↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Human-AI cooperation is a challenging problem in AI, as humans exhibit diverse and unpredictable behaviors. Existing methods for training cooperative AI agents often struggle to generalize well to real humans because simulated human partners do not fully capture the variability in actual human behaviors. This often leads to poor performance when tested with real human partners.
The paper proposes a novel method called GAMMA (Generative Agent Modeling for Multi-agent Adaptation) that addresses this issue by learning a generative model of human partners. This generative model can simulate a wide range of human behaviors and strategies to train a cooperative AI agent. The key contribution is the incorporation of both simulated and real human interaction data to create a more versatile and human-like partner model for training. The experimental results, performed in the Overcooked game, show significant performance improvements with GAMMA compared to previous approaches, highlighting its effectiveness in promoting robust and adaptable human-AI collaboration.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on human-AI cooperation. It introduces a novel approach using generative models to tackle the challenge of zero-shot coordination with diverse human partners. This work directly addresses a significant limitation in current multi-agent reinforcement learning techniques, opening new avenues for creating more robust and adaptable AI agents.
Visual Insights#
This figure displays the latent space visualization using t-SNE for three different scenarios: simulated data, human data, and human-adaptive sampling. The results show that the generative model (GAMMA) can generate a more diverse range of partner strategies than either simulated agents or a behavior cloning approach based on human data. In the human-adaptive sampling scenario, the generative model is steered towards generating agents similar to human players. This highlights the ability of GAMMA to cover a broader strategy space and to adapt to real-world human strategies.

This table lists the hyperparameters used for training the policy models in the paper. It includes specifications for the CNN (Convolutional Neural Network) layers, including kernel sizes and number of channels; hidden and recurrent layer sizes; activation function; weight decay; environment steps; number of parallel environments; episode length; PPO (Proximal Policy Optimization) batch size and epoch; PPO learning rate; Generalized Advantage Estimator (GAE) lambda; and discount factor gamma. These hyperparameters were used to train both simulated and human data models.
In-depth insights#
GAMMA: Generative Approach#
The GAMMA generative approach presents a novel solution to the challenge of training AI agents capable of seamless zero-shot cooperation with humans. Its core innovation lies in using a generative model to create a diverse range of simulated human partners, overcoming limitations of previous methods that relied solely on behavior cloning or limited simulated populations. This allows for training a more robust and adaptable agent, capable of handling unexpected strategies. The approach addresses the data scarcity problem inherent in human-AI collaboration by leveraging both real human and simulated data, enabling efficient training with only small amounts of expensive real human interaction data. A key feature is the Human-Adaptive sampling technique, which efficiently steers the generative model to prioritize human-like behavior patterns, resulting in enhanced performance in real-world human-AI interactions. The flexibility and scalability of GAMMA make it a promising technique for diverse multi-agent coordination tasks.
Human-AI Coordination#
Human-AI coordination is a crucial area of research, aiming to create AI systems that seamlessly collaborate with humans. Effective coordination necessitates robust AI agents capable of understanding and adapting to human behavior, which is inherently diverse and unpredictable. Current approaches focus on creating simulated human partners to train AI agents, but these often fail to capture the full spectrum of human strategies and styles. Generative models offer a promising solution by learning a latent representation of human behavior, allowing for flexible generation of diverse partners to train more adaptable AI agents. This approach tackles both the challenge of limited real-world human data and the shortcomings of simplistic synthetic data. The key to successful Human-AI coordination lies in developing AI systems that are not only cooperative but also robustly adaptable and generalizable to a wide variety of human partners, effectively bridging the gap between the simulated and real-world human interactions.
Overcooked Experiments#
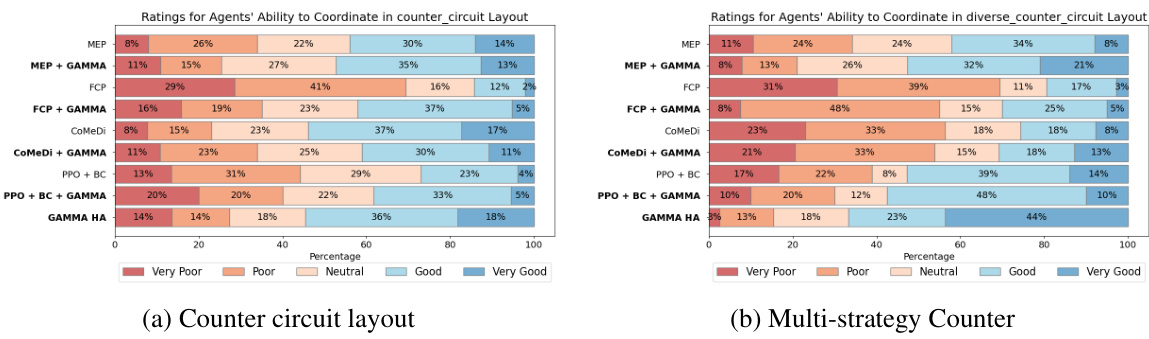
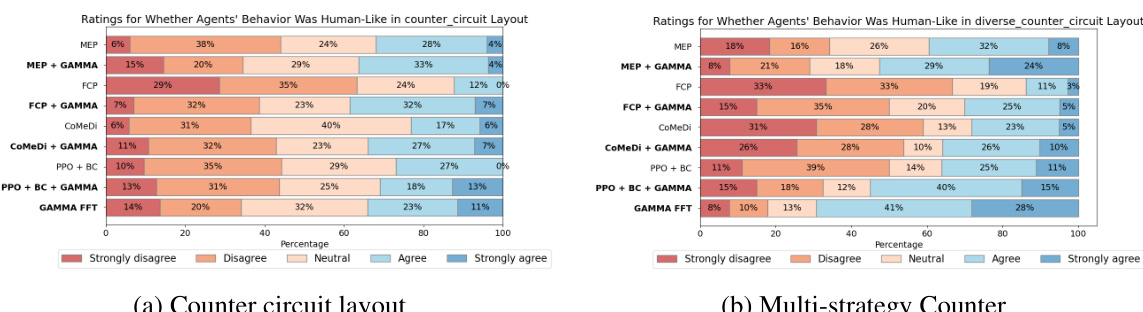
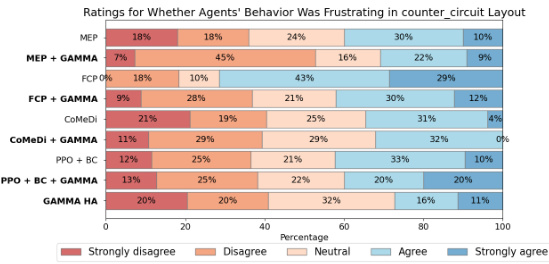
Overcooked, a collaborative cooking game, served as a crucial testbed for evaluating the efficacy of the proposed GAMMA framework. The selection of Overcooked was strategic, leveraging its established position as a benchmark within the multi-agent reinforcement learning field, specifically for assessing zero-shot coordination abilities. The experiments meticulously compared GAMMA’s performance against established baselines across a variety of Overcooked layouts, ranging from simpler scenarios to more complex, multi-step challenges. Results consistently demonstrated that GAMMA-trained agents exhibited superior zero-shot coordination performance when paired with human players, highlighting the framework’s capability to generalize well beyond the simulated training environment. A key element of the evaluation involved incorporating human data, demonstrating the significant performance gains that result from a combination of both human and simulated data in training the GAMMA agents. The human-adaptive sampling technique played a critical role in the experiments, allowing for efficient integration of limited human data to guide the agent’s learning towards improved coordination with human partners. The study also incorporated a user study that yielded valuable subjective insights, further reinforcing the qualitative benefits of GAMMA’s approach.
Human Data Efficiency#
Human data efficiency in AI research focuses on minimizing the amount of human-labeled data needed to train effective models. This is crucial because acquiring and annotating human data is often expensive, time-consuming, and may present privacy issues. The core challenge lies in bridging the gap between limited human data and the data-hungry nature of many machine learning algorithms. Approaches like data augmentation, semi-supervised learning, transfer learning, and meta-learning aim to address this by leveraging existing data more efficiently and incorporating unlabeled data. Generative models play a significant role, enabling the synthesis of new, realistic data points that supplement the scarce real-world human data. However, successful human data efficiency hinges on ensuring that synthetic data faithfully represents the true distribution of human behavior and avoids introducing biases or inaccuracies that might negatively impact model performance. The effectiveness of these techniques is highly context-dependent and often requires careful design and evaluation to achieve a satisfactory balance between efficiency and accuracy.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving data efficiency is key; current methods struggle with limited human data. Investigating techniques like meta-learning or few-shot learning could enable the generative model to adapt more readily to new human partners with minimal additional data. Expanding beyond Overcooked to diverse, more complex environments is crucial to assess generalization capabilities. The impact of human variability, including skill levels and playing styles, could be more comprehensively studied by incorporating detailed player modeling techniques and analyzing their effects on both generative model training and Cooperator agent performance. Finally, understanding how the latent space of human strategies evolves over time would inform more robust and dynamic human-AI teaming systems. Addressing these areas would significantly advance the field of human-AI cooperation.
More visual insights#
More on figures

This figure illustrates the GAMMA (Generative Agent Modeling for Multi-agent Adaptation) method. The left side shows how the generative model learns a latent distribution of partner strategies using both simulated agent data and real human interaction data. The latent representation, Z, encodes partner styles. The right side depicts how the trained generative model produces diverse partner agents (µz) that a Cooperator agent (πc) then learns to coordinate with using reinforcement learning (RL). The iterative interaction between the generative agents and the Cooperator enables robust, zero-shot cooperation with novel human partners.

This figure shows six different Overcooked game layouts used in the experiments. The first five are from previous work and are progressively more complex. The sixth layout, ‘Multi-strategy Counter’, is a new, more complex layout introduced by the authors, adding additional strategic choices (onion vs. tomato soup) to increase the difficulty and diversity of the possible strategies.

This figure compares the performance of different methods for training a cooperative agent in the Overcooked game. It shows learning curves (average normalized reward over training steps across all layouts), and a comparison of final normalized and original rewards across individual game layouts for different methods. The key takeaway is that using a generative model (GAMMA) consistently improves the performance of the cooperative agent, especially on more complex layouts.

This figure displays the average scores achieved by different cooperative agents when playing against real human partners in two Overcooked layouts: Counter Circuit and Multi-strategy Counter. Error bars represent the standard error, indicating statistical significance. Agents trained using human data are highlighted in green. The results demonstrate that GAMMA consistently outperforms baseline methods, regardless of whether the training data is simulated or human. GAMMA with human-adaptive sampling (GAMMA-HA) shows the best performance, effectively leveraging a small amount of human data to achieve superior cooperation with real humans.
This figure compares the latent space covered by different methods for generating agents in a cooperative game. Panel (a) shows that using GAMMA with simulated data produces a larger and more diverse strategy space compared to using the simulated agents directly. Panel (b) demonstrates that GAMMA trained on human data captures a wider range of strategies than a human proxy model. Panel (c) highlights the ability of GAMMA to control the latent space sampling and generate agents with a specific strategy profile, such as human coordinators.

This figure visualizes the latent space generated by different methods for training cooperative agents. It compares the latent space coverage of simulated agents, human players, behavior cloning, and generative agents trained on simulated or human data. Panel (a) shows interpolation capabilities of the generative model using simulated data, (b) compares generative model coverage to human proxy model coverage using human data, and (c) demonstrates human-adaptive sampling using generative model.
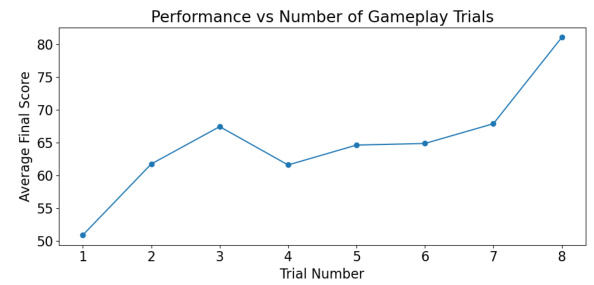
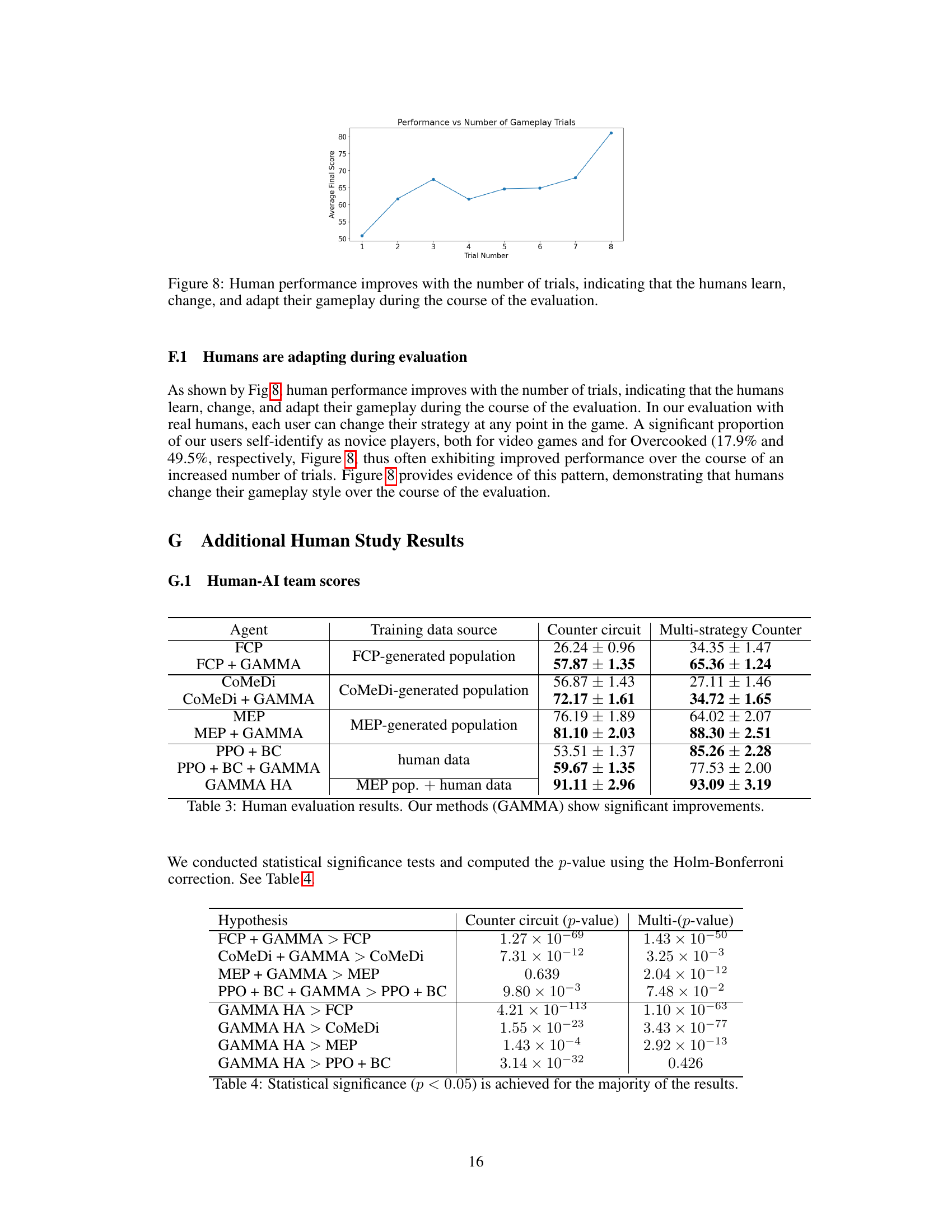
This figure shows the average final score achieved by human participants in the Overcooked game across eight gameplay trials. The scores steadily increase from trial one to eight, illustrating that humans continuously adapt their strategies and improve their performance as they gain more experience with the game and its challenges.

This figure shows the latent space visualization of different methods for generating agents’ strategies. (a) demonstrates how GAMMA, using a generative model trained on simulated data, can generate a wider range of strategies compared to simply using the simulated agents directly. (b) shows that, even with human data, GAMMA produces a more diverse range of strategies than a human proxy model based on behavior cloning. Finally, (c) highlights GAMMA’s ability to control the latent space sampling, allowing for targeting a specific population of agents (e.g., focusing on human-like strategies).
This figure visualizes the latent space of different methods for generating agents in a cooperative game. Panel (a) shows how GAMMA, using simulated data, generates agents that span a wider range of strategies than simply using the simulated agents alone. Panel (b) demonstrates that GAMMA, using human data, captures a greater diversity of strategies than a human proxy model. Panel (c) highlights GAMMA’s ability to control the sampling process to focus on a specific type of agent, such as human coordinators.
This figure compares the latent space coverage of different methods for generating agents in a cooperative game. (a) shows that using a generative model with simulated data expands the strategy space beyond the original simulated agents. (b) shows that the generative model on human data captures more diversity than a simple behavior cloning approach. (c) demonstrates the ability to control sampling to target specific agent characteristics (e.g., human-like coordination strategies).

This figure shows the latent space visualization of different methods for generating agents’ strategies in the Overcooked game. Panel (a) demonstrates how GAMMA, using simulated data, generates a more diverse range of strategies than the original simulated agent population. Panel (b) compares GAMMA’s performance on human data to a behavior cloning approach, highlighting GAMMA’s ability to capture the diversity of human strategies. Finally, Panel (c) shows how GAMMA allows for targeted agent generation by controlling the sampling process within the latent space, aiming for human-like coordination.

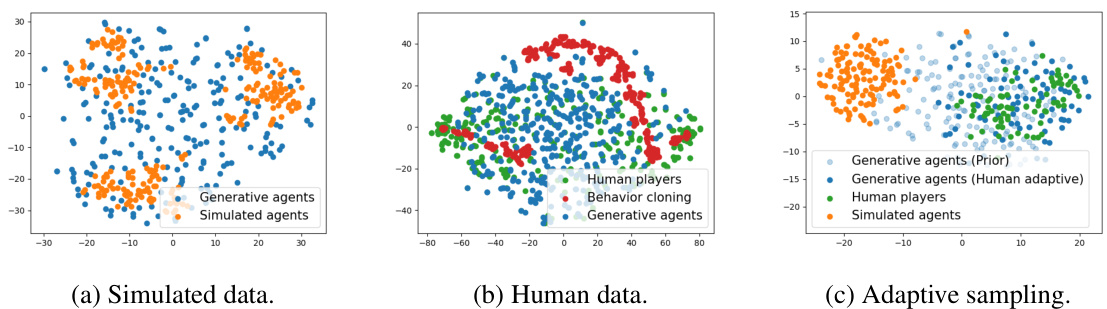
This figure compares the performance of different multi-agent reinforcement learning methods on six different Overcooked game layouts. The methods compared are FCP, FCP + GAMMA, CoMeDi, CoMeDi + GAMMA, MEP, and MEP + GAMMA. The y-axis represents the reward obtained, while the x-axis represents the number of steps in training. Error bars indicate the standard error of the mean. GAMMA consistently outperforms or matches the performance of the baselines across all six layouts, suggesting that the generative agent model is effective at training more robust cooperative agents.

This figure shows the learning curves for different methods using human data for two layouts: Counter Circuit and Multi-strategy Counter. The left panel (a) shows evaluation results against a held-out human proxy agent. The human adaptive sampling method (GAMMA-HA) learns faster but doesn’t outperform the baseline method (PPO + BC) which is trained to specifically exploit the human proxy agent. In contrast, the right panel (b) shows an evaluation against held-out self-play agents where GAMMA-HA with decoder-only fine-tuning (DFT) performs significantly better. This highlights the ability of GAMMA-HA to generalize well to diverse, unseen human players.

This figure shows the learning curves for three different methods of fine-tuning a generative model using human data: the original best decoder-only fine-tuning (DFT), the original full fine-tuning (FFT), and a new full fine-tuning method (FFT) with a larger KL divergence penalty coefficient. The new FFT method significantly improves upon the original FFT, achieving performance comparable to the original best DFT method. This suggests that increasing the KL divergence penalty coefficient can help to mitigate the issue of insufficient human data when fine-tuning generative models.
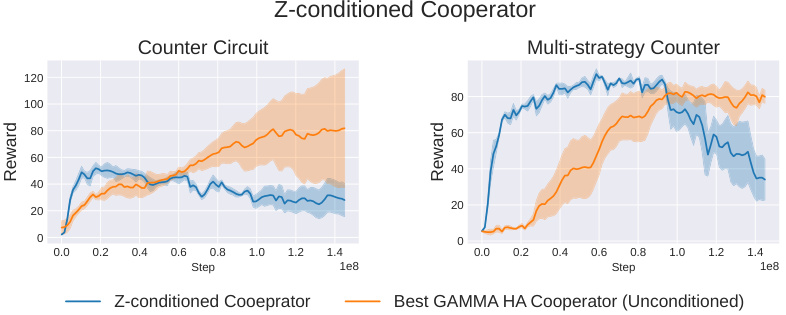
This figure shows the learning curves of two different cooperator agents trained on the Overcooked game. One is a standard cooperator and the other is a z-conditioned cooperator, meaning its policy is conditioned on a latent variable representing the partner’s strategy. The z-conditioned agent initially performs better, especially on the more complex ‘Multi-strategy Counter’ layout. However, its performance eventually decreases due to overfitting of the latent variable. This suggests a trade-off between quickly adapting to a specific partner and generalizing well to unseen partners.
More on tables

This table lists the hyperparameters used for training the variational autoencoder (VAE) models in the GAMMA framework. These hyperparameters control various aspects of the VAE’s architecture and training process, such as the convolutional neural network (CNN) layers, recurrent layer size, activation function, weight decay, parallel environments used for training, episode length, training epochs, chunk length for the recurrent layers, learning rate, KL penalty coefficient (β), and the dimensionality of the latent variable (z). Different settings might be used depending on the specific task or dataset.

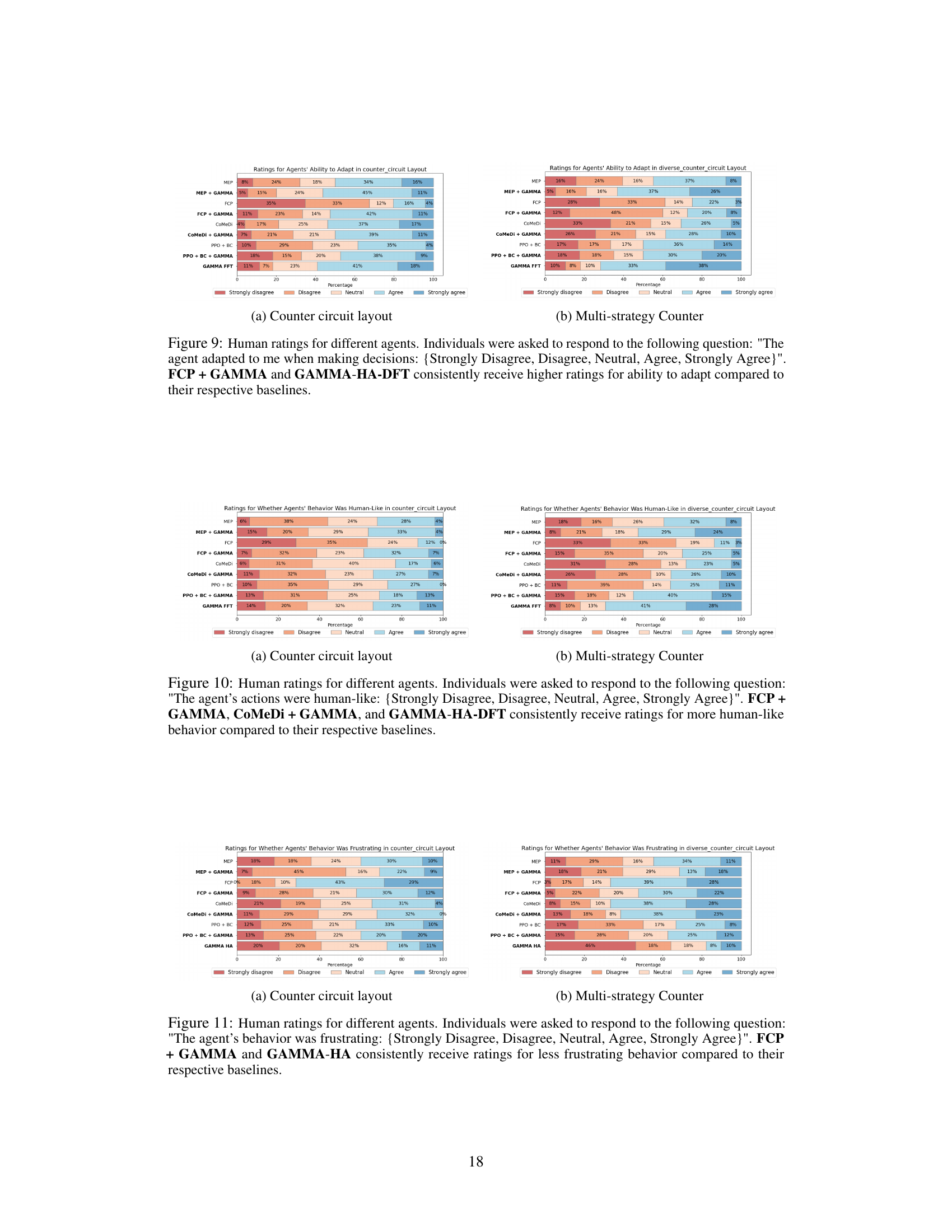
This table presents the results of a human evaluation comparing different methods for training cooperative agents in the Overcooked game. The ‘Agent’ column lists the various methods used, including baselines (FCP, CoMeDi, MEP, PPO + BC) and the proposed GAMMA method with various configurations. The ‘Training data source’ column shows what kind of data (simulated agent populations or human data) was used to train each method. The final two columns show the average scores achieved by each method in two specific Overcooked layouts: ‘Counter Circuit’ and ‘Multi-strategy Counter’. The results indicate significant performance improvements for methods using GAMMA.

This table presents the results of statistical significance tests, specifically p-values, comparing the performance of different methods used in the Overcooked game experiment. The Holm-Bonferroni correction was applied to control for multiple comparisons. Each row represents a hypothesis test comparing two different methods, such as FCP + GAMMA versus FCP (baseline). The p-values indicate the probability of observing the results obtained if there is no real difference between the methods being compared. Lower p-values suggest stronger evidence that a difference exists.

This table presents the results of a human evaluation comparing different methods for training cooperative agents in the Overcooked game. The methods are grouped by the type of training data used (simulated or human) and whether or not the GAMMA method was employed. The table shows the average scores achieved by each method on two layouts of varying complexity: Counter Circuit and Multi-strategy Counter. The results demonstrate that the GAMMA approach significantly improves performance, regardless of the data source, highlighting its effectiveness in enabling robust generalization to real human partners.
Full paper#