↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vector quantization (VQ) methods for image synthesis primarily focus on learning single-modal codebooks (e.g., image-only), leading to suboptimal performance in multi-modal applications like text-to-image generation. These methods struggle to effectively handle the differences between visual and textual data, resulting in a ‘modal gap’.
This paper introduces LG-VQ, a novel language-guided codebook learning framework that tackles this issue. LG-VQ leverages pre-trained text semantics to guide the codebook learning process, using two novel alignment modules to bridge the visual-textual gap. Experimental results demonstrate that LG-VQ significantly enhances performance on reconstruction and various multi-modal downstream tasks, showcasing its effectiveness and potential to advance multi-modal learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing single-modal codebooks in multi-modal tasks by introducing a novel language-guided codebook learning framework. This framework, LG-VQ, significantly improves the performance of various multi-modal downstream tasks such as text-to-image generation and image captioning, opening new avenues for research in unified multi-modal modeling. The model-agnostic nature of LG-VQ allows for easy integration into existing VQ models, making it widely applicable and potentially impactful for a broad range of researchers.
Visual Insights#
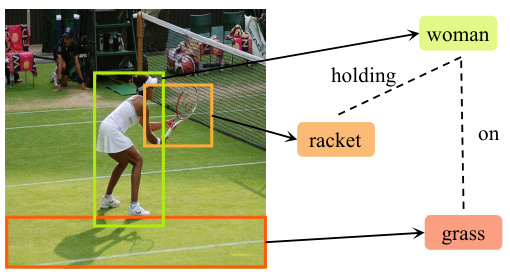
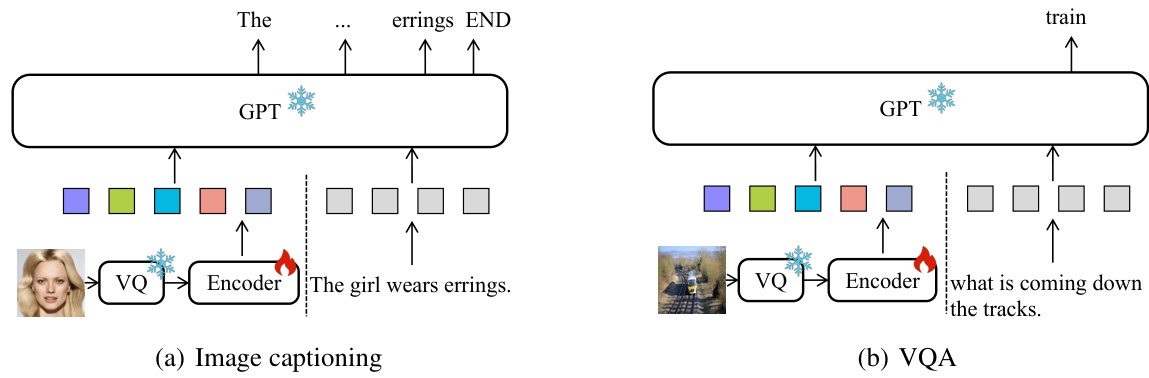
This figure shows an example of a visual question answering (VQA) task. The image shows a woman holding a tennis racket on a grass court. To answer the question “What is this woman holding?”, a model needs not only identify the objects ‘woman’ and ‘racket’, but also understand the semantic relationship between them, i.e., the woman is ‘holding’ the racket. This illustrates the importance of considering semantic relationships in multi-modal tasks.
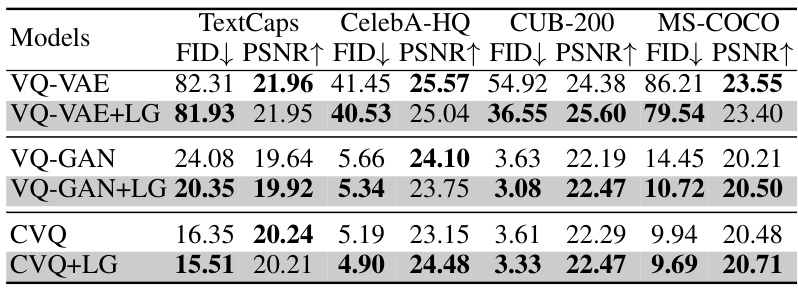
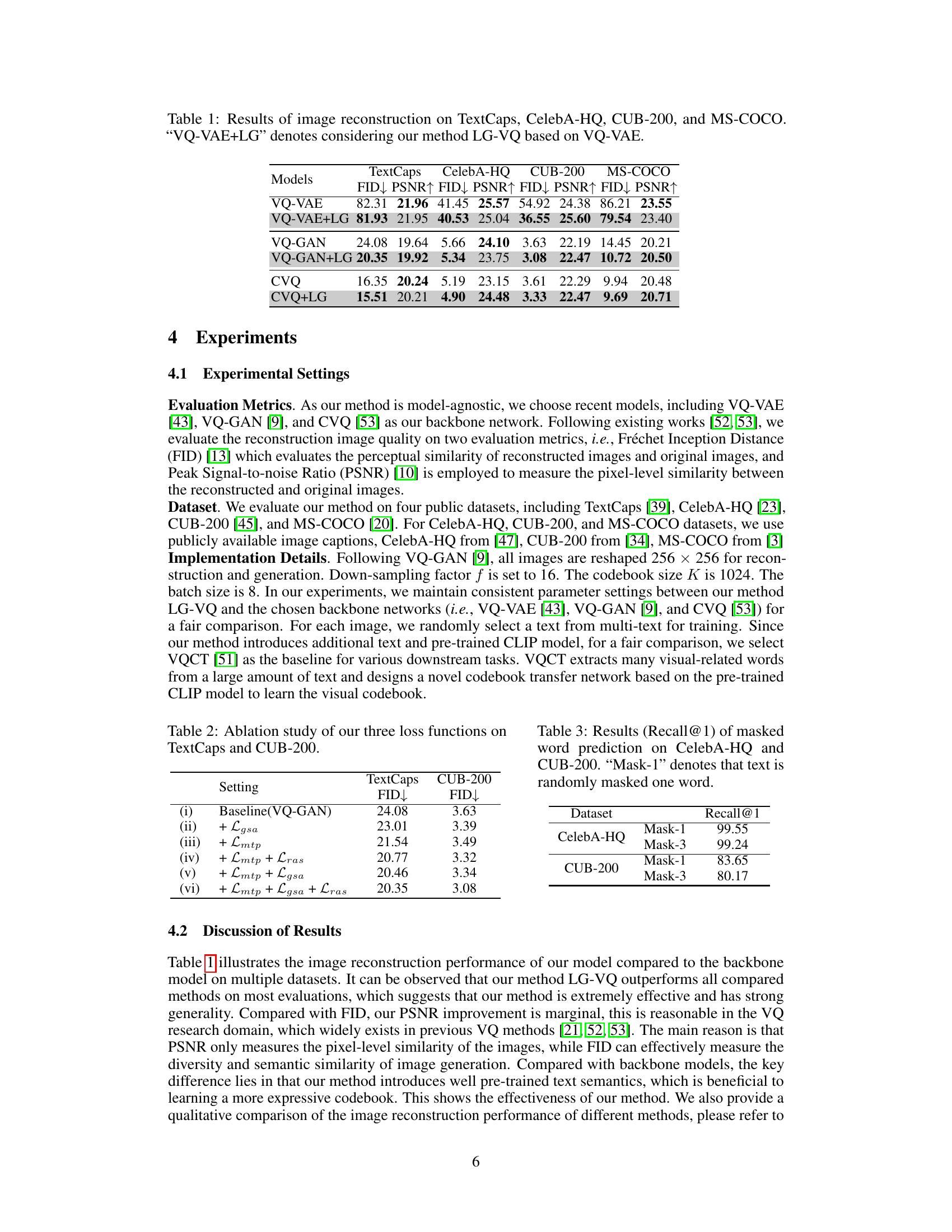
This table presents the results of image reconstruction experiments performed using four different models: VQ-VAE, VQ-VAE+LG, VQ-GAN, and VQ-GAN+LG. The evaluation metrics used are Fréchet Inception Distance (FID) and Peak Signal-to-noise Ratio (PSNR). Lower FID scores indicate better perceptual similarity to the original images, while higher PSNR values indicate better pixel-level similarity. The experiments were conducted on four datasets: TextCaps, CelebA-HQ, CUB-200, and MS-COCO, allowing for a comprehensive evaluation of the models’ performance across different image types and complexities.
In-depth insights#
LG-VQ Framework#
The LG-VQ framework presents a novel approach to codebook learning in vector quantization (VQ) models, specifically designed to address limitations in multi-modal tasks. Its core innovation lies in integrating pre-trained text semantics to guide the learning process, thereby bridging the semantic gap between visual and textual modalities. This is achieved through two key alignment modules: the Semantic Alignment Module, which enhances global semantic consistency via global semantic alignment and masked text prediction, and the Relationship Alignment Module, which injects semantic relationships between words directly into the codebook. The framework’s model-agnostic nature allows for easy integration with existing VQ models, making it highly versatile and applicable to a wide range of multi-modal applications. By effectively leveraging pre-trained text embeddings and focusing on semantic alignment at both global and relational levels, LG-VQ aims to learn a codebook that is far more expressive and robust to modal gaps, thus significantly improving performance on various downstream tasks such as text-to-image synthesis and image captioning. The superior performance showcased in experimental results on multiple benchmarks underscores the efficacy of the proposed methodology, highlighting its potential to advance the field of multi-modal learning.
Alignment Modules#
The core of the LG-VQ framework lies in its novel alignment modules, designed to bridge the semantic gap between visual codebooks and textual representations. These modules don’t simply align global semantics; they delve into the intricacies of relationships between words. The Semantic Alignment Module focuses on establishing consistency at a holistic level, using a pre-trained model to encode text semantics and aligning these with visual code representations through global semantic alignment and masked text prediction. This ensures that the codebook captures rich semantic information from the text. However, simple global alignment is insufficient for complex reasoning tasks. Therefore, the Relationship Alignment Module is introduced, inspired by VQA techniques. This module elegantly transfers the semantic relationships between words into the codebook, allowing the model to better understand the image. The model-agnostic design is a key strength, enabling straightforward integration into existing VQ models, enhancing their multi-modal capabilities. This dual-pronged approach ensures that the resulting codebook is not only rich in low-level visual information, but also deeply grounded in high-level semantic understanding derived from the text, dramatically improving performance on multi-modal tasks.
Multi-modal Gains#
The concept of “Multi-modal Gains” in a research paper likely refers to the advantages achieved by combining multiple modalities, such as text, images, and audio, within a single model or system. A thoughtful analysis would explore how these gains manifest. Do the combined modalities improve performance on downstream tasks such as image captioning or question answering beyond what’s achievable with unimodal approaches? Are the gains additive, synergistic, or even subtractive in certain scenarios? Does the paper delve into potential limitations? For instance, does increased complexity lead to more difficult training or higher computational costs? Are there specific architectural choices that amplify or diminish these multi-modal gains? Understanding the tradeoffs between multi-modal enhancements and potential drawbacks is crucial. A comprehensive analysis should critically assess how the paper quantifies and validates its claims of multi-modal gain, including any methodological choices that could affect the results. Finally, it should determine the generalizability of these gains to other datasets and tasks, discussing the robustness and broad applicability of the reported multi-modal advantages.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a codebook learning framework like LG-VQ, an ablation study would likely assess the impact of each module (Semantic Alignment Module, Relationship Alignment Module) and loss function (global semantic alignment loss, masked text prediction loss, relationship alignment supervision loss) by removing them individually or in combination and observing the effects on performance metrics such as FID and PSNR. The results would reveal whether each component is crucial for the overall performance gains of LG-VQ. A well-executed ablation study is vital to understand the model’s inner workings and the relative importance of its different aspects. This helps determine which components are most beneficial and can be retained, while identifying and potentially removing less significant components to streamline or improve the model’s efficiency and interpretability. The absence of a clear impact from a particular component might signal redundancy or potential areas for further refinement, while observing substantial performance drops when removing a component highlights its critical role in achieving optimal results. Therefore, careful design and interpretation of an ablation study are essential for validating and comprehending a complex method like LG-VQ.
Future Works#
The paper’s success in aligning language and visual codes through a multi-modal codebook learning framework opens exciting avenues for future research. Extending LG-VQ to handle more complex reasoning tasks, such as visual question answering and visual commonsense reasoning, is a crucial next step. This would involve incorporating more sophisticated semantic relationship modeling and potentially exploring more advanced architectures like transformers to better capture long-range dependencies. Investigating the impact of different pre-trained language models on LG-VQ’s performance is also vital, allowing researchers to assess the influence of varying semantic representations on codebook quality and downstream task success. Additionally, a thorough evaluation across a wider range of datasets is essential to fully demonstrate the robustness and generalizability of LG-VQ. Finally, exploring the potential of integrating LG-VQ with other generative models to create novel and more powerful applications, such as high-fidelity text-to-image generation, opens up an avenue for highly impactful future work.
More visual insights#
More on figures

The figure shows the architecture of the Language-Guided Vector Quantization (LG-VQ) model. The right side depicts the standard VQ-VAE (Vector Quantized Variational Autoencoder) architecture, which encodes an image into a sequence of discrete codes using an encoder and a codebook, and then reconstructs the image using a decoder. The left side shows the LG-VQ’s additions: a language-guided module that leverages pre-trained text semantics. This module consists of three loss functions: global semantic alignment (Lgsa), masked text prediction (Lmtp), and relationship alignment (Lras). These losses aim to align the image codebook with the text semantics, improving the model’s ability to handle multi-modal tasks. The pre-trained text is processed to obtain text semantics, which are then integrated into the codebook learning process via these three loss functions.

This figure illustrates the process of the Relationship Alignment Module in LG-VQ. It shows how semantic relationships between words are transferred into the codebook (Z). First, the visual tokens (Zvt) are aligned with words using a similarity measure. Then, the semantic relationship between these words is calculated. Finally, this relationship is used to adjust the codebook embeddings (Z) to better capture the relationships between words, enhancing the alignment between the visual tokens and text.

This figure illustrates the architecture of the Language-Guided Vector Quantization (LG-VQ) method. The architecture is divided into two main parts: a basic VQ-VAE module (right) and a language-guided module (left). The VQ-VAE module is a standard vector quantization model for image reconstruction, while the language-guided module incorporates pre-trained text information to guide the codebook learning process. The language-guided module consists of three loss functions: global semantic alignment (Lgsa), masked text prediction (Lmtp), and relationship alignment supervision (Lras). These losses work together to align the learned codebook with the input text, resulting in a multi-modal codebook that can be used for various downstream tasks. In essence, the pre-trained text helps the model learn richer semantic information for improved performance in downstream, multi-modal tasks.

This figure illustrates the process of the Relationship Alignment Module. First, the visual tokens (Zvt) are aligned with words using a pre-trained word embedding. Then, the semantic relationship between those two words is calculated. Finally, this semantic relationship is injected into the original codebook (Z) to further refine the alignment between visual and textual information. This step helps improve the model’s performance on complex reasoning tasks by incorporating relational context.

This figure illustrates the architecture of the Language-Guided Vector Quantization (LG-VQ) model. The model consists of two main parts: a basic VQ-VAE module (right) and a language-guided module (left). The VQ-VAE module is responsible for encoding images into discrete code tokens. The language-guided module takes pre-trained text semantics as input and uses three losses (global semantic alignment, masked text prediction, and relationship alignment) to guide the codebook learning process. This alignment ensures the codebook effectively captures rich semantic information from the text, leading to improved performance in multi-modal downstream tasks.
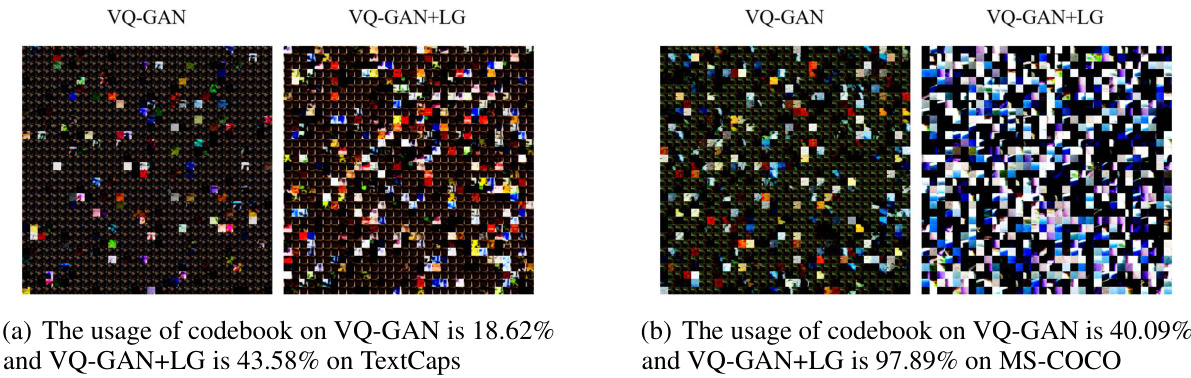
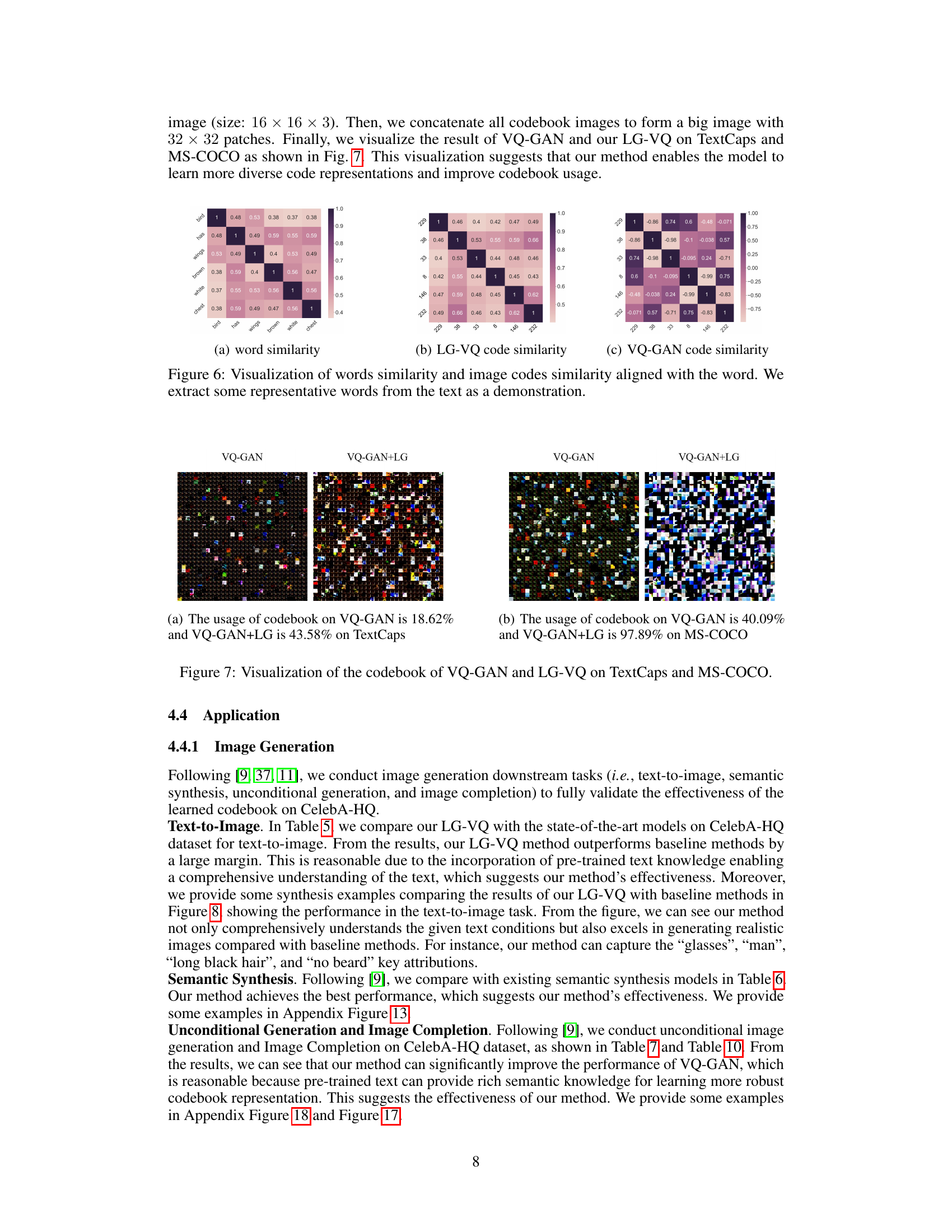
This figure visualizes the codebooks learned by VQ-GAN and LG-VQ on two datasets: TextCaps and MS-COCO. The visualization shows that LG-VQ leads to a more diverse and effectively utilized codebook compared to VQ-GAN. For TextCaps, VQ-GAN uses only 18.62% of its codebook, while LG-VQ uses 43.58%. The difference is even more pronounced on MS-COCO, where VQ-GAN uses 40.09% of its codebook, compared to 97.89% for LG-VQ. This indicates that LG-VQ learns a more comprehensive and representative codebook.

This figure shows the results of text-to-image and semantic image synthesis experiments performed on the CelebA-HQ dataset using four different models: VQ-GAN, VQ-GAN+LG, CVQ, and CVQ+LG. The text conditions are shown above each set of generated images. The images generated by VQ-GAN+LG and CVQ+LG, which incorporate the proposed LG-VQ method, appear to better capture the details specified in the text conditions, such as hair color, facial features, and accessories. The background color highlights these details.
This figure shows the overall architecture of the proposed LG-VQ model. The model combines a basic VQ-VAE (vector quantization variational autoencoder) module with a language-guided module. The language-guided module uses three losses to incorporate pre-trained text semantics into the codebook: global semantic alignment, masked text prediction, and relationship alignment. This alignment improves the learning of multi-modal knowledge and enhances performance on downstream tasks.

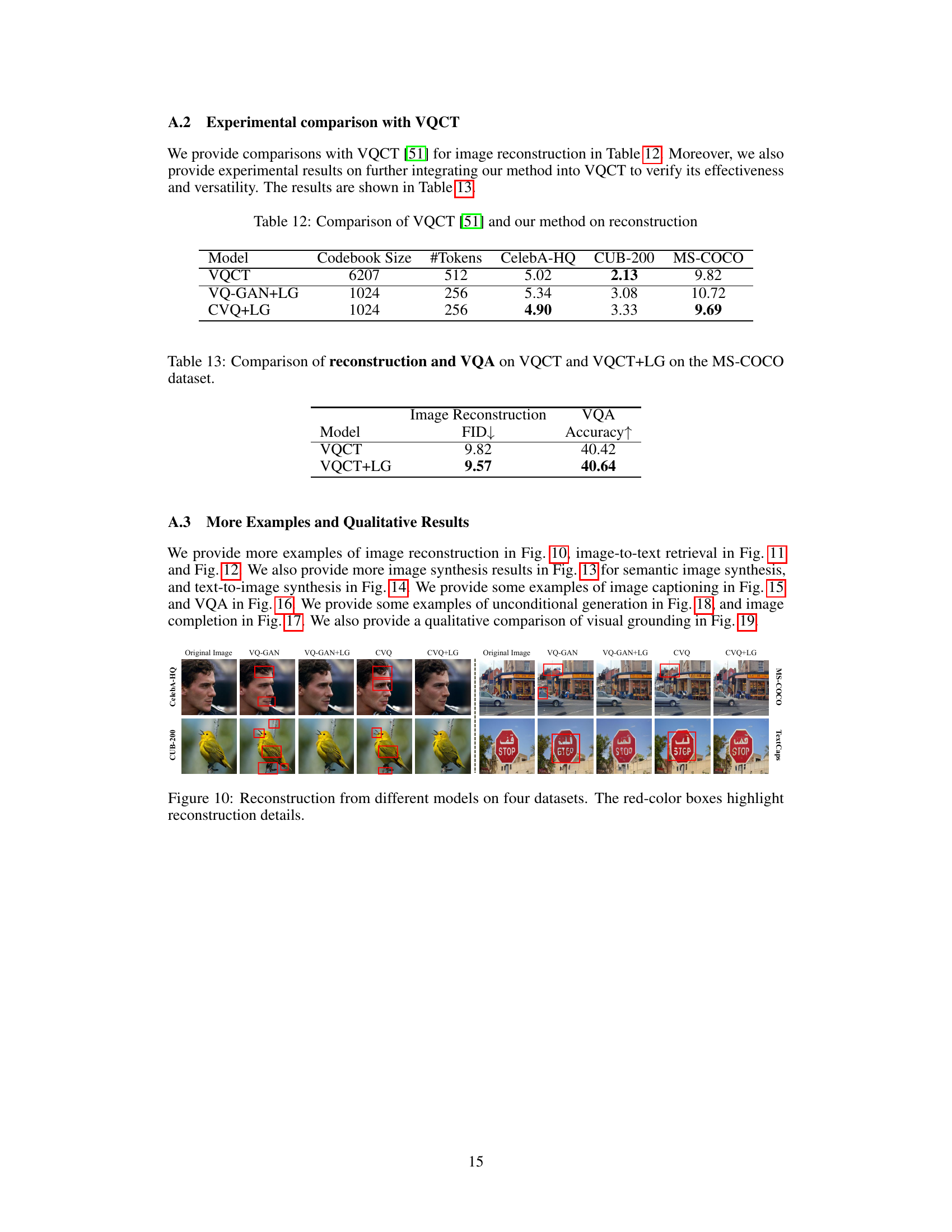
This figure shows the image reconstruction results from four different models (VQ-GAN, VQ-GAN+LG, CVQ, and CVQ+LG) on four datasets (CelebA-HQ, CUB-200, MS-COCO, and TextCaps). The red boxes highlight the reconstruction details, showing where the models struggle or succeed in reconstructing the images. This helps in visually comparing the performance of the different models on different types of images.

This figure shows the architecture of the proposed LG-VQ model. The model is composed of two main modules: a basic VQ-VAE module and a language-guided module. The VQ-VAE module is responsible for encoding and decoding images using a codebook. The language-guided module uses pre-trained text semantics to guide the learning of the codebook, aiming to improve the performance of multi-modal downstream tasks. The language-guided module uses three losses: global semantic alignment loss, masked text prediction loss, and relationship alignment supervision loss. These losses help to align the codebook with text semantics, resulting in a more expressive codebook.

This figure illustrates the architecture of the Language-Guided Vector Quantization (LG-VQ) model. The architecture is divided into two main parts. The right side shows the standard VQ-VAE (Vector Quantized Variational Autoencoder) module responsible for encoding and decoding images. The left side shows the novel language-guided module which incorporates pre-trained text semantics to improve the quality of the codebook. This module uses three loss functions: global semantic alignment (Lgsa), masked text prediction (Lmtp), and relationship alignment supervision (Lras) to align the codebook with the text, thereby leveraging rich semantic information from the text to enhance the quality and multi-modal capabilities of the codebook.

This figure shows the results of semantic image synthesis on the CelebA-HQ dataset using different methods. The results demonstrate that the proposed LG-VQ method can generate high-quality images with specific semantic attributes. The figure is divided into several rows, each row showing the results for a different image. Each row consists of three columns. The first column shows the input image, the second column shows the output generated by VQ-GAN+LG, and the third column shows the output generated by CVQ+LG. The images are accompanied by masks representing the semantic segmentation of the input image. Each mask represents different semantic attributes. In the figure, the masks and generated images can be seen to be well aligned with the semantic attributes of the input images.

This figure shows the results of text-to-image synthesis and semantic image synthesis experiments conducted using the CelebA-HQ dataset. The top row demonstrates text-to-image generation where the model generates images based on given text descriptions. The text descriptions are shown in light-blue boxes above each image, highlighting specific features or attributes. The bottom row showcases semantic image synthesis, where the model generates images corresponding to the given semantic descriptions (also shown in light-blue boxes). The color of the text background highlights the features mentioned in the descriptions. The purpose is to illustrate that the model can accurately generate images that closely match both the text and semantic attributes.

This figure shows a qualitative comparison of image captioning results on the CUB-200 dataset using VQ-GAN and the proposed LG-VQ model. For each image, the automatically generated captions from both models are displayed, highlighting the differences in the descriptions produced by each model. The LG-VQ model incorporates language-guided codebook learning, aiming to improve the quality and accuracy of the generated captions.

This figure visualizes the similarity between words and their corresponding image codes in the LG-VQ model. The top row shows a similarity matrix for words, highlighting the semantic relationships between them. The bottom row displays the similarity between the codes and words after alignment through the model, demonstrating how the model learns to capture semantic information from text and integrate it into its representation of images. The figure provides evidence of successful text-image alignment and the capability of the LG-VQ model to learn meaningful relationships between semantic representations of text and visual features.

This figure shows the image reconstruction results from four different models (VQ-GAN, VQ-GAN+LG, CVQ, CVQ+LG) on four datasets (TextCaps, CelebA-HQ, CUB-200, MS-COCO). The red boxes highlight specific details to illustrate the differences in reconstruction quality between the models. This helps in visually comparing the performance of the proposed LG-VQ method against existing methods on various datasets and image types.

This figure compares the image reconstruction results of four different models (VQ-GAN, VQ-GAN+LG, CVQ, CVQ+LG) on four different datasets (TextCaps, CUB-200, CelebA-HQ, MS-COCO). Red boxes highlight details to emphasize the differences in reconstruction quality between the models and datasets. It visually demonstrates the improved reconstruction capability of the proposed LG-VQ method by comparing it to the baseline models.

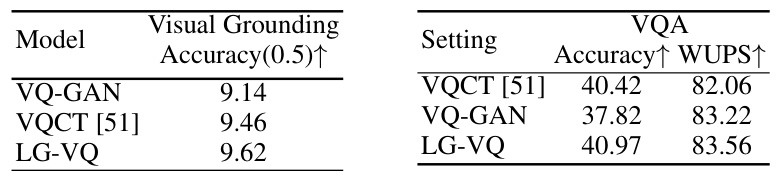
This figure shows the results of visual grounding experiments on the refcoco dataset. The task involves locating specific objects within an image based on a textual description. For each image, the ground truth bounding box (blue) for the described object is shown next to the model’s prediction (red). By visually comparing the two, one can assess the model’s accuracy in locating the correct object based on the textual cue. This demonstrates the performance of the LG-VQ model in handling cross-modal tasks.
More on tables
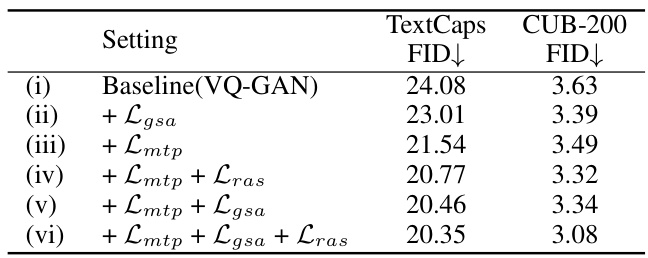
This table presents the results of an ablation study conducted to evaluate the individual contributions of the three loss functions (Lgsa, Lmtp, and Lras) used in the LG-VQ model. The study compares the model’s performance on two datasets, TextCaps and CUB-200, measured by FID (Fréchet Inception Distance), a metric that assesses the perceptual similarity between generated images and real images. The lower the FID score, the better the performance. By systematically adding each loss function, the table shows the impact of each component on the overall image reconstruction quality.
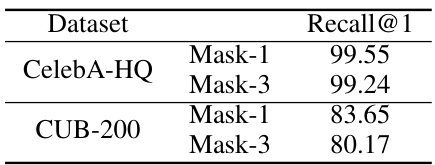
This table presents the recall@1 scores achieved by the LG-VQ model in a masked word prediction task. Two datasets are used, CelebA-HQ and CUB-200, and two masking scenarios are tested: masking one word randomly, and masking three words randomly. The recall@1 metric indicates the percentage of times the model correctly predicts the masked word as the top prediction. Higher scores signify better performance in recovering masked words.

This table presents a quantitative comparison of the similarity between word semantics and corresponding code representations. The Mean Squared Error (MSE) is used as the metric to measure the difference in similarity between word pairs and their corresponding code pairs. Lower MSE values indicate a higher degree of alignment between word semantics and code representations, suggesting the effectiveness of the proposed method in capturing semantic relationships within the codebook.

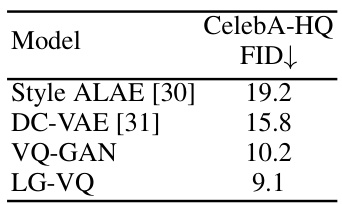
This table presents the results of the text-to-image task on the CelebA-HQ dataset. It compares the Fréchet Inception Distance (FID) scores, a metric for evaluating the quality of generated images, for several models. Lower FID scores indicate better image quality. The models compared include Unite and Conqu, Corgi, LAFITE, VQ-GAN, CVQ, VQ-GAN+LG (the proposed method with language guidance added to VQ-GAN), and CVQ+LG (the proposed method with language guidance added to CVQ). The table shows that the models incorporating the language-guided codebook learning (LG-VQ) achieve significantly lower FID scores, demonstrating improved image generation quality.

This table presents the Fréchet Inception Distance (FID) scores, a metric evaluating the quality of generated images, for semantic synthesis on the CelebA-HQ dataset. Lower FID scores indicate better image quality. The table compares the performance of several models, including baseline models (Reg-VQ, VQCT, VQ-GAN, CVQ) and the proposed LG-VQ method integrated with VQ-GAN and CVQ. The results show the FID scores achieved by each model, demonstrating the improvement in image quality obtained by incorporating the language-guided codebook learning approach.
This table presents the results of image reconstruction experiments using different models on four datasets: TextCaps, CelebA-HQ, CUB-200, and MS-COCO. The table compares the performance of several vector quantization (VQ) models, specifically VQ-VAE, VQ-GAN, and CVQ, both with and without the proposed LG-VQ method. The performance is measured using two metrics: FID (Fréchet Inception Distance), which assesses perceptual similarity, and PSNR (Peak Signal-to-Noise Ratio), which evaluates pixel-level similarity. Lower FID scores indicate better performance.
This table presents the quantitative results of image reconstruction experiments performed using four different models on four datasets. The models are VQ-VAE, VQ-VAE with the proposed LG-VQ method, VQ-GAN, and VQ-GAN with LG-VQ. The datasets are TextCaps, CelebA-HQ, CUB-200, and MS-COCO. The results are evaluated using two metrics: FID (Fréchet Inception Distance) and PSNR (Peak Signal-to-Noise Ratio). Lower FID scores indicate better perceptual similarity, while higher PSNR scores indicate better pixel-level similarity between the reconstructed images and the original images.

This table presents the Fréchet Inception Distance (FID) scores, a lower score indicating better performance, for image completion on the CelebA-HQ dataset. It compares the performance of the VQ-GAN model (baseline) with the LG-VQ model (the proposed method). The FID score for LG-VQ is significantly lower than for VQ-GAN, demonstrating the improved performance of LG-VQ in image completion tasks.
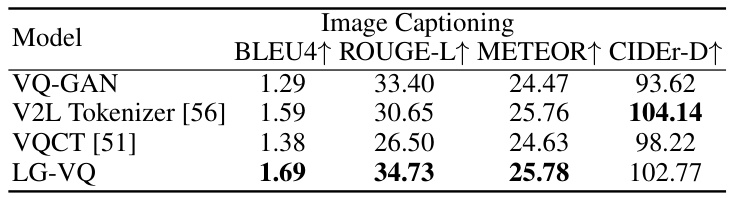
This table presents the results of image captioning experiments conducted on the CUB-200 dataset. Four different models were compared: VQ-GAN, V2L Tokenizer, VQCT, and the proposed LG-VQ model. The performance of each model is evaluated using four metrics: BLEU4, ROUGE-L, METEOR, and CIDEr-D. The table shows LG-VQ achieves competitive results compared to state-of-the-art methods.

This table presents the results of image reconstruction experiments performed using different models on four datasets: TextCaps, CelebA-HQ, CUB-200, and MS-COCO. It compares the performance of standard VQ-VAE and VQ-GAN models against their counterparts that incorporate the proposed LG-VQ method. The metrics used to evaluate reconstruction quality are Fréchet Inception Distance (FID) and Peak Signal-to-Noise Ratio (PSNR). Lower FID scores and higher PSNR values indicate better reconstruction performance. The results show that the inclusion of LG-VQ leads to improvements in image reconstruction quality across all datasets.
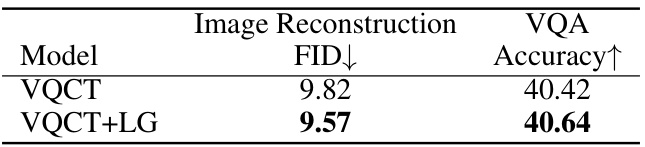
This table presents a comparison of the performance of two models, VQCT and VQCT+LG, on image reconstruction and Visual Question Answering (VQA) tasks using the MS-COCO dataset. The FID (Fréchet Inception Distance) score, a lower value indicating better image reconstruction quality, is reported for the image reconstruction task. The accuracy, a higher value indicating better performance, is shown for the VQA task. The results demonstrate the impact of integrating the Language-Guided VQ (LG-VQ) method into the VQCT model.
Full paper#