↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
In-context learning (ICL) empowers large language models (LLMs) to solve various tasks using input-output examples (demonstrations). However, ICL performance suffers from the large search space and noisy demonstrations. Existing methods using a single retriever model to select demonstrations face suboptimal performance.
This paper introduces MoD (Mixture of Demonstrations), a novel framework that addresses these issues. MoD partitions the demonstration pool into groups, each managed by an expert retriever, reducing the search space. It also employs an expert-wise training strategy, mitigating the effects of unhelpful demonstrations. Experiments across several NLP tasks show MoD achieves state-of-the-art performance, demonstrating the effectiveness of its approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working in in-context learning and large language models because it addresses the critical challenge of demonstration selection, significantly improving model performance and efficiency. It introduces a novel framework and training strategy that could lead to advancements in retrieval methods, paving the way for more robust and effective ICL applications.
Visual Insights#

This figure illustrates the overall process of the Mixture of Demonstrations (MoD) framework proposed in the paper. It shows three main stages: Demonstration Assignment, Expert-wise Training, and Inference. In the Demonstration Assignment stage, demonstrations are partitioned into groups, each assigned to an expert. The Expert-wise Training stage involves training individual retriever models for each expert to select helpful demonstrations, mitigating the impact of unhelpful ones. The Inference stage shows how, during inference, multiple experts collaborate to retrieve demonstrations for an input query, ultimately enhancing the LLM’s prediction accuracy.
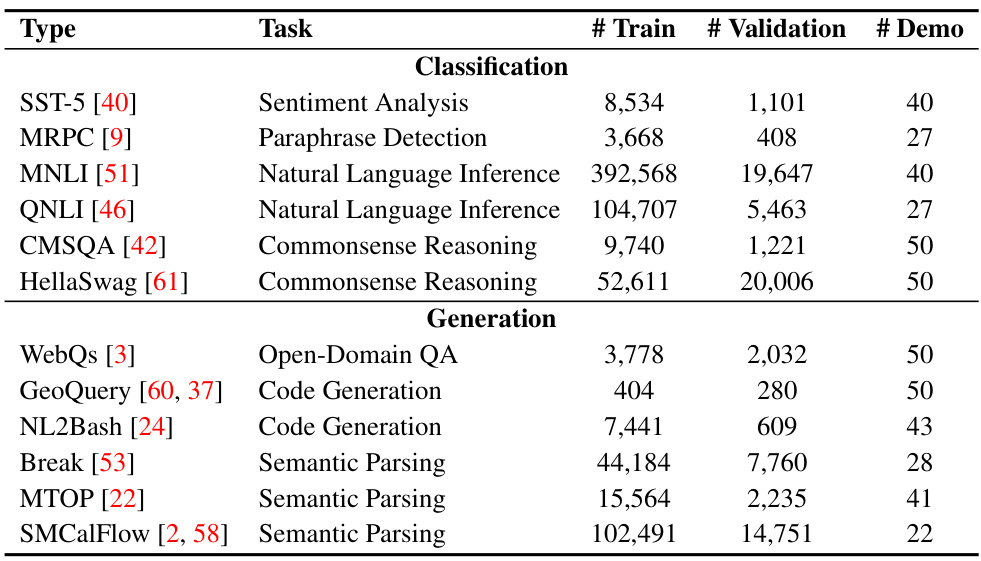
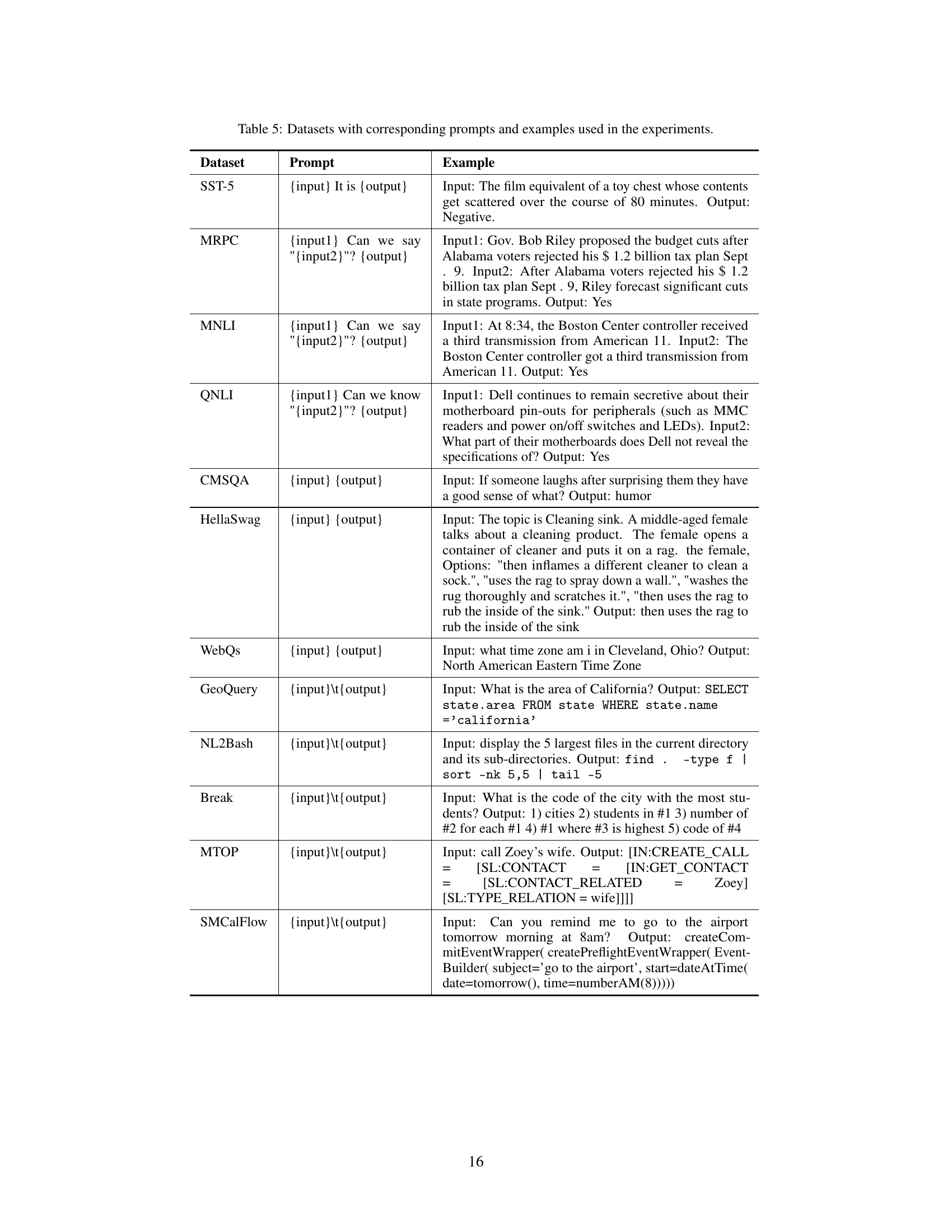
This table presents the datasets used in the experiments, categorized by type (classification or generation) and task. For each dataset, it provides the number of training samples, validation samples, and the average number of demonstrations used per task during validation. It also indicates the number of experts used in the MoD framework for each task.
In-depth insights#
MoD Framework#
The MoD (Mixture of Demonstrations) framework presents a novel approach to in-context learning (ICL) by tackling the challenges of large search spaces and suboptimal demonstration selection. MoD partitions the demonstration pool into groups, each managed by an expert retriever model, significantly reducing the search space compared to methods that examine the entire pool at once. This expert-based approach enhances the efficiency of the retrieval process. Further, MoD employs an expert-wise training strategy, iteratively optimizing each expert’s retriever while keeping others fixed, which mitigates the negative impact of unhelpful demonstrations. This coordinate-descent-inspired approach ensures that all used demonstrations are optimally selected during optimization, improving the quality of the retrieved set. During inference, experts collaboratively retrieve demonstrations, combining their strengths to create a diverse and effective set for the input query, ultimately leading to improved ICL performance. The framework’s key innovation lies in its coordinated and efficient management of diverse demonstration subsets, rather than relying on a single, potentially less effective, global retriever.
Expert-Wise Training#
Expert-wise training is a novel approach to optimizing a Mixture of Demonstrations (MoD) framework for in-context learning. Instead of globally optimizing all demonstration retrievers simultaneously, it iteratively optimizes each expert’s retriever model independently. This strategy is inspired by coordinate descent, focusing on one dimension (expert) at a time while holding others constant. By doing so, the method mitigates the negative impact of noisy or irrelevant demonstrations on the overall training process, leading to a more refined and effective retrieval of suitable demonstrations for enhancing in-context learning performance. This expert-wise approach is particularly beneficial in scenarios with large search spaces and noisy data, as it facilitates more precise optimization within each expert’s domain, improving overall model accuracy and robustness.
ICL Challenges#
In-context learning (ICL) presents significant challenges. Data efficiency is a major hurdle; ICL’s reliance on a limited number of demonstrations means performance is highly sensitive to their quality and selection. Robustness is another critical challenge; even small changes to demonstrations can dramatically impact results, highlighting a need for more reliable and stable ICL methods. Scalability is also a concern. Searching for the optimal demonstrations within large datasets is computationally expensive and inefficient. Additionally, generalization remains problematic. ICL often struggles to generalize to unseen data or tasks beyond the scope of the provided examples, limiting its applicability to real-world scenarios. Finally, understanding the mechanisms behind ICL’s success and failures is still an open research question, and a theoretical framework explaining its behavior is lacking. Addressing these challenges is crucial for advancing ICL and fully realizing its potential in various applications.
Retrieval Methods#
Effective retrieval methods are crucial for in-context learning, as they determine which demonstration examples are presented to the model. The ideal method should efficiently search a vast space of potential examples, selecting those most relevant and helpful to the current task. This requires addressing challenges like large search spaces and noisy data. Approaches may involve learning-based methods, optimizing a retriever model to score demonstrations and select a subset, or learning-free methods that directly choose demonstrations based on features like embedding similarity. An effective retrieval method must strike a balance between efficiency and accuracy, ensuring that the selected examples enhance model performance without incurring excessive computational costs. Furthermore, the retrieval process can be enhanced by considering interactions between demonstrations and the contextual relevance of each one for the specific task. Future directions include exploration of advanced techniques like mixture of experts models to further improve efficiency and diversity of retrieval. This would allow focusing the search process on specific subsets of data, enhancing performance and mitigating the negative impacts of noisy examples.
Future of ICL#
The future of In-Context Learning (ICL) hinges on addressing its current limitations. Improving the efficiency and scalability of demonstration selection is crucial, moving beyond exhaustive search methods and towards more sophisticated retrieval techniques that leverage the interplay between demonstrations. Developing methods robust to noisy or irrelevant demonstrations will be key, as will the exploration of techniques that can adapt to various task complexities and data distributions. Investigating the interplay between ICL and model architecture is another promising avenue; understanding how the model’s internal mechanisms interact with in-context examples could inform the design of more effective and efficient ICL systems. Furthermore, research into the theoretical foundations of ICL, explaining its effectiveness and limitations, is vital for guiding future advancements. Ultimately, the most impactful advancements will likely involve a combination of these approaches, leading to ICL systems that are both highly effective and practical for diverse applications.
More visual insights#
More on figures
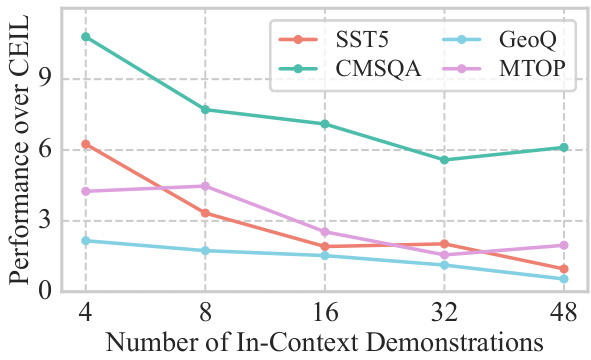
This figure shows the performance gain of the MoD model over the CEIL baseline across four different datasets (SST-5, CMSQA, GeoQ, MTOP) while varying the number of in-context demonstrations. The x-axis represents the number of in-context demonstrations used, ranging from 4 to 48. The y-axis shows the absolute performance improvement achieved by MoD compared to CEIL. Each dataset is represented by a different colored line, showing how the performance difference changes as more demonstrations are provided. The figure visually depicts the impact of varying demonstration numbers on the MoD model’s improved accuracy and the differences across various datasets.

This figure presents the results of an ablation study conducted to evaluate the impact of two key components of the MoD framework: the mixture-of-experts design and the expert-wise training. The x-axis represents four different datasets (SST5, CMSQA, GeoQ, MTOP), and the y-axis shows the model performance. Three bars for each dataset represent the performance of the full MoD model, MoD without the mixture-of-experts design (MoD w/o E), and MoD without expert-wise training (MoD w/o C). The error bars represent standard deviations. The results visually demonstrate the contributions of each component to the overall performance.
More on tables
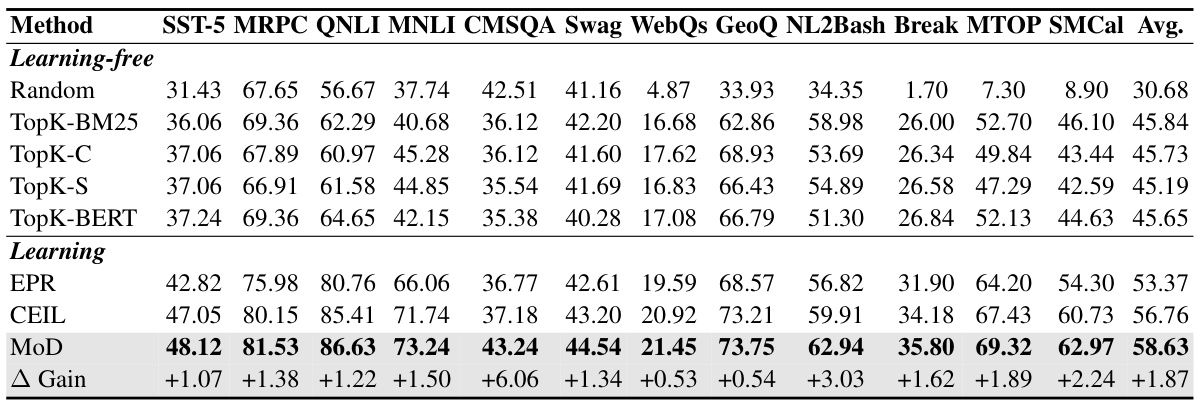
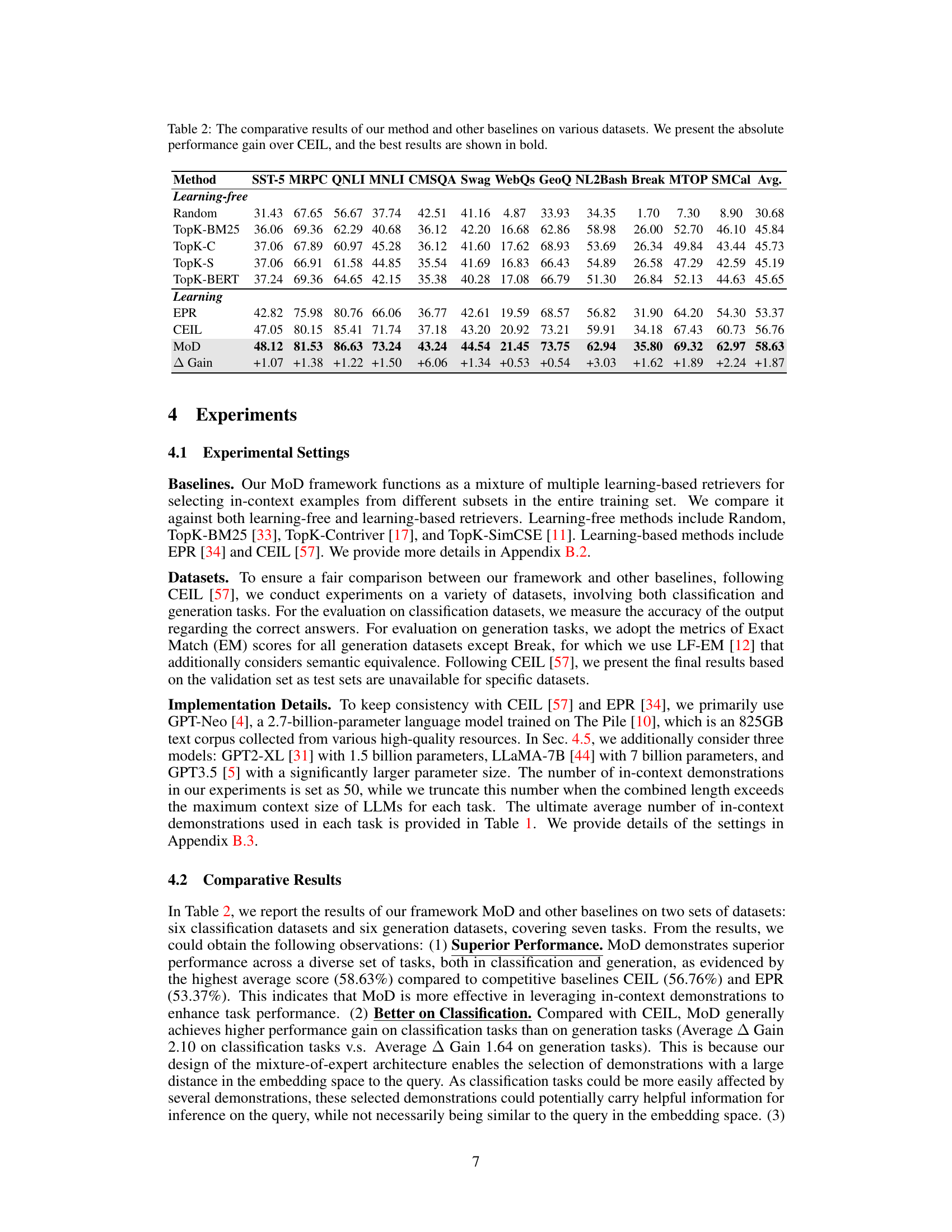
This table presents a comparison of the proposed MoD method against several baselines across various NLP datasets. It shows the absolute performance improvement of MoD over the CEIL baseline for both classification and generation tasks. The best results for each dataset are highlighted in bold.
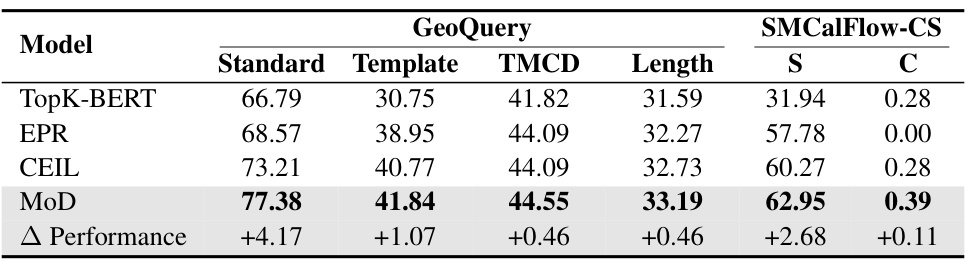
This table presents the performance comparison of MoD and other baselines (TopK-BERT, EPR, CEIL) on two compositional datasets: GeoQuery and SMCalFlow-CS. Each dataset has two subsets: a standard non-compositional set (S) and a compositional set (C) that includes cross-domain examples. The results are reported in terms of absolute performance gains of MoD compared to CEIL, showing MoD’s superior performance across all datasets, particularly in the compositional subsets.
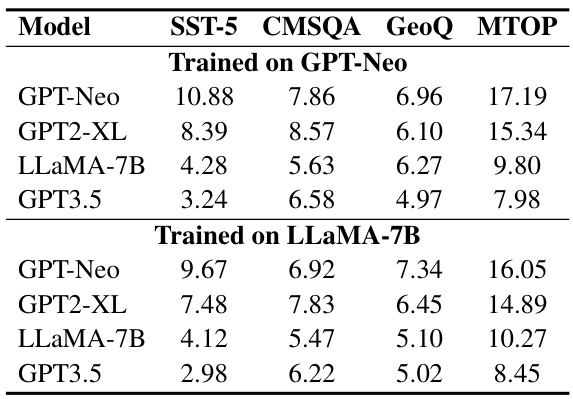
This table presents the results of a robustness study evaluating the transferability of the MoD framework across different LLMs. Retriever models trained on one LLM (GPT-Neo and LLAMA-7B) were used to select demonstrations for other LLMs (GPT-Neo, GPT2-XL, LLAMA-7B, and GPT3.5) on four different datasets (SST-5, CMSQA, GeoQ, and MTOP). The table shows the absolute performance gain of MoD over TopK-BERT for each LLM-dataset combination, demonstrating the model’s robustness and transferability.

This table compares the performance of the proposed MoD framework against several other baselines (both learning-free and learning-based methods) across various datasets encompassing classification and generation tasks. The table shows the absolute performance improvement of MoD over the CEIL baseline for each dataset and task. The best performance is highlighted in bold.
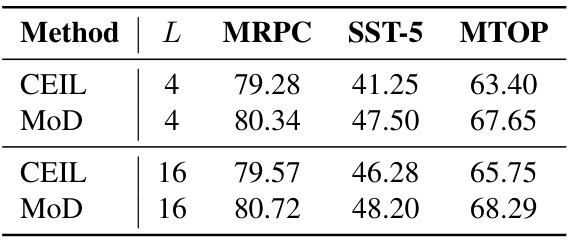
This table compares the performance of CEIL and MoD models with different numbers of in-context examples (4 and 16) across three datasets (MRPC, SST-5, and MTOP). It demonstrates that MoD consistently outperforms CEIL, even when using fewer examples.

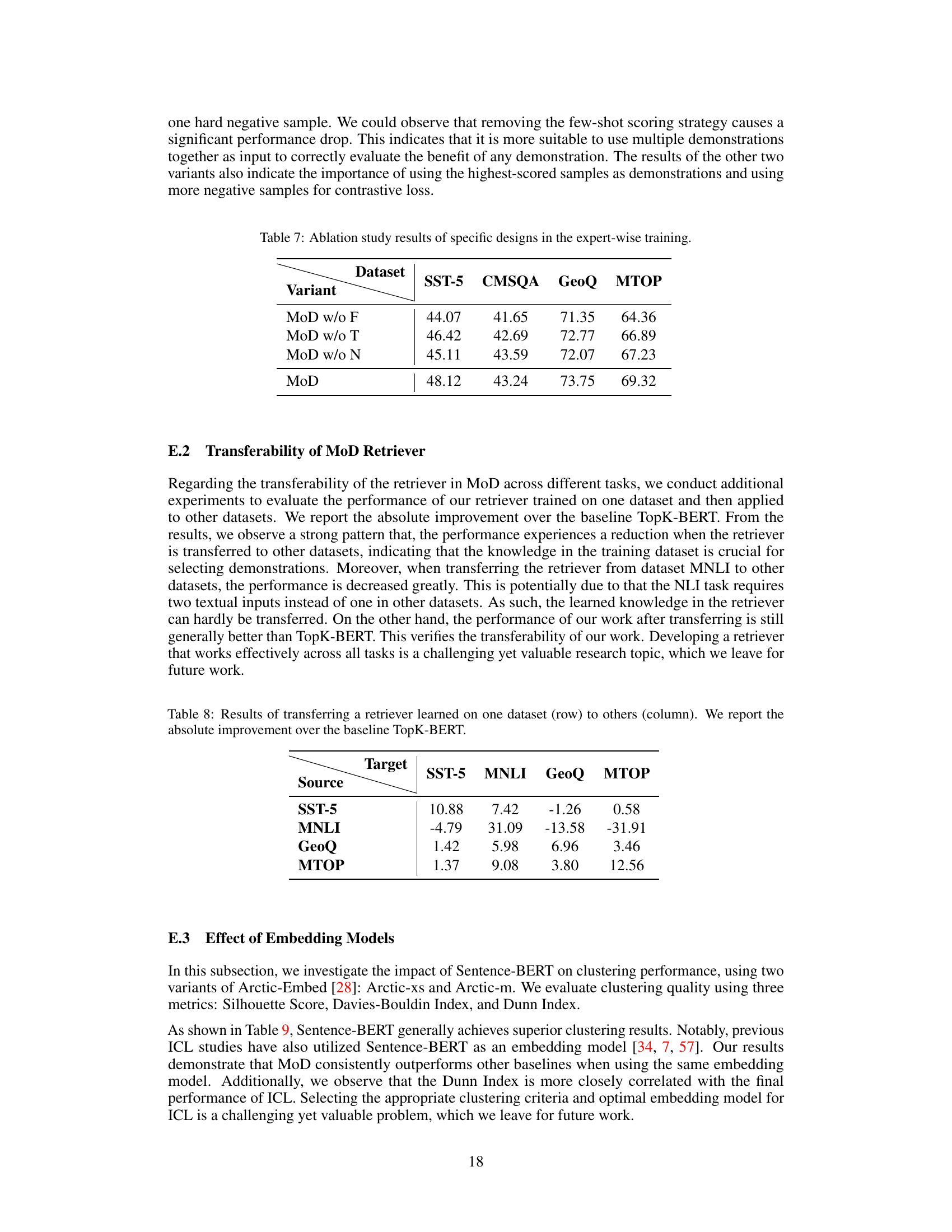
This table presents the ablation study results of the MoD framework. By removing the few-shot scoring, the random selection of demonstrations, and the hard negative samples in contrastive learning, the impact of each component in expert-wise training is evaluated. The results show that all three components contribute positively to the overall performance, with the few-shot scoring being the most critical.

This table presents the results of an experiment evaluating the transferability of the retriever model trained in the MoD framework. A retriever model was trained on each of four datasets (SST-5, MNLI, GeoQ, MTOP), and then used to select demonstrations for each of those four datasets. The table shows the absolute performance gain over a baseline model (TopK-BERT) for each dataset-to-dataset transfer. Positive values indicate improved performance, while negative values show a decline in performance when the model is transferred.

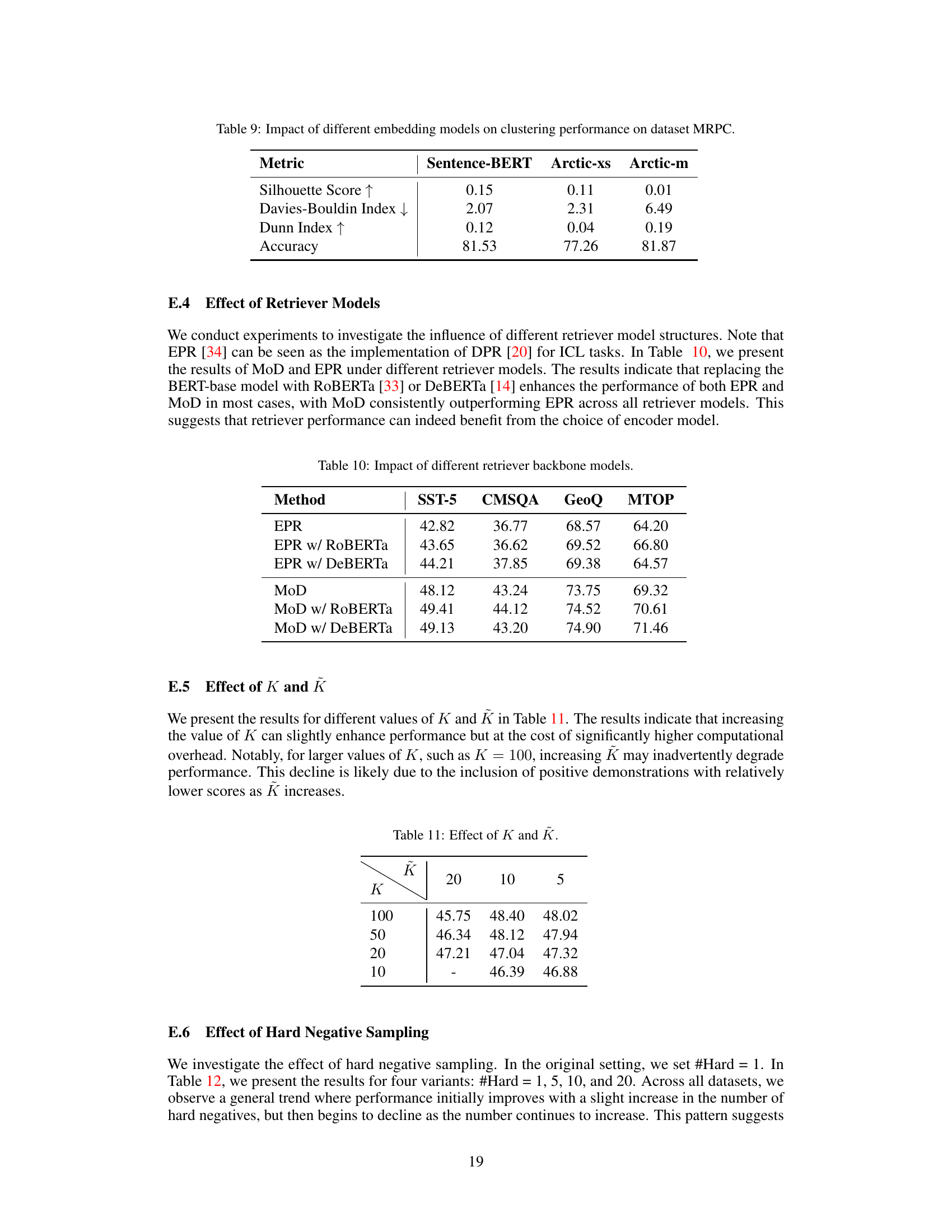
This table presents the results of clustering performance using three different embedding models (Sentence-BERT, Arctic-xs, and Arctic-m) on the MRPC dataset. The metrics used for evaluation are Silhouette Score, Davies-Bouldin Index, Dunn Index, and Accuracy. The table helps to assess the impact of the choice of embedding model on the quality of the resulting clusters, and ultimately on the overall classification accuracy.
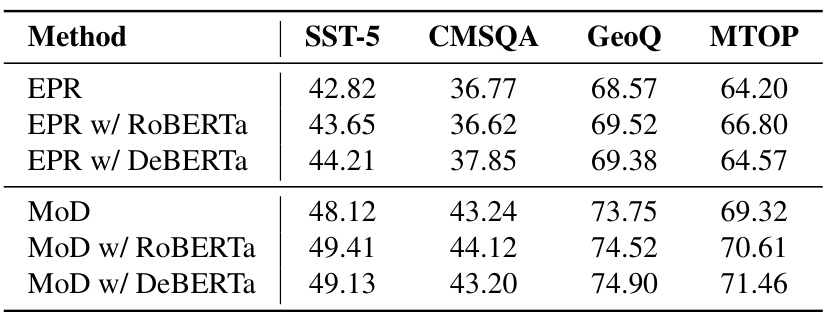
This table presents the results of experiments comparing the performance of EPR and MoD using different retriever models (BERT-base, RoBERTa, and DeBERTa) on four datasets: SST-5, CMSQA, GeoQ, and MTOP. The results show that MoD consistently outperforms EPR across all models, highlighting the benefit of the MoD framework.
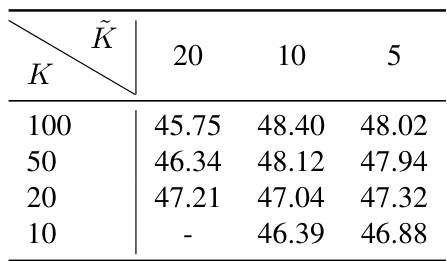
This table presents the results of experiments conducted to evaluate the effect of varying the number of top-K demonstrations retrieved by each expert (K) and the number of candidate demonstrations considered for scoring (K) within the MoD framework. The results demonstrate the impact of these hyperparameters on model performance across different datasets.
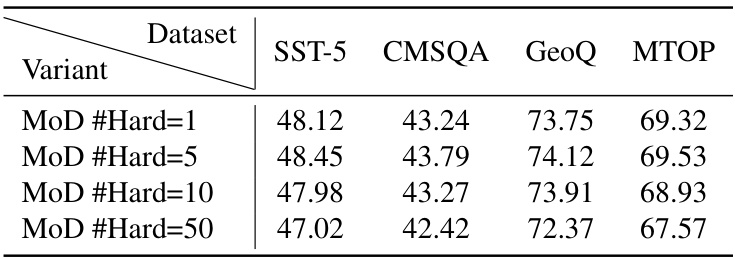
This table presents the ablation study results on the effect of varying the number of hard negative samples in the contrastive learning loss during the expert-wise training of the MoD framework. The results show that using a moderate number of hard negative samples, around 5, yields the best performance across four datasets (SST-5, CMSQA, GeoQ, and MTOP). Increasing the number of hard negatives beyond this optimal point leads to a decline in performance.
Full paper#