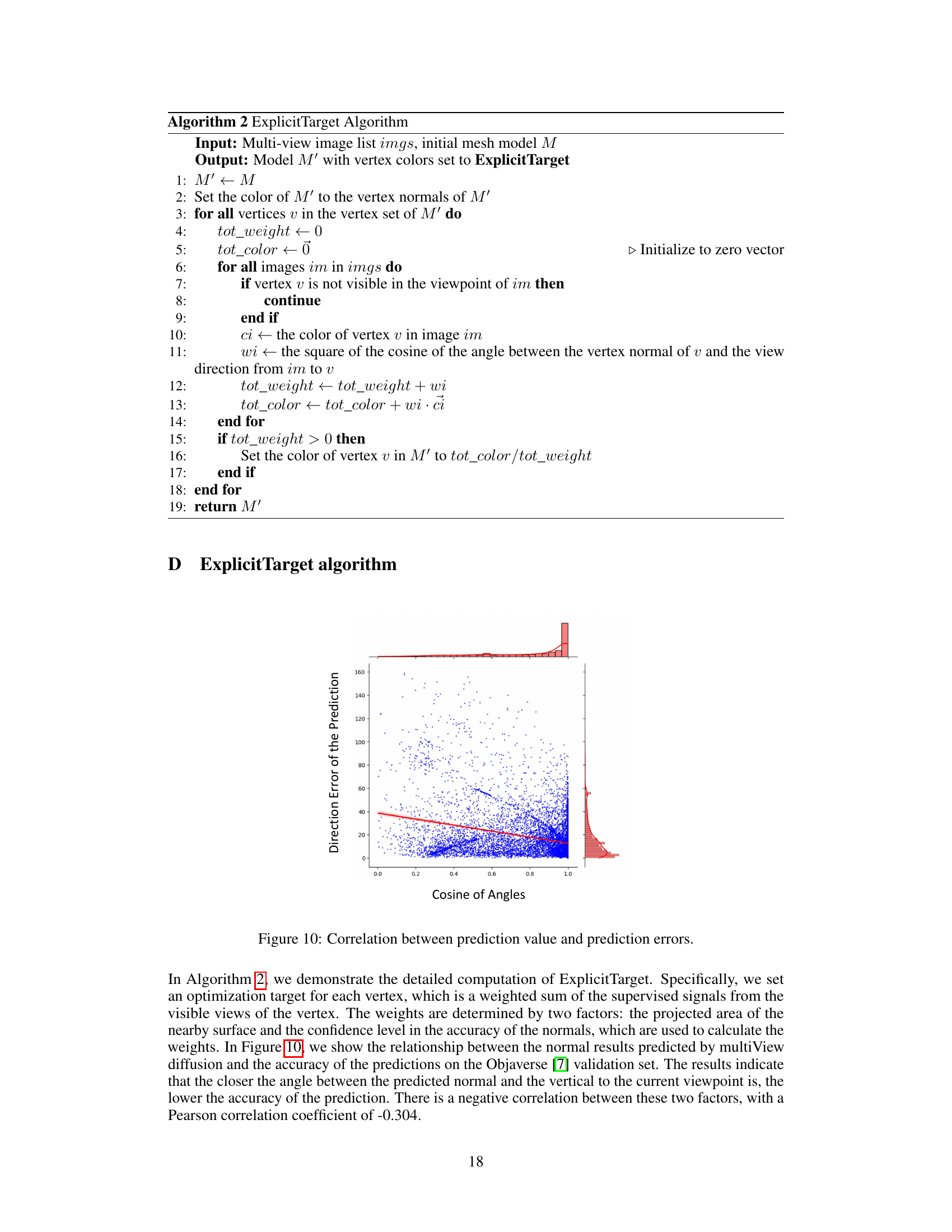
🔼 This table presents a quantitative comparison of the proposed Unique3D model against several state-of-the-art image-to-3D methods. The comparison uses seven metrics to evaluate both the visual quality (PSNR, SSIM, LPIPS, Clip-Similarity) and geometric accuracy (CD, Vol. IoU, F-Score) of the generated 3D meshes. The dataset used for evaluation is the Google Scanned Objects (GSO) dataset.
read the caption
Table 1: Quantitative comparison results for mesh visual and geometry quality. We report the metrics of PSNR, SSIM, LPIPS and Clip-Similarity [38], ChamferDistance (CD), Volume IoU and F-score on GSO [8] dataset.
In-depth insights#
Unique3D Overview#
Unique3D is presented as a novel image-to-3D framework emphasizing efficiency and high-quality mesh generation from single-view images. Its core innovation lies in a multi-pronged approach. First, it employs a multi-view diffusion model, generating multiple orthographic views and their corresponding normal maps. Second, a multi-level upscale process enhances resolution progressively. Finally, a unique instant and consistent mesh reconstruction algorithm, ISOMER, integrates color and geometric information for intricate detail reconstruction. Unique3D’s key strength is its ability to simultaneously achieve high fidelity, consistency, and speed, outperforming existing methods in both geometric and textural detail. This is accomplished through a clever combination of existing techniques adapted and optimized to work synergistically, representing a significant advancement in the field of image-to-3D generation.
Multi-view Diffusion#
Multi-view diffusion models represent a significant advancement in 3D generation, addressing limitations of single-view approaches. By training on multi-view datasets, these models learn to generate consistent and coherent views of an object from multiple viewpoints. This is crucial for overcoming the inherent ambiguities of reconstructing 3D shapes from a single image. The key advantage lies in the improved consistency and reduced ambiguity in the generated 3D representations. These models offer a path to higher-quality and more realistic 3D models because they inherently resolve issues such as inconsistent geometry or textures that can arise from methods relying on a single perspective. However, challenges remain in efficiently handling high-resolution images and achieving fine-grained details. The computational cost associated with multi-view processing can be substantial, representing a trade-off that needs to be carefully managed. Future work should focus on improving computational efficiency and exploring novel architectures to enable the generation of even more intricate and detailed 3D models from multi-view data.
Mesh Reconstruction#
Mesh reconstruction, a crucial aspect of 3D computer vision, focuses on efficiently generating high-quality 3D meshes from various input sources. Traditional methods often involved complex multi-stage pipelines, like Structure from Motion (SfM) and Multi-View Stereo (MVS), which proved computationally expensive and struggled with intricate details. Deep learning’s advent has significantly impacted this field, enabling approaches to achieve greater efficiency and detail. However, challenges remain. Methods based on Score Distillation Sampling (SDS), while producing diverse results, often suffer from long optimization times and inconsistencies. Multi-view diffusion models offer an alternative, generating multi-view images for reconstruction, but they too may struggle to capture fine textures and complex geometries at high resolution due to inconsistencies across views. The paper’s proposed ISOMER algorithm directly addresses these challenges by emphasizing speed and detailed reconstructions from multi-view images, suggesting a significant advancement in mesh reconstruction techniques. The move towards instant and consistent mesh reconstruction, as highlighted in ISOMER, represents a key direction for future development in the field.
High-Res Upscaling#
High-resolution upscaling in image-to-3D frameworks is crucial for achieving photorealistic results. The approach described likely involves a multi-stage process, starting with a lower-resolution multi-view image generation, followed by several upscaling steps. Each upscaling step likely uses a different model or algorithm tailored for specific enhancement needs. This might include enhancing texture details, correcting inconsistencies between generated views, and sharpening edges. The choice of using a multi-stage pipeline rather than a single high-resolution model is likely a trade-off between computational cost and achieved fidelity. Multi-stage pipelines allow for more efficient training and inference because each stage can focus on a specific aspect of image enhancement. A crucial aspect is ensuring consistency across multiple views throughout the upscaling process to maintain a coherent 3D representation. Careful selection of suitable models and loss functions in each stage is necessary to prevent artifacts and achieve high-fidelity results. Finally, the success of high-resolution upscaling is greatly dependent on the quality of the initially generated low-resolution multi-view images. If the base images are flawed or lack detail, subsequent upscaling will not be able to fully compensate for these shortcomings.
Future of Unique3D#
The future of Unique3D hinges on several key areas. Improving efficiency is paramount; while Unique3D is fast, further optimizations could reduce generation time significantly, making it even more practical for real-time applications. Enhanced resolution and detail are crucial; increasing the resolution of generated meshes and textures, particularly for complex geometries, remains a key challenge. Addressing this requires refining the multi-level upscale process and potentially exploring novel architectures. Expanding capabilities is another important direction; Unique3D currently focuses on mesh generation from single images. Future work could involve multi-image input for improved accuracy, or incorporation of additional modalities like depth information. Finally, robustness and generalizability need attention; the system’s performance on diverse datasets should be enhanced, addressing potential biases and inconsistencies in mesh reconstruction. Addressing these limitations will elevate Unique3D’s status as a leading image-to-3D technology.
More visual insights#
More on figures

🔼 This figure showcases a variety of 3D models generated by the Unique3D model. The models demonstrate the system’s ability to produce high-fidelity and diverse textured meshes from single images, highlighting its ability to capture details and nuances of the original images. The speed of generation (within 30 seconds) is also emphasized.
read the caption
Figure 1: Gallery of Unique3D. High-fidelity and diverse textured mesh generated by Unique3D from single-view wild images within 30 seconds.

🔼 This figure illustrates the pipeline of the Unique3D framework. It starts with a single input image and uses a multi-view diffusion model to generate four orthographic views. These views are then upscaled to higher resolution using a multi-level approach. A normal diffusion model is used to create corresponding normal maps, which are also upscaled. Finally, the high-resolution images and normal maps are fed into the ISOMER algorithm to reconstruct a high-quality 3D textured mesh.
read the caption
Figure 2: Pipeline of our Unique3D. Given a single in-the-wild image as input, we first generate four orthographic multi-view images from a multi-view diffusion model. Then, we progressively improve the resolution of generated multi-views through a multi-level upscale process. Given generated color images, we train a normal diffusion model to generate normal maps corresponding to multi-view images and utilize a similar strategy to lift it to high-resolution space. Finally, we reconstruct high-quality 3D meshes from high-resolution color images and normal maps with our instant and consistent mesh reconstruction algorithm ISOMER.

🔼 This figure presents a qualitative comparison of the 3D models generated by the proposed Unique3D method and several existing state-of-the-art image-to-3D techniques. For each method, the input image and the resulting 3D model are shown, demonstrating the high-fidelity geometry and texture details achieved by Unique3D. The results show that Unique3D generates superior results compared to the baselines in terms of both geometry and texture.
read the caption
Figure 3: Qualitative Comparison. Our approach provides superior geometry and texture.

🔼 This figure compares the 3D mesh reconstruction results of Unique3D against three other state-of-the-art methods: InstantMesh, CRM, and OpenLRM. The comparison highlights the superior quality of Unique3D in terms of both geometric accuracy (shape) and textural detail (surface appearance). For each input image, the figure shows the generated 3D models from all four methods, allowing for a direct visual comparison.
read the caption
Figure 4: Detailed Comparison. We compare our model with InstantMesh [63], CRM [60] and OpenLRM [11]. Our models generates accurate geometry and detailed texture.

🔼 This figure shows the ablation study performed on the ISOMER (Instant and consistent mesh reconstruction) algorithm. The results demonstrate the importance of two key components: ExplicitTarget and expansion regularization. (a) shows that without the ExplicitTarget, the generated mesh suffers from significant defects, particularly in regions with detailed textures or complex shapes. (b) reveals that without expansion regularization, the mesh often collapses in several areas.
read the caption
Figure 5: Ablation Study on ISOMER. (a) Without ExplicitTarget, the output mesh result has obvious defects. (b) Without expansion regularization, the output result collapses in some cases.

🔼 This figure shows an ablation study comparing the results of mesh coloring with and without the ExplicitTarget method. The top row displays meshes colored using ExplicitTarget, resulting in consistent and artifact-free coloring across multiple views. The bottom row displays meshes colored without ExplicitTarget, showcasing significant artifacts and inconsistencies in coloring across different views. This demonstrates the efficacy of ExplicitTarget in achieving color consistency in multi-view mesh reconstruction.
read the caption
Figure 6: Ablation on Colorize. We show a comparison of whether or not to apply ExplicitTarget in coloring, and we can see that the group that does not use ExplicitTarget has significant artifacts, as there is no precise consistency across multiple views.

🔼 This figure shows an ablation study on the effect of multi-level super-resolution on the generated multi-view images. It demonstrates that increasing the resolution from 256 to 512 to 2048 progressively improves the detail and fidelity of the generated images, without significantly altering the overall structure. This highlights the effectiveness of the proposed multi-level upscale process in enhancing the quality of the 3D mesh generation.
read the caption
Figure 7: Ablation on Resolution. The visualization of the generated multi-views images at different stages is shown. Multi-level super-resolution does not change the general structure, but only improves the detail resolution, allowing the model to remain well-detailed.

🔼 This figure demonstrates the capability of Unique3D to generate high-quality 3D textured meshes from challenging input images. The examples showcase the model’s ability to handle complex geometries, intricate textures, and diverse styles.
read the caption
Figure 8: Challenging examples

🔼 This figure showcases additional examples of 3D textured meshes generated by the Unique3D model from single input images. It expands on Figure 1, demonstrating the model’s ability to generate diverse and high-fidelity 3D models from a wider variety of input images. The figure shows various objects and characters such as cartoon characters, animals, and robots, each presented in multiple views to showcase the quality and consistency of the generated 3D models.
read the caption
Figure 9: More generated results of our method from a single image.

🔼 This figure illustrates the pipeline of the Unique3D framework. It starts with a single image as input, generates multi-view images and normal maps using diffusion models, enhances the resolution through multi-level upscaling, and finally reconstructs a high-quality 3D mesh using the ISOMER algorithm.
read the caption
Figure 2: Pipeline of our Unique3D. Given a single in-the-wild image as input, we first generate four orthographic multi-view images from a multi-view diffusion model. Then, we progressively improve the resolution of generated multi-views through a multi-level upscale process. Given generated color images, we train a normal diffusion model to generate normal maps corresponding to multi-view images and utilize a similar strategy to lift it to high-resolution space. Finally, we reconstruct high-quality 3D meshes from high-resolution color images and normal maps with our instant and consistent mesh reconstruction algorithm ISOMER.
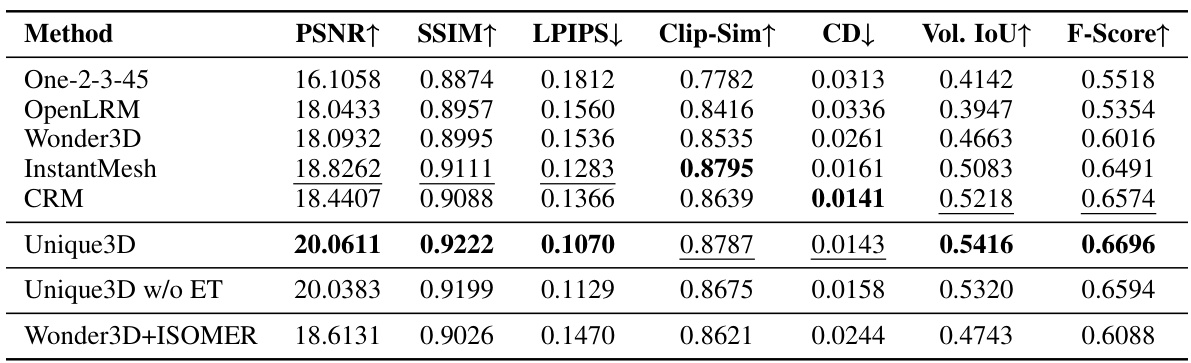
🔼 This figure displays the correlation between the cosine of angles (representing the angle between the predicted normal and the ground truth normal) and the direction error of the prediction. A negative correlation is observed, indicated by the red line of best fit, suggesting that as the cosine of the angle increases (angle decreases and the predicted normal is closer to the ground truth normal), the direction error decreases. The marginal distributions (histograms) on the top and right side show the distribution of the cosine of angles and direction error, respectively. The plot reveals insights into the accuracy of normal prediction, highlighting a higher accuracy for normals closer to the ground truth direction.
read the caption
Figure 10: Correlation between prediction value and prediction errors.

🔼 This figure shows an ablation study comparing the performance of the paper’s proposed fast mesh initialization method against a common alternative using a sphere as initialization. The input images are displayed on the left, followed by the results using the authors’ method and then a sphere-based initialization. Red circles highlight areas where the sphere-based initialization struggles to accurately capture the shape of the object. The comparison demonstrates that while a sphere initialization can sometimes produce reasonable results, the proposed method generally produces superior results.
read the caption
Figure 11: Ablations on Mesh Initialization. We compare the results of using our fast initialization method, versus using a sphere as an initialization.
More on tables

🔼 This table presents a quantitative comparison of the results obtained using the Unique3D model against a baseline. The comparison is based on 100 random samples with random rotation on the GSO dataset. The metrics used for evaluation are PSNR, SSIM, LPIPS, Clip-Sim, CD, Vol. IoU, and F-Score. Higher values for PSNR, SSIM, Clip-Sim, Vol. IoU, and F-Score indicate better performance; whereas lower values for LPIPS and CD indicate better performance.
read the caption
Table 2: Quantitative comparison results for ablation on 100 random samples with random rotation on GSO dataset.
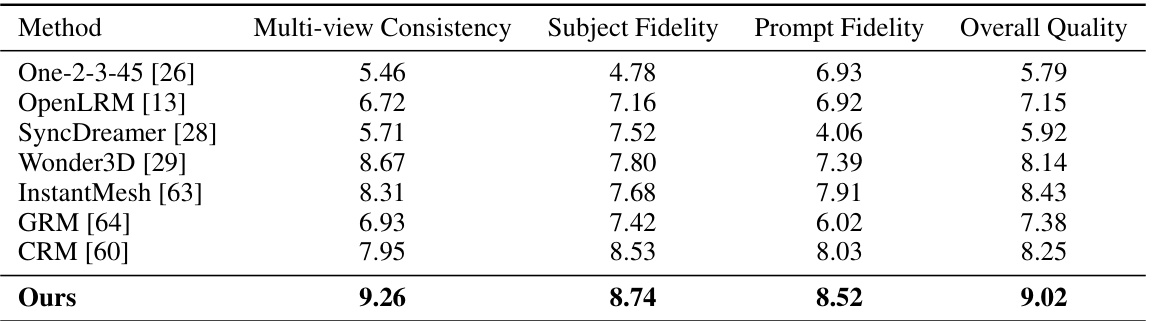
🔼 This table presents a quantitative comparison of the proposed Unique3D model against several state-of-the-art methods for 3D mesh generation from a single image. The comparison uses seven metrics to evaluate both the visual quality and geometric accuracy of the generated meshes. These metrics cover various aspects, including peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), learned perceptual image patch similarity (LPIPS), CLIP similarity, Chamfer distance (CD), volume Intersection over Union (IoU), and F-score. The results are reported on the Google Scanned Objects (GSO) dataset.
read the caption
Table 1: Quantitative comparison results for mesh visual and geometry quality. We report the metrics of PSNR, SSIM, LPIPS and Clip-Similarity [38], ChamferDistance (CD), Volume IoU and F-score on GSO [8] dataset.
Full paper#