↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual program induction (VPI) traditionally relies on one-shot methods, which struggle to create complex programs. This paper addresses this by introducing a system that learns to iteratively edit visual programs, improving their accuracy. Existing methods lack the ability to refine programs, creating a need for a more iterative, human-like approach.
The proposed system uses a self-supervised method. It integrates an ’edit network’ to suggest local edits to improve a program. This is combined with a one-shot program generation model, forming a bootstrapped finetuning loop. The results show significant improvements over one-shot methods across multiple domains, especially with limited training data and extended search times.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel self-supervised approach to visual program editing, overcoming the limitations of one-shot methods. Its editing-based paradigm significantly improves visual program reconstruction accuracy, particularly when more time is dedicated to program search. This offers significant advancements in visual program induction and opens new avenues for future research in areas like program synthesis and debugging. The method’s effectiveness with limited data is a crucial contribution, expanding the potential for applications in data-scarce domains.
Visual Insights#
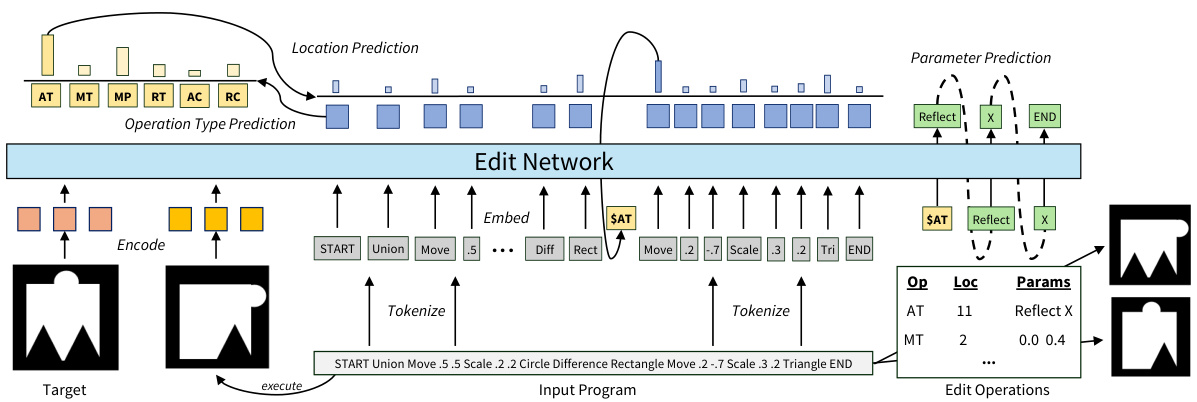
The figure illustrates the architecture of the edit network, which takes as input an existing visual program and its output, along with a target visual. The network predicts an edit operation (type, location, parameters) to improve the program’s similarity to the target. The edit operation is applied to the input program, and the process is iterated. The network is composed of three main modules: operation type prediction, location prediction, and parameter prediction.

This table presents the results of the test-set reconstruction accuracy across three different visual programming domains: Layout, 2D CSG, and 3D CSG. The table compares the performance of two approaches: using only a one-shot model (OS Only) and integrating an edit network with one-shot models (OS + Edit). The results show that the OS + Edit approach outperforms OS Only in all three domains, demonstrating the effectiveness of incorporating the edit network.
In-depth insights#
Self-Supervised VPI#
Self-supervised Visual Program Induction (VPI) tackles the challenge of automatically learning to generate programs from visual data without relying on labeled datasets. This approach is crucial because labeled data is often scarce and expensive to obtain in many visual domains. Self-supervised methods cleverly leverage the inherent structure and properties of visual data and programs to guide the learning process. Common techniques involve creating pseudo-labels or using a bootstrapping strategy where initial predictions are iteratively refined. A key advantage is the potential for improved generalization to unseen data since the model learns underlying patterns rather than memorizing specific examples. However, self-supervised VPI methods often require careful design of the learning objective and often involve more complex training procedures compared to supervised approaches. The success of such methods hinges on carefully balancing exploration (generating diverse programs) and exploitation (refining existing programs to better match visual targets). Effective self-supervised VPI represents a significant step towards robust and generalizable visual program synthesis capable of handling a wider array of complex visual data.
Edit Network Design#
The “Edit Network Design” section would detail the architecture and functionality of the neural network responsible for suggesting program edits. This would involve a description of the network’s input, likely including the original visual program’s code, its execution output, and the target visual representation. The network’s architecture would be explained, probably specifying the use of a recurrent or transformer-based model capable of processing sequential data and identifying relationships between program elements and visual features. Crucial aspects would be the method for representing edit operations, which might use a dedicated vocabulary or a learned embedding, and the mechanism for generating edits, whether this involved predicting a complete edit or a set of local modifications. The design choices in this section would be justified based on their effectiveness and efficiency in achieving the ultimate goal of program refinement. The loss function and training methodology used to optimize the network would also be discussed. A strong design would emphasize the network’s ability to reason locally about program structure, ensuring the generated edits are syntactically valid and lead to semantically meaningful changes in program behavior.
Joint Finetuning#
The concept of “Joint Finetuning” in the context of a research paper likely refers to a training strategy where multiple neural networks are simultaneously optimized. This approach is particularly beneficial when dealing with complex tasks that can be decomposed into sub-tasks, each handled by a specialized network. The key advantage is that the interaction between these models enhances performance beyond what individual models could achieve on their own. For example, one network might generate initial program candidates, which are then refined by an ’edit network’ that learns to propose and apply local changes to improve their accuracy. The simultaneous training of these networks facilitates a synergistic learning process, where the shortcomings of one are compensated for by the strengths of the other. This iterative refinement process is particularly powerful in scenarios lacking fully annotated datasets for supervision. The joint finetuning approach facilitates self-supervised learning, using the output of one network to generate training data for another. This bootstrapping technique, where the models iteratively improve each other, is crucial for tasks like visual program induction where acquiring fully labeled datasets can be challenging. Ultimately, the success of joint finetuning depends on carefully designing the individual networks and their interaction for optimal information exchange and mutual improvement.
Inference Algorithm#
The research paper’s “Inference Algorithm” section details a novel method for visual program induction. It cleverly integrates a one-shot model, capable of generating entire programs, with an edit network that predicts local program modifications. The algorithm begins by initializing a population of programs using the one-shot model. This population then iteratively evolves through rounds of edits proposed by the edit network, followed by resampling based on a reconstruction metric. This iterative refinement process leverages the strengths of both networks: the one-shot model provides initial, rough estimates, while the edit network refines them towards a visual target. The self-supervised nature of the training, through bootstrapped finetuning, addresses the challenge of limited annotated data. This method contrasts with traditional one-shot approaches by explicitly incorporating program execution and allowing for goal-directed edits, which mimics a more human-like programming workflow. Crucially, the approach controls for equal inference time across different methods, demonstrating performance improvements that widen with increased search time. The section effectively highlights the algorithm’s synergistic design and its advantages in terms of efficiency and accuracy.
Ablation Experiments#
Ablation studies systematically investigate a model’s design choices by removing or altering components and observing the impact on performance. In the context of a research paper, an ablation experiment section would provide evidence supporting the design decisions made. A well-designed ablation study will isolate the contribution of specific components, carefully analyzing how the removal of certain parts affects the final outcome. This would help confirm that claimed improvements are not due to spurious correlations or other unintended factors. For example, if a model incorporates multiple modules (e.g., an edit network and a one-shot model), an ablation study would individually assess the contribution of each. Results showcasing a significant performance drop when removing a particular module would strongly support its importance. Conversely, a negligible drop could suggest that the module is redundant or its design might need reevaluation. Careful consideration should be given to the methodology; for instance, ensuring all ablated variants use the same training regime and evaluation metrics for fair comparison. The ablation study’s outcomes are crucial for demonstrating the model’s robustness and establishing its specific strengths. Ultimately, a comprehensive ablation study enhances the credibility and overall significance of the research findings by demonstrating the necessity and effectiveness of the implemented design choices.
More visual insights#
More on figures

This figure illustrates the architecture of the edit network, a key component of the proposed system. The network takes as input a program, its execution result, and a visual target. It then predicts an edit operation, its location within the program, and any necessary parameters. The process involves tokenizing the input program and target, embedding them, and utilizing a Transformer decoder architecture to predict the type, location, and parameters of the edit. The predicted edits refine the input program incrementally to better match the target.

This figure illustrates the two main algorithms used in the paper. The left side shows the bootstrapping algorithm, which iteratively refines both the edit network and the one-shot model using a combination of synthetic and real data. The right side details the inference algorithm which begins with a population of programs generated by the one-shot model and progressively refines them towards the target visual representation by applying edits predicted by the edit network and then resampling based on reconstruction quality. This iterative process allows for a more directed and efficient program search compared to a purely one-shot approach.

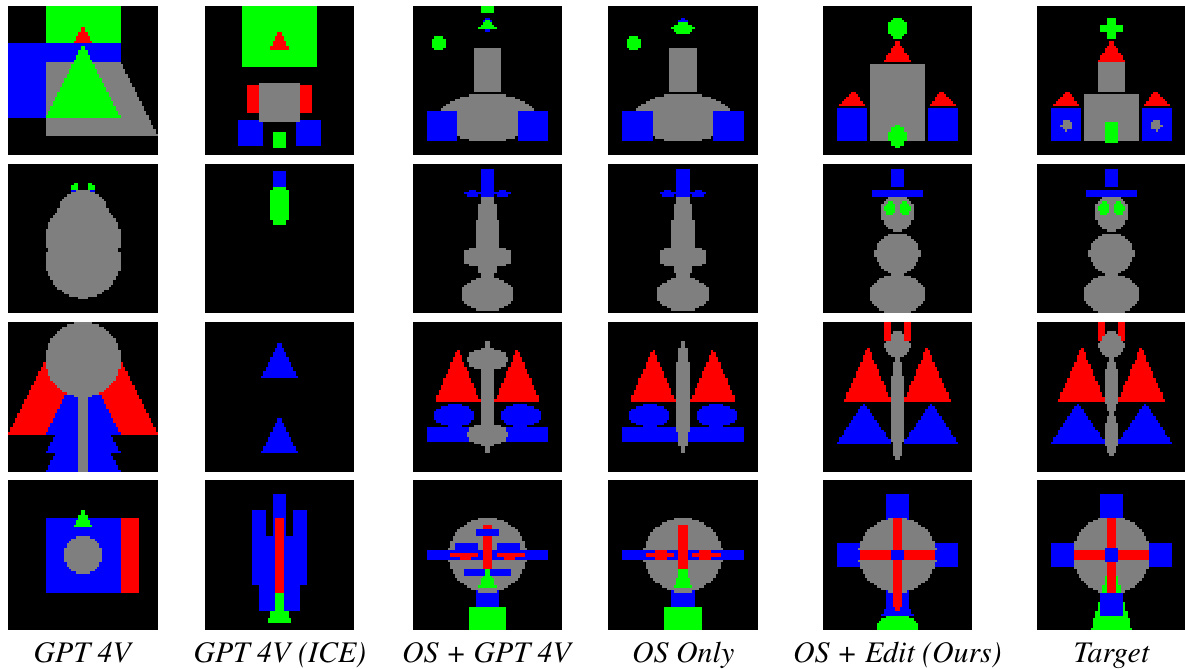
This figure compares the visual reconstruction results of two methods: a one-shot model and a joint approach combining a one-shot model with an edit network. The top row shows the reconstructions generated by the one-shot model alone. The middle row displays the results from the joint approach, highlighting its improved accuracy. The bottom row presents the target images that both methods aimed to reconstruct. The visual comparison clearly demonstrates the superior performance of the joint approach in accurately recreating the target images.
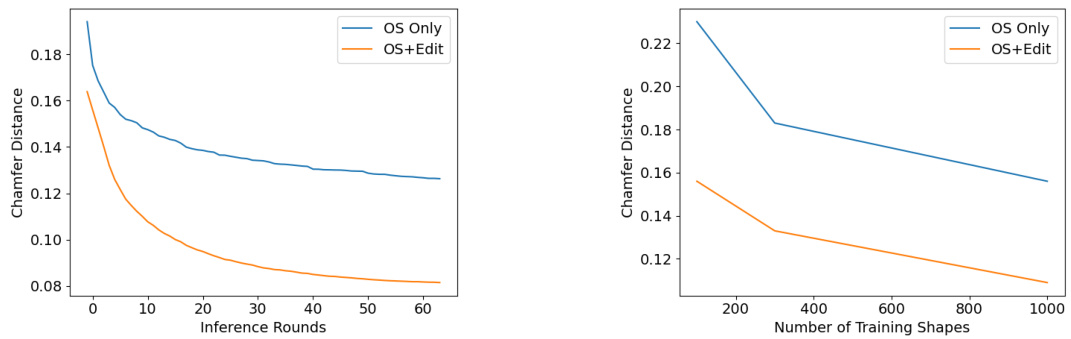
This figure shows two graphs that compare the performance of two different methods for visual program induction: one using only a one-shot model and another integrating an edit network with a one-shot model. The left graph shows how reconstruction accuracy changes as the inference time increases (number of inference rounds). The right graph shows how the accuracy changes as the size of the training dataset increases (number of training shapes). In both cases, the method incorporating the edit network consistently outperforms the one-shot model, particularly as more time is spent on inference or with larger training datasets.

This figure demonstrates the iterative process of the proposed inference algorithm. It begins with a population of initial program samples (top row), which are then iteratively modified (subsequent rows) by applying edits predicted by the edit network. Each edit brings the program closer to matching the target visual output (far right column), showing the iterative refinement of the program towards the target image.

This figure shows qualitative comparisons of 3D CSG reconstruction results. Three columns represent the results of using only a one-shot model, using the proposed joint model (one-shot + edit network), and the target shape. Each row displays a different shape, showcasing the improved accuracy of the proposed method in reconstructing complex 3D shapes that were not included in the initial training data.
The figure shows how the proposed method improves visual program reconstruction through iterative edits. Starting from an initial population of programs generated by a one-shot model, the algorithm iteratively applies local edits predicted by an edit network. The edits are guided by a visual target, and the process continues until the population converges towards programs that better reconstruct the target image. Each row represents a different visual program example, showing the initial population, the intermediate steps of applying edits, and the final result after multiple rounds of editing.
More on tables
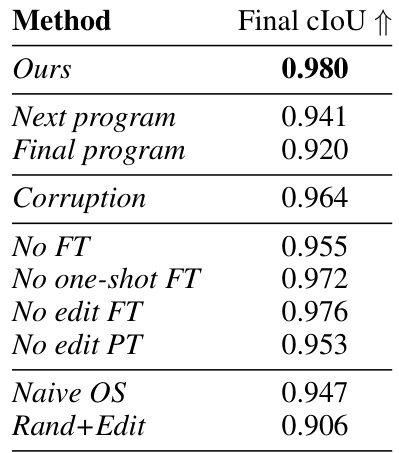
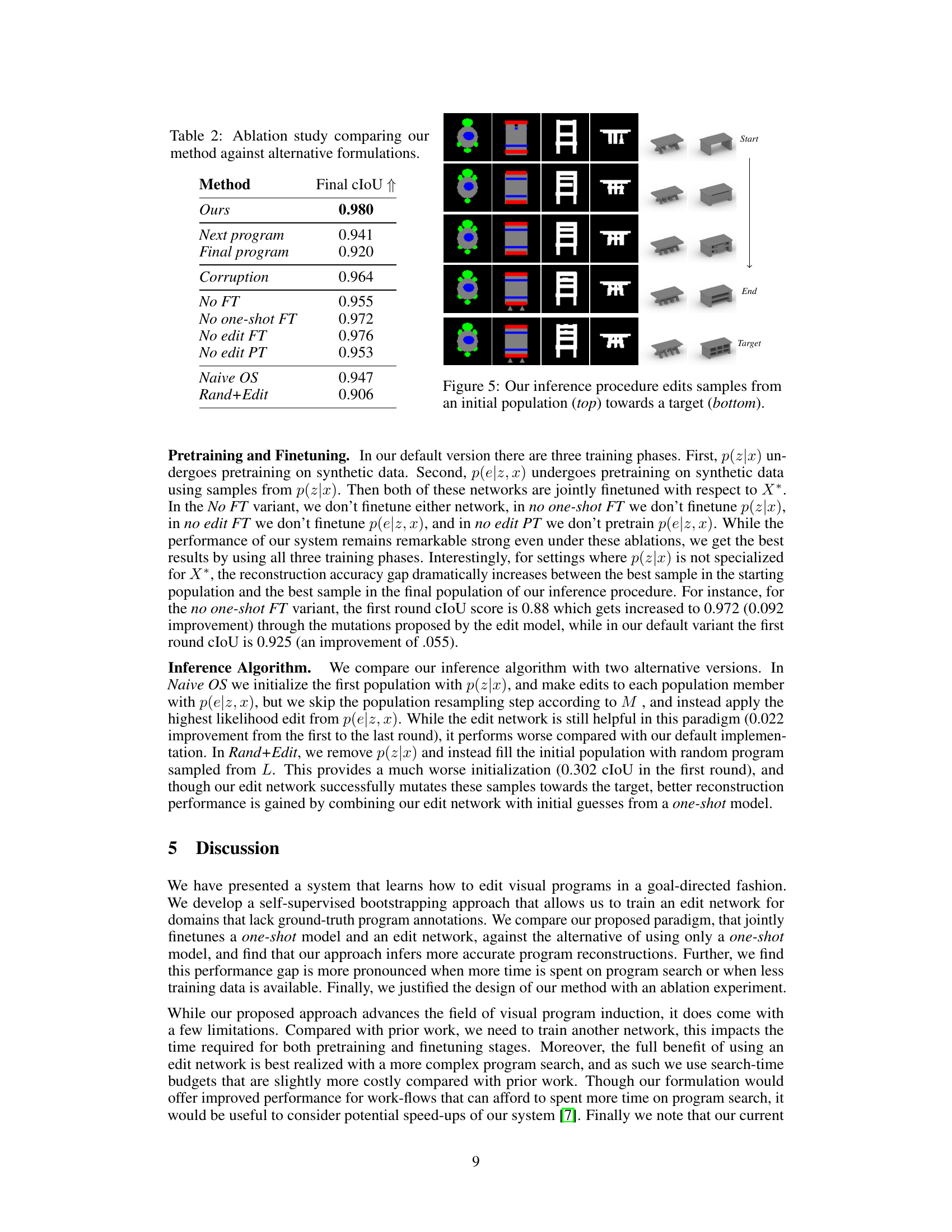
This table presents the results of an ablation study conducted to evaluate the design choices of the proposed system. It compares the performance of the default method against several variations, each removing or modifying a key component. Specifically, it examines the impact of different edit operation formulations, finetuning strategies, and the role of the one-shot network, offering insights into the relative importance of each element in the system’s overall performance.

This table presents the results of reconstruction accuracy for challenging tasks, specifically those from concepts or categories unseen during training. The results are compared for two approaches: using only one-shot models and the proposed joint paradigm integrating one-shot models with an edit network. The table highlights the superior performance of the joint approach in both Layout and 3D CSG domains.

This table presents the results of an ablation study performed on the 2D CSG domain. It shows the Chamfer Distance, a measure of reconstruction error, achieved by different variants of the proposed method. These variants systematically remove or disable components of the training process such as finetuning the one-shot model or the edit network, and pretraining the edit network to assess their individual contribution to the overall performance. The lower the Chamfer Distance, the better the reconstruction.
Full paper#