TL;DR#
Deep learning is currently constrained by the high cost and inefficiency of using large datasets. This paper investigates the efficiency properties of data from both optimization and generalization perspectives. It points out the limitations of self-supervised learning and dataset distillation approaches to solve this issue.
The paper introduces RELA, a novel method that uses a publicly available pre-trained model to create efficient training data. This significantly accelerates representation learning, demonstrated by reducing computational costs by 50% while maintaining accuracy on ImageNet-1K. RELA is shown to outperform existing methods across various self-supervised learning algorithms and datasets, showcasing its versatility and potential to transform the efficiency of representation learning in deep learning. The findings reveal that modifications to data can significantly influence the optimization of model training.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of data inefficiency in deep learning, offering a novel approach to accelerate training. It’s highly relevant to current trends in self-supervised learning and dataset distillation. The proposed method, RELA, provides a practical solution with potential for significant impact across various deep learning tasks. It also opens up new research avenues in data optimization and efficient representation learning.
Visual Insights#

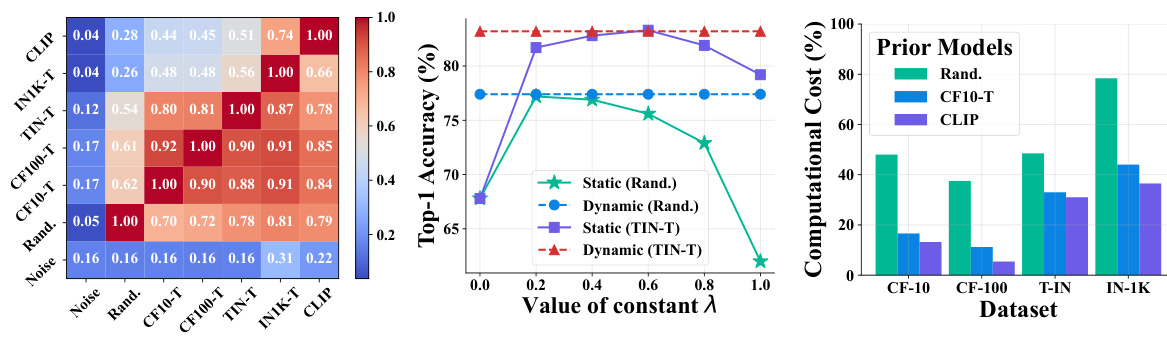
🔼 This figure illustrates the framework and intuition behind the RELA method. The framework shows RELA working in two stages: first optimizing data using a pre-trained model and a dataset, and then accelerating learning algorithms using this optimized data. The intuition section demonstrates how RELA creates a shortcut in the learning process by using efficient data to enable faster convergence towards the optimal representation.
read the caption
Figure 1: Framework and Intuition of RELA: (1) Framework: RELA serves as both a data optimizer and an auxiliary accelerator. Initially, it operates as a data optimizer by leveraging an dataset and a pre-trained model (e.g., one sourced from online repositories) to generate an efficient dataset. Subsequently, RELA functions as an auxiliary accelerator, enhancing existing (self-)supervised learning algorithms through the effective utilization of the efficient dataset, thereby promoting efficient representation learning. (2) Intuition: The central concept of RELA is to create an efficient-data-driven shortcut pathway within the learning process, enabling the initial model $ to rapidly converge towards a 'proximal representation ' of the target model $* during the early stages of training. This approach significantly accelerates the overall learning process.
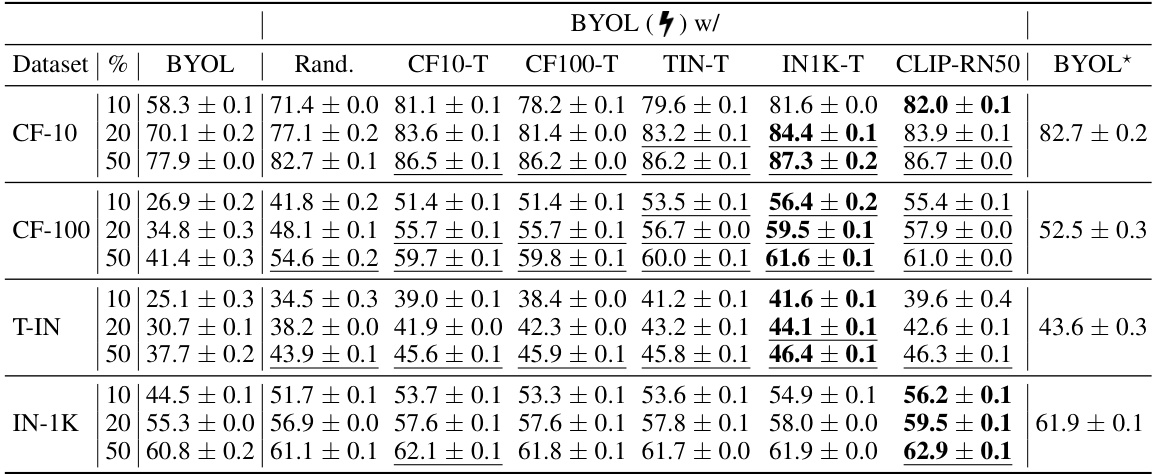
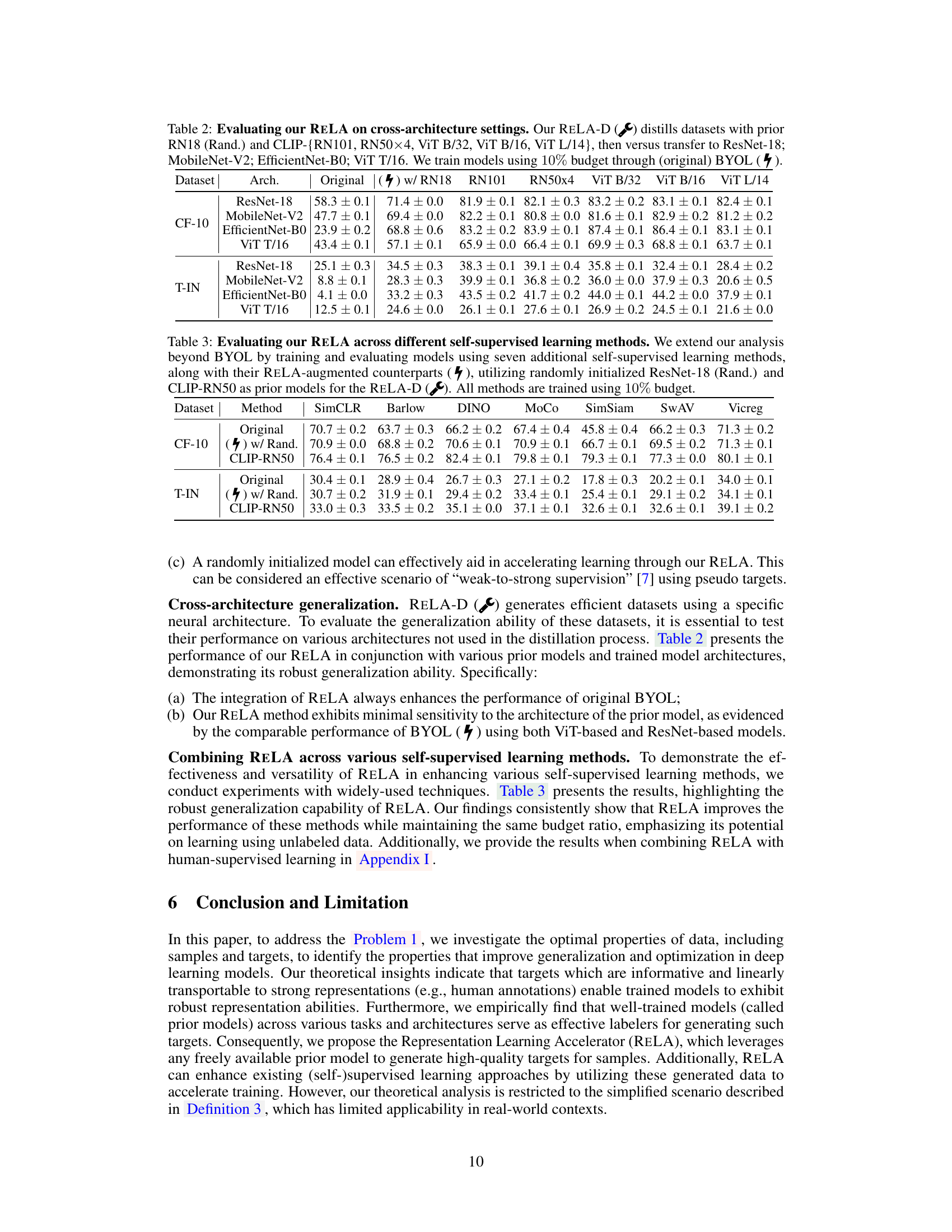
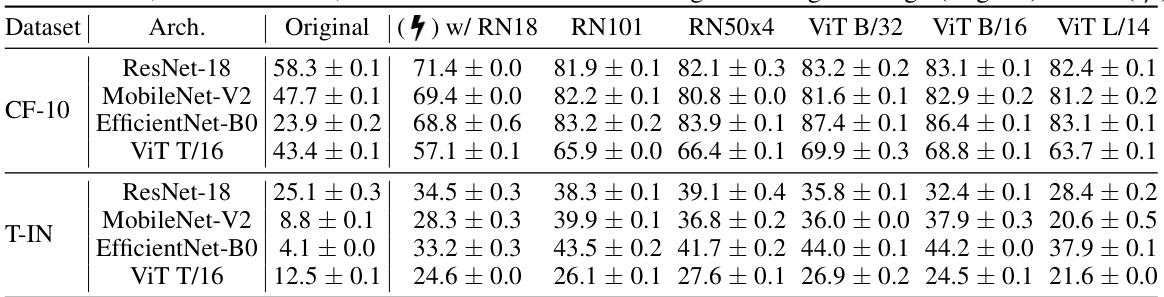
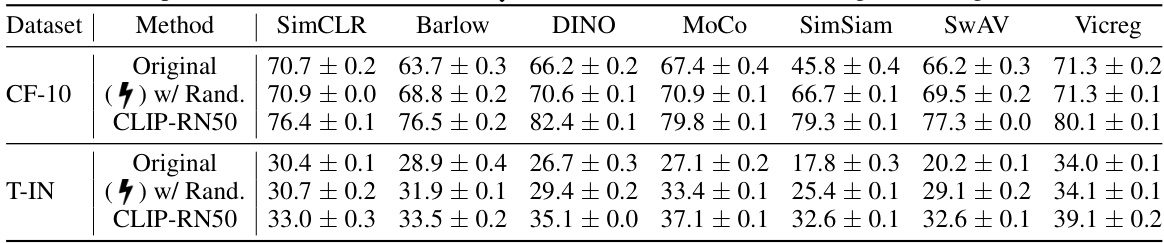
🔼 This table benchmarks the proposed RELA method against the baseline BYOL method across four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-1K) and varying training budget percentages (10%, 20%, 50%). It compares the performance of BYOL trained with different prior models used by RELA, including randomly initialized networks and those pre-trained on other datasets. The results highlight the impact of different prior models on RELA’s performance relative to BYOL trained with a full budget.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
In-depth insights#
Efficient Data#
The concept of ‘Efficient Data’ in machine learning research centers around the idea of using data more effectively, minimizing resource consumption while maximizing model performance. This involves strategies to reduce the quantity of data needed (data condensation), improve data quality (noise reduction, data augmentation refinement), or better utilize existing datasets (transfer learning, multi-task learning). Data efficiency is critical due to the ever-increasing cost of data acquisition, annotation, and storage. Effective strategies for efficient data leverage pre-trained models, theoretical analyses of data properties to accelerate training or improve generalization. Optimizing data representation and efficient data generation are also important considerations, as is establishing bounds for generalization performance using the more efficient data. Ultimately, the quest for ’efficient data’ drives innovation in representation learning, leading to more sustainable and scalable AI systems.
RELA Framework#
The RELA framework, designed to accelerate representation learning, cleverly leverages readily available pre-trained models as a catalyst for generating efficient training data. Its core innovation lies in recognizing that these ‘prior models’ effectively produce efficient data by informing the training process. Instead of relying on extensive, computationally expensive dataset distillation, RELA optimizes data properties, such as minimizing variance and preventing noisy mappings between samples and targets, leading to quicker convergence. RELA’s two-stage approach first uses a prior model to optimize data, creating a shortcut path toward the target representation. Subsequently, it seamlessly integrates with existing self-supervised learning algorithms, dynamically adjusting its contribution to accelerate the learning process. This framework is particularly valuable because it enhances efficiency without sacrificing accuracy, offering a potential solution to the data scalability challenges hindering the advancement of machine learning models.
Data Properties#
The concept of ‘Data Properties’ in machine learning is crucial for model efficiency and generalization. The paper investigates how inherent data characteristics, like variance and label accuracy, influence training dynamics. Lower variance data, for example, facilitates faster convergence, as demonstrated empirically and theoretically. The study uncovers the significance of creating a bijective mapping between samples and targets, suggesting the avoidance of noisy data mappings through refinement techniques. Optimal data exhibits a clear, one-to-one relationship between data points and labels, which isn’t always present in real-world datasets. By understanding and manipulating these properties, the research proposes methods to synthesize efficient training datasets, accelerating model training without compromising accuracy. This highlights the untapped potential of optimizing data quality to improve learning efficiency. The paper also establishes generalization bounds for models trained on such optimized data, providing a theoretical framework for this data-centric approach to representation learning.
Generalization Bounds#
Generalization bounds in machine learning offer a crucial way to theoretically analyze the gap between a model’s performance on training data and its performance on unseen data. A tight generalization bound provides confidence that a model’s performance won’t significantly degrade when it encounters new, previously unseen examples. The paper likely explores how data properties impact generalization ability. Efficient data, while potentially reducing training time, might not guarantee good generalization unless specific conditions regarding data distribution and model capacity are met. The theoretical framework presented likely involves bounding generalization error using techniques such as Rademacher complexity or VC dimension, possibly relating these bounds to characteristics of the optimized efficient data (e.g., variance, distribution similarity to the original data). The results likely demonstrate a trade-off between efficiency and generalization: optimized data may enhance training efficiency but at the cost of slightly reduced generalization performance, offering valuable insights into practical data-driven model optimization.
Future Work#
The paper’s core contribution is a novel method, RELA, that leverages pre-trained models to accelerate representation learning. Future research could explore several promising avenues. One is to investigate RELA’s performance with more complex and larger-scale datasets, moving beyond the four datasets used in the paper. Another is to conduct a more extensive comparison with state-of-the-art data-efficient techniques, including those not directly comparable to the self-supervised learning methods considered. The theoretical analysis could be expanded beyond the simplified bimodal Gaussian distribution scenario to offer a more generalizable understanding of data properties. A crucial area to explore is developing more sophisticated adaptive strategies for the weighting coefficient (λ) in RELA. Finally, investigating the potential of RELA in other machine learning tasks, such as natural language processing, and exploring its applicability in other domains beyond image recognition would be beneficial. This would further solidify RELA’s versatility and effectiveness in broader contexts.
More visual insights#
More on figures
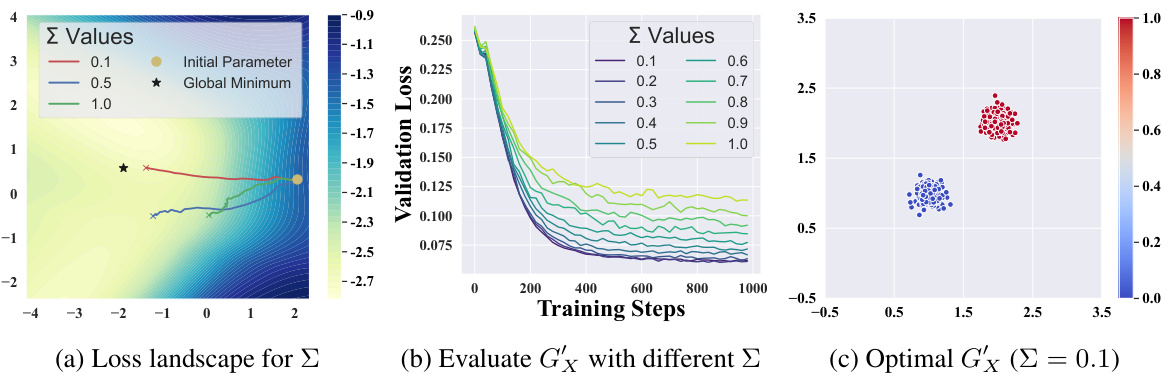
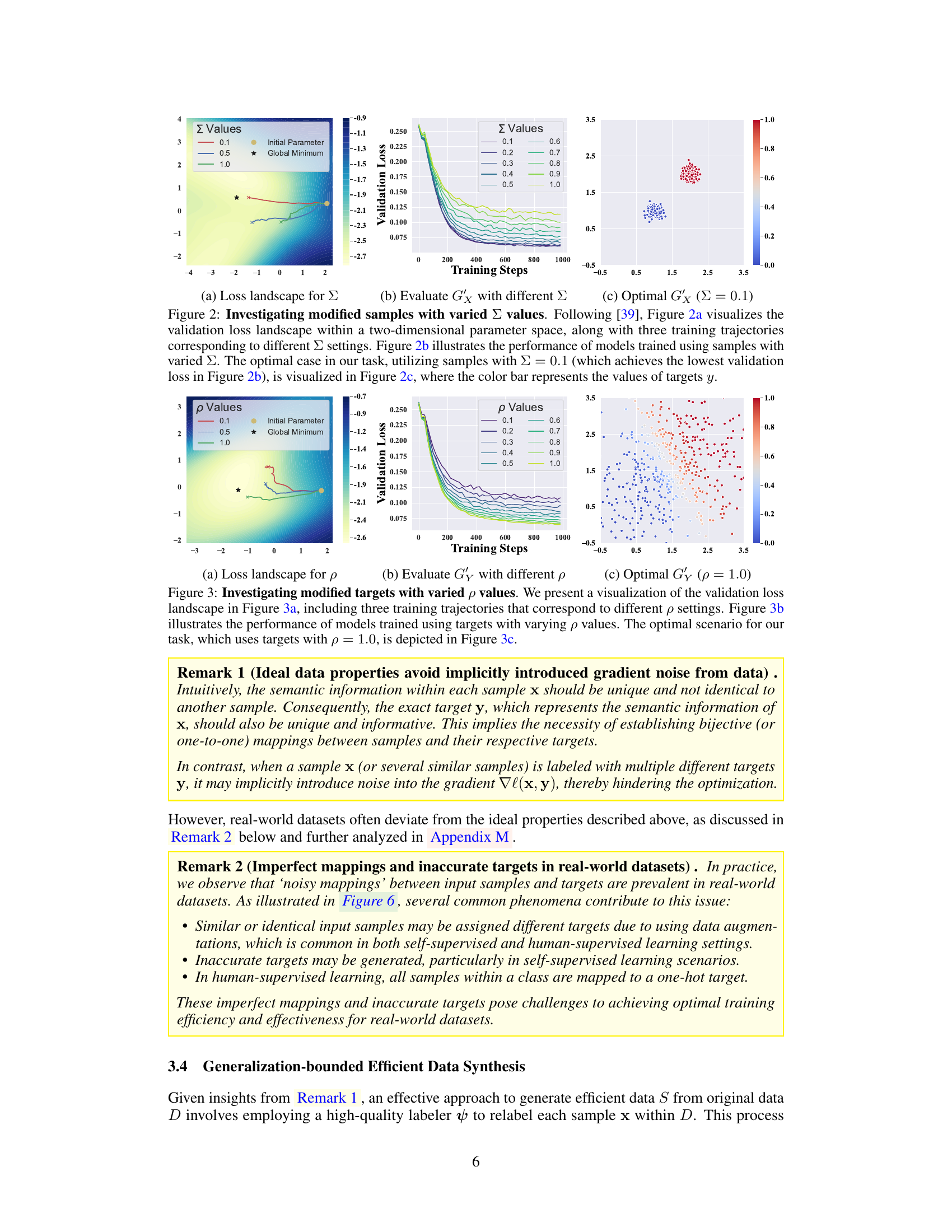
🔼 This figure shows the impact of modifying the variance (∑) of the data samples on the model training process. (a) shows the loss landscape, illustrating how different variance levels affect the optimization path. (b) presents the validation loss for models trained with different variances, showing faster convergence for smaller variances. (c) visualizes the optimal data distribution (∑ = 0.1) which leads to the lowest validation loss and fastest convergence.
read the caption
Figure 2: Investigating modified samples with varied ∑ values. Following [39], Figure 2a visualizes the validation loss landscape within a two-dimensional parameter space, along with three training trajectories corresponding to different ∑ settings. Figure 2b illustrates the performance of models trained using samples with varied ∑. The optimal case in our task, utilizing samples with ∑ = 0.1 (which achieves the lowest validation loss in Figure 2b), is visualized in Figure 2c, where the color bar represents the values of targets y.

🔼 This figure shows an empirical and theoretical investigation of data-centric efficient learning. It demonstrates the effect of modifying sample variance (Σ) and re-labeling intensity (p) on the convergence rate and performance of a binary classification task using a bimodal Gaussian mixture distribution. The results indicate that smaller variance and higher re-labeling intensity lead to faster convergence and better performance.
read the caption
Figure 2: Investigating modified samples with varied ∑ values. Following [39], Figure 2a visualizes the validation loss landscape within a two-dimensional parameter space, along with three training trajectories corresponding to different ∑ settings. Figure 2b illustrates the performance of models trained using samples with varied Σ. The optimal case in our task, utilizing samples with ∑ = 0.1 (which achieves the lowest validation loss in Figure 2b), is visualized in Figure 2c, where the color bar represents the values of targets y.
🔼 This figure shows an empirical and theoretical investigation of data-centric efficient learning. It contains three subfigures: (a) shows the loss landscape for different sigma values, (b) evaluates the performance with different sigma values, and (c) shows the optimal case with sigma=0.1. The study demonstrates that modifying the variance of the sample distribution influences the convergence rate of the optimization process, impacting overall representation learning.
read the caption
Figure 2: Investigating modified samples with varied ∑ values. Following [39], Figure 2a visualizes the validation loss landscape within a two-dimensional parameter space, along with three training trajectories corresponding to different ∑ settings. Figure 2b illustrates the performance of models trained using samples with varied ∑. The optimal case in our task, utilizing samples with ∑ = 0.1 (which achieves the lowest validation loss in Figure 2b), is visualized in Figure 2c, where the color bar represents the values of targets y.

🔼 This figure presents an empirical and theoretical analysis of how modifying sample variance affects the performance of a binary classification model trained on a bimodal Gaussian mixture distribution. The results show that decreasing the variance of the data leads to faster convergence and better performance. The figure also demonstrates this effect through loss landscapes, training curves across different variances, and a visualization of optimal data properties. The analysis suggests that modifying sample variance and re-labeling data points can accelerate the training process.
read the caption
Figure 2: Investigating modified samples with varied ∑ values. Following [39], Figure 2a visualizes the validation loss landscape within a two-dimensional parameter space, along with three training trajectories corresponding to different ∑ settings. Figure 2b illustrates the performance of models trained using samples with varied ∑. The optimal case in our task, utilizing samples with ∑ = 0.1 (which achieves the lowest validation loss in Figure 2b), is visualized in Figure 2c, where the color bar represents the values of targets y.

🔼 The figure illustrates the framework and intuition of the Representation Learning Accelerator (RELA). RELA is a two-stage process. First, it uses a pre-trained model and existing data to generate an efficient dataset. Second, it integrates this data into an existing self-supervised learning algorithm to accelerate the learning process. The core idea is that by producing a more efficient dataset, the initial model quickly approaches the target model’s representation during training. The figure shows a schematic of this two-stage process, highlighting the shortcut pathway created by RELA in the representation space.
read the caption
Figure 1: Framework and Intuition of RELA: (1) Framework: RELA serves as both a data optimizer and an auxiliary accelerator. Initially, it operates as a data optimizer by leveraging an dataset and a pre-trained model (e.g., one sourced from online repositories) to generate an efficient dataset. Subsequently, RELA functions as an auxiliary accelerator, enhancing existing (self-)supervised learning algorithms through the effective utilization of the efficient dataset, thereby promoting efficient representation learning. (2) Intuition: The central concept of RELA is to create an efficient-data-driven shortcut pathway within the learning process, enabling the initial model $ to rapidly converge towards a 'proximal representation ' of the target model $* during the early stages of training. This approach significantly accelerates the overall learning process.

🔼 This figure shows an empirical and theoretical investigation of data-centric efficient learning using a bimodal Gaussian mixture distribution. It visualizes the validation loss landscape for different variance settings (∑), showing how smaller variances lead to faster convergence and better performance. It also shows the impact of modified targets (p) on the convergence rate of model training.
read the caption
Figure 2: Investigating modified samples with varied ∑ values. Following [39], Figure 2a visualizes the validation loss landscape within a two-dimensional parameter space, along with three training trajectories corresponding to different ∑ settings. Figure 2b illustrates the performance of models trained using samples with varied ∑. The optimal case in our task, utilizing samples with ∑ = 0.1 (which achieves the lowest validation loss in Figure 2b), is visualized in Figure 2c, where the color bar represents the values of targets y.
More on tables
🔼 This table benchmarks the proposed RELA method against the baseline BYOL method. It compares the performance of models trained with different percentages (10%, 20%, 50%) of the original training budget, using various pre-trained models as priors in RELA. The results are shown across four datasets: CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet. Underlined values indicate performance exceeding that of the fully trained BYOL model, while bold values represent the best performance achieved for a given budget percentage.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
🔼 This table benchmarks the performance of RELA against the baseline BYOL model across four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K) and various training budgets (10%, 20%, and 50%). It compares RELA using different prior models (randomly initialized, four BYOL-trained models on different datasets, and CLIP-RN50) against the full BYOL training. The table highlights results that outperform the full BYOL training and those achieving the best performance for a given budget ratio. ResNet-18 is the primary architecture, with ResNet-50 used only for ImageNet-1K.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.

🔼 This table benchmarks the performance of RELA against the baseline BYOL method across four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-1K) and various training budget percentages (10%, 20%, 50%). It compares the performance of BYOL trained with different prior models (including randomly initialized networks, BYOL-trained models on different datasets, and CLIP-RN50). The table highlights results that surpass full BYOL training or achieve the best performance for a given budget percentage, showcasing RELA’s effectiveness in improving training efficiency.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.

🔼 This table compares the performance of RELA (with different prior models) and standard BYOL on four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet) using different training budgets (10%, 20%, 50%, and 100%). It shows that RELA consistently outperforms BYOL, especially with stronger prior models and lower budgets. The results are presented as Top-1 accuracy and demonstrate the effectiveness and efficiency of RELA.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.

🔼 This table benchmarks the performance of RELA against BYOL using various prior models and different training budget ratios (10%, 20%, 50%). It compares the results across four datasets: CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K. The prior models used for RELA include a randomly initialized network, four BYOL-trained models, and CLIP-RN50. The table highlights results that outperform the full BYOL training and those achieving the best performance for each budget ratio.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
🔼 This table benchmarks the proposed RELA method against the baseline BYOL method. It compares the performance of models trained with different training budgets (10%, 20%, and 50%) and with various prior models (including randomly initialized networks and BYOL-trained models on different datasets). The evaluation is performed on four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K), and the results show that RELA consistently outperforms BYOL, especially when using stronger prior models and with reduced training budgets.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
🔼 This table benchmarks the RELA method against the BYOL method across four datasets with varying training budgets. It compares the performance of BYOL trained with different percentages (10%, 20%, 50%) of the original training budget against RELA trained using six different prior models (randomly initialized, four BYOL*-trained models from different datasets, and CLIP-RN50). The results show that RELA generally outperforms BYOL, particularly with reduced training budgets, and that stronger prior models lead to better results. The best results for each budget are highlighted.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
🔼 This table benchmarks the RELA method against the BYOL method using various prior models and different training budgets. It shows the top-1 accuracy results across four datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K) for different training budget percentages (10%, 20%, and 50%). The prior models used include a randomly initialized network, four BYOL-trained models from different datasets, and a CLIP-RN50 model. The table highlights results that surpass the full training performance and those achieving the best performance for each budget percentage. ResNet-18 is used for most models, except for ImageNet-1K, where ResNet-50 is employed.
read the caption
Table 1: Benchmark our RELA with various prior models against BYOL. We compare evaluation results of the models trained using BYOL with 10%, 20% and 50% training budget/steps; • BYOL (7) with different prior models; BYOL with full budget, denoted as BYOL* in this table. Regarding the prior models used for our RELA, we respectively utilize six models with increasing representation capabilities, including ⚫ randomly initialized network (Rand.); • four BYOL*-trained models (CF10-T, CF100-T, TIN-T, IN1K-T) corresponding to four datasets (listed below); • CLIP-RN50. The evaluations are performed across four datasets, i.e., CIFAR-10 (CF-10), CIFAR-100 (CF-100), Tiny-ImageNet (T-IN), and ImageNet-1K (IN-1K). We underline the results that outperform the full training, and bold the results that achieve the highest performance using a specific ratio of budget. All the networks used for training are ResNet-18, except the ResNet-50 used for IN-1K.
Full paper#