↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current video anomaly detection (VAD) systems struggle with semantic understanding and limited interaction. Existing datasets are scarce, hindering open-world applicability. This research addresses these limitations.
The proposed HAWK framework uses interactive large visual language models to improve semantic understanding and incorporates motion modality for enhanced anomaly detection. It uses a dual-branch architecture, an auxiliary consistency loss, and motion-to-language supervision, achieving state-of-the-art performance on several benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it presents HAWK, a novel framework for open-world video anomaly detection that surpasses existing methods. Its use of interactive large visual language models (VLMs) and explicit integration of motion modality is highly relevant to current research trends and opens up several avenues for further investigation, particularly in the areas of open-world understanding, video description generation, and question-answering.
Visual Insights#
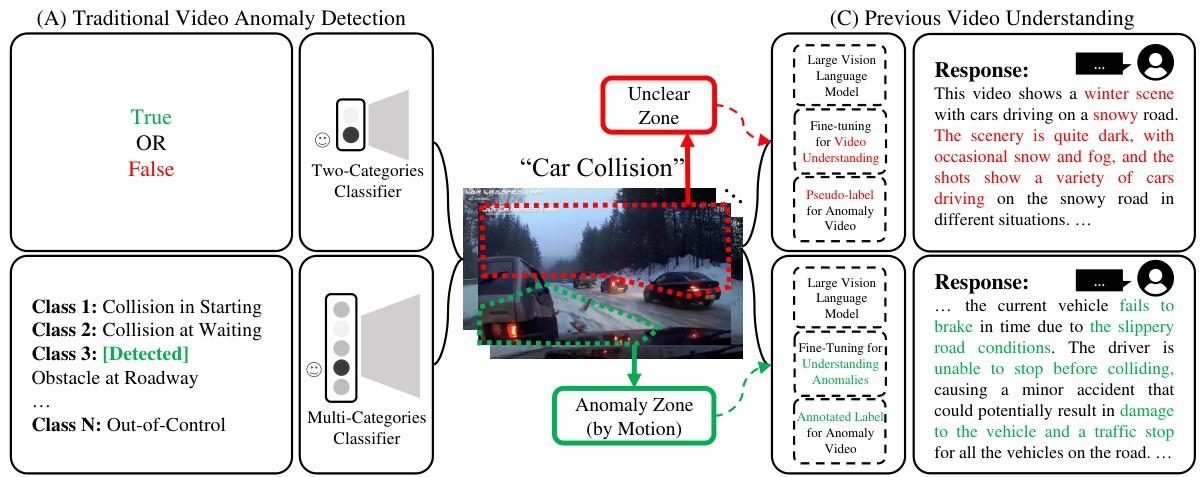
This figure illustrates the evolution of video anomaly detection frameworks. (A) shows a traditional approach using a simple binary classifier. (B) improves upon this by incorporating semantic information through a multi-class classifier, still lacking user interaction. (C) demonstrates a video understanding framework that offers interactive semantic information but cannot pinpoint anomalies. Finally, (D) presents the proposed HAWK framework, which combines motion and visual information, enabling precise anomaly identification and interaction with users via rich semantic information and annotated labels.
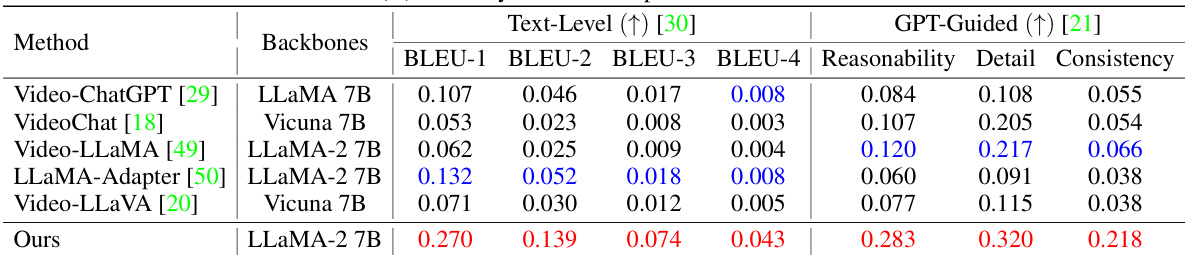
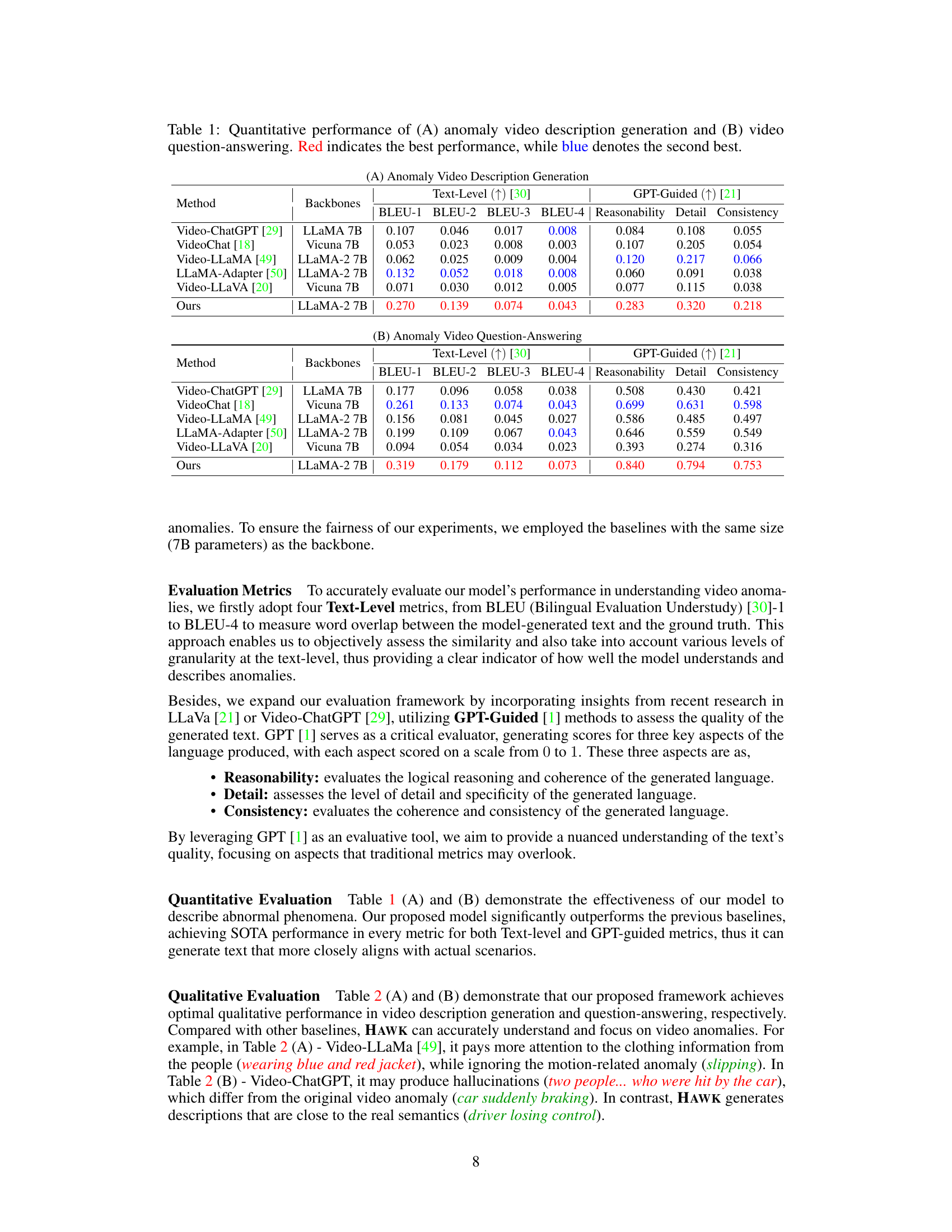
This table presents a quantitative comparison of HAWK’s performance against several baselines on two key tasks: anomaly video description generation and video question-answering. The evaluation metrics used include both text-level metrics (BLEU-1 to BLEU-4) and GPT-guided metrics (Reasonability, Detail, Consistency). The table is split into two parts: (A) shows results for video description generation, and (B) shows results for video question-answering. The best performing model in each metric is highlighted in red, and the second-best is in blue. This allows for a clear comparison of HAWK’s performance against state-of-the-art methods in the field.
In-depth insights#
Motion Modality Fusion#
Motion modality fusion, in the context of video anomaly detection, is a crucial technique to enhance the system’s ability to identify unusual events. By integrating motion information with other modalities like appearance, the model can better discern subtle differences between normal and anomalous activities. Effective fusion strategies could leverage techniques such as concatenation, attention mechanisms, or more sophisticated deep learning architectures that explicitly learn to weigh and combine motion features with other visual cues. The success of motion modality fusion is strongly tied to the quality and representation of motion features. Approaches could range from using optical flow to extract dense motion fields to employing simpler, yet effective, techniques like spatiotemporal features extracted from video frames or convolutional neural networks tailored to motion pattern analysis. A critical aspect is how to harmoniously integrate motion information with other visual information. The model architecture needs to be designed thoughtfully so motion information is not simply appended but is processed and combined effectively with the other modalities. Furthermore, careful consideration should be given to dataset bias, as motion features might exhibit variations across datasets depending on factors such as camera viewpoint and motion capture techniques. Robustness to noise and variations in motion characteristics is paramount for reliable anomaly detection, necessitating well-designed architectures and training strategies that mitigate the effects of such challenges. Overall, the thoughtful incorporation of motion modality through advanced fusion techniques is key to building robust and accurate video anomaly detection systems.
Interactive VLM#
Interactive VLMs (Visual Language Models) represent a significant advancement in AI, particularly within the context of video anomaly detection. Interactivity is key; it allows for a dynamic feedback loop between the model and the user, enabling more precise understanding and interpretation of complex visual data. Unlike traditional static VLMs, interactive versions allow users to guide the model’s analysis, potentially refining its focus or prompting it to consider different aspects of the video, improving the accuracy of anomaly detection. This is especially beneficial in open-world scenarios where diverse and unpredictable events may occur. By incorporating human-in-the-loop interaction, the inherent ambiguities in visual data are reduced, leading to more reliable and efficient anomaly identification. Furthermore, the user interaction can also be used for model training, through direct feedback, improving performance and making the model more adaptable to changing conditions. The integration of natural language processing within the interactive VLM allows for detailed explanations and annotations, creating a more transparent and informative process. This is important for building trust and understanding with users who may not be experts in computer vision.
Open-world VAD#
Open-world Video Anomaly Detection (VAD) presents a significant challenge compared to traditional VAD, which typically operates under controlled settings and limited anomaly types. Open-world VAD necessitates systems that can handle diverse, unseen anomalies in a wide range of environments. This requires robust models with strong generalization capabilities that can adapt to new scenarios without extensive retraining. Key aspects involve developing methods for handling the lack of labeled data for novel anomalies, potentially leveraging techniques such as few-shot learning or unsupervised anomaly detection. Effective solutions should also integrate rich contextual information like scene semantics and motion patterns to better identify subtle anomalies that may not be easily detected visually. Addressing the open-ended nature of user interaction is crucial, requiring natural language processing capabilities to provide explanations and answer user questions about anomalies within the context of the overall video content. Successfully tackling open-world VAD would significantly impact fields like autonomous driving, security surveillance, and healthcare, enabling more robust and reliable AI systems in real-world scenarios.
Dataset Engineering#
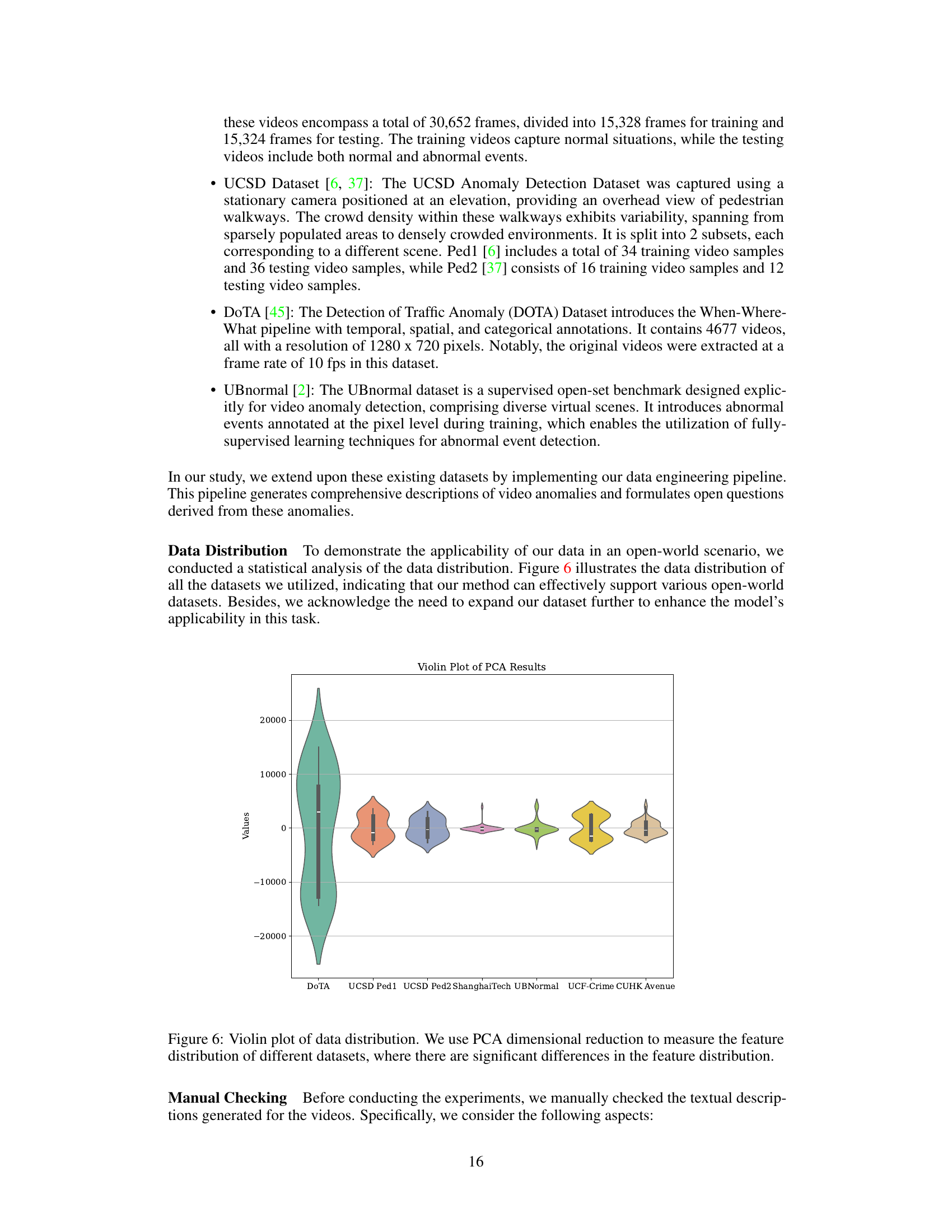
The ‘Dataset Engineering’ section of a research paper is crucial, detailing how the data used in the study was created or compiled. A strong section will highlight the challenges faced in data acquisition, such as data scarcity or lack of relevant annotations. It should then meticulously explain the strategies implemented to overcome these hurdles. This might involve creating new datasets, augmenting existing datasets, or developing novel annotation techniques. The description needs to be specific, including the datasets used, the number of samples, the annotation process, and any tools or techniques employed (e.g., using GPT-4 to generate descriptions). A successful approach will present a justification for the chosen methodology and a discussion on the limitations of the dataset, acknowledging any potential biases or shortcomings which might affect the generalizability of the findings. Transparency and reproducibility should be central, providing readers with enough information to understand and potentially replicate the dataset creation process. Finally, any ethical considerations related to data collection or use must also be addressed.
Future Directions#
Future research directions stemming from this video anomaly detection model could significantly enhance its capabilities and applicability. Expanding to a wider range of scenarios, such as diverse weather conditions or different camera viewpoints, is crucial. Improving the model’s ability to localize anomalies within video frames would be beneficial for practical applications such as security monitoring. A vital improvement would be incorporating background information to improve contextual understanding and reduce false positives. Further research should also focus on developing real-time or near real-time anomaly detection, as well as improving the model’s robustness in the face of noisy data or adversarial attacks. Finally, exploring methods to enhance user interaction and provide more comprehensive explanations for detected anomalies would enhance usability and transparency.
More visual insights#
More on figures
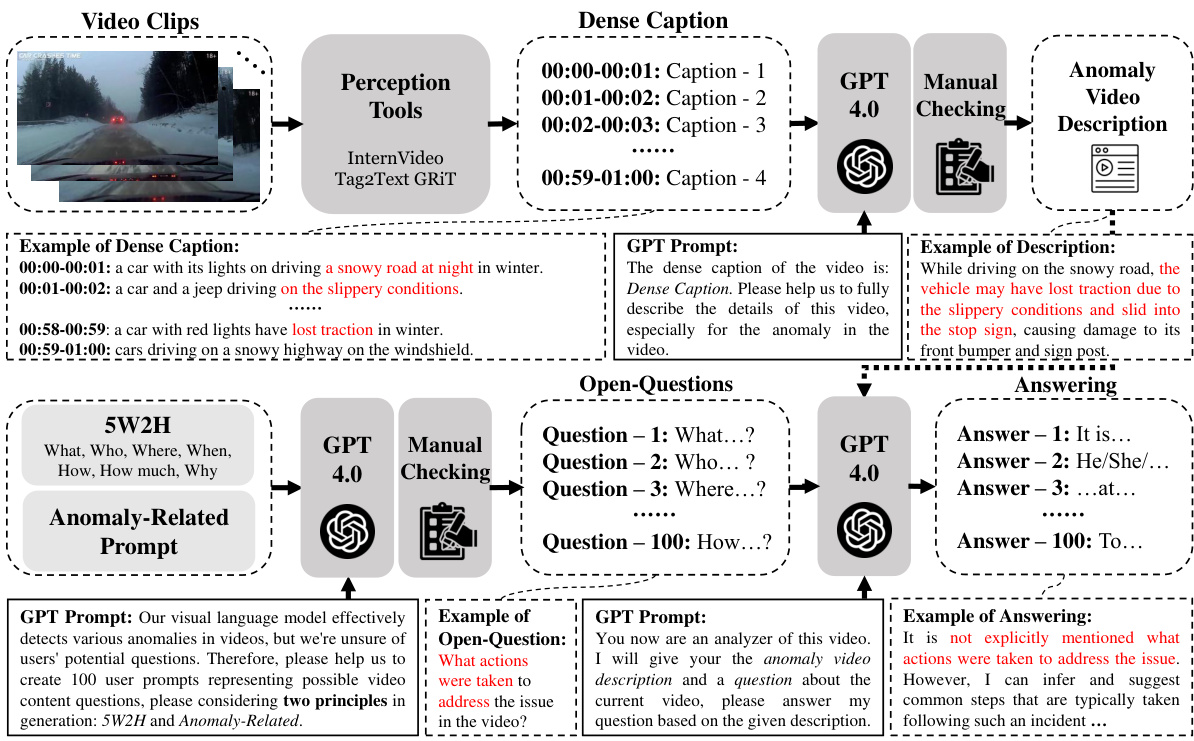
This figure illustrates the two-stage process used to create the dataset. The first stage focuses on generating detailed descriptions of video anomalies. Videos are segmented, dense captions are created for each segment using perception tools, and then GPT-4 is used to generate comprehensive anomaly descriptions based on these captions. These descriptions undergo manual checking for accuracy. The second stage involves creating question-answer pairs for user interaction. GPT-4 generates open-ended questions based on the video descriptions and the 5W2H and Anomaly-Related principles. Finally, GPT-4 generates answers based on both the questions and video descriptions. This process results in a dataset rich in descriptive information and question-answer pairs for various anomaly scenarios.

This figure illustrates the architecture of HAWK, a dual-branch framework for video anomaly understanding. It integrates both appearance (video) and motion modalities. The video branch processes video frames to extract appearance features, while the motion branch extracts motion features. Both branches use pre-trained video encoders (EVA-CLIP and Video Q-Former). A consistency loss in a tight space enforces agreement between the video and motion modalities. Motion-related language is extracted from the descriptions to supervise motion interpretation. Finally, a large language model (LLaMA-2) integrates the visual (video and motion) and textual embeddings to generate language descriptions or answer questions.
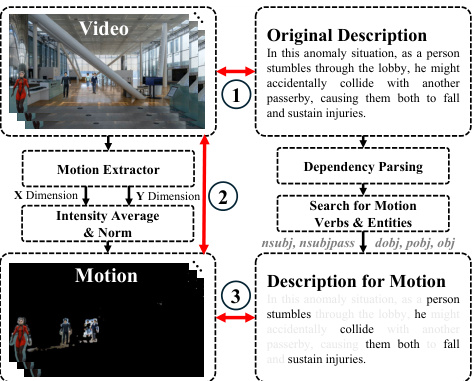
This figure illustrates the architecture of the HAWK model, highlighting the dual-branch design for video and motion understanding. It shows how both modalities are integrated with a large language model (LLaMA-2) for video description generation. The training process involves optimizing three loss functions: video-language matching loss, video-motion consistency loss, and motion-language matching loss. The inference process uses the combined video and motion features to generate descriptions, enabling fine-grained anomaly interpretation.
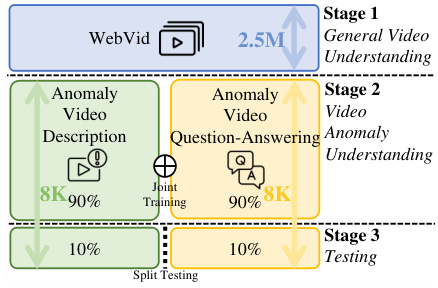
This figure illustrates the three-stage training and testing process employed in the paper. Stage 1 involves pre-training on the WebVid dataset [3] to acquire general video understanding. Stage 2 fine-tunes the model on a curated anomaly video dataset for video anomaly understanding, using both video description generation and question-answering tasks, with joint training. Stage 3 involves testing the model independently on the two tasks (video description and question-answering) on a held-out 10% of the dataset.
This figure shows the architecture of HAWK, a dual-branch framework that integrates motion modality. The black and gray paths represent the training process, which involves optimizing for video-language matching, video-motion consistency, and motion-language matching losses. The gray path alone represents the inference process, where the model generates language descriptions based on video and motion inputs. The figure highlights the key components of the framework including video encoders, motion extractors, projection layers, LLaMa-2 language model and loss functions.

This figure illustrates the process of creating the dataset used in the HAWK model. The top half shows how dense captions are generated for video clips, followed by GPT-4 generating more detailed descriptions of anomalies, and then manual checking for accuracy. The bottom half details the generation of question-answer pairs using GPT-4 based on the video descriptions and two principles (5W2H and Anomaly-Related). These pairs aim to simulate real-world user inquiries about video anomalies.

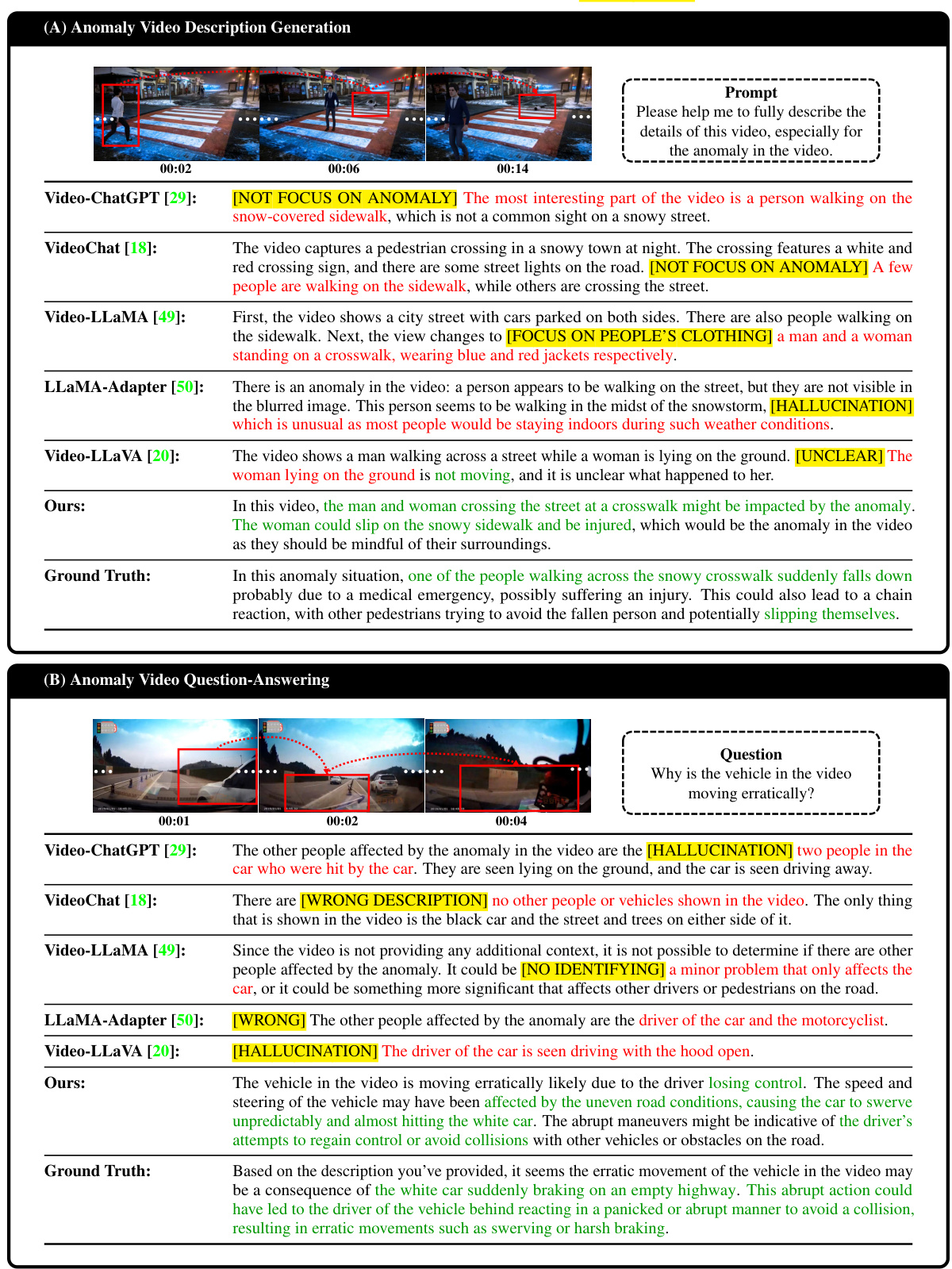
This figure shows a demonstration of HAWK’s capabilities in understanding open-world video anomalies. The user provides a video showing a car fire and asks HAWK to identify the anomaly and suggest solutions. HAWK correctly identifies the car fire as an anomaly and proposes steps for investigation, including checking for mechanical issues, looking for external factors, consulting experts, and conducting a thorough investigation. The interaction highlights HAWK’s ability to interpret complex real-world scenarios and provide actionable insights.

This figure shows the architecture of HAWK, a dual-branch framework for understanding video anomalies. It explicitly integrates motion modality using two branches: one for processing video appearance features and one for motion features. Both branches share the same architecture but use separate parameters. The video and motion embeddings are then projected into a common language feature space and combined with text tokens (prompt) before being fed into a large language model (LLaMA-2). During training, video-language matching loss, video-motion consistency loss, and motion-language matching loss are used to optimize the model. During inference, only the gray path is used, generating language descriptions based on video and motion features as well as text prompts.
More on tables
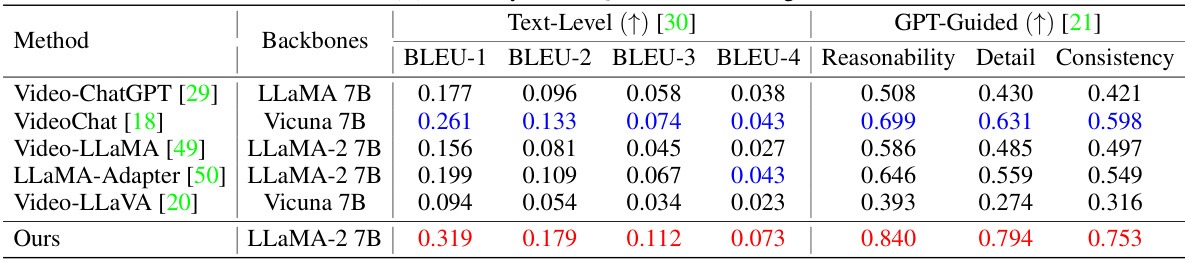
This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. The results are broken down by different metrics: BLEU scores (BLEU-1 to BLEU-4) for text-level evaluation and Reasonability, Detail, and Consistency scores for GPT-guided evaluation. Red highlights the best-performing model for each metric, and blue indicates the second-best performance. The table showcases HAWK’s superior performance across all metrics compared to existing state-of-the-art approaches.
This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. For each task, the table shows the performance metrics (BLEU scores, Reasonability, Detail, and Consistency) achieved by each model. The use of red and blue highlights the top two performing models for each metric, offering a clear visual comparison of the relative strengths and weaknesses of different approaches. The table provides a concise summary of the experimental results, showcasing the superior performance of the HAWK model.
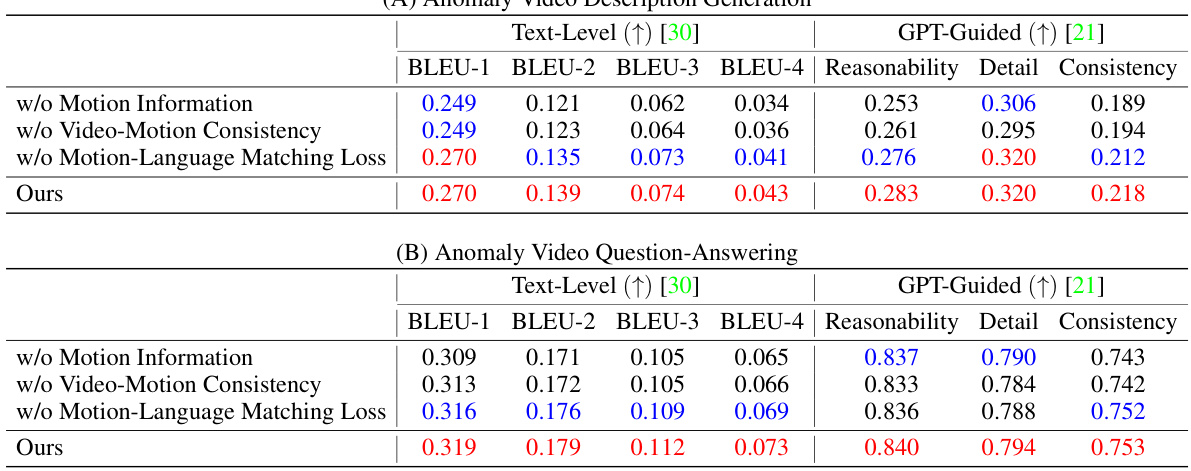
This table presents a quantitative comparison of the HAWK model against several baselines across two tasks: anomaly video description generation and video question-answering. The evaluation metrics used are BLEU scores (BLEU-1 to BLEU-4), representing the similarity between the model’s generated text and the ground truth. Additionally, GPT-Guided metrics (Reasonability, Detail, Consistency) provide a more nuanced assessment of the generated text quality, considering aspects like logical reasoning, level of detail, and overall coherence. Red highlighting indicates the best-performing model for each metric, while blue highlights the second-best. The results show HAWK’s superior performance compared to existing baselines.

This table presents a quantitative comparison of the HAWK model against several baseline models across two key tasks: anomaly video description generation and video question-answering. The evaluation metrics used are both text-level (BLEU scores) and GPT-guided (Reasonability, Detail, Consistency). The table is divided into two parts (A and B), each corresponding to one of the tasks. Red highlights the best performing model for each metric, while blue highlights the second best. This allows for a direct comparison of HAWK’s performance against state-of-the-art baselines in both tasks.

This table presents a quantitative comparison of HAWK’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. For each task (A and B), the table shows the performance metrics (BLEU scores, Reasonability, Detail, and Consistency). The BLEU scores measure the similarity between generated text and ground truth, while Reasonability, Detail, and Consistency reflect the quality of the generated text as assessed by GPT. Red highlights the top-performing model for each metric, indicating HAWK’s superior performance. The use of baseline models allows for a direct comparison and validation of HAWK’s efficacy.

This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two tasks: anomaly video description generation and video question-answering. For each task, it shows the results of various evaluation metrics, including BLEU scores (1-4) which measure the similarity between generated text and ground truth, as well as GPT-guided metrics (Reasonability, Detail, Consistency) which assess the quality of generated text from a more nuanced perspective. Red highlighting indicates the top-performing model for each metric, while blue denotes the second-best performer. This allows for a comprehensive comparison of HAWK’s capabilities across multiple evaluation criteria.

This table presents a quantitative comparison of the proposed HAWK model against several baselines for two key tasks: anomaly video description generation and video question-answering. The evaluation metrics used are BLEU scores (BLEU-1 to BLEU-4) reflecting the similarity of generated text to ground truth, and GPT-guided metrics (Reasonability, Detail, Consistency) measuring the quality and coherence of the generated text. The table is divided into two sections (A) and (B), each corresponding to one task. For each method and task, the table shows the performance using different backbones (LLMs) and their sizes in terms of parameters (e.g., 7B). Red highlights the best-performing model for each metric, and blue indicates the second-best.

This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. The results are broken down into Text-Level metrics (BLEU-1 to BLEU-4, which measure the similarity between generated and ground truth text) and GPT-Guided metrics (Reasonability, Detail, and Consistency, which assess the quality of the generated text from a holistic perspective). Red highlights the top-performing model for each metric, while blue indicates the second-best performance. The table demonstrates HAWK’s superior performance compared to established baselines.

This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. The results are evaluated using both text-level metrics (BLEU-1, BLEU-2, BLEU-3, BLEU-4) and GPT-guided metrics (Reasonability, Detail, Consistency). The best-performing model in each metric is highlighted in red, and the second-best is highlighted in blue. The table is divided into two sections (A and B), corresponding to each of the tasks, and shows the performance across different backbone models.
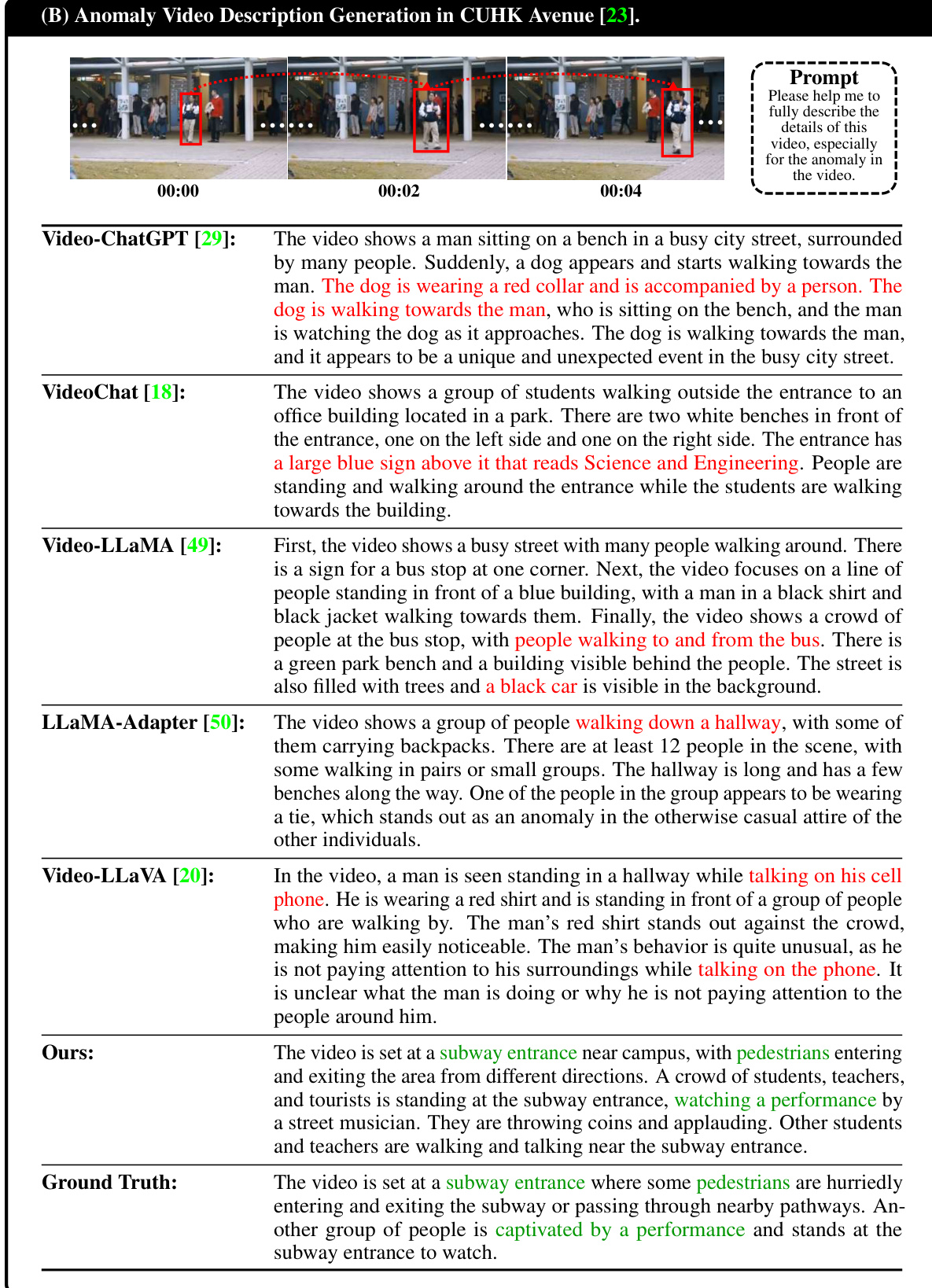
This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. For each task, it shows the results for multiple metrics: Text-Level metrics (BLEU-1, BLEU-2, BLEU-3, BLEU-4) and GPT-Guided metrics (Reasonability, Detail, Consistency). The best performing model for each metric is highlighted in red, while the second-best is in blue. This allows for a comprehensive evaluation of HAWK’s capabilities compared to existing state-of-the-art approaches.

This table presents a quantitative comparison of HAWK’s performance against several baseline models on two tasks: anomaly video description generation and video question-answering. The results are broken down into text-level metrics (BLEU-1 to BLEU-4) and GPT-guided metrics (Reasonability, Detail, Consistency). Red highlights the best-performing model for each metric, while blue indicates the second-best. This allows for a clear visualization of HAWK’s superiority in both video description and question-answering capabilities.
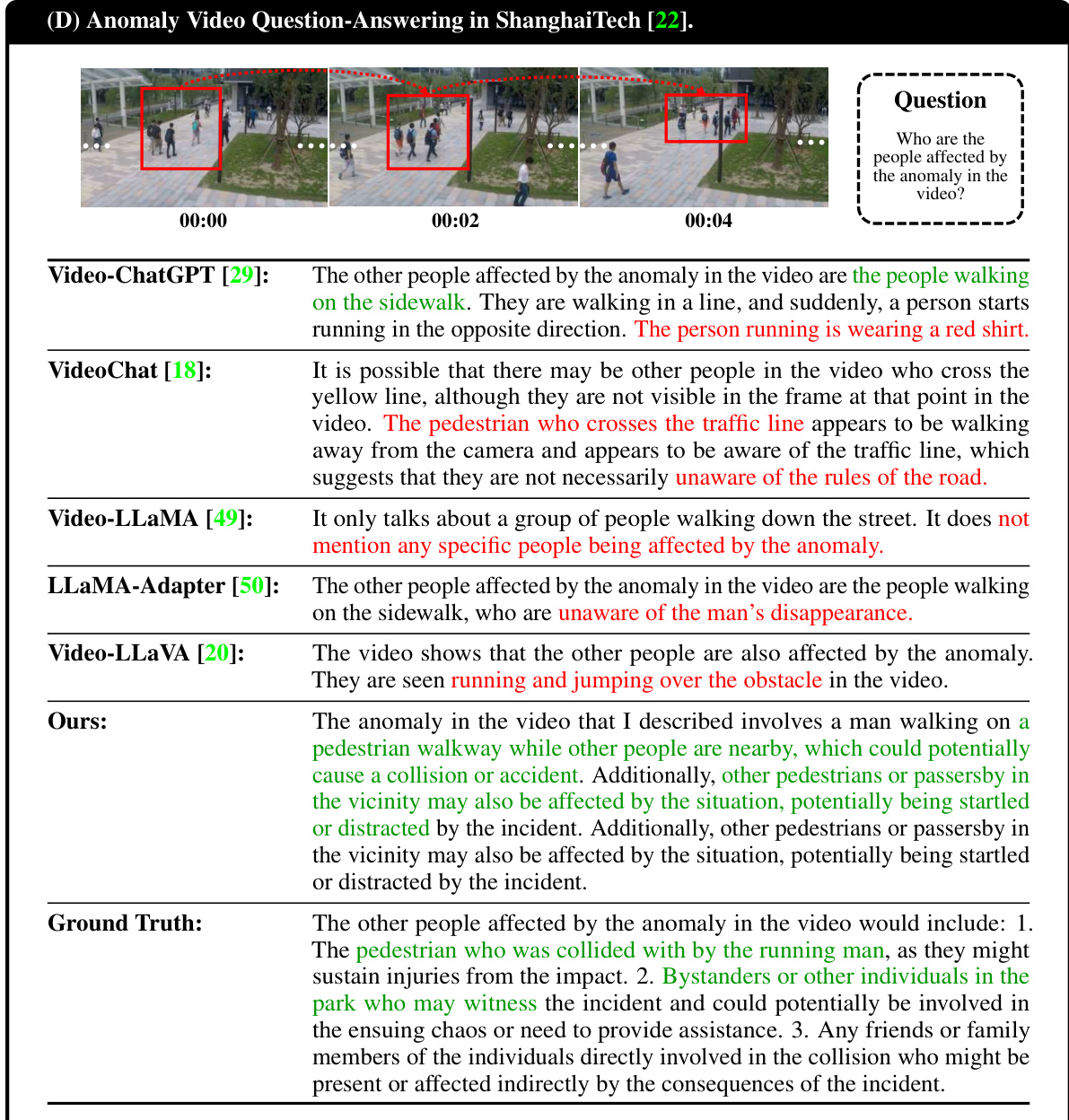
This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two key tasks: anomaly video description generation and video question-answering. The evaluation metrics used include BLEU scores (BLEU-1 through BLEU-4), which measure the similarity between generated text and ground truth, and GPT-guided metrics (Reasonability, Detail, Consistency), which assess the quality of the generated text based on human-like evaluation criteria. The table is divided into two sections (A and B) representing each task, and the best and second-best performing models are highlighted in red and blue, respectively. The results showcase HAWK’s superior performance in comparison to other state-of-the-art video understanding models.

This table presents a quantitative comparison of the HAWK model’s performance against several baseline models on two tasks: anomaly video description generation and video question-answering. For each task, it shows the results using both text-level metrics (BLEU-1 to BLEU-4) and GPT-guided metrics (Reasonability, Detail, Consistency). The best-performing model for each metric is highlighted in red, and the second-best is in blue. This allows for a comprehensive evaluation of the HAWK model’s ability to understand and generate descriptive text related to video anomalies.
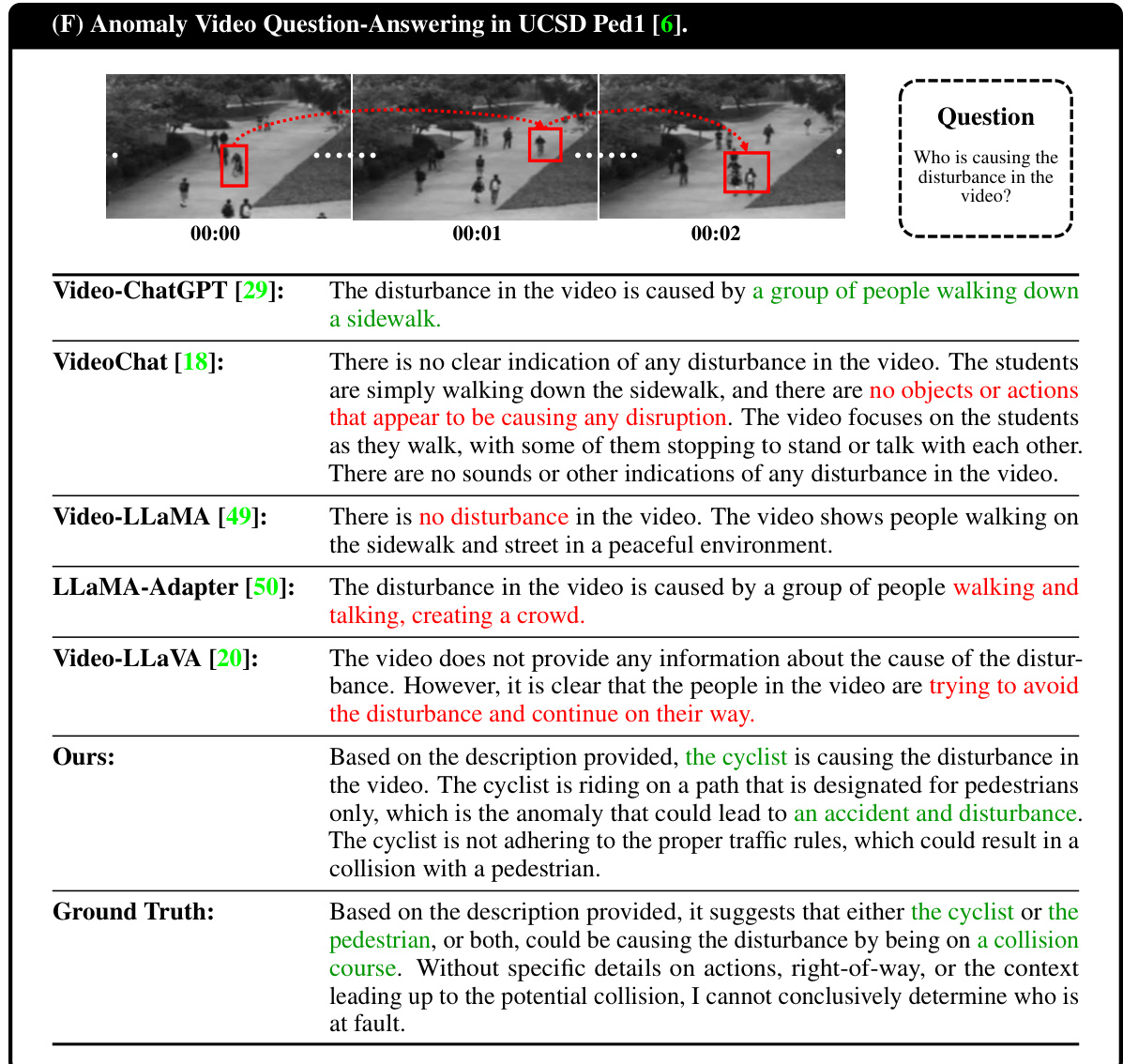
This table presents a quantitative comparison of the HAWK model’s performance against several baseline models in two key tasks: anomaly video description generation and video question-answering. The evaluation metrics used are BLEU scores (BLEU-1 to BLEU-4) for text-level evaluation and GPT-guided metrics (Reasonability, Detail, Consistency) which assess the quality of the generated text using GPT-4. Red highlights the best-performing model for each metric, while blue signifies the second-best. This allows for a comprehensive comparison of the HAWK model’s capabilities against existing state-of-the-art models in the field of video anomaly understanding.
Full paper#