TL;DR#
Multi-modal fusion, integrating information from different sources like text, images, and audio, is crucial for many AI applications, but current methods struggle to efficiently capture the complex dynamics of interactions between various modalities. State Space Models (SSMs) like Mamba show promise in improving this process by modeling sequential data effectively but they still have limitations.
The researchers introduce Coupled Mamba, a novel SSM-based approach. It enhances multi-modal fusion by efficiently coupling state chains of multiple modalities. The model uses an inter-modal hidden state transition scheme and a global convolution kernel for parallel computing, leading to faster inference and lower memory usage. Experiments demonstrate that Coupled Mamba significantly outperforms existing methods across various datasets, showcasing improved accuracy and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves multi-modal fusion, especially for sequential data. Coupled Mamba’s enhanced efficiency and accuracy addresses a key limitation of existing state space models (SSMs) while demonstrating superior performance on multiple benchmark datasets, paving the way for improved applications in various fields such as sentiment analysis and video understanding. Its innovative approach to parallel computing and global convolution kernel design offers exciting possibilities for researchers working with SSMs and multi-modal data.
Visual Insights#
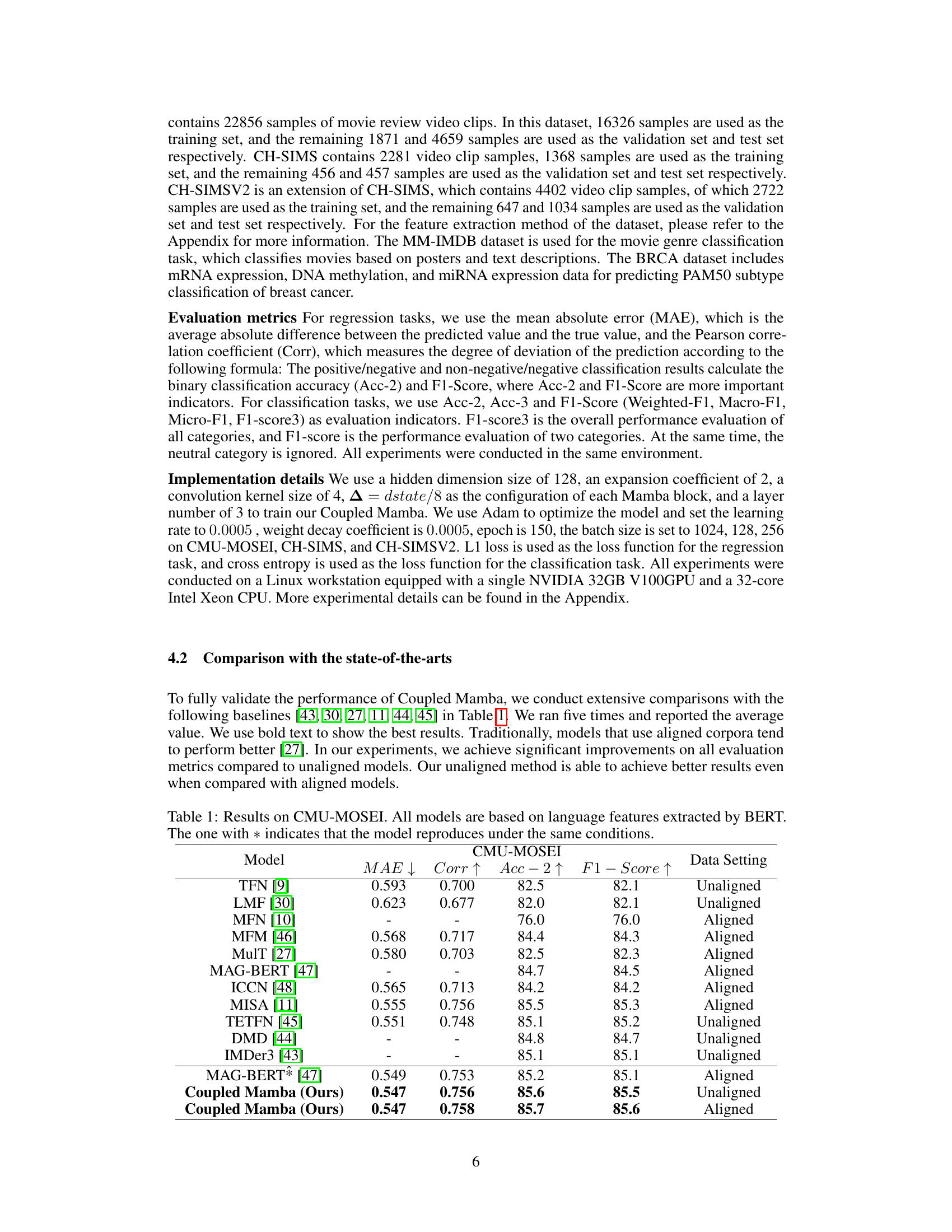
🔼 The figure illustrates the architecture of the Coupled Mamba model, which is a multi-modal fusion model based on state space models. It shows N layers, each comprising M Coupled Mamba blocks (one for each modality). Each block receives the sequence data of multiple modalities as input, aggregates the states, and transitions to the next time step’s state for each modality. Pooling layers are used to adapt the output for downstream tasks. The model integrates multiple modalities via a state transition scheme dependent on previous time steps’ states from its own chain and neighboring chains.
read the caption
Figure 1: Architecture of Coupled Mamba.

🔼 This table presents the results of the CMU-MOSEI experiment, comparing the performance of the proposed Coupled Mamba model against several state-of-the-art models. The models are evaluated using four metrics: Mean Absolute Error (MAE), Pearson Correlation (Corr), Accuracy (Acc-2), and F1-Score. The data settings for each model indicate whether the data was aligned or unaligned. The table highlights that Coupled Mamba achieves comparable or better results than existing models, even with unaligned data.
read the caption
Table 1: Results on CMU-MOSEI. All models are based on language features extracted by BERT. The one with * indicates that the model reproduces under the same conditions.
In-depth insights#
Coupled Mamba Model#
The Coupled Mamba model presents a novel approach to enhance multi-modal fusion by integrating the strengths of State Space Models (SSMs) and the Mamba model. It addresses the limitation of traditional methods in capturing complex interactions between modalities, particularly in scenarios with intricate intra- and inter-modality correlations. The core innovation lies in its coupled state transition scheme, where the current state of each modality depends on both its own previous state and the states of neighboring modalities. This design enables a richer representation of the dynamic interactions between different data types. Furthermore, the model incorporates a carefully designed expedite coupled state transition scheme and a global convolution kernel, which are crucial for maintaining the hardware-aware parallelism essential for efficient multi-modal fusion. Experimental results across various datasets demonstrate significant improvements in accuracy and efficiency compared to state-of-the-art methods, showcasing the efficacy of the Coupled Mamba model’s unique architecture for advanced multi-modal processing. The model’s design successfully balances capturing complex relationships between modalities and computational efficiency.
Multimodal Fusion#
Multimodal fusion, the integration of information from multiple sources (e.g., text, images, audio), is a critical area in artificial intelligence. The paper highlights the limitations of traditional neural methods in capturing complex interactions between modalities, especially when dealing with intricate correlations. State Space Models (SSMs) are presented as a promising alternative because their inherent state evolution process facilitates a more robust and powerful fusion paradigm. However, the paper notes a key challenge for SSMs is their adaptation for multi-modal scenarios while maintaining efficient hardware-aware parallelism. The proposed Coupled SSM addresses this by introducing an inter-modal state transition mechanism that carefully balances independent intra-modality processing with effective cross-modality interaction. This approach, combined with a novel global convolution kernel for parallelization, is shown to improve performance and resource efficiency. The results demonstrate substantial gains in F1-score and inference speed, highlighting the potential of SSM-based fusion techniques for complex multimodal tasks.
Parallel SSMs#
Parallel State Space Models (SSMs) represent a significant advancement in sequence modeling, offering enhanced efficiency compared to traditional recurrent neural networks. Their inherent parallelism stems from the ability to pre-compute intermediate results through iterative processes, unlike RNNs that rely on sequential computations. This parallel nature is particularly crucial for handling long sequences and high-dimensional data, which are common in multi-modal applications. Hardware acceleration is often readily achievable in parallel SSMs due to their structure, leading to faster training and inference times, especially beneficial for real-time applications. However, designing parallel SSMs for multi-modal fusion requires careful consideration to maintain independence of intra-modality processes while efficiently combining information across modalities. The challenge lies in striking a balance between leveraging parallelism for efficiency and ensuring effective information exchange between different modalities. Effective solutions typically involve carefully crafted schemes for aggregating and transmitting information between state chains representing individual modalities.
Experimental Results#
The “Experimental Results” section of a research paper is crucial for demonstrating the validity and impact of the proposed methods. A strong presentation will not only report key metrics (accuracy, F1-score, precision, recall) but also provide insightful analysis. This might involve comparing performance against established baselines, showcasing improvements across various datasets or experimental settings, and thoroughly discussing any unexpected outcomes. Visualizations like graphs and tables are essential for clear communication. Statistical significance testing should be employed to determine whether observed performance gains are genuine or merely due to chance. Beyond just numbers, a compelling analysis will explore the reasons behind the results, connecting the findings back to the theoretical underpinnings of the work. Finally, a good “Experimental Results” section addresses any limitations encountered during experimentation and proposes directions for future research based on the observed results.
Future Directions#
Future research could explore several promising avenues. Extending Coupled Mamba to handle even more modalities (e.g., incorporating physiological signals) would enhance its applicability to complex real-world scenarios. Investigating more sophisticated state coupling mechanisms could improve the model’s ability to capture intricate inter-modal dependencies. A deeper investigation into the optimal architecture and hyperparameter settings for various multi-modal tasks is warranted. The impact of different input representations on Coupled Mamba’s performance should be systematically assessed. Finally, exploring applications in new domains beyond the ones studied in the paper (e.g., medical image analysis, robotics) could uncover valuable insights and demonstrate its broader usefulness.
More visual insights#
More on figures

🔼 This figure illustrates the Coupled Mamba model’s architecture. It shows how the model receives multi-modal inputs (Xt-1) at time step t-1. These inputs are processed through three key matrices (B, C, S) representing input, output, and state transition respectively. Notably, the hidden states (h) from all modalities are summed before being used to generate the next time step’s hidden states (ht). This process continues sequentially over time.
read the caption
Figure 2: Coupling Mamba receives input Xt−1, and performs internal state switching and output through three key parameter matrices, where B, C and S are respectively represented as the input matrix, output matrix and state transfer matrix. The hidden states are summed across modalities and used for state transition input to generate next time states. The state is propagated sequentially in time.
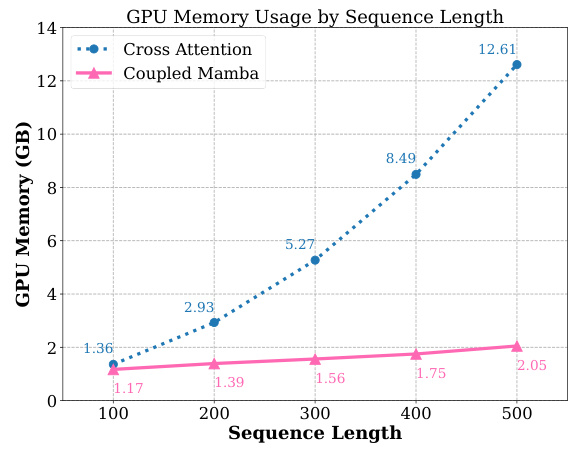
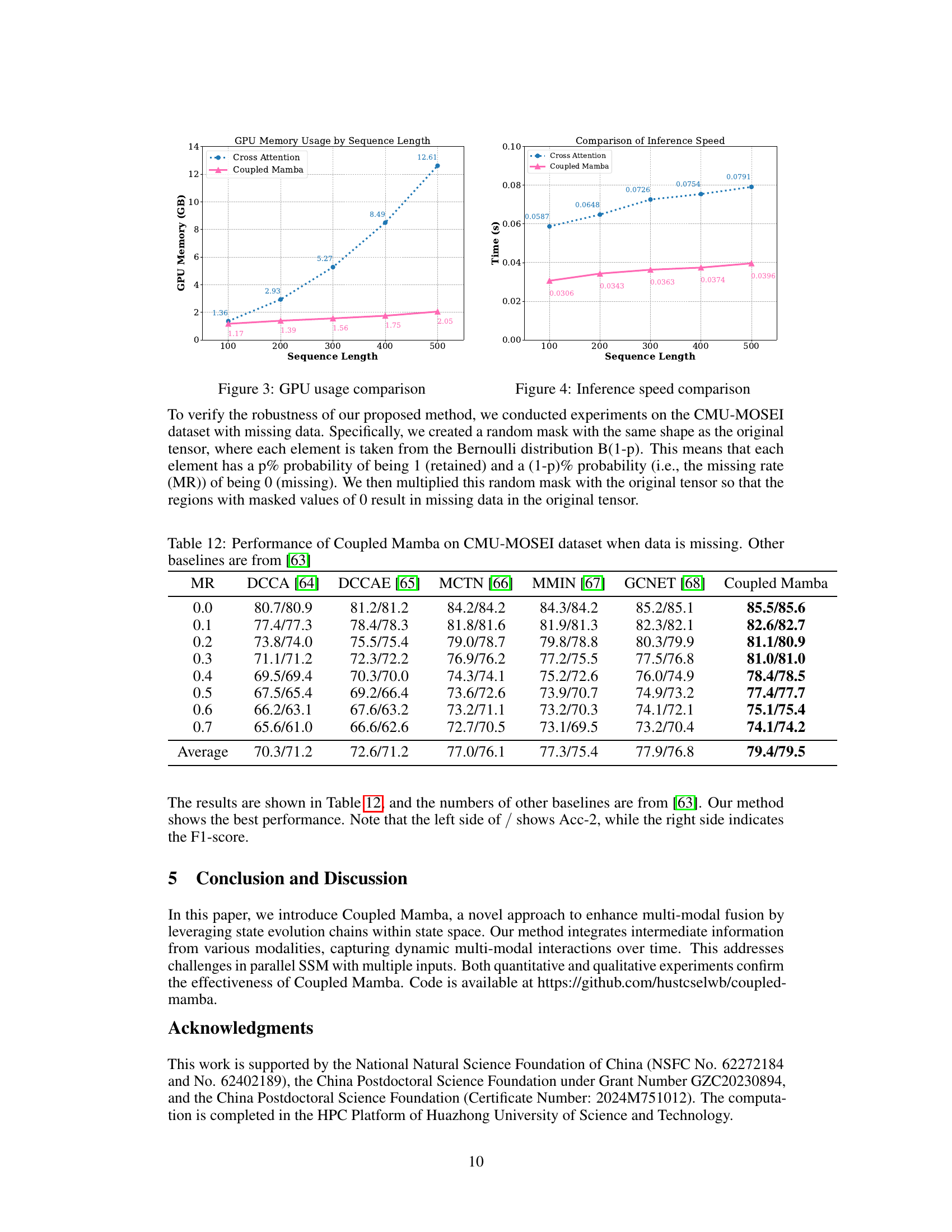
🔼 This figure compares the GPU memory usage of Coupled Mamba and Cross Attention methods with varying sequence lengths. It shows that Coupled Mamba uses significantly less GPU memory than Cross Attention, especially as the sequence length increases. The Y-axis represents GPU memory usage in GB, while the X-axis shows the sequence length. The graph visually demonstrates the memory efficiency advantage of Coupled Mamba.
read the caption
Figure 3: GPU usage comparison
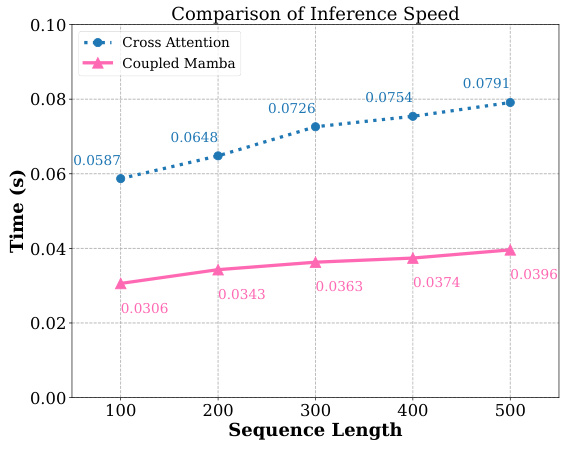
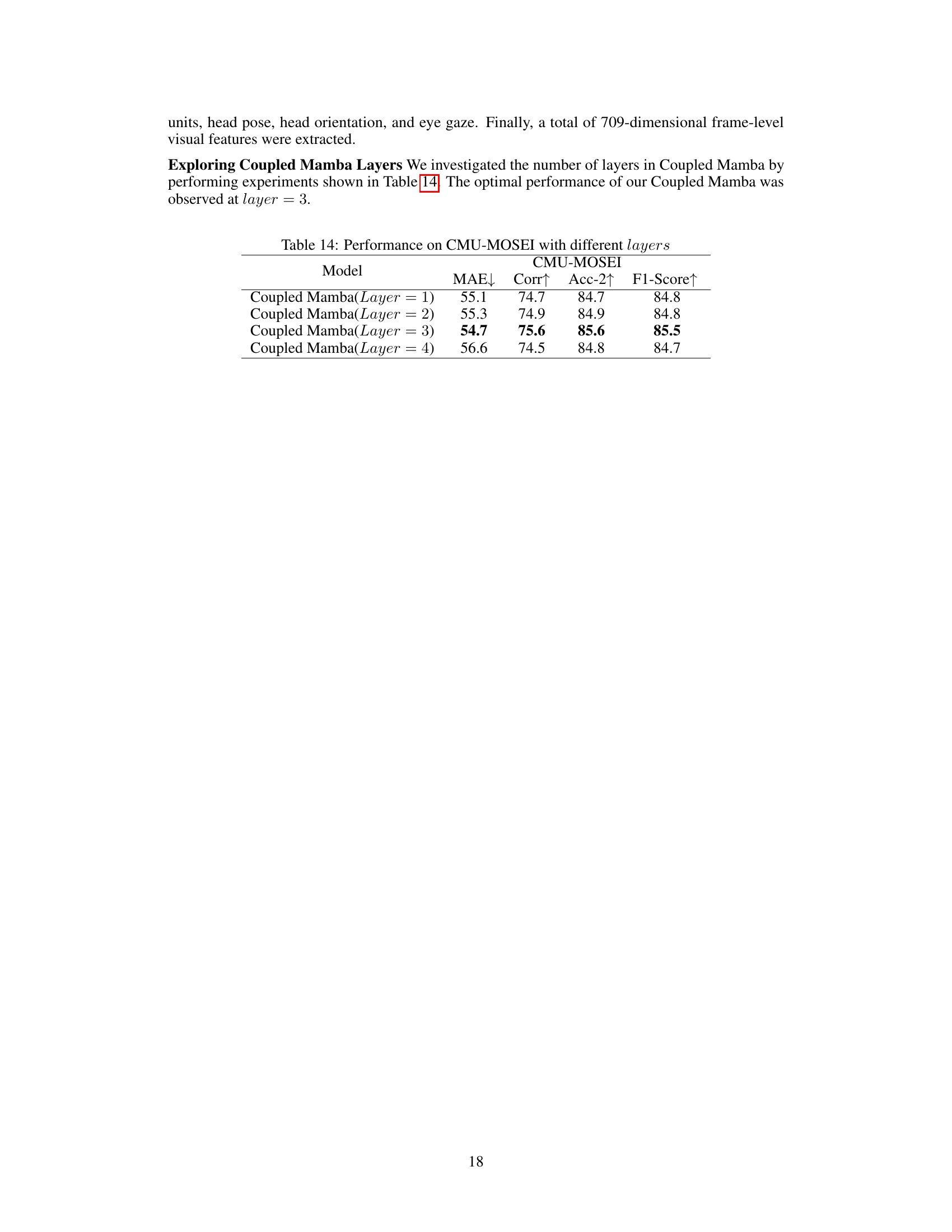
🔼 This figure compares the inference speed of Coupled Mamba and Cross Attention models across varying sequence lengths. The results demonstrate that Coupled Mamba consistently shows faster inference times than Cross Attention, and the difference in speed becomes more pronounced as the sequence length increases.
read the caption
Figure 4: Inference speed comparison
More on tables

🔼 This table presents the results of the CH-SIMS experiment, focusing on the performance comparison of different models on a Chinese dataset. The models’ performances are evaluated using accuracy metrics (Acc-2, Acc-3, Acc-5) and F1-score, all based on language features extracted using BERT. The data used is unaligned, meaning that the modalities are not synchronized.
read the caption
Table 2: Results on CH-SIMS (Chinese). All models are based on language features extracted by BERT, and the results are compared on unaligned data. Acc-N represents N-level accuracy.
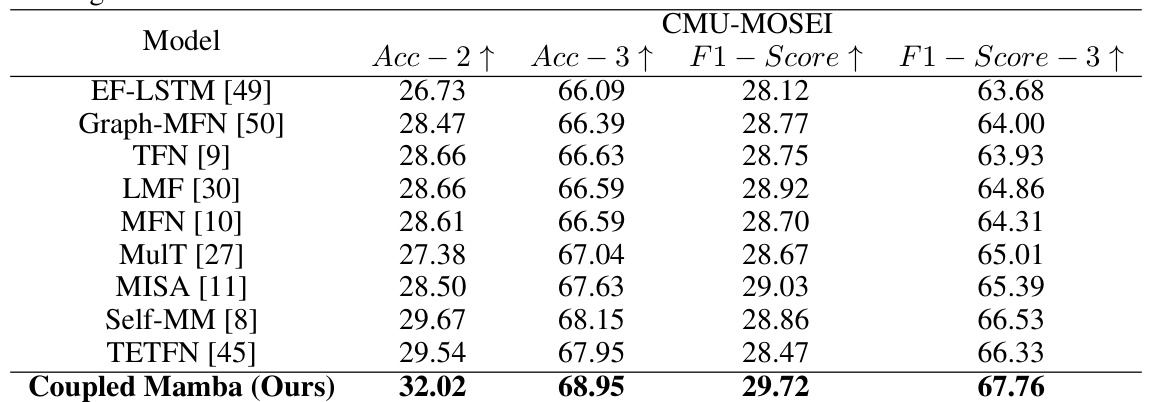
🔼 This table presents the classification results on the CMU-MOSEI dataset for various models, all using BERT-extracted language features and unaligned data. The results, averaged over five runs, show the accuracy (Acc-2, Acc-3), and F1-score (F1-Score, F1-Score-3) achieved by each model, highlighting the performance of the proposed Coupled Mamba model in comparison to state-of-the-art baselines.
read the caption
Table 3: Results of classification tasks on CMU-MOSEI. All models are based on language features extracted by BERT, and the results are performed on unaligned data. We ran it five times and report the average results.
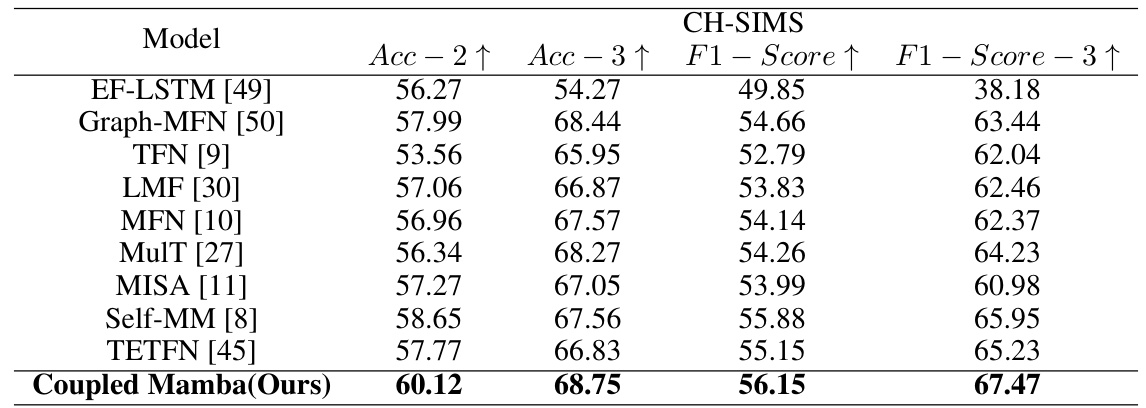
🔼 This table presents the results of a classification task performed on the CH-SIMS dataset. The models are evaluated based on language features extracted using BERT, and all experiments use unaligned data. The results reported are averages across five runs. The table compares the performance of Coupled Mamba against several other state-of-the-art models using standard classification metrics (Acc-2, Acc-3, F1-Score, F1-Score-3).
read the caption
Table 4: Classification task results on CH-SIMS. All models are based on language features extracted by BERT and the results are performed on unaligned data. We ran it five times and report the average results.
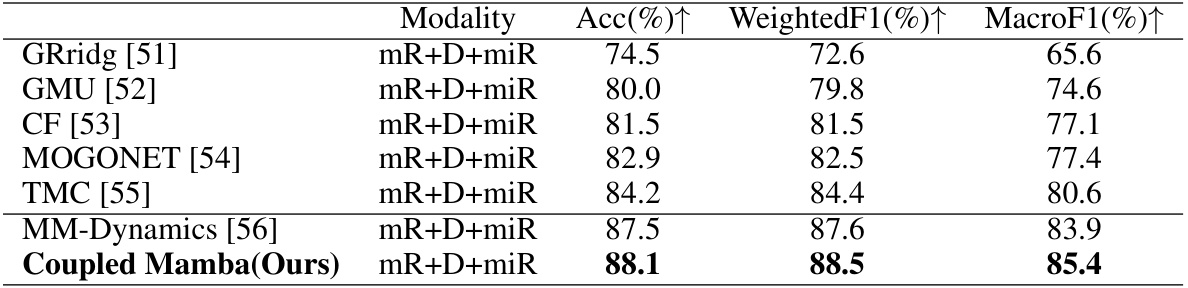
🔼 This table presents the results of the BRCA benchmark, which involves predicting PAM50 subtypes of breast cancer using multi-omics data (mRNA expression, DNA methylation, and miRNA expression). The table compares the performance of several methods (GRridg, GMU, CF, MOGONET, TMC, MM-Dynamics) against the proposed Coupled Mamba model. The performance is measured using Accuracy (Acc), Weighted F1-score, and Macro F1-score. Coupled Mamba achieves the best performance across all three metrics.
read the caption
Table 5: Result on the BRCA benchmark: mR, D, and miR denote mRNA expression, DNA methylation, and miRNA expression data respectively. The best results are in bold.
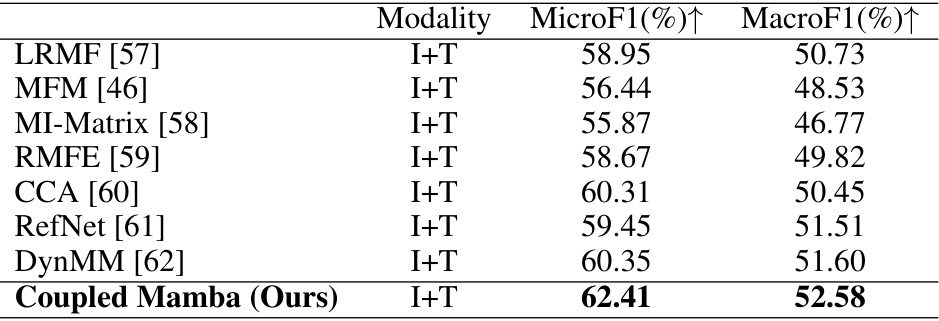
🔼 This table presents the performance comparison of different multi-modal fusion methods on the MM-IMDB benchmark dataset. The methods are evaluated based on MicroF1 and MacroF1 scores, which are common metrics for evaluating classification performance. The table shows that the proposed Coupled Mamba model outperforms other state-of-the-art methods.
read the caption
Table 6: Result on the MM-IMDB benchmark. I and T denote image and text respectively. The best results are in bold.
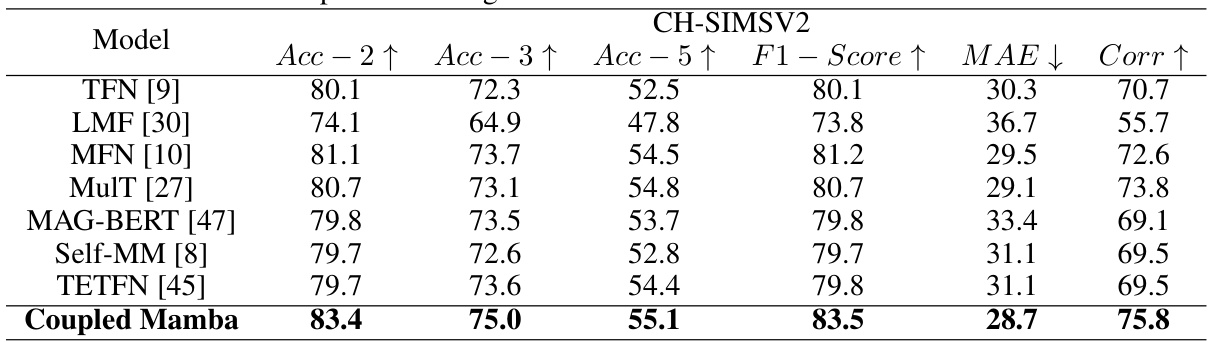
🔼 This table presents the results of the experiments conducted on the CH-SIMSV2 dataset using unaligned data. The model, Coupled Mamba, is compared against several state-of-the-art methods. The performance metrics used include Accuracy at different levels (Acc-2, Acc-3, Acc-5), F1-score, Mean Absolute Error (MAE), and Pearson Correlation (Corr). The results are averaged across five runs to enhance reliability. This table shows that Coupled Mamba outperforms other methods in most metrics.
read the caption
Table 7: Results on CH-SIMSV2, consistent across all experimental settings, using unaligned data. We run it five times and report the average results.

🔼 This table presents the results of the CMU-MOSEI experiment comparing the performance of the proposed Coupled Mamba model against other state-of-the-art models. The evaluation metrics include Mean Absolute Error (MAE), Pearson Correlation Coefficient (Corr), Accuracy (Acc-2), and F1-Score. The data setting indicates whether the model used aligned or unaligned data. The table shows that Coupled Mamba outperforms other models, especially in the unaligned data setting.
read the caption
Table 1: Results on CMU-MOSEI. All models are based on language features extracted by BERT. The one with * indicates that the model reproduces under the same conditions.

🔼 This table presents the performance of the Coupled Mamba model on the CMU-MOSEI dataset using different values for the timescale parameter Δ. The results show how varying Δ (dstate/16, dstate/8, dstate/4) impacts the model’s performance, as measured by Correlation (Corr↑), Accuracy (Acc-2↑), and F1-Score (F1-Score↑). The best performance is achieved with Δ = dstate/8.
read the caption
Table 9: Performance on CMU-MOSEI with different timescale Δ
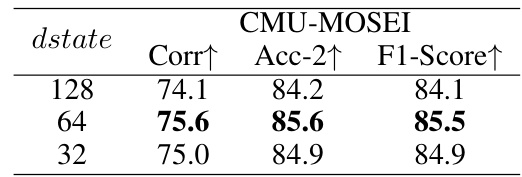
🔼 This table presents the performance of the Coupled Mamba model on the CMU-MOSEI dataset when varying the
dstatehyperparameter.dstateinfluences the dimensionality of the hidden state space within the model. The table shows the correlation (Corr↑), accuracy (Acc-2↑), and F1-score (F1-Score↑) for three differentdstatevalues (128, 64, and 32). The results highlight the impact of this hyperparameter on model performance, indicating an optimal value fordstatethat yields the best results on this specific dataset and task.read the caption
Table 10: Performance on CMU-MOSEI with different dstate

🔼 This table compares the performance of four different multimodal fusion methods on the CMU-MOSEI dataset. The methods are Average Fusion, Concat Fusion, Mamba Fusion, and the proposed Coupled Fusion. The results show the Mean Absolute Error (MAE), Pearson Correlation Coefficient (Corr), Accuracy (Acc-2), and F1-Score for each method. Coupled Fusion achieves the best performance across all metrics.
read the caption
Table 11: Comparison of fusion methods

🔼 This table presents the performance of the Coupled Mamba model and several baseline models on the CMU-MOSEI dataset under varying levels of missing data (Missing Rate or MR). The results are shown for different missing rates (0.0 to 0.7), reporting both Accuracy (Acc-2) and F1-score for each model. The Coupled Mamba consistently demonstrates superior performance across all missing data rates compared to the baselines.
read the caption
Table 12: Performance of Coupled Mamba on CMU-MOSEI dataset when data is missing. Other baselines are from [63]

🔼 This table presents the results of classification experiments conducted on the CMU-MOSI dataset. It compares the performance of the proposed Coupled Mamba model against several other state-of-the-art methods. The metrics used for comparison include Acc-2 (binary classification accuracy), Acc-3 (3-level accuracy), F1-Score (overall F1-score), and F1-Score-3 (F1-score considering three levels). The results are averages over five runs, performed under identical experimental conditions, ensuring a fair comparison.
read the caption
Table 13: Results on the CMU-MOSI dataset for classification task, all results are performed under the same conditions, and the average results are reported after five runs.

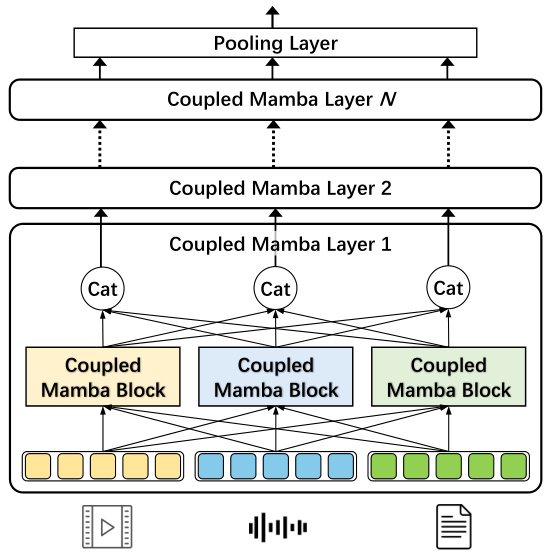
🔼 This table presents the results of experiments conducted on the CMU-MOSEI dataset to determine the optimal number of layers for the Coupled Mamba model. The table shows that using 3 layers yields the best performance, as measured by MAE, Correlation, Accuracy, and F1-Score.
read the caption
Table 14: Performance on CMU-MOSEI with different layers
Full paper#