↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
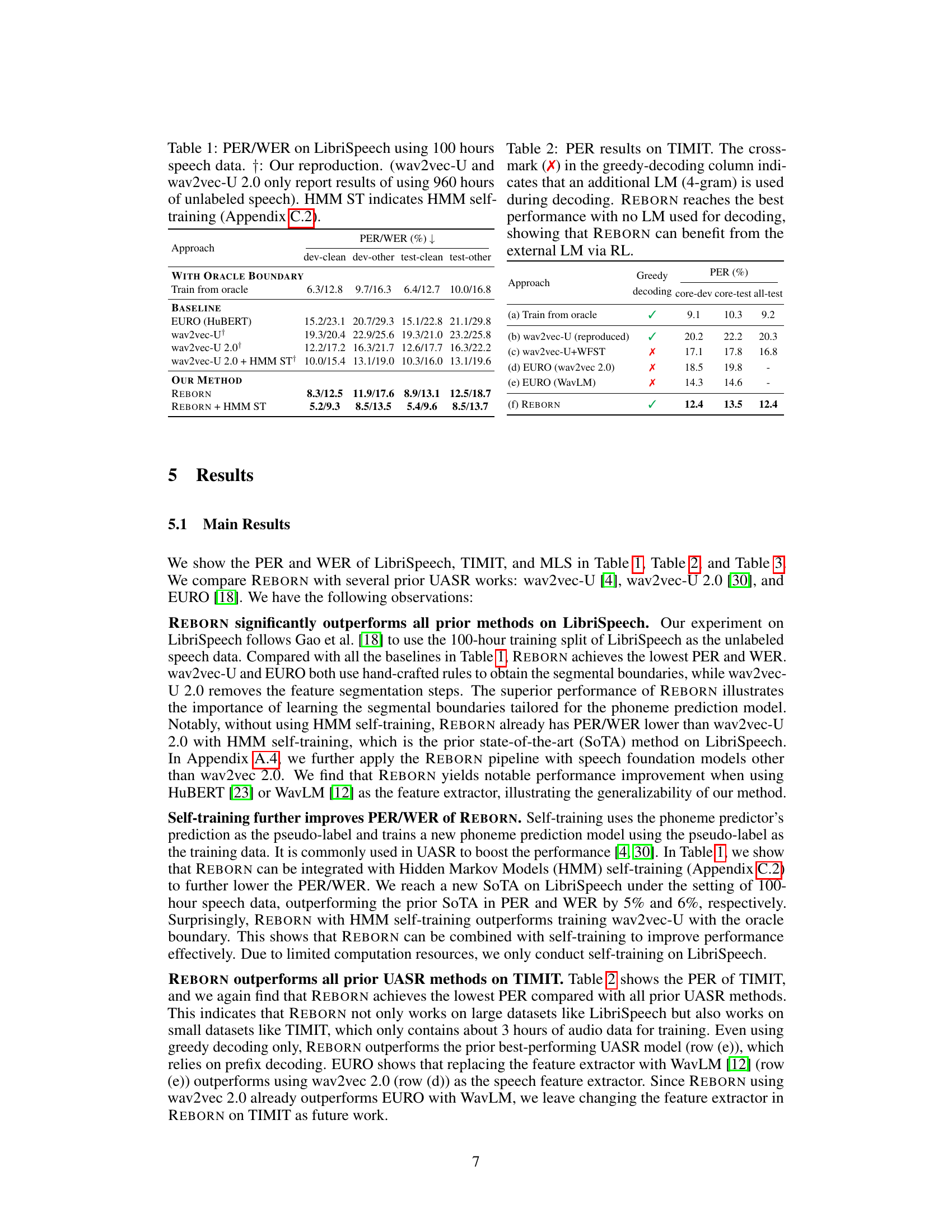
TL;DR#
Unsupervised Automatic Speech Recognition (ASR) struggles with the variable length and unknown boundaries of speech segments, especially without paired speech-text data. Existing methods often rely on handcrafted rules or separately learned modules for boundary detection, limiting performance. This paper introduces REBORN, a novel approach that addresses this by iteratively training a segmentation model (using reinforcement learning) and a phoneme prediction model. The segmentation model is trained to favor segmentations that improve the phoneme prediction model’s performance (lower perplexity). REBORN significantly improves the state-of-the-art in unsupervised ASR performance across various datasets and languages.
REBORN’s iterative training effectively refines both the segmentation and prediction models, leading to more accurate transcriptions. By analyzing the learned segmental boundaries, the researchers found that these are smaller than phonemes, which enhances the accuracy of the phoneme predictions. This method also offers robustness and generalizability, outperforming existing methods regardless of the underlying speech foundation model used. The improved accuracy and efficiency hold considerable promise for advancing unsupervised ASR, especially in low-resource scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents REBORN, a novel approach to unsupervised automatic speech recognition (ASR) that significantly outperforms existing methods. It tackles the challenging problem of segmenting speech signals without labeled data, paving the way for more accessible ASR in low-resource languages. The iterative training and reinforcement learning techniques used are significant advancements in the field, and the results open new avenues for research in unsupervised representation learning and cross-modality distribution matching.
Visual Insights#
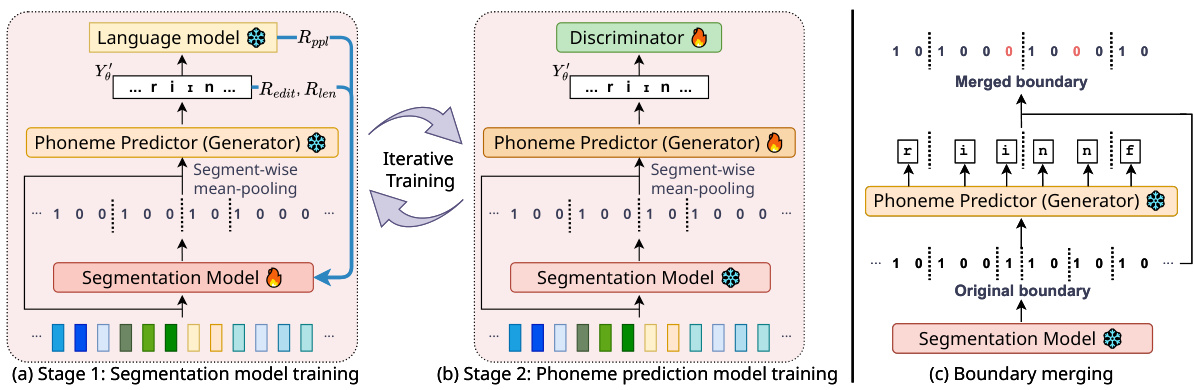
🔼 This figure illustrates the iterative training process of REBORN. (a) shows the training of the segmentation model using reinforcement learning (RL) to learn better segment boundaries. The reward function guides the model towards segmentations that result in lower perplexity phoneme predictions. (b) illustrates the training of the phoneme prediction model using adversarial training (GAN). The phoneme predictor takes the speech features, segmented by the segmentation model, as input and outputs a phoneme transcription. (c) depicts the boundary merging step. Segments with identical phoneme predictions are merged to create more coherent segmental structures. This iterative process refines both the segmentation and phoneme prediction models, ultimately improving the overall unsupervised ASR performance.
read the caption
Figure 1: (a) and (b): REBORN iterates between using RL to train the segmentation model and using adversarial training to train the phoneme prediction model. (c): An illustration of the segmentation/boundary merging. 1 means the start of a segment while 0 is not. Given the original segmentation and the predicted phoneme sequence, we merge the segments that result in the same phoneme prediction into the same segment, yielding the merged boundary.
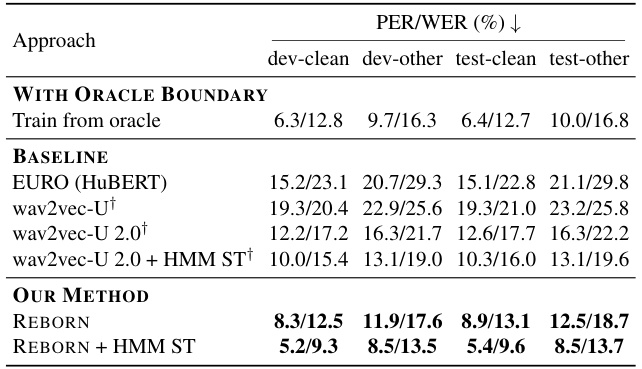
🔼 This table presents the Phoneme Error Rate (PER) and Word Error Rate (WER) for different unsupervised automatic speech recognition (ASR) models on the LibriSpeech dataset using 100 hours of speech data. It compares REBORN’s performance against several baseline models, including wav2vec-U, wav2vec-U 2.0, and EURO, both with and without HMM self-training. The results showcase REBORN’s superior performance compared to existing methods.
read the caption
Table 1: PER/WER on LibriSpeech using 100 hours speech data. †: Our reproduction. (wav2vec-U and wav2vec-U 2.0 only report results of using 960 hours of unlabeled speech). HMM ST indicates HMM self-training (Appendix C.2).
In-depth insights#
Iterative Training#
The concept of “Iterative Training” in the context of unsupervised Automatic Speech Recognition (ASR) involves a cyclical refinement process. The core idea is to alternate between training a segmentation model (which identifies boundaries within the speech signal) and a phoneme prediction model (which maps segments to phonemes). The segmentation model learns to produce segmentations that lead to improved phoneme predictions, evaluated using metrics such as perplexity. This iterative approach, unlike single-stage methods, allows for continuous improvement and overcomes the limitations of fixed, pre-defined segmentation strategies. Reinforcement learning is often employed to train the segmentation model, due to the lack of labeled data for direct supervised training, rewarding better segmentations by their contribution to a lower perplexity score in the following phoneme prediction stage. This iterative refinement, therefore, creates a feedback loop where the improved segmentation leads to better phoneme prediction, which subsequently guides further refinement of the segmentation process, producing more accurate and robust unsupervised ASR models.
Boundary Learning#
Boundary learning in the context of speech recognition is a crucial, yet challenging, task. It focuses on accurately identifying the boundaries separating distinct units within a continuous speech signal, such as phonemes or words. The difficulty arises from the inherent variability in speech, with boundaries often being ambiguous and context-dependent. Effective boundary learning methods are essential for accurate speech transcription. Reinforcement learning (RL) has shown promise, allowing the system to learn optimal segmentations by maximizing a reward function related to the accuracy of subsequent phoneme prediction. Iterative training schemes are also valuable, refining both the boundary segmentation and the phoneme prediction models concurrently to achieve better overall performance. The choice of feature representation and the type of segmentation model employed significantly impact the effectiveness of boundary learning, underscoring the importance of selecting suitable components for the specific speech recognition task. Finally, careful consideration of evaluation metrics is vital, as standard metrics may not fully capture the nuances of accurate boundary identification.
Reward Design#
Reward design in reinforcement learning (RL) for unsupervised speech recognition is crucial because it directly influences the segmentation model’s learning. The effectiveness hinges on how well the reward function guides the model toward segmentations that improve phoneme prediction accuracy. This paper cleverly uses a weighted sum of three components: perplexity difference, aiming for lower perplexity in predicted phoneme sequences; edit distance, encouraging similarity to previous segmentations; and length difference, preventing drastic length changes between iterations. The interplay of these rewards is key—perplexity difference alone could lead to unnatural segmentations; the other two offer regularization to maintain reasonable phoneme sequences and prevent drastic deviations between iterations. Iterative refinement using these rewards is essential, as each iteration improves the phoneme model, leading to more informative rewards for the segmentation model. Behavior cloning helps initialize the segmentation model, providing a solid starting point for RL training. The thoughtful combination of different reward types with iterative training and smart initialization creates a robust and effective approach.
UASR Advances#
Recent advances in unsupervised automatic speech recognition (UASR) have focused on overcoming the limitations of traditional methods. Significant progress has been made in areas like feature extraction, leveraging self-supervised learning techniques to extract richer representations from unlabeled speech data. New model architectures such as generative adversarial networks (GANs) and reinforcement learning (RL) methods have shown promise in capturing the complex mapping between speech signals and textual transcriptions without paired data. Iterative training schemes, alternating between segmentation and phoneme prediction models, have proven effective in refining model parameters and improving accuracy. The use of larger, multilingual datasets is also enabling the development of more robust models capable of handling diverse speech characteristics. While these advancements are promising, challenges remain in handling noisy speech, speaker variations, and low-resource languages. Future research will likely explore more sophisticated boundary segmentation strategies, advanced reward functions in RL approaches, and improved techniques for incorporating language modeling into the UASR pipeline. Furthermore, developing benchmark datasets and evaluation metrics tailored to UASR will facilitate unbiased comparisons across different systems and contribute towards faster development.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending REBORN to handle noisy speech and low-resource languages is crucial for broader real-world applicability. Investigating alternative reward functions and training strategies within the reinforcement learning framework could further enhance performance and stability. A comprehensive comparison against other unsupervised ASR models on a wider range of datasets and languages would solidify the generalizability claims. Furthermore, exploring the integration of REBORN with other speech processing techniques, such as speaker diarization and language modeling, could yield significant improvements. Analyzing the learned segmental boundaries in more detail, possibly correlating them with linguistic units, could provide valuable insights into the underlying mechanisms. Finally, investigating the scalability of REBORN to larger datasets and more complex languages is essential for assessing its potential for practical deployment.
More visual insights#
More on figures

🔼 This figure shows the phoneme error rate (PER) on the LibriSpeech test-clean set over training epochs. Two lines are plotted: one for a segmentation model that was pre-trained using behavior cloning (BC) and one trained from scratch. The BC pre-trained model shows faster convergence to a lower PER, indicating that the behavior cloning step significantly improves the performance of the segmentation model.
read the caption
Figure 2: PER across training epochs on the test-clean split of LibriSpeech. BC pretraining speeds up convergence and raises performance.

🔼 This figure shows the phoneme error rate (PER) at different stages of the REBORN model training process on the LibriSpeech test-clean dataset. The x-axis represents the different stages (initialization with wav2vec-U, then iterative training of segmentation model and phoneme prediction model), and the y-axis shows the PER. The figure shows a significant decrease in PER after the first iteration of training, and further improvement with each subsequent iteration, indicating the effectiveness of the iterative training approach.
read the caption
Figure 3: PER of each stage during REBORN's two-stage iterative training on the test-clean split of LibriSpeech. St.: stage; w2vu: wav2vec-U.
More on tables

🔼 This table presents the Phoneme Error Rate (PER) results on the TIMIT dataset for different approaches. It compares the performance of REBORN against several baseline methods, including using oracle boundaries, wav2vec-U with and without WFST decoding, and EURO with different feature extractors. The table highlights that REBORN achieves the lowest PER, even without using a language model (LM) during decoding. This indicates that REBORN effectively learns to leverage the language model’s information implicitly through the reinforcement learning process.
read the caption
Table 2: PER results on TIMIT. The cross-mark (X) in the greedy-decoding column indicates that an additional LM (4-gram) is used during decoding. REBORN reaches the best performance with no LM used for decoding, showing that REBORN can benefit from the external LM via RL.
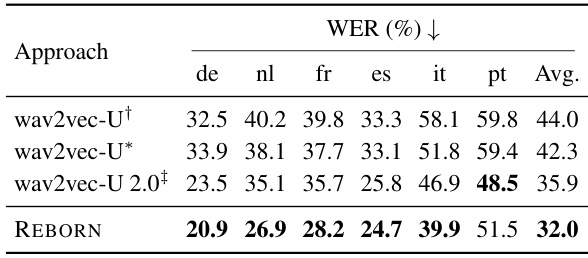
🔼 This table compares the Word Error Rate (WER) achieved by different unsupervised Automatic Speech Recognition (ASR) models on the Multilingual LibriSpeech (MLS) dataset. The models compared include wav2vec-U (with and without the authors’ reproduction), wav2vec-U 2.0, and the proposed REBORN model. WER is reported for six different languages within MLS (de, nl, fr, es, it, pt) as well as the average WER across all languages. The table highlights REBORN’s improved performance compared to previous state-of-the-art methods.
read the caption
Table 3: WER on MLS. †: Results from Baevski et al. [4]. *: Our reproduction of wav2vec-U, used as the initialization of the phoneme prediction model in REBORN. ‡: Results from Liu et al. [30].
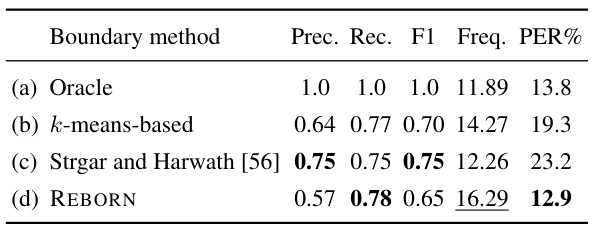
🔼 This table compares the performance of four different boundary segmentation methods on the LibriSpeech test-clean dataset. The methods are: Oracle (ground truth), k-means-based (from wav2vec-U), Strgar and Harwath (a state-of-the-art unsupervised method), and REBORN. The table shows precision, recall, F1-score, frequency (segments per second), and phoneme error rate (PER) for each method. All methods use the same phoneme prediction model, highlighting the impact of different segmentation approaches.
read the caption
Table 4: Boundary evaluation results of different segmentation methods on LibriSpeech test-clean split. The second-last column (Freq.) is the number of segments per second. All the methods share the same phoneme prediction model trained with the k-means-based segmentation of wav2vec-U.

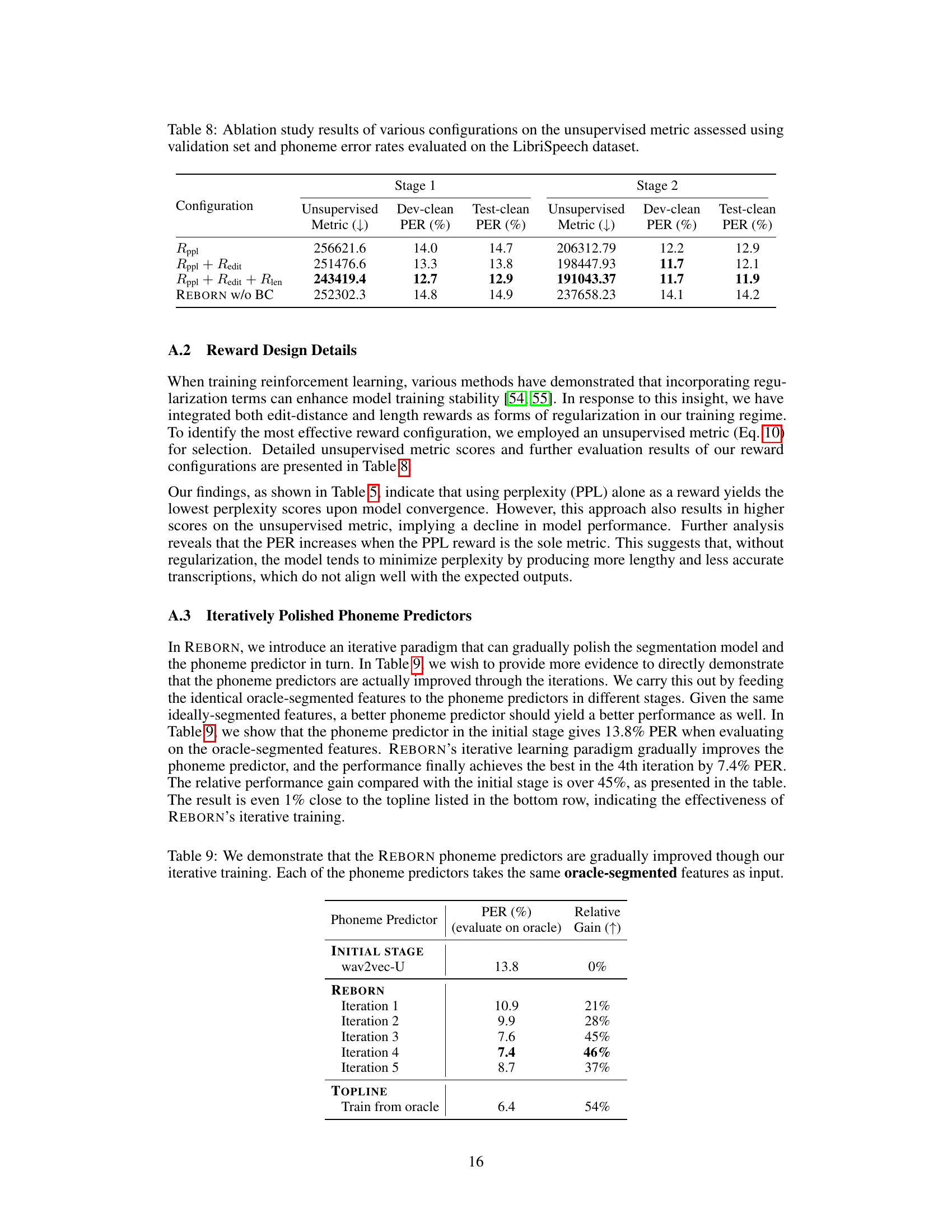
🔼 This table presents an ablation study comparing different reward function combinations used in the REBORN model for unsupervised automatic speech recognition. It shows the impact of using perplexity difference reward (Rppl), edit distance reward (Redit), and length difference reward (Rlen) individually and in combination on the model’s performance. Additionally, it demonstrates the effect of behavior cloning (BC) initialization on the first iteration’s results. Row (c) represents the full REBORN model configuration.
read the caption
Table 5: We compare different reward functions and the effect of BC initialization with first iteration results on LibriSpeech test-clean. Row (c) is REBORN.
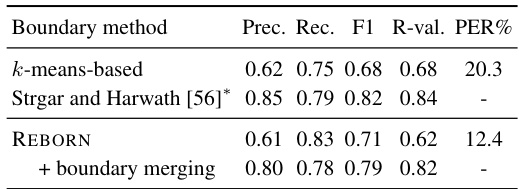
🔼 This table compares the performance of different boundary segmentation methods on the LibriSpeech test-clean dataset. It shows precision, recall, F1-score, R-value (a measure of boundary quality), and phoneme error rate (PER) for each method. The methods compared include the original k-means based method from wav2vec-U, the method proposed by Strgar and Harwath, and the REBORN method (both before and after boundary merging). The table demonstrates that REBORN, particularly after boundary merging, achieves better boundary precision and lower PER compared to other methods despite having a lower F1 score compared to Strgar and Harwath.
read the caption
Table 4: Boundary evaluation results of different segmentation methods on LibriSpeech test-clean split. The second-last column (Freq.) is the number of segments per second. All the methods share the same phoneme prediction model trained with the k-means-based segmentation of wav2vec-U.
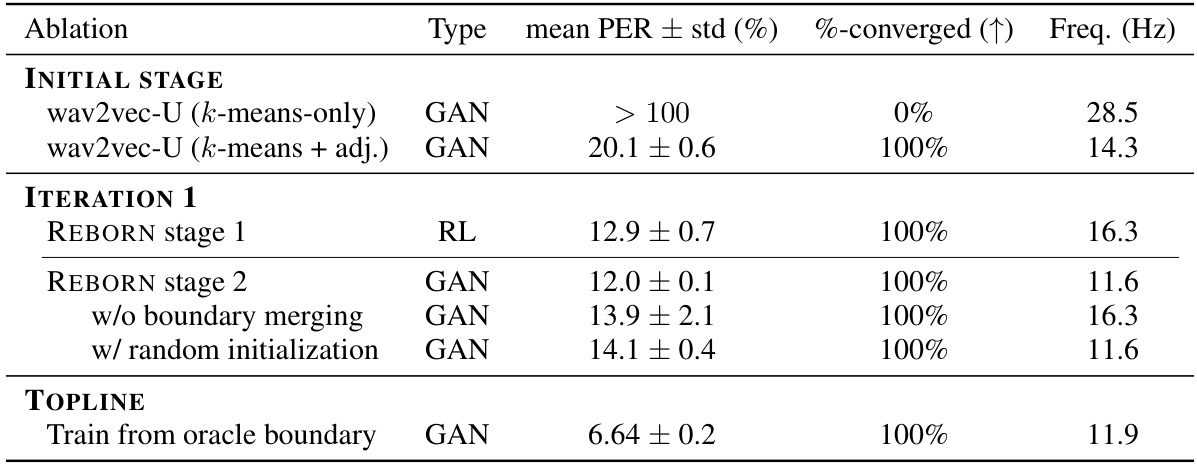
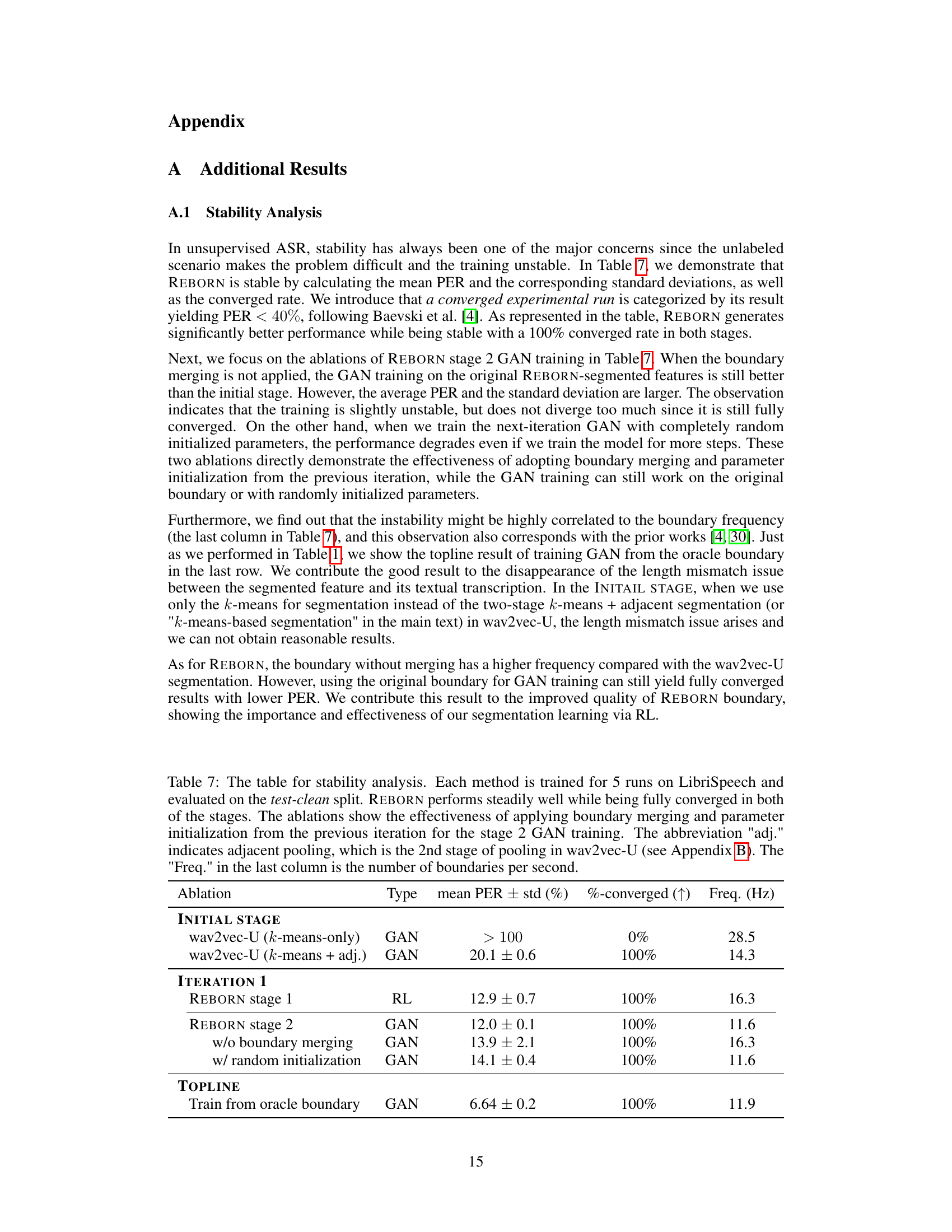
🔼 This table presents the results of a stability analysis conducted on the REBORN model. The main finding is that the model demonstrates consistent and stable performance across multiple runs, achieving a 100% convergence rate in both training stages. Ablation studies show the importance of boundary merging and using the previous iteration’s parameters to initialize the GAN training in Stage 2. A comparison with a topline result using oracle boundaries further highlights the effectiveness of the learned boundaries in REBORN.
read the caption
Table 7: The table for stability analysis. Each method is trained for 5 runs on LibriSpeech and evaluated on the test-clean split. REBORN performs steadily well while being fully converged in both of the stages. The ablations show the effectiveness of applying boundary merging and parameter initialization from the previous iteration for the stage 2 GAN training. The abbreviation 'adj.' indicates adjacent pooling, which is the 2nd stage of pooling in wav2vec-U (see Appendix B). The 'Freq.' in the last column is the number of boundaries per second.

🔼 This table presents the ablation study on different reward functions and behavior cloning initialization. It shows the unsupervised metric (lower is better), dev-clean PER, and test-clean PER for different configurations: using only Rppl (perplexity difference reward), adding Redit (edit distance reward), and finally adding Rlen (length difference reward) and comparing with REBORN without behavior cloning. The results demonstrate that using all three reward functions, along with behavior cloning, leads to improved performance, particularly in reducing the phoneme error rate.
read the caption
Table 8: Ablation study results of various configurations on the unsupervised metric assessed using validation set and phoneme error rates evaluated on the LibriSpeech dataset.
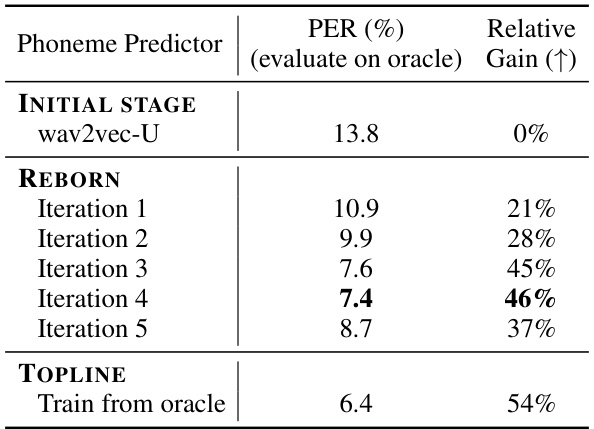
🔼 This table shows the Phoneme Error Rate (PER) when using the oracle segmented features as input, for different stages of the REBORN model training. It demonstrates that the iterative training process in REBORN leads to progressively better phoneme prediction models. The PER is evaluated on the test-clean set of LibriSpeech. The initial stage uses wav2vec-U. The topline represents results using the oracle boundaries which are not available in real unsupervised scenarios.
read the caption
Table 9: We demonstrate that the REBORN phoneme predictors are gradually improved though our iterative training. Each of the phoneme predictors takes the same oracle-segmented features as input.
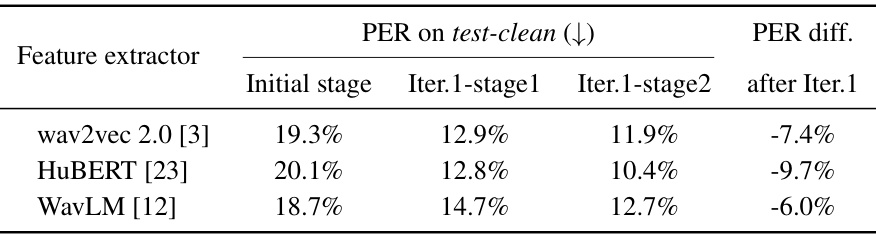
🔼 This table presents the results of an ablation study evaluating the generalizability of the REBORN model across three different speech foundation models: wav2vec 2.0, HuBERT, and WavLM. The performance (PER) is measured on the LibriSpeech test-clean dataset. For each model, the table shows the initial performance, the performance after the first stage of training in REBORN, the performance after the second stage, and the overall performance improvement after one iteration of REBORN. The results demonstrate that REBORN consistently improves performance across all three foundation models, showcasing its robustness and generalizability.
read the caption
Table 10: We implement REBORN across different speech foundation models on LibriSpeech. The results are evaluated on test-clean. REBORN has exhibited strong generalizability by providing substantial performance improvements across different speech foundation models. We extract the 15th layer representations from HuBERT and WavLM following EURO [18].

🔼 This table presents the optimal weighting coefficients (Cppl, Cedit, Clen) for the reward function used in the REBORN model’s training. These coefficients were determined through hyperparameter searches performed separately for each dataset (LibriSpeech, TIMIT, and MLS) to achieve optimal performance. The table is organized to show the optimal coefficients for each stage (Stage 1 and Stage 2) of training of REBORN model. The different iterations of the model training are also taken into account.
read the caption
Table 11: Best reward configurations obtained through hyperparameter searches on each dataset.
Full paper#