↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many computational problems lack a single universally superior algorithm; the choice often depends on the specific problem instance. This paper tackles this challenge by proposing a novel data-driven approach using neural networks to learn a mapping from problem instances to the best-performing algorithm. This is particularly relevant to branch-and-cut methods in mixed-integer optimization, where efficient algorithm selection is crucial for reducing computational time.
The authors formalize this idea and develop rigorous sample complexity bounds for the proposed approach, ensuring the learned algorithm generalizes well to unseen data. They then apply this method to branch-and-cut, demonstrating its efficacy through extensive computational experiments. Results show significant reductions in branch-and-cut tree sizes compared to traditional methods, highlighting the potential impact of this neural network approach in improving the efficiency of solving complex optimization problems.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to algorithm selection using neural networks, offering a data-driven solution to complex optimization problems. The rigorous sample complexity analysis provides a theoretical foundation, while the computational results demonstrate significant improvements over previous methods. This opens avenues for future research in data-driven algorithm design and its applications to various optimization tasks. The combination of theoretical analysis and empirical validation makes it a valuable contribution to both the machine learning and optimization communities.
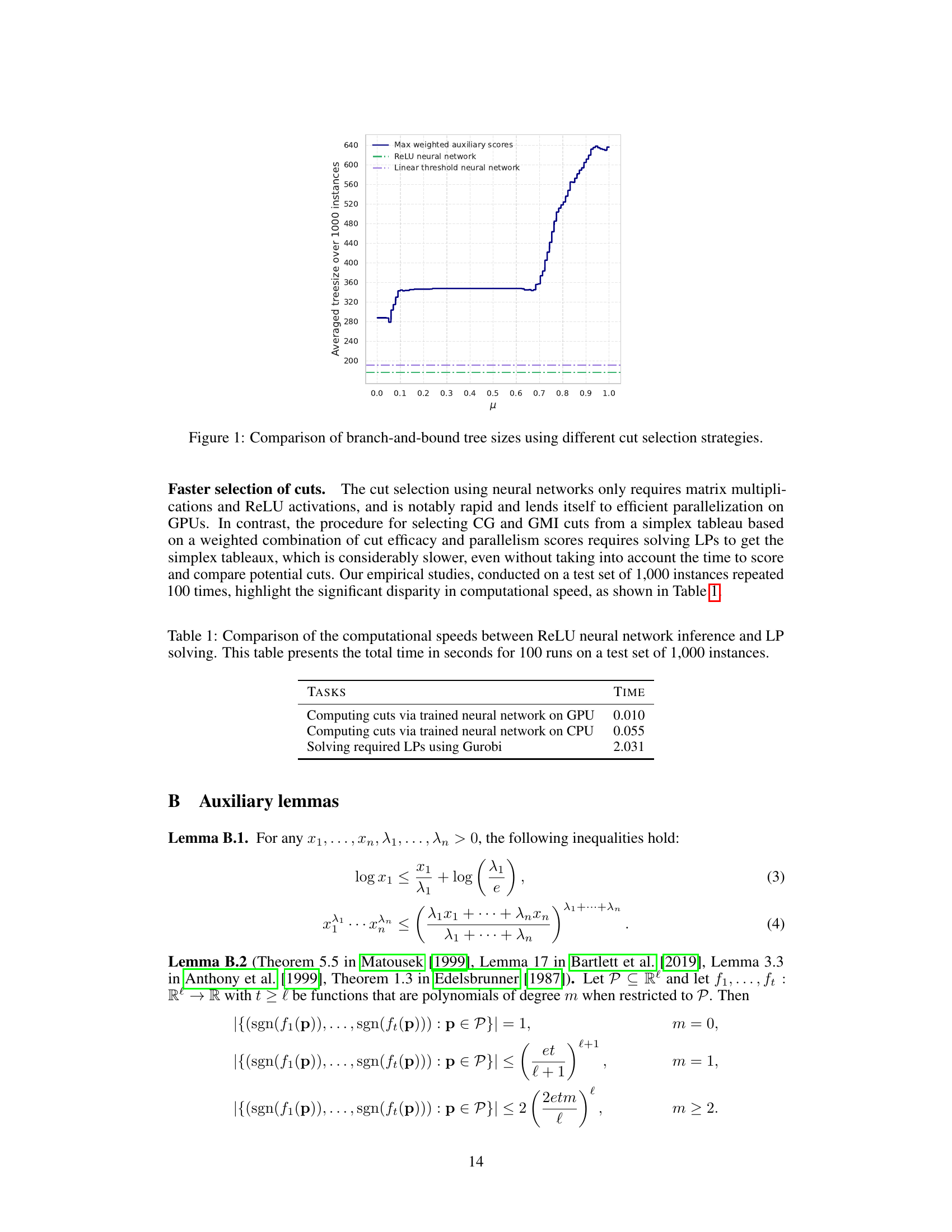
Visual Insights#

This figure compares the average branch-and-bound tree sizes across 1000 test instances for three different cut selection strategies: (1) selecting cuts based on the highest convex combination score of cut efficacy and parallelism, (2) using a ReLU neural network, and (3) using a linear threshold neural network. The x-axis represents the tuning parameter (µ) for the weighted auxiliary score approach, while the y-axis represents the average tree size. The plot demonstrates that the neural network approaches significantly reduce the average tree size compared to the weighted auxiliary score method, suggesting superior cut selection performance. The results highlight the potential of neural networks in improving branch-and-cut efficiency.

This table compares the computation time for three different cut selection methods: using a ReLU neural network on a GPU, using a ReLU neural network on a CPU, and using Gurobi to solve the required linear programs. The results highlight the significantly faster computation time of the neural network approaches, particularly on a GPU, compared to solving linear programs.
Full paper#