↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many AI models unintentionally memorize training data, affecting their performance and trustworthiness. Existing methods for measuring this memorization are computationally expensive and challenging to apply to large, open-source models. This limits our understanding of how widespread memorization is and hinders efforts to develop more robust AI systems.
This research introduces new, simpler methods to efficiently measure memorization in AI models. These methods are significantly faster and more scalable than previous approaches and enable the evaluation of memorization in large-scale open-source models. The study’s findings demonstrate that open-source models generally exhibit lower levels of memorization compared to models trained on smaller subsets of data, providing valuable insights into model behavior and reliability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on representation learning and model memorization. It introduces efficient methods for measuring memorization, enabling the analysis of large open-source models and facilitating the development of more robust and generalizable models. This addresses a critical limitation of previous memorization measurement techniques and paves the way for improved understanding and mitigation of memorization issues in the field. The practical tool developed is highly valuable for evaluating memorization rates in large models and promotes the development of more robust and trustworthy AI systems.
Visual Insights#
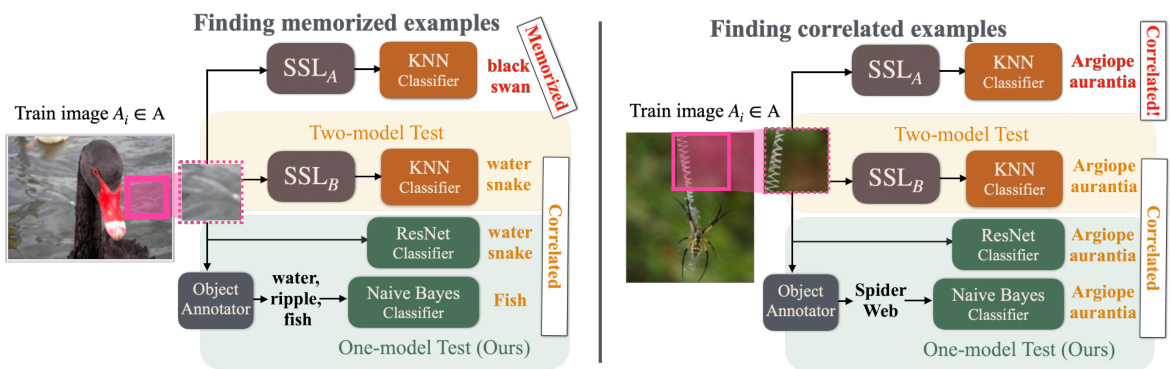
This figure illustrates the difference between the original two-model déjà vu test and the proposed one-model test. The original test trains two separate models on disjoint subsets of the training data to measure memorization by comparing their performance. In contrast, the one-model test uses a single classifier trained to predict the foreground object from only the background crop, thus making the memorization evaluation much more efficient and scalable.

This table presents the accuracy of different classifiers (ResNet and Naive Bayes with varying numbers of top crop annotations) in predicting dataset-level correlations. It compares these one-model test accuracies against the intersection of results from three two-model tests (VICReg, Barlow Twins, and DINO). The goal is to evaluate how well the simpler one-model tests align with the more complex two-model approach in identifying these correlations.
In-depth insights#
Déjà Vu Detection#
Déjà vu, in the context of machine learning, refers to the phenomenon where a model appears to recognize a data point it has previously encountered, even when only presented with partial or indirect information. Déjà vu detection methods aim to identify instances where a model’s performance exceeds what would be expected based on dataset-level correlations alone, suggesting that the model has ‘memorized’ specific training examples rather than truly learned generalizable features. Effective déjà vu detection is crucial for assessing model robustness and generalization ability. Current approaches often involve comparing the model’s performance on a novel task to a baseline established using dataset-level correlations, often necessitating training multiple models. However, this process is computationally expensive and can be difficult to scale to large datasets. Therefore, developing more efficient methods to detect déjà vu, possibly using single-model evaluations or more sophisticated statistical analysis, is a critical area of research to enable accurate evaluation of memorization in machine learning models and improve their reliability.
One-Model Approach#
The “One-Model Approach” presented offers a significant advancement in evaluating memorization in representation learning models. By cleverly circumventing the need for training a second model to establish dataset-level correlations, as required by the two-model approach, it drastically reduces computational cost and data requirements. This is particularly crucial when dealing with large-scale, open-source models. The proposed approach utilizes either a simple image classification network or a Naive Bayes classifier trained on a subset of the training data. These models effectively quantify dataset-level correlations, enabling the efficient measurement of memorization without the need for extensive retraining. This innovation makes memorization analysis significantly more accessible and scalable, unlocking new possibilities for evaluating various models. However, the accuracy of the one-model approach is dependent on the choice of the reference model and its ability to accurately capture dataset-level correlations. While comparative results show a good degree of agreement with the traditional two-model approach, a potential limitation is that the one-model approach might exhibit greater sensitivity to certain inductive biases and noise which could affect its overall reliability. Therefore, using the one-model method in conjunction with multiple reference models is advisable to ensure the robustness and accuracy of the results. Further research is needed to explore the limitations and potential improvements.
Open-Source Models#
The study of open-source models reveals crucial insights into the memorization capabilities of large language models. The researchers found that these models, despite being trained on massive datasets, exhibit significantly lower aggregate memorization compared to models trained on smaller subsets of the same data. This suggests a correlation between dataset size and memorization, highlighting the importance of dataset diversity and size for generalization. The results emphasize the robustness of open-source models, implying that the widespread availability of these models does not necessarily equate to a significant increase in memorization risks. This finding is particularly important considering the growing adoption of open-source models for various applications, and underlines the need for further research to fully understand the interplay between model architecture, training data, and memorization tendencies. The study’s methodology, employing efficient one-model tests instead of computationally expensive two-model approaches, makes the analysis readily scalable and applicable to a wide range of open-source models. This enhanced efficiency is a valuable contribution that allows for more extensive evaluation and comparison of memorization across different models.
Dataset-Level Correlation#
Dataset-level correlation is a crucial concept in evaluating memorization within machine learning models. It refers to the inherent relationships between different data points, which exist regardless of the model’s training. Failing to account for these correlations can lead to an overestimation of a model’s memorization ability. The challenge lies in distinguishing between a model’s true memorization of training data and its ability to predict outcomes based on these pre-existing dataset-level correlations. The paper explores various methods to accurately quantify these correlations, enabling a more precise measurement of memorization. Effective methods for quantifying dataset-level correlations are essential for developing robust memorization tests. Accurate assessment is critical for building more generalized and trustworthy AI models.
Future Directions#
Future research could explore more sophisticated methods for estimating dataset-level correlations, potentially leveraging advanced machine learning techniques or incorporating prior knowledge about the data distribution. Investigating the interplay between different memorization measurement methods and their respective strengths and weaknesses is crucial for developing a more robust and comprehensive understanding of memorization. Furthermore, research should focus on developing more effective techniques for mitigating memorization in large language models, perhaps by incorporating regularization strategies during training or employing data augmentation to improve generalization. The impact of memorization on the fairness and robustness of models deserves further investigation, along with exploring the potential societal implications of unintentionally memorizing sensitive training data. Finally, extending the current memorization measurement framework to other types of machine learning models and exploring the connection between memorization and other properties like model robustness and efficiency will provide valuable insights for the field.
More visual insights#
More on figures
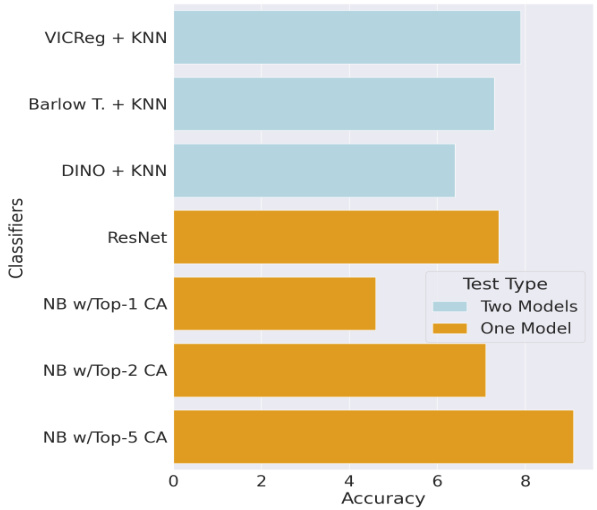
This figure presents a comparison of population-level correlation accuracy across different models using two different test types: a two-model test and a one-model test. The two-model test utilizes KNN on VICReg, Barlow Twins, and DINO representations, while the one-model test employs ResNet50 and a Naive Bayes classifier. The left panel displays the accuracy scores, showing that ResNet50 and Naive Bayes with top-2 classifications perform similarly to VICReg and Barlow Twins. The right panel shows the top 5 predicted dataset-level correlation classes and their corresponding percentages.
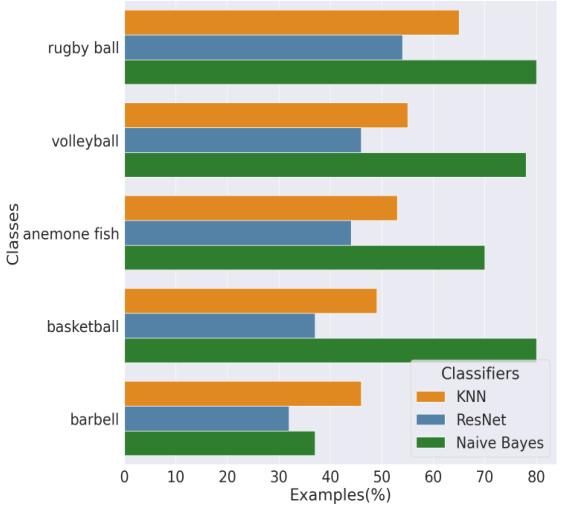
This figure presents a comparison of population-level correlation accuracy across different models, using both two-model and one-model tests. The left panel shows the accuracy scores, highlighting the similarity between ResNet50/Naive Bayes and VICReg/Barlow Twins. The right panel displays the top 5 predicted dataset-level correlation classes and the percentage of examples in each class that show correlation.
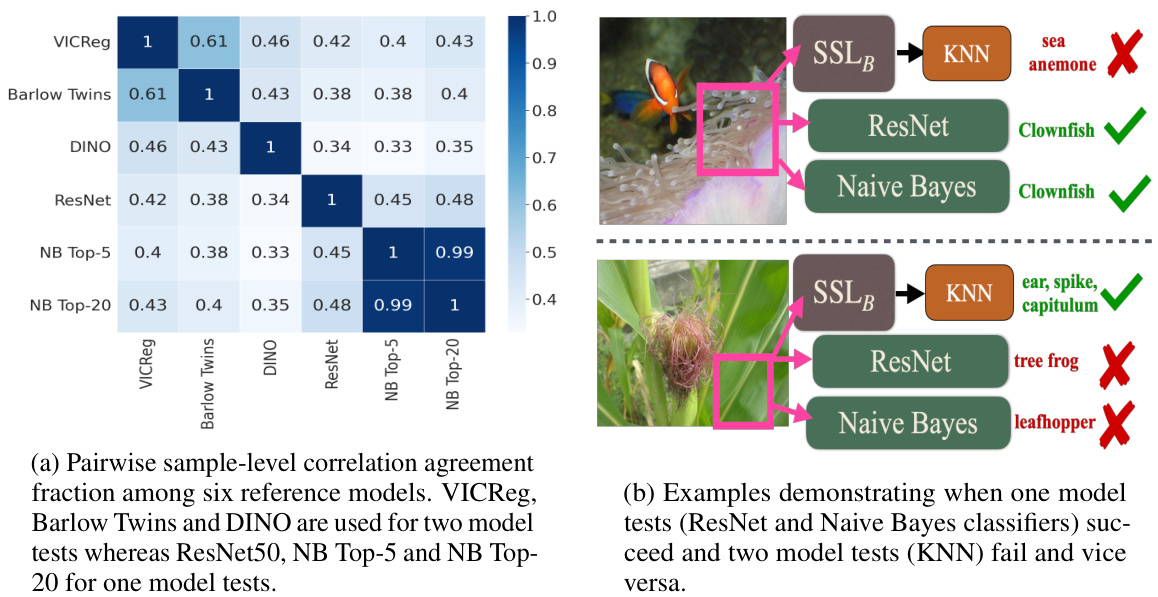
This figure shows two subfigures. The left one shows a heatmap representing the pairwise sample-level correlation agreement among different models in predicting dataset-level correlations. The right one shows examples where one-model tests (ResNet and Naive Bayes) are successful in predicting the foreground object from the background crop, while two-model tests (KNN) fail and vice versa. It highlights the different strengths and weaknesses of the two approaches in various scenarios, especially dealing with ambiguous relationships between foreground and background.
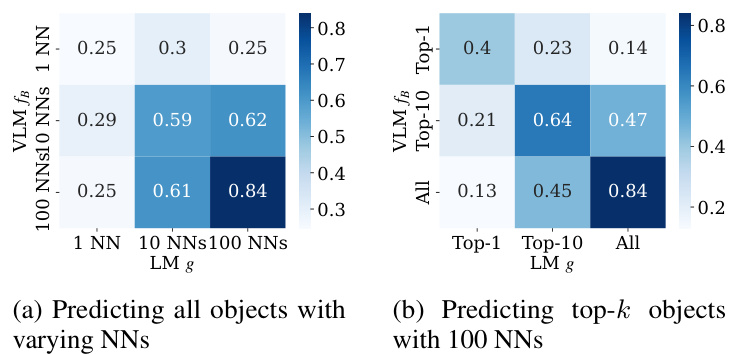
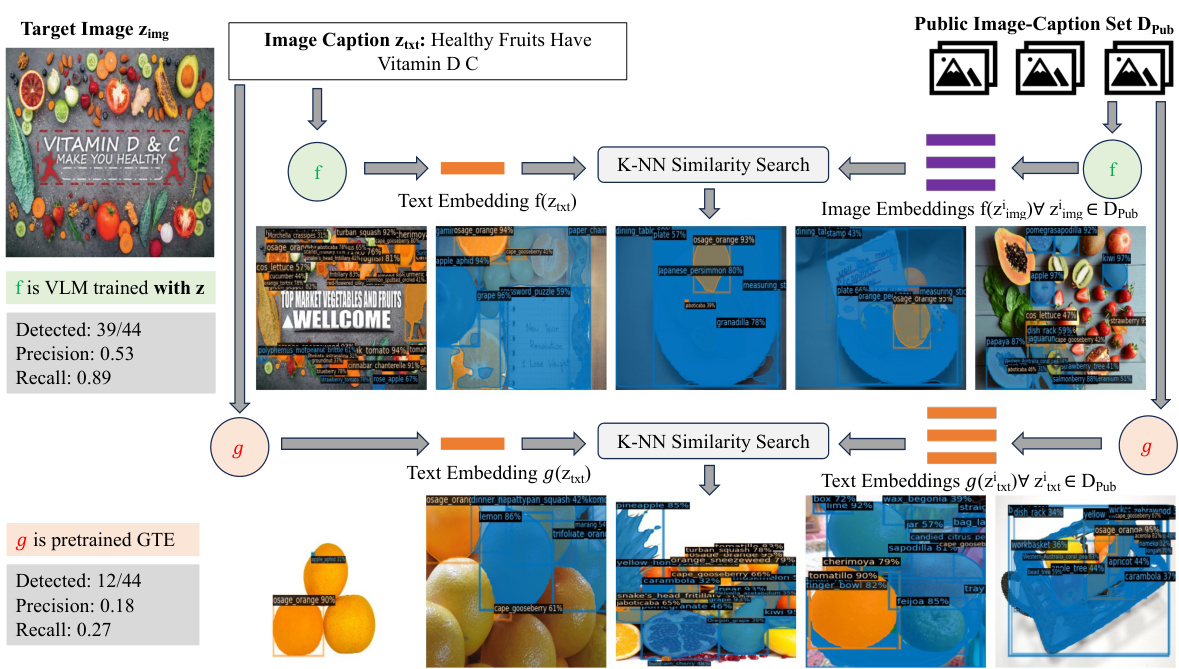
This figure compares the performance of a two-model test (using a reference VLM fB) and a one-model test (using a GTE language model g) for predicting objects in images based on their captions. The heatmaps show pairwise sample-level agreement, indicating the level of consistency between the two methods in their predictions. The results suggest that the one-model test, which is computationally less expensive, can provide a reasonable approximation of the memorization measured by the more expensive two-model test.
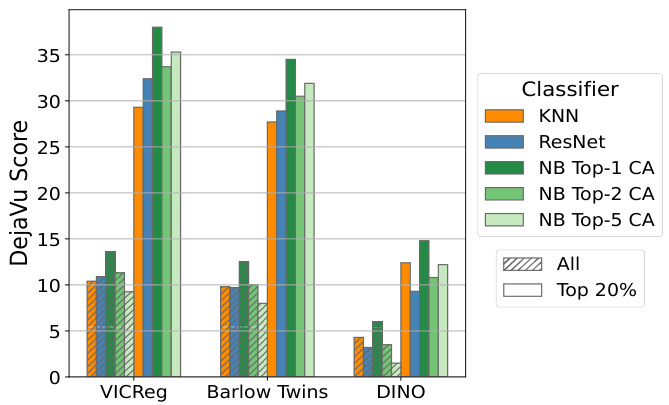
This figure compares the overall and top 20% most confident DejaVu scores obtained using one-model and two-model tests on three different self-supervised learning (SSL) models (VICReg, Barlow Twins, and DINO) trained on a 300k subset of ImageNet. The one-model tests utilize a ResNet classifier and a Naive Bayes classifier with varying numbers of top-k crop annotations, while the two-model test employs a KNN classifier. The comparison helps to assess the consistency of memorization measurement across different methods.

This figure compares the overall and top 20% most confident DejaVu scores obtained using one-model tests (ResNet classifier and Naive Bayes with top k crop annotations) and two-model tests (KNN classifier) for three different self-supervised learning models: VICReg, Barlow Twins, and DINO. The models were trained on a 300k subset of the ImageNet dataset. The DejaVu score reflects the degree of memorization, with higher scores indicating more memorization. The comparison helps assess the consistency and accuracy of different memorization measurement approaches.

This figure compares the population-level memorization results for various Vision-Language Models (VLMs) using two different evaluation metrics: Population Precision Gap (PPG) and Population Recall Gap (PRG). It shows the results for predicting the top-1, top-10, and all objects in a dataset. The results are broken down into two model tests and one model tests, providing a comparison of the two approaches.

This figure compares the overall and top 20% most confident déjà vu (memorization) scores obtained using one-model tests (ResNet and Naive Bayes classifiers with varying numbers of top-k crop annotations) and a two-model test (KNN classifier). The comparison is performed for three different self-supervised learning models: VICReg, Barlow Twins, and DINO, all trained on a 300k subset of the ImageNet dataset. The results illustrate how closely the one-model and two-model test results align and provide insights into memorization levels for different models.
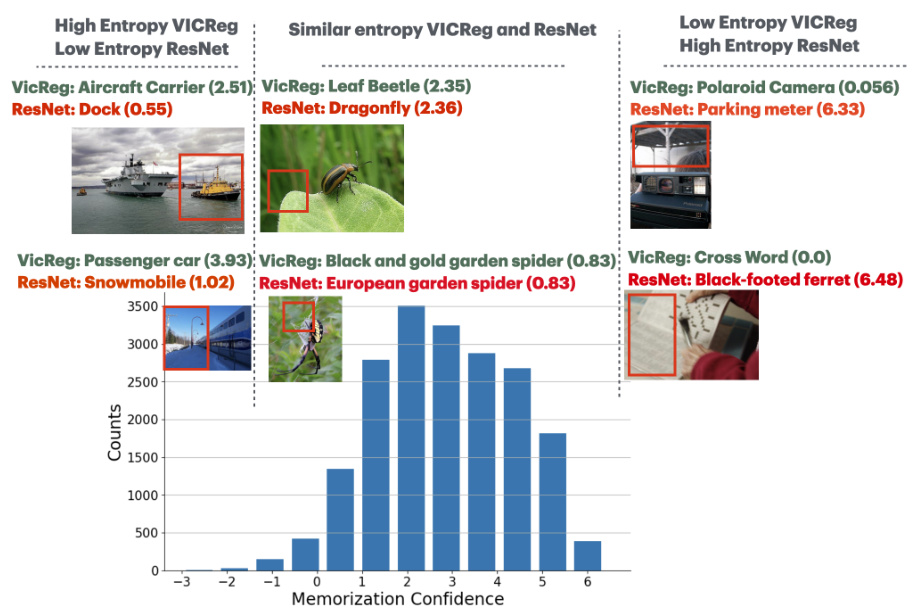
This figure visualizes the distribution of memorization confidence scores for pre-trained VICReg OSS model with ResNet as correlation detector. The memorization confidence for each example is computed as the difference between the entropy of the correlation classifier and the entropy of the KNN classifier. The histogram shows that memorized examples with high memorization confidence scores are rarer and more likely to be memorized. Examples in the middle of the distribution are easier to confuse with another class, while those with negative memorization confidence have higher memorization and slightly lower correlation entropy.

This figure visualizes the distribution of memorization confidence scores for a pre-trained VICReg OSS model. The x-axis represents the top-L records (samples sorted from high to low memorization confidence), and the y-axis shows precision, recall, and F-score gaps. Positive gaps indicate that the target model memorizes the training sample; larger gaps suggest higher degrees of memorization. Different lines represent different numbers of nearest neighbors (NNs) used in the similarity search during the evaluation process.

This figure demonstrates two examples of common dataset-level correlations identified by the ResNet and Naive Bayes classifiers. The first correlation shows a strong association between images containing stoves or kitchens and the presence of microwaves. The second correlation shows that images with skies, poles, and water are frequently associated with gondolas. These correlations, learned by the classifiers, highlight the ability of the models to predict foreground objects based solely on background information, even in the absence of explicit memorization.

This figure illustrates a one-model déjà vu test. The task is to predict the foreground object given only the background crop of an image. The figure shows that while KNN correctly predicts the foreground object, ResNet and Naive Bayes classifiers fail, indicating memorization.

This figure shows five examples of images that the VICReg OSS model memorized. For each image, the original image is shown alongside its corresponding background crop. The labels of the objects are also shown. The caption indicates that neither the Naive Bayes nor ResNet classifiers could predict the correct object label based on the background crop alone, suggesting that the model memorized the association between the background and foreground object in these cases.
This figure illustrates the proposed one-model approach for measuring déjà vu memorization in image representation learning. It contrasts the original two-model method (which trains two separate models on disjoint datasets to assess dataset-level correlations) with the new one-model method. The one-model method uses a single classifier (either a ResNet50 or a Naive Bayes classifier) trained to directly predict the foreground object from the background crop, eliminating the need for training a second model for correlation estimation. This simplification allows efficient memorization measurement on large, pre-trained models.

This figure illustrates the proposed one-model déjà vu test, which simplifies the original two-model approach by replacing the second model with a classifier directly predicting foreground objects from background crops. It contrasts the two-model approach, which trains separate models on disjoint data splits to measure dataset-level correlations, with the proposed one-model test’s more efficient single-classifier approach.

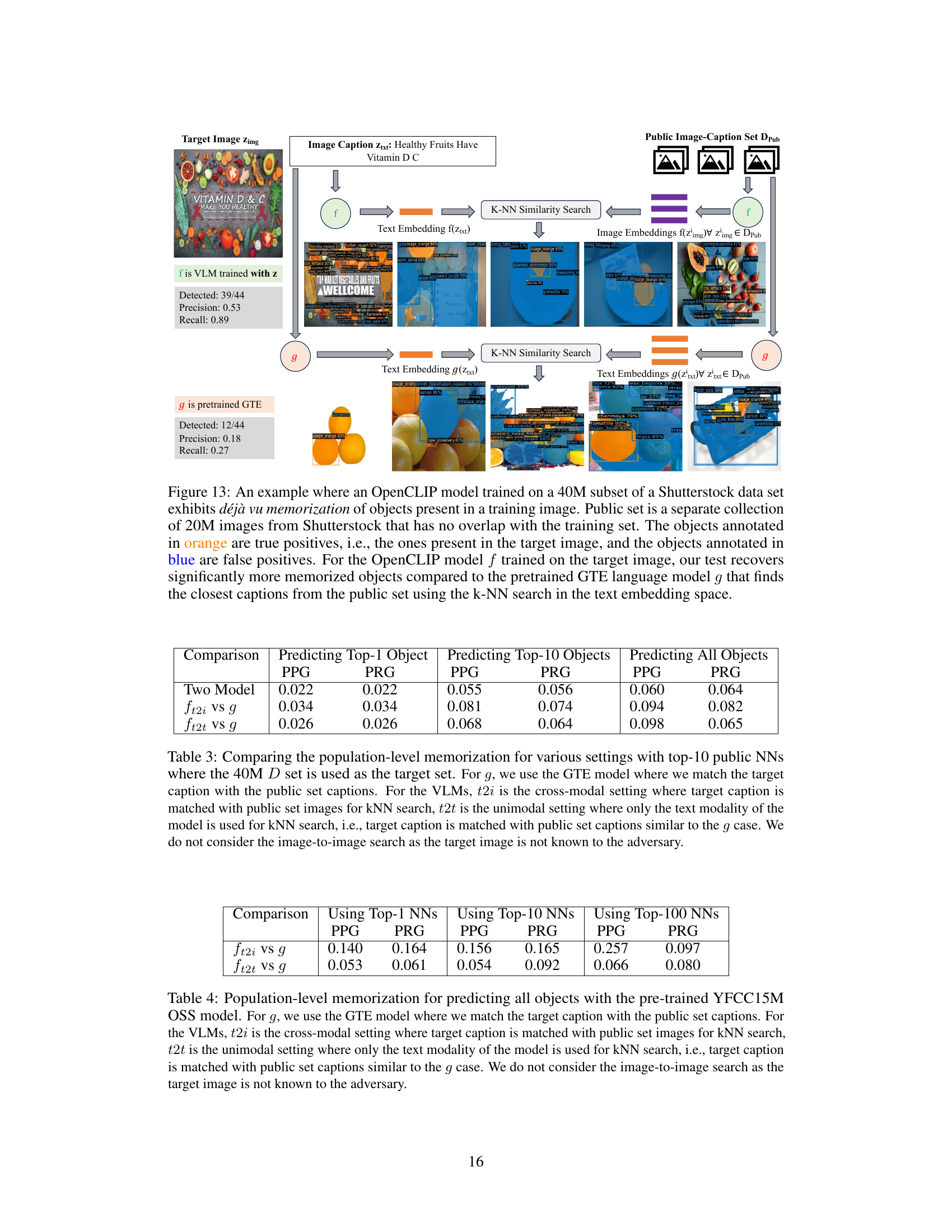
This figure presents several examples to illustrate how well the Large Language Model (LLM) and the Vision-Language Model (VLM) capture correlations for predicting objects in images. Each example shows a target image and its caption. Then, the top 5 nearest neighbors (NNs) from a public dataset are displayed for both the VLM and LLM, along with the predicted labels and the number of objects recovered, precision, and recall. Comparing the results of the VLM and LLM across different images highlights their strengths and weaknesses in capturing correlations and predicting objects based on textual descriptions.

This figure illustrates the proposed one-model déjà vu test, comparing it to the original two-model approach. The task remains predicting the foreground object from only the background. The key difference is that the new method uses a single classifier (ResNet50 or Naive Bayes) trained to directly predict the foreground, eliminating the need for training a second model to estimate dataset-level correlations.
More on tables

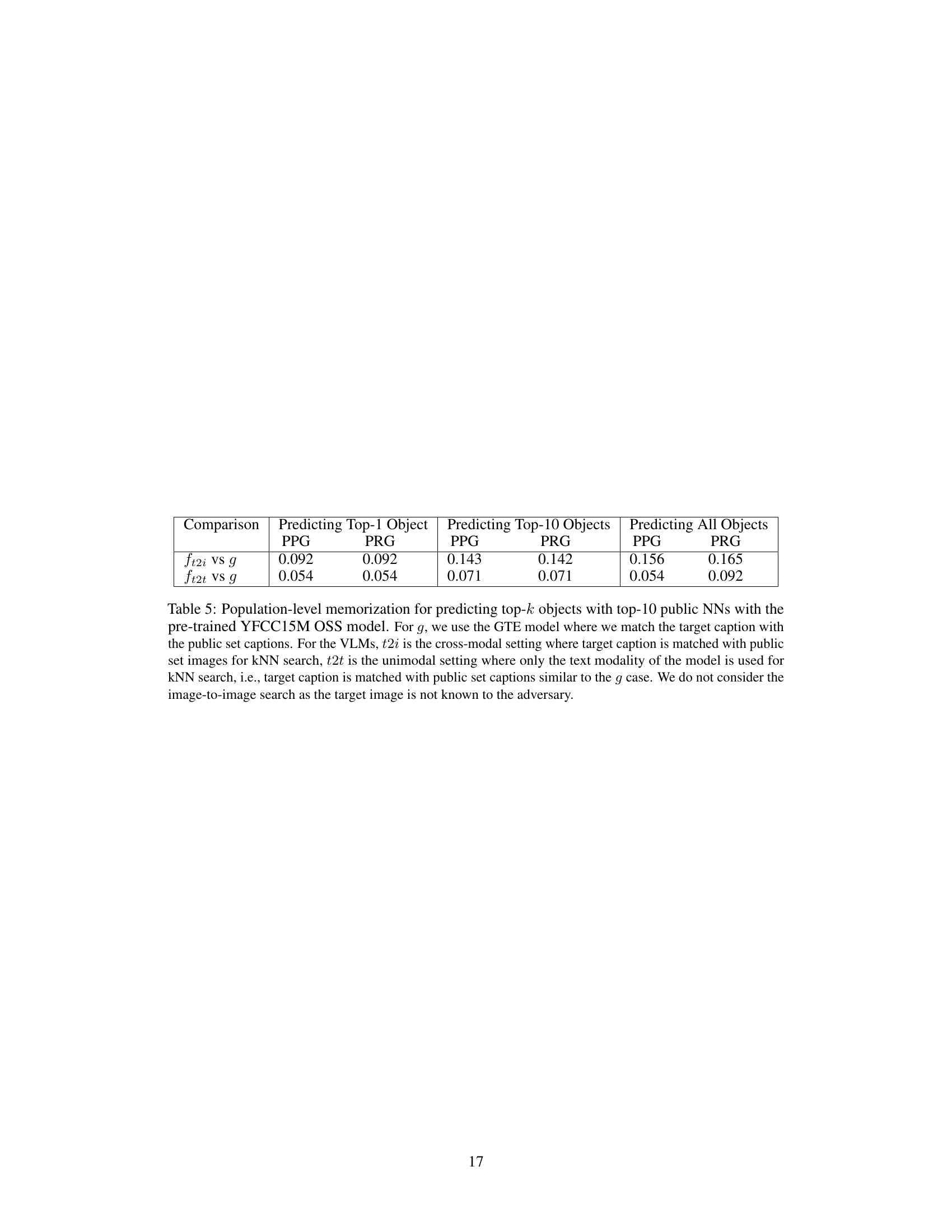
This table compares population-level memorization results for predicting all objects using different methods. It uses a 40M subset (D) for the target set and compares a two-model test with two one-model tests (ft2i vs g and ft2t vs g). The GTE model is used for g, matching target captions with public set captions. The VLMs use cross-modal (ft2i) and unimodal (ft2t) settings. Image-to-image search is not used because the target image is unknown to the adversary. The table shows PPG and PRG values for each method using Top-1, Top-10 and Top-100 nearest neighbors (NNs).

This table compares the population-level memorization results (PPG and PRG) for different experimental settings in a vision-language model (VLM). It contrasts a two-model approach with a one-model approach using a pre-trained GTE language model (g) as a reference. The comparison is made across three scenarios: predicting the top-1, top-10, and all objects. The results highlight how the different methods and settings affect the quantification of memorization.

This table presents the population-level memorization results for predicting all objects using different numbers of nearest neighbors (NNs) from a public set. It compares the performance of a two-model test (using a Vision Language Model, or VLM) against a one-model test (using a pre-trained Generalized Text Embedding, or GTE, language model). The results show the Population Precision Gap (PPG) and Population Recall Gap (PRG) for both methods under various settings. The ’t2i’ setting represents cross-modal retrieval, while ’t2t’ represents unimodal (text-only) retrieval. The table highlights the differences between the two methods and explores their memorization capabilities in different retrieval scenarios.

This table presents a comparison of population-level memorization results for different settings using top-10 nearest neighbors from a public set. It contrasts a two-model approach with a one-model approach using a pre-trained language model (GTE) as a reference, showing results for predicting top-1, top-10, and all objects. The comparison considers cross-modal and unimodal settings for the VLMs, highlighting that the image-to-image search was excluded because the target image was unknown to the adversary.
Full paper#