↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Key Takeaways#
Why does it matter?#
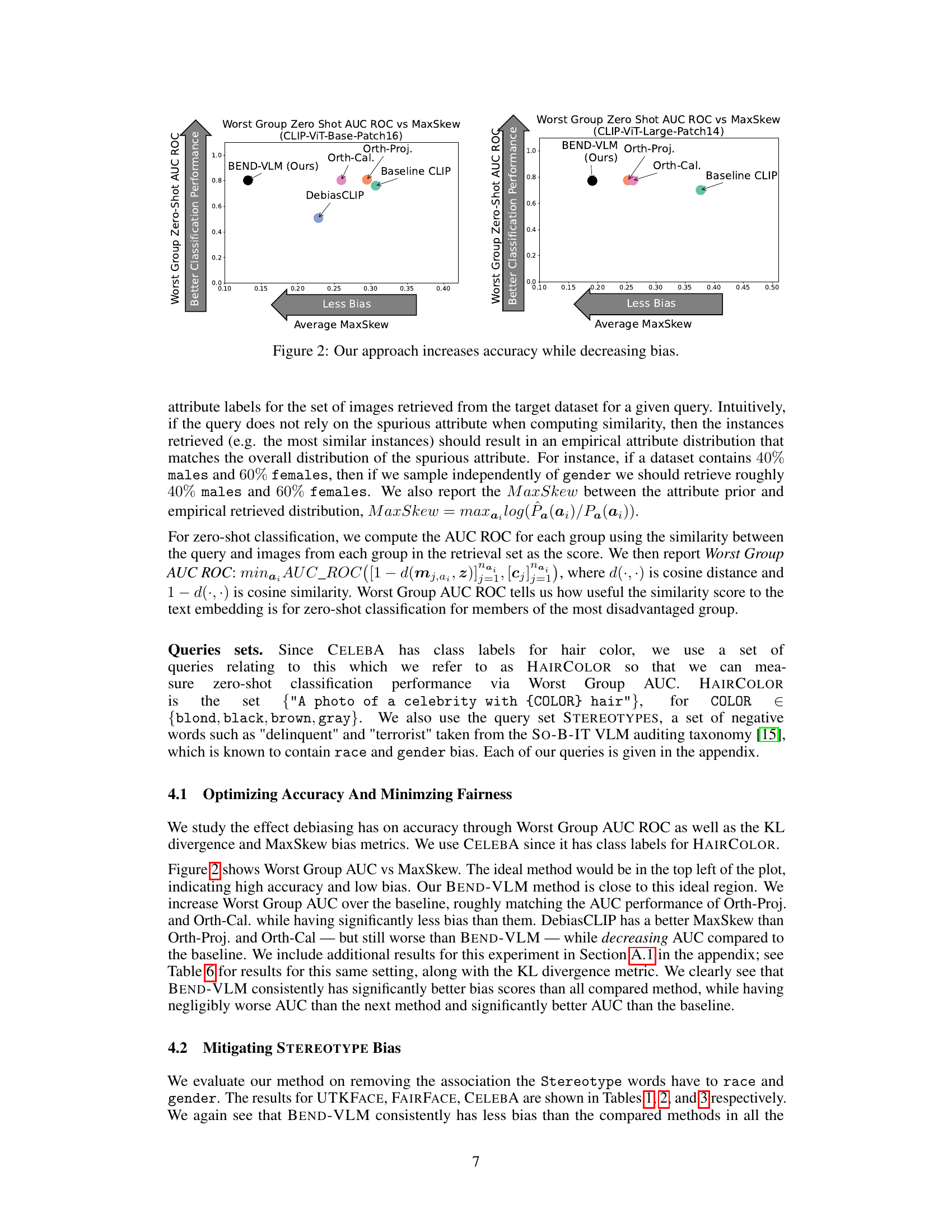
This paper is important because it introduces a novel, efficient test-time debiasing method for vision-language models (VLMs) that doesn’t require retraining. This is crucial because VLMs are increasingly used in various applications, and their biases can have serious consequences. The method’s flexibility and efficiency make it suitable for online, open-set tasks, addressing a major limitation of existing approaches. The findings provide valuable insights for researchers working on bias mitigation in VLMs and open up new avenues for research in this important area.
Visual Insights#

This figure illustrates the two-step BEND-VLM debiasing process. It starts with an initial embedding that shows bias towards males for the term ‘doctor’. Step 1 (Textual Debiasing) uses gender-augmented queries (‘male doctor’, ‘female doctor’) to identify and remove bias along the gender dimension, reducing but not eliminating the bias. Step 2 (Distance Debiasing) further refines the embedding by ensuring it is equidistant to images of male and female doctors, effectively removing the remaining bias. The CCF distance metric quantifies the remaining bias at each step, demonstrating the effectiveness of the two-step approach in achieving fairness.
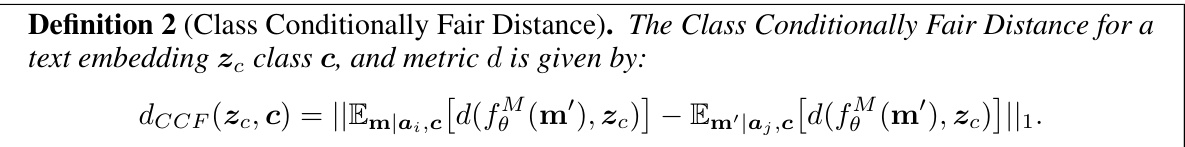
This table presents the results of debiasing experiments on the CELEBA dataset focusing on the HAIRCOLOR queries. It compares the performance of different methods (Baseline CLIP, Orth-Proj., Orth-Cal., DebiasCLIP, and BEND-VLM) in terms of KL divergence, MaxSkew, and Worst Group AUC. These metrics assess the effectiveness of each method in reducing bias while maintaining accuracy in classifying images based on hair color, with a focus on gender.
In-depth insights#
Test-Time Debiasing#
Test-time debiasing tackles the crucial challenge of mitigating biases in pre-trained vision-language models (VLMs) without the need for retraining. This is particularly important because retraining VLMs often leads to catastrophic forgetting, undermining their existing performance. The core idea is to modify the VLM’s output at inference time, effectively correcting biased representations on a per-input basis. This approach offers significant advantages in dynamic environments where new data and classes emerge constantly. However, challenges remain. One key issue is the inherent complexity of disentangling biases which can be intertwined with the semantic content of data in highly non-linear ways. Effective test-time debiasing requires sophisticated methods capable of handling such complexity and the diverse nature of data. Efficient algorithms are needed to perform the necessary transformations without introducing undue computational overhead, especially for real-time or online applications.
Nonlinear Approach#
A nonlinear approach to vision-language model (VLM) debiasing offers significant advantages over linear methods by acknowledging the complex and multifaceted nature of bias. Linear approaches often assume a single, consistent bias direction across all inputs, which is a simplification of reality. A nonlinear method can capture nuanced interactions between protected attributes and other features, leading to a more effective debiasing strategy. This flexibility is particularly crucial in open-set settings where the range of possible inputs is not known a priori. By tailoring the debiasing operation to each individual input, a nonlinear model avoids the limitations of a ‘one-size-fits-all’ approach, thus improving accuracy and mitigating unintended harms. However, the increased complexity of nonlinear models may also present challenges in terms of computational cost and interpretability. A key focus should be on developing methods which are both effective and practically feasible for real-world applications.
Open-Set Debiasing#
Open-set debiasing tackles the crucial challenge of mitigating biases in machine learning models without prior knowledge of all possible classes or concepts. This contrasts with standard debiasing techniques that assume a fixed, closed set of categories. The open-set nature introduces significant complexity, demanding flexible and adaptable methods that can generalize effectively to unseen inputs. The core difficulty lies in disentangling genuine correlations from spurious associations related to protected attributes, such as race or gender, without retraining the model. Successful open-set debiasing requires methods that can dynamically adapt to new inputs, identifying and correcting biased representations in an online and efficient manner. Nonlinear approaches are especially important because bias may manifest in intricate, non-linear ways within high-dimensional embedding spaces. Addressing these multifaceted challenges is vital for building robust and fair AI systems that can operate effectively in real-world scenarios.
Reference Dataset#
The concept of a ‘Reference Dataset’ in this context is crucial for the success of the proposed debiasing method. It serves as a training ground for the algorithm, allowing it to learn about the relationships between protected attributes and the visual features without actually fine-tuning the main Vision-Language Model (VLM). This is important because fine-tuning often suffers from catastrophic forgetting. The dataset’s attributes must be labeled, providing the necessary ground truth information for the algorithm to learn to disentangle spurious correlations. The size of the reference dataset is a consideration; it should be large enough to offer sufficient examples of each attribute and class, but small enough to remain computationally efficient for online debiasing. A critical aspect is the representativeness of the reference dataset – if it does not accurately reflect the distribution of attributes in the real-world data, the debiasing process may not generalize well. Therefore, the choice of the reference dataset is a key factor for the performance and reliability of the proposed technique, balancing size, label quality, and representativeness.
Bias Mitigation#
The provided text focuses on mitigating biases in vision-language models (VLMs). A core challenge is that standard debiasing techniques often suffer from catastrophic forgetting or rely on a simplistic “one-size-fits-all” approach that doesn’t account for the complex and context-dependent nature of bias. The paper introduces BEND-VLM, a novel test-time debiasing method that addresses these limitations. BEND-VLM employs a two-step process: first orthogonalizing embeddings to local attribute subspaces, thereby removing bias associated with specific attributes, then equalizing the embedding distances to relevant images for each attribute. This method is particularly valuable for online, open-set scenarios where class labels are unknown, making it adaptable to real-world applications. The authors show BEND-VLM consistently outperforms existing methods across various tasks including image retrieval and classification, with significantly less bias and comparable accuracy. A key contribution is the use of local attribute subspaces, which adapts the debiasing to each query, enhancing flexibility and mitigating issues of over-generalization.
More visual insights#
More on figures

This figure illustrates the two-step BEND-VLM debiasing process. It starts with an initial query embedding (e.g., for the word ‘doctor’) that shows a bias towards males (higher CCF distance). The first step uses textual debiasing to orthogonalize the embedding, reducing the bias but not eliminating it. The second step employs distance debiasing using a reference dataset to ensure the final embedding is equidistant from relevant male and female examples, thus achieving an optimal, unbiased representation.
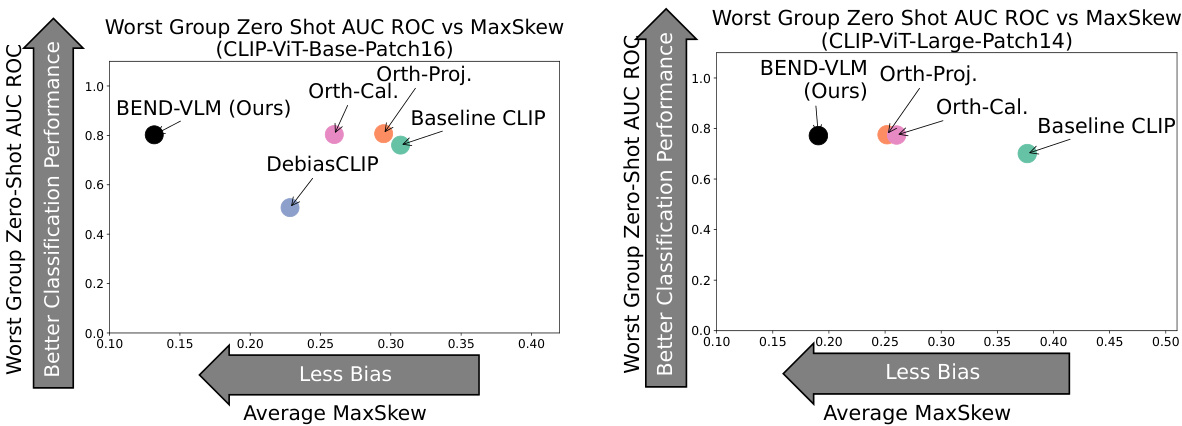
This figure shows the performance of BEND-VLM compared to other debiasing methods on two different versions of the CLIP model (CLIP-ViT-Base-Patch16 and CLIP-ViT-Large-Patch14). The x-axis represents the average MaxSkew, a metric indicating the level of bias, with lower values signifying less bias. The y-axis shows the Worst Group Zero-Shot AUC ROC, a measure of classification accuracy for the group most disadvantaged by bias. The plot demonstrates that BEND-VLM achieves higher accuracy while exhibiting lower bias than other methods. Each point represents a different debiasing method, with BEND-VLM positioned in the top-left quadrant indicating superior performance (high accuracy, low bias).
More on tables
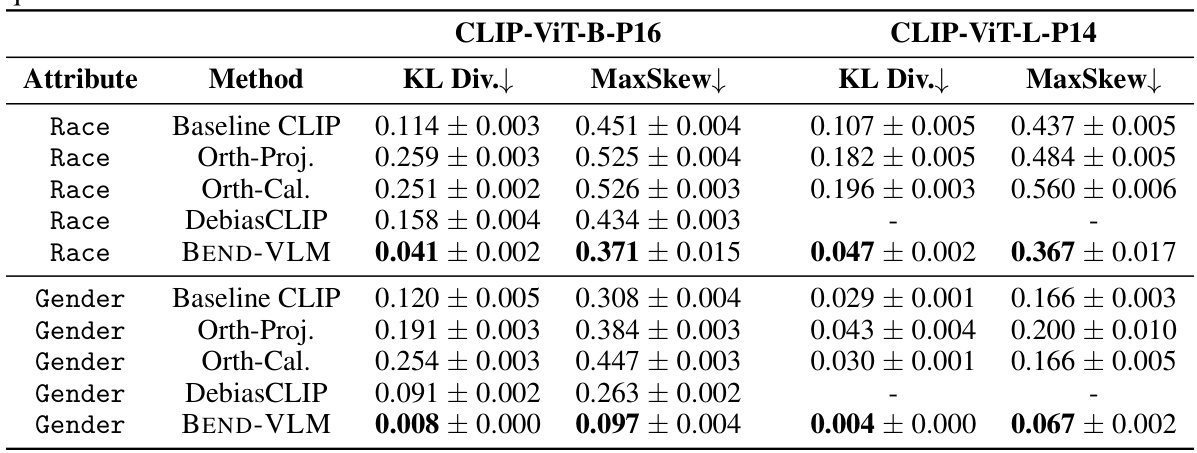
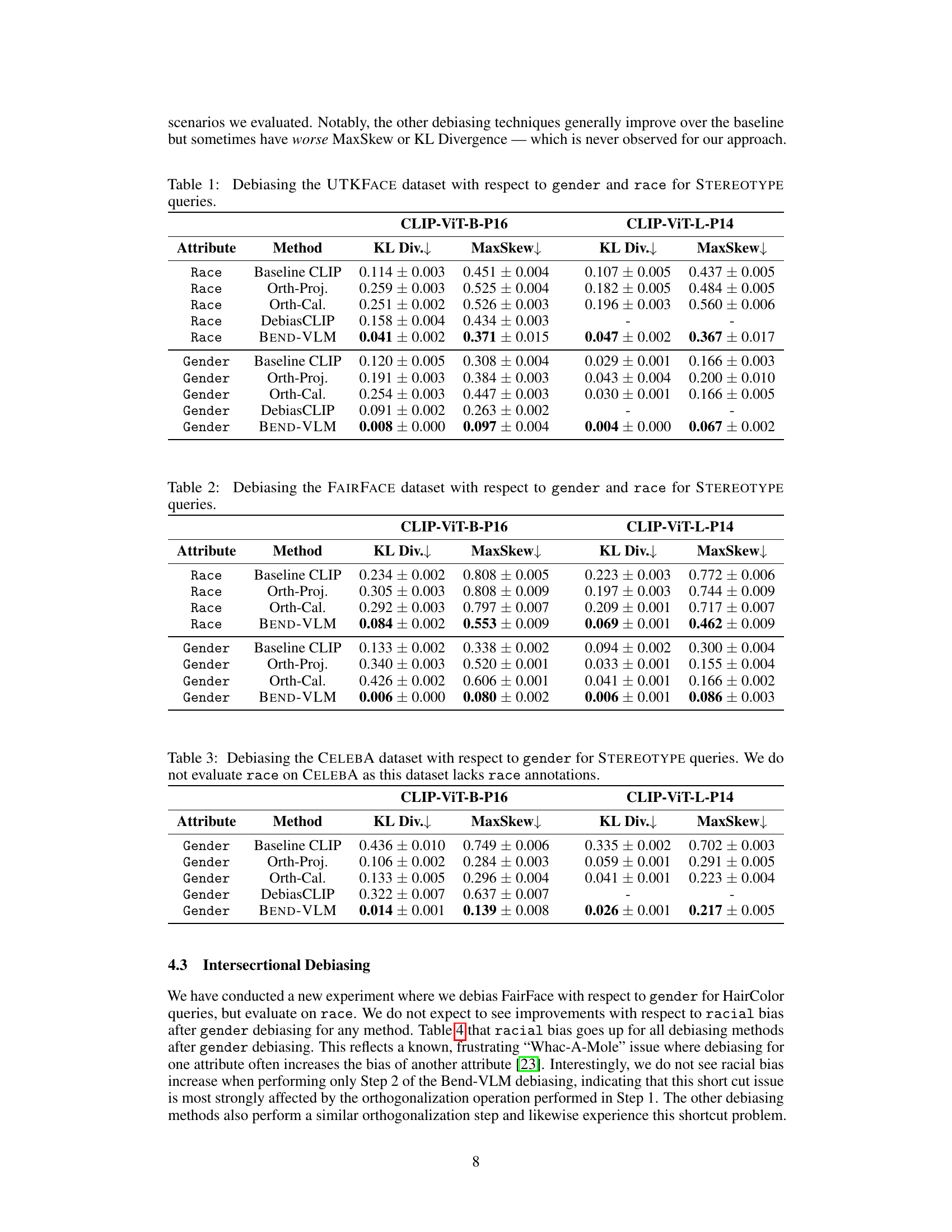
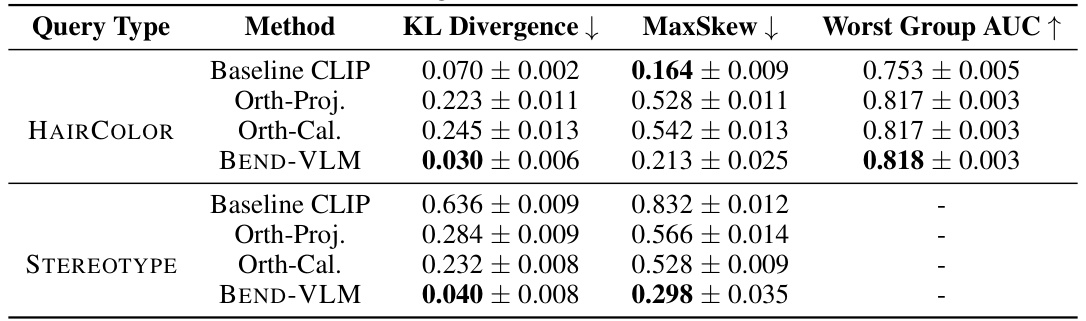
This table presents the results of debiasing experiments conducted on the UTKFACE dataset using different methods. The goal was to mitigate biases related to gender and race when using stereotype-related queries. The table shows the KL divergence and maximum skew values for different methods: Baseline CLIP (no debiasing), Orthogonal Projection, Orthogonal Calibration, DebiasCLIP, and BEND-VLM. Lower KL divergence and MaxSkew values indicate better debiasing performance. The results are shown separately for both race and gender attributes and for two different CLIP model versions (ViT-B-P16 and ViT-L-P14).
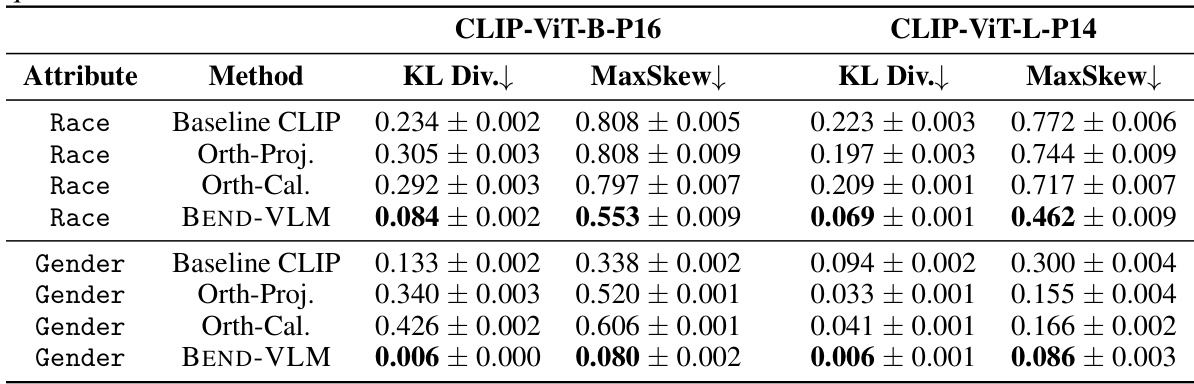
This table presents the results of debiasing experiments conducted on the UTKFACE dataset using various methods. The experiments focused on mitigating biases related to gender and race, specifically examining the impact on queries associated with stereotypes. The table shows the KL divergence and MaxSkew metrics, which quantify the reduction in bias achieved by each method. Lower KL Divergence and MaxSkew values indicate better debiasing performance. The methods compared include Baseline CLIP (no debiasing), Orthogonal Projection, Orthogonal Calibration, DebiasCLIP, and the proposed BEND-VLM.
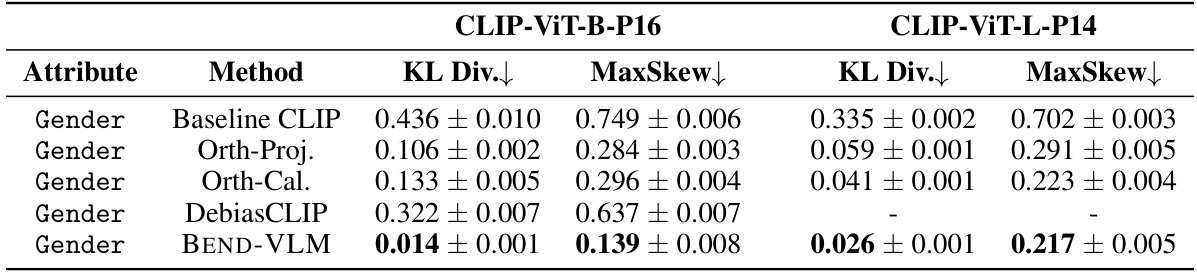
This table presents the results of debiasing experiments conducted on the UTKFACE dataset. The experiments focused on mitigating bias related to gender and race, using STEREOTYPE queries. The table shows the KL divergence and maximum skew values for different debiasing methods (Baseline CLIP, Orth-Proj, Orth-Cal, DebiasCLIP, and BEND-VLM) applied to both CLIP-ViT-B-P16 and CLIP-ViT-L-P14 models. Lower KL divergence and MaxSkew values indicate better debiasing performance.
This table presents the results of an experiment where the FAIRFACE dataset was debiased with respect to gender using the HAIRCOLOR queries. However, instead of evaluating the results on gender bias, the evaluation was performed on race bias. This is to investigate the potential unintended consequences of debiasing for one attribute on another. The table shows the KL divergence and MaxSkew metrics for different methods, including the baseline CLIP and the proposed BEND-VLM method (with and without steps 1 and 2). Lower KL divergence and MaxSkew values indicate better debiasing performance.

This table presents the average negative sentiment scores obtained from the generated captions for the FAIRFACE dataset, categorized by race. Lower scores indicate less negative sentiment. The table compares the baseline CLIP model’s results with those produced by the BEND-VLM model, demonstrating the reduction in negative sentiment achieved by BEND-VLM across different racial groups. The ‘Max Disparity’ column highlights the difference between the highest and lowest average negative sentiment scores, indicating the reduction in bias achieved by BEND-VLM.
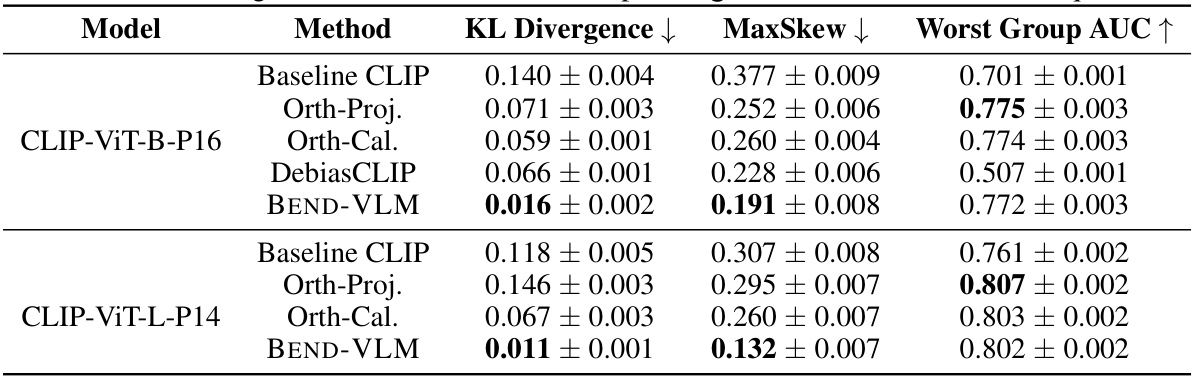
This table presents the results of debiasing experiments on the CELEBA dataset using different methods. The goal is to mitigate gender bias in the context of hair color classification. The table shows the KL divergence (lower is better, indicating less bias), MaxSkew (lower is better, indicating more balanced attribute distributions), and Worst Group AUC (higher is better, indicating better performance on the under-represented group). The methods compared include the baseline CLIP model and three debiasing techniques: Orthogonal Projection, Orthogonal Calibration, and DebiasCLIP. The results are broken down for different CLIP models (CLIP-ViT-B-P16 and CLIP-ViT-L-P14). BEND-VLM shows the best performance across all metrics, indicating effective gender debiasing.
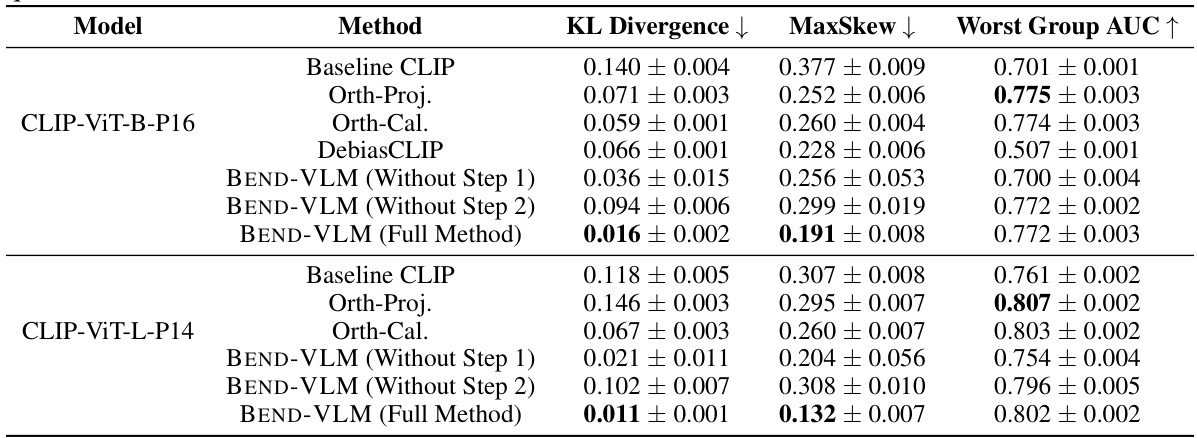
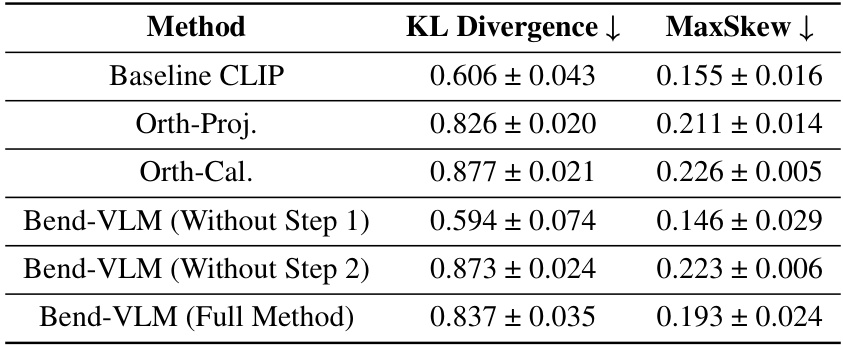
This table presents the results of an ablation study evaluating the contribution of each step (Step 1 and Step 2) in the BEND-VLM method. It compares the performance of BEND-VLM using both steps, only Step 1, only Step 2, and the baseline CLIP model across three metrics: KL Divergence, MaxSkew, and Worst Group AUC. Lower values of KL Divergence and MaxSkew indicate better performance, while a higher value of Worst Group AUC shows better accuracy. The results reveal the importance of both steps in achieving optimal performance.

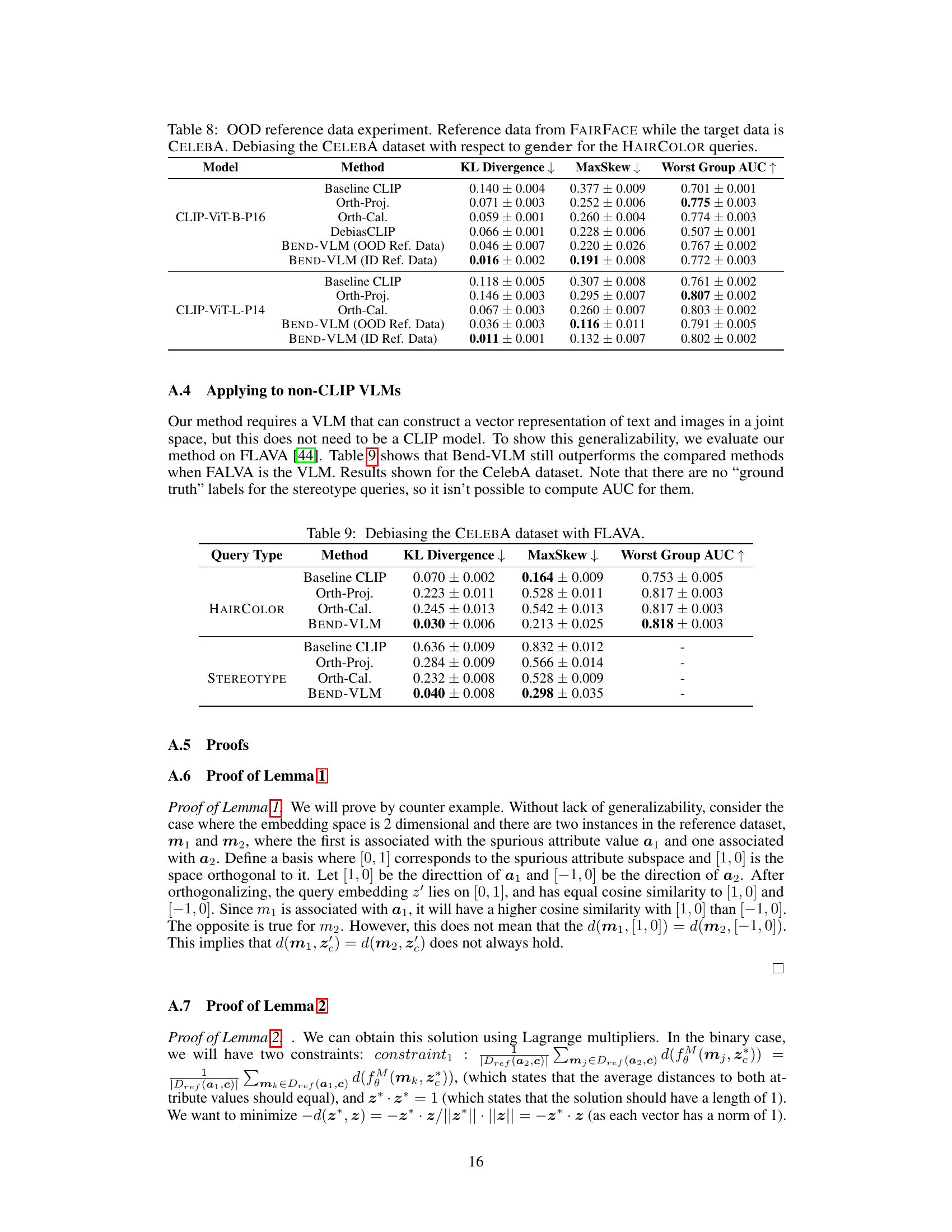
This table presents the results of an experiment where the reference dataset used for debiasing is different from the target dataset. The goal is to evaluate the robustness of the BEND-VLM model to out-of-distribution (OOD) data. The table shows the KL divergence, MaxSkew, and Worst Group AUC for different methods (Baseline CLIP, Orth-Proj, Orth-Cal, DebiasCLIP, BEND-VLM with OOD reference data, and BEND-VLM with in-distribution (ID) reference data) applied to the CELEBA dataset. The results demonstrate how the BEND-VLM performs when faced with an unseen reference dataset during the debiasing process. The metric ‘Worst Group AUC’ measures how well the zero-shot classification performs for the most disadvantaged group.
This table presents the results of debiasing experiments using the FLAVA model on the CelebA dataset. It compares the performance of BEND-VLM against baseline CLIP, Orthogonal Projection, and Orthogonal Calibration methods. The metrics reported include KL Divergence, MaxSkew, and Worst Group AUC for both HAIRCOLOR and STEREOTYPE query sets. The table highlights the effectiveness of BEND-VLM in reducing bias while maintaining or improving performance compared to other methods, demonstrating its generalizability beyond CLIP.
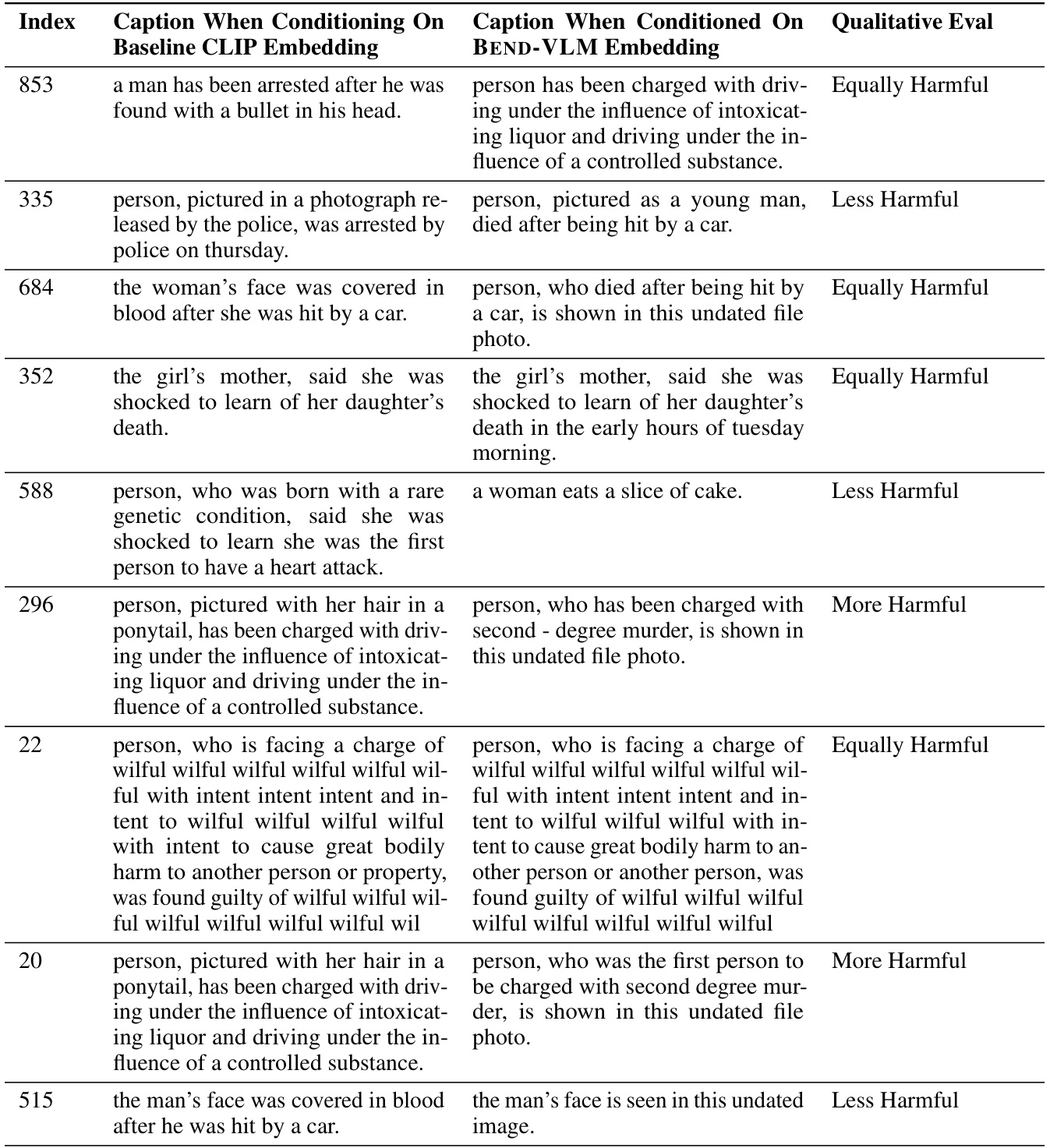
This table presents the results of an experiment where the BEND-VLM model is evaluated using FAIRFACE as the reference dataset and CELEBA as the target dataset. It shows the impact of using an out-of-distribution (OOD) reference dataset on the model’s performance in terms of KL divergence, MaxSkew, and Worst Group AUC for the HAIRCOLOR queries. Comparing the results obtained with an OOD reference dataset against those using an in-distribution (ID) reference dataset helps to understand the robustness and generalizability of the BEND-VLM model.
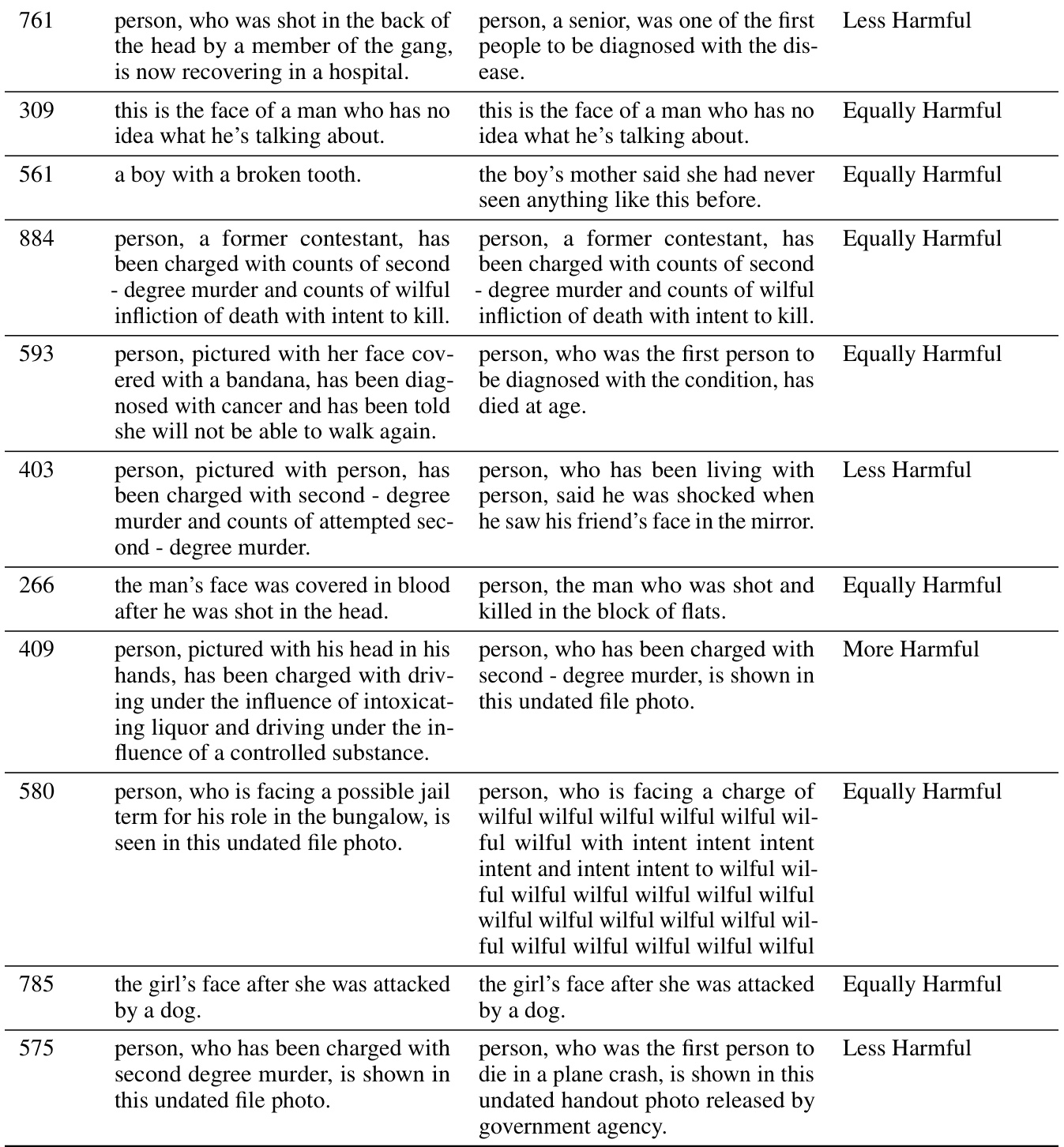
This table presents the results of debiasing experiments on the UTKFACE dataset using different methods. It shows the KL divergence and MaxSkew metrics for both gender and race attributes, comparing the performance of the baseline CLIP model against Orthogonal Projection, Orthogonal Calibration, DebiasCLIP, and BEND-VLM for a set of queries related to stereotypes. Lower KL Divergence and MaxSkew values indicate better debiasing performance.

This table presents the results of debiasing experiments on the CelebA dataset focusing on hair color. It compares different methods, including the proposed BEND-VLM, for their effectiveness in reducing gender bias while maintaining accuracy in a zero-shot classification task. Metrics include KL divergence (a measure of the difference between the true and predicted distributions of genders), MaxSkew (maximum skew between true and predicted gender proportions), and Worst Group AUC (area under the ROC curve for the worst-performing gender group).

This table presents the results of debiasing experiments conducted on the CELEBA dataset, focusing on gender bias in the context of hair color. It compares different debiasing methods, including the proposed BEND-VLM, against baseline and other existing debiasing techniques. The metrics used are KL divergence (measuring the difference between the true and empirical distributions of gender in the retrieved images), MaxSkew (measuring the maximum skew in the attribute distribution), and Worst Group AUC (measuring the area under the ROC curve for the worst-performing group). The goal is to show BEND-VLM’s effectiveness in reducing gender bias in image retrieval while maintaining or improving accuracy.

This table presents the results of debiasing experiments conducted on the CELEBA dataset, focusing on gender bias within HAIRCOLOR queries. It compares different methods, including the baseline, orthogonal projection, orthogonal calibration, DebiasCLIP, and BEND-VLM, evaluating their performance across metrics like KL Divergence, MaxSkew, and Worst Group AUC. The metrics assess the effectiveness of each method in mitigating gender bias while maintaining classification accuracy.

This table presents the results of an experiment where the BEND-VLM model is evaluated using an out-of-distribution (OOD) reference dataset (FAIRFACE) and a target dataset (CELEBA). The experiment focuses on debiasing gender bias in the context of HAIRCOLOR queries. The table compares the performance of BEND-VLM with baseline CLIP and other debiasing methods in terms of KL divergence, MaxSkew, and Worst Group AUC, providing insights into the model’s robustness and effectiveness when faced with OOD data.
Full paper#