TL;DR#
Vision Transformers (ViTs) excel in capturing long-range dependencies but suffer from quadratic time and memory complexity due to their self-attention mechanism. This limits their application in resource-constrained scenarios. Previous linear attention methods attempted to reduce the complexity but often compromised accuracy.
This paper introduces QT-ViT, a novel approach to improve linear self-attention using quadratic Taylor expansion. By cleverly approximating the softmax function, QT-ViT maintains superior performance while significantly reducing computational overhead. The proposed method outperforms existing linear self-attention techniques and achieves state-of-the-art results on various vision tasks, offering a compelling balance between efficiency and accuracy. The key is combining the benefits of quadratic expansion for better accuracy and linear approximation for fast inference.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the efficiency of Vision Transformers (ViTs), a crucial architecture in computer vision. By addressing the quadratic complexity of self-attention, it enables the application of ViTs to larger-scale problems and higher-resolution images, opening new possibilities for real-world applications. The proposed method’s superior performance over existing linear attention methods makes it highly relevant to current research trends, pushing the boundaries of efficient deep learning.
Visual Insights#
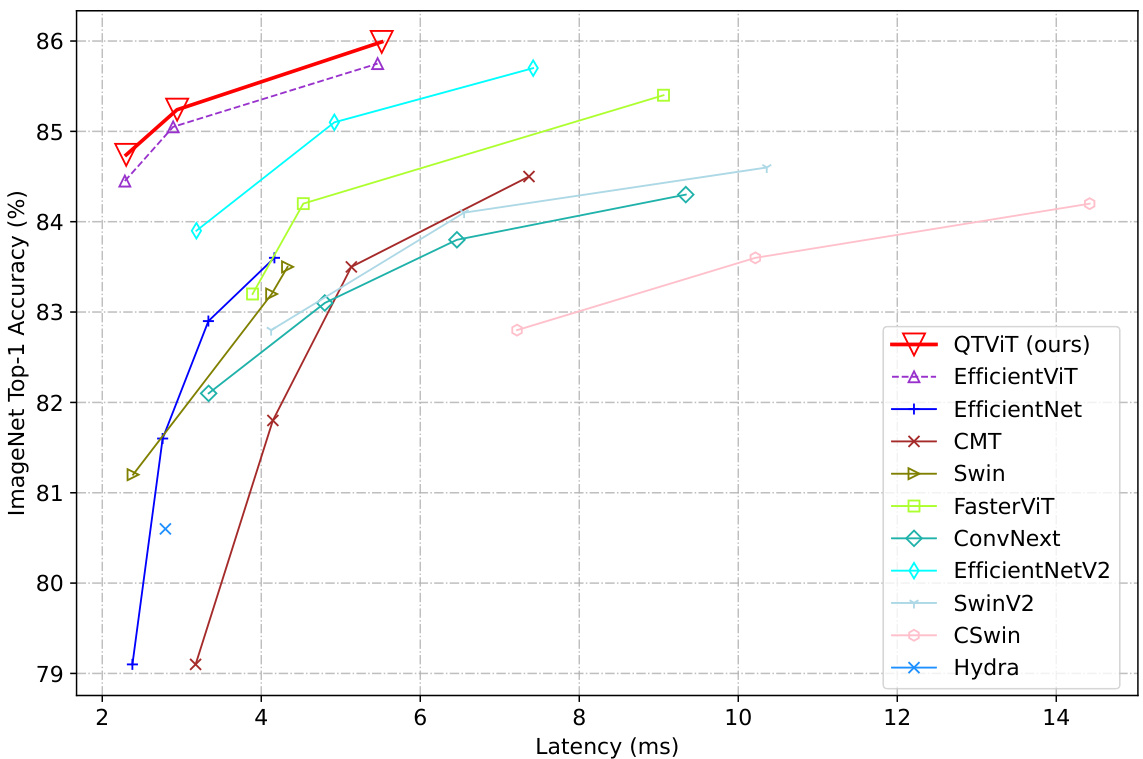
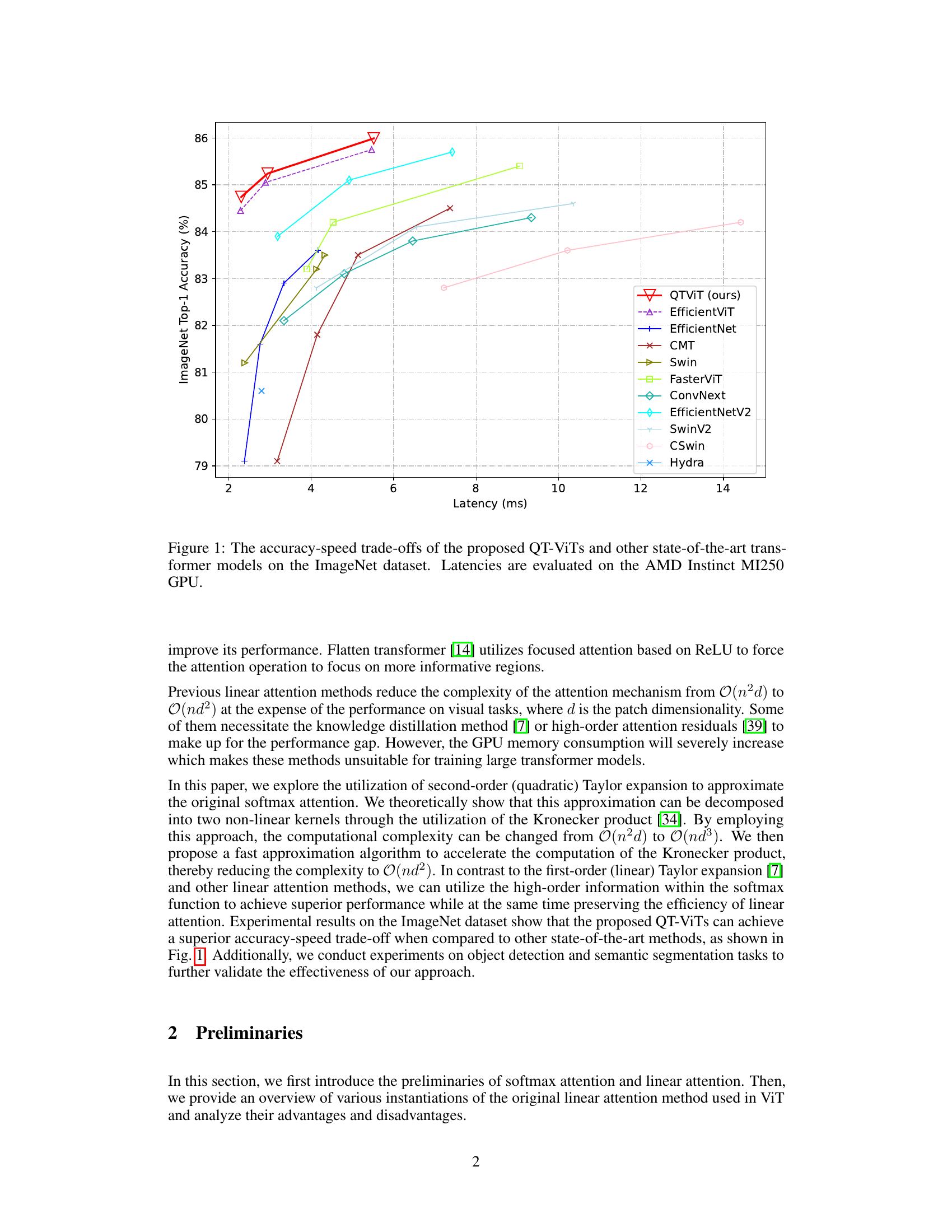
🔼 This figure compares the accuracy and speed of various vision transformer models, including the proposed QT-ViT models, on the ImageNet dataset. The x-axis represents the latency (in milliseconds) of each model, indicating the inference speed, while the y-axis represents the ImageNet top-1 accuracy. The plot shows the accuracy-speed trade-off for each model, illustrating how different models balance accuracy and computational efficiency. QT-ViTs are demonstrated to achieve state-of-the-art results by achieving a new Pareto front, meaning they significantly outperform the compared models in terms of accuracy for a given speed or provide faster inference for a given accuracy level.
read the caption
Figure 1: The accuracy-speed trade-offs of the proposed QT-ViTs and other state-of-the-art transformer models on the ImageNet dataset. Latencies are evaluated on the AMD Instinct MI250 GPU.
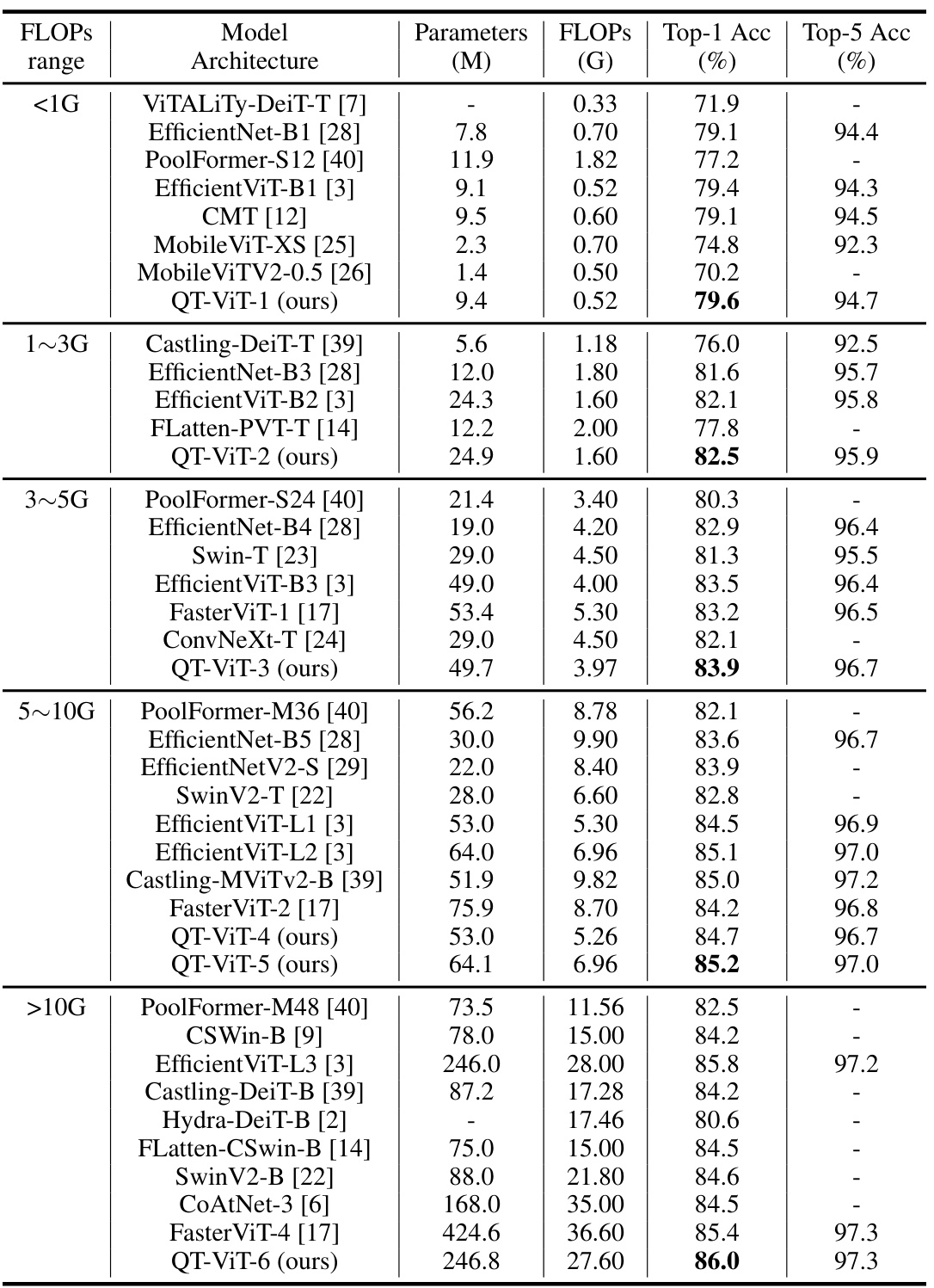
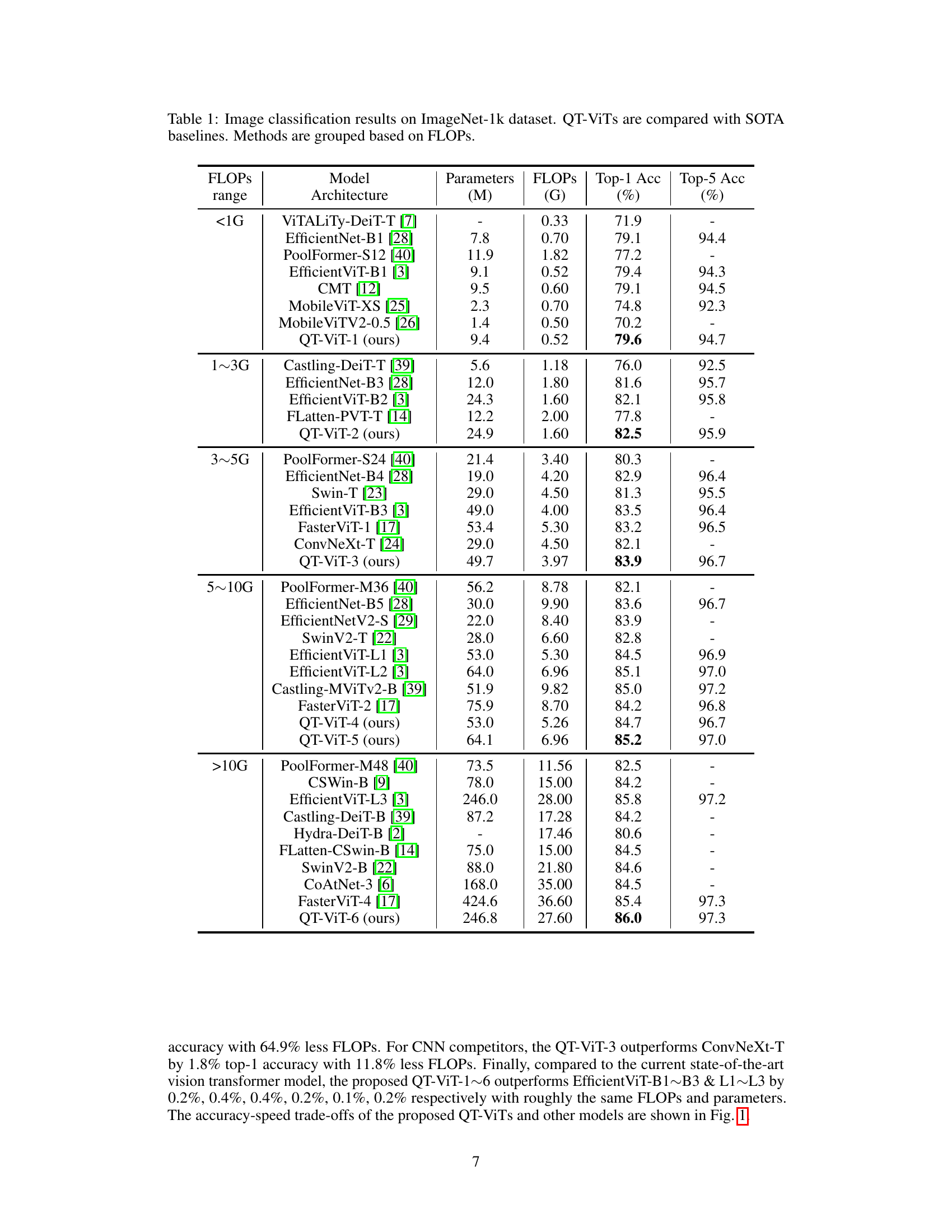
🔼 This table presents a comparison of the proposed QT-ViT models against state-of-the-art vision transformers and CNNs on the ImageNet-1k image classification benchmark. The models are categorized into groups based on their FLOPs (floating-point operations), and their performance is evaluated using Top-1 and Top-5 accuracy metrics. The table also shows the number of parameters for each model.
read the caption
Table 1: Image classification results on ImageNet-1k dataset. QT-ViTs are compared with SOTA baselines. Methods are grouped based on FLOPs.
In-depth insights#
Quadratic Attention#
Quadratic attention, a theoretical concept, would represent a significant advancement in attention mechanisms. Unlike linear attention, which scales linearly with the input sequence length, quadratic attention inherently captures pairwise relationships between all tokens. This could lead to richer contextual understanding and improved performance on tasks requiring complex relationships between elements. The computational cost of quadratic attention is, however, a primary concern. Approximations, like using Taylor expansions as explored in the paper, are necessary to make quadratic attention practical. The balance between accuracy and efficiency is crucial in designing a viable quadratic attention model, making the choice of approximation method extremely important. Further research should focus on optimizing approximation techniques for speed and memory efficiency while maximizing the benefits of true pairwise interactions.
EfficientViT Advance#
An EfficientViT advance likely focuses on enhancing the efficiency of Vision Transformers (ViTs) by addressing the quadratic complexity of self-attention. Key improvements could involve novel linear attention mechanisms, more efficient softmax approximations (e.g., using Taylor expansions), or architectural modifications that reduce computational cost. These could include techniques like sparse attention, local attention, or attention mechanisms that scale linearly with the input size, enabling faster inference and lower memory requirements. Furthermore, a successful advance would likely demonstrate superior performance compared to existing methods while maintaining or even surpassing accuracy. The trade-off between speed and accuracy is crucial here. Improvements might also explore efficient training strategies and knowledge distillation to enhance performance further, ultimately enabling the broader applicability of ViTs in resource-constrained environments or for real-time applications. The research would need to thoroughly evaluate the proposed approach on standard benchmark datasets. A comprehensive comparison with state-of-the-art methods would validate its efficiency gains and overall effectiveness.
Kronecker Product#
The research paper leverages the Kronecker product as a crucial tool for efficiently approximating the computationally expensive softmax operation in vision transformers. By decomposing the quadratic Taylor expansion of the softmax function using the Kronecker product, the authors achieve a significant reduction in complexity. This decomposition allows the attention mechanism to scale more effectively to larger input sizes, a key limitation of traditional self-attention methods. However, the resulting quadratic expansion still presents a computational challenge. To mitigate this, a fast approximation algorithm is introduced, which cleverly manipulates the structure of the Kronecker product to reduce the computational cost further, ultimately improving both speed and accuracy. This highlights the power and versatility of the Kronecker product for handling high-dimensional data structures and complex mathematical operations within deep learning models, especially in contexts where computational efficiency is paramount.
Ablation Experiments#
Ablation experiments systematically remove components of a model to determine their individual contributions. In a vision transformer (ViT) context, this might involve removing or modifying attention mechanisms, specific layers, or activation functions. The goal is to isolate the impact of each part, understanding which elements are crucial for performance and which are redundant. Well-designed ablation studies provide crucial evidence for a model’s design choices, demonstrating that the selected components are indeed beneficial. They help avoid overfitting by showing that performance isn’t solely driven by a single component. Results often reveal unexpected interactions between components, highlighting the importance of a holistic approach to model design. Finally, understanding which parts contribute most to performance can guide future improvements and potentially lead to more efficient architectures.
Future Works#
Future research directions stemming from this work on quadratic Taylor expansion for linear attention in vision transformers (ViTs) could explore several promising avenues. Extending the approach to other attention mechanisms beyond self-attention, such as cross-attention, would broaden its applicability. Investigating higher-order Taylor expansions to further refine the approximation of softmax attention is another key area, potentially yielding even better accuracy-efficiency trade-offs. Combining QT-ViT with other optimization techniques, like pruning or quantization, could further enhance efficiency for deployment on resource-constrained devices. Additionally, a thorough examination of the impact of different kernel functions and their suitability for various vision tasks warrants investigation. Finally, applying QT-ViT to larger-scale vision tasks and datasets, such as those involving high-resolution images or long videos, would establish its robustness and practical value in real-world applications.
More visual insights#
More on tables

🔼 This table compares the performance of different kernel functions used in linear attention mechanisms within the context of vision transformers. It shows the top-1 accuracy achieved by various methods, each using a different kernel function to approximate the softmax attention. The baseline represents the standard softmax attention with quadratic complexity, while the others use linear approximations with varying kernels (ReLU, cosine similarity, mean, sigmoid & softmax, angular, 1st order Taylor expansion). The table highlights the improvement in accuracy achieved by the proposed QT-ViT method using a 2nd order Taylor expansion kernel.
read the caption
Table 2: Results of using different kernels. The baseline method uses the original self-attention operation with O(N2d) computational complexity and is used as the strong baseline. Other methods use different linear attentions.
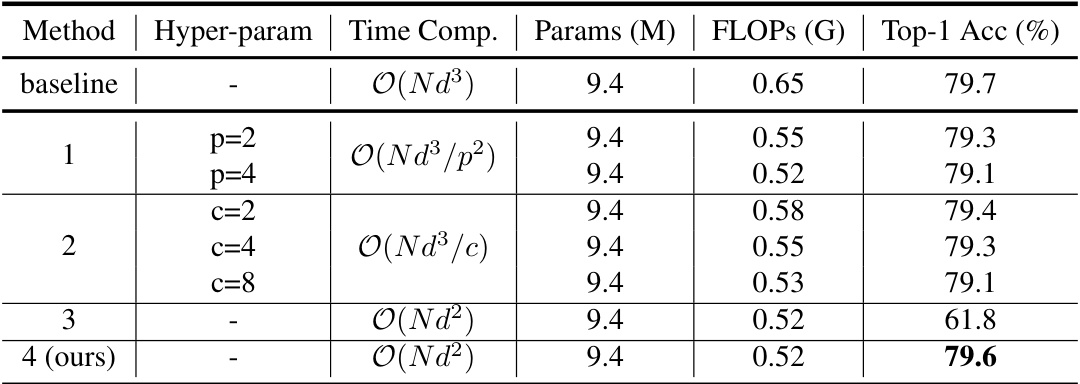
🔼 This table presents the ablation study results focusing on the impact of different methods to reduce the time complexity of the Kronecker product within the QT-ViT model. It compares different approaches, including pooling the input vector, dividing it into chunks, randomly preserving elements, and using the proposed compact version (ours), assessing their effects on computational complexity and top-1 accuracy on ImageNet-1k.
read the caption
Table 3: Ablation on reducing the time complexity of the Kronecker product. The experiments are conducted using the QT-ViT-1 model on the ImageNet-1k dataset.
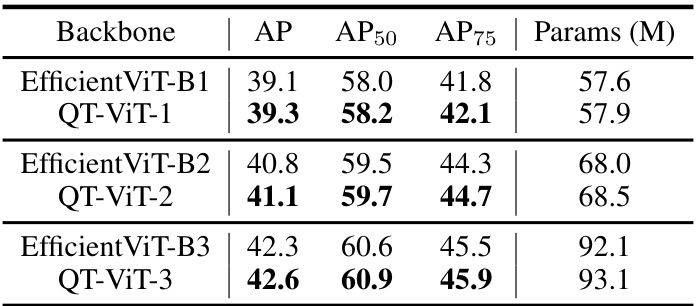
🔼 This table presents a comparison of object detection results on the COCO 2017 dataset using different backbone models. It shows the mean Average Precision (AP), AP at IoU threshold of 0.5 (AP50), AP at IoU threshold of 0.75 (AP75), and the number of parameters (in millions) for EfficientViT and QT-ViT models of varying sizes (B1, B2, B3). The results highlight the performance improvement achieved by QT-ViT compared to EfficientViT.
read the caption
Table 4: Experimental results on COCO 2017 dataset using different backbones.
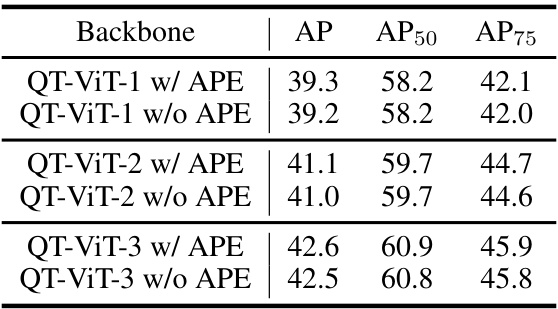
🔼 This table presents the experimental results of object detection on the COCO 2017 dataset using different backbones. It compares the performance of EfficientViT and QT-ViT models with and without absolute positional embedding (APE). The metrics used for comparison are AP (Average Precision), AP50 (Average Precision at IoU=0.5), and AP75 (Average Precision at IoU=0.75).
read the caption
Table 5: Experimental results on COCO 2017 dataset using different backbones.
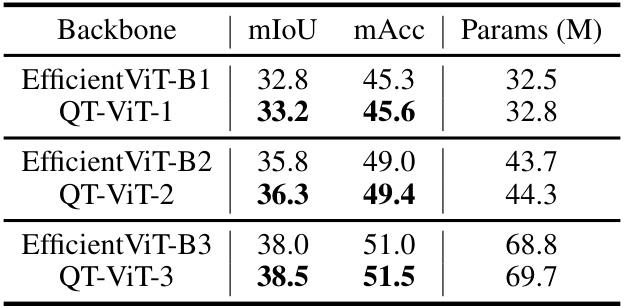
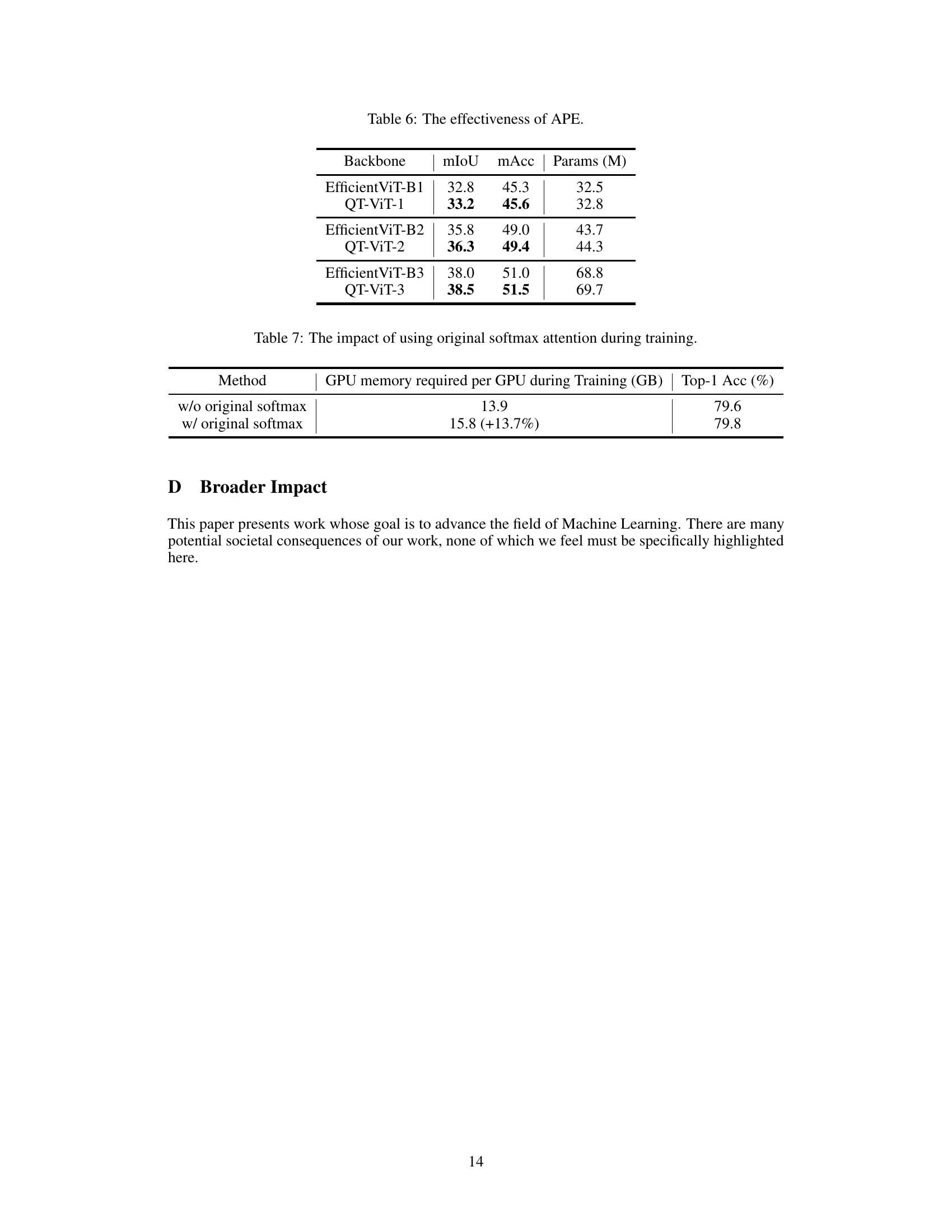
🔼 This table presents the results of adding absolute positional embedding (APE) to the QT-ViT models for the semantic segmentation task on the ADE20K dataset. It compares the performance (mIoU and mAcc) and the number of parameters of QT-ViT models with and without APE, showing that using APE improves performance.
read the caption
Table 6: The effectiveness of APE.

🔼 This table shows the impact on GPU memory usage and top-1 accuracy when using the original softmax attention during training versus not using it. The results indicate a significant increase in memory usage (13.7%) with minimal improvement in accuracy.
read the caption
Table 7: The impact of using original softmax attention during training.
Full paper#