TL;DR#
Many existing hair editing methods struggle with accurately manipulating hair color and style while preserving other facial features. StyleGAN-based methods suffer from limited spatial distribution in latent space, causing issues with multi-color hair editing and facial feature preservation. Diffusion models offer an improvement, but lack sufficient control for the hair editing task and struggle with retaining original hair color or transferring hair color faithfully from reference images.
HairDiffusion uses Latent Diffusion Models (LDMs) to address these challenges. It introduces a Multi-stage Hairstyle Blend (MHB) to decouple the control of hair color and hairstyle in the latent space, allowing for more precise editing. A warping module is also trained to align hair color with the target area, further improving editing quality. The model is fine-tuned using a multi-color hairstyle dataset to improve accuracy with multi-color hairstyles. Experiments demonstrate the efficacy of the method in editing multi-color hairstyles while effectively preserving facial attributes.
Key Takeaways#
Why does it matter?#
This paper is significant for researchers in image synthesis and computer vision because it presents a novel approach for hair editing that tackles limitations in existing methods. It combines the strengths of diffusion models and multi-stage blending for precise control over hair color and style, while effectively preserving other facial features. This opens up opportunities for creating more realistic and detailed virtual avatars and improving image editing software.
Visual Insights#

🔼 This figure showcases the results of the HairDiffusion model on various hair editing tasks. It demonstrates the model’s ability to edit both hairstyle and hair color individually or simultaneously using different input modalities (text descriptions, reference images, and stroke masks). The images highlight the model’s effectiveness in handling multiple hair colors and maintaining high-quality results, even in complex scenarios.
read the caption
Figure 1: Our framework supports individual or collaborative editing of hairstyle and color, utilizing text, reference images, and stroke maps. With exceptional performance, particularly evident in editing multiple hair colors.

🔼 This table presents a quantitative comparison of different hair editing methods in terms of their ability to preserve irrelevant facial attributes. It uses three metrics: Identity Similarity (IDS), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM). Higher scores indicate better preservation of identity and image quality in the non-hair regions of the face after hair editing. The comparison helps to demonstrate the effectiveness of the proposed method (Ours) in maintaining facial features while altering the hair.
read the caption
Table 1: Quantitative comparison for irrelevant attributes preservation. IDS [13] denotes identity similarity, PSNR, and SSIM are calculated at the intersected non-hair regions before and after editing.
In-depth insights#
Latent Diffusion Edits#
The concept of “Latent Diffusion Edits” points towards a powerful technique in image manipulation. It leverages the strengths of latent diffusion models, which excel at generating high-quality, realistic images, to perform targeted edits. Instead of directly modifying pixel values, edits happen within the latent space of the diffusion model. This latent space represents the image in a compressed, disentangled form, allowing for more precise and controlled manipulations. By modifying the latent representation, and then reconstructing the image, sophisticated edits become achievable, such as realistic hair color and style changes or detailed inpainting. The method likely involves carefully designed loss functions to ensure that the edits are faithfully reflected in the final image while maintaining the integrity of other features. A key advantage is the ability to control multiple aspects of the image simultaneously, enabling more complex and nuanced alterations than traditional methods permit. However, challenges associated with disentanglement, computational cost, and the potential for artifacts or inconsistencies in the final image must be considered. The success of this technique hinges on the quality and size of the training dataset and the cleverness of the model architecture in learning a robust and meaningful latent space representation. Finally, the ethical implications of image manipulation at this level warrant attention and require careful consideration.
Multi-Stage Blend#
The proposed Multi-Stage Blend strategy is a novel approach to disentangle and independently control hair color and hairstyle within a latent diffusion model for image editing. Its core innovation lies in the blending of color and style proxies at distinct stages of the diffusion process. This allows for precise manipulation of each attribute without undesired interference. By separating the control, the model avoids the limitations of single-stage methods that struggle to manage multiple hair colors or preserve irrelevant facial features. The strategy uses two different proxies: a style proxy and a color proxy. The style proxy guides the hairstyle, while the color proxy guides the color. The multi-stage aspect is crucial, as it allows the model to prioritize color accuracy early in the diffusion process and then seamlessly integrate the style later, achieving high fidelity in both aspects while preserving the source image’s integrity. This approach’s effectiveness hinges on the careful design and blending of these proxies, overcoming challenges inherent to previous methods based on StyleGAN and other diffusion models.
Warping Module#
The warping module is a crucial component of the HairDiffusion model, addressing the challenge of aligning the hair color from a reference image to the target image. Its core function is image registration, specifically designed for hair. The module’s architecture leverages a pre-trained network, likely a convolutional neural network (CNN), which is fine-tuned on a dataset of aligned hair images. This fine-tuning process enables the network to learn the complex transformations necessary to align hair across different facial poses and hairstyle variations. A key innovation is the integration of additional priors, such as DensePose estimations and hair segmentation maps. These additional inputs help guide the warping process, ensuring accurate alignment even with complex hairstyles or significant pose changes. The warping module’s output, the color proxy, serves as a critical intermediate representation, providing accurate color and structural information for the subsequent diffusion process. The effectiveness of the warping module is clearly demonstrated by quantitative results and qualitative visual comparisons, showcasing superior performance compared to existing hair color transfer methods. Although sophisticated, the warping module’s performance is still limited by factors such as significant pose differences, complex hair textures, and incomplete hair regions in the input images. Future work might explore ways to improve its robustness, potentially involving more advanced architectures or innovative data augmentation strategies.
Ablation Analyses#
Ablation analyses systematically investigate the contribution of individual components within a complex model. In this context, it would likely involve removing or deactivating specific modules (e.g., the warping module, the multi-stage hairstyle blend, or specific components within them) to understand their impact on the overall performance. Key insights would emerge by comparing results with and without each module. For instance, removing the warping module could reveal its effectiveness in aligning hair color, while disabling the multi-stage blend would clarify its role in disentangling hairstyle and color. Analyzing the results with quantitative metrics (e.g., FID, PSNR, SSIM) and qualitative observations would help pinpoint strengths and weaknesses of different architectural choices. The ablation study might also explore variations within a module, like different numbers of layers or alternative implementations, further refining the design process. Ultimately, ablation analysis provides crucial evidence for justifying the chosen model architecture and its individual components by demonstrating their contribution to performance and robustness.
Future of HairEdits#
The future of HairEdits lies in seamless integration with existing image and video editing tools, offering intuitive interfaces and advanced features. Improved AI models, trained on larger and more diverse datasets, will enhance realism and precision, enabling manipulation of fine hair details, diverse hair textures, and complex hairstyles with greater accuracy. Real-time processing capabilities will become increasingly crucial for applications in virtual try-ons, virtual reality, and augmented reality experiences, demanding efficient algorithms and optimized hardware. Ethical considerations regarding the potential misuse of this technology for creating deepfakes or perpetuating harmful stereotypes must be addressed proactively through robust safeguards and responsible development practices. Finally, personalized hair editing tools tailored to individual preferences and hair types, may emerge, enhancing user experience and fostering creative self-expression.
More visual insights#
More on figures
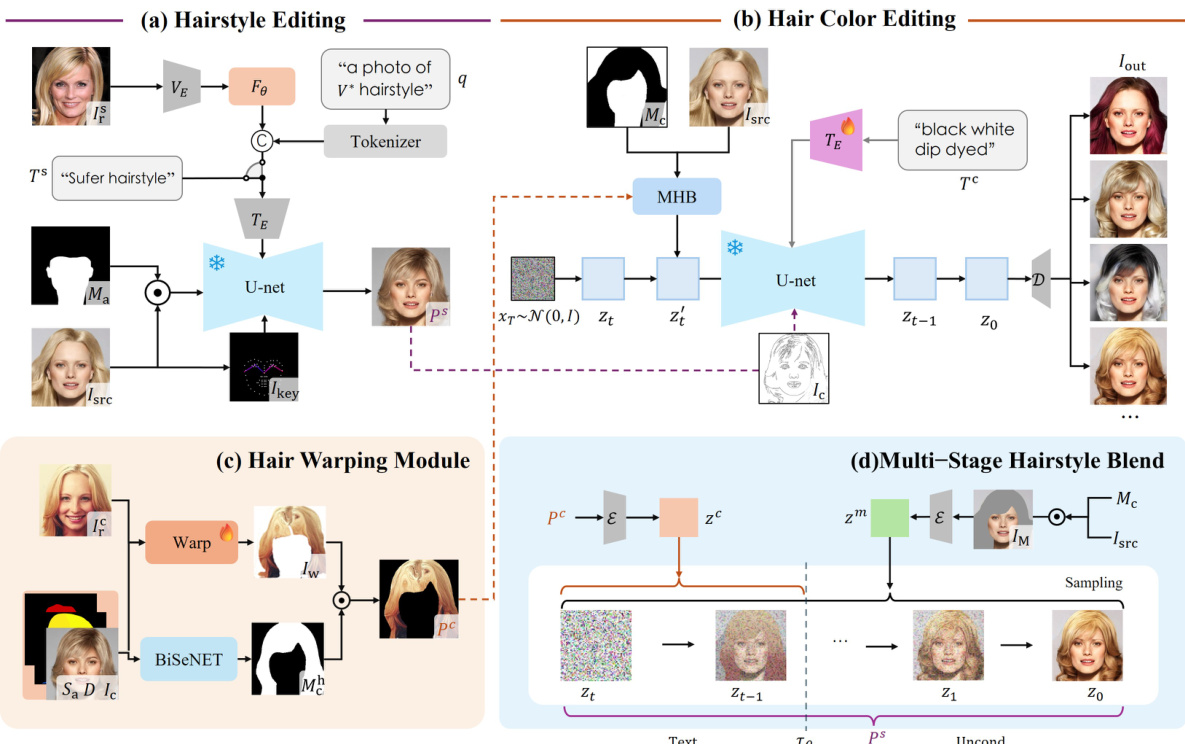
🔼 This figure provides a visual overview of the HairDiffusion model, illustrating its pipeline for both hairstyle and hair color editing. It shows how the model uses different components: hairstyle editing leverages a hairstyle description or reference image along with a hair-agnostic mask and source image to generate a style proxy. Hair color editing utilizes both style and color proxies with a hair-agnostic mask and source image. A warping module aligns the color reference image with the source image to obtain a color proxy. Finally, a multi-stage hairstyle blend method combines the style and color proxies within the diffusion process for refined editing.
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image I as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Me and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image I is used to obtain the color proxy Pe through a warping module. In the case of changing only the hairstyle while preserving the original hair color, I = Isrc. (d) The color proxy Pº and the style proxy Ps are blended at different stages of the diffusion process.

🔼 This figure compares the results of HairDiffusion with several other state-of-the-art hair editing methods. It showcases examples of various hair color and style edits, highlighting the superior performance of HairDiffusion in terms of image quality, detail preservation, and the ability to maintain the integrity of background and facial features. The simplified text prompts used for each edit are also displayed for reference.
read the caption
Figure 3: Visual comparison with HairCLIPv2 [36], HairCLIP [35], TediGAN [38], Power-Paint ('ControlNet' version) [47], ControlNet-Inpainting [42], and DiffCLIP [18]. The simplified text descriptions (editing hairstyle, hair color, or both of them) are listed on the leftmost side. Our approach demonstrates better editing effects and irrelevant attribute preservation (e.g., identity, background).

🔼 This figure compares the results of the proposed HairDiffusion method with the HairCLIPv2 method on two examples of hair editing. The left side shows a transformation from a short, dark haircut to a vibrant red afro. The right side shows a change from dark hair to blonde ringlets. Both examples highlight HairDiffusion’s improved ability to preserve facial details and other features such as eyebrows, earrings, and makeup, unlike HairCLIPv2, which shows noticeable artifacts and alterations to non-hair regions. The detailed comparison demonstrates the superior performance of HairDiffusion in maintaining the integrity of the original image while accomplishing the desired hair editing.
read the caption
Figure 4: Comparison with HairCLIPv2 [36] in detail. Our approach shows better preservation of irrelevant attributes.

🔼 This figure compares the results of HairDiffusion with several state-of-the-art hair color transfer methods. The input images are shown in the first column, followed by the results generated by each method. The figure demonstrates HairDiffusion’s ability to accurately transfer hair color while maintaining the integrity of other facial features.
read the caption
Figure 5: Visual comparison with HairCLIPv2 [36], HairCLIP [35], Barbershop [45], CtrlHair [11], MichiGAN [33] and HairFastGAN [26] on hair color transfer.

🔼 This figure demonstrates an ablation study on the HairDiffusion model. It shows the effects of different components of the model on the final output. The top row shows the results of text-guided hairstyle editing. The bottom row shows the results of reference image-guided hair color editing. Each column shows the results of adding one more component to the model. The first column shows the original image. The second column shows the results of adding a hair-agnostic mask. The third column shows the results of adding pose control. The fourth column shows the results of adding a color proxy (unwarped). The fifth column shows the results of adding a warping module. The sixth column shows the results of adding bilateral filtering.
read the caption
Figure 6: Ablation studies on text-guided hairstyle editing and reference image-guided hair color editing.

🔼 This figure shows the results of ablation studies on the warping module and its post-processing steps. It visually demonstrates the effect of each step (warping, patch match, bilateral filter) on hair color transfer and hairstyle generation. Each row represents a different hair style and color transfer scenario. By comparing the results of each step, one can understand the contribution of each component to the final output and how these individual components work together.
read the caption
Figure 7: Visualizations of the ablation studies on the warping module and corresponding post-processing.
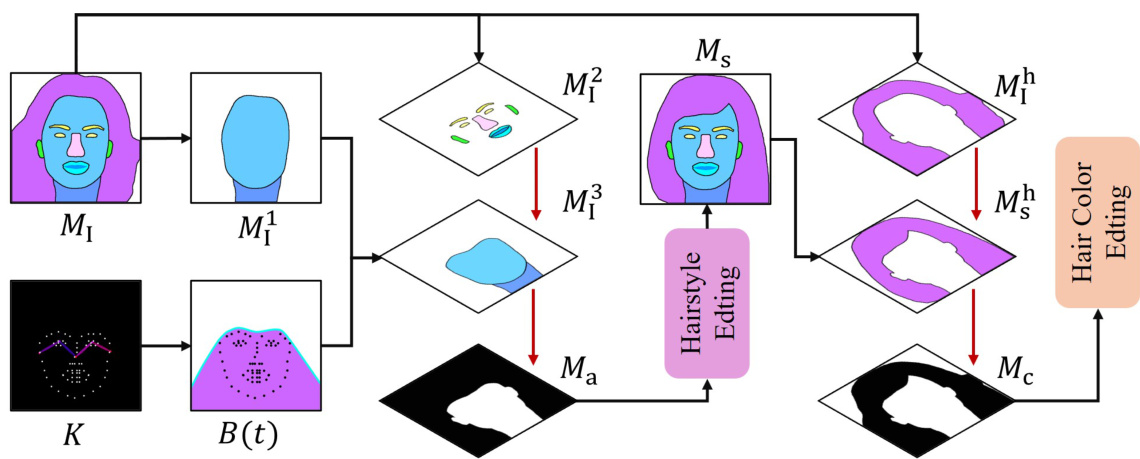
🔼 This figure illustrates the HairDiffusion framework, showing its two main stages: hairstyle editing and hair color editing. The hairstyle editing stage uses a text description or reference image along with a hair-agnostic mask to generate a style proxy, which is then used to modify the hairstyle in the input image. The hair color editing stage utilizes both a style proxy and a color proxy (obtained from a reference image via a warping module) to control both hairstyle and hair color simultaneously. The multi-stage hairstyle blend (MHB) is also highlighted, demonstrating how the color and style proxies are integrated into the diffusion process. Different masks (Ma and Mc) are employed for different stages to better separate the control of hair and facial features.
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image Iref as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Mc and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image Iref is used to obtain the color proxy Pc through a warping module. In the case of changing only the hairstyle while preserving the original hair color, Iref = Isrc. (d) The color proxy Pc and the style proxy Ps are blended at different stages of the diffusion process.
🔼 This figure provides a visual overview of the HairDiffusion model, illustrating the different stages involved in hairstyle and hair color editing. Panel (a) shows the process of generating a ‘style proxy’ from a text description or reference image, combined with a hair-agnostic mask and the input image. Panel (b) demonstrates how the style proxy and a ‘color proxy’ (obtained from a reference color image via a warping module shown in (c)) are used together for collaborative editing. Panel (d) details the multi-stage hairstyle blend, showing how the color and style proxies are blended in different stages of the diffusion process to create the final edited image.
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image I as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Me and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image I is used to obtain the color proxy Pc through a warping module. In the case of changing only the hairstyle while preserving the original hair color, I = Isrc. (d) The color proxy Pc and the style proxy Ps are blended at different stages of the diffusion process.

🔼 This figure provides a visual overview of the HairDiffusion framework. Panel (a) illustrates hairstyle editing using text or image input and a hair-agnostic mask. Panel (b) shows how hair color and hairstyle can be edited collaboratively, leveraging both color and style proxies. Panel (c) details the hair warping module that aligns the hair color reference image with the input image. Finally, Panel (d) demonstrates the multi-stage hairstyle blend (MHB) which integrates color and style information during different stages of the diffusion process.
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image Iref as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Mc and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image Iref is used to obtain the color proxy Pc through a warping module. In the case of changing only the hairstyle while preserving the original hair color, Iref = Isrc. (d) The color proxy Pc and the style proxy Ps are blended at different stages of the diffusion process.

🔼 This figure provides a visual comparison of hair reconstruction results between the proposed HairDiffusion method and two other state-of-the-art methods: StyleGAN Salon and HairFastGAN. It showcases the performance of each method on a variety of hairstyles and hair colors, highlighting the strengths and limitations of each approach in terms of accuracy, color preservation, and overall visual realism. The figure is crucial in demonstrating the efficacy of HairDiffusion in generating high-quality and realistic results.
read the caption
Figure 11: Visualization of the reconstruction comparison with StyleGAN Salon and HairFastGAN.

🔼 This figure demonstrates an ablation study on the HairDiffusion model, showing the effects of different components on hairstyle and hair color editing. The top row showcases original images and the bottom row shows the results after the editing process. Each column presents a different ablation experiment by removing specific components of the model: hair-agnostic mask, pose control, color proxy (unwarped), warping module, and bilateral filtering. The results show the importance of each component in achieving high-quality results, highlighting how different combinations of factors influence the model’s capacity to generate realistic and consistent hairstyle and hair color edits.
read the caption
Figure 6: Ablation studies on text-guided hairstyle editing and reference image-guided hair color editing.

🔼 This figure demonstrates the limitations of using stroke map encoders in latent space for hair color editing. The second column shows that the method overlooks details in the hair color, failing to capture the nuances and variations. The fourth column illustrates a mismatch between the generated and provided hair color areas, highlighting the model’s inability to accurately replicate the specified color patterns.
read the caption
Figure 13: By using a stroke map encoder in the latent space, it inevitably overlooks details of hair color, as shown in the second column. And it does not completely match the provided hair color areas, as shown in the fourth column.

🔼 This figure illustrates the HairDiffusion framework, showing the process of hairstyle and hair color editing. It consists of four parts: (a) Hairstyle editing using text or reference image as input and a hair-agnostic mask to generate a style proxy. (b) Hair color editing using both style and color proxies, along with a hair-agnostic mask, for combined or individual control. (c) Hair warping module that aligns the reference hair color image to the source image using facial keypoints and generates a color proxy. (d) Multi-stage hairstyle blend that combines color and style proxies at different diffusion stages for effective hair editing.
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image Iref as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Mc and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image Iref is used to obtain the color proxy Pc through a warping module. In the case of changing only the hairstyle while preserving the original hair color, Iref = Isrc. (d) The color proxy Pc and the style proxy Ps are blended at different stages of the diffusion process.

🔼 This figure provides a visual overview of the HairDiffusion framework. It illustrates the process of hairstyle editing using text or image input (a), hair color editing using a color proxy and style proxy (b), the hair warping module that aligns the hair color from the reference image to the source image (c), and the multi-stage hairstyle blend that combines the style and color proxies for better editing results (d).
read the caption
Figure 2: Overview of HairDiffusion: (a) Using a hairstyle description Ts or reference image Iref as conditional input, coupled with the hair-agnostic mask Ma and source image Isrc, we can get the style proxy Ps. (b) Leveraging the color proxy and style proxy, along with the hair-agnostic mask Mc and source image Isrc, enables individual or collaborative editing of hair color and hairstyle. (c) Given a series of conditions driven from the input image Ic, the hair color reference image Iref is used to obtain the color proxy Pc through a warping module. In the case of changing only the hairstyle while preserving the original hair color, Iref = Isrc. (d) The color proxy Pc and the style proxy Ps are blended at different stages of the diffusion process.
More on tables

🔼 This table presents the results of a user study comparing different hair editing methods across three categories: text-driven editing, color transfer, and cross-modal editing. The metrics evaluated are Accuracy (how well the method achieved the desired edit), Preservation (how well the method preserved irrelevant facial features), and Naturalness (how realistic the resulting image appears). Each cell shows the percentage of user votes for each method in each category, with bold and underlined entries indicating the top two performers.
read the caption
Table 2: User study on text-driven image manipulation, color transfer, and cross-modal hair editing methods. Accuracy denotes the manipulation accuracy for given conditional inputs, Preservation indicates the ability to preserve irrelevant regions and Naturalness denotes the visual realism of the manipulated image. The numbers represent the percentage of votes. Bold and underline denote the best and the second best result, respectively.

🔼 This table presents a quantitative analysis of the ablation study conducted on the warping module within the HairDiffusion model. By systematically removing components (warping module, patch match, and bilateral filtering), the impact on model performance is evaluated using FID, FIDclip, and SSIM metrics. The results demonstrate that the combination of all three components achieves the best performance. The table helps readers understand the contribution of each component to the overall performance of HairDiffusion.
read the caption
Table 3: Quantitative comparison of different variants of warping module with various conditions removed. We achieve the best performance by leveraging the remaining techniques.
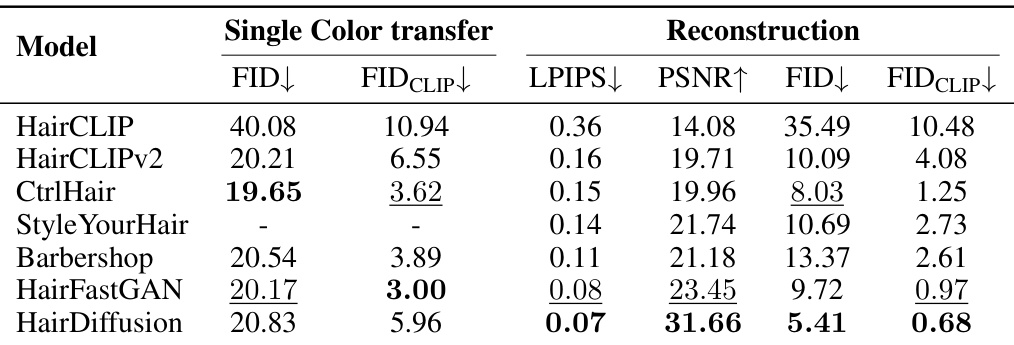
🔼 This table presents a quantitative comparison of different methods for single color transfer and self-transfer reconstruction tasks. The metrics used are FID (Frechet Inception Distance), FID_CLIP (FID calculated using CLIP features), LPIPS (Learned Perceptual Image Patch Similarity), PSNR (Peak Signal-to-Noise Ratio), and for reconstruction tasks FID and FID_CLIP. Lower FID and FID_CLIP scores indicate better image quality, while lower LPIPS indicates better perceptual similarity. Higher PSNR indicates better fidelity to the original image. The best performing method in each category is highlighted in bold and underlined.
read the caption
Table 4: Quantitative comparison of single color transfer and self-transfer reconstruction metrics. Bold and underline denote the best and the second best result, respectively.
Full paper#



















