↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current LiDAR-based novel view synthesis heavily relies on pre-computed poses, which are often inaccurate due to limitations in point cloud registration. Pose-free Neural Radiance Fields (NeRFs) methods, while promising, lack geometric consistency. This paper tackles these issues by presenting a novel framework.
GeoNLF tackles these challenges with a hybrid approach. It alternates between global neural reconstruction and pure geometric pose optimization. A selective-reweighting strategy prevents overfitting, while geometric constraints enhance the robustness of optimization, producing superior results in both novel view synthesis and multi-view registration of low-frequency large-scale point clouds, as demonstrated on the NuScenes and KITTI-360 datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it presents GeoNLF, a novel framework that significantly improves LiDAR-based novel view synthesis and multi-view registration, especially for large-scale, low-frequency point clouds. This addresses a critical challenge in autonomous driving and robotics, pushing the boundaries of 3D scene understanding. The introduction of a hybrid approach combining neural and geometric optimization offers a new avenue for research in this field, leading to more accurate and robust 3D reconstruction. The proposed selective-reweighting and geometric constraint strategies can also inspire improvements in other NeRF-based applications.
Visual Insights#

This figure compares the registration results of several methods, including pairwise methods (GeoTrans, ICP), multi-view methods (SGHR, MICP), a gradient-based method (LiDARNeRF-HASH), and the proposed GeoNLF method. The results are visualized using point clouds colored by height, showing the accuracy of pose estimation in each method. GeoNLF significantly outperforms other methods by achieving higher accuracy and avoiding outlier frames, demonstrating its robustness and effectiveness in point cloud registration.
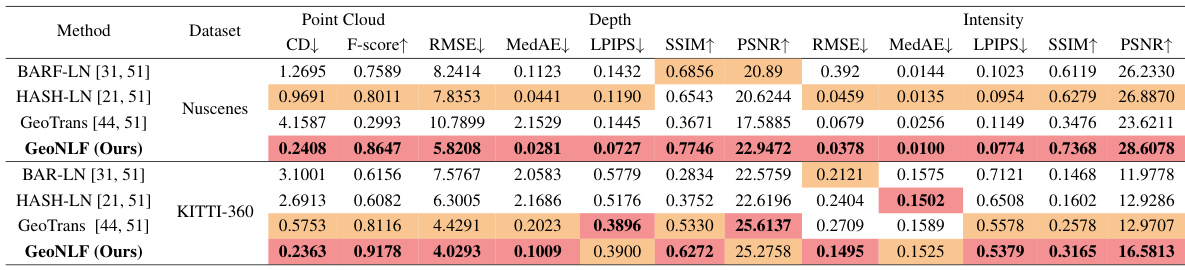
This table presents a quantitative comparison of novel view synthesis (NVS) performance on the NuScenes and KITTI-360 datasets. The comparison includes several state-of-the-art methods, categorized by their approach (gradient-based, learning-based, traditional). Metrics used for comparison are CD (Chamfer distance), F-score, RMSE (Root Mean Square Error), MedAE (Median Absolute Error), LPIPS (Learned Perceptual Image Patch Similarity), SSIM (Structural Similarity Index), and PSNR (Peak Signal-to-Noise Ratio). Lower values for CD, RMSE, MedAE, and LPIPS are better; higher values for F-score, SSIM, and PSNR are better. The table highlights the superior performance of the proposed GeoNLF method across various metrics on both datasets.
In-depth insights#
Pose-Free LiDAR#
Pose-free LiDAR methods are transforming 3D scene understanding by eliminating the reliance on precise pre-computed poses, a significant challenge in traditional LiDAR processing. This approach is particularly valuable in scenarios with sparse or low-frequency point cloud data where accurate pose estimation is difficult. Key advantages include robustness to noisy or incomplete data, and the ability to reconstruct scenes from fewer viewpoints. The core idea lies in incorporating geometric constraints and employing neural networks to learn the scene’s structure directly from the point cloud data, thus sidestepping the need for accurate initial pose estimates. Challenges remain in balancing geometric consistency with accurate scene representation, avoiding overfitting, and efficiently handling large-scale datasets. Furthermore, future research should focus on addressing the trade-offs between computational cost and accuracy, developing more effective strategies for outlier rejection and robust optimization, and exploring applications in dynamic scene reconstruction.
GeoNLF Framework#
The GeoNLF framework, a hybrid approach for large-scale LiDAR data processing, cleverly combines neural radiance fields (NeRFs) with geometric optimization. Alternating between global NeRF refinement and pure geometric pose optimization, GeoNLF addresses limitations of existing pose-free methods by leveraging point cloud’s inherent geometric structure. A crucial aspect is selective-reweighting, mitigating overfitting on outlier frames, enhancing robustness, especially under sparse data conditions. The framework’s success is further bolstered by the incorporation of explicit geometric constraints, maximizing the utilization of point cloud information beyond simple depth supervision, thus significantly improving registration and novel view synthesis accuracy. This sophisticated design allows GeoNLF to excel in challenging large-scale, low-frequency scenarios where traditional methods often struggle. The synergy of neural reconstruction and geometric refinement is a key innovation, providing a robust and accurate solution for LiDAR data processing.
Geometric Optimization#
The core of the proposed method lies in its hybrid approach to geometric optimization, cleverly alternating between global neural reconstruction (using Neural LiDAR Fields) and a pure geometric pose refinement stage. This synergistic strategy leverages the strengths of both approaches: NeRF’s capability for global scene understanding and a geometric optimizer’s precision in aligning point clouds locally. The geometric optimizer itself is a graph-based method, enhancing robustness by incorporating geometric constraints derived directly from the LiDAR point cloud data and employing a selective-reweighting strategy. This effectively mitigates overfitting and addresses the issue of outlier frames, which can significantly hinder traditional methods. The integration of geometric constraints further improves optimization by fully utilizing the implicit geometric information abundant in point clouds, surpassing reliance solely on range maps. This holistic approach is key to GeoNLF’s success in achieving high-quality novel view synthesis and accurate multi-view registration, particularly impressive in challenging scenarios involving sparse and low-frequency large-scale point clouds.
Selective Re-weighting#
The selective re-weighting strategy in this research is a crucial technique to enhance the robustness of the model during training. It directly addresses the issue of overfitting, especially prevalent when dealing with sparse and low-frequency LiDAR data. By identifying frames with outlier poses, which manifest as significantly higher rendering losses, this method dynamically adjusts the learning rate. Outlier frames receive a reduced learning rate, preventing the model from overfitting to these unreliable observations while still allowing for pose correction through gradient propagation. This approach is vital for maintaining multi-view consistency and improving the overall quality of the reconstruction. The strategy is elegantly implemented, avoiding negative impacts on radiance fields. The selective re-weighting acts as a filter, effectively mitigating the adverse effects of outliers during global optimization and leading to more accurate pose estimation. This technique, in combination with the geometric constraints and the graph-based optimization, demonstrates a powerful and efficient strategy to achieve state-of-the-art performance in challenging large-scale LiDAR processing.
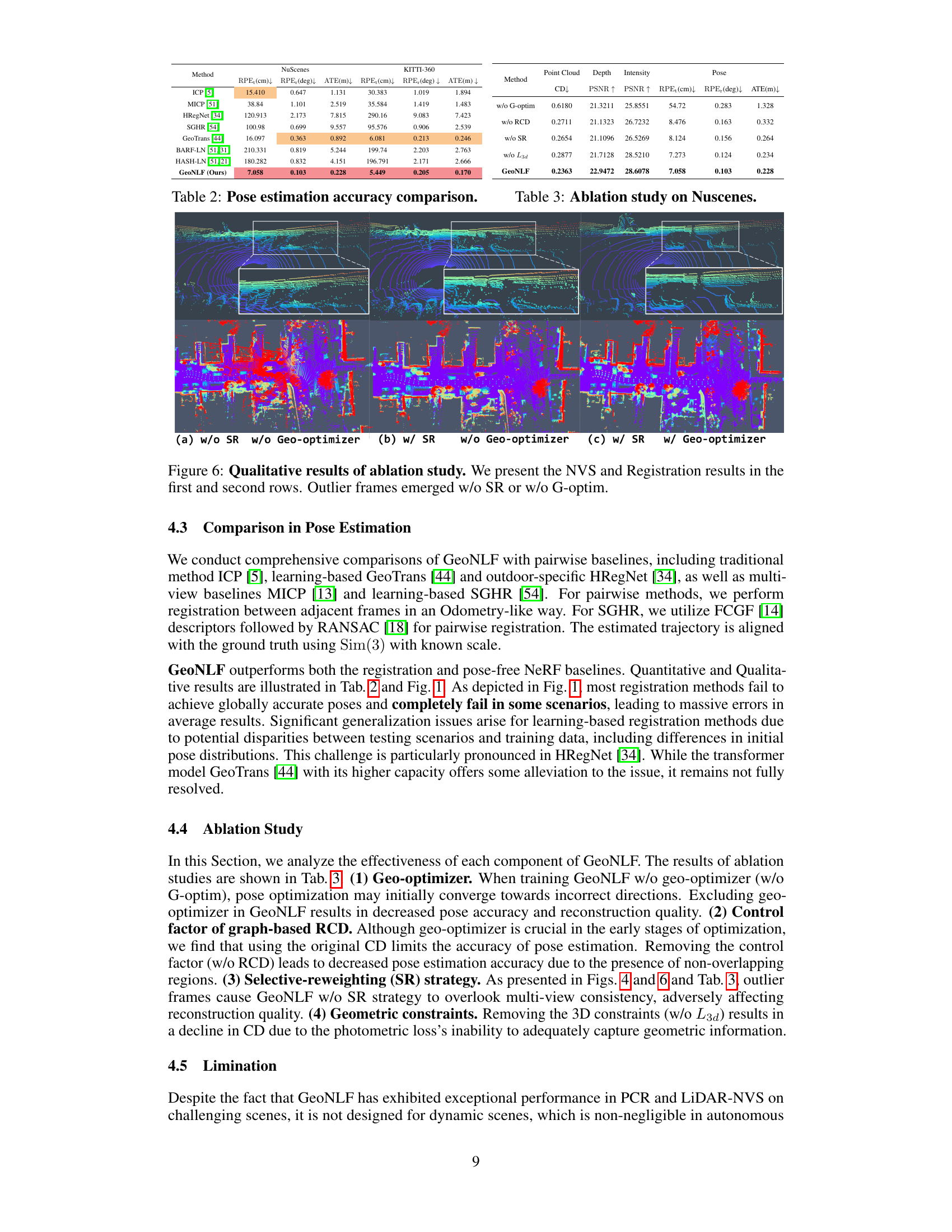
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In this context, it is crucial to carefully select which components to ablate, ensuring that the ablated parts are meaningful and well-defined. The results should be interpreted cautiously, as removing one component might indirectly affect others, masking true individual impacts. A well-designed ablation study will incorporate multiple ablation settings, ideally exploring various combinations of components, to gain a more complete understanding. Moreover, it’s important to quantify the impact of each ablation, using clear metrics to demonstrate a statistically significant effect. This allows for a robust comparison between different model configurations, providing insights that support the claims made regarding the importance of specific components. Finally, a strong ablation study will acknowledge and discuss potential limitations, such as confounding effects between ablated components, emphasizing the need for careful interpretation of the results.
More visual insights#
More on figures
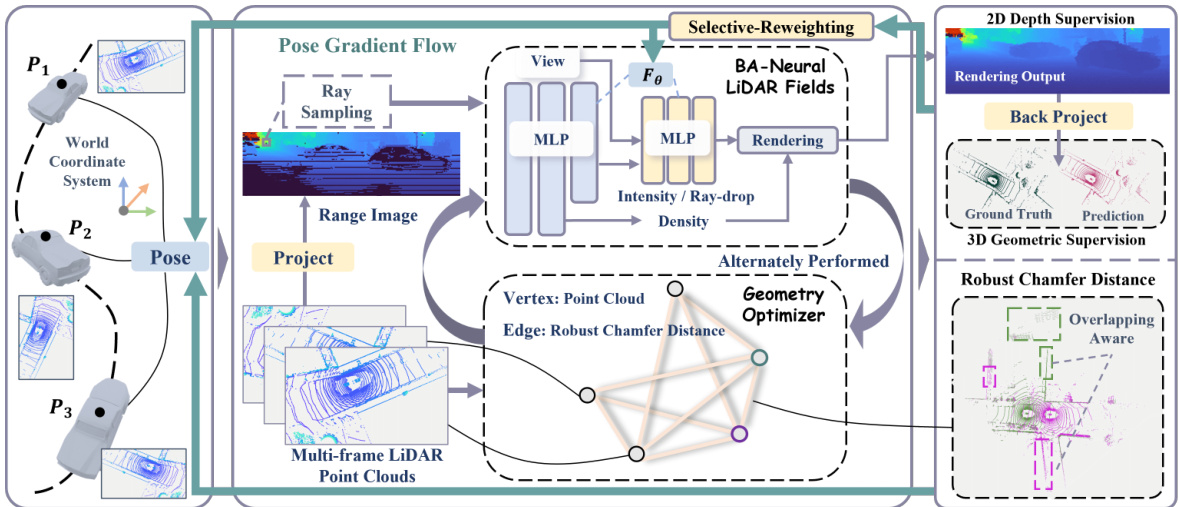
This figure shows the architecture of the GeoNLF framework. It’s a hybrid approach that alternates between two main processes: global optimization of bundle-adjusting neural LiDAR fields (using a coarse-to-fine training strategy) and graph-based pure geometric optimization (using a graph constructed from multiple frame point clouds and a graph-based loss). Key components include selective re-weighting to mitigate overfitting from outlier frames and explicit geometric constraints derived from point cloud data (e.g., normal information) to improve the accuracy and geometric consistency of the results. The framework takes multi-frame LiDAR point clouds as input and produces rendered range images and point cloud reconstructions.

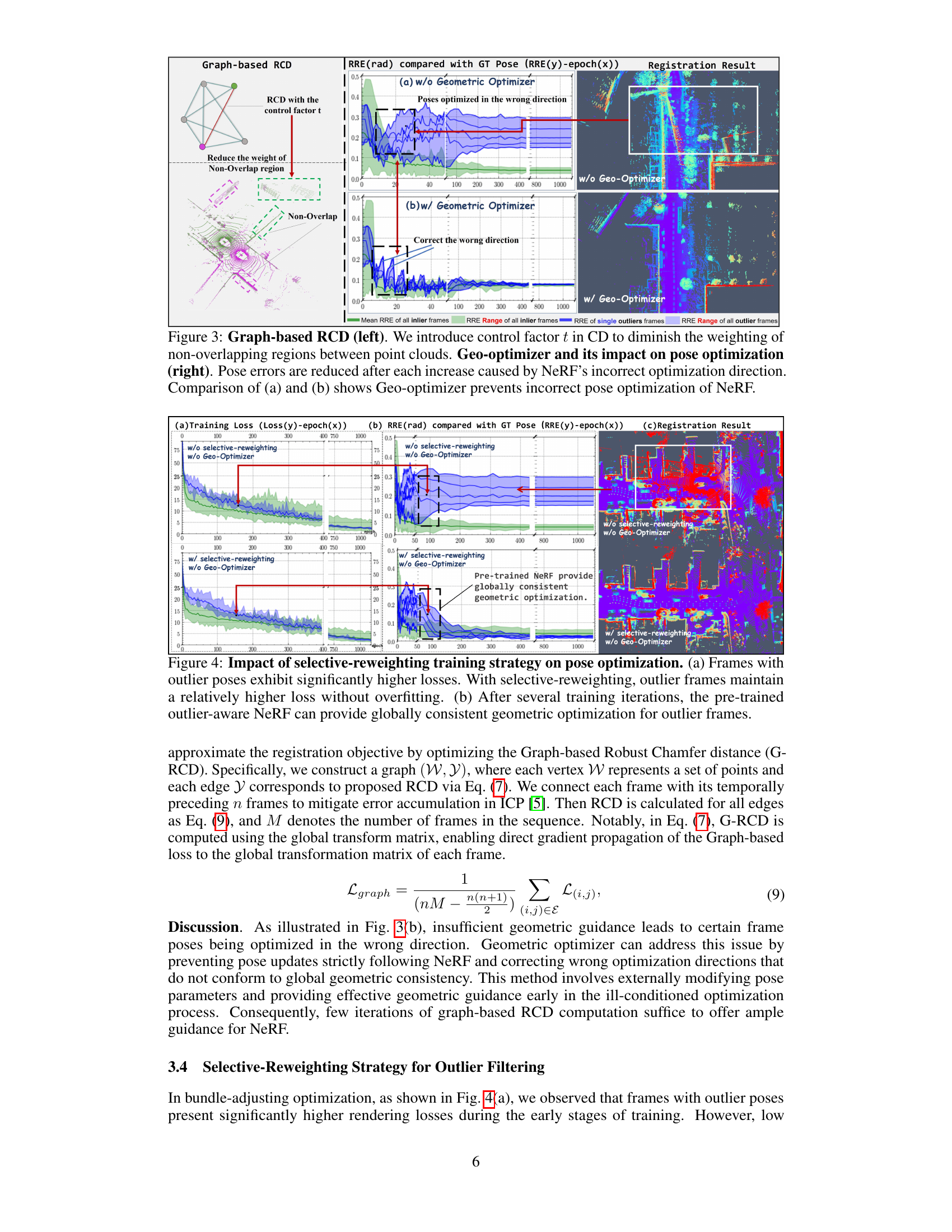
This figure shows the impact of the proposed geometry-guided optimization on the pose estimation. The left part illustrates how the graph-based robust Chamfer distance (RCD) is used to reduce the weight of non-overlapping regions between point clouds. The right part demonstrates how the Geo-optimizer corrects the wrong optimization direction caused by the neural radiance field (NeRF). The comparison between (a) and (b) shows that the Geo-optimizer significantly improves the pose estimation accuracy by preventing incorrect pose optimization.

This figure shows the effect of selective-reweighting on pose optimization. The top row displays results without selective re-weighting, demonstrating that outlier frames have significantly higher losses and lead to poor global optimization. The bottom row shows that with selective re-weighting, outlier frames still have higher losses, but the overfitting is mitigated, leading to improved global optimization after training.
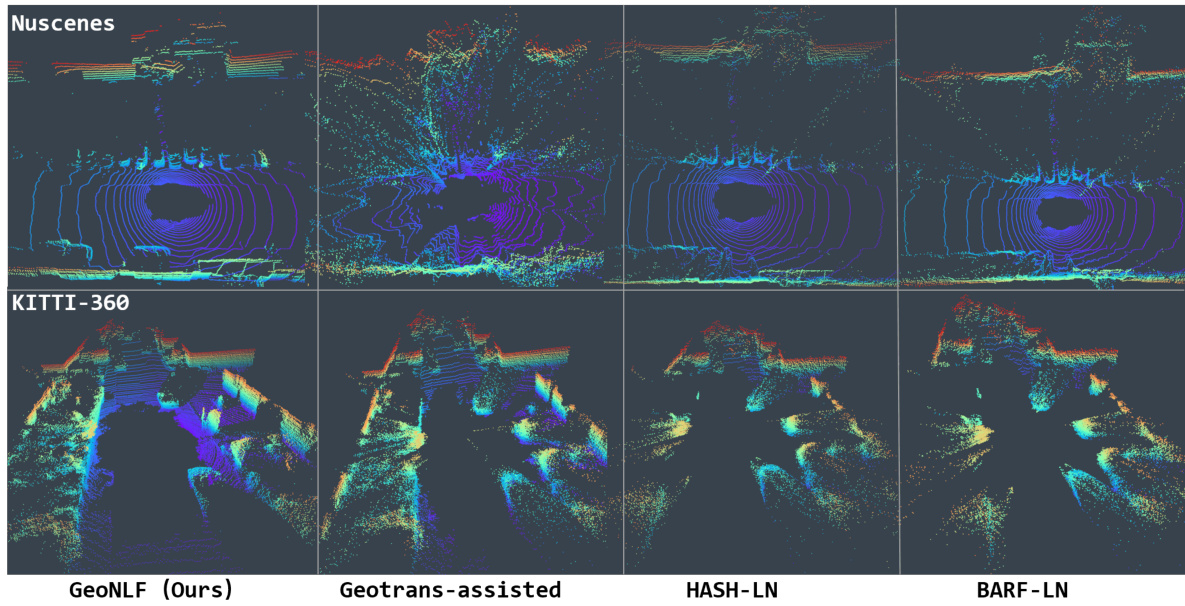
This figure presents a qualitative comparison of novel view synthesis (NVS) results using GeoNLF and several other methods. The top row shows results for the Nuscenes dataset, and the bottom row shows results for the KITTI-360 dataset. Each column represents a different method: GeoNLF (the proposed method), GeoTrans-assisted NeRF (using GeoTrans for pose estimation then LiDAR-NeRF for reconstruction), HASH-LN (a LiDAR-NeRF based method), and BARF-LN (another LiDAR-NeRF based method). The figure visually demonstrates the superior quality of novel views generated by GeoNLF compared to alternative approaches, highlighting that GeoTrans fails to produce satisfactory results on the Nuscenes dataset due to inaccurate pose estimation. The visual comparison showcases the improvements in point cloud reconstruction accuracy and completeness achieved by the proposed GeoNLF method.
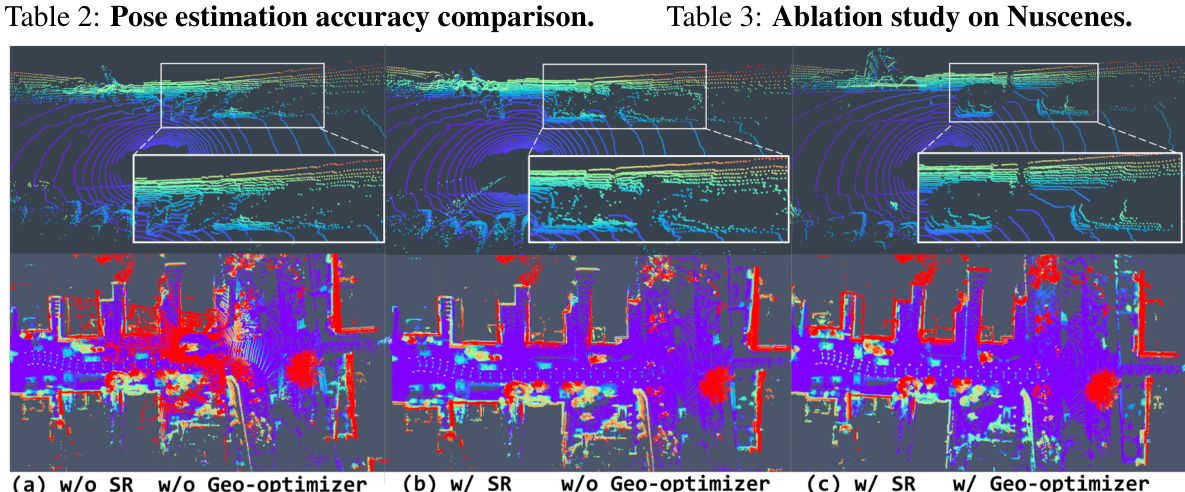
This figure shows a qualitative comparison of the results obtained with different configurations of the GeoNLF model. The top row displays the results of novel view synthesis (NVS), where the model attempts to generate new views of a scene from existing point cloud data. The bottom row displays the results of point cloud registration (PCR), where the model attempts to align multiple point clouds. The columns represent different ablation studies: (a) Without selective-reweighting (SR) and without geometric optimizer (G-optim). (b) With selective-reweighting and without geometric optimizer. (c) With selective-reweighting and with geometric optimizer. The results demonstrate that both SR and G-optim are important components of the model, as their absence leads to the emergence of outlier frames (incorrect poses and NVS reconstruction), especially in the second row, registration results.

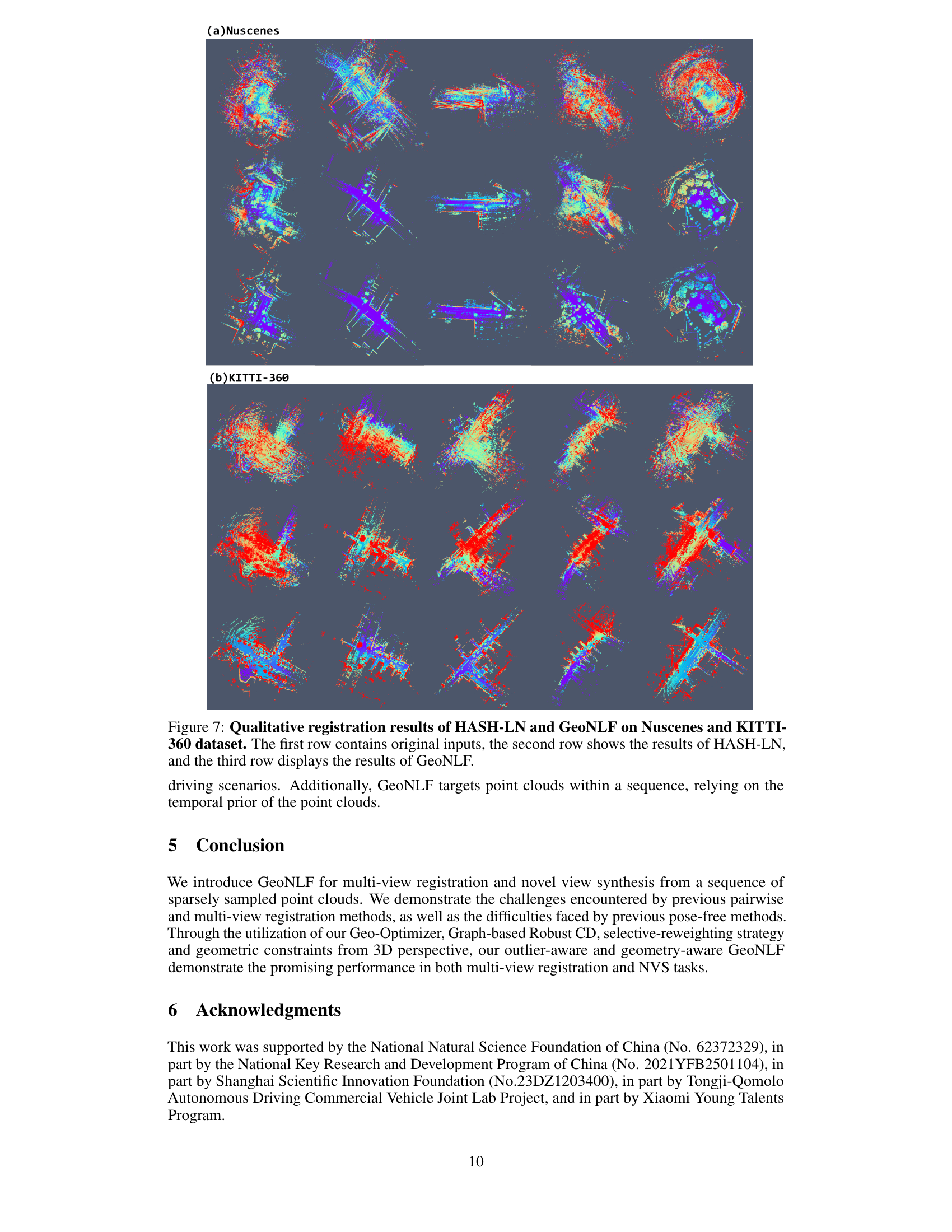
This figure shows a qualitative comparison of the point cloud registration results obtained using HASH-LN and the proposed GeoNLF method. The figure is divided into two parts: (a) Nuscenes and (b) KITTI-360. Each part displays three rows of point cloud data: the first row shows the original input point clouds, the second row shows the results obtained using the HASH-LN method, and the third row shows the results obtained using the GeoNLF method. The color variations in the point clouds represent different features or characteristics of the point clouds. The comparison allows for a visual assessment of the accuracy and quality of point cloud registration achieved by each method. The GeoNLF method is expected to demonstrate superior registration accuracy compared to HASH-LN.
Full paper#