↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models is computationally expensive. Parameter-Efficient Fine-Tuning (PEFT) methods aim to reduce this cost by training only a small subset of parameters. However, existing PEFT methods often neglect the spectral information inherent in the pretrained model weights. This paper introduces Spectral Adapter, a novel fine-tuning method that incorporates this spectral information to improve parameter efficiency.
Spectral Adapter works by performing Singular Value Decomposition (SVD) on pretrained weights and then fine-tuning the top singular vectors. The authors demonstrate through experiments that Spectral Adapter significantly outperforms existing PEFT methods on various benchmarks, improving both parameter efficiency and accuracy. Moreover, it offers a natural solution to multi-adapter fusion problems, which commonly occur when adapting models to multiple tasks simultaneously. The theoretical analysis supports these empirical findings, showing that Spectral Adapter improves rank capacity, allowing for greater flexibility in model adaptation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and effective approach to fine-tuning large language models, improving both parameter efficiency and accuracy. It leverages spectral information, a largely unexplored area in PEFT methods, opening new avenues for research into more efficient and effective model adaptation techniques. The findings are relevant to researchers working on parameter-efficient fine-tuning, especially those focused on large language models, which are currently computationally expensive to adapt to downstream tasks. The code release further enhances the impact, allowing other researchers to build upon the findings and contribute to the field.
Visual Insights#
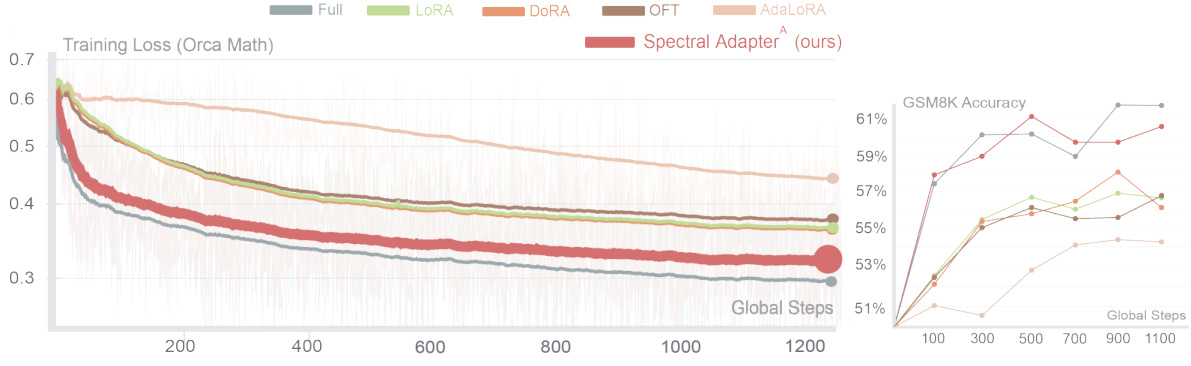
🔼 This figure shows a comparison of different parameter-efficient fine-tuning (PEFT) methods on the Llama 3 8B language model. The left panel displays the training loss curves for full fine-tuning, LoRA, DoRA, Orthogonal Fine-Tuning (OFT), AdaLoRA, and the proposed Spectral Adapter, using the Orca Math dataset. The right panel shows the corresponding GSM8K accuracy. The key takeaway is that Spectral Adapter achieves a performance closest to full fine-tuning, while maintaining a significantly smaller number of trainable parameters (only 0.23%).
read the caption
Figure 1: Training loss of fine-tuning Llama3 8B model with Orca Math dataset [38] and evaluation score on GSM8K benchmark [8]. We follow experimental setup in [53], see Appendix F.1 for details. All methods except full fine-tuning maintain approximately 0.23% trainable parameters.

🔼 This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark when fine-tuning the DeBERTaV3-base model. The methods compared include LoRA, DoRA, OFT, AdaLoRA, and the proposed Spectral Adapter. The table shows the accuracy achieved by each method on various GLUE tasks (MNLI, SST-2, MRPC, etc.) along with the number of trainable parameters used. Spectral Adapter demonstrates superior performance with fewer trainable parameters.
read the caption
Table 1: Accuracy comparison of fine-tuning DeBERTaV3-base with various PEFT methods on GLUE benchmarks. Spectral is abbreviation for Spectral Adapter4. See Section 4.1 for experimental details.
In-depth insights#
Spectral Fine-tuning#
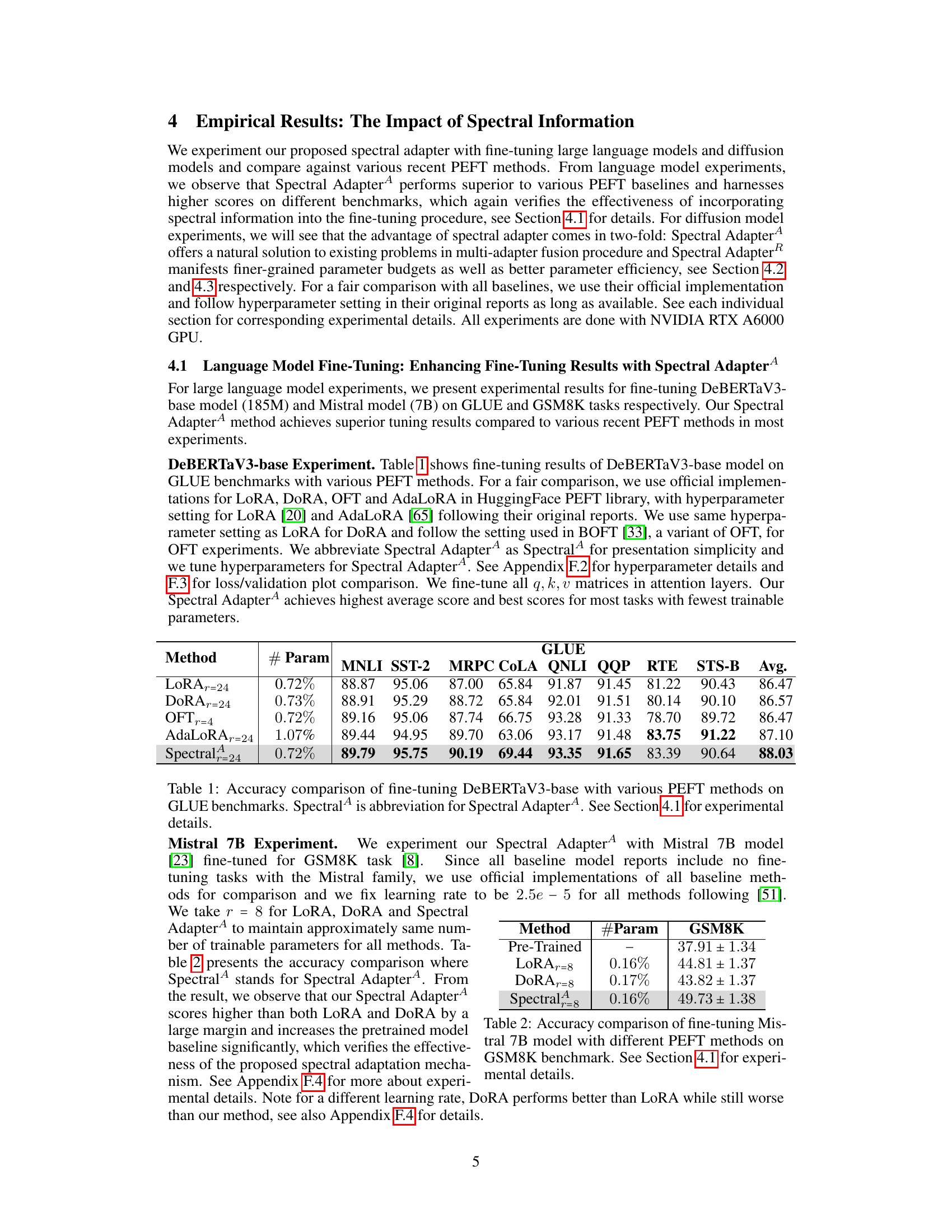
Spectral fine-tuning, as presented in the research paper, offers a novel approach to parameter-efficient fine-tuning (PEFT) by leveraging the spectral information embedded within pretrained model weights. Instead of directly modifying the weights, this method focuses on tuning the top singular vectors obtained via singular value decomposition (SVD). This strategic approach offers several key advantages. First, it enhances the rank capacity of low-rank adapters, allowing for more expressive adaptations with a limited number of trainable parameters. Second, it improves parameter efficiency and tuning performance compared to other PEFT methods such as LoRA and OFT. Third, it provides a natural solution to the problem of multi-adapter fusion in diffusion models, avoiding issues like concept collision and identity loss by strategically distributing different concepts across different spectral spaces. The theoretical analysis supports the method’s superiority, demonstrating a doubled rank capacity compared to LoRA. Empirical results on diverse tasks, including language and vision model fine-tuning, confirm these advantages. Although the method requires SVD computation, the runtime overhead is minimal, particularly when using efficient SVD algorithms like randomized SVD, making spectral fine-tuning a practical approach for enhancing current PEFT techniques.
Adapter Rank Capacity#
The concept of ‘Adapter Rank Capacity’ in the context of parameter-efficient fine-tuning (PEFT) methods is crucial for understanding the model’s ability to adapt to new tasks effectively. Higher rank capacity implies greater flexibility for the adapter to learn complex transformations, allowing for better performance on diverse downstream tasks. The analysis of rank capacity often involves comparing different PEFT approaches, such as LoRA and the proposed spectral adapter methods. A key finding might demonstrate that spectral methods possess a significantly higher rank capacity compared to traditional low-rank approaches like LoRA, given an equal number of trainable parameters. This advantage stems from the way spectral adapters leverage the spectral information of pretrained weights, allowing for a richer representation of the adaptation needed for new tasks. This increased capacity translates to improved performance and better generalization on downstream tasks, particularly beneficial when dealing with complex or high-dimensional data. However, it’s important to note that high rank capacity doesn’t guarantee superior performance; the quality of the learned adaptation is also influenced by factors like the optimization algorithm and the training data. Therefore, while high rank capacity is a desirable trait in a PEFT method, it should be considered in conjunction with other performance metrics for a comprehensive evaluation.
Subspace Alignment#
The concept of ‘Subspace Alignment’ in the context of fine-tuning large language models focuses on how the spectral information of pretrained weights relates to optimal neuron alignment. The core idea is that the top singular vectors of the pretrained weight matrices capture important directional information that aligns well with the ideal neuron directions for the downstream task. This alignment is crucial for efficient fine-tuning because it allows the model to adapt quickly without significantly disrupting the underlying structure learned during pre-training. The theoretical analysis likely involves demonstrating that the optimal neuron alignment resides within the subspace spanned by the top singular vectors, implying that focusing fine-tuning efforts on this subspace is more efficient and effective than randomly modifying weights across the entire space. This contrasts with methods that only consider magnitude, highlighting the potential benefits of leveraging spectral information. By aligning with this pre-trained subspace, the method avoids potentially destructive interference and improves overall parameter efficiency, enabling better performance with fewer trainable parameters. Empirical observations demonstrating superior performance compared to methods that ignore spectral information would strongly support this theoretical claim. The practical implications are significant, potentially leading to more efficient and robust fine-tuning methods for large models where computational resources are a critical constraint.
Multi-adapter Fusion#
Multi-adapter fusion, in the context of parameter-efficient fine-tuning (PEFT) methods for large language models (LLMs), addresses the challenge of effectively combining multiple adapters trained for different tasks or concepts. A naive approach of simply adding the adapters can lead to identity loss and concept binding, where individual concepts become blurred or entangled. The paper explores this problem, highlighting how spectral adaptation, specifically by distributing concepts across distinct spectral spaces of the pretrained weight matrices, offers an elegant solution. This is in contrast to prior methods such as gradient fusion or orthogonal adaptation, which often involve complex optimization procedures or manual intervention to preserve individual characteristics. Spectral adaptation provides a more efficient and natural way to fuse multiple adapters, maintaining distinct identities and leading to improved performance in downstream tasks, particularly in the realm of diffusion models, as demonstrated by experimental results. The underlying theoretical foundation suggests that spectral methods offer superior rank capacity compared to traditional techniques, further validating this innovative approach to adapter fusion.
Parameter Efficiency#
The concept of parameter efficiency is central to the paper, focusing on methods to reduce the number of trainable parameters in fine-tuning large language models (LLMs) and diffusion models. Low-Rank Adaptation (LoRA) is highlighted as a successful existing method. The paper introduces Spectral Adapters, which leverage the spectral information of pre-trained weight matrices to enhance parameter efficiency. Two mechanisms are proposed: additive tuning and orthogonal rotation of top singular vectors. Theoretical analysis shows that Spectral Adapters improve the rank capacity of low-rank adapters compared to LoRA, suggesting greater flexibility for adaptation with a fixed parameter budget. Empirical results demonstrate that Spectral Adapters achieve superior performance on various benchmarks, showcasing better parameter efficiency than LoRA and other techniques while also offering solutions for multi-adapter fusion. The approach’s practicality is further demonstrated by a low computational overhead, making it a promising avenue for efficient fine-tuning of massive models.
More visual insights#
More on figures
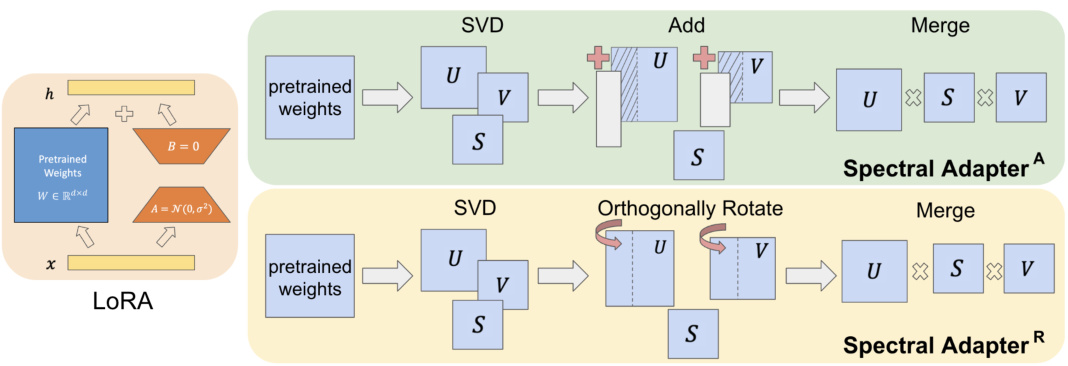
🔼 This figure illustrates the two proposed spectral adapter methods in comparison to the LoRA method. LoRA adds a low-rank trainable matrix to pretrained weights. In contrast, the Spectral AdapterA method additively tunes the top singular vectors (columns of U and V matrices from the SVD decomposition of the pretrained weight matrix W), and the Spectral AdapterR method orthogonally rotates those top singular vectors. Both methods leverage spectral information from the pretrained weights for efficient fine-tuning.
read the caption
Figure 2: Compared to LoRA which proposes to add low-rank trainable matrices to pretrained weights, we study two types of spectral adapters: Spectral AdapterA considers additively tuning the top columns of singular vector matrices and Spectral AdapterR considers orthogonally rotating the top columns of singular vector matrices.
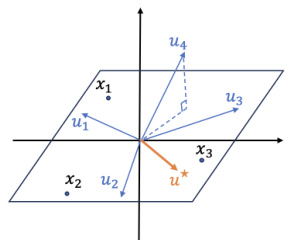
🔼 This figure illustrates the alignment of the top singular vector of pretrained weights with the ideal neuron direction in a simplified two-layer ReLU network. The data points are assumed to lie on a two-dimensional plane (xy-plane), representing a low-dimensional manifold. The pretrained neuron directions (u₁, u₂, u₃, u₄) are shown, with most lying in the xy-plane. However, due to optimization errors, some neurons deviate slightly from this plane. The top singular vector (u*) of the pretrained weight matrix W(1) is shown to align closely with the xy-plane, indicating that it recognizes the ideal neuron direction more accurately than individual pretrained neurons. This observation supports the choice of tuning the top singular vectors in the proposed spectral adaptation method.
read the caption
Figure 3: Top singular vector of pretrained weight recognizes more ideal neuron direction. Illustration plot for Section 3.2.
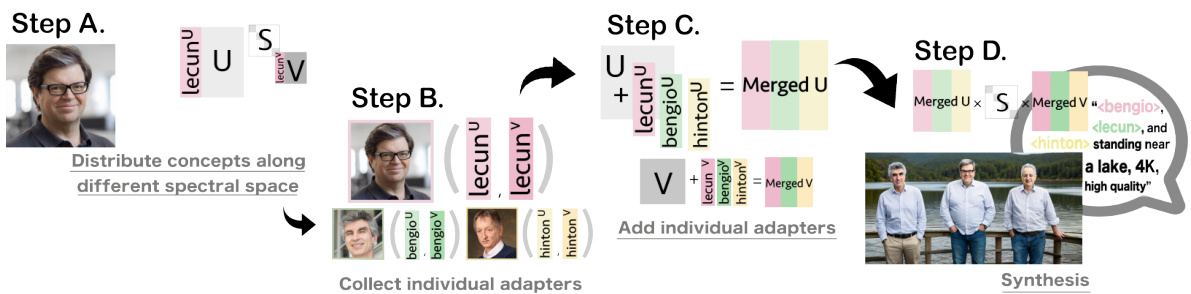
🔼 This figure illustrates the process of multi-adapter fusion using the proposed spectral adapter method. It shows how different concepts (e.g., images of three different people) can be incorporated into the spectral space of a pre-trained diffusion model without causing identity loss or concept mixing. The process involves distributing each concept along a different set of spectral dimensions, then collecting the individual adapters and adding them together to create the final merged adapter. This approach is contrasted with simpler methods of adapter fusion that struggle to maintain individual object characteristics.
read the caption
Figure 4: Distributing different concept tunings along different spectral space helps with identity preservation in multi-adapter fusion, see Section 4.2 for details.

🔼 This figure illustrates the proposed method for multi-adapter fusion in diffusion models. It shows how different concepts (e.g., different objects or characteristics) can be assigned to different parts of the spectral space of pretrained model weights. This allows the model to fine-tune multiple concepts simultaneously without interference or identity loss. The figure showcases a four-step process: (A) Separate concepts are initially encoded in different spectral spaces, (B) Individual spectral adapters are collected, (C) These adapters are added together, and (D) The merged spectral adapters are used for synthesis. This approach addresses the challenge of multi-adapter fusion in diffusion models, where simply adding adapters together often leads to problems like concept mixing or loss of identity.
read the caption
Figure 4: Distributing different concept tunings along different spectral space helps with identity preservation in multi-adapter fusion, see Section 4.2 for details.

🔼 This figure illustrates the architecture of the proposed Spectral Adapter and compares it with the LoRA method. LoRA adds a low-rank trainable matrix to the pretrained weights. In contrast, the Spectral Adapter has two variants: Spectral AdapterA, which additively tunes the top singular vectors of the pretrained weight matrix, and Spectral AdapterR, which orthogonally rotates them. Both methods utilize Singular Value Decomposition (SVD) of the pretrained weights before fine-tuning.
read the caption
Figure 2: Compared to LoRA which proposes to add low-rank trainable matrices to pretrained weights, we study two types of spectral adapters: Spectral AdapterA considers additively tuning the top columns of singular vector matrices and Spectral AdapterR considers orthogonally rotating the top columns of singular vector matrices.

🔼 This figure compares the generation results of various parameter-efficient fine-tuning (PEFT) methods on a custom vase concept using the Chilloutmix diffusion model. The x-axis represents the number of trainable parameters used, ranging from 1K to over 800K. Each column shows the generated vase images for a given method and parameter budget, demonstrating the impact of different PEFT methods on image generation quality and parameter efficiency. The reference column displays the actual images used for training. The alignment scores shown below each image indicate how well the generated image matches the reference images, illustrating the ability of each method to generate accurate and realistic vases with different levels of parameter usage. The Spectral Adapter consistently outperforms the other methods.
read the caption
Figure 6: Generation results for prompt “aon a table” after fine-tuning Chilloutmix diffusion model [1] on custom vase images with different PEFT methods. See Section 4.3 for details.

🔼 This figure compares the performance of various parameter-efficient fine-tuning (PEFT) methods on a custom vase concept generation task using the Chilloutmix diffusion model. The x-axis shows the number of trainable parameters used, while the y-axis implicitly represents the quality of the generated images. The results demonstrate that Spectral Adapter achieves comparable or better image generation quality with significantly fewer trainable parameters compared to other methods such as LoRA, OFT, LiDB, SVDiff, and VeRA. This highlights the effectiveness of Spectral Adapter in enhancing parameter efficiency for fine-tuning.
read the caption
Figure 6: Generation results for prompt “aon a table” after fine-tuning Chilloutmix diffusion model [1] on custom vase images with different PEFT methods. See Section 4.3 for details.
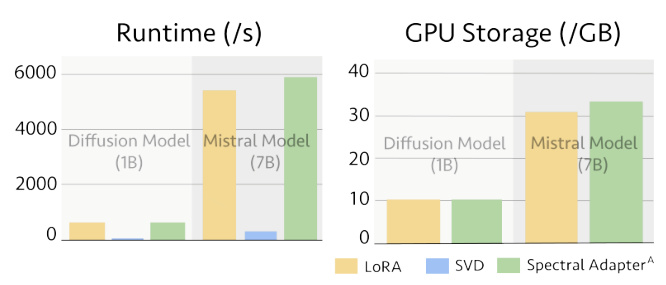
🔼 This figure compares the runtime and GPU storage costs of LoRA, SVD, and Spectral Adapter^ when fine-tuning a 1B parameter diffusion model and a 7B parameter Mistral language model. It demonstrates that Spectral Adapter^ incurs minimal additional overhead compared to LoRA, addressing potential concerns about the computational cost of the proposed method.
read the caption
Figure 8: Runtime and GPU storage cost plot. See Section 4.4 for details.
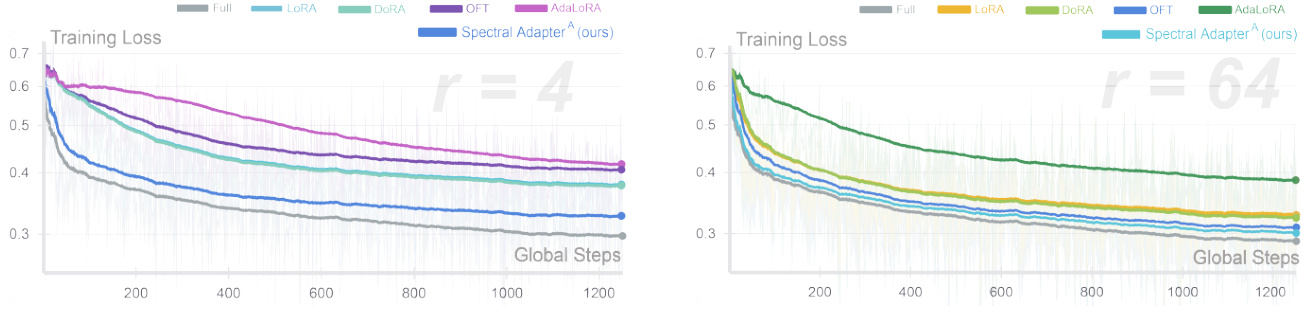
🔼 This figure shows the training loss curves for fine-tuning a Llama3 8B model on the Orca Math dataset using different parameter-efficient fine-tuning (PEFT) methods. The left panel shows results for a rank of 4, while the right panel shows results for a rank of 64. The figure demonstrates the impact of the number of trainable parameters on the training loss, and highlights that the proposed Spectral Adapter consistently outperforms other PEFT methods.
read the caption
Figure 9: More experiments with Llama3 8B model with different number of trainable parameters. In the left plot, the training loss of LoRA and DORA overlaps. See Appendix F.1 for details.
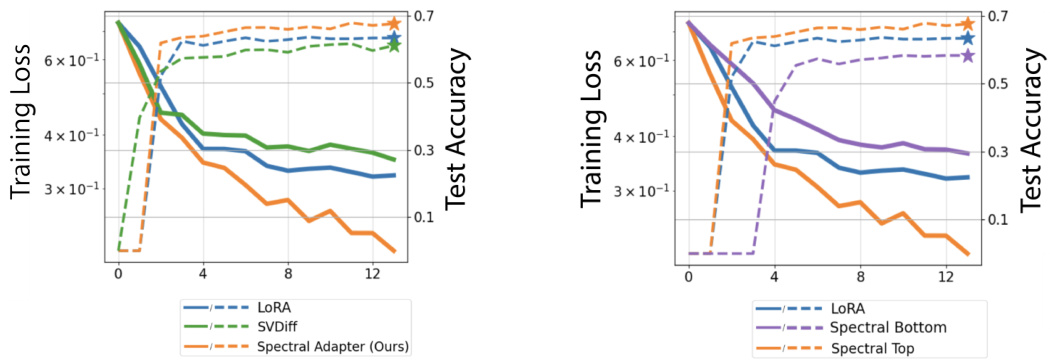
🔼 The figure shows the training loss curves and GSM8K accuracy for different parameter-efficient fine-tuning (PEFT) methods compared to full fine-tuning on the Llama 3 8B model using the Orca Math dataset. Spectral Adapter achieves results closest to full fine-tuning while maintaining minimal trainable parameters (0.23%).
read the caption
Figure 1: Training loss of fine-tuning Llama3 8B model with Orca Math dataset [38] and evaluation score on GSM8K benchmark [8]. We follow experimental setup in [53], see Appendix F.1 for details. All methods except full fine-tuning maintain approximately 0.23% trainable parameters.

🔼 This figure compares the generation results of four different methods: LoRA, Orthogonal Adaptation, Spectral Adapter (top ranks), and Spectral Adapter (bottom ranks). Each method was used for single toy concept tuning, and the results for four different prompts are shown. The prompts describe various scenarios involving different toys. The ‘reference’ row shows images of the four toys, which serve as the basis for comparison. The figure aims to illustrate that the spectral adapter performs better than the other methods when only tuning the top ranks of singular values, as shown in the caption.
read the caption
Figure 11: Generation results for single toy concept tuning with LoRA, Orthogonal Adaptation, and Spectral Adapter4 with top and bottom ranks tuned respectively.

🔼 This figure compares the image generation results of three different fine-tuning methods: LoRA, Orthogonal Adaptation, and Spectral Adapter (with top and bottom ranks). Each method was used to fine-tune a diffusion model on three individual animal concepts (dog1, cat, dog2). The prompts used varied the animal’s activity and location. The ‘reference’ row shows the original images used for training. The results demonstrate the effectiveness of the Spectral Adapter (particularly when tuning the top ranks) in generating images that are more aligned with the prompts compared to the other methods. Orthogonal Adaptation shows some success, but less overall than Spectral Adapter.
read the caption
Figure 12: Generation results for single animal concept tuning with LoRA, Orthogonal Adaptation, and Spectral AdapterA with top and bottom ranks tuned respectively.

🔼 This figure demonstrates the results of multi-object generation using the Chilloutmix diffusion model. Four custom toy concepts were used, each tuned with different adapters. The figure compares results from four different fusion methods: Gradient Fusion, FedAvg, Orthogonal Adaptation, and the proposed Spectral Adapter. The goal is to show how well each method preserves individual object identities while fusing multiple adapters. Each row displays the generated images from a different method for three different prompts. The ‘reference’ column shows the real-world toy images used as the training data.
read the caption
Figure 13: Generation results of Chilloutmix diffusion model [1] tuned on four custom toy concepts with different fused adapters. See Appendix F.5.2 for details.

🔼 This figure shows the results of generating images of three computer scientists (Yoshua Bengio, Yann LeCun, and Geoffrey Hinton) using a diffusion model fine-tuned with different multi-adapter fusion methods. The methods compared are Gradient Fusion, FedAvg, Orthogonal Adaptation, and the proposed Spectral Adapter. The prompt used was: ’’’
and and , standing near a lake, 4K, high quality, high resolution.’’’. The figure demonstrates the ability of the Spectral Adapter to generate images with clearer and more consistent styles across characters compared to the other methods. Appendix F.5.2 provides further details on the experimental setup. read the caption
Figure 14: Generation results of Chilloutmix diffusion model [1] tuned on photos of three computer scientists with different fused adapters. See Appendix F.5.2 for details.

🔼 This figure compares the performance of various parameter-efficient fine-tuning (PEFT) methods on a custom vase concept generation task using the Chilloutmix diffusion model. Different methods are compared at various parameter budgets (1k, 20k, 100k, 200k, 300k, 400k, 500k, and >800k parameters). The results show generated images for each method and parameter budget, along with the alignment score reflecting how well the generated image matches the reference image. The figure highlights the ability of Spectral Adapter to generate high-quality images with fewer trainable parameters compared to other methods.
read the caption
Figure 6: Generation results for prompt “aon a table” after fine-tuning Chilloutmix diffusion model [1] on custom vase images with different PEFT methods. See Section 4.3 for details.
More on tables
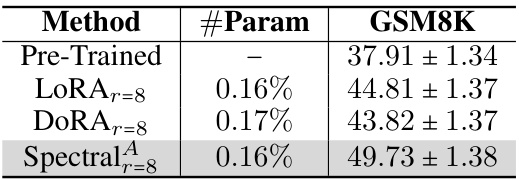
🔼 This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods on the GSM8K benchmark when fine-tuning the Mistral 7B language model. The methods compared include LoRA, DoRA, and the proposed Spectral Adapter. The table shows the accuracy achieved by each method, along with the percentage of trainable parameters used relative to the full model. The results indicate that the Spectral Adapter achieves the highest accuracy with a comparable number of parameters to LoRA.
read the caption
Table 2: Accuracy comparison of fine-tuning Mistral 7B model with different PEFT methods on GSM8K benchmark. See Section 4.1 for experimental details.

🔼 This table compares different parameter-efficient fine-tuning (PEFT) methods in terms of their parameter efficiency and granularity. It shows the number of trainable parameters required by each method (LoRA, SVDiff, LiDB, OFT, VeRA, and Spectral AdapterR), the granularity of the parameter budget (how finely the number of parameters can be adjusted), and whether auxiliary parameters are required. Spectral AdapterR offers a good balance between parameter efficiency and granularity.
read the caption
Table 3: Baseline methods comparison for parameter efficiency. Granularity indicates number of trainable parameter budgets available. See Section 4.3 for details.
🔼 This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark when fine-tuning the DeBERTaV3-base model. The methods compared include LoRA, DORA, OFT, AdaLoRA, and the proposed Spectral Adapter. The table shows the accuracy achieved by each method on various GLUE tasks (MNLI, SST-2, MRPC, COLA, QNLI, QQP, RTE, and STS-B) along with the number of trainable parameters used. The results demonstrate the superior performance and parameter efficiency of the proposed Spectral Adapter4.
read the caption
Table 1: Accuracy comparison of fine-tuning DeBERTaV3-base with various PEFT methods on GLUE benchmarks. Spectral is abbreviation for Spectral Adapter4. See Section 4.1 for experimental details.

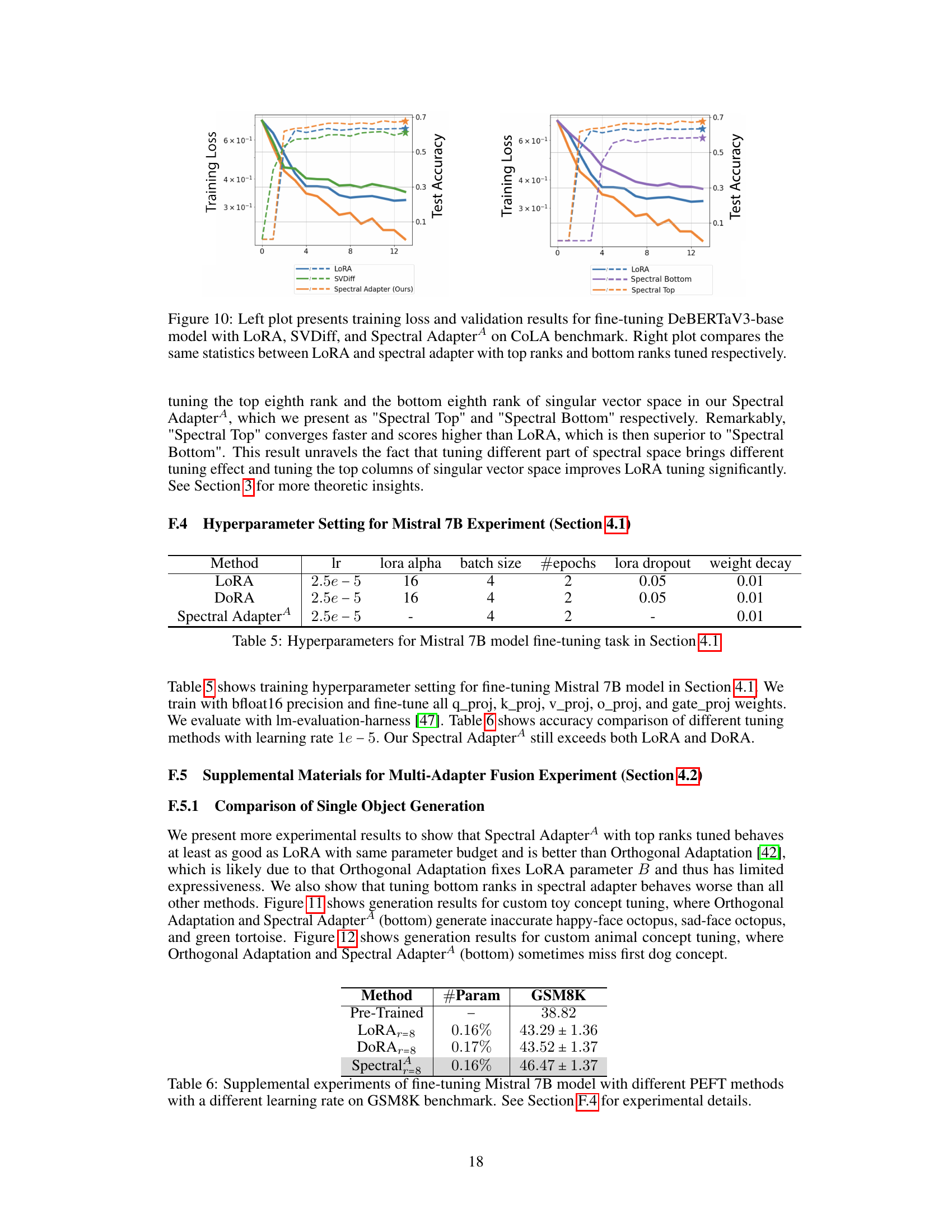
🔼 This table displays the hyperparameter settings used for fine-tuning the Mistral 7B language model in Section 4.1 of the paper. It includes the learning rate, LoRA alpha, batch size, number of epochs, LoRA dropout rate, and weight decay for LoRA, DoRA, and the proposed Spectral Adapter method. Note the absence of a LoRA alpha value for the Spectral Adapter, indicating a difference in hyperparameter optimization for this method compared to the others.
read the caption
Table 5: Hyperparameters for Mistral 7B model fine-tuning task in Section 4.1
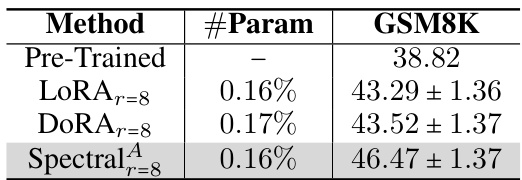
🔼 This table presents the results of fine-tuning the Mistral 7B language model on the GSM8K benchmark using different parameter-efficient fine-tuning (PEFT) methods. The methods compared are LoRA, DoRA, and the proposed Spectral Adapter. The table shows the accuracy achieved by each method, along with the number of trainable parameters used as a percentage of the total model parameters. The results demonstrate the superior performance of the Spectral Adapter in achieving higher accuracy with a comparable number of trainable parameters.
read the caption
Table 2: Accuracy comparison of fine-tuning Mistral 7B model [23] with different PEFT methods on GSM8K benchmark. See Section 4.1 for experimental details.

🔼 This table compares different parameter-efficient fine-tuning (PEFT) methods in terms of their parameter efficiency. It shows the number of trainable parameters required for each method, categorized by the granularity of parameter tuning (how many parameters are adjusted). The table highlights the parameter efficiency improvement of Spectral AdapterR compared to other baselines, including LoRA, SVDiff, LiDB, OFT, and VeRA. It also includes an ‘Auxiliary Param’ column to indicate if any auxiliary parameters are used.
read the caption
Table 3: Baseline methods comparison for parameter efficiency. Granularity indicates number of trainable parameter budgets available. See Section 4.3 for details.
🔼 This table presents the hyperparameter settings used for the Spectral AdapterR model in the diffusion model fine-tuning experiments described in Section 4.3 of the paper. It details the learning rates for both the ’text’ and ‘unet’ components of the model for different rank values (r) across three different concepts (vase, chair, table). The variations in learning rates across the concepts and ranks highlight the model’s adaptability and the influence of hyperparameter tuning on performance.
read the caption
Table 8: Hyperparameters for Spectral AdapterR for diffusion model fine-tuning task in Section 4.3
Full paper#