↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality 3D models from images has been challenging due to limitations in scalability and the need for indirect methods (e.g., multi-view generation). Existing methods often involve multiple steps, leading to efficiency issues and potential loss of detail. Many methods rely on rendered images for supervision, which can be less effective than direct geometry supervision.
Direct3D tackles these problems with a two-component approach: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). The D3D-VAE efficiently encodes 3D shapes, using a semi-continuous surface sampling strategy for better supervision, while the D3D-DiT fuses positional information from triplane latent space with image conditions, creating a scalable model that directly generates high-quality 3D assets from single images. Extensive experiments show Direct3D outperforming existing methods significantly.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Direct3D, a novel approach that significantly improves the quality and scalability of image-to-3D generation. It directly trains on large-scale 3D datasets, avoiding the indirect multi-view approach and improving both accuracy and efficiency. This offers researchers a new state-of-the-art method, and opens up potential avenues for research in large-scale 3D data training and high-fidelity 3D content creation.
Visual Insights#

This figure showcases the results of Direct3D, a novel image-to-3D generation method. It demonstrates the model’s ability to generate high-quality, diverse 3D shapes from a wide range of input images, even those generated by text-to-image models. The figure highlights the model’s state-of-the-art generation quality and generalizability, achieved by directly training on a large-scale 3D dataset and using a novel 3D latent diffusion model.
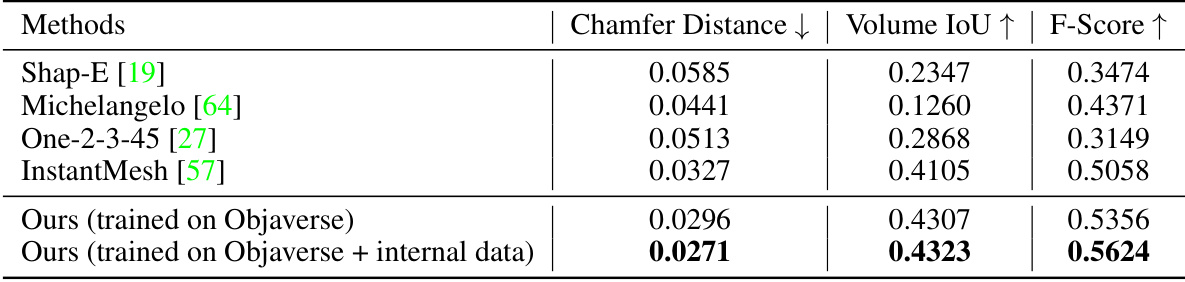
This table presents a quantitative comparison of the proposed Direct3D model against several state-of-the-art image-to-3D generation methods on the Google Scanned Objects (GSO) dataset. The metrics used for comparison include Chamfer Distance (lower is better), Volume IoU (higher is better), and F-Score (higher is better). The results demonstrate the superior performance of Direct3D in terms of generating high-quality 3D models.
In-depth insights#
Direct 3D Diffusion#
The concept of “Direct 3D Diffusion” presents a compelling alternative to traditional multi-stage image-to-3D pipelines. Instead of indirectly generating 3D shapes through intermediate multi-view image representations, this approach directly learns a mapping from a single image to a 3D latent space. This direct approach offers significant advantages in terms of efficiency and scalability, bypassing the computationally expensive and potentially lossy steps involved in multi-view reconstruction. Direct 3D diffusion models often leverage innovative 3D representations like triplanes or occupancy grids, which are inherently more efficient for encoding and decoding 3D information compared to implicit representations. Furthermore, the use of conditional diffusion models allows the incorporation of image features directly into the 3D generation process, leading to better alignment between the generated 3D model and the input image. However, challenges remain in effectively training these models due to the complexities of 3D data, requiring novel supervision strategies and architectural designs. The success of this paradigm depends heavily on the ability to learn efficient latent representations capable of capturing intricate geometric details. The ultimate promise lies in its potential to democratize high-quality 3D content creation by simplifying and accelerating the workflow.
TriPlane Latent Space#
The concept of a “TriPlane Latent Space” in 3D generation is intriguing. It suggests a method of representing complex 3D shapes using three 2D feature maps, effectively encoding a three-dimensional structure in a lower-dimensional space. This approach could offer advantages in computational efficiency and scalability, particularly when handling high-resolution 3D models. The inherent structure of the triplane, with each plane potentially representing orthogonal views or other related features, might facilitate the generation of more coherent and detailed 3D models. However, limitations could include the potential loss of information during the encoding and decoding processes, particularly concerning fine geometric details. The success of this approach hinges on the effectiveness of the encoding and decoding networks in capturing and recovering the essential 3D structure, requiring careful design and training to minimize information loss. The triplane latent space offers a potentially significant advancement in 3D generation, particularly for its potential scalability and efficiency, but its success relies critically on robust encoding and decoding techniques. Further exploration of various triplane configurations and neural architectures is essential to fully understand its potential and limitations.
Image Conditioning#
Image conditioning, in the context of image-to-3D generation, is a crucial technique that leverages information from a 2D image to guide the synthesis of a corresponding 3D model. Effective image conditioning ensures that the generated 3D object accurately reflects the visual content, semantic understanding, and details present in the input image. This conditioning can be implemented at multiple levels, including pixel-level alignment which meticulously aligns fine-grained image details with the 3D model, and semantic-level alignment that uses higher-level image features (like object classes) to guide the overall structure and content of the 3D output. The success of image conditioning depends heavily on the quality and representational power of the image features used and the effectiveness of the mechanism used to integrate these features into the 3D generation process. A well-designed image conditioning module is essential for generating high-quality, realistic, and semantically consistent 3D models from images, bridging the gap between 2D and 3D representations. It directly impacts the realism, detail, and overall accuracy of the generated 3D output, enabling the creation of sophisticated and detailed 3D assets from readily available 2D image data.
Scalability#
The concept of scalability in the context of image-to-3D generation is multifaceted. Direct3D’s scalability is primarily achieved through its native 3D generative model, bypassing the multi-view approach and associated computational burdens. This allows for training on larger-scale 3D datasets, which are generally limited in size. Furthermore, the use of a compact and continuous triplane latent space significantly contributes to efficiency and scalability, enabling the processing of higher-resolution 3D shapes. The incorporation of image-conditional mechanisms does not appear to negatively impact scalability, suggesting a well-designed architecture that maintains efficiency while providing high-quality results. However, the paper does not explicitly quantify scalability in terms of computational resources used or the size of datasets that can be effectively handled, leaving room for further investigation and a more precise understanding of its limits. A rigorous scalability analysis, possibly across different hardware and dataset sizes, would strengthen the claim of scalability and provide a more comprehensive perspective on Direct3D’s practical capabilities.
Future Work#
The paper’s significant contribution lies in its novel approach to direct 3D shape generation from a single image, bypassing multi-view methods. Future work could explore several promising avenues: expanding the model’s scalability to handle significantly larger-scale 3D datasets, improving the efficiency and speed of generation, and enhancing the model’s ability to generate more complex and detailed 3D scenes. Further research into incorporating more sophisticated semantic understanding could lead to better control over the generated shapes, allowing for finer-grained manipulation of object features. Addressing the model’s current limitations, such as struggles with complex geometry and consistency in fine details, would enhance its practicality. A critical aspect for future development is investigating the model’s robustness to noise and variations in input image quality. Finally, ethical considerations regarding potential misuse of high-fidelity 3D generation technology must be addressed.
More visual insights#
More on figures
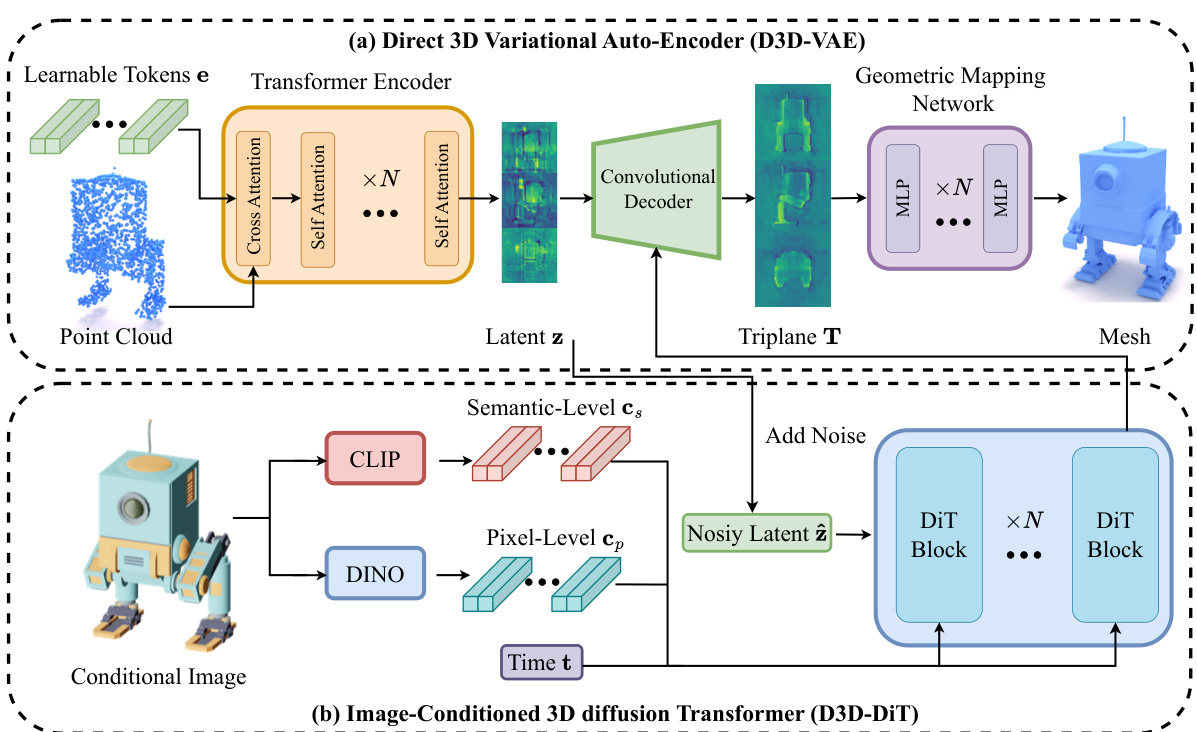
This figure illustrates the Direct3D framework, which consists of two main components: the Direct 3D Variational Auto-Encoder (D3D-VAE) and the Direct 3D Diffusion Transformer (D3D-DiT). The D3D-VAE encodes high-resolution point clouds into a compact triplane latent space, which is then decoded into a high-resolution occupancy grid. The D3D-DiT generates 3D shapes from this latent space, conditioned on an input image. The image conditioning involves both pixel-level and semantic-level information extracted using DINO-v2 and CLIP, respectively.
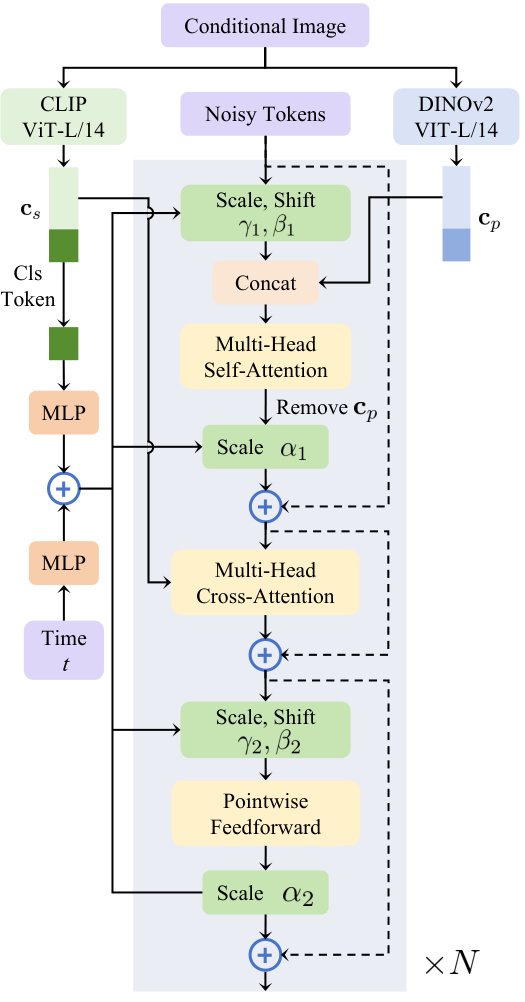
This figure shows the architecture of the 3D Diffusion Transformer (D3D-DiT) which is a crucial part of the Direct3D model. It illustrates how pixel-level and semantic-level image information is integrated into the model’s diffusion process using pre-trained DINO-v2 and CLIP models. The figure details the flow of information through multiple DiT blocks, highlighting the mechanisms for multi-head self-attention, multi-head cross-attention, and pointwise feedforward operations within the blocks. The use of learnable scale and shift parameters is also depicted.

This figure presents a qualitative comparison of 3D model generation results from different methods (Shap-E, One-2-3-45, Michelangelo, InstantMesh, and the proposed Direct3D method) using images from the Google Scanned Objects (GSO) dataset as input. Each row shows a different input image and the corresponding 3D models generated by each method. The purpose is to visually demonstrate the relative strengths and weaknesses of each approach in terms of accuracy, detail, and overall quality of the generated 3D models.

This figure shows a qualitative comparison of 3D mesh generation results from different methods using text prompts as input. The text prompts are converted into images using text-to-image models before being fed into the 3D generation methods. This helps visualize the differences in the quality and detail of the 3D models produced by each approach. The input image for each row is consistent across all methods, allowing for direct comparison of the generated outputs.

This figure displays several examples of 3D models generated by the Direct3D model and then textured using SyncMVD. The figure showcases the model’s ability to produce high-quality 3D assets that are suitable for texturing, demonstrating the final output after applying textures to the base 3D model. The examples include a chess queen, a totem, a mech suit, and a teapot.
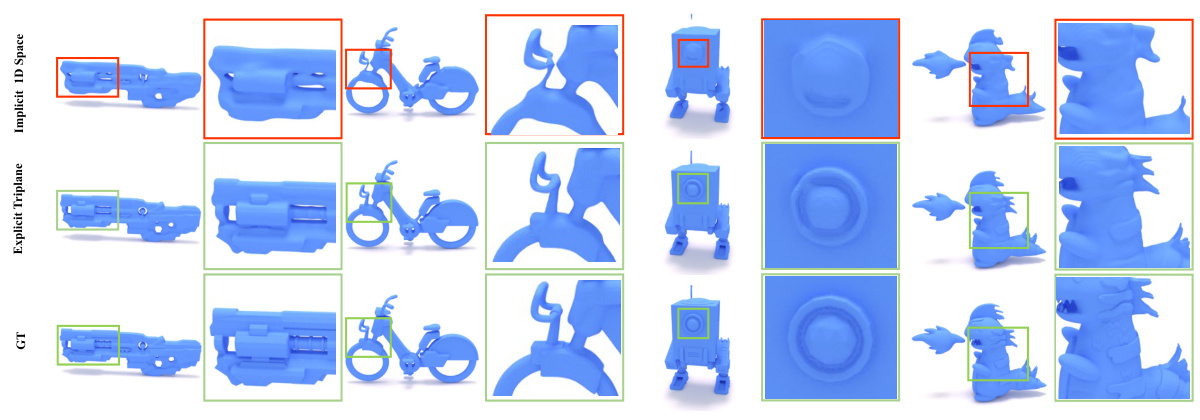
This figure compares the 3D model reconstruction quality using different latent space representations. The top row shows the results using an implicit 1D latent space, demonstrating difficulties in reconstructing fine details. The middle row showcases the reconstruction using the proposed explicit triplane latent, which effectively recovers high-frequency geometric details, leading to more realistic 3D models. The bottom row displays the ground truth (GT) 3D models for comparison. The red boxes highlight regions where the implicit 1D method struggles to reconstruct fine details, while the green boxes point to areas where the explicit triplane method excels.
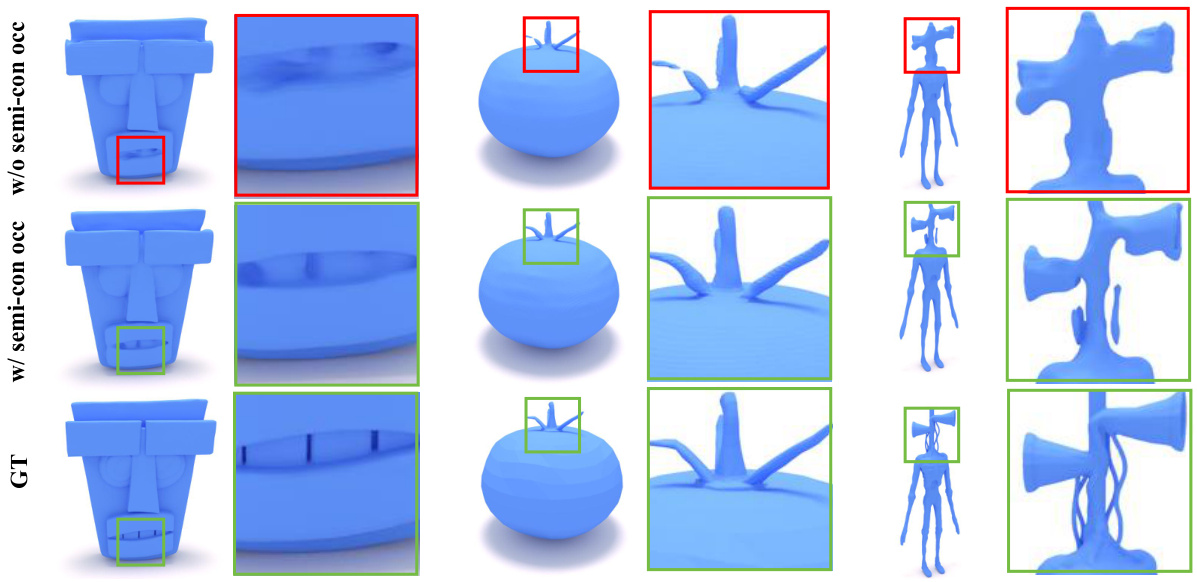
This figure shows a qualitative comparison of 3D model reconstruction results using different surface sampling strategies. The top row shows results without using the semi-continuous surface sampling strategy, which results in artifacts. The middle row demonstrates improvements using the semi-continuous surface sampling strategy. The bottom row displays the ground truth models (GT). The comparison highlights the benefits of the semi-continuous sampling strategy in accurately reconstructing fine details and avoiding artifacts, especially in areas with thin or complex geometries.

This figure compares the 3D model generation results of different diffusion models, including D3D-SD 1.5, D3D-SD 2.1, D3D-DiT (without pixel alignment), and D3D-DiT. It highlights the impact of the network architecture and the pixel alignment module on the quality and detail of the generated 3D models, demonstrating the superiority of the D3D-DiT model with pixel alignment in producing high-fidelity 3D meshes that closely match the input images. The figure showcases two example image-to-3D generation results: a coffee machine and an angel statue. It clearly shows that D3D-DiT with pixel alignment produces the most realistic and accurate 3D model.

This figure contains several additional examples of 3D models generated by the Direct3D model, showcasing the variety and quality of the 3D shapes it produces. The models include various objects like a dog, a watch, a guitar, a hat, a vacuum cleaner, a sandcastle, an axe, a bird, a teapot, and a chest. For each object, multiple views are provided to fully capture the 3D shape.
More on tables

This table presents the results of a user study that evaluated the quality and consistency of 3D meshes generated by different methods. Users rated the meshes on a scale of 1 to 5, with higher scores indicating better quality and consistency. The methods compared include Shap-E, One-2-3-45, Michelangelo, InstantMesh, and the authors’ proposed method (Ours). The table shows that the authors’ method achieved significantly higher scores for both quality and consistency, indicating that their approach generates superior 3D models.

This table presents a quantitative comparison of 3D shape reconstruction results using two different latent space representations: an implicit 1D space (Shape2VecSet) and an explicit triplane (the authors’ method). The comparison is based on the Objaverse evaluation set and uses three metrics: Chamfer Distance (lower is better), Volume IoU (higher is better), and F-Score (higher is better). The results demonstrate the superior performance of the explicit triplane representation in accurately reconstructing 3D shapes.

This table presents a quantitative comparison of the model’s performance using different sampling strategies during training. It shows the Chamfer Distance, Volume IoU, and F-Score metrics for models trained with and without a semi-continuous surface sampling strategy. The results demonstrate the effectiveness of the semi-continuous sampling strategy in improving reconstruction quality.
Full paper#



















