TL;DR#
Current methods for 3D reconstruction of dynamic scenes struggle with handling complex interactions between multiple objects, often relying on template models or requiring additional inputs like depth or optical flow. These approaches frequently result in lengthy training times and struggle to generalize well. Template-based methods lack the flexibility needed to reconstruct diverse real-world scenes accurately.
This research introduces TFS-NeRF, a template-free approach using an invertible neural network (INN) to predict linear blend skinning weights efficiently. By disentangling entity motions and using semantic-aware ray sampling, TFS-NeRF generates high-quality, semantically separable 3D reconstructions. Extensive experiments demonstrate significant improvements in reconstruction accuracy and training efficiency compared to existing methods. TFS-NeRF’s template-free nature and efficient INN-based approach enable superior generalizability and improved reconstruction quality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, efficient method for 3D reconstruction of dynamic scenes with interacting entities. This addresses a significant challenge in computer vision and has implications for AR/VR, robotics, and other fields. The use of invertible neural networks and semantic-aware ray sampling improves efficiency and accuracy, setting a new standard for dynamic scene reconstruction. The work also opens avenues for future research on more complex interactions and improved generalization.
Visual Insights#
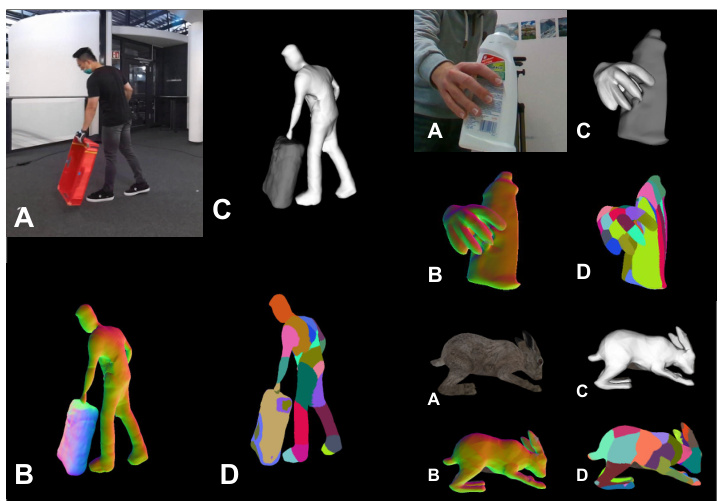
🔼 This figure demonstrates the shortcomings of existing dynamic-NeRF models in reconstructing complex, interactive dynamic scenes. It highlights the challenge of accurately representing the geometry of interacting entities (humans and objects) from limited video input. The proposed TFS-NeRF model aims to address these limitations by generating a more realistic and semantically consistent 3D reconstruction using sparse/single-view RGB videos, achieving plausible geometry for each individual semantic element.
read the caption
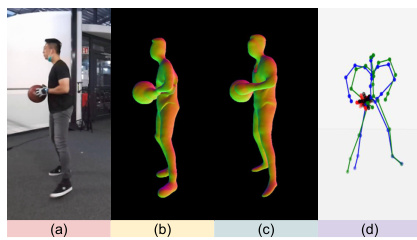
Figure 1: Existing dynamic-NeRF models struggle to generate plausible 3D reconstructions for generic dynamic scenes featuring humans and objects engaged in complex interactions. In this work, we introduce a Neural Radiance Field model designed for 3D reconstruction of such generic scenes, captured using a sparse/single-view video, capable of producing plausible geometry for each semantic element within the scene. In this figure, A: Input RGB, B: predicted normal map, C: predicted semantic reconstruction, and D: predicted skinning weight.

🔼 This table compares the proposed TFS-NeRF method with existing dynamic NeRF methods. The comparison is based on three key aspects: whether the method is template-free, whether it relies on pre-trained features, and the number of entities it can reconstruct (single vs. multiple). This helps to highlight the novelty and advantages of TFS-NeRF, particularly its ability to handle multiple interacting entities in a template-free manner without the need for pre-trained features.
read the caption
Table 1: Our approach vs. existing dynamic NeRFs.
In-depth insights#
Template-Free NeRF#
Template-free NeRFs represent a significant advancement in neural radiance field (NeRF) technology by removing the reliance on pre-defined template models, such as SMPL for human bodies. This frees NeRFs from the limitations of template-based approaches, enabling them to generalize to a broader range of objects and dynamic scenes. The key advantage lies in their ability to handle arbitrary deformable entities and complex interactions between multiple objects, overcoming the limitations of template-based methods which often struggle to represent diverse shapes and motions accurately. Template-free NeRFs learn the underlying geometry and deformation directly from data, usually sparse or single-view RGB videos, without relying on additional inputs like depth maps or optical flow. However, template-free methods often introduce challenges related to training efficiency as they typically require intricate optimization techniques, such as iterative root-finding methods, leading to increased computational cost and training times. Research efforts are focused on addressing these efficiency challenges through techniques like invertible neural networks to bypass computationally expensive processes and disentangling the motions of interacting objects. These improvements promise accurate and semantically separable 3D reconstruction, showcasing the considerable potential of template-free NeRFs for applications demanding high-fidelity representation of dynamic scenes.
INN for LBS#
Utilizing an Invertible Neural Network (INN) for Linear Blend Skinning (LBS) weight prediction offers a significant advantage in dynamic scene reconstruction. Traditional methods often rely on iterative root-finding algorithms, which are computationally expensive and slow to converge. The INN approach, however, learns a direct mapping between deformed and canonical spaces, bypassing the iterative process and significantly improving training efficiency. This is crucial for handling complex interactions between multiple objects in dynamic scenes, where accurate and detailed representation of motion is paramount. Disentangling entity motions and optimizing per-entity skinning weights further enhances the quality and semantic separability of the reconstruction. By employing an INN, the method overcomes a key computational bottleneck inherent in prior template-free methods, thereby making high-quality dynamic scene reconstruction with accurate articulation of multiple entities computationally feasible and practical. The INN’s inherent bijectivity ensures a robust and accurate transformation, contributing to the overall accuracy and efficiency of the 3D reconstruction.
Semantic Reconstruction#
Semantic reconstruction in 3D scene understanding aims to generate meaningful and labeled 3D models, going beyond simple geometric representation. It involves assigning semantic labels (e.g., ‘human’, ‘chair’, ’table’) to different parts of the reconstructed scene. This is crucial for higher-level tasks such as scene understanding, object manipulation, and human-robot interaction. The challenge lies in accurately segmenting and classifying different objects, especially in dynamic scenes where objects interact and occlude each other. Techniques for semantic reconstruction often leverage deep learning methods, such as convolutional neural networks (CNNs) and neural radiance fields (NeRFs), to learn complex relationships between visual data and semantic labels. Data quality, including accurate semantic annotations, significantly influences performance. Furthermore, the computational cost of creating high-fidelity, semantically-rich 3D models can be substantial, requiring efficient algorithms and hardware. Future research will likely explore more robust and efficient algorithms that handle complex scenarios such as dynamic objects and significant occlusions, leading to applications in augmented reality, robotics, and autonomous driving.
Dynamic Scene#
The concept of ‘Dynamic Scene’ in a research paper likely encompasses the challenges and opportunities in representing and reconstructing scenes with moving elements. This would necessitate addressing temporal consistency, ensuring that the scene’s evolution over time is accurately and smoothly depicted. Methods for handling object interactions—collisions, occlusions, and interdependence of movement—are critical. The reconstruction process may involve techniques like neural radiance fields (NeRFs), but would need significant adaptations to manage the time-varying nature of the scene. The research would likely explore efficient computational approaches to process sequences of images or videos and might focus on semantic segmentation, providing a meaningful labeling of different objects within the scene. Generalizability to diverse scenes and object types would be a key evaluation criterion, along with the quality of the reconstruction and the accuracy of the portrayal of movement and interaction.
Multi-Entity Interaction#
The concept of ‘Multi-Entity Interaction’ in a research paper would explore scenarios involving interactions between multiple entities, possibly of different types (rigid, non-rigid, deformable). A key challenge is handling complex relationships and dependencies between these entities. The paper likely investigates novel methods to model and reconstruct these interactions. Disentangling individual entity motions while considering their mutual influences and occlusions would be a core focus. The analysis likely involves novel representations to capture the dynamic geometry, semantic information of each entity, and techniques for efficient training and inference. The paper might propose new loss functions or network architectures designed to achieve accurate and semantically separable reconstructions, which might also address efficiency in handling interactions of multiple entities in complex dynamic scenes. Evaluation metrics would then assess the accuracy and efficiency of proposed methods, potentially involving ground-truth comparisons or qualitative assessments of reconstructed geometries.
More visual insights#
More on figures
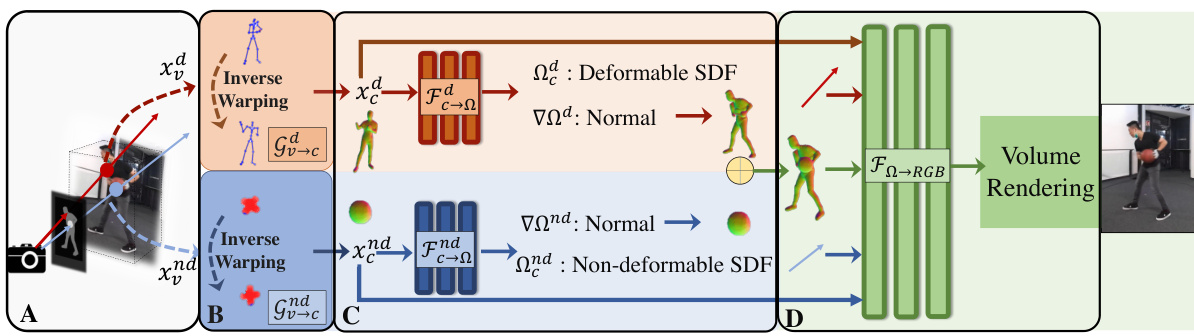
🔼 This figure illustrates the proposed TFS-NeRF framework. It consists of four stages: semantic-aware ray sampling, inverse warping, SDF prediction, and volume rendering. The framework uses semantic segmentation to separate interacting entities and learns forward Linear Blend Skinning (LBS) via an invertible neural network (INN). It generates semantically separable 3D reconstructions from sparse/single-view RGB videos, effectively handling dynamic scenes with interacting objects.
read the caption
Figure 2: Overview of the system. A: To produce a semantically separable reconstruction of each element, first, we perform a semantic-aware ray sampling. Given a 2D semantic segmentation mask, we shoot two sets of rays and sample two sets of 3D points for differentiating the deformable and non-deformable entities of the scene, {xd}i, {xnd}i under interactions. B: Next, each set of points is transformed from the deformed/view space (input frame) to its respective canonical space by inverse warping enabled by the learned forward LBS (Details are presented in Fig. 3. C: Then the individual geometry is predicted at the canonical space in the form of canonical SDFs by two independent SDF prediction networks Fd->(θd), Fnd->(θnd) for the deformable and non-deformable entities denoted as j ∈ {d, nd}. D: Finally, the output SDFs are used to predict a composite scene rendering. Both these branches are optimized jointly using the RGB reconstruction loss.

🔼 This figure illustrates the process of transforming points from view space to canonical space using an Invertible Neural Network (INN). The INN takes the deformed space points (xv) and the pose of the 3D skeleton (Jp) as input. An initial transformation is applied to estimate the canonical space points (xinit), which are then used as input to the INN. The INN learns a bijective mapping between view space and canonical space. The skinning weights (ws) are predicted by a separate Multilayer Perceptron (MLP) that takes the transformed canonical points as input. Finally, the canonical points are transformed back to the deformed space using inverse warping.
read the caption
Figure 3: Overview of the transformation from view space to canonical space.
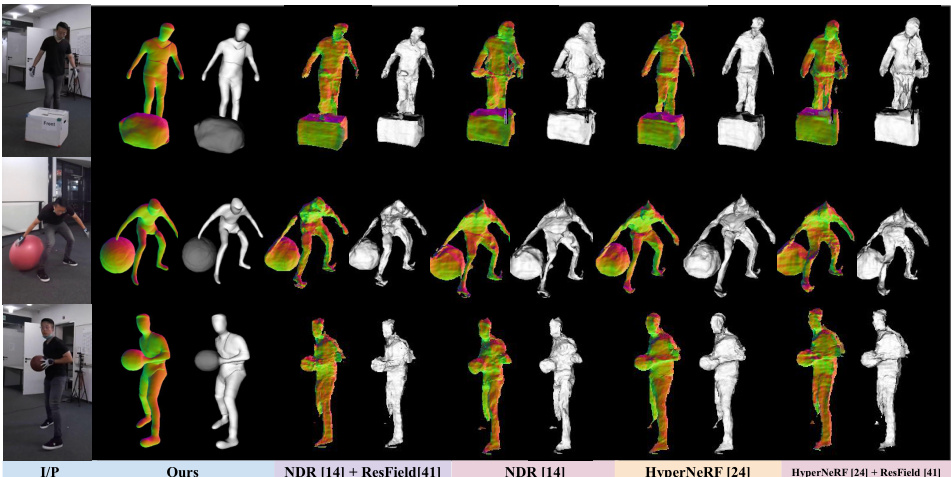
🔼 This figure compares the qualitative results of the proposed TFS-NeRF method against other state-of-the-art methods on the BEHAVE dataset. The top row shows input images, while the subsequent rows display 3D reconstructions generated by different methods for three distinct interaction scenarios involving humans and objects (a person standing on a box, a person interacting with a ball, and a person holding a basketball). The figure visually demonstrates the superior quality and accuracy of the TFS-NeRF reconstructions compared to the alternatives, particularly in handling complex interactions and object deformations.
read the caption
Figure 5: Qualitative comparison with SoTA methods on BEHAVE dataset.
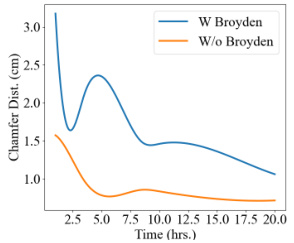
🔼 This figure compares the convergence speed of the proposed INN-based method with the Broyden method for learning the forward LBS (Linear Blend Skinning). The x-axis represents training time in hours, and the y-axis shows the Chamfer distance (a metric for evaluating the accuracy of 3D reconstruction). The graph clearly demonstrates that the INN method (W/o Broyden) converges significantly faster than the Broyden method (W Broyden), achieving lower Chamfer distance in a shorter period. This highlights the efficiency gain of the proposed INN-based approach.
read the caption
Figure 7: INN vs Broyden formulation.

🔼 This figure shows a comparison between the results of existing dynamic-NeRF models and the proposed model. The existing models struggle to generate plausible 3D reconstructions of dynamic scenes with interacting humans and objects. The proposed model, on the other hand, is able to generate plausible geometry for each semantic element in the scene, even when there are complex interactions between the entities.
read the caption
Figure 1: Existing dynamic-NeRF models struggle to generate plausible 3D reconstructions for generic dynamic scenes featuring humans and objects engaged in complex interactions. In this work, we introduce a Neural Radiance Field model designed for 3D reconstruction of such generic scenes, captured using a sparse/single-view video, capable of producing plausible geometry for each semantic element within the scene. In this figure, A: Input RGB, B: predicted normal map, C: predicted semantic reconstruction, and D: predicted skinning weight.
🔼 This figure demonstrates the limitations of existing dynamic-NeRF models in reconstructing complex dynamic scenes with interacting entities. It highlights the challenge of generating accurate 3D reconstructions, especially when dealing with both humans and objects interacting. The figure shows an example of input RGB images and compares them with the output from existing models, showcasing limitations in generating plausible geometries and semantic separation. The authors’ proposed model addresses these shortcomings and produces better results as described in the paper.
read the caption
Figure 1: Existing dynamic-NeRF models struggle to generate plausible 3D reconstructions for generic dynamic scenes featuring humans and objects engaged in complex interactions. In this work, we introduce a Neural Radiance Field model designed for 3D reconstruction of such generic scenes, captured using a sparse/single-view video, capable of producing plausible geometry for each semantic element within the scene. In this figure, A: Input RGB, B: predicted normal map, C: predicted semantic reconstruction, and D: predicted skinning weight.
More on tables
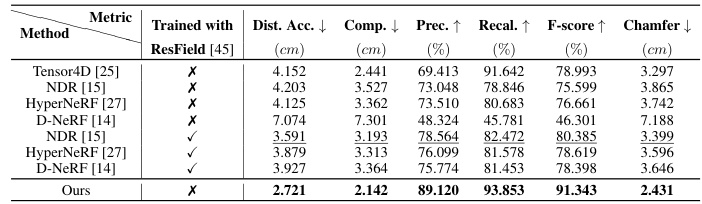
🔼 This table presents a quantitative comparison of different methods for 3D scene reconstruction on the BEHAVE dataset. It shows the performance of various methods, including the proposed TFS-NeRF, on metrics such as Average Distance Accuracy (Dist. Acc.), Completeness, Precision, Recall, F-score, and Chamfer Distance. The methods are evaluated both with and without using ResField layers to highlight the impact of incorporating temporal residual layers for handling complex temporal motions. The table provides a comprehensive evaluation of the reconstruction accuracy and effectiveness of each method.
read the caption
Table 3: Scene reconstruction results on BEHAVE [31] dataset.

🔼 This table presents a quantitative comparison of different methods for scene reconstruction on the BEHAVE dataset. It shows the performance of various methods, including the authors’ proposed method, across several metrics: Average Distance Accuracy (Dist. Acc.), Completeness, Precision, Recall, F-score, and Chamfer distance. The table is divided into two sections: one for results without using the ResField [45] and another section for results with ResField. The results highlight the superior performance of the authors’ method in terms of holistic scene reconstruction accuracy.
read the caption
Table 3: Scene reconstruction results on BEHAVE [31] dataset.

🔼 This table presents a quantitative comparison of the proposed TFS-NeRF method against two baseline methods (NDR [15] and HyperNeRF [27], both trained with ResField [45]) on the HO3D-V3 dataset [44] for hand-object reconstruction. The metrics used for evaluation include Average Distance Accuracy (Dist. Acc.), F-score, and Chamfer distance for both hand and object reconstruction. The table highlights the superior performance of TFS-NeRF in achieving high accuracy and detail in both hand and object reconstructions.
read the caption
Table 4: Reconstruction results on HO3D-V3 dataset [44].

🔼 This table presents a quantitative comparison of the proposed TFS-NeRF method against two baseline methods, TAVA and AnimatableNeRF, for human and animal reconstruction tasks. The upper section shows results on the ZJU-MoCap dataset, while the lower section shows results on a synthetic animal dataset. Metrics include Distance Accuracy (Dist. Acc.), Completeness (Comp.), Precision (Prec.), Recall (Recal.), F-score, and Chamfer distance (Chamfer). Lower values for Dist. Acc. and Chamfer indicate better performance. Higher values for Prec., Recal., and F-score also indicate better performance.
read the caption
Table 5: Reconstruction on ZJU-Mocap (upper) [9, 46] and synthetic animal dataset [28] (lower).

🔼 This table presents the ablation study results focusing on holistic reconstruction performance on the BEHAVE dataset. It shows the impact of different design choices and loss functions on the key metrics: Distance Accuracy (Dist. Acc.), F-score, and Chamfer distance. The ablation experiments systematically remove or modify certain components of the proposed TFS-NeRF method to isolate their contributions and understand their influence on the final reconstruction quality. The rows represent different configurations, and the columns represent the performance metrics.
read the caption
Table 6: Ablation on BEHAVE for holistic reconstruction.

🔼 This table presents a quantitative analysis of the model’s performance on the BEHAVE dataset, comparing reconstruction results using ground truth masks and poses against those using predicted masks and poses. It assesses the impact of using predicted data (from object detection and pose estimation models) rather than ground truth information on the accuracy of 3D reconstruction of humans, objects, and the entire scene. Metrics such as Distance Accuracy (Dist. Acc.), Completeness (Comp.), Precision (Prec.), Recall (Recal.), F-score, and Chamfer Distance (Chamfer) are used to evaluate the reconstruction quality in different scenarios.
read the caption
Table 8: Reconstruction results on the BEHAVE dataset with predicted semantic masks and predicted pose.
Full paper#



















