TL;DR#
Open-vocabulary segmentation models struggle due to imprecise and inaccurate class names in existing benchmark datasets. This imprecision hinders model generalization and accurate evaluation, leading to discrepancies between model outputs and actual visual segments. The lack of consistent, high-quality names is a significant hurdle.
To overcome this, the authors introduce RENOVATE, a framework that automatically improves class names. RENOVATE leverages foundation models for automated renaming, significantly reducing manual effort. The improved names lead to up to 15% better model performance and increased training efficiency. Furthermore, the study reveals that RENOVATE allows for more fine-grained analysis of model performance, enhancing evaluation benchmarks and providing valuable insights for future model improvements and dataset curation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in open-vocabulary segmentation. It addresses a critical yet overlooked problem: the impact of imprecise class names in benchmark datasets. RENOVATE’s framework provides a practical solution to improving data quality and model evaluation, opening avenues for more robust and efficient open-vocabulary models. This work is relevant to the broader vision-language field, pushing the boundaries of how we approach dataset creation and evaluation.
Visual Insights#

🔼 This figure shows examples of inaccurate, overly general, and context-lacking names from popular segmentation datasets (MS COCO, ADE20K, and Cityscapes). It highlights how the original names in these benchmarks often fail to capture the precise visual content of the segments, leading to issues with model generalization and evaluation. The figure then shows how the authors’ ‘renovated’ names provide more accurate and descriptive labels, improving alignment with human understanding and enabling better model performance.
read the caption
Figure 1: Problems of names in current segmentation benchmarks. We demonstrate examples from well-known datasets: MS COCO [13], ADE20K [14], and Cityscapes [15]. Our renovated names are visually more aligned and help models to generalize better.

🔼 This table shows examples of how context names are used to generate candidate names for three classes from the ADE20K dataset. It highlights the importance of context in disambiguating polysemous words (words with multiple meanings) and generating more precise and descriptive names for the visual segments. The original names are compared with generated candidate names, showing how the context helps to refine the descriptions.
read the caption
Table 1: Examples of context names and generated candidate names for three selected classes from ADE20K. Context names are key to comprehending general terms such as “field” and “box” and disambiguating polysemous terms like “cradle”, which, in this context, refers to a baby bed rather than a phone cradle or a mining tool.
In-depth insights#
Name Renovation#
The concept of “Name Renovation” in the context of open-vocabulary image segmentation is a novel approach to improving model performance and evaluation. The core idea revolves around enhancing the precision and descriptive quality of class labels in existing datasets. Poorly defined or ambiguous names hinder model generalization and accurate evaluation. By improving the names, the research aims to bridge the gap between human understanding of visual concepts and the machine’s interpretation. A key aspect is the use of a renaming model, likely trained on a large language model (LLM) and image captioning model, to suggest improved names for each visual segment. This automated approach addresses the limitations of manual annotation, making the process scalable and more consistent. The results suggest that improved names facilitate improved model training, resulting in significant performance gains, as well as enabling a more fine-grained analysis of model outputs and errors.
Model Training#
The success of open-vocabulary segmentation models hinges on robust model training strategies. Effective training leverages large, high-quality datasets with precisely annotated visual segments and associated class names. However, the quality of class names in existing datasets is often suboptimal, impacting model generalization. This research addresses this issue by introducing a novel name-refinement approach, RENOVATE, which generates more precise names for each segment. The resulting refined names enable the training of stronger open-vocabulary segmentation models, achieving a notable performance improvement. The training methodology itself likely incorporates strategies to handle the increased complexity resulting from the richer name space, potentially involving techniques like negative sampling to enhance model generalization and data efficiency. The impact of training with the improved names is evaluated by comparing performance against models trained with original names and other name refinement strategies. Careful analysis of the training process provides key insights into the importance of high-quality naming for optimal model performance and demonstrates the efficacy of RENOVATE in significantly improving open-vocabulary segmentation model capabilities.
Evaluation Metrics#
Choosing the right evaluation metrics is crucial for assessing the performance of open-vocabulary segmentation models. Standard metrics, like mean Intersection over Union (mIoU), while widely used, might not fully capture the nuances of semantic similarity between predicted and ground truth labels. The paper highlights the limitations of traditional metrics in evaluating fine-grained semantic differences, particularly when dealing with the detailed and descriptive names generated by their RENOVATE framework. This motivates the adoption of open evaluation metrics [40], which incorporate semantic similarity scores to provide more contextually relevant assessments. This shift highlights the importance of moving beyond simple class-level accuracy to a more nuanced evaluation that considers the semantic relationship between predicted and ground-truth segment labels. The open metrics approach helps to better identify and understand the types of errors that the model is making, such as benign misclassifications, where the predicted label is semantically close to the ground truth but not exactly the same. The transition to semantic similarity-based metrics is a significant advancement in evaluating open-vocabulary models, which allows for a more comprehensive and accurate evaluation of their performance. The combination of both standard and open metrics offers a more holistic and informative view of the model capabilities.
Benchmark Impact#
The “Benchmark Impact” section of a research paper would critically assess how the proposed work affects existing benchmarks in the field. This goes beyond simply reporting improved performance; a strong analysis would delve into the why behind the improvements. It should discuss whether the advancements are due to inherent improvements in the method itself, or are a result of addressing limitations or biases within the benchmark datasets. Specific examples showing how the work directly interacts with or improves the benchmark’s metrics, such as precision, recall, or F1-score for specific classes, are crucial. Furthermore, the analysis should determine if the improvements generalize across different benchmarks or are specific to a particular dataset. Addressing potential biases within the benchmark and how the work mitigates these would demonstrate robustness and reliability. Finally, it needs to evaluate the long-term implications. Do the findings suggest a need for benchmark redesign or further research to address identified shortcomings? A thoughtful analysis would demonstrate the work’s significance and impact, solidifying its contributions to the research community.
Future Directions#
Future research could explore several avenues to enhance the RENOVATE framework. Improving the name generation process is key; while GPT-4 demonstrates promise, exploring other large language models or incorporating multi-modal techniques could yield superior results. Automating the verification process currently relying on human annotators would significantly improve scalability. This might involve employing multiple vision-language models for consensus-based naming or developing a more sophisticated metric for automatically assessing name quality. Expanding the scope to encompass a wider range of datasets and tasks beyond panoptic segmentation would also strengthen RENOVATE’s generalizability and impact. Additionally, investigating the impact of improved names on downstream applications, such as object detection or action recognition, would highlight the broader usefulness of this method. Finally, a thorough examination of potential biases introduced by the foundation models used in name generation is crucial to ensure fairness and avoid the perpetuation of existing societal biases.
More visual insights#
More on figures
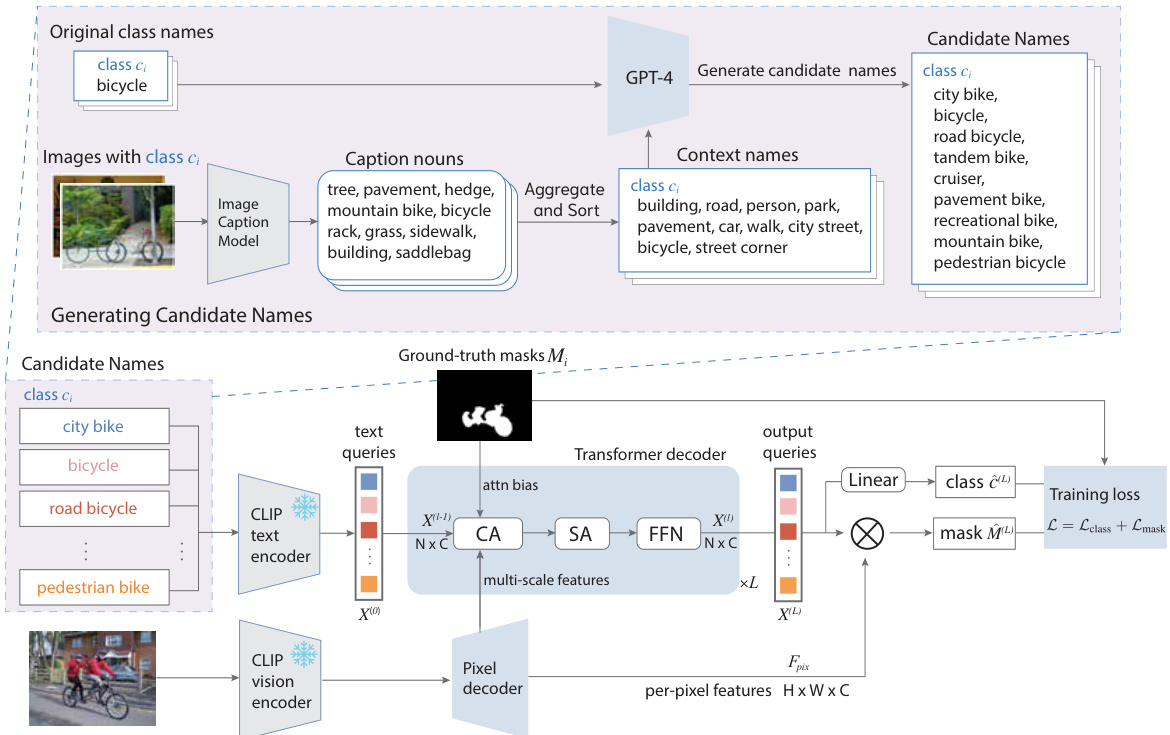
🔼 This figure illustrates the two-step process of RENOVATE: candidate name generation and renaming model training. First, a pool of candidate names is generated for each class using GPT-4, informed by original class names and context names derived from image captions. Then, a renaming model is trained to match these candidate names with the corresponding ground-truth segmentation masks. The model uses a CLIP-based vision encoder, a transformer decoder, and a pixel decoder to integrate visual and textual information, selecting the best-matching candidate name for each segment based on pixel-wise alignment. The figure simplifies the process by showcasing only one segment, but in practice, multiple segments are trained jointly.
read the caption
Figure 2: Overview of candidate name generation and renaming model training. We generate candidate names based on the context names and train the renaming model to match them with the segments. For illustration clarity, we show only one segment. In practice, multiple segments are jointly trained, pairing with the text queries.
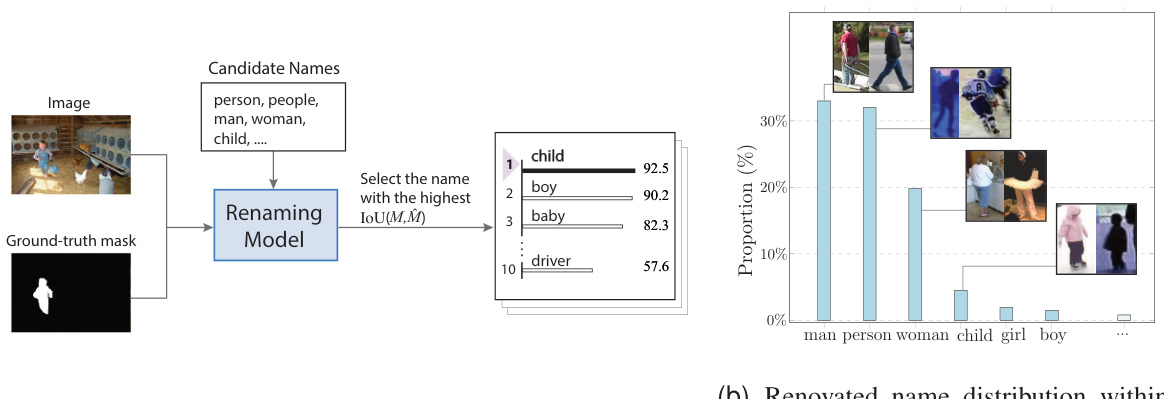
🔼 This figure shows the process of obtaining renovated names using a renaming model. Part (a) illustrates the process: the model takes ground truth segment masks and candidate names as input and selects the name with the highest IoU (Intersection over Union) score with the ground truth mask. Part (b) demonstrates the usefulness of the renovated names for dataset analysis by showing the distribution of renovated names within the original ‘person’ class, highlighting the ability to perform more granular analysis.
read the caption
Figure 3: Obtaining renovated names. In (a) we illustrate how we use the renaming model to obtain a renovated name for each segment. In (b) we demonstrate that the renaming results are helpful to dataset analysis with examples from 'person' class.
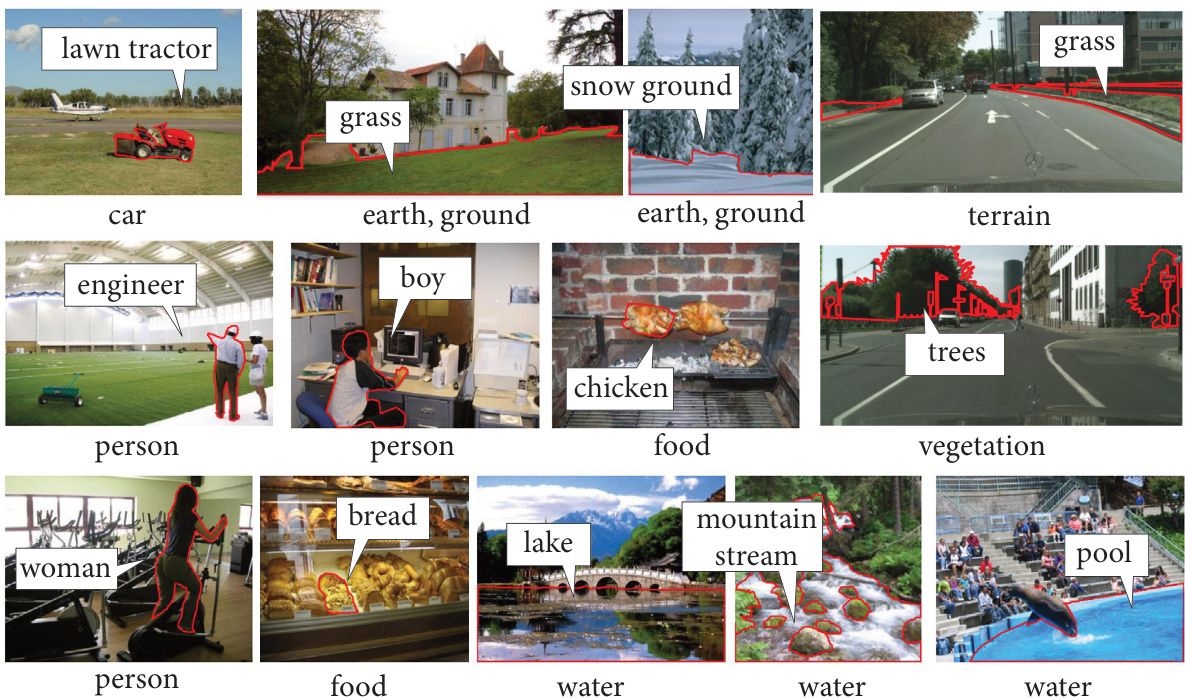
🔼 This figure shows several examples of how the model renovates names for image segments. For each segment, a comparison between the original name and the renovated name is provided. The goal is to show how the renovated names are more accurate and descriptive of the visual content, aligning better with human-level categorization.
read the caption
Figure 4: Examples of renovated names on segments from the validation sets of ADE20K and Cityscapes. For each segment, we show the original name below the image and the renovated name in the text box. See more visual results in the supplements.
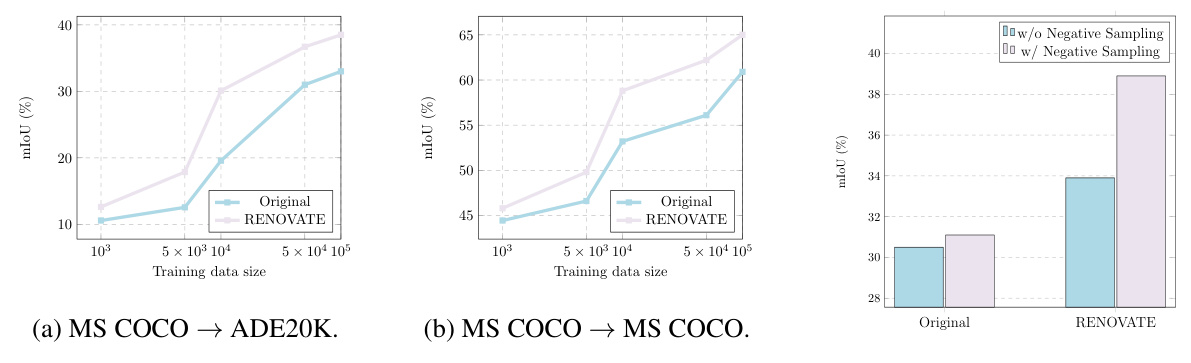
🔼 This figure compares the data efficiency of training models using RENOVATE names versus original names. The results show that models trained with RENOVATE names achieve comparable performance with significantly less training data compared to those trained with original names. This highlights the improved data quality and enhanced training efficiency provided by RENOVATE names.
read the caption
Figure 5: Data efficiency comparison between RENOVATE and original names.
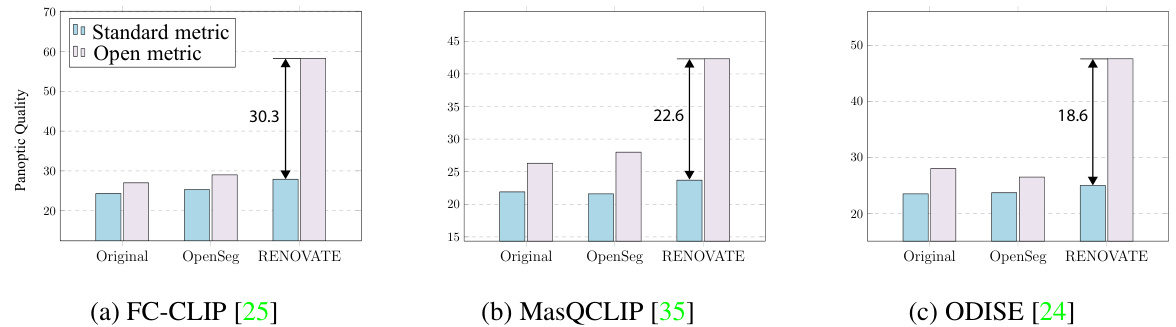
🔼 This figure compares the performance of three different open-vocabulary segmentation models (FC-CLIP, MasQCLIP, and ODISE) on the ADE20K dataset using three different sets of names (Original, OpenSeg, and RENOVATE). It shows the Panoptic Quality (PQ) using both standard and open metrics. The results highlight the impact of using RENOVATE names, demonstrating improved performance, especially when using open metrics which account for semantic similarity between names.
read the caption
Figure 7: Open-vocabulary evaluation on ADE20K with different names, metrics, and models.
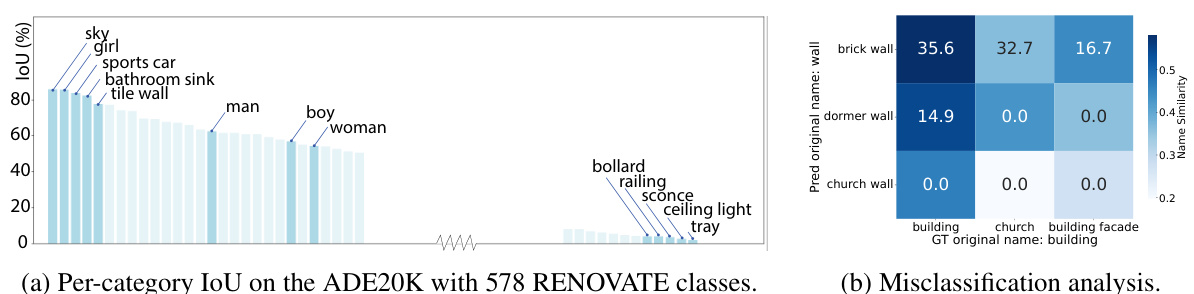
🔼 This figure demonstrates the ability of RENOVATE names to enable more fine-grained analysis of model performance. Subfigure (a) shows a per-category Intersection over Union (IoU) analysis on the ADE20K dataset using 578 RENOVATE classes. This illustrates the model’s performance on various categories, highlighting those with high and low IoU scores. Subfigure (b) presents a misclassification analysis focusing on the frequent misclassifications of ‘building’ as ‘wall’, detailing the proportion of each misclassification and the semantic similarity between the misclassified names.
read the caption
Figure 8: RENOVATE names enable more fine-grained analysis on models. (a) Per-category IoU with highlighted top/bottom-5 RENOVATE names and selected names from the “person

🔼 The figure shows the results of a human preference study comparing the original names used in existing datasets with the RENOVATE names generated by the proposed method. 20 researchers were asked to choose the name that best matches a set of image segments. The results show a significant preference (82%) for the RENOVATE names, suggesting that these names are a better reflection of the visual content than the original names.
read the caption
Figure B.1: Human preference study. A survey of 20 researchers is conducted to compare preferences between the original names versus RENOVATE names on the validation sets. RENOVATE names are favored in 82% cases.
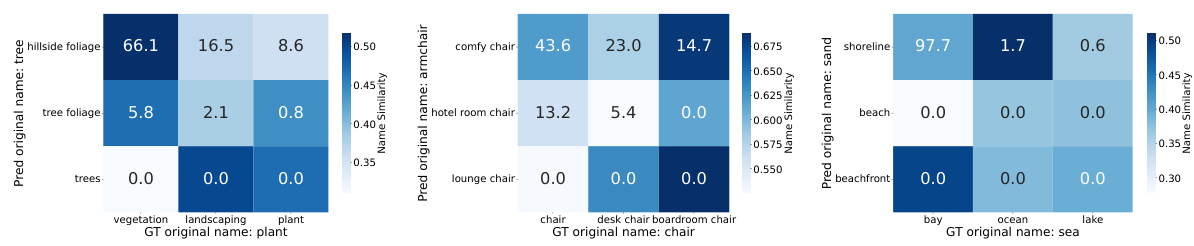
🔼 This figure shows more examples of fine-grained misclassification analysis using RENOVATE names. The analysis reveals that many misclassifications are semantically close to the ground truth, highlighting the value of RENOVATE names in providing more nuanced model evaluation. Each subfigure displays a confusion matrix showing the frequency of misclassifications between similar names.
read the caption
Figure B.2: More examples of fine-grained misclassification analysis.

🔼 This figure shows a human evaluation study comparing the original names and RENOVATE names for segments in ADE20K and Cityscapes validation sets. Part (a) displays the user interface used for verification, where human annotators choose the best name among several suggestions provided by the model. Part (b) shows a bar graph indicating that RENOVATE names significantly reduce the time required for the verification process.
read the caption
Figure C.1: Human verification for upgrading benchmarks. We ask 5 human annotators to verify the names of segments in the validation sets of ADE20K and Cityscapes. As shown in (a), humans are given the top 3 suggestions from the model and are asked to verify the selected name or choose a more matching name from either the other top 3 names or the rest of the candidate names. (b) shows that RENOVATE name suggestions significantly speed up the human verification/annotation process.
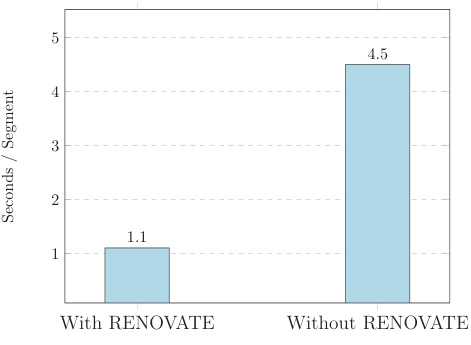
🔼 This figure shows the human verification process of the names generated by the RENOVATE model. Part (a) illustrates the user interface used in the verification study, where annotators select the best name from a list of suggestions for each image segment. Part (b) presents a bar graph comparing the time taken per segment for name verification when using RENOVATE suggestions versus when not using them. The results show that the RENOVATE suggestions significantly reduce the time required for verification.
read the caption
Figure C.1: Human verification for upgrading benchmarks. We ask 5 human annotators to verify the names of segments in the validation sets of ADE20K and Cityscapes. As shown in (a), humans are given the top 3 suggestions from the model and are asked to verify the selected name or choose a more matching name from either the other top 3 names or the rest of the candidate names. (b) shows that RENOVATE name suggestions significantly speed up the human verification/annotation process.

🔼 This figure shows two examples where human annotators and the model disagree on the best name for a segment. The first example highlights the difficulty in naming extremely small segments. The second example illustrates ambiguity when visual cues are insufficient to confidently determine the most appropriate name.
read the caption
Figure C.2: Typical cases when humans and models disagree during human verification. We show two typical cases when humans may choose different names from our model-selected names. (a) shows when segments are too small to recognize, it can be difficult to decide which name is correct. This may indicate a limitation of our renaming method on extremely small objects. (b) shows when there is a lack of sufficient visual cues to infer the names of the segments, the choices are ambiguous. For example, both “river” and “lake” are reasonable choices for the segment in the top right image without more information of the scene. Note (a) and (b) consist only a minority of all the segments.

🔼 This figure shows more examples of how the RENOVATE model improves names in the MS COCO dataset. For each image segment, the original name given in the dataset is shown below the image, alongside the improved name generated by the RENOVATE model, displayed in a text box. The improved names tend to be more descriptive and accurate representations of the visual content.
read the caption
Figure E.2: More examples of renovated names on segments from the validation set of MS COCO. For each segment, we show the original name below the image and the renovated name in the text box.

🔼 This figure shows more examples on how the renaming model selects the best matching names for image segments, based on the intersection over union (IoU) scores between the predicted mask and the ground truth mask. Each example shows the original name, the top-ranked RENOVATE name and the IoU score, along with several alternative names and their respective IoU scores. It visually demonstrates the model’s ability to identify semantically-aligned names from the candidate pool, even if the top-ranked name is not a perfect match.
read the caption
Figure D.1: More examples on name selection based on IoU scores.

🔼 This figure shows several examples of image segments from ADE20K and Cityscapes datasets. For each segment, the original name given in the dataset and the new name generated by the RENOVATE model are displayed. The goal of the RENOVATE model is to provide more precise and descriptive names that align better with human intuition and basic categories. The supplementary materials contain more examples.
read the caption
Figure 4: Examples of renovated names on segments from the validation sets of ADE20K and Cityscapes. For each segment, we show the original name below the image and the renovated name in the text box. See more visual results in the supplements.
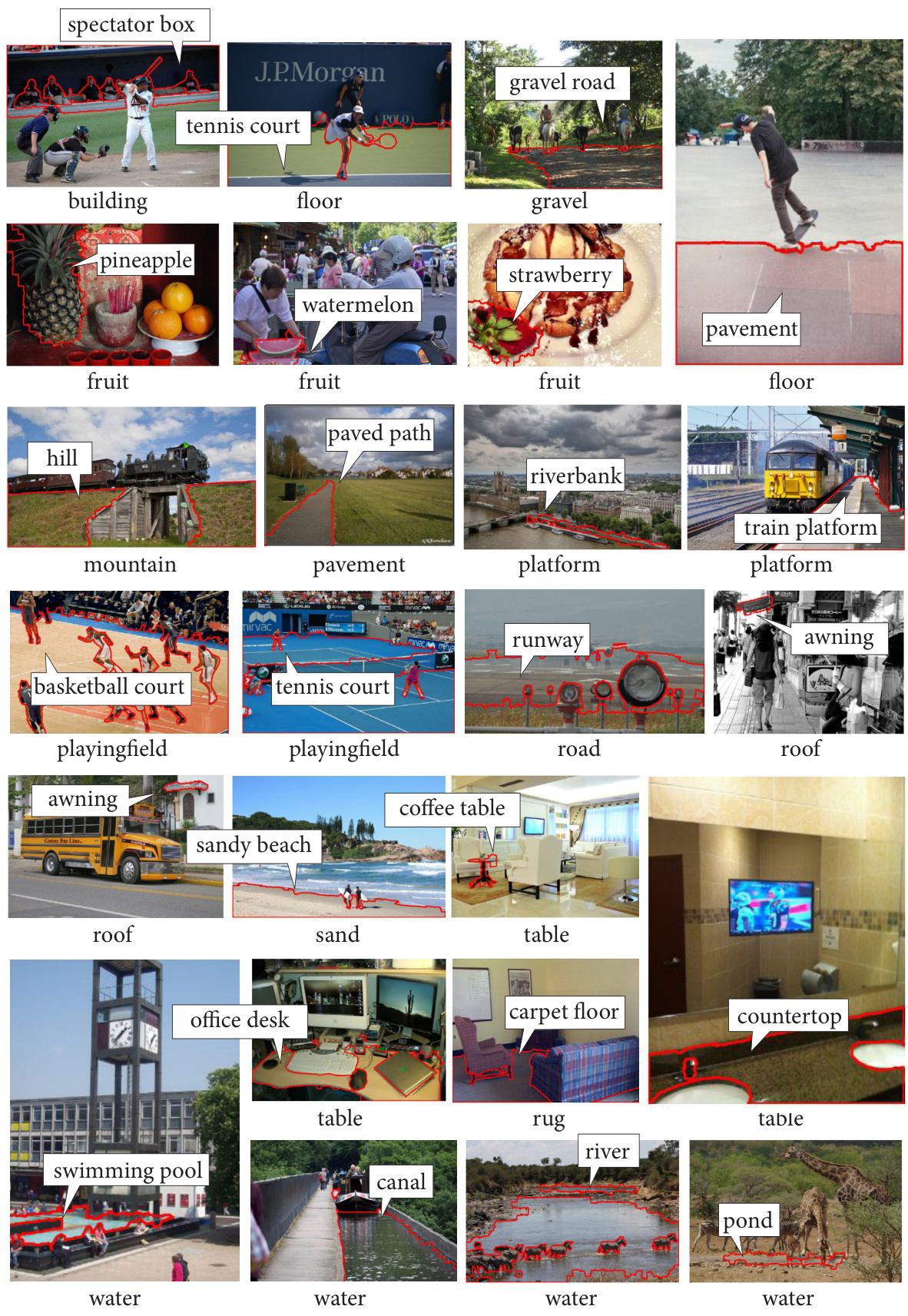
🔼 This figure shows several examples of how the model renovates names in the ADE20K and Cityscapes datasets. Each example shows a segment from an image, with the original name given below it and the improved, more specific name provided in a text box above it. This demonstrates the model’s ability to provide more accurate and descriptive names for visual segments.
read the caption
Figure 4: Examples of renovated names on segments from the validation sets of ADE20K and Cityscapes. For each segment, we show the original name below the image and the renovated name in the text box. See more visual results in the supplements.

🔼 This figure demonstrates RENOVATE’s ability to identify and correct inaccurate annotations in existing datasets. It shows several examples where the original name assigned to a segment is incorrect, and the RENOVATE model proposes a more accurate and descriptive name. This highlights the model’s capability to improve data quality by aligning names with the actual visual content of the segments.
read the caption
Figure E.3: RENOVATE can find wrong annotations and suggest corrections.

🔼 This figure shows three examples of how RENOVATE identifies segments with shared semantic concepts across different datasets (COCO and ADE20K). In each example, a segment from COCO is labeled with a general name (e.g., ‘paper’, ‘counter’, ‘pavement’). RENOVATE then refines this name to a more precise and descriptive label (e.g., ‘paper bag’, ‘bar counter’, ‘runway’). Importantly, the refined names accurately reflect the visual content of the segments and are consistent across the two datasets, demonstrating that RENOVATE can identify shared semantic concepts despite dataset-specific naming conventions.
read the caption
Figure E.4: RENOVATE uncovers segments with shared semantic concepts across datasets.

🔼 This figure shows four examples of how the RENOVATE model can rename segments in images using generated masks from SAM2 and image tags from RAM. Each image has the RAM-generated tags listed as captions and the SAM2-generated masks are overlaid with their respective RENOVATE names. Note that some objects might not be fully segmented by SAM2, and thus, not all objects will have corresponding tags.
read the caption
Figure E.5: RENOVATE can rename segments on generated masks and image tags. We show the full list of the image-level RAM-generated tags as captions of each image and plot all SAM2-generated masks with their best-matching tags. Note some objects are not shown in the image as they are not segmented out by SAM2.

🔼 This figure demonstrates RENOVATE’s ability to rename segments even when the segments are generated by other models rather than ground truth annotations. It showcases the use of RENOVATE with SAM (Segment Anything Model) generated masks and RAM (Recognize Anything Model) generated image tags. The image shows several segments with their corresponding RENOVATE-generated names, highlighting the model’s capability to provide relevant names even for segments not perfectly delineated in the original image.
read the caption
Figure E.5: RENOVATE can rename segments on generated masks and image tags. We show the full list of the image-level RAM-generated tags as captions of each image and plot all SAM2-generated masks with their best-matching tags. Note some objects are not shown in the image as they are not segmented out by SAM2.

🔼 This figure shows four examples where RENOVATE is used to rename segments in images. The top row shows that RENOVATE can rename segments generated by SAM2 in the image using generated image tags from RAM. The bottom row shows another set of examples using the same methodology. The results illustrate that RENOVATE can generate relevant names even for segments in images that were not segmented by SAM2.
read the caption
Figure E.5: RENOVATE can rename segments on generated masks and image tags. We show the full list of the image-level RAM-generated tags as captions of each image and plot all SAM2-generated masks with their best-matching tags. Note some objects are not shown in the image as they are not segmented out by SAM2.

🔼 This figure demonstrates the application of RENOVATE to generated masks from the SAM2 model and image tags from RAM. It showcases that RENOVATE can provide names for segments even when the input is not from a fully annotated dataset. The figure illustrates several examples of images, their associated RAM-generated tags, and the SAM2 masks with corresponding RENOVATE-generated names.
read the caption
Figure E.5: RENOVATE can rename segments on generated masks and image tags. We show the full list of the image-level RAM-generated tags as captions of each image and plot all SAM2-generated masks with their best-matching tags. Note some objects are not shown in the image as they are not segmented out by SAM2.
More on tables

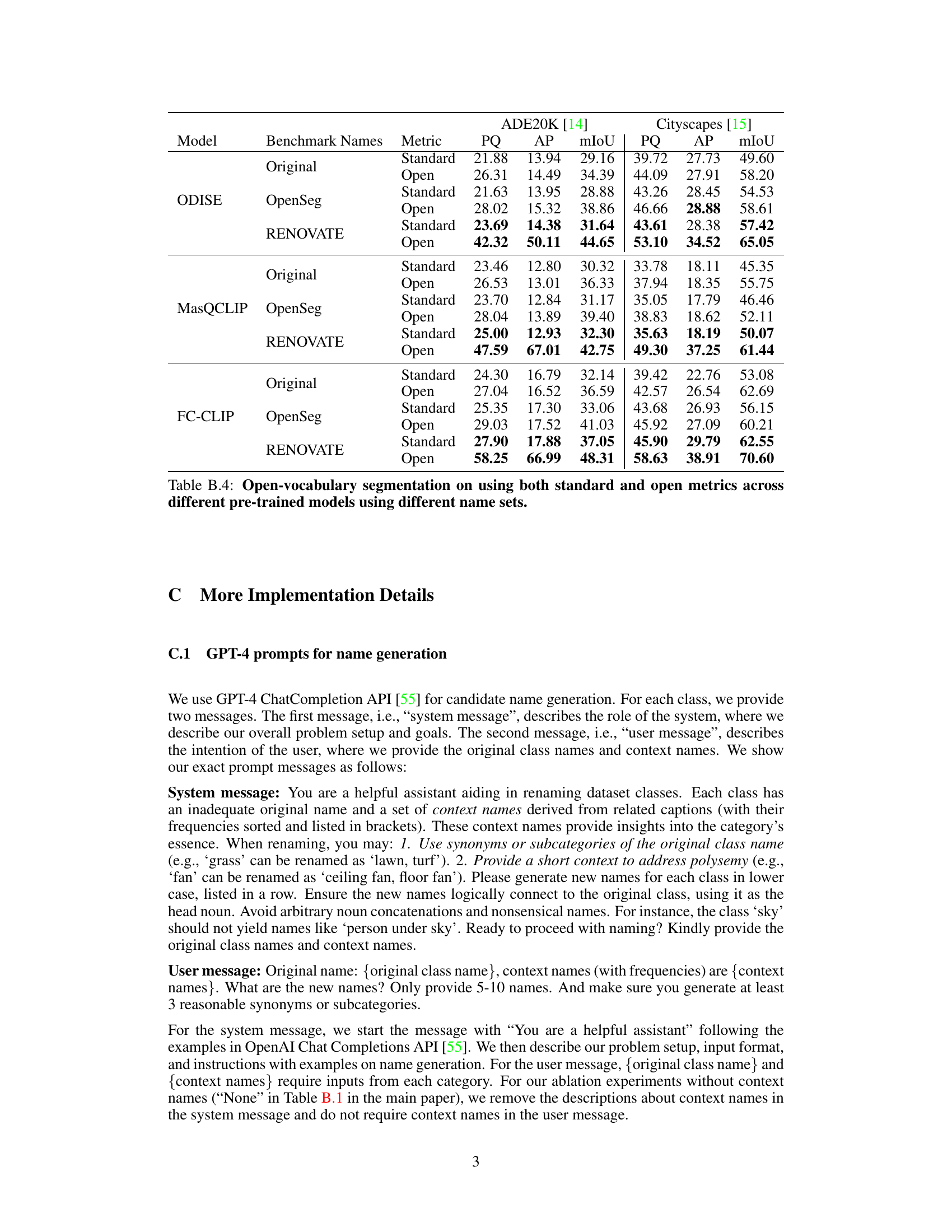
🔼 This table presents a comparison of statistics for three popular panoptic segmentation datasets (COCO, ADE20K, and Cityscapes) before and after applying the RENOVATE name renovation process. The ‘Original classes’ column shows the number of unique classes in each dataset as originally defined. The ‘Segments/Class’ column indicates the average number of image segments per class. The lower half of the table shows the corresponding statistics after the renovation process: ‘RENOVATE names’ is the number of distinct names generated by RENOVATE, and ‘Segments/Name’ is the average number of segments per new name. The comparison highlights that RENOVATE increases the number of distinct names significantly, creating a finer-grained categorization of segments within each dataset.
read the caption
Table 2: Statistics of renovated datasets.
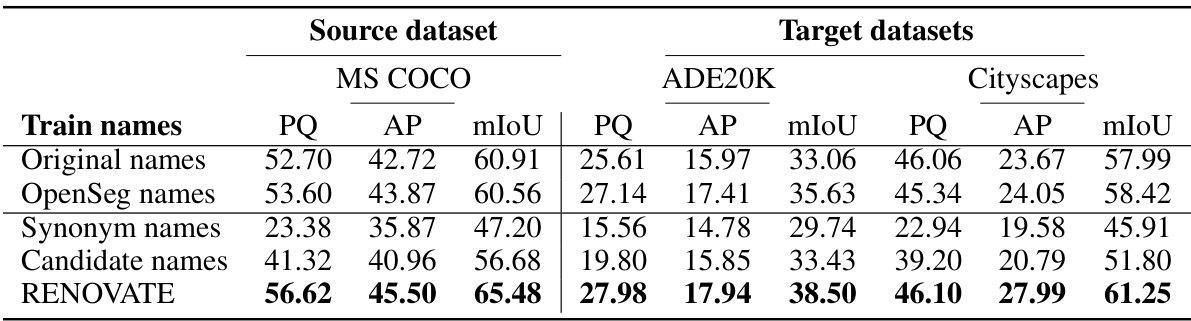
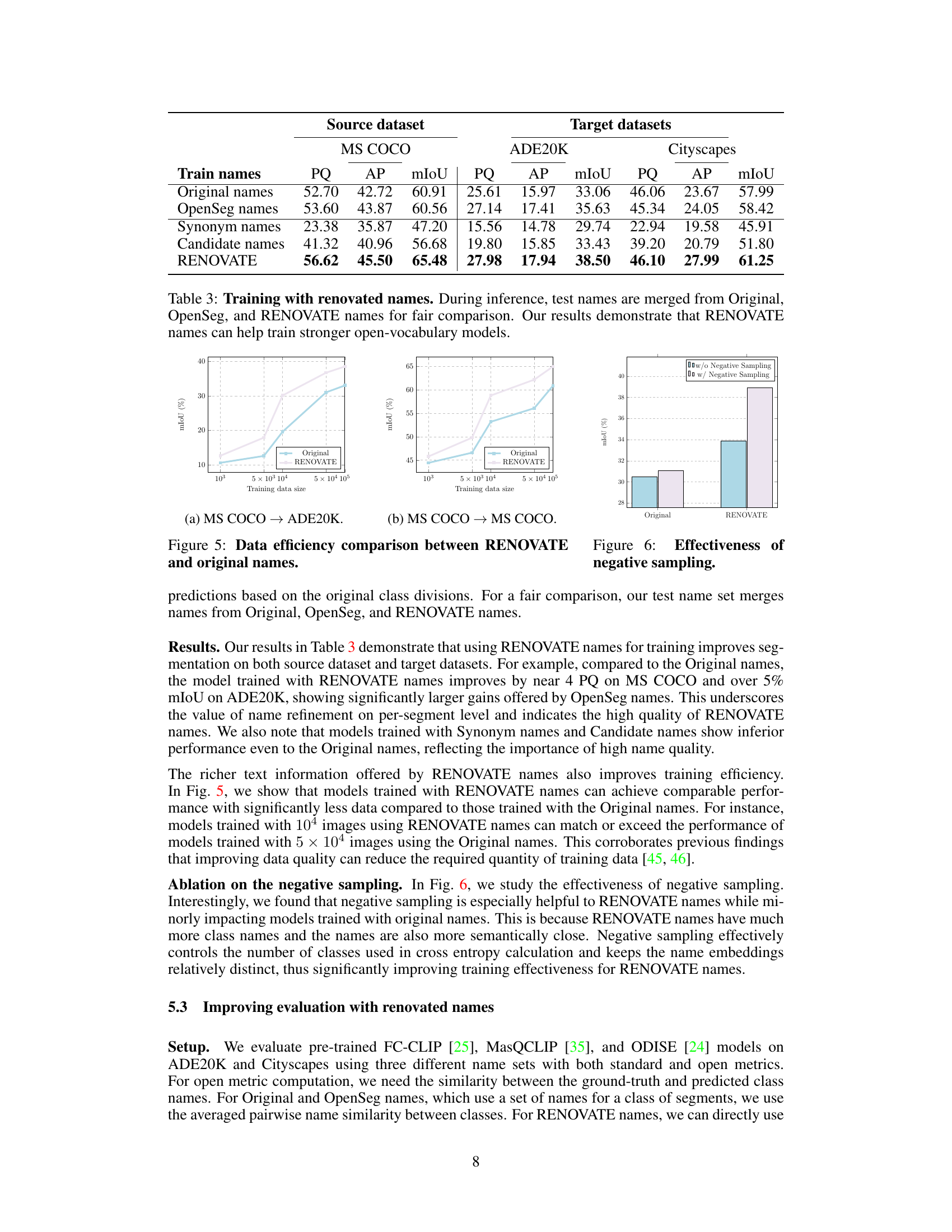
🔼 This table presents the results of training open-vocabulary segmentation models on the MS COCO dataset using different sets of names: original names, OpenSeg names, synonym names, candidate names, and RENOVATE names. The table shows that using RENOVATE names leads to significant improvements in model performance, as measured by PQ, AP, and mIoU metrics. During inference, to ensure a fair comparison, the test names were a combination of all name types. The results highlight the effectiveness of using high-quality, contextually relevant names for training.
read the caption
Table 3: Training with renovated names. During inference, test names are merged from Original, OpenSeg, and RENOVATE names for fair comparison. Our results demonstrate that RENOVATE names can help train stronger open-vocabulary models.

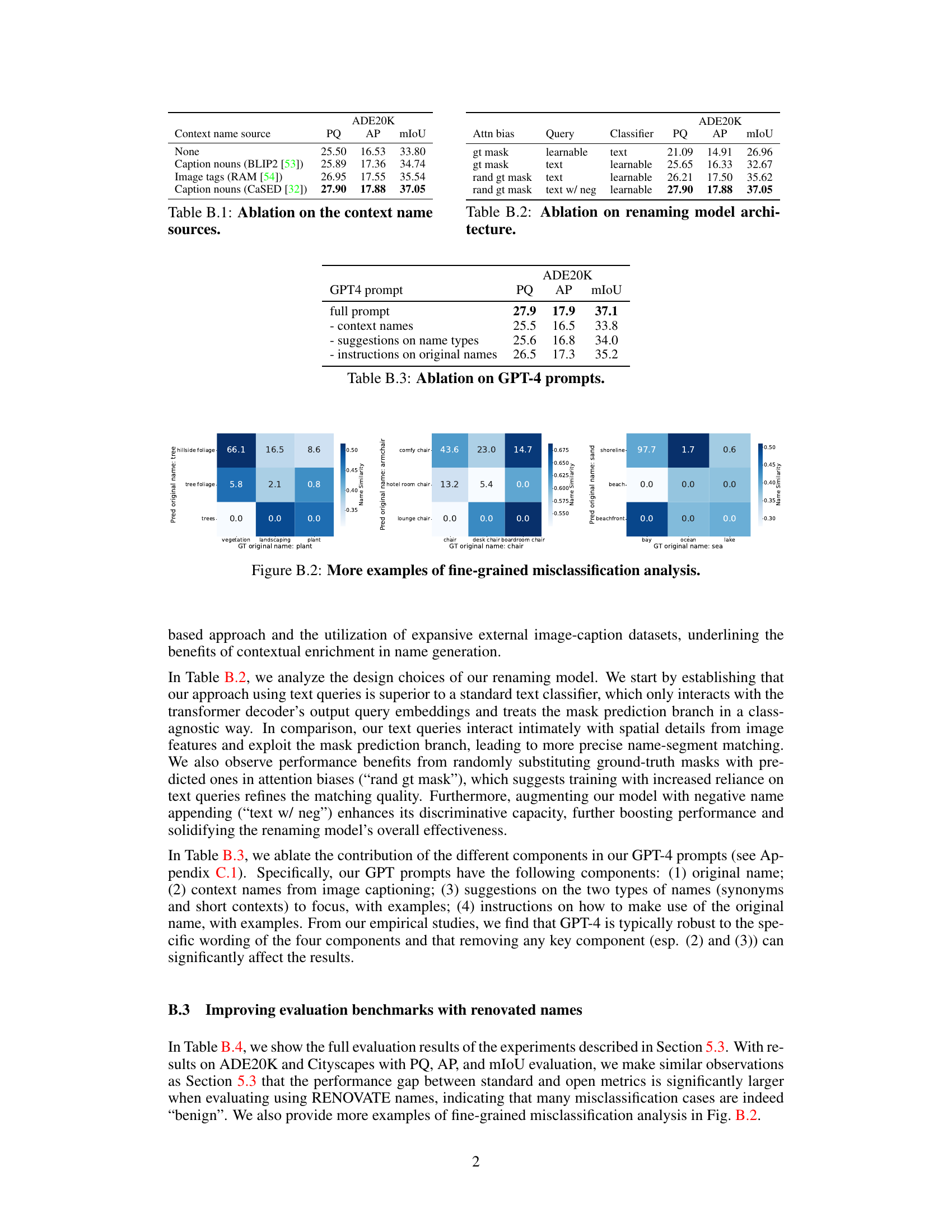
🔼 This table presents the results of ablation studies conducted on the context name sources used in the candidate name generation phase. The experiment compares different methods for generating context names: no context names, captions from BLIP2, image tags from RAM, and captions from CaSED. The table shows that using captions from CaSED resulted in the highest PQ, AP, and mIoU scores, indicating that the quality of context names significantly impacts the performance of the candidate name generation.
read the caption
Table B.1: Ablation on the context name sources.

🔼 This table presents the ablation study results on different GPT-4 prompts used for generating candidate names. It shows the impact of various components of the prompt, such as using context names, suggestions on name types, and instructions on original names, on the performance metrics (PQ, AP, mIoU) on the ADE20K dataset. The results indicate the importance of each component for generating high-quality candidate names.
read the caption
Table B.3: Ablation on GPT-4 prompts.

🔼 This table presents the results of training open-vocabulary segmentation models on the MS COCO dataset using different sets of names: Original, OpenSeg, Synonym, Candidate, and RENOVATE. The performance is evaluated using PQ, AP, and mIoU metrics on the MS COCO, ADE20K, and Cityscapes datasets. It highlights the improved performance achieved by using RENOVATE names, demonstrating their effectiveness in training stronger models.
read the caption
Table 3: Training with renovated names. During inference, test names are merged from Original, OpenSeg, and RENOVATE names for fair comparison. Our results demonstrate that RENOVATE names can help train stronger open-vocabulary models.

🔼 This table presents the results of training open-vocabulary segmentation models using different sets of names: original names, OpenSeg names, synonym names, candidate names, and RENOVATE names. The models were evaluated using standard metrics (PQ, AP, mIoU) on MS COCO, ADE20K, and Cityscapes datasets. The table shows that using RENOVATE names for training leads to significant performance improvements compared to the other name sets. During testing, names from all sets were used for fair comparison.
read the caption
Table 3: Training with renovated names. During inference, test names are merged from Original, OpenSeg, and RENOVATE names for fair comparison. Our results demonstrate that RENOVATE names can help train stronger open-vocabulary models.
Full paper#