↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Adapting large vision-language models (VLMs) to specific tasks with limited data is challenging. Existing methods often struggle to balance task-specific adjustments with preservation of general knowledge, leading to poor generalization. This is because they focus on observed data samples without considering the underlying structure of the latent manifolds.
This paper introduces a Homology Consistency (HC) constraint to address this challenge. HC leverages persistent homology to explicitly constrain the correspondence between image and text latent manifolds, guiding the tuning process to maintain structural equivalence. The HC constraint is implemented for two common adapter tuning paradigms. Results on 11 datasets demonstrate significant improvements over existing methods in both few-shot learning and domain generalization, showcasing HC’s robustness and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and effective method for improving the efficiency and generalizability of vision-language model tuning. The Homology Consistency constraint offers a new perspective on aligning image and text latent manifolds, addressing a key challenge in efficient transfer learning. This work is highly relevant to the current focus on efficient adaptation of large-scale models for downstream tasks with limited data, potentially opening new avenues in the field of few-shot learning and domain generalization.
Visual Insights#
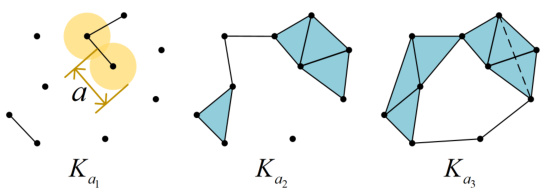
This figure illustrates the concept of a filtration in persistent homology. It shows a sequence of nested simplicial complexes (K_a1, K_a2, K_a3) built from a point cloud. As the parameter ‘a’ (representing a distance threshold) increases, more edges and higher-dimensional simplices are added to the complex, reflecting the growth of connected components and the appearance/disappearance of topological features (e.g., holes) at different scales. This progression visualizes how persistent homology tracks the evolution of topological features across multiple scales by observing their ‘birth’ and ‘death’ within the filtration.
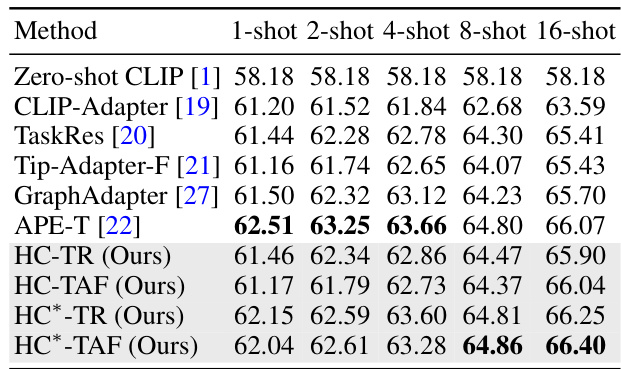
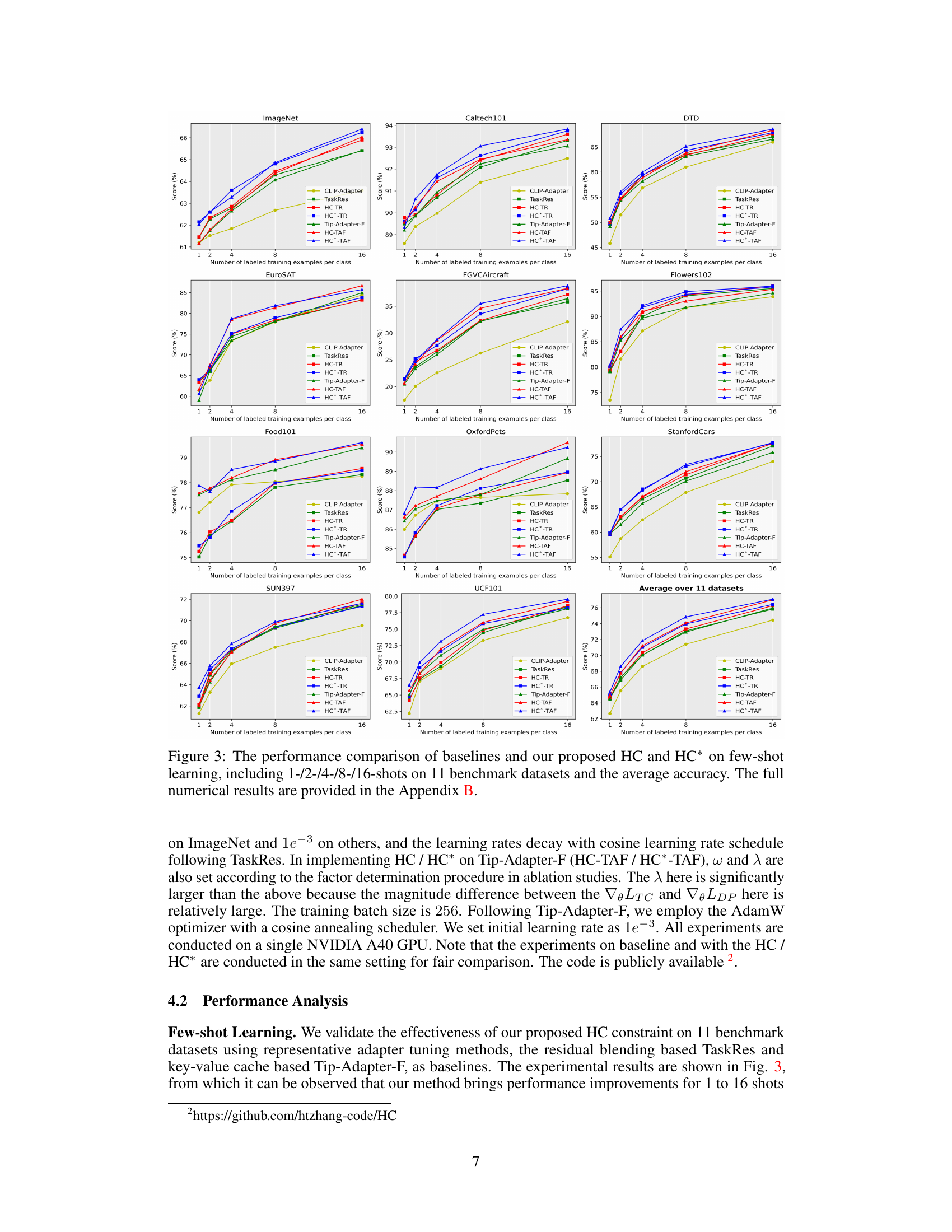
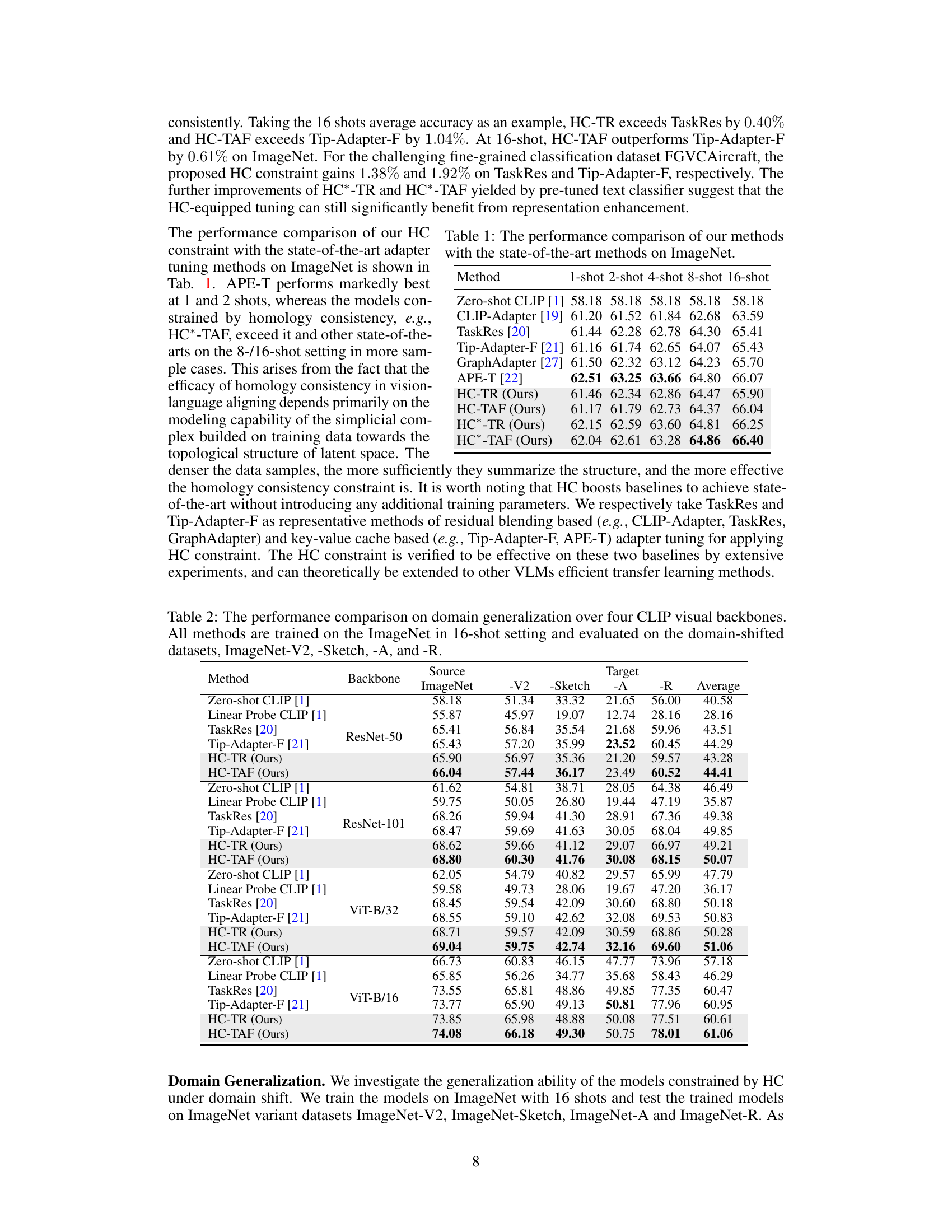
This table compares the performance of the proposed Homology Consistency (HC) method with state-of-the-art adapter tuning methods on the ImageNet dataset. It shows the average accuracy achieved by different methods for few-shot image classification (1, 2, 4, 8, and 16 shots per class). The results highlight the improvements achieved by HC-TR and HC-TAF compared to existing methods, especially with a larger number of shots.
In-depth insights#
HC Constraint Tuning#
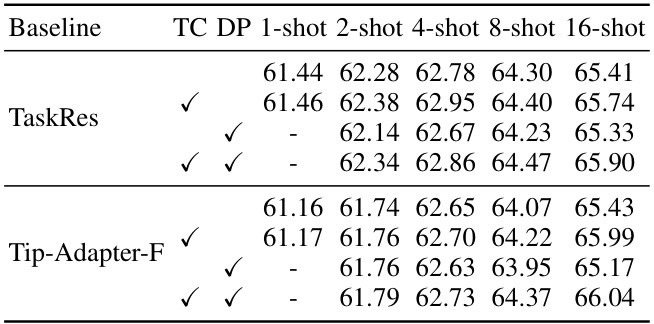
The proposed HC (Homology Consistency) constraint tuning method offers a novel approach to efficient transfer learning in vision-language models (VLMs). By leveraging persistent homology from topological data analysis, HC explicitly constrains the correspondence between image and text latent manifolds, ensuring that the semantic alignment is adjusted while preserving pre-trained general knowledge. This is a significant improvement over existing methods that only consider observed samples. The method constructs simplicial complexes to capture the topology of latent manifolds, then tracks the persistence of homology classes across scales, guiding the tuning process to maintain topological equivalence. The HC constraint is tailored for two main adapter tuning paradigms (residual blending and key-value cache), demonstrating its adaptability and practicality. Extensive experiments on various datasets showcase improved few-shot learning and robust domain generalization capabilities, highlighting the efficacy and robustness of the HC constraint in enhancing VLM tuning. A key strength is the explicit focus on preserving the underlying structure of the latent manifolds, leading to better generalization, addressing a critical limitation of prior approaches that rely solely on limited sample data. The method’s theoretical foundation in topology also provides a clear rationale for its effectiveness.
Persistent Homology#
Persistent homology, a concept from topological data analysis, offers a powerful method for analyzing the shape and structure of data. Instead of focusing solely on point-wise features, it captures global topological features such as connected components, loops, and voids, which are robust to noise and variations in the data. By tracking the persistence of these features across different scales, it identifies significant structures that are not merely artifacts of the sampling process. Persistent homology effectively summarizes the underlying topology, providing a concise yet informative representation suitable for various machine learning tasks. This makes it particularly useful for comparing the latent manifolds of image and text embeddings in vision-language models, as topological features provide a means of aligning semantics across modalities, even with limited data.
Adapter Tuning Methods#
Adapter tuning methods offer an efficient approach to adapting pre-trained vision-language models (VLMs) to downstream tasks, avoiding the catastrophic forgetting often seen with full fine-tuning. These methods typically involve inserting lightweight modules, or adapters, into the pre-trained network, allowing for task-specific adjustments without altering the original model’s weights. Key-value cache based methods represent a significant advancement, enabling efficient adaptation by storing task-relevant information in a cache, leveraging the power of pre-trained embeddings while dynamically adjusting based on new inputs. However, a crucial challenge remains in maintaining the correspondence of image and text latent manifolds during adaptation. While adapter tuning efficiently adjusts model parameters, it’s vital to preserve the inherent semantic relationships learned during pre-training. Future research should focus on techniques that explicitly address this challenge, potentially integrating topological data analysis to guide adaptation and ensure robustness across diverse downstream tasks. This is crucial for the reliable and effective deployment of VLMs in real-world applications.
Few-Shot Learning#
The heading ‘Few-Shot Learning’ in this context likely refers to a section of the research paper detailing experiments where vision-language models (VLMs) are evaluated on their ability to perform well on downstream tasks with minimal training data. The core challenge is adapting pre-trained VLMs to new tasks without overfitting to limited samples while retaining the general knowledge acquired during pre-training. The results in this section would likely demonstrate how effectively the proposed method (Homology Consistency constraint) enhances the performance of VLMs in few-shot scenarios. The experiments would probably involve several benchmark datasets and different VLM architectures, comparing the proposed method’s performance against state-of-the-art baseline techniques. The analysis would focus on the accuracy and generalization capabilities, likely showing how the Homology Consistency method helps bridge the gap between limited data and robust model performance. Key metrics to look for in this section would be classification accuracy across different numbers of training examples per class (e.g., 1, 2, 4, 8, 16 shots). A strong few-shot learning performance would be a significant contribution, highlighting the method’s effectiveness in handling limited data while maintaining generalization to unseen data points. The discussion might also include analysis of the computational costs associated with different approaches, especially if the Homology Consistency method significantly increases computational demands.
Future Work#
The ‘Future Work’ section of this research paper presents exciting avenues for expanding upon the current findings. Extending the homology consistency constraint to higher-dimensional homology classes is crucial for a more comprehensive understanding of complex data structures. Investigating the application of this method to diverse downstream tasks beyond few-shot learning would significantly broaden its practical impact and demonstrate its generalizability. This includes exploring its use in tasks such as domain adaptation, zero-shot learning, and visual question answering. Furthermore, a thorough comparative analysis against other state-of-the-art efficient transfer learning methods across a wider range of datasets and tasks would strengthen the overall contribution. Finally, exploring the computational efficiency of the proposed method and developing strategies for optimizing its performance on large-scale datasets is essential for practical applications. Addressing these points would not only enhance the paper’s significance but also pave the way for significant advancements in efficient vision-language model tuning.
More visual insights#
More on figures
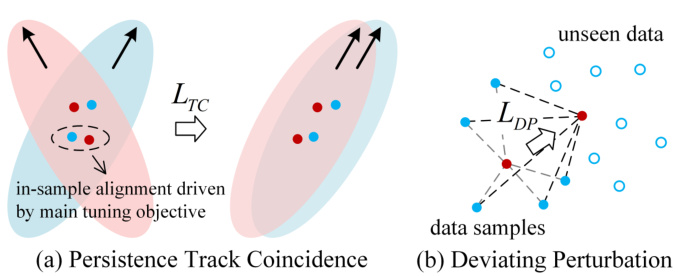
This figure illustrates the Homology Consistency (HC) constraint, a key component of the proposed method. Panel (a) shows the concept of ‘Persistence Track Coincidence’ (TC). It explains how the method aligns the topological structures of image and text latent manifolds by ensuring that the directions of persistence tracks in both manifolds match. This goes beyond simply aligning observed data points and aims to capture the overall relationship between the manifolds. Panel (b) depicts ‘Deviating Perturbation’ (DP). This addresses the issue of limited data in few-shot learning by encouraging a uniform distribution of text-related images around their corresponding texts, even beyond the seen data. This prevents overfitting and improves generalization.

This figure compares the performance of different methods on 11 benchmark datasets for few-shot image classification. The methods include baseline approaches (CLIP-Adapter, TaskRes, Tip-Adapter-F) and the proposed methods with and without a pre-trained text classifier (HC-TR, HC*-TR, HC-TAF, HC*-TAF). The x-axis represents the number of labeled training examples per class (1, 2, 4, 8, 16 shots), and the y-axis represents the classification accuracy. The results show the improvement achieved by incorporating the homology consistency constraint (HC) in the adapter tuning methods.
More on tables
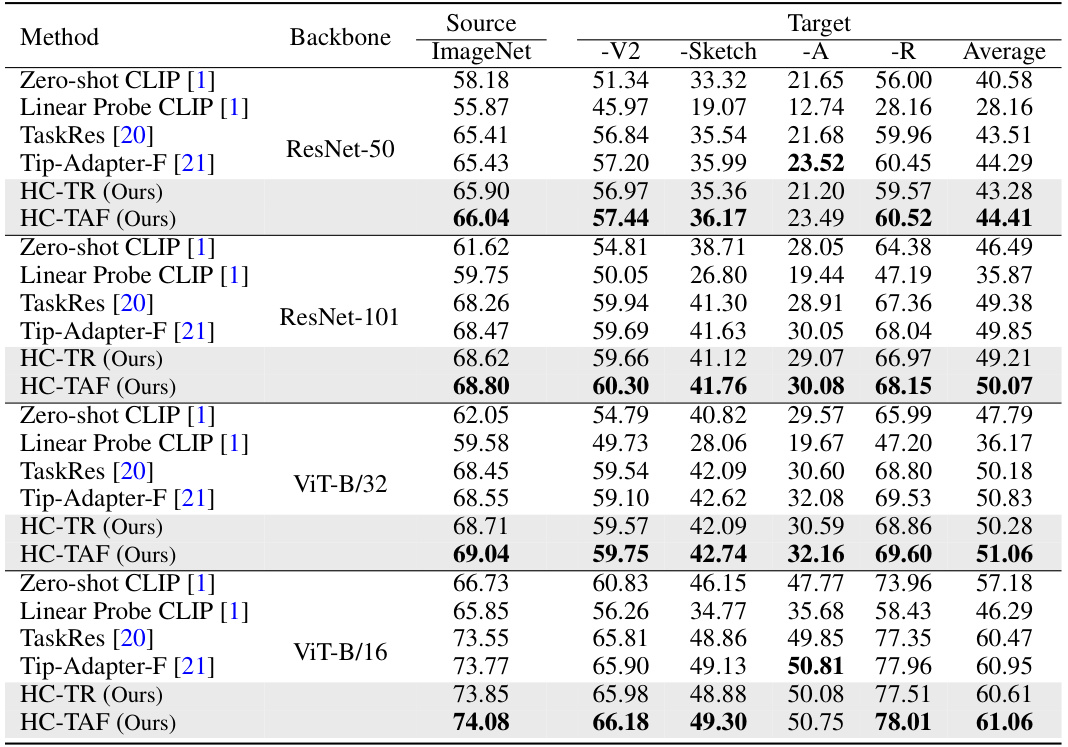
This table presents the performance comparison of different methods on domain generalization. The methods are all trained on the ImageNet dataset using 16 shots per class. The performance is then evaluated on four domain-shifted versions of ImageNet: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. The table shows the average accuracy across these four datasets, as well as the individual accuracy for each dataset. This allows assessing the generalization capabilities of different approaches when facing domain shift.
This table presents the results of few-shot learning experiments on 11 benchmark datasets using different methods: CLIP-Adapter, TaskRes, Tip-Adapter-F, HC-TR, HC*-TR, HC-TAF, and HC*-TAF. The table shows the average accuracy for 1, 2, 4, 8, and 16 labeled training examples per class. It compares the performance of baseline methods against the proposed Homology Consistency (HC) constraint method. The HC methods incorporate the proposed technique using both residual blending and key-value cache tuning paradigms. The full numerical results can be found in Appendix B.
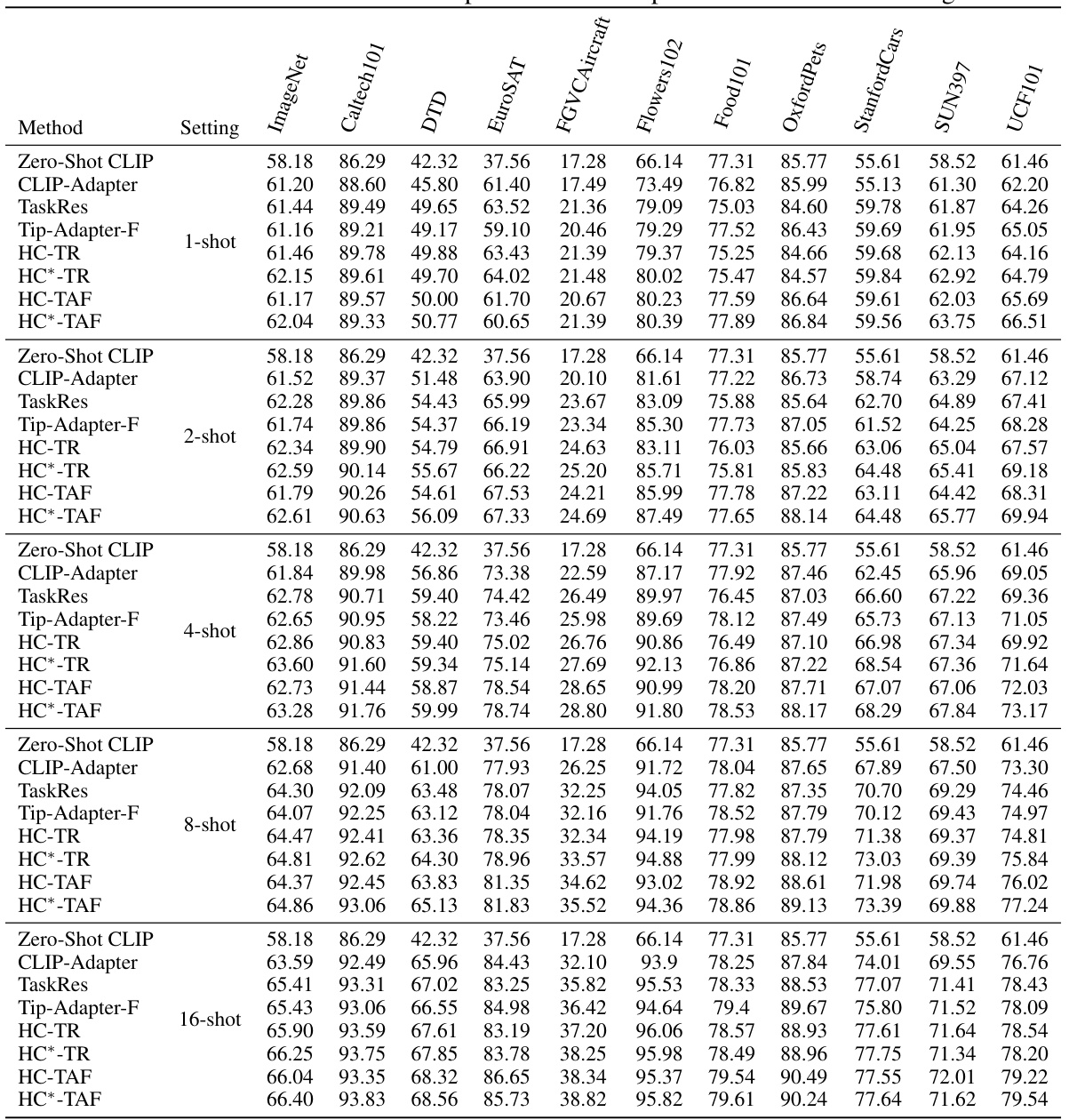
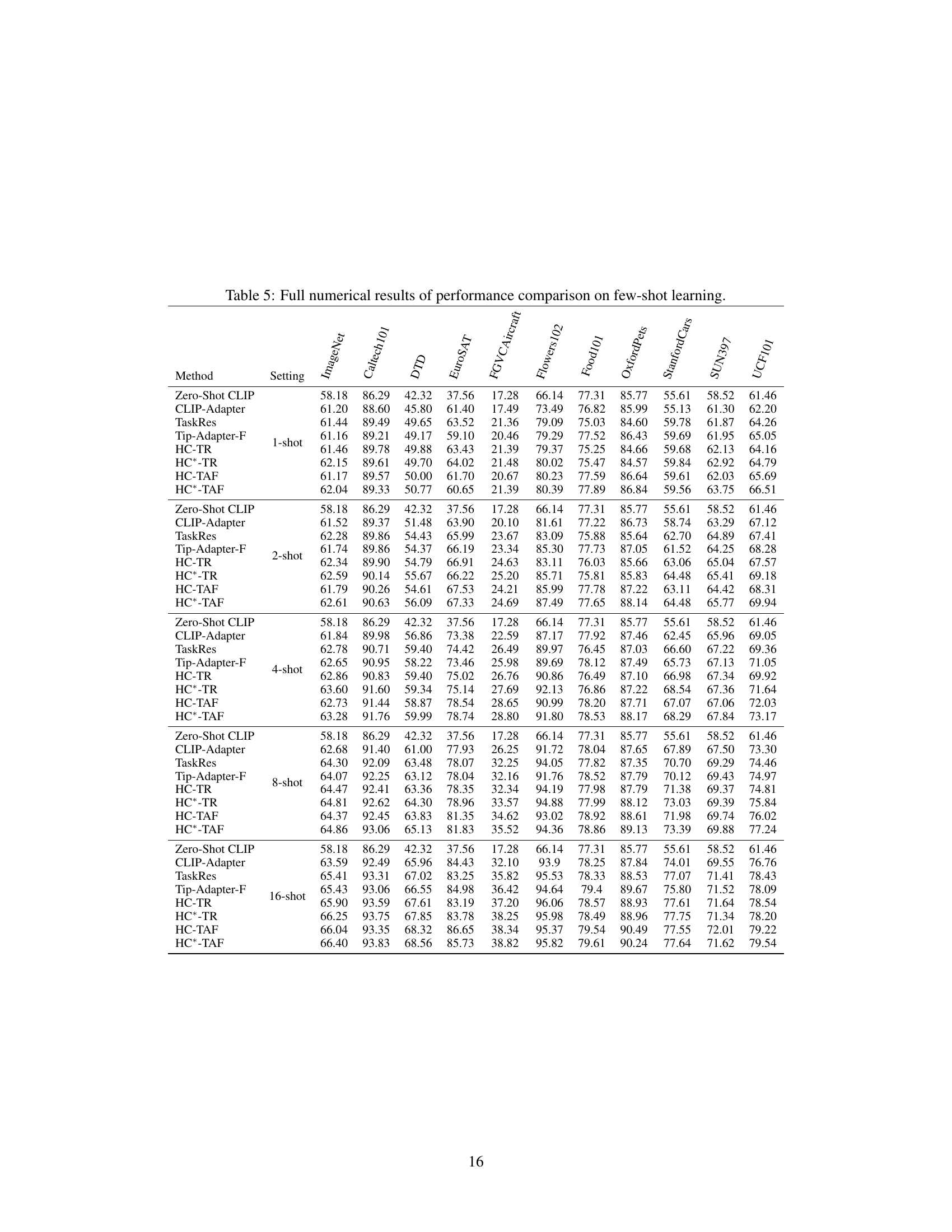
This table presents the complete numerical results of the few-shot learning experiments conducted in the paper. It provides a detailed breakdown of the performance of various methods (Zero-Shot CLIP, CLIP-Adapter, TaskRes, Tip-Adapter-F, HC-TR, HC*-TR, HC-TAF, HC*-TAF) across 11 benchmark datasets (ImageNet, Caltech101, DTD, EuroSAT, FGVCAircraft, Flowers102, Food101, OxfordPets, StanfordCars, SUN397, UCF101) under different shot settings (1-shot, 2-shot, 4-shot, 8-shot, 16-shot). This allows for a comprehensive comparison of the proposed Homology Consistency (HC) method against baseline approaches.
Full paper#