↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current novel view synthesis methods for dynamic scenes struggle with automatically capturing and re-posing object skeletons, often requiring object-specific templates or pose annotations, and lacking real-time performance. This paper addresses this challenge by proposing a template-free approach using 3D Gaussian Splatting and superpoints. The method achieves visually compelling results while enabling fast rendering speed. Existing methods are limited to replaying motion within the original timeframe, hindering manipulation of individual objects.
This novel technique reconstructs dynamic objects by treating superpoints as rigid parts, thus allowing the discovery of an underlying skeleton model. An adaptive control strategy is employed to reduce redundant superpoints. The research demonstrates the efficacy of this approach by achieving real-time rendering of high-resolution images and obtaining highly re-posable 3D objects. The effectiveness is showcased through extensive experiments, proving the approach’s superior visual fidelity and efficiency compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to real-time dynamic view synthesis that avoids the need for object-specific templates and can reconstruct high-fidelity 3D scenes. This is highly relevant to various applications in fields such as virtual/augmented reality and movie production. The real-time rendering capability and class-agnostic nature opens up new research possibilities in object manipulation and control within dynamic scenes. The proposed method’s efficiency and effectiveness are further validated through extensive experiments.
Visual Insights#
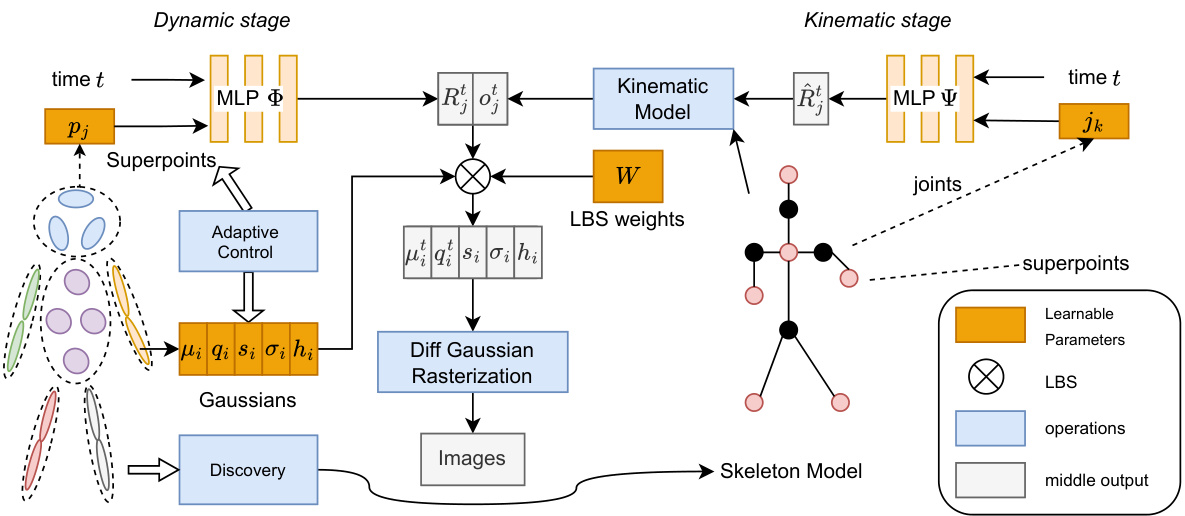
This figure illustrates the two-stage training process of the proposed method. The dynamic stage focuses on reconstructing the 3D object using 3D Gaussians and superpoints. An adaptive control strategy is employed to manage the number of superpoints. Subsequently, in the kinematic stage, a skeleton model is derived based on superpoint motions, leading to an articulated 3D model.
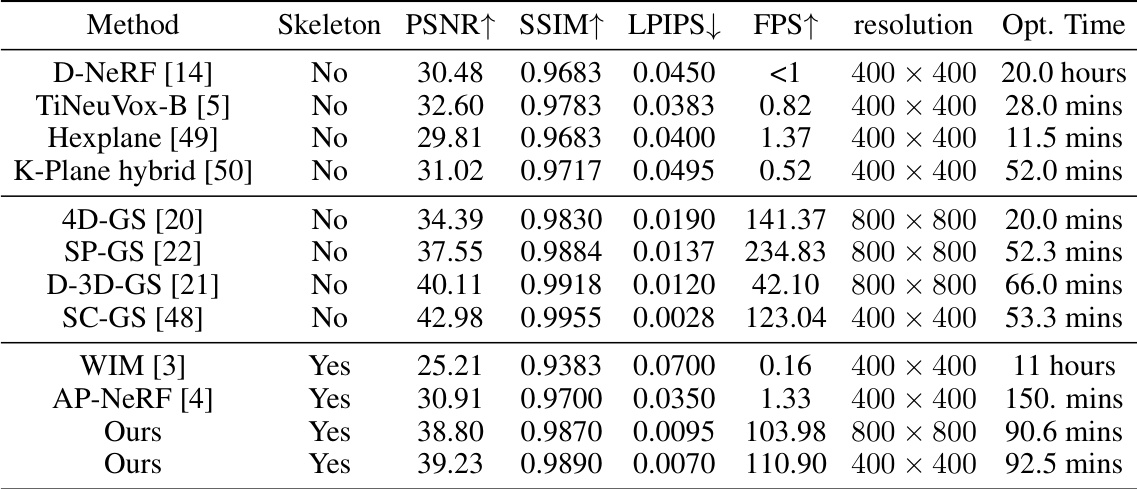
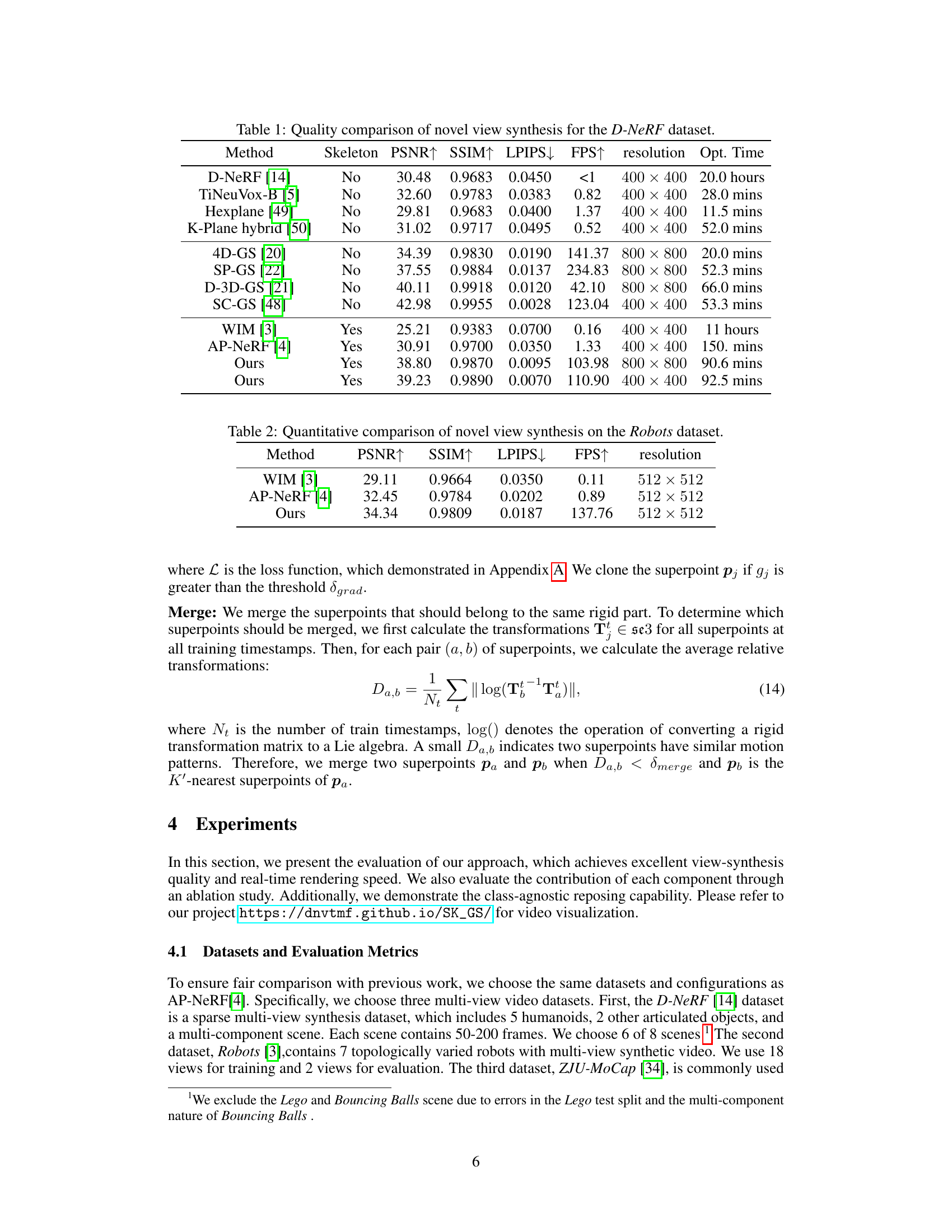
This table compares the proposed method with several state-of-the-art methods for novel view synthesis on the D-NeRF dataset. Metrics include PSNR, SSIM, LPIPS, FPS, resolution, and optimization time. The table shows that the proposed method achieves superior performance in terms of both rendering quality and speed, especially when compared to template-free methods like WIM and AP-NeRF. The proposed method also demonstrates real-time rendering capability.
In-depth insights#
Template-Free 3D#
The concept of “Template-Free 3D” in the context of this research paper likely refers to methods for reconstructing three-dimensional models from visual data without relying on pre-defined templates or prior shape knowledge. This is a significant advancement because traditional methods often require object-specific templates, which limits their generalizability. Template-free approaches enable more robust and versatile 3D modeling, particularly for complex, articulated objects or those found in natural scenes. This approach is likely achieved through learning inherent structural properties and relationships directly from the input data (e.g., videos) utilizing techniques such as Gaussian Splatting and superpoints. The ability to automatically infer skeletal models is a key part of this, enabling real-time reposing and dynamic view synthesis capabilities. This method surpasses previous template-based techniques by significantly improving scalability and handling complex object motions without reliance on predefined categories. The elimination of templates makes this approach much more efficient and adaptable to real-world scenarios.
Gaussian Splatting#
Gaussian splatting, a novel point-based rendering technique, offers significant advantages in real-time view synthesis. By representing scenes as a collection of 3D Gaussian distributions, it achieves high-fidelity results with efficient rendering. This method’s strength lies in its ability to handle complex scenes and dynamic motions effectively, overcoming limitations of previous approaches. The use of superpoints in conjunction with Gaussian splatting enables the automatic discovery of skeletal models from videos, paving the way for real-time re-posable 3D object reconstruction. Adaptive control strategies further enhance efficiency by optimizing the number of superpoints and preventing redundancy. However, limitations exist in its ability to handle extremely complex motions and its reliance on accurate input data, potentially impacting generalization to unseen poses.
Skeleton Discovery#
The paper presents a novel approach to automatically discover the skeleton model of dynamic objects from videos without using object-specific templates. The method leverages 3D Gaussian Splatting and superpoints to reconstruct the object, treating superpoints as rigid parts. The core of the skeleton discovery lies in analyzing the intuitive cues within the superpoint motions, using them to infer connections between the parts. This is achieved by calculating the relative position and orientation changes between superpoints over time and applying an adaptive control strategy to prevent redundant superpoints. The resulting skeleton model serves as a simplified representation, enabling real-time reposing of the 3D object. The approach’s strength lies in its template-free nature and efficiency, allowing class-agnostic handling of articulated objects, and its effectiveness is validated through extensive experiments.
Real-Time Repose#
The concept of “Real-Time Repose” in the context of 3D object manipulation from video data is a significant advancement. It suggests the ability to not only reconstruct a 3D model of a dynamic object (such as a human or robot) but also to manipulate its pose in real-time. This implies a system capable of generating novel views of the object in different poses, without needing extensive pre-processing or training. Real-time performance is crucial for interactive applications and virtual/augmented reality, where immediate feedback is needed. The key challenge addressed by this concept involves accurately capturing and representing the object’s articulated structure, allowing for realistic and efficient pose adjustments. Success would hinge on efficient algorithms that balance speed and accuracy in both object modeling and pose manipulation. Template-free approaches, as hinted at in the paper, add further complexity by necessitating the automatic learning of skeletal structures from motion data alone. The research likely focuses on optimizing the trade-off between computational cost and visual fidelity, making interactive pose manipulation a reality.
Future Directions#
Future research directions for template-free articulated Gaussian splatting could involve improving the robustness of skeleton discovery, particularly for complex scenes with occlusions or non-rigid deformations. Further work could explore more sophisticated articulation models beyond the current kinematic model, potentially using techniques from physics-based simulation or learned representations. Another important area would be extending the approach to handle larger-scale, more complex scenes, which would necessitate efficient techniques for managing a vastly increased number of Gaussians and superpoints. Finally, enhancing the system’s ability to generalize across object categories and handle scenarios with significant viewpoint changes would represent significant advancements. This could involve incorporating richer feature representations or leveraging more robust methods for view synthesis.
More visual insights#
More on figures

This figure shows a qualitative comparison of novel view synthesis results on the D-NeRF dataset for five different sequences. The methods compared are WIM, AP-NeRF, the proposed ‘ours’ method, and the ground truth. Each row represents a different sequence, with several frames shown from different viewpoints for each method. The red boxes highlight specific areas where differences between the methods are apparent. The goal is to visualize the strengths and weaknesses of each approach in terms of visual fidelity, detail preservation, and overall realism.

This figure compares the qualitative results of novel view synthesis on the Robots dataset using three different methods: WIM, AP-NeRF, and the proposed method. The figure shows several examples of robot poses, with each row representing a different robot. For each robot, there are four columns showcasing the results from WIM, AP-NeRF, the authors’ proposed method, and finally the ground truth. Red boxes highlight areas where differences between the methods and the ground truth are most apparent, giving a visual illustration of the relative performance of each method on object reconstruction and pose accuracy.

This figure displays a qualitative comparison of novel view synthesis results on the D-NeRF dataset. It showcases the ground truth images alongside the results generated by four different methods: the authors’ proposed approach, AP-NeRF, WIM, and Ours. The comparison highlights the visual differences between the methods, particularly in terms of detail preservation, reconstruction accuracy, and overall visual fidelity.

This figure demonstrates the reposing capability of the proposed method. It shows how the learned skeleton model can be used to generate novel poses by interpolating between a canonical pose and a target pose. The interpolation is smooth and natural, showing the effectiveness of the method in controlling the movement of individual parts of the object.

This figure shows a qualitative comparison of novel view synthesis results on the D-NeRF dataset. It compares the results of the proposed method with those of WIM, AP-NeRF, and the ground truth. Each column represents a different method, and each row represents a different sequence from the dataset. The images visually demonstrate the quality of novel view synthesis achieved by each method, allowing for a direct comparison of visual fidelity, motion accuracy and detail.

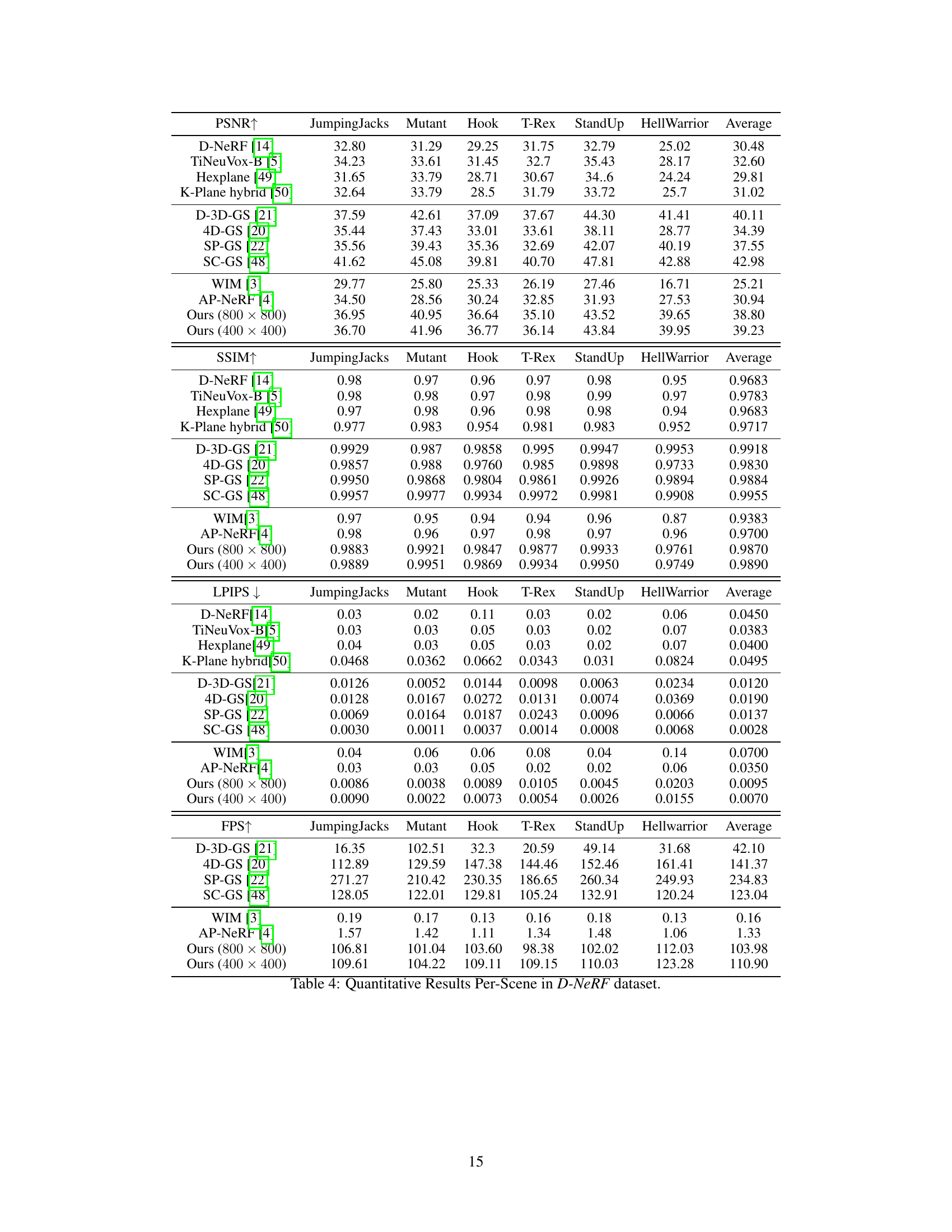
This figure shows a qualitative comparison of novel view synthesis results on the D-NeRF dataset. It compares the results of the proposed method with those of WIM [3] and AP-NeRF [4]. The comparison includes five different sequences of human actions (jumping jacks, mutant, hook, T-rex, and standup) and their corresponding novel views generated by each method. The ground truth images are also provided for reference. The figure visually demonstrates the superior visual quality and rendering speed of the proposed method compared to the baseline methods.

This figure presents a qualitative comparison of novel view synthesis results on the D-NeRF dataset. It shows the reconstructed objects from four different methods: AP-NeRF, ours, WIM, and the ground truth. For each method, multiple views of the same object in different poses are presented, allowing for a visual comparison of the accuracy and quality of the reconstructions. This comparison highlights the strengths and weaknesses of each approach in terms of visual fidelity and detail preservation.
More on tables

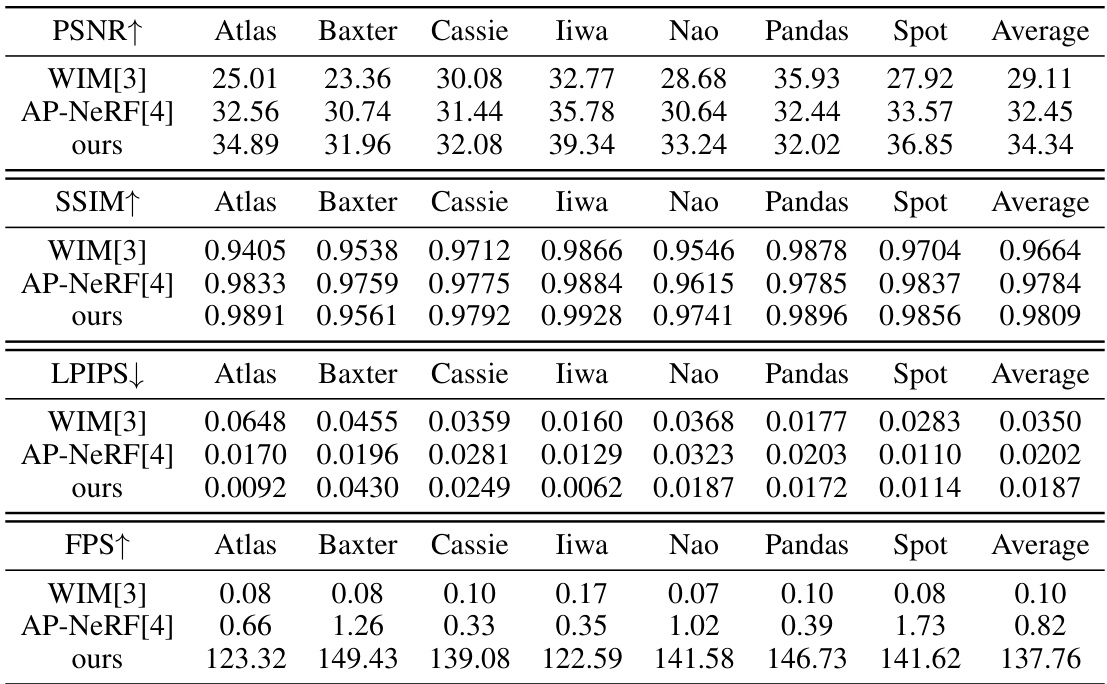
This table presents a quantitative comparison of the proposed method against state-of-the-art methods, WIM and AP-NeRF, for novel view synthesis on the Robots dataset. The comparison is based on three metrics: PSNR, SSIM, and LPIPS, which evaluate the visual quality of the synthesized images. Additionally, the table includes the rendering speed (FPS) and resolution of the synthesized images. The results demonstrate that the proposed method outperforms existing approaches in terms of both visual quality and rendering speed.
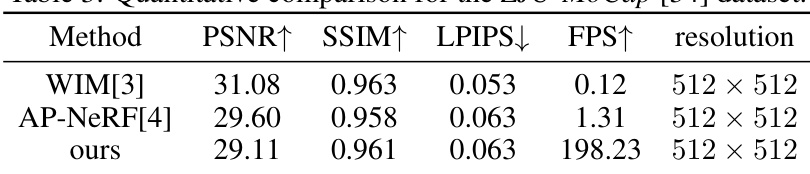
This table presents a quantitative comparison of the proposed method with WIM[3] and AP-NeRF[4] on the ZJU-MoCap dataset. It shows the PSNR, SSIM, LPIPS, and FPS for each method at a resolution of 512x512 pixels. The results highlight the superior speed of the proposed method while demonstrating comparable performance in terms of image quality metrics.
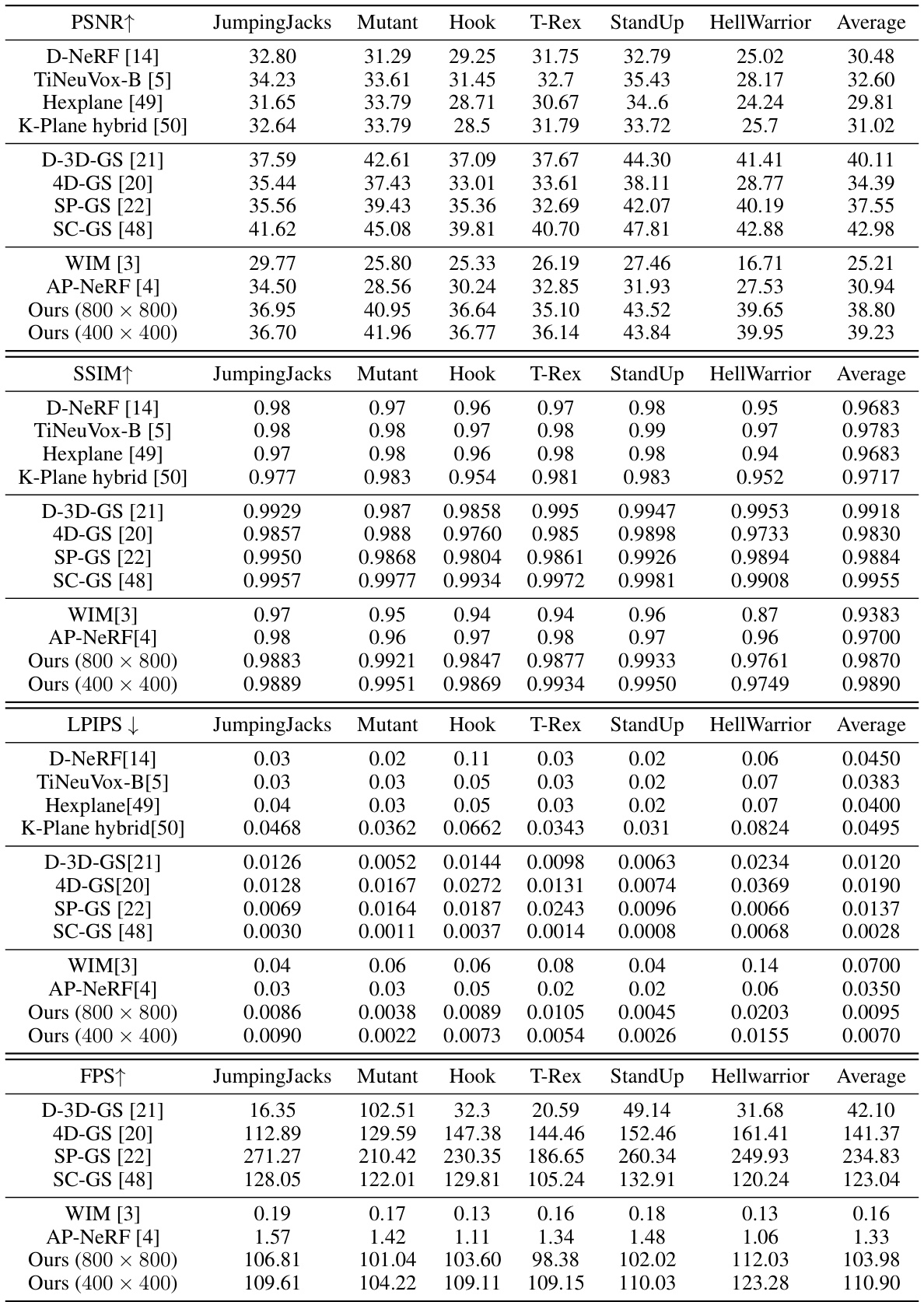
This table compares the proposed method with other state-of-the-art methods for novel view synthesis on the D-NeRF dataset. The metrics used for comparison include PSNR, SSIM, LPIPS, and FPS. The table shows that the proposed method achieves better performance in terms of visual quality (PSNR, SSIM, LPIPS) and rendering speed (FPS) compared to other methods.
This table presents a quantitative comparison of the proposed method against WIM and AP-NeRF on the ZJU-MoCap dataset. The metrics used for comparison are PSNR, SSIM, LPIPS, and FPS. Higher PSNR and SSIM values indicate better visual quality, while a lower LPIPS value indicates a smaller perceptual difference between the generated and ground truth images. Higher FPS indicates faster rendering speed. The results demonstrate that the proposed method outperforms the baselines in terms of both speed and visual quality.

This table presents the training time (in hours), GPU VRAM usage (in GB), the number of Gaussians (in 10^5), and the number of superpoints used for each scene in the D-NeRF dataset. These metrics give insight into the computational cost associated with training the model for different scenes with varying complexity.

This table presents the results of an ablation study conducted to determine the optimal number of initial superpoints (M) for the \textquotesingle hellwarrior\textrquotesingle scene in the D-NeRF dataset. The study varied the number of superpoints (M) and measured the impact on PSNR, SSIM, and LPIPS metrics. The results help to understand how the choice of the initial number of superpoints affects the overall quality of the novel view synthesis.
Full paper#