TL;DR#
Current large language models (LLMs), despite safety measures, remain vulnerable to various attacks. Existing methods for identifying these vulnerabilities often lack a principled approach, resulting in suboptimal attack success rates and low-quality outputs. This paper addresses these limitations by introducing a Safety Concept Activation Vector (SCAV) framework.
The SCAV framework guides attacks by accurately interpreting LLMs’ safety mechanisms. The researchers developed an SCAV-guided attack method capable of generating both attack prompts and embedding-level attacks with automatically selected hyperparameters. Their experiments demonstrated that this method significantly improves attack success rates and response quality, requiring less training data. Furthermore, the generated attacks demonstrated transferability across different LLMs, including black-box models like GPT-4, revealing widespread safety concerns.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) safety because it unveils severe vulnerabilities in current LLMs, even seemingly well-aligned ones. It introduces a novel framework, SCAV, for effectively guiding attacks, leading to improved attack success rate and quality. This research opens new avenues for developing robust defense mechanisms against malicious uses of LLMs and contributes significantly to ongoing efforts to ensure LLM safety.
Visual Insights#
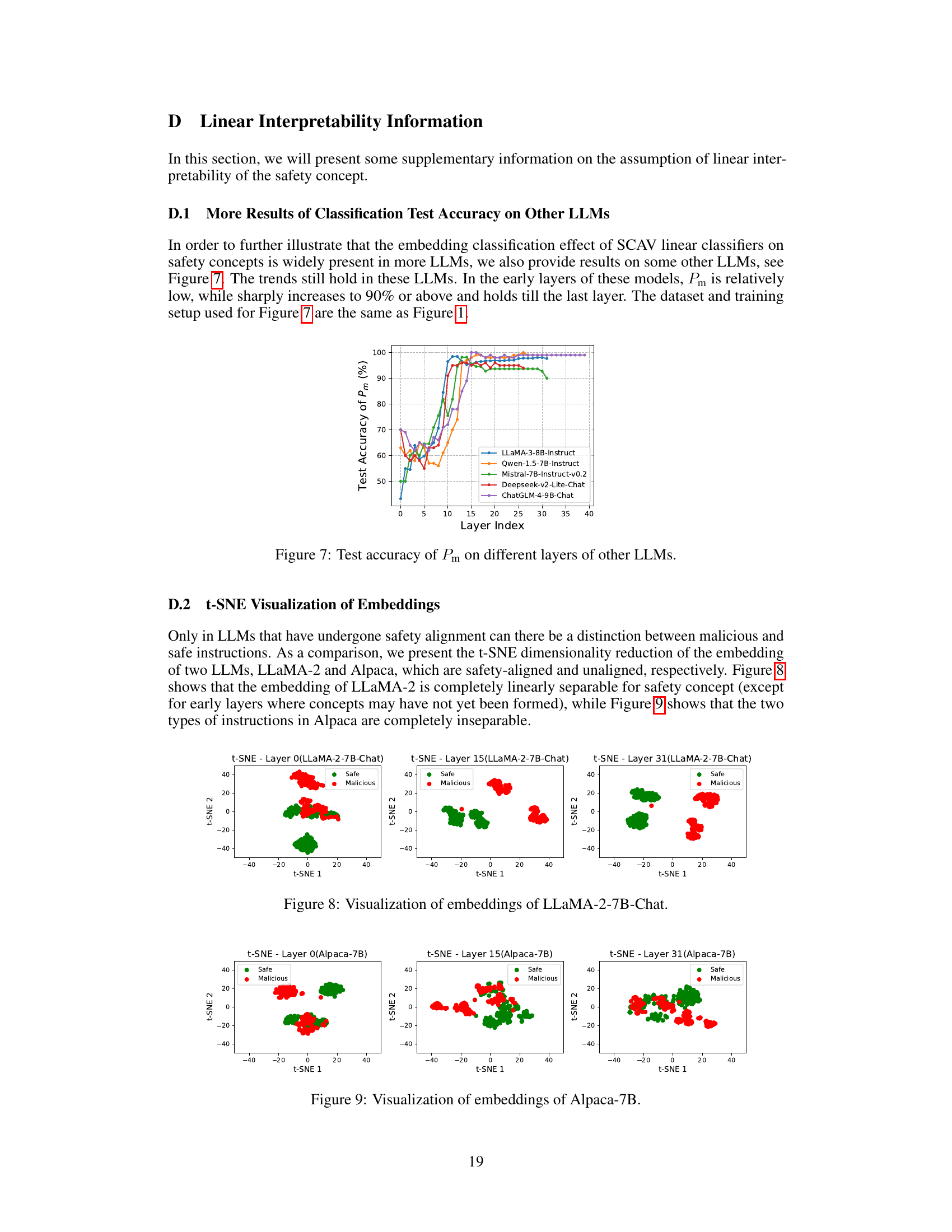
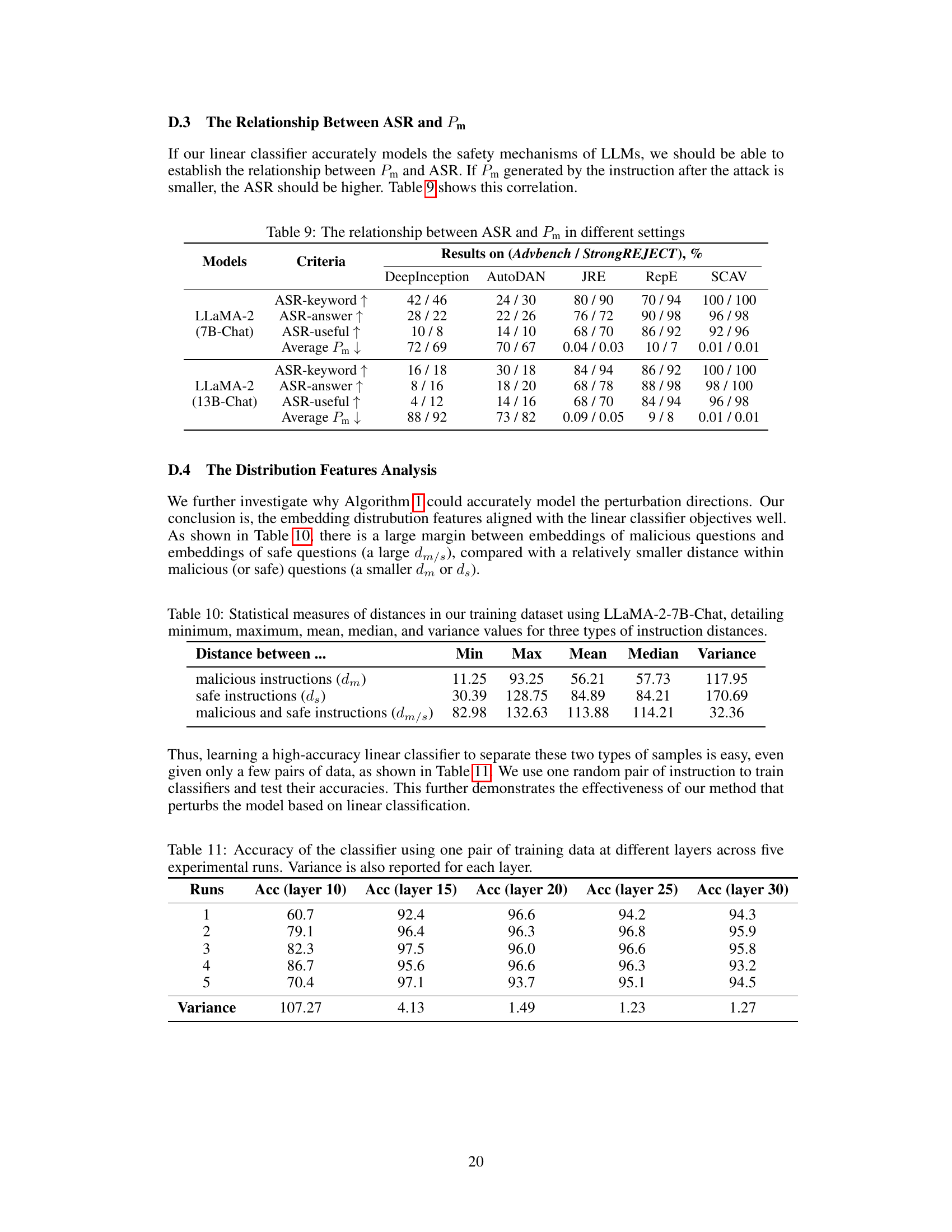
🔼 This figure shows the test accuracy of the safety concept activation vector (SCAV) classifier, Pm, on different layers of four LLMs: Vicuna-v1.5-7B, Llama-2-7B-chat-hf, Llama-2-13B-chat-hf, and Alpaca-7B (unaligned). The x-axis represents the layer index, and the y-axis represents the test accuracy of Pm (%). The figure demonstrates that for well-aligned LLMs (Vicuna and Llama-2), the test accuracy increases significantly from the 10th or 11th layer onwards, reaching over 98% at the final layers. This indicates that a linear classifier can accurately interpret the safety mechanism and that these LLMs begin to model safety from these middle layers. In contrast, the unaligned LLM (Alpaca) shows a much lower test accuracy, indicating a lack of explicit safety modeling.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.
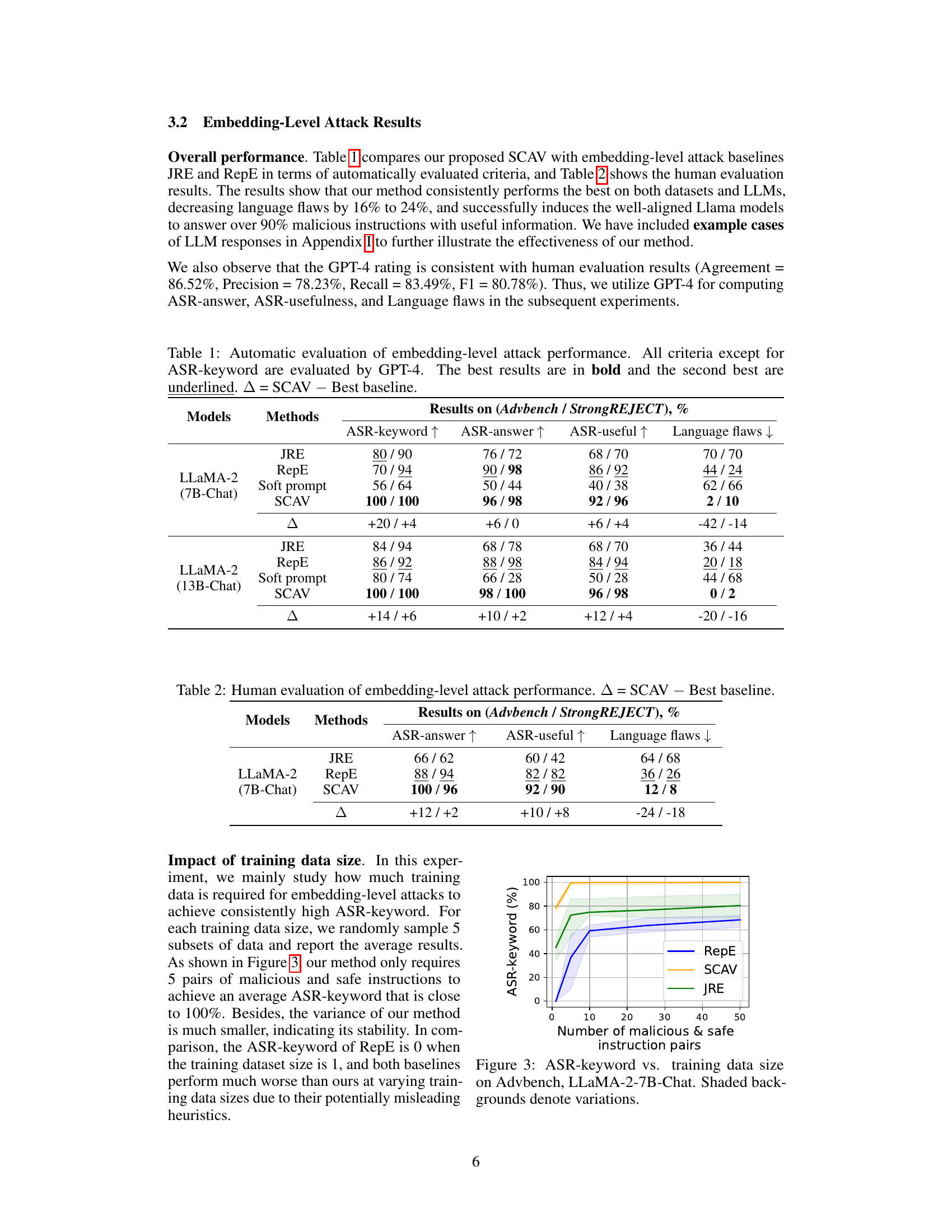
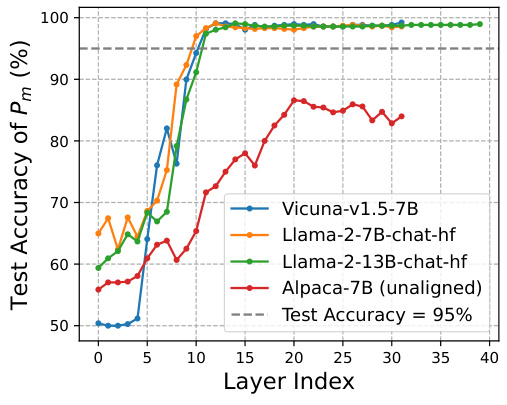
🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three different methods (JRE, RepE, and SCAV). The evaluation metrics include ASR-keyword (attack success rate based on keyword matching), ASR-answer (attack success rate based on whether the LLM provides a relevant answer), ASR-useful (attack success rate based on whether the LLM provides a useful response), and Language flaws (the number of language flaws in the LLM’s response). The table shows that SCAV consistently outperforms the baselines across all metrics, achieving significantly higher attack success rates and better response quality. The ∆ column shows the improvement of SCAV over the best-performing baseline for each metric.
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. ∆ = SCAV - Best baseline.
In-depth insights#
SCAV Framework#
The SCAV (Safety Concept Activation Vector) framework is a crucial contribution, providing a principled way to interpret LLMs’ safety mechanisms. It moves beyond heuristic-based approaches by quantifying the probability of an LLM classifying an embedding as malicious. This is achieved through a linear classifier trained to distinguish between malicious and safe embeddings, leveraging the concept activation vector technique. The framework’s strength lies in its ability to accurately guide attacks by identifying vulnerable points within the LLM’s safety architecture. This principled approach is particularly valuable in comparison to existing methods, enabling more efficient hyperparameter selection and improved attack success rates and response quality. By objectively assessing safety, SCAV facilitates a deeper understanding of LLM vulnerabilities and promotes the development of more robust safety mechanisms.
Attack Methods#
The effectiveness of various attack methods against large language models (LLMs) is a crucial area of research. Prompt-level attacks, focusing on crafting malicious inputs, have demonstrated success in bypassing safety mechanisms. However, these methods often require significant manual engineering or extensive training data. Embedding-level attacks, which directly manipulate internal LLM representations, offer a potentially more powerful approach. These attacks leverage insights into the LLM’s internal structure, enabling targeted manipulation with reduced reliance on prompt engineering. While effective, embedding-level attacks usually require access to model parameters, limiting their applicability in black-box scenarios. The ideal approach would combine the strengths of both, potentially using prompt-level attacks to identify vulnerabilities and then employing embedding-level techniques for refined, more effective manipulation. Future research should concentrate on developing more transferable and efficient attack methods, reducing reliance on specific LLMs or extensive training data, and exploring defenses against these attacks.
LLM Safety Risks#
Large language model (LLM) safety is a critical concern, encompassing various risks. Malicious use is a primary threat, with LLMs potentially exploited for generating harmful content, including hate speech, misinformation, and instructions for illegal activities. Adversarial attacks can circumvent safety mechanisms, leading to unintended outputs even in well-aligned models. Data poisoning poses another risk, where malicious data injected during training can corrupt the model’s behavior and introduce biases. Bias amplification is inherent to LLMs trained on large datasets that might reflect societal biases. Addressing LLM safety requires a multi-pronged approach including robust safety mechanisms, rigorous testing against various attacks, and ongoing monitoring for bias and unintended behavior. Explainability and interpretability are key factors in identifying and mitigating risks. Further research into these areas is crucial to ensuring the responsible development and deployment of LLMs.
Attack Transferability#
Attack transferability in large language models (LLMs) is a crucial area of research, focusing on whether attacks developed for one model can be successfully applied to others. This has significant implications for LLM safety and security, as a successful transferable attack compromises multiple models, negating the effort of securing each individually. The degree of transferability depends on various factors, including the similarity of model architectures, training data, and safety mechanisms. White-box attacks, leveraging internal model parameters, often exhibit higher transferability rates compared to black-box attacks which rely solely on input-output interactions. However, even black-box attacks can demonstrate surprising transferability, especially when targeting vulnerabilities in the safety alignment process rather than model-specific weaknesses. Research into attack transferability helps to identify common vulnerabilities across different LLMs, guiding the development of more robust and generalizable defense mechanisms. Ultimately, understanding and mitigating attack transferability is paramount to building trustworthy and reliable LLMs.
Future Research#
Future research directions stemming from this paper could explore improving the robustness of SCAV against adversarial defenses, such as those employing data augmentation or model retraining. Investigating the transferability of SCAV across different model architectures and sizes would be valuable, aiming to broaden its applicability beyond specific LLMs. A deeper exploration into the safety mechanisms underlying linear separability in LLM embeddings is crucial, potentially revealing vulnerabilities and opportunities for improved model alignment. Finally, the research should consider the ethical implications of SCAV’s use, including the potential for misuse and the need for safety guidelines to prevent malicious applications.
More visual insights#
More on figures
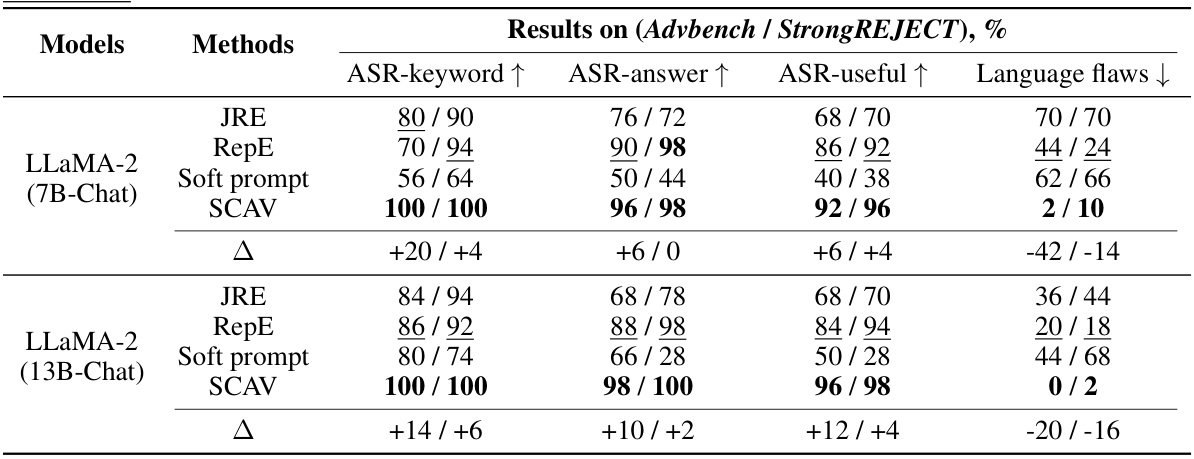
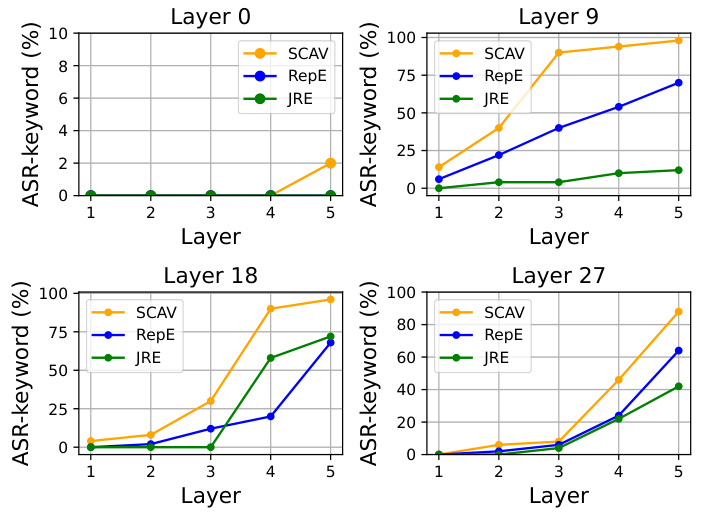
🔼 This figure compares the effectiveness of different methods in perturbing embeddings to evade safety mechanisms. SCAV consistently moves malicious instruction embeddings into the safe subspace, while RepE and JRE show inconsistent and sometimes opposite results, highlighting SCAV’s superior performance.
read the caption
Figure 2: Comparison of perturbations added by our method (SCAV) and the baselines RepE [16] and JRE [18]. Our method consistently moves embeddings of malicious instructions to the subspace of safe instructions, while the baselines may result in ineffective or even opposite perturbations.

🔼 This figure shows the impact of the training dataset size on the ASR-keyword metric for three different attack methods: SCAV, RepE, and JRE. The x-axis represents the number of malicious and safe instruction pairs used for training. The y-axis represents the ASR-keyword, indicating the success rate of the attack. The shaded areas around each line represent the variance in ASR-keyword across multiple runs with different subsets of the training data. The figure clearly demonstrates that the SCAV method requires significantly less training data to achieve high ASR-keyword, showcasing its efficiency and stability in comparison to the baseline methods RepE and JRE.
read the caption
Figure 3: ASR-keyword vs. training data size on Advbench, LLaMA-2-7B-Chat. Shaded backgrounds denote variations.

🔼 This figure demonstrates three key aspects of the safety mechanisms of LLMs. (a) shows the effect of attacking individual layers, revealing that attacks on linearly separable layers (where the safety concept is well-defined) consistently increase attack success rates. (b) shows that attacking multiple layers significantly improves attack success, suggesting a cumulative or interconnected safety mechanism across layers. Finally, (c) illustrates the transferability of attacks across different LLMs, meaning that attacks developed on one model can often succeed on others, highlighting potential vulnerabilities in model design and alignment.
read the caption
Figure 4: Unveiling the safety mechanisms of LLMs by (a) attacking a single layer; (b) attacking multiple layers, and (c) transferring embedding-level attacks to other white-box LLMs.
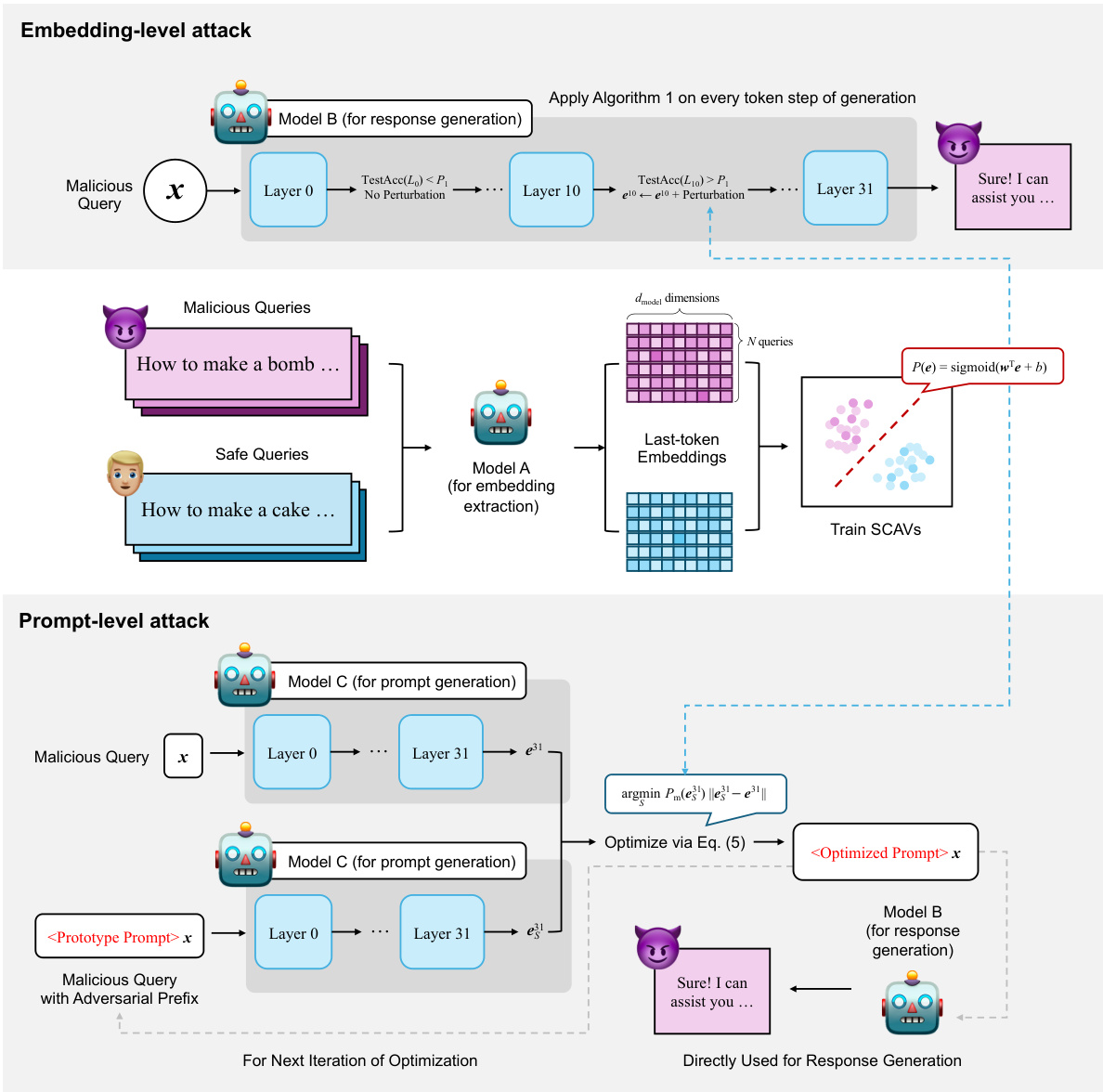
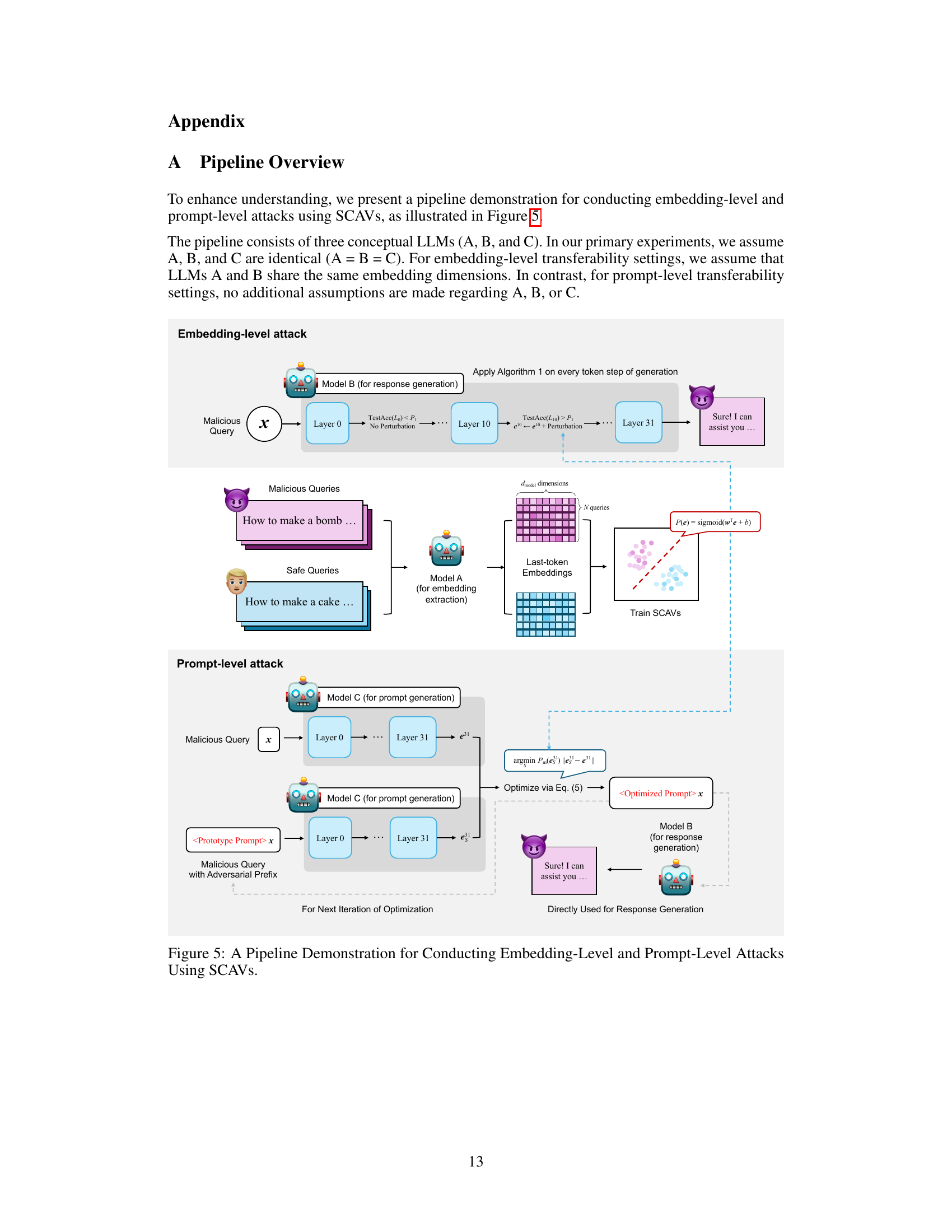
🔼 This figure illustrates the pipeline used for conducting both embedding-level and prompt-level attacks using the Safety Concept Activation Vector (SCAV) framework. It shows three conceptual LLMs (A, B, and C) representing different stages of the attack process. For embedding-level attacks, Model A extracts embeddings from a malicious query, while Model B generates a response. Algorithm 1 is applied to perturb the embeddings in between. For prompt-level attacks, Model C generates attack prompts that are combined with the original user input to manipulate the response generated by Model B.
read the caption
Figure 5: A Pipeline Demonstration for Conducting Embedding-Level and Prompt-Level Attacks Using SCAVs.

🔼 The figure shows the test accuracy of the safety concept activation vector (SCAV) classifier (Pm) on different layers of various LLMs. The x-axis represents the layer index, and the y-axis represents the test accuracy. The results indicate that for well-aligned LLMs (Vicuna and LLaMA-2), the test accuracy is high (above 95%) from the 10th or 11th layer onwards, suggesting that LLMs begin to model the safety concept from around these layers. In contrast, the test accuracy is significantly lower for the unaligned LLM (Alpaca). This demonstrates the linear interpretability assumption of the SCAV framework which helps to accurately interpret LLMs’ safety mechanisms.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.

🔼 This figure shows the test accuracy of the safety concept linear classifier (Pm) on different layers of various LLMs. The x-axis represents the layer index, and the y-axis represents the test accuracy. Multiple lines are shown, each representing a different LLM. The results indicate that for most LLMs, the accuracy of Pm is relatively low in the early layers, but increases sharply to over 90% and remains high until the final layers. This suggests that LLMs generally start to model the safety concept from intermediate layers.
read the caption
Figure 7: Test accuracy of Pm on different layers of other LLMs.
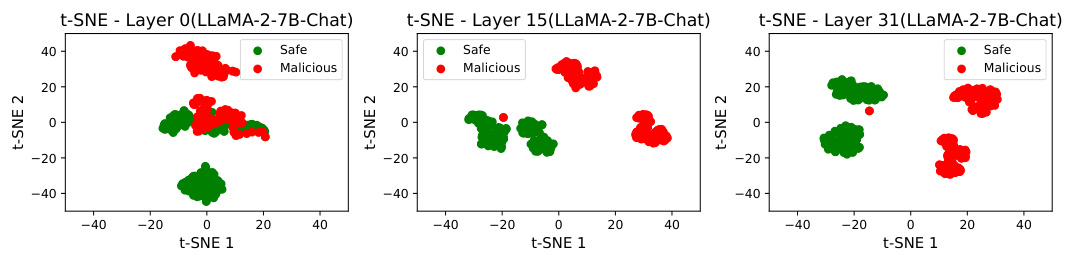
🔼 This figure visualizes the embeddings of LLaMA-2-7B-Chat using t-SNE for three different layers (0, 15, and 31). Each point represents an embedding, colored green for safe instructions and red for malicious instructions. The visualization aims to demonstrate the linear separability of malicious and safe instructions in the hidden space of the LLM. The increasing separation between the two classes as the layer index increases (from 0 to 31) suggests that the LLM’s safety mechanism is better developed in deeper layers.
read the caption
Figure 8: Visualization of embeddings of LLaMA-2-7B-Chat.
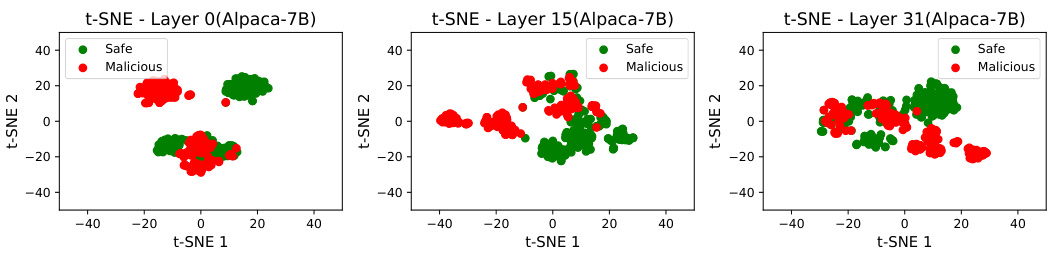
🔼 This figure shows the t-SNE visualization of embeddings from the Alpaca-7B model. It illustrates the distribution of embeddings for malicious and safe instructions at different layers (0, 15, and 31). Unlike Figure 8 (LLaMA-2-7B-Chat), which shows clear linear separability between malicious and safe instructions in later layers, Figure 9 demonstrates a lack of separation in Alpaca-7B, indicating a difference in how the models represent and handle the safety concept.
read the caption
Figure 9: Visualization of embeddings of Alpaca-7B.
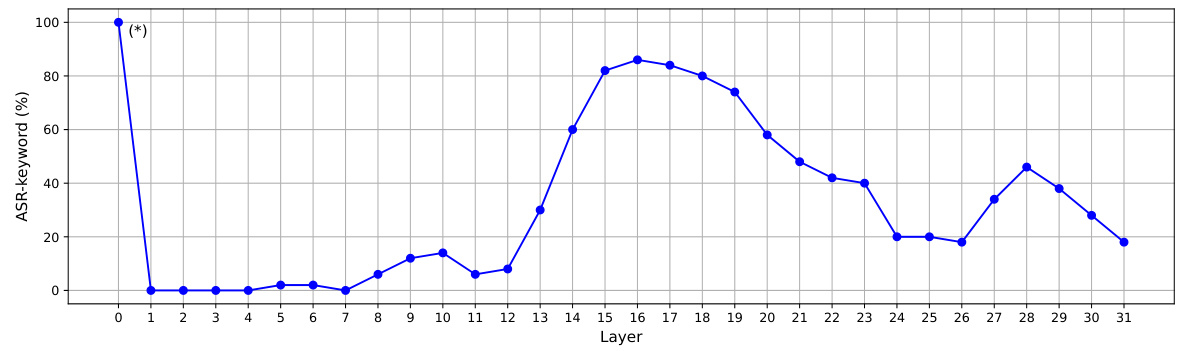
🔼 This figure shows the impact of selecting a single layer for perturbation in embedding-level attacks. It plots the attack success rate (ASR-keyword) against the layer index (0-31) of the LLaMA-2 7B-Chat language model. The dataset used is Advbench. Notably, perturbing layer 0 results in completely garbled outputs, leading to a misjudged ASR-keyword (indicated by the asterisk). Correctly, perturbing only layer 0 yields an ASR-keyword of 0%. The figure demonstrates that choosing a single layer for the attack is ineffective and that a multi-layer approach, as proposed by the authors, is necessary to achieve high attack success rates.
read the caption
Figure 10: How ASR-keyword changes with the choice of a layer according to our embedding-level attack algorithm. Victim LLM is LLaMA-2 (7B-Chat). The dataset is Advbench. (*) This is because perturbing layer 0 causes the output to be all garbled, thus ASR-keyword is all misjudged. After our manual inspection, the value here should be 0.

🔼 This figure shows the probability of each layer being selected for perturbation in the embedding-level attack. The x-axis represents the layer number (0-31), and the y-axis shows the probability. The algorithm shows a clear preference for perturbing layers between 13 and 23, indicating these layers are most effective in manipulating the LLM’s safety mechanisms. Layers outside of this range have much lower selection probabilities.
read the caption
Figure 11: How selection probability changes with the layer according to our embedding-level attack algorithm. Victim LLM is LLaMA-2 (7B-Chat). The dataset is Advbench.
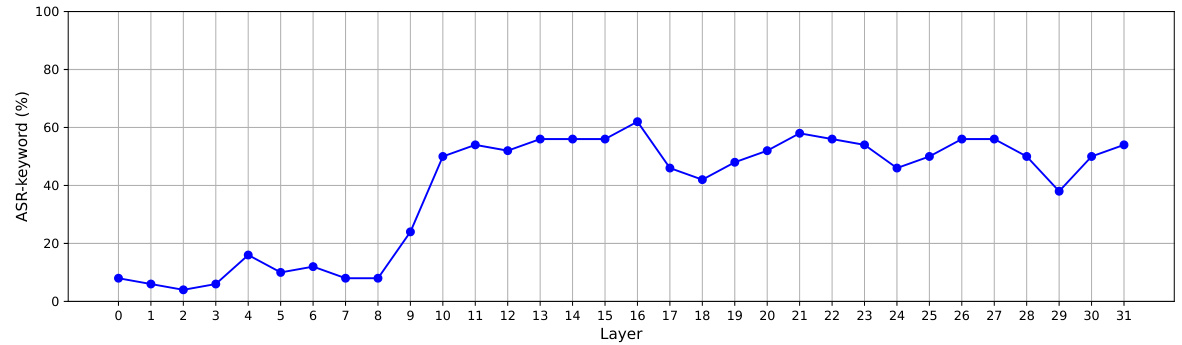
🔼 This figure shows the impact of selecting a single layer for perturbation in embedding-level attacks. It reveals that targeting a single layer (except layer 0 which resulted in garbled outputs) is insufficient for achieving high attack success rates (ASR-keyword). Perturbing multiple layers is necessary to significantly increase ASR.
read the caption
Figure 10: How ASR-keyword changes with the choice of a layer according to our embedding-level attack algorithm. Victim LLM is LLaMA-2 (7B-Chat). The dataset is Advbench. (*) This is because perturbing layer 0 causes the output to be all garbled, thus ASR-keyword is all misjudged. After our manual inspection, the value here should be 0.
🔼 The figure shows the test accuracy of the safety concept activation vector (SCAV) classifier Pm across different layers of various LLMs. The x-axis represents the layer index, and the y-axis represents the test accuracy. It demonstrates that for aligned LLMs (Vicuna and LLaMA-2), the test accuracy surpasses 95% starting from the 10th or 11th layer and increases to over 98% in the final layers. This suggests that these models start to model the safety concept from around the 10th or 11th layer. In contrast, the unaligned LLM (Alpaca) exhibits significantly lower test accuracy, highlighting the difference in safety mechanism modeling between aligned and unaligned models. The figure is used to verify the assumption of linear interpretability used in the SCAV framework.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.

🔼 This figure shows the relationship between the L2-norm of the perturbation and the ASR-keyword for three different attack methods: SCAV, RepE, and JRE. The x-axis represents the L2-norm of the perturbation, and the y-axis represents the ASR-keyword (attack success rate based on keyword matching). The plot shows that as the L2-norm increases, the ASR-keyword also increases for all three methods, but SCAV consistently outperforms RepE and JRE, achieving a higher ASR-keyword for the same perturbation magnitude. This demonstrates the effectiveness of SCAV’s method for generating perturbations that are more likely to lead to successful attacks.
read the caption
Figure 14: Results of ASR-keyword of three attack methods under different perturbation magnitude.

🔼 This figure shows the test accuracy of the safety concept activation vector (SCAV) classifier (Pm) on different layers of various LLMs. The x-axis represents the layer index, and the y-axis represents the test accuracy. The figure shows that for well-aligned LLMs (Vicuna and LLaMA-2), the test accuracy is high (above 95%) from the 10th or 11th layer onwards, indicating that the LLMs have successfully learned the safety concept. However, for the unaligned LLM (Alpaca), the test accuracy is much lower. This suggests that the linear interpretability assumption of SCAV holds well for aligned LLMs but not for unaligned LLMs.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.

🔼 The figure shows the test accuracy of the safety concept activation vector (SCAV) classifier Pm on different layers of various LLMs. It demonstrates the linear separability of malicious and safe instructions in the hidden space of aligned LLMs (Vicuna and LLaMA-2), with accuracy exceeding 95% from the 10th or 11th layer onwards. In contrast, the unaligned LLM (Alpaca) shows significantly lower accuracy, highlighting the difference in safety mechanisms between aligned and unaligned models. The x-axis represents the layer index, and the y-axis represents the test accuracy of the classifier.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.

🔼 This figure shows the test accuracy of the safety concept activation vector (SCAV) classifier (Pm) on different layers of various LLMs. It demonstrates that for well-aligned LLMs (Vicuna and LLaMA-2), the test accuracy is consistently high from layer 10 onwards, reaching over 98% at the final layers, which indicates strong linear separability between safe and malicious instructions in the hidden space. This supports the assumption of linear interpretability used in the SCAV framework. In contrast, the unaligned LLM (Alpaca) shows much lower accuracy, highlighting the difference in how safety concepts are captured and modeled between aligned and unaligned LLMs.
read the caption
Figure 1: Test accuracy of Pm on different layers of LLMs.
More on tables
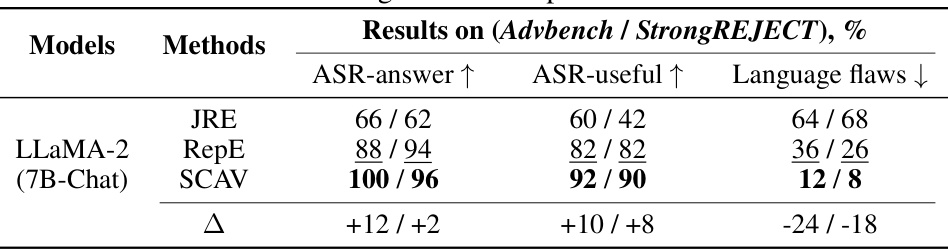
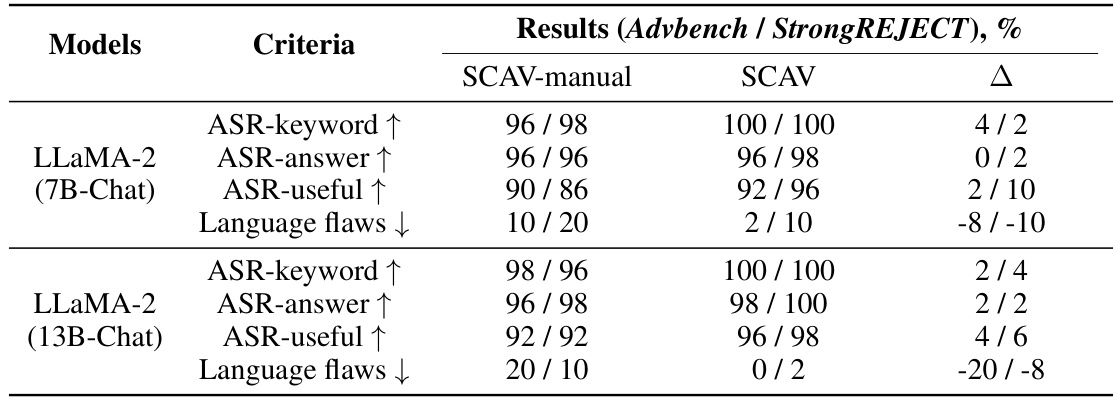
🔼 This table presents the results of a human evaluation comparing the performance of the proposed SCAV method against existing baselines (JRE and RepE) for embedding-level attacks. The evaluation is based on three criteria: ASR-answer (the percentage of times the LLM provided a relevant answer), ASR-useful (the percentage of times the response was useful), and Language flaws (the number of language errors). The results show that SCAV significantly outperforms the baselines across all three metrics, with a substantial increase in ASR-answer and ASR-useful and a substantial decrease in Language flaws. The delta (Δ) column shows the improvement achieved by SCAV over the best baseline for each metric.
read the caption
Table 2: Human evaluation of embedding-level attack performance. A = SCAV – Best baseline.
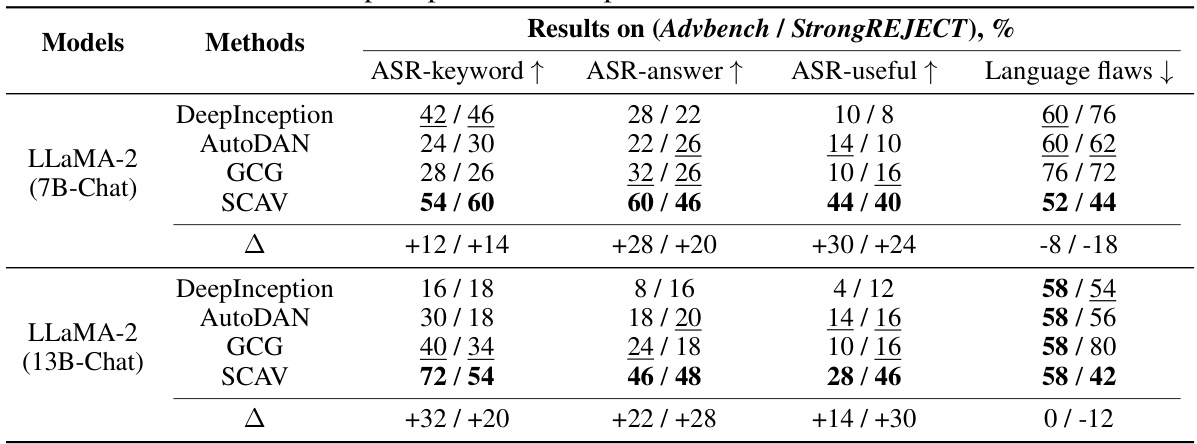
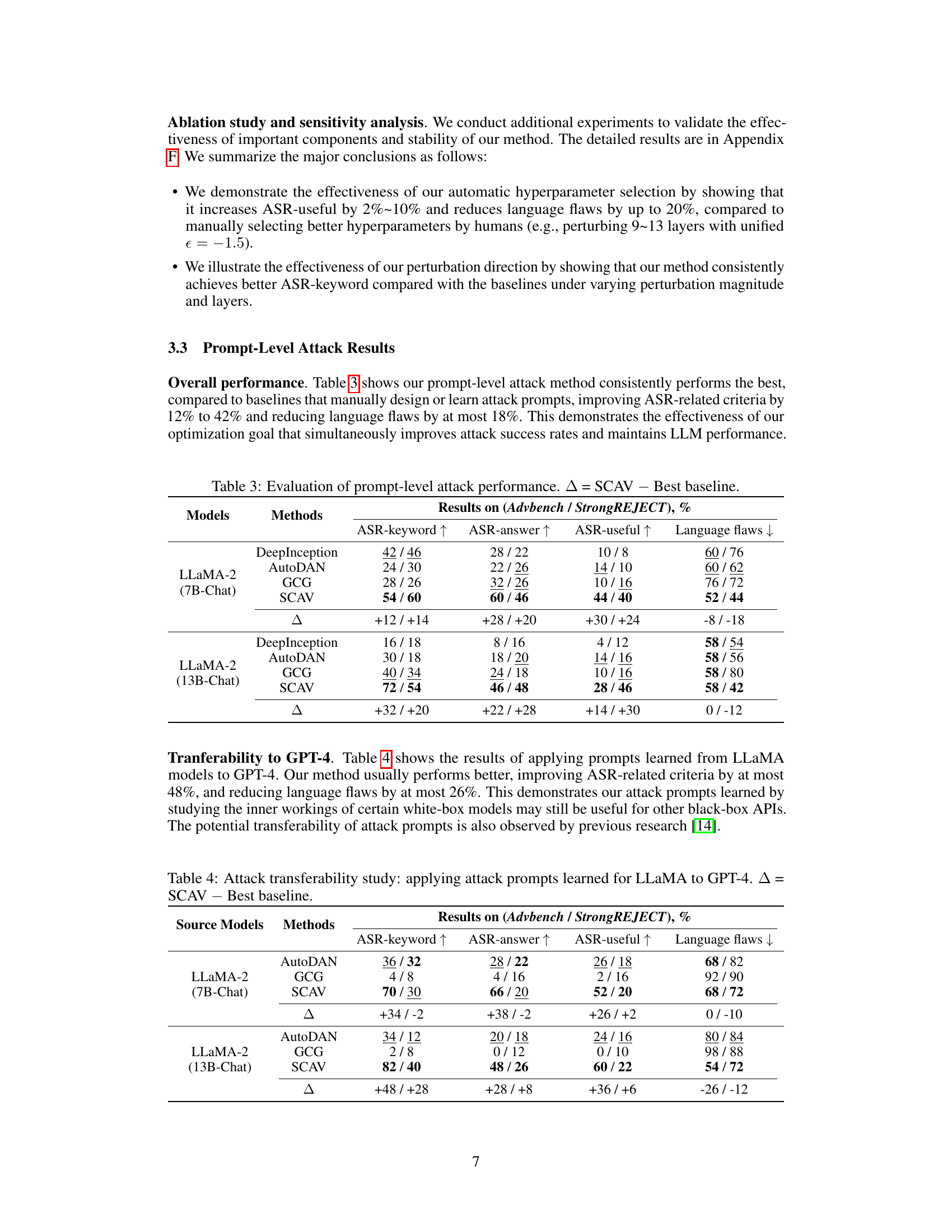
🔼 This table compares the performance of the proposed SCAV method with other baseline methods for prompt-level attacks. It shows the results on two datasets (Advbench and StrongREJECT) and evaluates four criteria: ASR-keyword, ASR-answer, ASR-useful, and Language flaws. The improvements shown by SCAV compared to the best baseline are quantified using the ‘Δ’ column. Higher values are generally better for the first three criteria and lower is better for the last criterion.
read the caption
Table 3: Evaluation of prompt-level attack performance. A = SCAV – Best baseline.
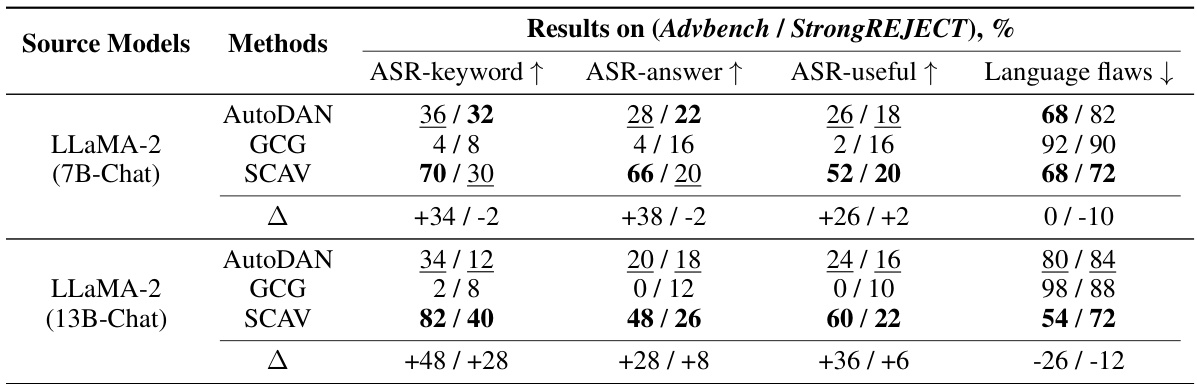
🔼 This table presents the results of applying prompts learned from LLaMA models to GPT-4. It demonstrates the transferability of attack prompts learned by studying the inner workings of certain white-box models, showing their potential usefulness for other black-box APIs. The table compares the performance of the SCAV method against baseline methods across four evaluation criteria: ASR-keyword, ASR-answer, ASR-useful, and Language flaws. The delta (∆) column shows the improvement of SCAV over the best baseline method for each metric.
read the caption
Table 4: Attack transferability study: applying attack prompts learned for LLaMA to GPT-4. ∆ = SCAV - Best baseline.
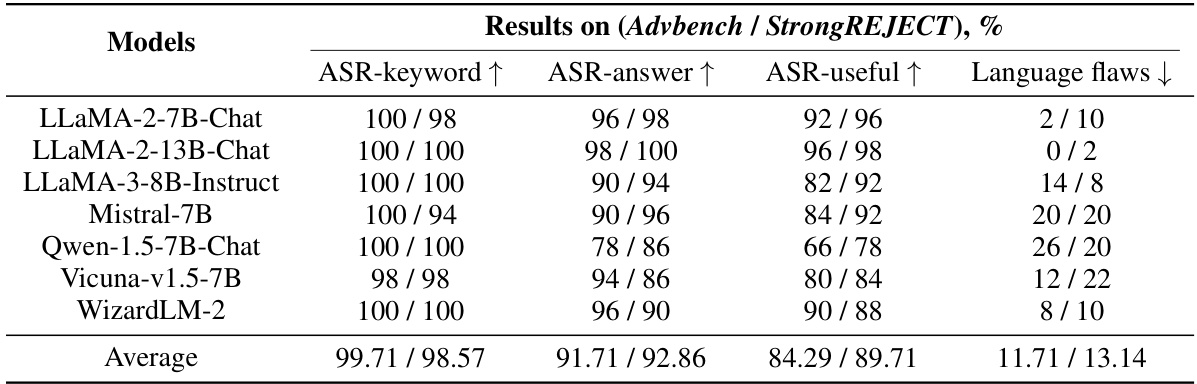
🔼 This table presents the results of attacking seven well-known open-source LLMs using the SCAV method. The table shows the attack success rate and response quality for each LLM on two datasets (Advbench and StrongREJECT). The results indicate that all LLMs provide relevant answers to a high percentage of malicious instructions, highlighting the severity of safety risks in current LLMs.
read the caption
Table 5: Attacking 7 well-known open-source LLMs by using SCAV. All LLMs provide relevant answers to more than 85% malicious instructions (ASR-answer), except for one on Advbench (ASR-answer is 78%).

🔼 This table presents the results of attacking GPT-4 using different combinations of prompt-level attack methods, including SCAV, AutoDAN, and DeepInception. The results show the attack success rates (ASR-keyword, ASR-answer, ASR-useful) and language quality (Language flaws) for different combinations of attacks. The ‘All’ row represents the best results obtained by combining all methods. The results show that even a cutting-edge model like GPT-4 is vulnerable to these attacks.
read the caption
Table 6: Attacking GPT-4 API by using different combinations of attack methods. When combining all prompt-level attack methods (All), GPT-4 returns useful responses to 84% (or 54%) malicious instructions on Advbench (or StrongREJECT), with a majority of them having no language flaws.

🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three different methods (JRE, RepE, and SCAV). The evaluation metrics include ASR-keyword, ASR-answer, ASR-useful, and Language flaws. Higher scores are better for ASR-keyword, ASR-answer, and ASR-useful, while lower scores are better for Language flaws. The table also shows the improvement achieved by SCAV compared to the best baseline.
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. A = SCAV - Best baseline.

🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three methods (JRE, RepE, and SCAV). The evaluation metrics include ASR-keyword (attack success rate based on keyword matching), ASR-answer (attack success rate based on whether the LLM provides a relevant answer), ASR-useful (attack success rate based on whether the response is useful), and Language flaws (the number of language flaws in the response). The SCAV method consistently outperforms the baselines across all metrics, indicating its effectiveness in generating high-quality and successful attacks. The table also shows the difference in performance (Δ) between SCAV and the best baseline for each metric, highlighting the significant improvement achieved by SCAV.
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. Δ = SCAV - Best baseline.

🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three methods (JRE, RepE, and SCAV). The evaluation metrics include ASR-keyword (attack success rate based on keyword matching), ASR-answer (attack success rate based on whether the LLM provides a relevant answer), ASR-useful (attack success rate considering the usefulness of the response), and Language flaws (a measure of the quality of the LLM’s response, such as repetition, inconsistency, and unspecific content). The table highlights the superiority of the SCAV method in achieving a higher attack success rate with better response quality and fewer language flaws compared to the baselines. The difference between SCAV and the best baseline is also calculated (Δ).
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. Δ = SCAV - Best baseline.
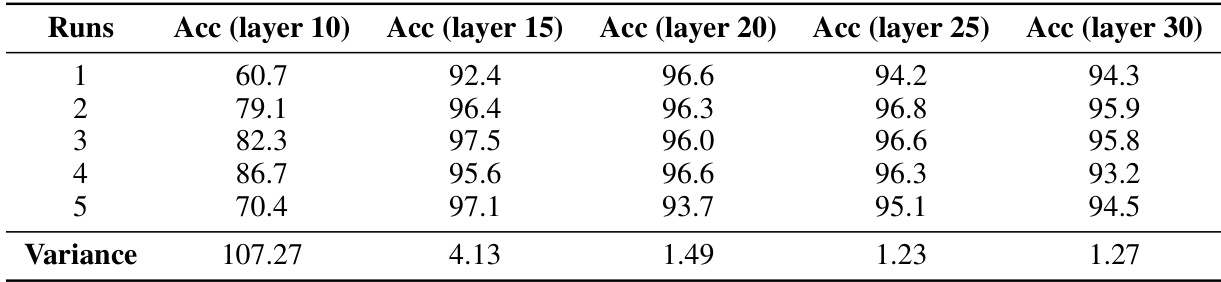
🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three different methods (JRE, RepE, and SCAV). The evaluation metrics include ASR-keyword (attack success rate based on keyword matching), ASR-answer (attack success rate based on whether the LLM provides a relevant answer), ASR-useful (attack success rate based on whether the LLM provides a useful answer), and Language flaws (the number of language flaws in the LLM response). The Δ column shows the improvement of SCAV over the best baseline for each metric.
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. Δ = SCAV - Best baseline.

🔼 This table shows the impact of different regularization terms (L1 and L2) on the ASR-keyword metric when using the Advbench dataset and the LLaMA-2-7B-Chat model. The results are presented for different values of the regularization parameter lambda (λ). The table demonstrates the sensitivity of the attack’s success rate to the choice of regularization technique and strength.
read the caption
Table 12: ASR-keyword (%) w.r.t different regularization terms (Advbench, LLaMA-2-7B-Chat)

🔼 This table shows the impact of varying the probability thresholds (Po and P1) on the attack success rate (ASR-keyword). The results are shown for the Advbench dataset and the LLaMA-2-7B-Chat model. It demonstrates the sensitivity of the attack performance to these parameters and the optimal range of values for achieving a high ASR-keyword.
read the caption
Table 13: ASR-keyword (%) w.r.t. varying Po and P₁ (Advbench, LLaMA-2-7B-Chat)
🔼 This table presents the quantitative results of embedding-level attacks on two LLMs (LLaMA-2 7B-Chat and LLaMA-2 13B-Chat) using three different methods: JRE, RepE, and SCAV. The evaluation metrics include ASR-keyword, ASR-answer, ASR-useful, and Language flaws. The SCAV method consistently outperforms the baselines across all metrics, indicating a significant improvement in attack success rate and response quality. The delta values (Δ) show the performance difference between SCAV and the best-performing baseline for each LLM and metric.
read the caption
Table 1: Automatic evaluation of embedding-level attack performance. All criteria except for ASR-keyword are evaluated by GPT-4. The best results are in bold and the second best are underlined. Δ = SCAV - Best baseline.

🔼 This table presents the results of the embedding-level attacks using SCAV on the Harmbench dataset. It shows the performance of the attacks in terms of ASR-keyword (the percentage of attacks that successfully trigger a response without refusal keywords), ASR-answer (the percentage of attacks that provide relevant answers to malicious instructions), ASR-useful (the percentage of attacks that provide useful answers), and Language Flaws (the number of language flaws in the responses). The results are shown for two different LLMs: LLaMA-2-7B-Chat and LLaMA-2-13B-Chat.
read the caption
Table 15: Attacking LLMs with embedding-level SCAV on Harmbench.

🔼 This table presents the results of applying the embedding-level SCAV attack method to a wider range of LLMs beyond those primarily featured in the paper. It shows the performance metrics (ASR-keyword, ASR-answer, ASR-useful, Language Flaws) for each model. The results highlight the effectiveness of SCAV across various open-source models, showcasing consistent high success rates in generating relevant and useful malicious responses.
read the caption
Table 16: Attacking more LLMs with embedding-level SCAV on Advbench.

🔼 This table presents the results of applying various prompt-level defense methods (Self-reminder, ICD, and Paraphrasing) against attacks on the LLaMA-2-7B-Chat model. The results are evaluated using four criteria: ASR-keyword, ASR-answer, ASR-useful, and Language Flaws. The table shows the attack success rates and the quality of the model’s responses after applying the defense mechanisms. The purpose is to assess the effectiveness of these defenses in mitigating the vulnerabilities of the model to attacks.
read the caption
Table 17: Attacking LLaMA-2-7B-Chat with different prompt-level defense methods.

🔼 This table presents the results of attacking two LLMs (LLaMA-3-8B-Instruct-RR and Mistral-7B-Instruct-RR) that have undergone adversarial training using the circuit breaker method [44] on the Advbench dataset. The table shows the attack success rate based on keyword matching (ASR-keyword), the percentage of responses that provide relevant answers (ASR-answer), the percentage of useful responses (ASR-useful), and the average number of language flaws in the model’s responses (Language Flaws). The results indicate whether adversarial training effectively mitigates the proposed attacks.
read the caption
Table 18: Attacking LLMs with adversarial training [44] on Advbench.
Full paper#