↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-to-image models, while capable of generating images from text prompts, often struggle with accurately representing specific subjects or styles when fine-tuned on limited personal data. Existing fine-tuning methods sometimes compromise image-text alignment or subject fidelity. This paper tackles this problem by focusing on improving the robustness and consistency of these personalized models.
The proposed solution is Direct Consistency Optimization (DCO). DCO works by directly controlling the difference between the fine-tuned model and its pre-trained counterpart, minimizing knowledge loss during fine-tuning. This approach outperforms previous baselines in terms of both image-text alignment and subject fidelity. Furthermore, DCO allows seamless merging of separately fine-tuned models for greater compositionality and control. The researchers also introduce ‘consistency guidance sampling’ for adjusting the balance between subject consistency and textual alignment during generation.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents Direct Consistency Optimization (DCO), a novel approach that enhances the robustness and consistency of personalized text-to-image diffusion models. This addresses a key challenge in the field, where fine-tuning often leads to models that are not robust and struggle with composing concepts from pre-trained models. DCO’s superior performance opens up exciting avenues for researchers interested in improving personalized image generation and composition.
Visual Insights#

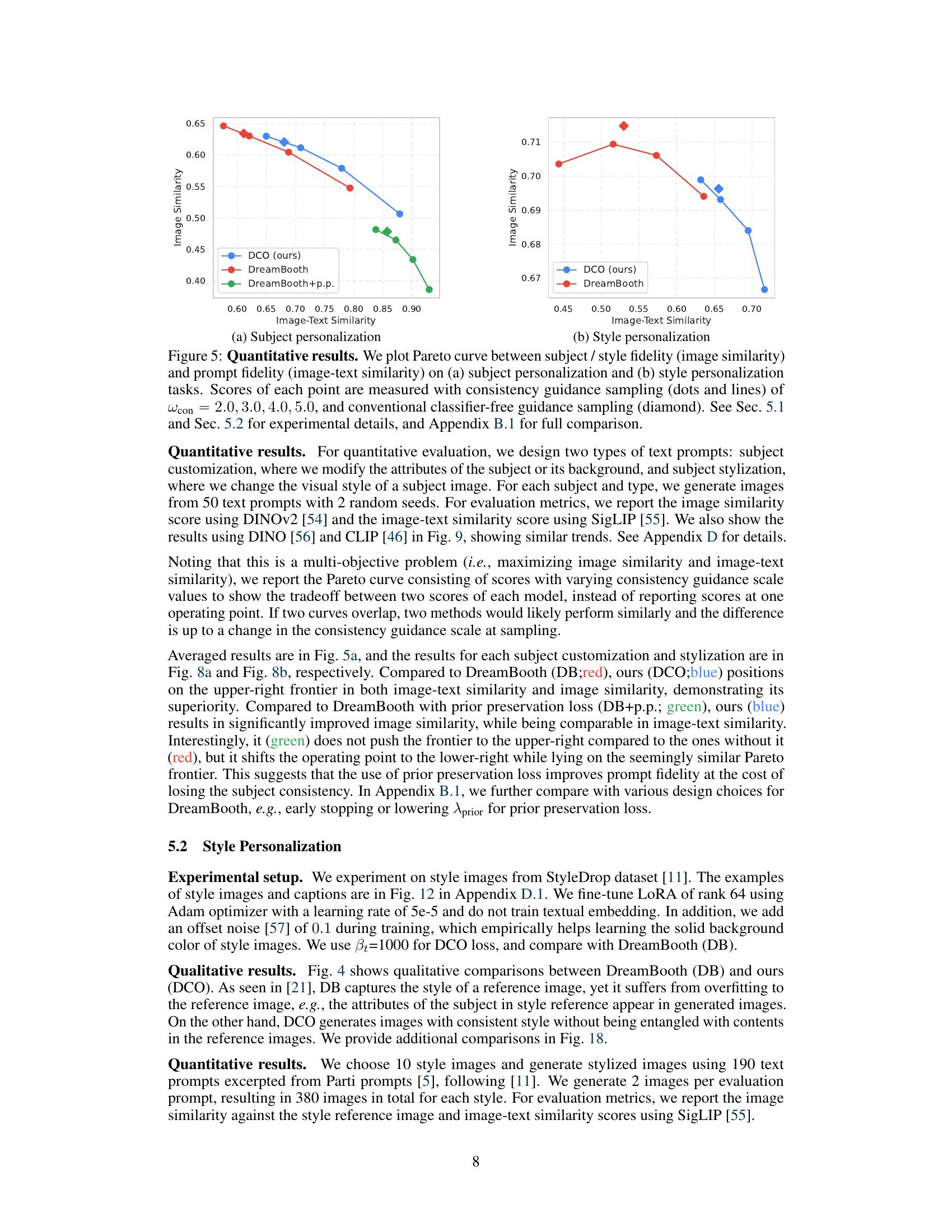
This figure demonstrates the effectiveness of Direct Consistency Optimization (DCO) for text-to-image (T2I) model customization. Panel (a) shows that DCO outperforms DreamBooth and DreamBooth with prior preservation in generating images with high subject fidelity and prompt fidelity. It achieves this by improving the balance between consistency and image-text alignment. Panel (b) showcases the key advantage of DCO: fine-tuned subject and style models can be directly merged without interference, enabling the generation of images containing a custom subject in a custom style.
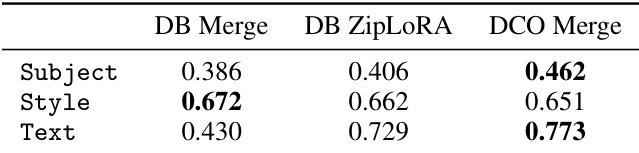
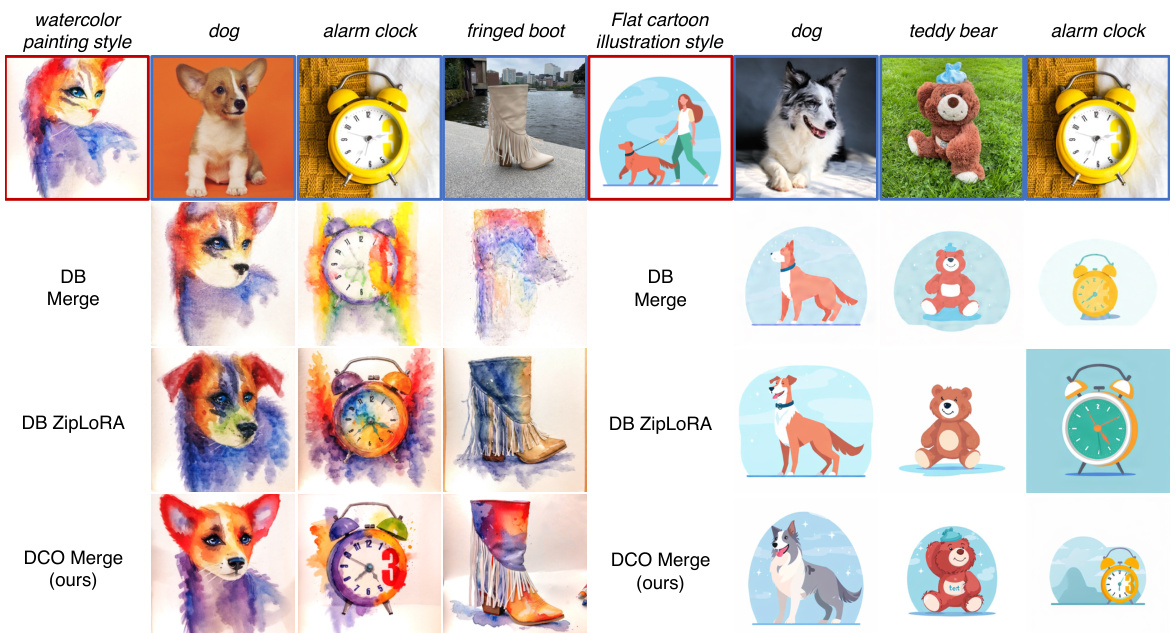
This table presents a quantitative comparison of three different methods for generating images with a specific subject and style. The methods compared are DreamBooth Merge (DB Merge), DreamBooth ZipLoRA (DB ZipLoRA), and the proposed Direct Consistency Optimization Merge (DCO Merge). The table shows the average scores for three different metrics: Subject similarity, Style similarity, and Text similarity. Higher scores indicate better performance. The DCO Merge method shows the highest subject and text similarity scores.
In-depth insights#
Direct Consistency#
Direct consistency, in the context of a research paper focusing on robust text-to-image diffusion model customization, likely refers to a novel training objective aimed at minimizing the divergence between a fine-tuned model and its pretrained counterpart. This approach, unlike traditional methods, directly controls the deviation, ensuring that newly learned concepts are integrated without significant loss of pretrained knowledge. The core idea is to maintain a direct and consistent relationship between the original model’s capabilities and the enhancements brought about by fine-tuning. This ensures improved robustness, preventing issues like knowledge forgetting and enabling seamless integration with other fine-tuned models or concepts from the pretrained model. The success of this method could be evaluated through improved Pareto efficiency, achieving superior balance between image-text alignment and subject/style fidelity compared to other customization techniques. A key advantage might be the ability to merge independently customized models (e.g., subject and style) without interference, allowing for more complex and creative image generation.
DCO for T2I#
Direct Consistency Optimization (DCO) for Text-to-Image (T2I) models presents a novel approach to fine-tuning pre-trained diffusion models. Instead of relying on additional data or solely minimizing the standard diffusion loss, DCO directly controls the deviation between the fine-tuned and pre-trained models. This approach is particularly useful for tasks where generating images from a small set of personal images is desired, as it balances the fidelity to the reference images with the overall image-text alignment. By minimizing the divergence between the fine-tuned and pre-trained models, DCO effectively prevents knowledge loss, leading to more robust and consistent results. The method’s effectiveness is demonstrated through superior performance over baseline methods in both subject and style customization, achieving a better Pareto frontier between subject fidelity and prompt fidelity. Furthermore, the resulting models exhibit improved composability, allowing for seamless merging of separately trained subject and style models without interference, opening up exciting possibilities for creative image generation.
Style & Subject Merge#
The concept of “Style & Subject Merge” in the context of text-to-image diffusion models is a significant advancement, focusing on the ability to combine independently customized models representing distinct styles and subjects. Direct Consistency Optimization (DCO) is crucial here, as it enables the merging of these models without significant interference or loss of fidelity. The challenge lies in maintaining both style and subject integrity during the merging process, which previous methods struggled with. DCO overcomes this by carefully controlling the deviation between the fine-tuned and pretrained models, ensuring a balance between learning new concepts and retaining existing knowledge. This allows seamless combination, for example, generating an image of a “teddy bear” in the style of a “watercolor painting.” The success of style and subject merging highlights DCO’s effectiveness in low-shot learning and its potential for enhancing the creative capabilities of T2I models. The ability to directly merge, as opposed to using post-optimization techniques, simplifies the process and offers greater efficiency. However, the success of the merging is highly dependent on the semantic similarity between the styles and subjects, with challenges arising when merging highly similar concepts. Future research could focus on mitigating this issue and further improving the robustness and controllability of the merge operation.
Consistency Guidance#
Consistency guidance, as a sampling strategy in the paper, is a crucial technique for controlling the trade-off between subject consistency and text alignment in text-to-image generation. It enhances the model’s ability to generate images that faithfully reflect the reference images while maintaining adherence to the given text prompt. The method cleverly leverages a learned consistency function during inference, allowing for a continuous adjustment of this balance. By varying the consistency guidance scale, users can fine-tune the output images to prioritize either a higher degree of faithfulness to the reference images or a greater alignment with the textual description. This flexible approach addresses the limitations of existing methods that often struggle to maintain an optimal balance between these two important aspects of image generation. The effectiveness of consistency guidance is further underscored by its integration with the Direct Consistency Optimization (DCO) loss function, demonstrating synergistic improvements in image quality and fidelity. The ability to dynamically control the balance between consistency and prompt adherence makes consistency guidance a powerful tool for personalized image generation.
Ablation & Limits#
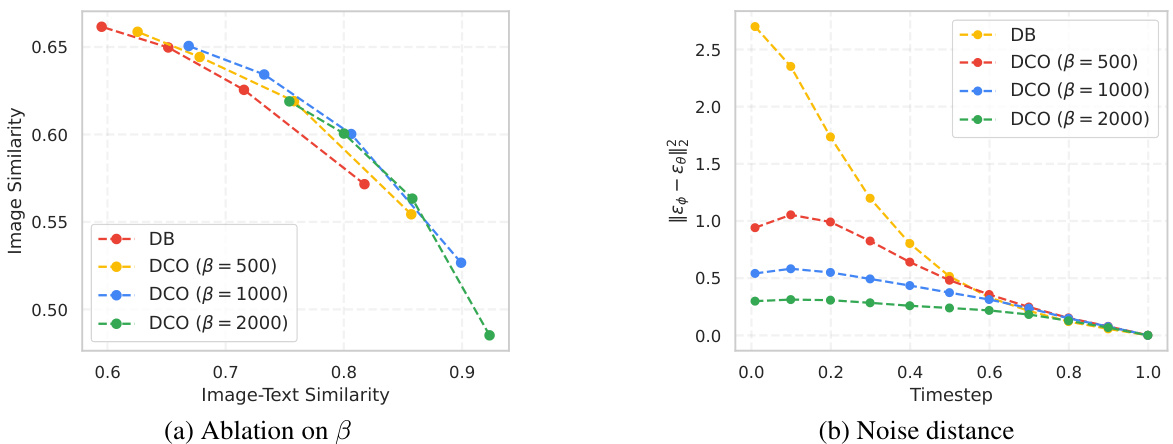
An ‘Ablation & Limits’ section in a research paper would systematically analyze the model’s performance by removing or altering individual components to understand their contributions. Ablation studies would isolate the impact of specific design choices, such as different loss functions or network architectures. The limits portion would address the model’s shortcomings and boundaries, identifying scenarios where it fails or performs poorly. This might include discussing limitations in data representation, generalization capabilities, computational constraints, and ethical implications. The insights gained would highlight the model’s strengths, weaknesses, and areas needing further improvement. A thoughtful analysis would involve a detailed examination of experimental results, comparing the effects of different ablation scenarios, and providing a nuanced discussion of the findings, including potential causes for limitations and suggestions for future research directions. The goal is to not only showcase what the model does well but also what it struggles with, furthering the understanding of the approach and its overall utility.
More visual insights#
More on figures

This figure shows a comparison of different methods for customizing text-to-image diffusion models. (a) illustrates how Direct Consistency Optimization (DCO) improves upon existing methods (DreamBooth and DreamBooth with prior preservation) in terms of generating images with high fidelity to both the prompt and the subject, achieving a superior balance between these two aspects. (b) demonstrates the advantage of DCO in allowing for seamless merging of separately customized subject and style models, enabling the generation of images featuring a specific subject in a specific style.

This figure demonstrates the effectiveness of Direct Consistency Optimization (DCO) in comparison to other methods (DreamBooth, DreamBooth with prior preservation). Panel (a) shows DCO achieving higher prompt and subject fidelity. Panel (b) illustrates the ability of DCO to merge independently customized subject and style models for generating images combining both attributes.

This figure compares the results of generating images of custom subjects with varying attributes and styles using three different methods: DreamBooth, DreamBooth with prior preservation, and the proposed DCO method. The results demonstrate that while DreamBooth successfully generates images of the subject, it does not always align with the text prompt. Adding prior preservation improves text alignment but reduces subject fidelity. The DCO method is shown to achieve the best results, balancing both image-text alignment and subject fidelity.

This figure compares the performance of three different methods for generating images of custom subjects: DreamBooth, DreamBooth with prior preservation, and the proposed Direct Consistency Optimization (DCO) method. The results show that DCO achieves the best balance between subject fidelity (how well the generated image matches the reference image) and prompt fidelity (how well the generated image matches the text prompt).
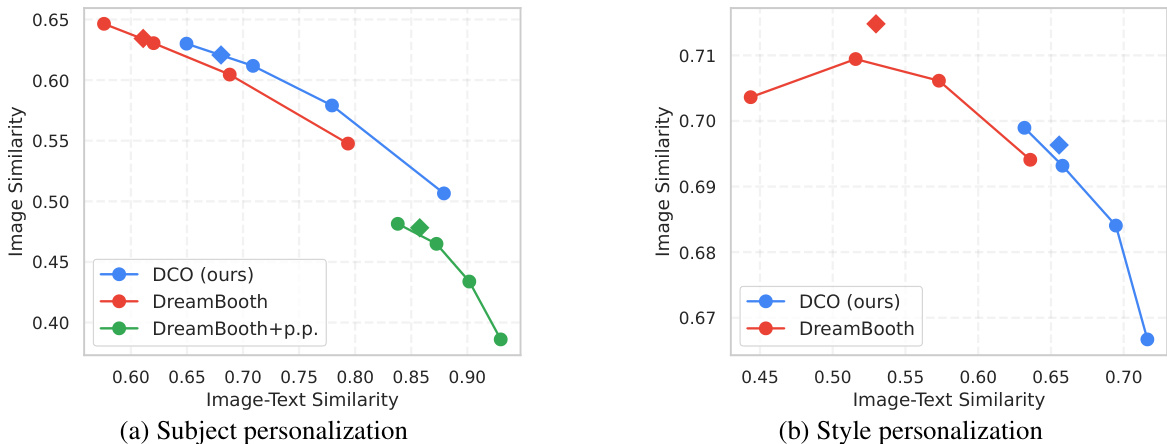
This figure shows the Pareto frontier curves for both subject and style personalization tasks. The x-axis represents image-text similarity, and the y-axis represents image similarity. Each point on the curve represents a trade-off between these two metrics, obtained using different consistency guidance sampling values (wcon). The figure demonstrates that the proposed DCO method outperforms the baselines (DreamBooth and DreamBooth with prior preservation) by achieving a superior balance between subject/style fidelity and image-text alignment. Appendix B.1 provides further details and a more complete comparison.
This figure demonstrates the effectiveness of Direct Consistency Optimization (DCO) in comparison to other methods, such as DreamBooth and DreamBooth with prior preservation loss. Part (a) shows DCO’s improvement in generating images with high prompt fidelity and subject fidelity. Part (b) highlights DCO’s ability to merge customized subject and style models for generating images with a specific subject in a particular style.
This figure shows the Pareto curves comparing image similarity (representing subject/style fidelity) against image-text similarity (representing prompt fidelity) for both subject and style personalization tasks. The curves illustrate the trade-off between these two metrics; improving one often comes at the expense of the other. Different sampling methods (consistency guidance and classifier-free guidance) are compared, showing how the choice of sampling affects the balance between fidelity to the prompt and fidelity to the subject or style. The results indicate that the proposed method (DCO) achieves a better balance than previous baselines.
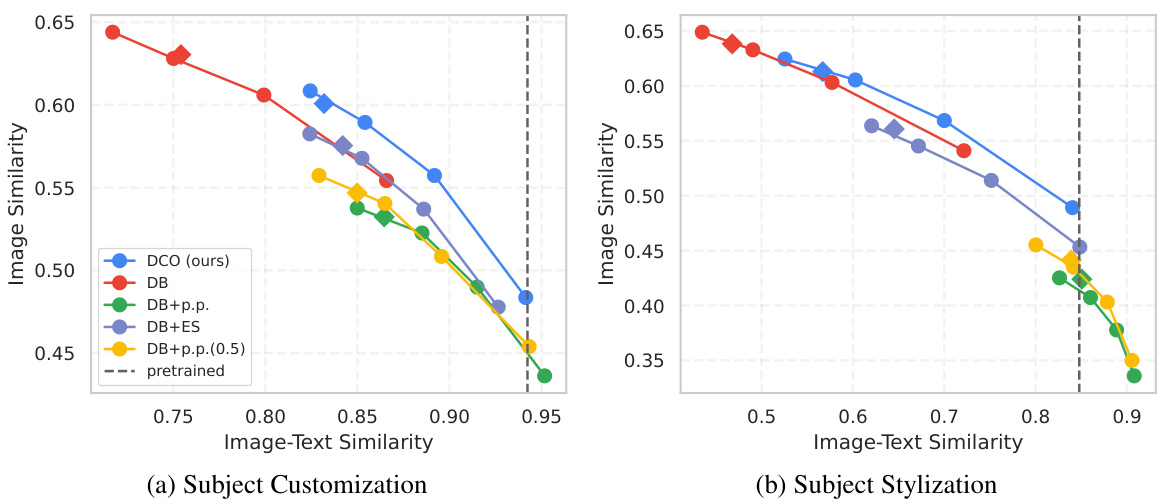
This figure shows the Pareto frontier curves for both subject and style personalization tasks. The x-axis represents image-text similarity, and the y-axis represents image similarity (fidelity to the subject or style). Each curve represents a different method (DCO, DreamBooth, DreamBooth with prior preservation), and the points on each curve represent different levels of consistency guidance during sampling. The figure demonstrates that DCO achieves a superior balance between image-text alignment and subject/style consistency compared to the baseline methods.
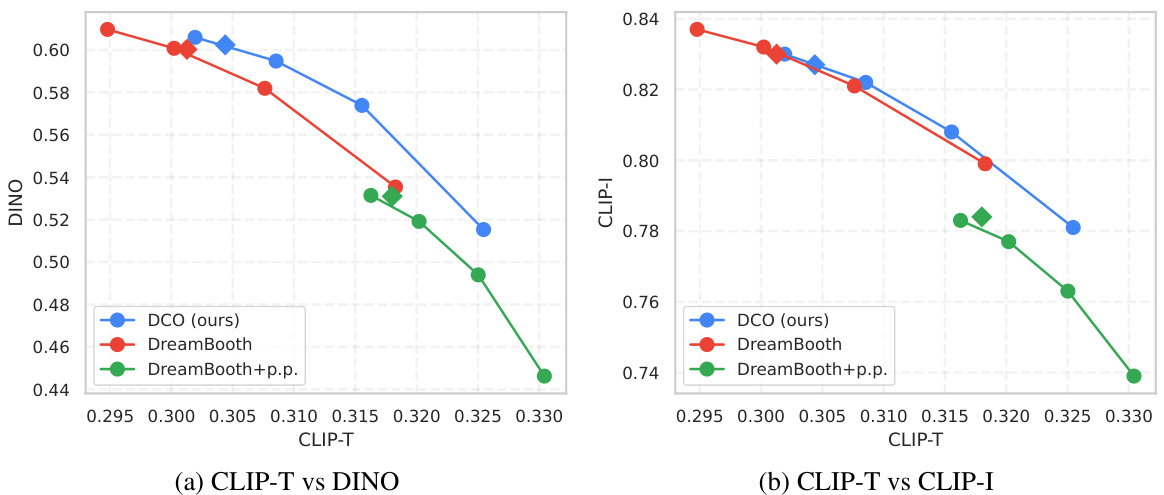
This figure presents Pareto curves showing the trade-off between image similarity (subject/style fidelity) and image-text similarity (prompt fidelity) for both subject and style personalization tasks. The curves illustrate the performance of Direct Consistency Optimization (DCO) compared to baseline methods (DreamBooth, DreamBooth with prior preservation). Different sampling methods (consistency guidance with varying wcon values and conventional classifier-free guidance) are also shown. The results demonstrate DCO’s superior performance, achieving higher fidelity in both image-text alignment and subject/style consistency.

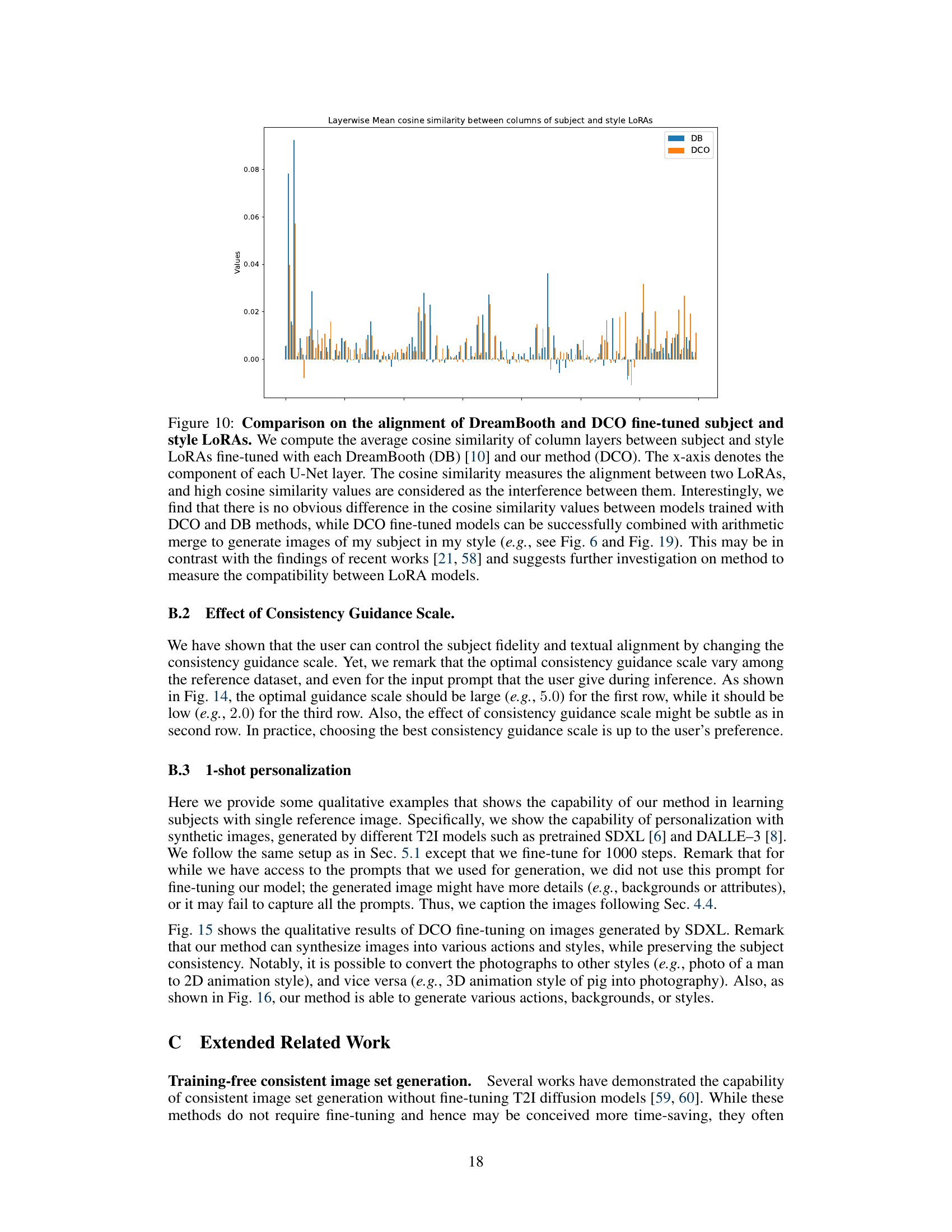
This figure compares the alignment of subject and style LoRAs fine-tuned using DreamBooth (DB) and Direct Consistency Optimization (DCO). It measures the average cosine similarity between the columns of the LoRA layers in the U-Net. High cosine similarity suggests interference between LoRAs. The figure shows that there’s no significant difference in cosine similarity between the DB and DCO methods, implying that DCO effectively merges LoRAs while retaining model compatibility, unlike findings in some other works.

This figure shows a comparison of different methods for customizing text-to-image diffusion models. (a) illustrates the improved performance of Direct Consistency Optimization (DCO) compared to DreamBooth and DreamBooth with prior preservation, showing better trade-off between image-text alignment and subject consistency. (b) demonstrates the advantage of DCO in merging separately customized subject and style models, enabling generation of images with specific subjects in desired styles.
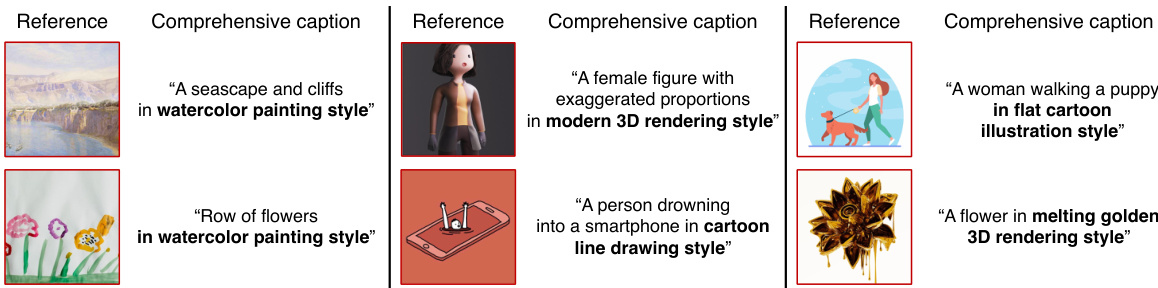
This figure demonstrates the advantages of Direct Consistency Optimization (DCO) over other methods for text-to-image generation. Panel (a) shows that DCO improves the balance between generating images that match the prompt (prompt fidelity) and those that accurately depict the specified subject (subject fidelity) compared to DreamBooth and DreamBooth with prior preservation. Panel (b) highlights DCO’s ability to merge independently customized models (subject and style) to generate images with the desired subject and style.

This figure compares the results of subject generation using three different methods: DreamBooth, DreamBooth with prior preservation, and the authors’ proposed method (DCO). It demonstrates that DCO achieves better image-text alignment and subject fidelity than the other methods. The results show that while DreamBooth captures subjects well, it struggles with accurate text prompt following. Adding prior preservation improves textual alignment but sacrifices subject fidelity. The DCO approach excels in both aspects, producing images that closely match the text prompts while maintaining high fidelity to the original subject.

This figure shows how changing the consistency guidance scale (wcon) affects image generation in a text-to-image model. Different values of wcon produce images with varying degrees of fidelity to the reference images and textual consistency. This highlights the trade-off between prompt fidelity and subject consistency that can be controlled during inference. The example uses three different subjects (a monster toy, a monster toy, and a sloth).

This figure shows a comparison of different methods for customizing text-to-image diffusion models. (a) demonstrates that the proposed Direct Consistency Optimization (DCO) method outperforms other methods in terms of both prompt fidelity (how well the generated image matches the text prompt) and subject fidelity (how well the generated image matches the reference image). (b) illustrates that models trained with DCO can be easily combined to generate images with a custom subject and style, unlike other approaches.

This figure demonstrates the 1-shot personalization capability of the proposed Direct Consistency Optimization (DCO) method using synthetic images generated by Stable Diffusion XL (SDXL). It showcases the model’s ability to generate images of a subject (man and pig) performing various actions and in diverse styles, starting from a single reference image. The prompts used for generating the reference images are explicitly mentioned.

This figure demonstrates the effectiveness of Direct Consistency Optimization (DCO) in comparison to DreamBooth and DreamBooth with prior preservation loss in generating images with high subject and prompt fidelity. The left panel (a) shows that DCO improves the balance between subject fidelity (how well the generated image matches the reference image) and prompt fidelity (how well the generated image matches the text prompt) compared to the baselines. The right panel (b) illustrates the ability of DCO to seamlessly merge fine-tuned models for subject and style, allowing for a higher degree of customization and creative control.

This figure compares the image generation results of three different methods: DreamBooth, DreamBooth with prior preservation, and the proposed Direct Consistency Optimization (DCO). For several subjects, each method is prompted to generate images with varying attributes and styles. The results demonstrate that DCO achieves the best balance between accurately capturing the subject and adhering to the text prompt’s specifications.
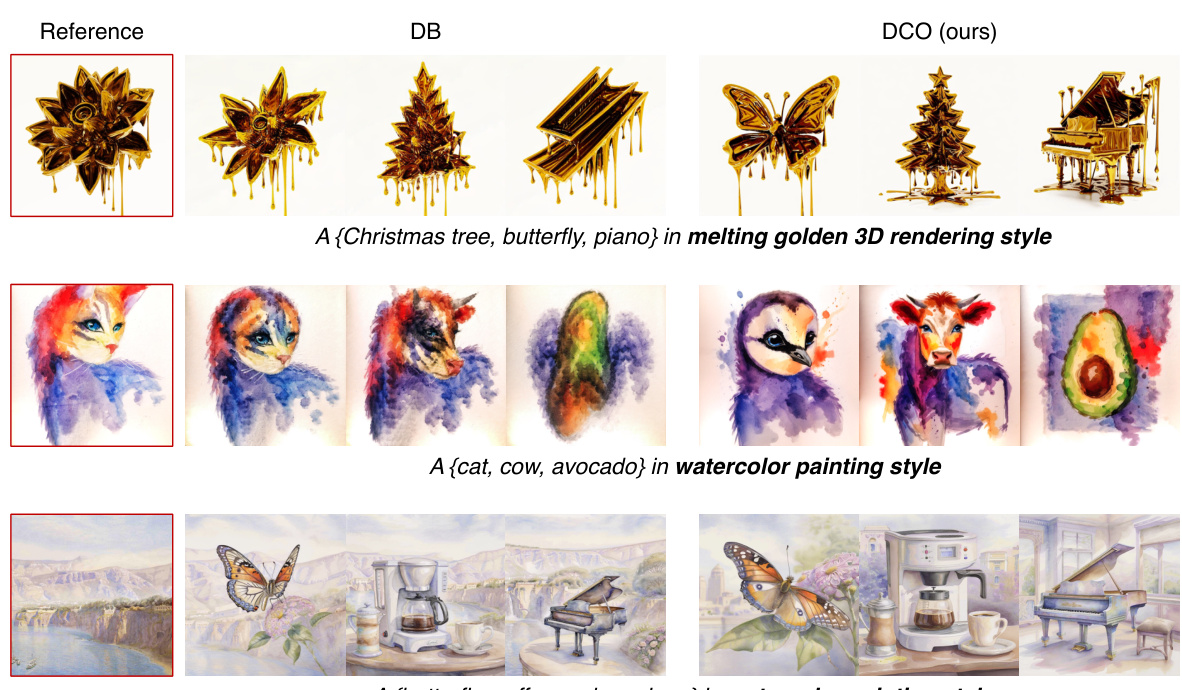
This figure shows additional qualitative results comparing the proposed Direct Consistency Optimization (DCO) method with the DreamBooth (DB) baseline for style customization. The results demonstrate that DCO generates style-consistent images while DB tends to overfit, resulting in the undesirable inheritance of attributes from the reference image.

This figure demonstrates the effectiveness of Direct Consistency Optimization (DCO) compared to other methods for image generation. (a) shows that DCO improves the trade-off between generating images that closely match the prompt (prompt fidelity) and images that closely resemble the reference images used for training (subject fidelity). (b) shows the additional benefit of DCO in that its fine-tuned models can be merged to create images with a custom subject and a custom style. This is a significant improvement over other methods that struggle with this merging process.

This figure compares the results of merging subject and style models trained using different methods. DreamBooth (DB) and Direct Consistency Optimization (DCO) are compared with DB models further post-processed with ZipLoRA. The results show DCO produces better quality and more consistent results than the other methods, highlighting its ability to preserve subject and style fidelity during merging.
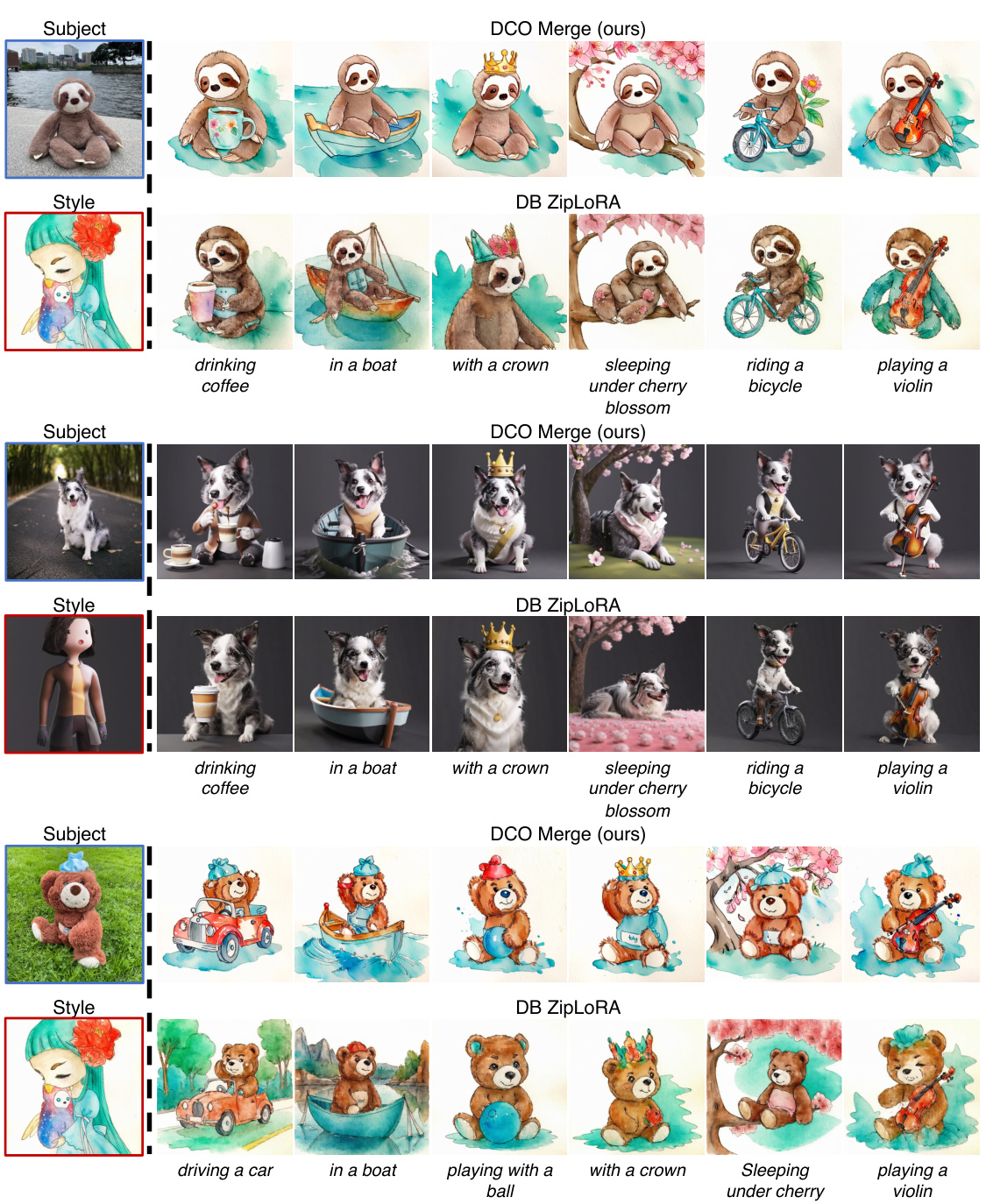
This figure demonstrates the results of merging subject and style models fine-tuned with DreamBooth (DB) and Direct Consistency Optimization (DCO). It shows that merging DCO-trained models results in higher-quality images with better preservation of subject and style fidelity compared to merging DB-trained models, even when using post-optimization techniques like ZipLoRA.
More on tables
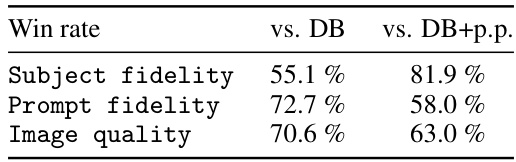
This table presents the results of a user study comparing the performance of the proposed Direct Consistency Optimization (DCO) method against two baseline methods (DreamBooth (DB) and DreamBooth with prior preservation loss (DB+p.p.)) across three evaluation criteria: subject fidelity, prompt fidelity, and image quality. For each criterion, the table shows the percentage of times users preferred images generated using DCO over those generated by each baseline method. It indicates the relative strengths of DCO in terms of generating images that accurately reflect the subject, align with prompts, and exhibit high overall quality.

This table presents a quantitative comparison of three different methods for generating images of a custom subject in a custom style. The methods compared are: DreamBooth merge (DB Merge), DreamBooth with ZipLoRA (DB ZipLoRA), and the authors’ proposed Direct Consistency Optimization merge (DCO Merge). The table reports the average image similarity scores (using DINOv2) for subject and style, as well as the image-text similarity score (using SigLIP) for each method. These metrics evaluate how well the generated images match the intended subject, style, and textual description.
Full paper#