TL;DR#
Machine learning on graphs is powerful but vulnerable to bias. Existing graph structures can amplify biases, leading to unfair outcomes in applications like social recommendations. Current synthetic graph generation methods also don’t sufficiently address this issue, hindering responsible AI development. This poses challenges for deploying graph machine learning in real-world systems where fairness is crucial.
The paper introduces FairWire, a framework that uses a novel fairness regularizer to mitigate structural bias. This regularizer is theoretically grounded and empirically shown to be effective. FairWire is applied in a diffusion-based graph generation model, producing fair synthetic graphs suitable for various tasks. Experiments validate that FairWire effectively mitigates bias without sacrificing model performance, making a significant step towards equitable AI applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the significant problem of bias in graph machine learning, a rapidly growing field. It offers practical solutions for creating fairer models and datasets, which is critical for building trustworthy and equitable AI systems. The proposed methods are versatile and applicable to various graph-related tasks, opening new avenues for research in fairness-aware graph learning. Its theoretical analysis provides a strong foundation for future work, helping to guide the development of even more effective bias mitigation techniques.
Visual Insights#

🔼 This figure visualizes the distribution of intra-edges (blue) and inter-edges (red) in synthetic graphs generated using two different methods for the Cora dataset. The left panel shows the graph generated by the GraphMaker method (a fairness-agnostic approach), while the right panel shows the graph generated by the FairWire method (a fairness-aware approach). The visualization highlights the difference in edge distribution between the two methods. GraphMaker shows a higher density of intra-edges indicating a bias towards connections within the same sensitive group, while FairWire demonstrates a more balanced distribution, suggesting a reduction in bias and improved fairness. This visual comparison supports the paper’s findings regarding the effectiveness of FairWire in mitigating structural bias in graph generation.
read the caption
Figure 1: Distribution of the intra-edges (blue) and inter-edges (red) in the synthetic graphs created for Cora dataset by GraphMaker (47) (left) and FairWire (right).
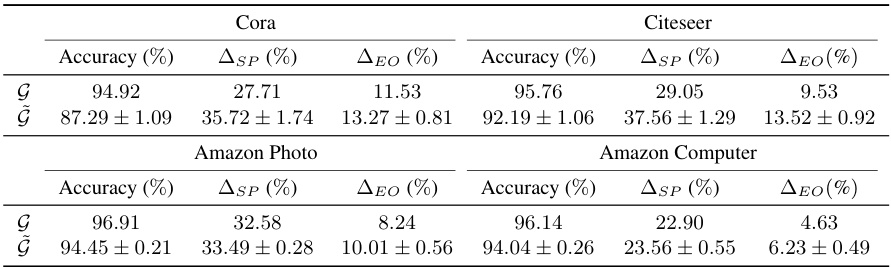
🔼 This table presents a comparison of the performance of original graphs (G) and synthetic graphs (G~) generated using a diffusion model across four different datasets: Cora, Citeseer, Amazon Photo, and Amazon Computer. For each dataset, it shows the accuracy, statistical parity (ASP), and equal opportunity (ΔEO) for link prediction. Lower ASP and ΔEO values indicate better fairness. The results highlight that the synthetic graphs generated by the diffusion model exhibit higher values for ASP and ΔEO than the original graphs, indicating an increase in bias after graph generation.
read the caption
Table 1: Comparative results
In-depth insights#
Fair Graph Mining#
Fair graph mining presents a crucial intersection of fairness and graph-structured data analysis. It tackles the challenge of mitigating biases that may exist within graph data and subsequently lead to unfair or discriminatory outcomes in machine learning models trained on such data. Algorithmic bias amplification through graph neural networks (GNNs) is a significant concern addressed by fair graph mining, as these methods can exacerbate existing societal prejudices. The development of fairness-aware algorithms for graph-based applications like link prediction and node classification is paramount to ensuring equitable results. Fair graph mining research also investigates the creation of synthetic, fair graphs that preserve valuable statistical properties while protecting privacy and avoiding discriminatory representations. This field necessitates both theoretical analysis to understand the root causes of bias in graph structures and practical methodologies that can be implemented to mitigate these biases. The ultimate goal is to empower the use of graph data analytics while upholding fairness and ethical considerations.
Bias Amplification#
The concept of bias amplification in the context of graph neural networks (GNNs) is critical. The inherent biases present in real-world graph data, reflecting societal inequalities or structural biases, are often exacerbated rather than mitigated by GNN models. This means that the output of a GNN, intended for tasks such as link prediction or node classification, can significantly amplify the initial biases, leading to unfair or discriminatory results. This is particularly concerning in applications that impact individuals’ lives, such as loan applications or hiring processes. The paper’s exploration of fairness regularizers offers a promising avenue for mitigating these issues, suggesting that focusing on structural fairness during model training is key to obtaining unbiased predictions. Understanding and addressing bias amplification is essential for responsible development and deployment of GNN-based systems. Failure to do so risks creating systems that perpetuate societal inequalities rather than solving them.
FairWire Framework#
The FairWire framework tackles the critical issue of bias amplification in graph generation models. It introduces a novel fairness regularizer, LFairWire, designed to mitigate structural bias in graph data. This regularizer is theoretically grounded, analyzing the sources of bias in dyadic relationships and offering a versatile solution applicable to various graph-related tasks. FairWire leverages LFairWire within a diffusion-based graph generation model, enabling the generation of synthetic graphs that accurately reflect real-world network characteristics while effectively reducing structural bias. Experiments on real-world networks demonstrate the framework’s effectiveness, validating its ability to improve fairness without significantly compromising utility in link prediction and node classification tasks. The framework’s task-agnostic nature and scalability make it a significant contribution to the field of fair machine learning.
Diffusion Models#
Diffusion models, in the context of graph generation, offer a powerful approach to synthesize realistic and complex graph structures. They function by iteratively adding noise to a graph until it becomes pure noise, then learning to reverse this process to generate new graphs. This generative process allows for capturing intricate relationships and statistical properties present in real-world graphs, making them particularly useful for tasks where real data is scarce, sensitive, or computationally expensive to work with. A key advantage is the ability to control certain aspects of the generated graphs, such as degree distributions or community structure, providing a pathway to address issues like fairness and bias in downstream applications. However, challenges remain in scaling diffusion models to handle extremely large graphs and ensuring that the generated graphs accurately reflect all relevant structural properties of the original data. Fairness-aware graph generation using diffusion models represents a significant frontier, requiring methods to mitigate bias amplification inherent in the generative process itself and ensuring generated sensitive attributes align with realistic distributions, thereby avoiding unintentional discriminatory patterns in the resultant synthetic graphs.
Future of Fairness#
The “Future of Fairness” in machine learning, especially within graph-structured data, necessitates a multi-pronged approach. Addressing inherent biases in algorithms and datasets is crucial; this requires deeper investigation into the root causes of bias, going beyond simple demographic factors to incorporate the nuanced ways societal structures influence data representation. Developing more robust and versatile fairness metrics is essential to move beyond simplistic notions of fairness, accommodating the complex interplay between different fairness criteria and real-world contexts. Research should focus on the development of more effective, explainable, and less resource-intensive fairness interventions, that can be broadly applied and easily integrated into existing machine learning workflows. Finally, fostering a collaborative environment between researchers, policymakers, and practitioners is critical for ensuring the responsible development and implementation of fair AI systems, promoting transparency and accountability in their use and impact.
More visual insights#
More on tables
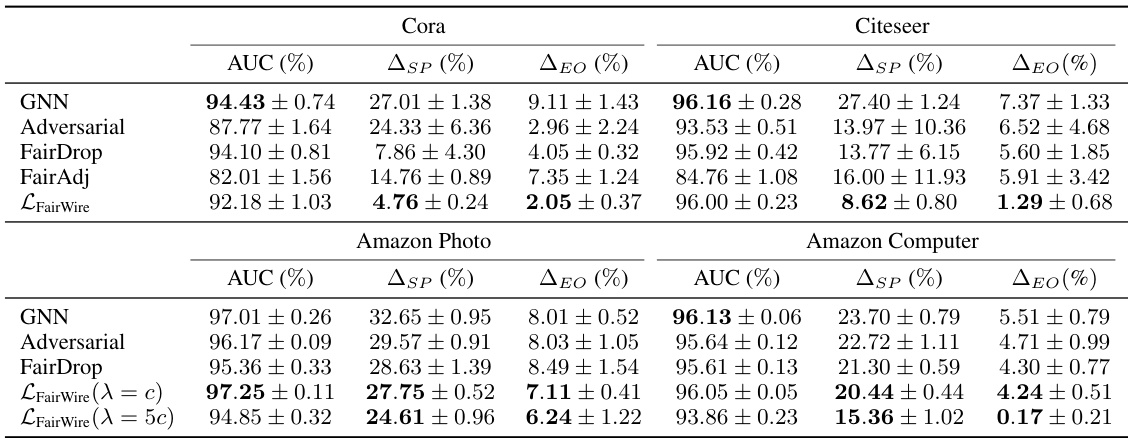
🔼 This table presents the results of a link prediction experiment comparing the performance of several fairness-aware methods against a baseline GNN model. The metrics used to evaluate performance are AUC (Area Under the Curve), ASP (statistical parity), and ΔEO (equal opportunity). Lower values for ASP and ΔEO indicate better fairness. The table shows that the proposed LFairWire method achieves better fairness while maintaining comparable utility to the baseline GNN model and outperforming other fairness-aware baselines. Results are provided for multiple datasets (Cora, Citeseer, Amazon Photo, and Amazon Computer).
read the caption
Table 2: Comparative link prediction results.
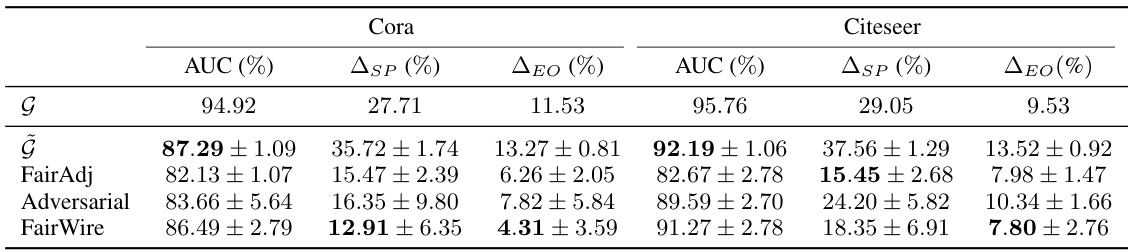
🔼 This table presents a comparison of link prediction results for original graphs (G) and synthetic graphs generated using different methods. The metrics include AUC (Area Under the Curve), ASP (Statistical Parity), and ΔEO (Equal Opportunity). Lower values of ASP and ΔEO indicate better fairness. The table shows that FairWire achieves better fairness compared to the baseline GNN (Graph Neural Network) and other fairness-aware methods while maintaining relatively high utility (AUC).
read the caption
Table 3: Comparative results for graph generation on Link Prediction.
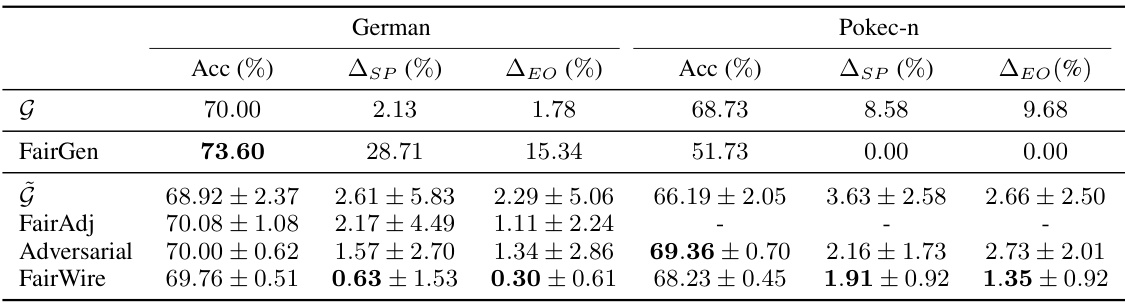
🔼 This table presents the comparative results for node classification on two datasets, German and Pokec-n, using various methods including FairGen, FairAdj, Adversarial, and FairWire. The metrics used are accuracy (Acc), statistical parity (ΔSP), and equal opportunity (ΔEO). Lower values for ΔSP and ΔEO indicate better fairness. The table shows the performance of these methods on both link prediction and node classification tasks, highlighting the effectiveness of FairWire in achieving a balance between accuracy and fairness.
read the caption
Table 4: Comparative results for graph generation on Node Classification.
🔼 This table compares the performance of different link prediction methods (GNN, Adversarial, FairDrop, FairAdj, and LFairWire) across four datasets (Cora, Citeseer, Amazon Photo, and Amazon Computer). The metrics used are AUC (Area Under the Curve), ASP (statistical parity), and ΔEO (equal opportunity). Lower values for ASP and ΔEO indicate better fairness. The table shows that LFairWire generally achieves higher AUC (better utility) and lower ASP and ΔEO (better fairness) compared to the baseline GNN model and other fairness-aware baselines.
read the caption
Table 2: Comparative link prediction results.

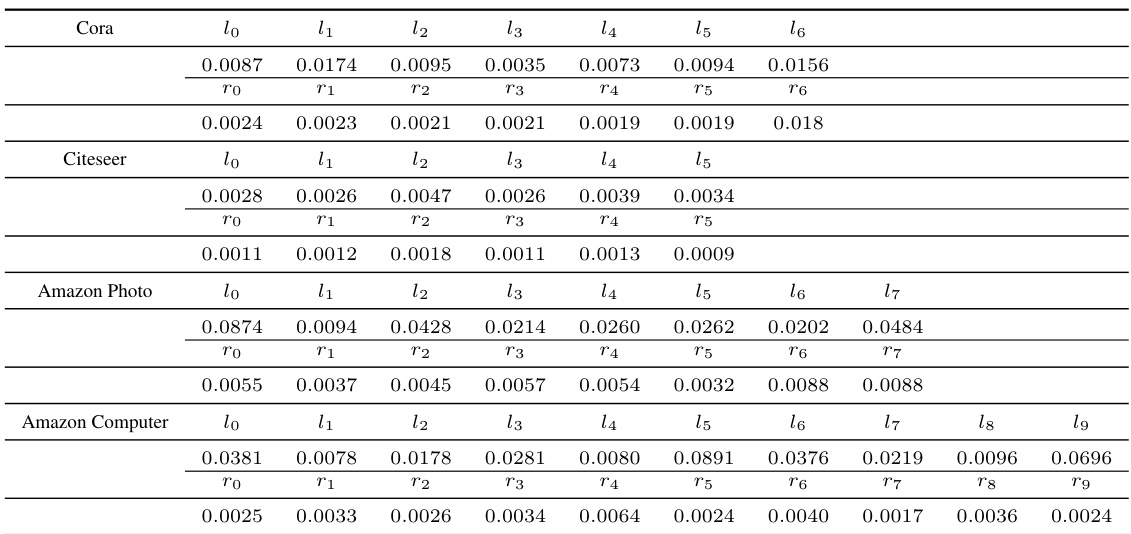
🔼 This table presents the empirical validation of Assumption 3 from Section 4.1 of the paper. Assumption 3 states that the sum of all entries in the adjacency matrix should be significantly larger than the expected degree of a node sampled uniformly from the node set. The table lists the sum of all entries in the adjacency matrix (Σvᵢ,vⱼ∈V Ãᵢⱼ) and the expected degree (EÃ,vᵢ~U[V][d(V)ᵢ]) for four real-world datasets (Cora, Citeseer, Amazon Photo, Amazon Computer). The values in the table show that Assumption 3 is satisfied in all four real-world datasets, which supports the validity of the theoretical analysis.
read the caption
Table 6: Validity of Assumption 3 for real-world graphs.

🔼 This table presents the statistical information for the datasets used in the paper. It shows the number of nodes (|V|), number of edges (|ε|), number of features (F), and number of sensitive groups (K) for each dataset: Cora, Citeseer, Amazon Photo, Amazon Computer, German Credit, and Pokec-n.
read the caption
Table 7: Dataset statistics.

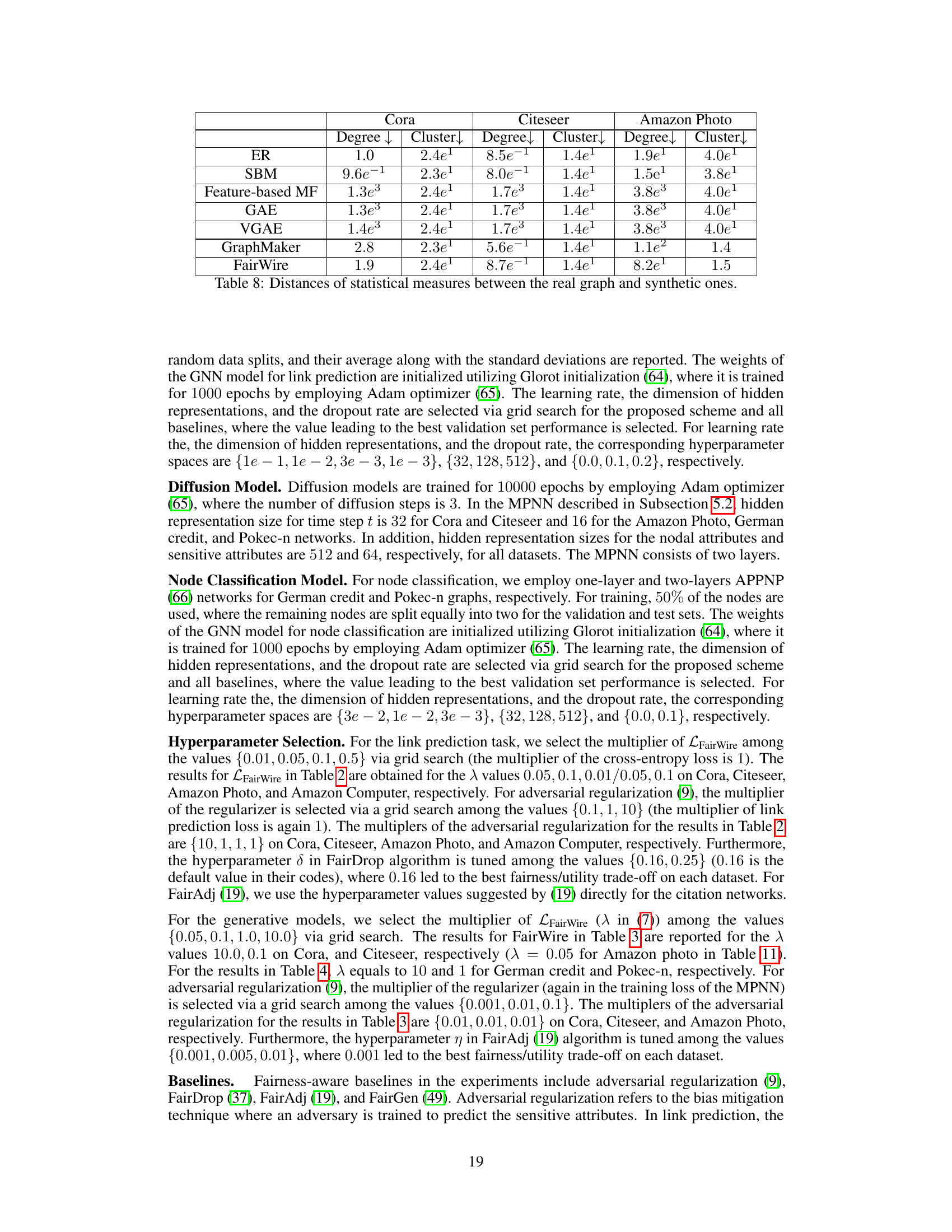
🔼 This table presents the 1-Wasserstein distances between the node degree distributions and clustering coefficient distributions of the original and synthetic graphs generated by different methods. Lower values indicate better similarity between the generated and original graph structures. The methods compared include traditional baselines (Erdos-Rényi, Stochastic Block Model), deep learning methods (Feature-based MF, GAE, VGAE), a fairness-agnostic graph generation baseline (GraphMaker), and the proposed FairWire method. The results show that FairWire can generate graphs with structural properties similar to the original data.
read the caption
Table 8: Distances of statistical measures between the real graph and synthetic ones.

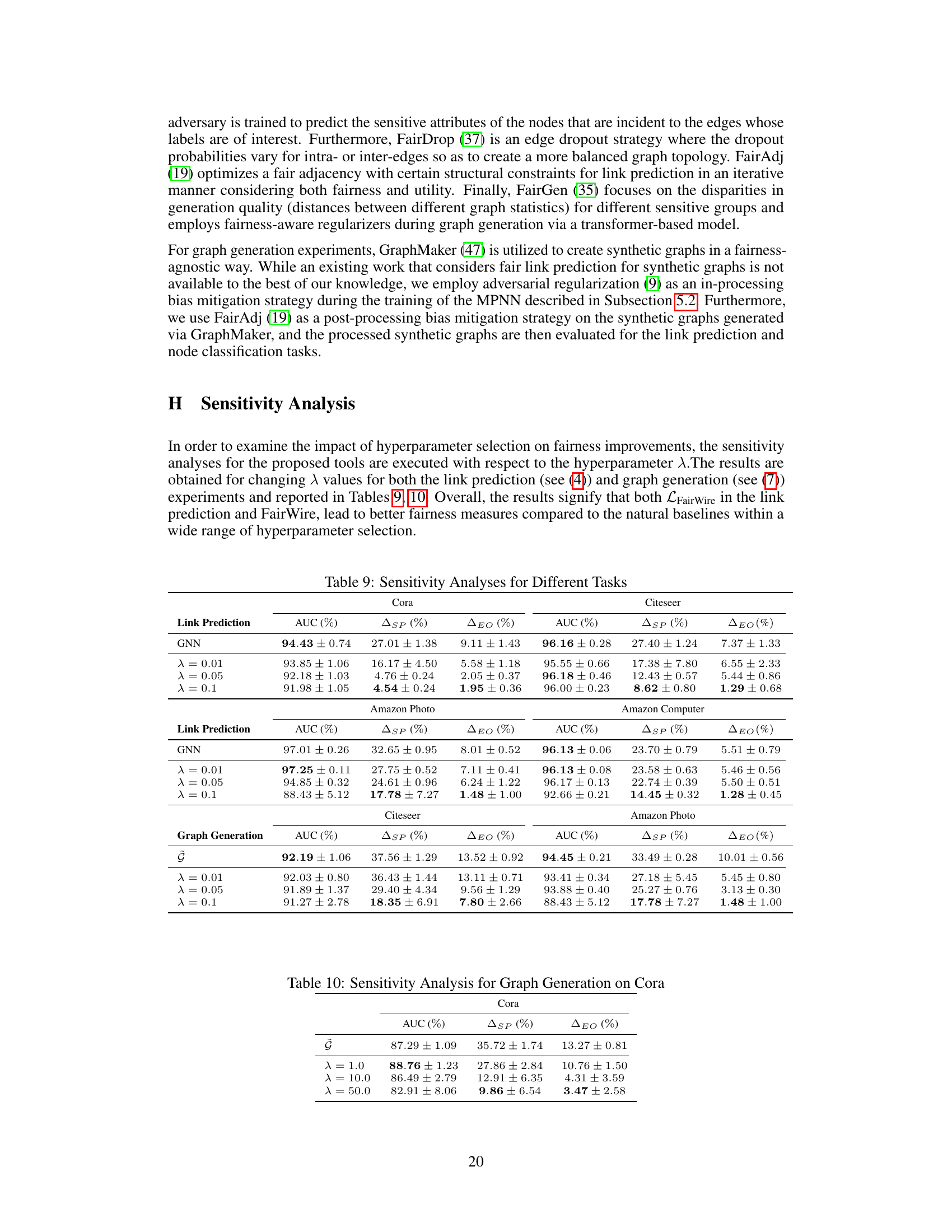
🔼 This table presents a comparison of link prediction results using different methods on four datasets (Cora, Citeseer, Amazon Photo, and Amazon Computer). The methods compared include a standard GNN (baseline) and three fairness-aware approaches (Adversarial, FairDrop, and FairAdj). The results are shown for three different values of a hyperparameter (λ) for the fairness-aware method LFairWire which was proposed in the paper. For each method and dataset, the table shows the AUC, ASP (statistical parity), and ΔΕΟ (equal opportunity) scores. Lower ASP and ΔΕΟ scores indicate better fairness.
read the caption
Table 2: Comparative link prediction results.

🔼 This table shows the results of a sensitivity analysis performed on the Cora dataset for graph generation using the FairWire framework. The analysis focuses on how different values of the hyperparameter λ impact the AUC (Area Under the Curve), ΔSP (Statistical Parity), and ΔEO (Equal Opportunity) metrics. Lower values for ΔSP and ΔEO indicate better fairness.
read the caption
Table 10: Sensitivity Analysis for Graph Generation on Cora
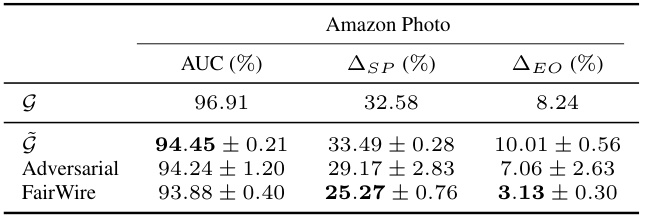
🔼 This table compares the performance of original graphs (G) against synthetic graphs (G) generated using different methods, specifically evaluating the accuracy, statistical parity (ASP), and equal opportunity (ΔEO) metrics for link prediction. It shows that synthetic graph generation amplifies existing biases and that the FairWire method mitigates this amplification more effectively than other baselines.
read the caption
Table 1: Comparative results
Full paper#