TL;DR#
Existing knowledge graph construction methods are limited by coarse-grained approaches, failing to capture the nuances of real-world n-ary relationships and their diverse schemas. This leads to incomplete and inaccurate knowledge representation. The variable arity and order of entities in n-ary relations further complicate the construction process.
This paper introduces Text2NKG, a novel fine-grained n-ary relation extraction framework. It employs a span-tuple classification method with hetero-ordered merging and output merging to address the challenges of variable arity and entity order. Text2NKG supports four NKG schemas, showcasing its flexibility. Experimental results demonstrate that Text2NKG significantly outperforms existing methods, achieving state-of-the-art performance.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Text2NKG, a novel framework for fine-grained n-ary relation extraction, addressing limitations in current NKG construction methods. Its flexibility in handling various NKG schemas and achieving state-of-the-art performance makes it highly relevant to researchers working on knowledge graph construction and natural language processing. The work opens avenues for developing more sophisticated and accurate NKGs with broader applications.
Visual Insights#

🔼 This figure illustrates the process of constructing an N-ary Relational Knowledge Graph (NKG) from a natural language text. The text describes several facts about Albert Einstein’s life, including his education, professional positions, and the Nobel Prize he received. The figure shows how these facts are represented as interconnected n-ary relational facts within an NKG. Each n-ary fact involves multiple entities (Einstein, University of Zurich, Physics, Doctorate, Nobel Prize, etc.) and their relationships, capturing richer knowledge than simple binary relations. The different colored circles represent different n-ary facts, and their overlaps highlight the shared entities and relationships, demonstrating the interconnectedness of information within the NKG.
read the caption
Figure 1: An example of NKG construction.

🔼 This table presents the statistics of the HyperRED dataset used in the paper’s experiments. It shows the counts of entities, relations (broken down by four different schema types: hyper-relational, event-based, role-based, and hypergraph-based), sentences, and n-ary relational facts within the training, development, and test sets of the dataset. This information is crucial for understanding the scale and characteristics of the data used to evaluate the Text2NKG model.
read the caption
Table 1: Dataset statistics, where the columns indicate the number of entities, relations with four schema, sentences and n-ary relational facts in all sets, train set, dev set, and test set, respectively.
In-depth insights#
N-ary RE Framework#
An N-ary RE framework, designed for extracting n-ary relations from text, is a significant advancement in knowledge graph construction. Its core strength lies in handling the inherent complexities of real-world facts, moving beyond binary relationships to encompass the varied structures and arities present in NKGs. The framework likely employs a multi-stage process. Initially, it probably identifies and represents entities within the text using techniques like named entity recognition (NER) and/or span identification. A crucial element would be a method to classify span-tuples into appropriate n-ary relations, possibly using a multi-label classification approach or some variant of sequence labeling. This stage would need to account for the variable order of entities in an n-ary tuple and the varying number of relations involved, depending on the NKG schema used. Subsequent steps might involve merging or resolving overlapping or conflicting relations, optimizing for the schema’s specific constraints. The framework’s ability to support diverse NKG schemas, like hyper-relational, event-based, and role-based, increases its versatility and practical applicability. The overall success depends heavily on the effectiveness of the chosen classification model and the robustness of the merging strategies. Evaluation would require benchmarking against existing methods using suitable datasets with different NKG structures.
Span-tuple Classification#
Span-tuple classification, as a core component of the Text2NKG framework, presents a novel approach to fine-grained n-ary relation extraction. Instead of traditional methods that rely on fixed-arity relations, Text2NKG leverages span-tuples, which represent ordered sets of entities extracted from the text. This approach addresses the challenge of variable-arity relations in real-world scenarios, which traditional methods often struggle with. By classifying these span-tuples with multi-label classification, Text2NKG effectively captures the relationships between multiple entities in a single model. Furthermore, the method’s reliance on ordered span-tuples allows for the incorporation of semantic information related to entity order. This is crucial in scenarios where the order of entities within a relationship significantly impacts its meaning. The multi-label classification aspect enhances the model’s ability to manage complex relational structures, where a single span-tuple might be associated with multiple relation types simultaneously. This contrasts with traditional binary RE methods, which struggle with the complexity of real-world relationships. The use of packed levitated markers also significantly improves efficiency, by reducing the number of training examples required. While the technique tackles variable-arity, further investigation into how this approach generalizes to extremely long sequences or exceptionally complex relationships could provide additional insight into its limitations and strengths.
Multi-schema Adaptability#
The concept of “Multi-schema Adaptability” in the context of a research paper likely refers to a system’s or model’s capacity to function effectively across various knowledge graph schemas. This is crucial because different applications and datasets often employ different schema structures. A system lacking this adaptability would be limited in its applicability and interoperability. A truly adaptable system should seamlessly handle variations in the representation of entities and relationships, accommodating diverse ways to express the same underlying knowledge. This likely involves intelligent schema mapping, flexible data representation, and robust query mechanisms. The paper probably showcases experiments demonstrating the model’s performance across multiple schemas, evaluating its effectiveness in each scenario and comparing performance metrics. Furthermore, the paper may discuss the challenges of designing a multi-schema system, such as the computational cost of handling schema heterogeneity and potential trade-offs between adaptability and performance efficiency. Finally, a key aspect could be the ease with which the system can be adapted to new schemas, potentially highlighting features like automatic schema learning or inference.
Output Merging Method#
The Output Merging Method, as described in the research paper, is a crucial post-processing step in the Text2NKG framework, aiming to elevate the accuracy of n-ary relation extraction. It takes 3-ary relational facts, output from the hetero-ordered merging stage, and intelligently combines them to construct higher-arity (n-ary) facts. The core of this method lies in its ability to handle variable arity, meaning it can seamlessly generate n-ary relations of any number of entities without prior knowledge or predefined constraints. The approach considers various NKG schemas (hyper-relational, event-based, role-based, and hypergraph-based) and dynamically merges facts that share common entities and relations, according to each schema’s structure. This unsupervised learning technique is especially important because real-world knowledge often exhibits variable entity interactions. The method’s capacity to unify disparate facts into cohesive, higher-arity relationships greatly improves the expressiveness and accuracy of the constructed NKG. This results in a more complete and accurate representation of the underlying knowledge, ultimately contributing to enhanced performance in downstream NKG applications.
Future Research#
Future research directions stemming from this paper could explore several key areas. First, extending Text2NKG’s capabilities to handle longer contexts and relations spanning multiple sentences is crucial. Current limitations on sequence length restrict applicability to larger documents. Investigating techniques like hierarchical attention mechanisms or advanced transformer models designed for long sequences would be valuable. Second, integrating unsupervised methods, such as large language models, to improve data efficiency and reduce reliance on labeled data, is a promising direction. Combining the strengths of supervised and unsupervised approaches might boost performance, particularly in low-resource scenarios. Third, the current work primarily focuses on four NKG schemas. Enhancing Text2NKG to support a wider range of schemas and adapt more flexibly to diverse data formats would significantly broaden its utility. Finally, rigorous evaluations on more diverse benchmark datasets are essential to thoroughly assess the robustness and generalization ability of Text2NKG. A comprehensive evaluation across different domains, languages, and levels of noise would increase confidence in its effectiveness. Furthermore, exploring applications in specific real-world scenarios, such as event extraction and question answering systems, would demonstrate Text2NKG’s practical value and identify areas needing further refinement.
More visual insights#
More on figures
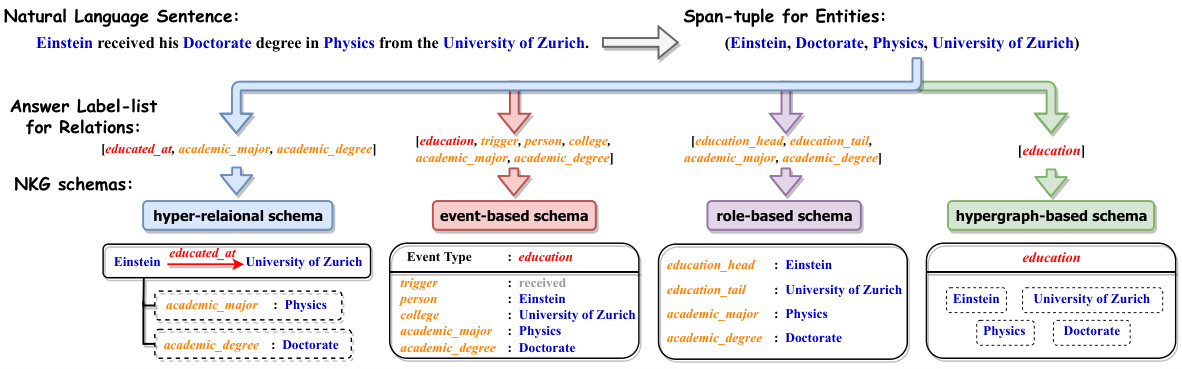
🔼 This figure illustrates the process of extracting a four-arity relational fact from a sentence. It shows how a sentence, ‘Einstein received his Doctorate degree in Physics from the University of Zurich.’ is processed. First, a span-tuple of entities is identified: (Einstein, University of Zurich, Doctorate, Physics). Then, based on the identified entities and the sentence’s meaning, a list of relations is generated: [educated_at, academic_major, academic_degree]. Finally, these entities and relations are combined to form a four-arity relational fact in different NKG schemas (hyper-relational, event-based, role-based, hypergraph-based), demonstrating how the system handles varied schema representations of the same underlying information.
read the caption
Figure 2: Taking a real-world textual fact as an example, we can extract a four-arity structured span-tuple for entities (Einstein, University of Zurich, Doctorate, Physics) with an answer label-list for relations accordingly as a 4-ary relational fact from the sentence through n-ary relation extraction.
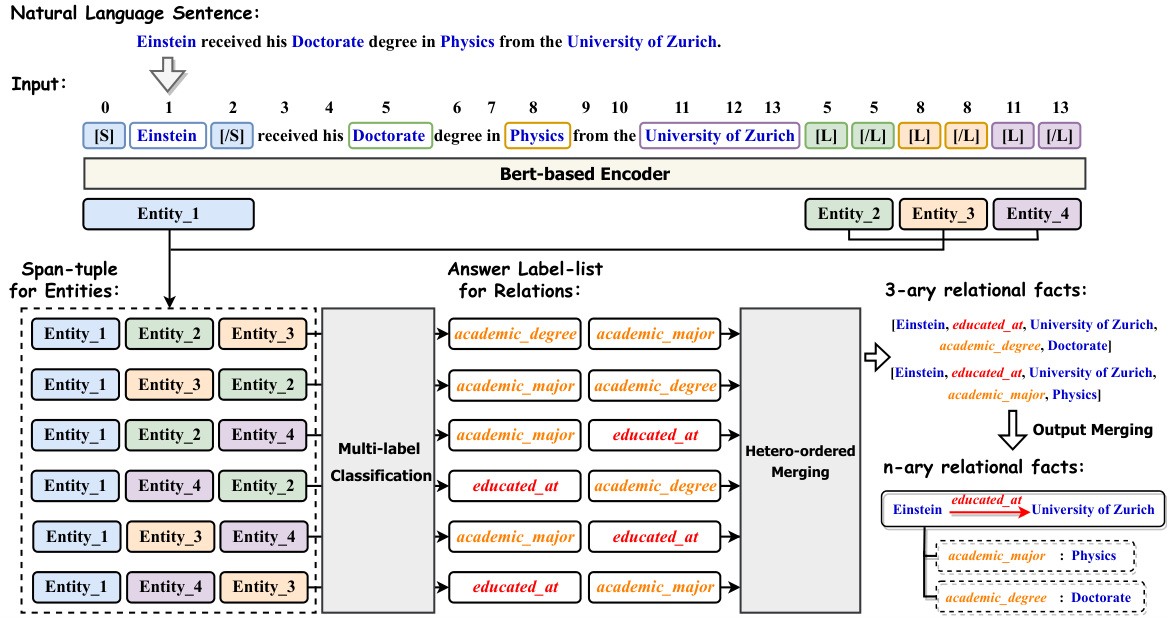
🔼 This figure illustrates the Text2NKG framework’s process of extracting n-ary relation facts from a sample sentence. It begins by inputting a sentence, then performs entity recognition, and creates span-tuples representing various entity combinations. A BERT-based encoder processes these tuples, feeding the information into a multi-label classification step to predict relations between entities. Hetero-ordered merging refines these predictions, and output merging combines 3-ary relations into higher-arity ones. The example shown focuses on the hyper-relational schema of NKGs.
read the caption
Figure 3: An overview of Text2NKG extracting n-ary relation facts from a natural language sentence in hyper-relational NKG schema for an example.

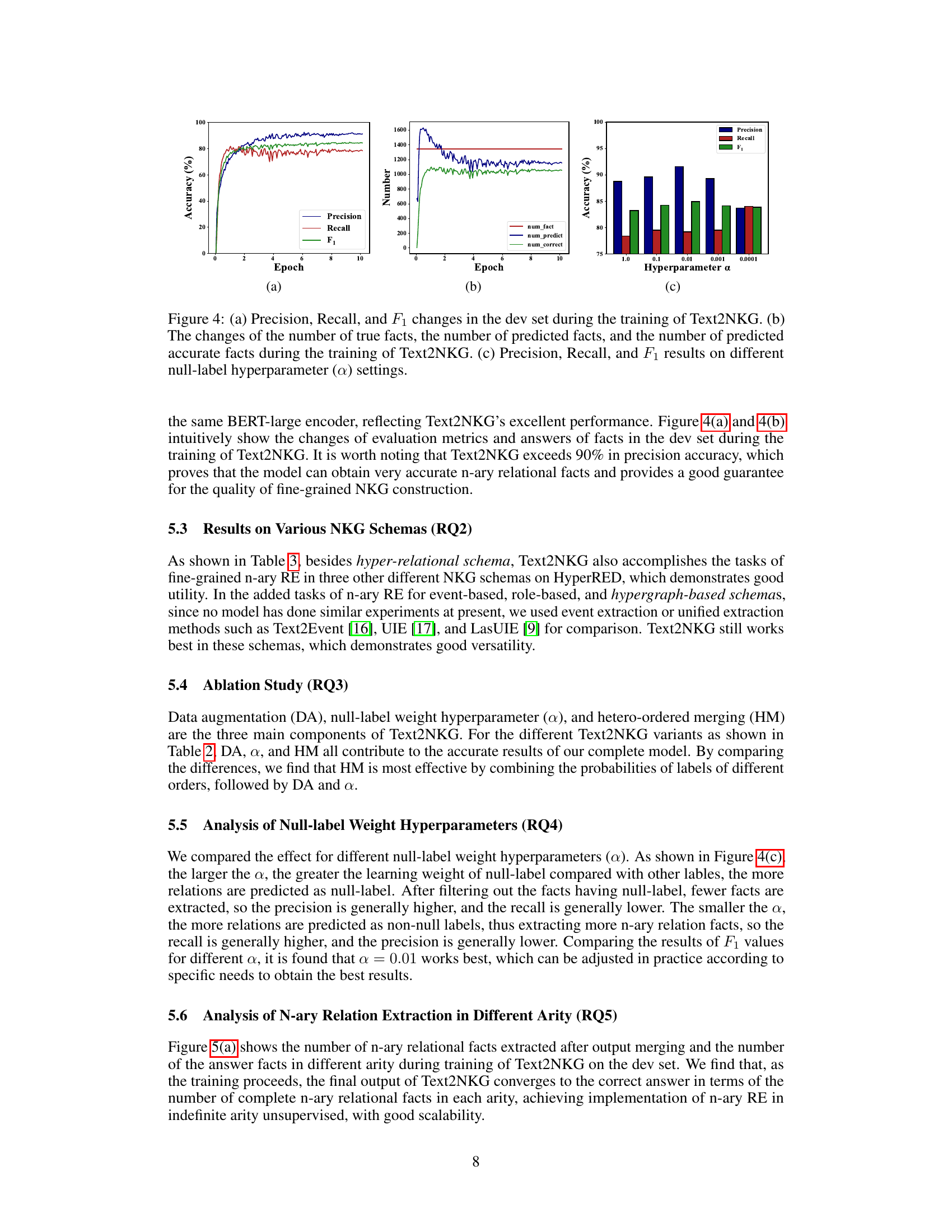
🔼 This figure shows three plots illustrating different aspects of the Text2NKG model’s performance during training and how it is affected by hyperparameter α. Plot (a) displays the precision, recall, and F1-score on the development set over training epochs. Plot (b) shows the number of true facts, predicted facts, and correctly predicted facts over epochs. Plot (c) demonstrates how precision, recall, and F1-score vary with different α values.
read the caption
Figure 4: (a) Precision, Recall, and F₁ changes in the dev set during the training of Text2NKG. (b) The changes of the number of true facts, the number of predicted facts, and the number of predicted accurate facts during the training of Text2NKG. (c) Precision, Recall, and F₁ results on different null-label hyperparameter (α) settings.

🔼 Figure 5(a) is a graph showing the number of n-ary relations extracted by Text2NKG during training, broken down by arity (number of entities involved). It compares the number of predicted relations (‘pred_n’) against the actual number of relations (‘ans_n’) in the ground truth dataset, across different epochs of training. Figure 5(b) provides a concrete example of how Text2NKG extracts n-ary relational facts from a sample sentence. It shows how a single sentence is processed to generate n-ary relational facts according to four different knowledge graph schemas (hyper-relational, event-based, role-based, and hypergraph-based).
read the caption
Figure 5: (a) The changes of the number of extracted n-ary RE in different arity, where 'pred_n' represents the number of extracted n-ary facts with different arities by Text2NKG, and 'ans_n' represents the ground truth. (b) Case study of Text2NKG's n-ary relation extraction in four schemas on HyperRED.
More on tables
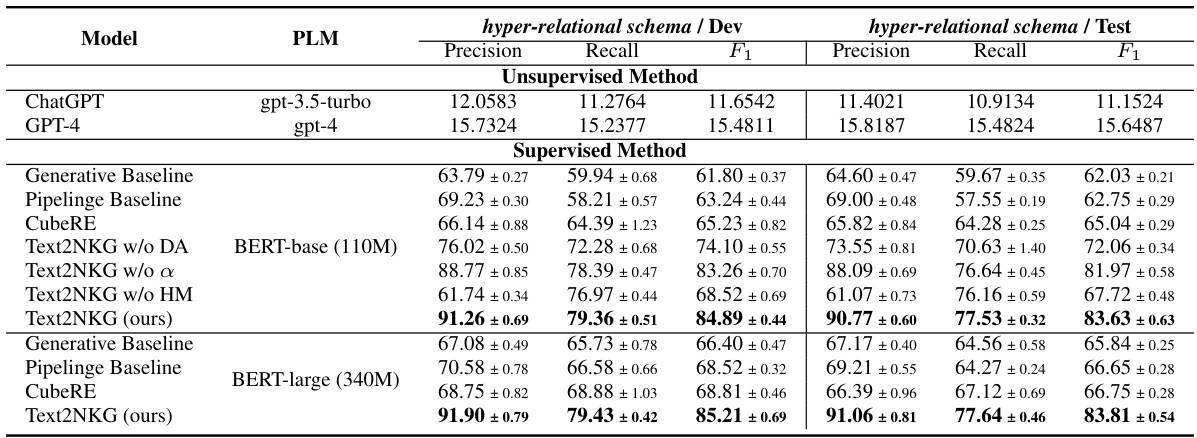
🔼 This table presents a comparison of the Text2NKG model’s performance against other baseline models on the hyper-relational extraction task using the HyperRED dataset. It shows precision, recall, and F1 scores for both unsupervised and supervised methods. The best-performing model in each metric is highlighted in bold.
read the caption
Table 2: Comparison of Text2NKG with other baselines in the hyper-relational extraction on HyperRED. Results of the supervised baseline models are mainly taken from the original paper [5]. The best results in each metric are in bold.
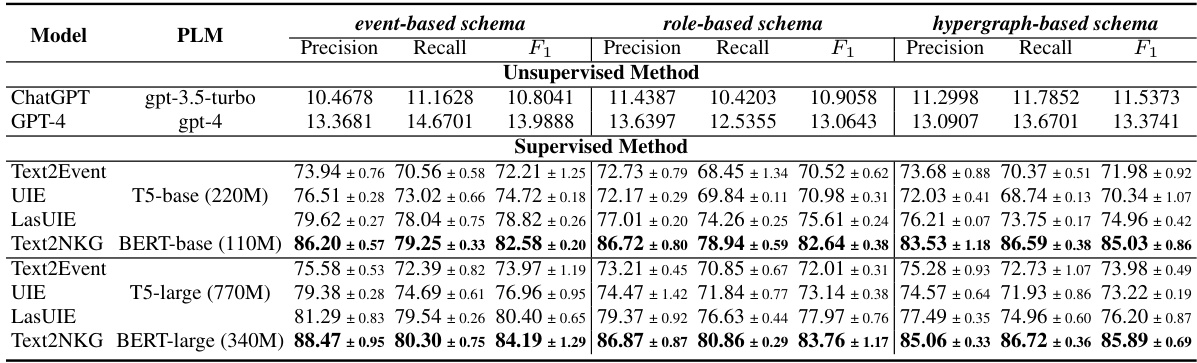
🔼 This table presents a comparison of the Text2NKG model’s performance against other baselines on three different NKG schemas: event-based, role-based, and hypergraph-based. The results are shown for both precision, recall, and F1-score metrics, offering a comprehensive evaluation of Text2NKG’s adaptability across various schema types. The best-performing model in each metric is highlighted in bold.
read the caption
Table 3: Comparison of Text2NKG with other baselines in the n-ary RE in event-based, role-based, and hypergraph-based schemas on HyperRED. The best results in each metric are in bold.

🔼 This table presents the statistics of the HyperRED dataset used in the paper’s experiments. It shows the number of entities, the number of relations categorized across four different NKG schemas (hyper-relational, event-based, role-based, and hypergraph-based), and the number of sentences and n-ary relational facts in the training, development, and test sets. This information is crucial for understanding the scale and characteristics of the data used for evaluating the performance of the proposed Text2NKG model.
read the caption
Table 1: Dataset statistics, where the columns indicate the number of entities, relations with four schema, sentences and n-ary relational facts in all sets, train set, dev set, and test set, respectively.
Full paper#