↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-Language Navigation (VLN) systems guide agents through environments using textual instructions. Current approaches rely on supervised learning, often accumulating errors and struggling to generalize well. This limitation stems from solely focusing on conditional action distributions and neglecting the inherent complexities of the Markov decision process.
This paper introduces Energy-based Navigation Policy (ENP), a novel method that models the joint state-action distribution using an energy-based model. By maximizing the likelihood of expert actions and modeling navigation dynamics, ENP globally aligns with expert policies. Results show significant performance improvements on standard VLN benchmarks, surpassing existing methods across different architectures. The ENP approach provides a robust and generalizable solution to VLN, overcoming the challenges of error accumulation and distribution mismatch in traditional methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel Energy-based Navigation Policy (ENP) for Vision-Language Navigation (VLN), significantly improving performance on various benchmarks. It offers a fresh perspective on existing limitations and opens doors for future research using energy-based methods within VLN and beyond.
Visual Insights#
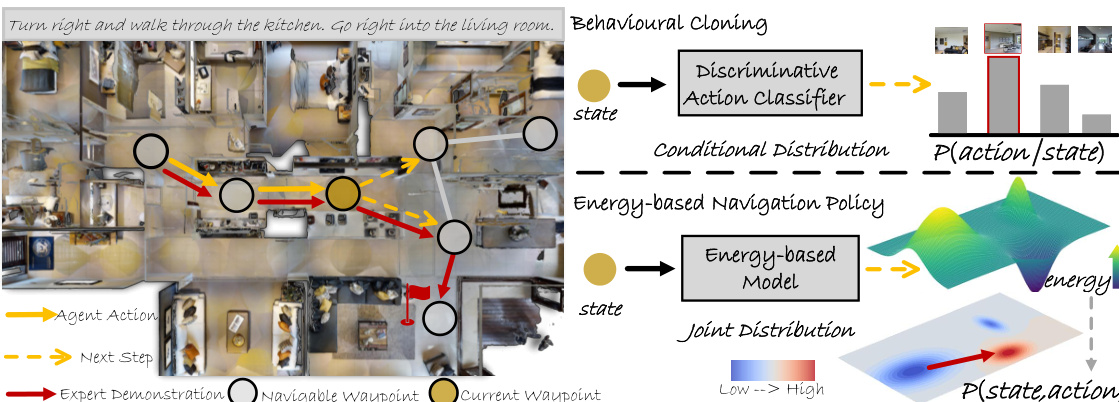
This figure compares the behavioral cloning (BC) method and the proposed Energy-based Navigation Policy (ENP) for Vision-Language Navigation (VLN). BC directly optimizes the conditional action distribution, meaning it learns to predict the next action given the current state. ENP, on the other hand, models the joint state-action distribution using an energy-based model. In ENP, low energy values represent state-action pairs the expert is most likely to take, while high energy values indicate less likely pairs. This allows ENP to capture the global relationship between states and actions, leading to a more robust and generalizable policy.
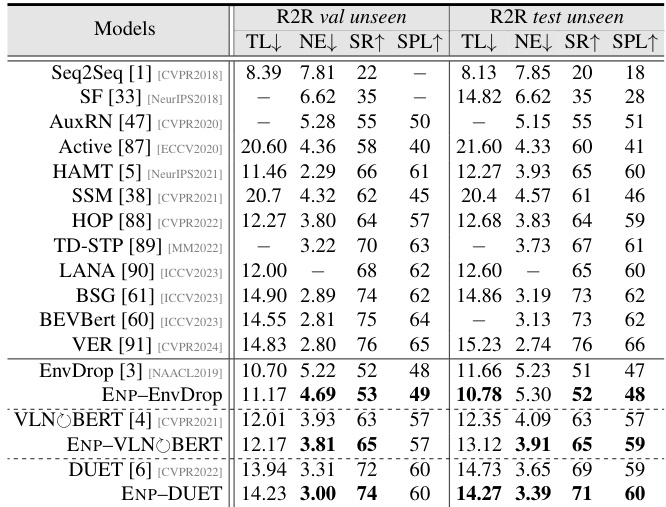
This table presents a quantitative comparison of the proposed Energy-based Navigation Policy (ENP) with several state-of-the-art methods on the R2R benchmark. It shows the performance of different models using various metrics, such as Success Rate (SR), Success Rate weighted by Path Length (SPL), Trajectory Length (TL), and Navigation Error (NE). The results are broken down for the validation (unseen) and test (unseen) splits of the dataset, illustrating the generalization capabilities of each model.
In-depth insights#
Energy-Based VLN#
Energy-based Vision-Language Navigation (VLN) offers a novel approach to address limitations of traditional VLN methods. Instead of directly optimizing the conditional action distribution, as done in behavioral cloning, energy-based models learn the joint state-action distribution. This allows for a more global understanding of the expert policy, capturing the underlying dynamics of navigation and reducing the accumulation of errors inherent in sequential decision-making. By assigning low energy values to state-action pairs frequently selected by the expert, the model implicitly learns to prioritize likely actions in different navigation contexts. Theoretically, this is equivalent to minimizing the divergence between the agent’s and expert’s occupancy measures, providing a principled way to match the expert’s behavior. This framework is flexible, easily adaptable to diverse VLN architectures, and demonstrates improved performance across various benchmarks, showcasing the potential for energy-based methods to significantly enhance the performance of existing VLN models.
ENP Framework#
The Energy-Based Navigation Policy (ENP) framework offers a novel approach to vision-language navigation (VLN) by modeling the joint state-action distribution using an energy-based model. Unlike traditional methods that focus on conditional action distributions, ENP captures the global alignment with expert policy by maximizing the likelihood of actions and modeling navigation state dynamics. This addresses the accumulation of errors in Markov Decision Processes, a common issue in VLN. Low energy values represent state-action pairs frequently performed by experts, guiding the learning process towards a more robust and generalizable policy. The theoretical equivalence to minimizing forward divergence between expert and agent occupancy measures ensures a closer alignment to expert behavior. Furthermore, ENP’s flexibility allows for adaptation to diverse VLN architectures, enhancing the performance of existing models across various benchmarks.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In vision-language navigation (VLN), this might involve removing modules like the language encoder, visual encoder, or attention mechanism. By observing performance drops after removing each component, researchers can pinpoint critical parts of the model and identify areas for improvement. For example, a significant performance decrease after removing the attention mechanism suggests that effectively aligning visual and linguistic information is crucial for successful navigation. Conversely, a minimal performance change indicates a less critical role, perhaps suggesting areas of redundancy or potential simplification. These insights reveal critical architectural features essential for VLN and guide future model development, focusing on improving the crucial components while streamlining less impactful ones. Furthermore, ablation studies help evaluate the relative importance of different model aspects, offering a quantitative understanding of model design choices. This detailed analysis provides insights into design choices and guides future efforts to optimize model performance and efficiency.
Continuous VLN#
Continuous Vision-Language Navigation (VLN) presents a significant advancement over discrete VLN by enabling agents to navigate in truly continuous environments, removing the constraints of pre-defined navigation graphs. This allows for more realistic and challenging scenarios, better reflecting real-world navigation tasks. The shift to continuous space necessitates new approaches to action representation and policy learning. Instead of discrete actions (e.g., move forward, turn left), continuous VLN requires modeling actions as continuous control signals, such as speed and steering angle. This shift also impacts reward design, as it must be appropriately defined in a continuous space to effectively guide the agent’s learning. Furthermore, efficient exploration techniques become crucial in continuous domains to handle the vast state space. Research in continuous VLN often leverages advanced deep reinforcement learning methods, potentially incorporating techniques such as model-predictive control, to tackle the complexity and achieve robust navigation performance.
Future Work#
The authors mention exploring the Energy-based Navigation Policy (ENP) on more VLN architectures and tasks, highlighting the need to verify its generalizability. They also acknowledge the challenge of efficiently sampling from high-dimensional, unnormalized distributions, suggesting future exploration of MCMC-free methods and neural implicit samplers. Improving the training efficiency of ENP by addressing the computational cost of the SGLD inner loop is another area for improvement. A key direction is enabling agents to actively acquire skills through observation, similar to humans, potentially reducing the reliance on large amounts of expert demonstration data. Finally, they encourage further research into mitigating the risks of collisions and enhancing navigation safety in real-world scenarios, emphasizing the importance of collision avoidance and robust navigation techniques. The overall goal is to extend the energy-based policy to various real-world scenarios and improve upon the existing limitations of VLN agents.
More visual insights#
More on figures
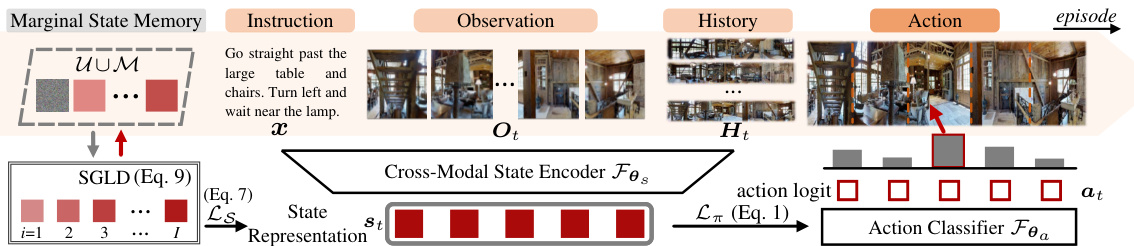
The figure illustrates the Energy-based Navigation Policy (ENP) framework. It shows how, at each time step, the agent takes in an instruction, current observation, and past navigation history. This information is processed by a cross-modal state encoder to produce a state representation. This representation is then used by an action classifier to predict the next action. Critically, ENP incorporates a marginal state memory and uses Stochastic Gradient Langevin Dynamics (SGLD) to optimize both the cross-entropy loss of the action prediction and a marginal state matching loss, ensuring alignment with the expert’s navigation policy.

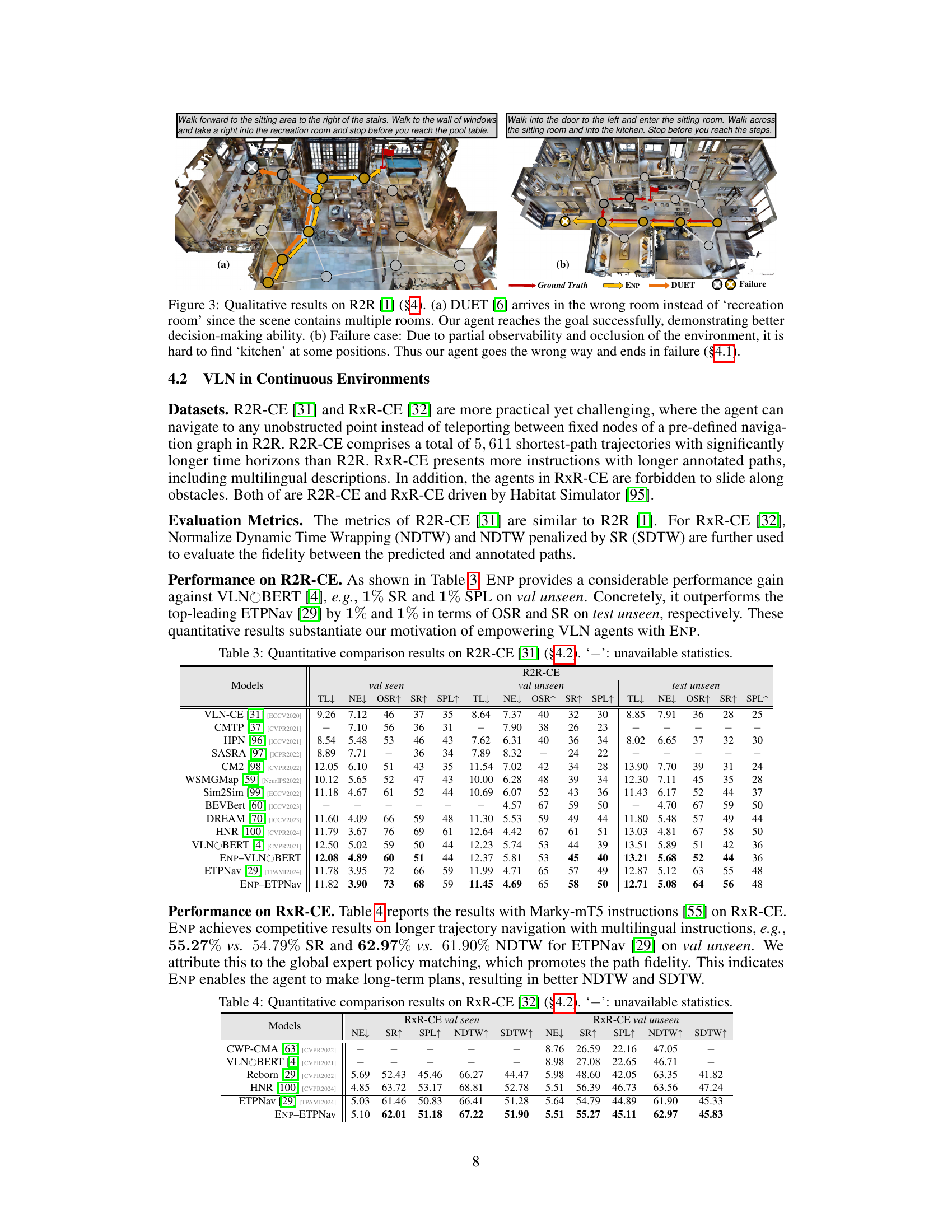
This figure compares the qualitative results of the proposed Energy-based Navigation Policy (ENP) and the existing DUET method on the R2R benchmark. Two examples are shown. In (a), DUET fails to reach the correct room, while ENP successfully navigates to the goal, highlighting ENP’s improved decision-making abilities. In (b), both methods fail because of partial observability and occlusion in the environment; this emphasizes the challenges of VLN.

This figure illustrates the Energy-based Navigation Policy (ENP) framework. The agent receives an instruction, observes the environment, and uses its history to predict its next action. The ENP model learns by optimizing both a cross-entropy loss (L1) and a marginal state matching loss (Ls) using Stochastic Gradient Langevin Dynamics (SGLD) sampling and a marginal state memory to improve sampling efficiency. This contrasts with previous methods that only focus on the conditional action distribution.
More on tables
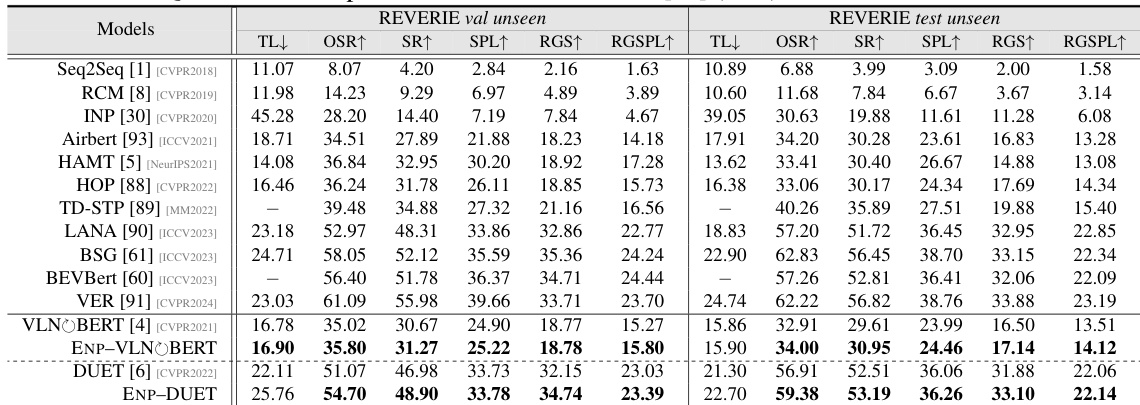
This table presents a quantitative comparison of the proposed Energy-based Navigation Policy (ENP) method against other state-of-the-art methods on the REVERIE dataset. It shows the performance of different models across various metrics, including Trajectory Length (TL), Oracle Success Rate (OSR), Success Rate (SR), Success Rate weighted by Path Length (SPL), Remote Grounding Success rate (RGS), and Remote Grounding Success weighted by Path Length (RGSPL). The results are broken down for both the validation unseen and test unseen sets, illustrating the generalization ability of the models.
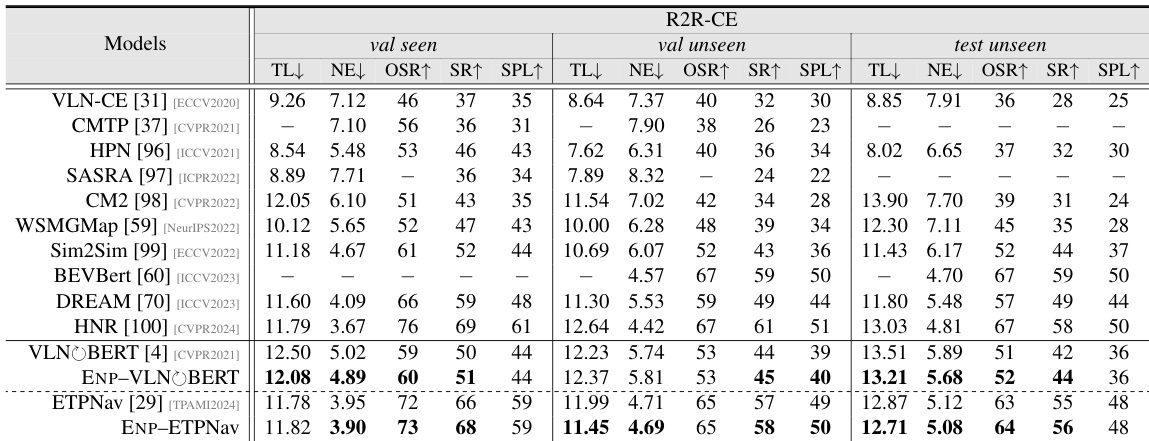
This table presents a quantitative comparison of the proposed Energy-based Navigation Policy (ENP) method with several existing state-of-the-art Vision-Language Navigation (VLN) models on the R2R-CE benchmark. It shows the performance of each method across different metrics (TL: Trajectory Length, NE: Navigation Error, OSR: Oracle Success Rate, SR: Success Rate, SPL: Success Rate weighted by Path Length) for three different splits of the dataset (val seen, val unseen, test unseen). The results demonstrate the improvement achieved by incorporating ENP.
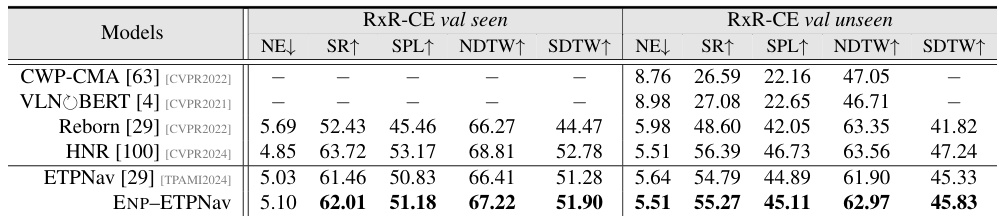
This table presents a quantitative comparison of different models’ performance on the RxR-CE benchmark. The metrics used are Navigation Error (NE), Success Rate (SR), Success rate weighted by Path Length (SPL), Normalized Dynamic Time Wrapping (NDTW), and NDTW penalized by SR (SDTW). Lower NE is better, while higher values for SR, SPL, NDTW, and SDTW are preferred. The table compares the performance of several models, including ENP-ETPNav (the proposed model in this paper), on both seen and unseen splits of the RxR-CE dataset, providing a comprehensive comparison.

This ablation study investigates the impact of using only the discriminative action loss (Lπ) versus using both the discriminative action loss and the marginal state distribution matching loss (Lπ + Ls) on the performance of the Energy-based Navigation Policy (ENP) model. Results are shown for two different VLN architectures, VLNOBERT and DUET&ETPNav, on the R2R and R2R-CE validation sets. Success Rate (SR) and Success Rate weighted by Path Length (SPL) are used to evaluate performance.

This table presents an ablation study on the effect of step size and Gaussian noise in the Stochastic Gradient Langevin Dynamics (SGLD) sampler used in the Energy-based Navigation Policy (ENP) framework. The study investigates the impact of different step sizes (€) and noise variances (Var(ξ)) on the performance of the ENP model for two different VLN datasets: R2R and R2R-CE. The results show the sensitivity or insensitivity of the model to changes in these hyperparameters.
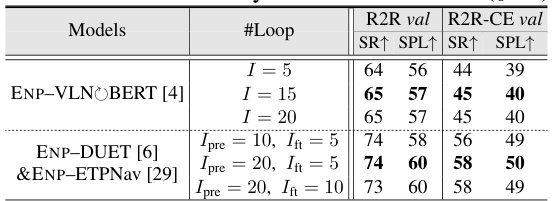
This table presents the ablation study on the number of SGLD (Stochastic Gradient Langevin Dynamics) iterations performed per training step. It shows how the Success Rate (SR) and Success Rate weighted by Path Length (SPL) metrics are affected by varying the number of iterations (I, Ipre, Ifit) for different VLN models on R2R and R2R-CE datasets.
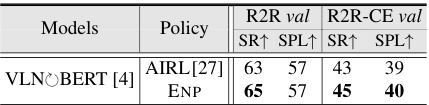
This table compares the performance of ENP and AIRL on VLNOBERT [4] architecture for R2R and R2R-CE datasets. It shows success rate (SR) and success rate weighted by path length (SPL) for both validation sets. The results indicate that ENP outperforms AIRL on both datasets.
Full paper#