↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Monocular depth estimation faces the challenge of scale ambiguity, where the depth map’s scale is unknown, leading to relative depth outputs instead of precise metric depth measurements. Existing methods often struggle with generalization across diverse datasets due to dataset-specific biases. This limits practical utility in downstream applications requiring accurate spatial information.
This paper introduces RSA, a method that leverages language descriptions of scenes to transform relative depth maps into metric depth. RSA takes as input a text caption describing the objects present in an image and outputs parameters for a linear transformation applied to the relative depth map. Evaluated on several datasets (NYUv2, KITTI, VOID), RSA shows improved accuracy and generalization, even outperforming common practices like linear fitting. This method holds significant promise for advancing monocular depth estimation in a variety of applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and robotics. It addresses a fundamental challenge in monocular depth estimation—scale ambiguity—by introducing a novel method for recovering metric-scaled depth maps using language descriptions. This offers a significant advancement in 3D scene understanding and opens new avenues for research in zero-shot transfer, and applications demanding precise depth information like autonomous driving and robotics.
Visual Insights#
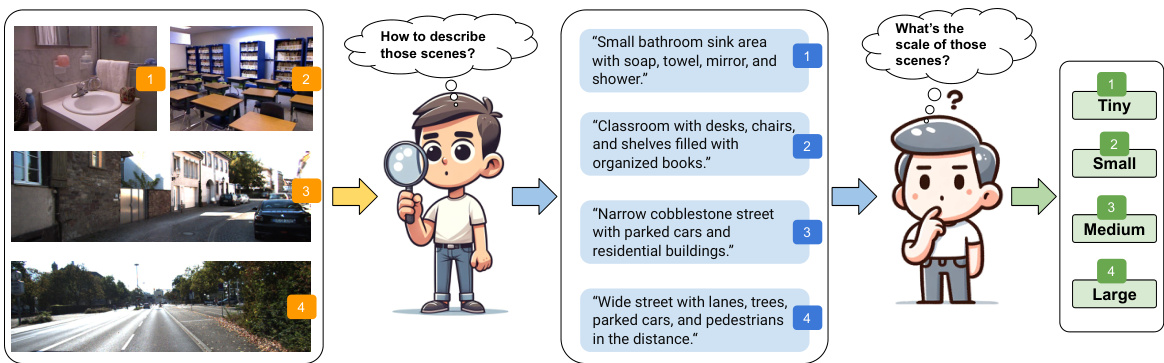
This figure illustrates the core idea of the paper: using textual descriptions of a scene to infer the scale. Four example images are shown, each with a corresponding textual description and a label indicating the scale (Tiny, Small, Medium, Large). The figure visually demonstrates the relationship between the objects present in a scene, their typical sizes, and the overall scale.

This table presents a quantitative comparison of different methods for monocular depth estimation on the NYUv2 dataset. It compares various scaling techniques (using images, a global scale and shift, median scaling, and linear fitting to ground truth) against the proposed RSA method. The results are evaluated using several metrics (δ < 1.25, δ < 1.25², δ < 1.25³, Abs Rel, log10 RMSE). The table highlights the improved generalization capabilities of RSA, particularly when trained on multiple datasets, compared to image-based scaling methods.
In-depth insights#
Scale Ambiguity#
Scale ambiguity in monocular depth estimation is a fundamental challenge stemming from the loss of depth information during image projection. Methods that address this often rely on training data, leading to biases and limiting generalization to unseen environments. This inherent ill-posedness necessitates strategies to recover metric scale. The paper explores using language descriptions as a crucial supplementary modality to resolve this ambiguity. This approach leverages the fact that certain objects are strongly associated with specific scene scales; therefore, a caption can provide information not directly available in the image itself. By incorporating textual information, the method proposes to align relative depth maps to metric scales, enhancing accuracy and generalizability. The innovative use of language addresses limitations of existing approaches that rely on dataset-specific biases, potentially improving cross-domain and zero-shot performance. The core idea is to learn a linear transformation between relative and metric depth based on textual context, thus effectively using language as a powerful scale prior.
Language-Based Scale#
The concept of ‘Language-Based Scale’ in the context of monocular depth estimation is quite novel. It leverages the inherent relationship between object sizes mentioned in a text description and their real-world scales to resolve the scale ambiguity problem inherent in monocular depth estimation. This approach cleverly uses language as an additional modality, bridging the gap between the visual input and the metric depth output. The method’s effectiveness is dependent on the accuracy and detail of language descriptions, and the ability of the model to correctly interpret the textual information and relate it to the depth map. A key advantage is its potential for generalization across diverse datasets and environments, as language descriptions are less susceptible to environmental changes like illumination and viewpoint variations, compared to using visual cues alone. However, challenges remain in handling ambiguous descriptions or those that lack sufficient detail, which could lead to inaccurate scale estimation. Robustness of the language model is critical, as the accuracy of depth scaling depends directly on how well the textual information is parsed and translated into scaling factors.
RSA Model#
The RSA model, designed for metric-scale monocular depth estimation, cleverly leverages language descriptions to resolve the inherent scale ambiguity in single-image depth prediction. Instead of relying solely on image features, RSA incorporates textual information, enriching the model’s understanding of the scene’s context. This integration allows RSA to learn a transformation that maps relative depth to metric depth, effectively bridging the gap between the ill-posed nature of monocular depth estimation and the need for precise metric measurements. The model’s architecture is modular and flexible, enabling the use of various pre-trained monocular depth models and text encoders. The utilization of a linear transformation, parameterized by the language description, offers efficiency and simplicity. Furthermore, training on multiple datasets demonstrates RSA’s robustness and generalizability. The combination of image and textual input provides a unique and powerful approach that overcomes a fundamental limitation of traditional monocular depth estimators.
Zero-Shot Transfer#
The concept of ‘Zero-Shot Transfer’ in the context of monocular depth estimation is fascinating. It explores the possibility of a model trained on specific datasets to generalize to unseen datasets without any additional training. This is a significant leap towards building more robust and versatile depth estimation systems. The paper leverages language descriptions as a crucial bridge for achieving this zero-shot capability. The idea is that scene descriptions provide valuable context about scale and object types, which are usually missing in single-image depth estimation. By incorporating this linguistic information, the model can infer metric scale and apply a learned transformation to relative depth maps, enabling accurate depth estimation in novel environments. The success of this approach relies on the ability of the language model to effectively capture scene characteristics and translate them into parameters for the depth transformation. This method also offers potential advantages in terms of efficient data acquisition and resource usage, as it reduces the need for extensive labeled data for every new domain. However, challenges remain, including the inherent ambiguity of natural language and the potential impact of linguistic variation on model performance. A key future research direction would be to further improve the robustness and accuracy of zero-shot transfer by addressing these limitations.
Future Work#
The authors propose several avenues for future research. Improving depth estimation accuracy is paramount, as inaccuracies in the input relative depth map directly impact the final metric depth. This might involve exploring more sophisticated methods for refining relative depth predictions or incorporating additional modalities beyond language to further constrain depth estimation. Expanding the scope of language integration is crucial. The current approach uses global, text-based scale adjustment; refining this to handle region-specific or even pixel-wise scale variations would greatly enhance accuracy and application versatility. Addressing robustness to noisy or misleading text captions is also important. The current work relies on accurate text descriptions, but a more robust system should be able to handle errors or ambiguities in the input language. Finally, the authors acknowledge the potential for misuse of the technology and suggest developing safeguards and mitigating strategies to prevent harmful applications.
More visual insights#
More on figures
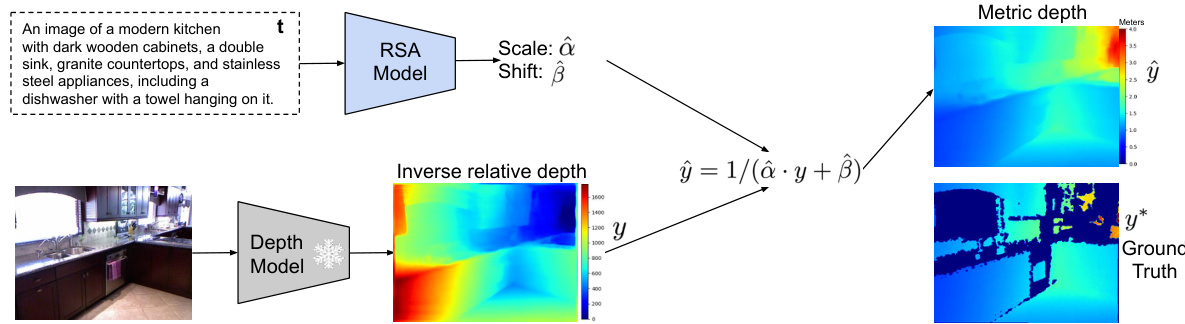
This figure illustrates the overall process of the RSA method. It starts with an input image and its corresponding textual description. The textual description is fed into the RSA model, which then outputs scale and shift parameters. These parameters, along with the inverse relative depth obtained from a pre-trained depth model processing the image, are used to compute the final metric depth prediction, which is then compared to the ground truth metric depth map for evaluation.
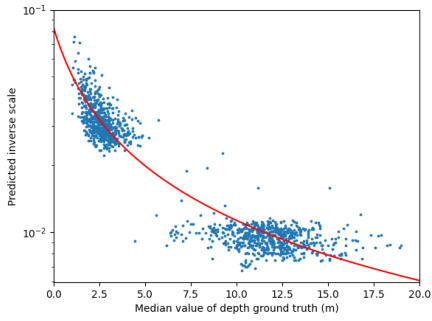
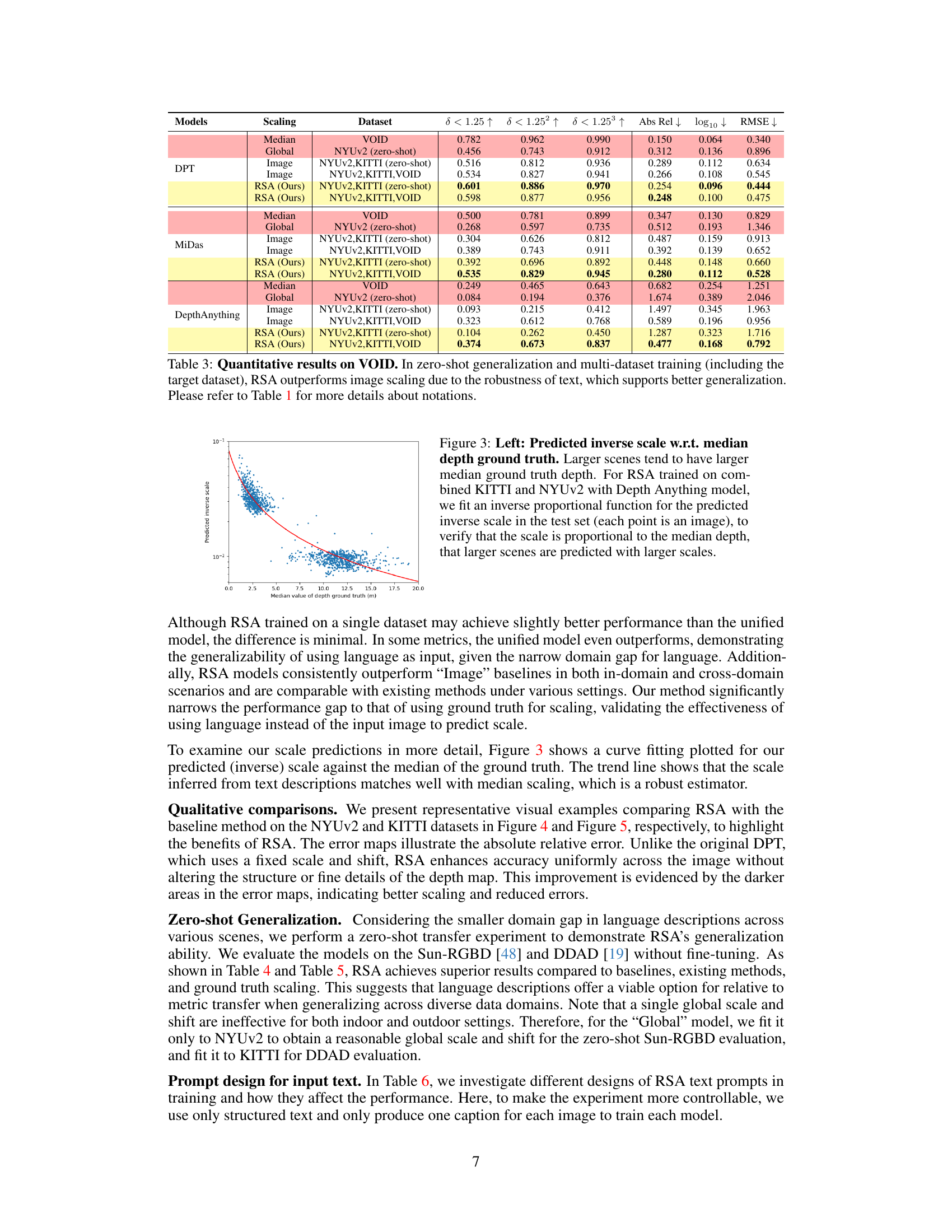
This figure shows a scatter plot and a fitted curve. The scatter plot shows the relationship between the predicted inverse scale (y-axis) and the median value of depth ground truth (x-axis) for images in a test set. The fitted curve, an inverse proportional function, demonstrates that the predicted inverse scale is inversely proportional to the median ground truth depth. This confirms the model’s ability to predict larger scales for larger scenes.

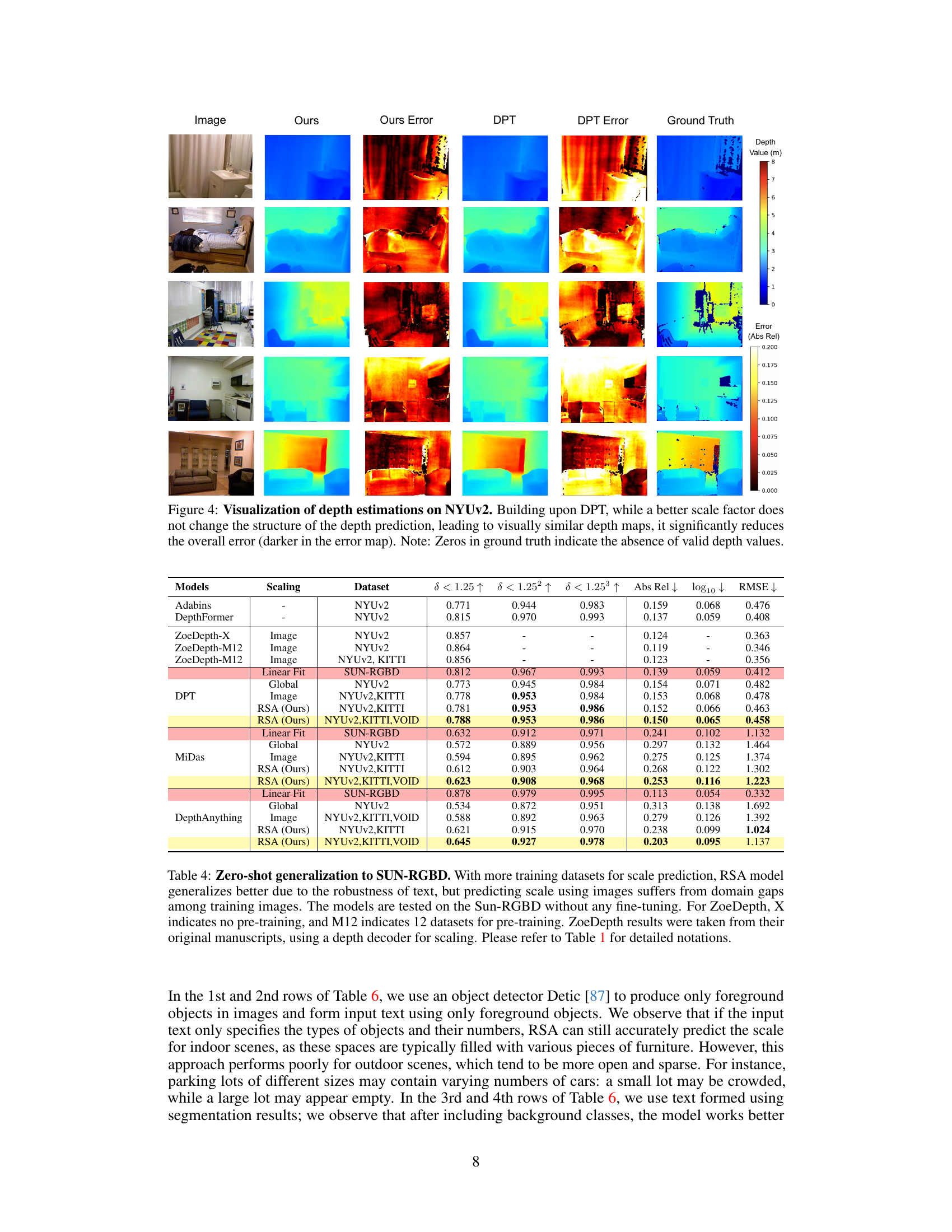
This figure compares the depth estimation results of the proposed RSA method with the baseline DPT method on the NYUv2 dataset. For each image, it shows the original image, the depth map generated by RSA, the error map for RSA (showing the absolute relative error), the depth map generated by DPT, the error map for DPT, and finally, the ground truth depth map. The visualization demonstrates that while RSA and DPT produce visually similar depth maps, RSA significantly reduces the overall error compared to DPT. Darker colors in the error maps represent lower error values.

This figure compares depth estimation results from the proposed RSA method and the baseline DPT method on the KITTI dataset. The figure shows three example image pairs, their corresponding depth maps produced by RSA and DPT, and their absolute relative error maps. The goal is to visually demonstrate how RSA, with its learned scale adjustment, improves upon DPT’s depth estimations, particularly for scenes with large depth variations. Darker regions in the error maps indicate lower error. Zeros in the ground truth denote missing depth information.
More on tables
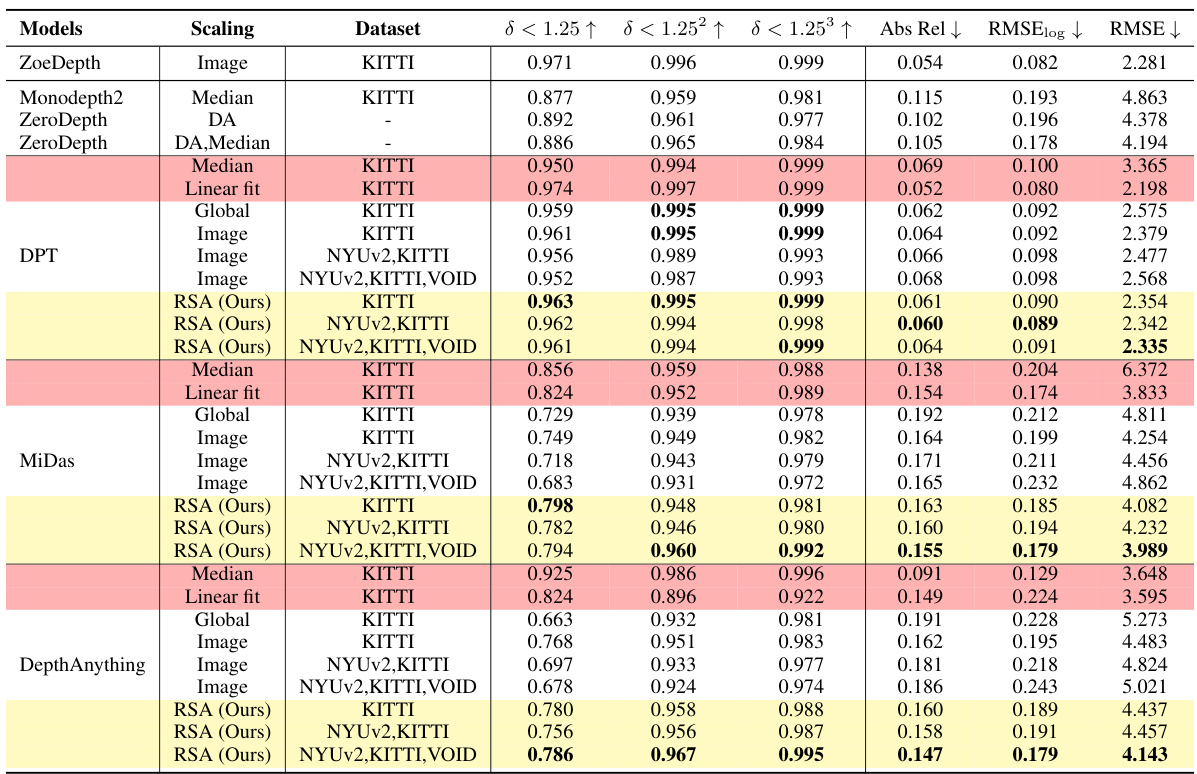
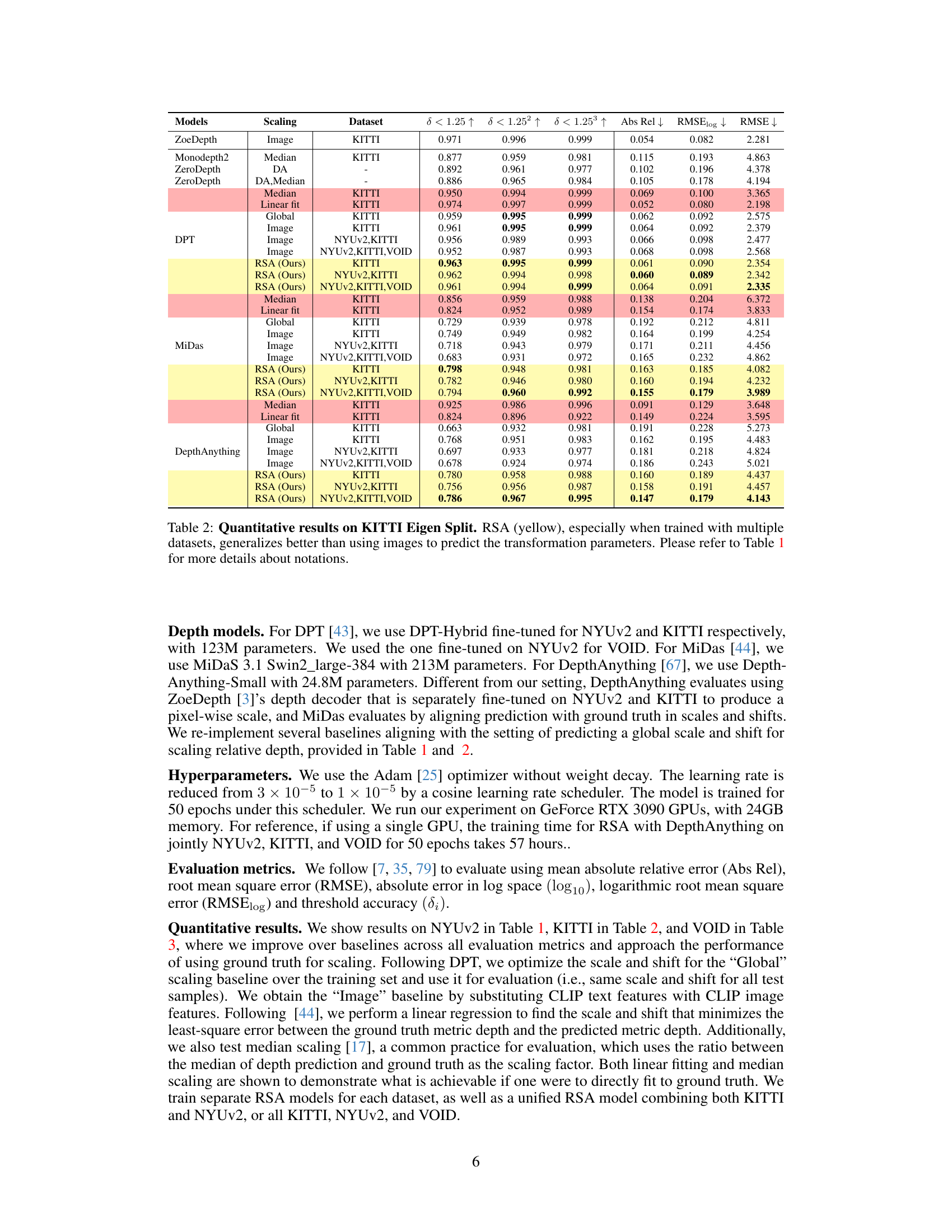
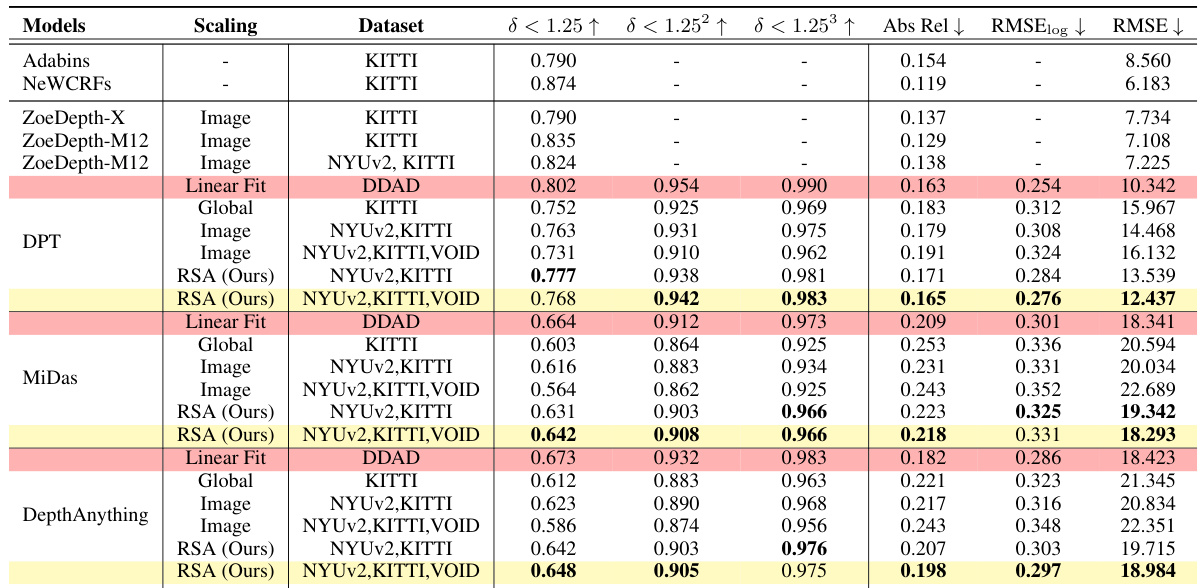
This table presents a quantitative comparison of different monocular depth estimation models on the KITTI Eigen Split dataset. The models are evaluated using several metrics (δ < 1.25, δ < 1.25², δ < 1.25³, Abs Rel, RMSElog, RMSE), comparing different scaling methods (Image, Median, Linear fit, Global, RSA). The results show that the RSA method, especially when trained on multiple datasets (NYUv2, KITTI, VOID), achieves better generalization compared to using images alone to predict scale and shift parameters. The table also provides a baseline comparison using median scaling and linear fitting.
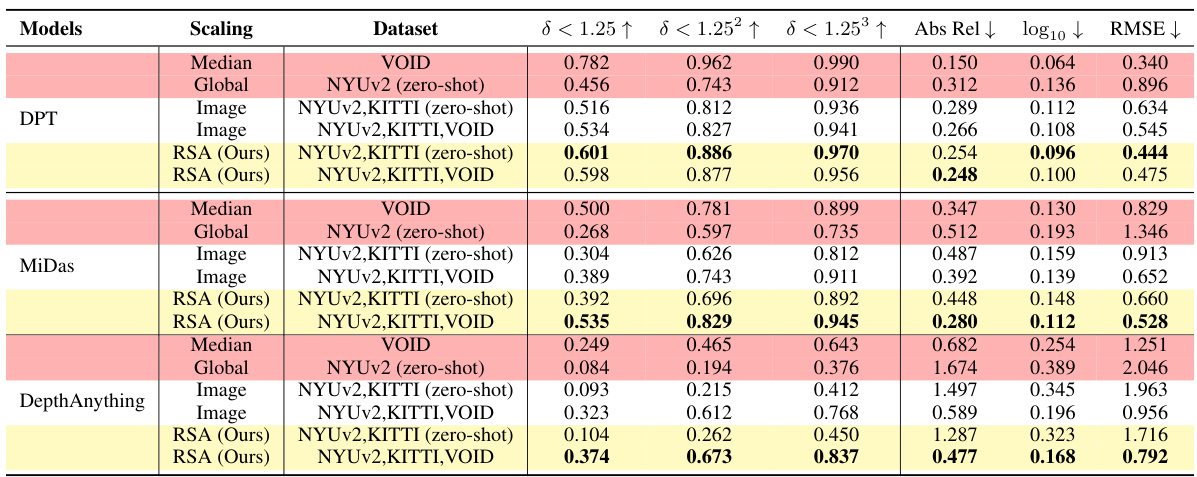
This table presents a quantitative comparison of different methods for depth estimation on the VOID dataset, focusing on zero-shot generalization capabilities. It compares RSA (the proposed method) against several baselines, including image-based scaling, median scaling, and a global scaling approach. The results are evaluated using several metrics (δ<1.25, δ<1.25², δ<1.25³, Abs Rel, log10 RMSE). The table demonstrates RSA’s superior performance, particularly when trained on multiple datasets, highlighting the robustness of language descriptions in achieving better zero-shot generalization than image-based methods.
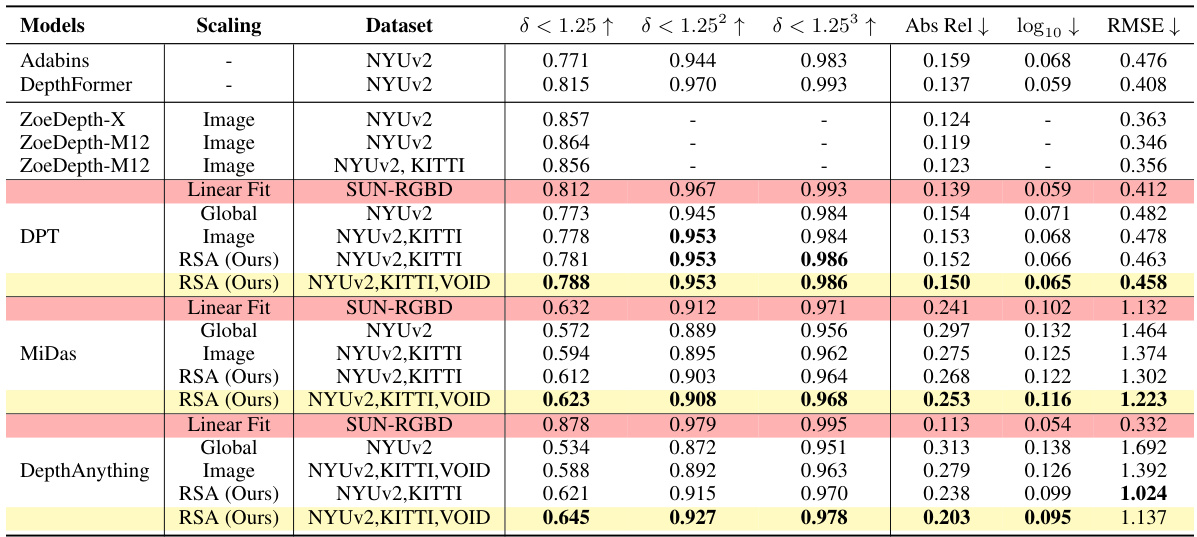
This table presents a quantitative comparison of different monocular depth estimation methods on the NYUv2 dataset. It evaluates the performance of various methods in terms of their ability to accurately predict metric depth from a single image. The methods compared include several baselines (Global, Image, Median, Linear Fit, and ZoeDepth) and the proposed RSA method. The table shows the results for three different metrics (δ < 1.25, δ < 1.25², δ < 1.25³), along with Absolute Relative error (Abs Rel), log10 RMSE, and RMSE. The results demonstrate RSA’s superior performance, particularly when trained on multiple datasets, highlighting its ability to generalize across different scenarios.
This table presents a quantitative comparison of different methods for monocular depth estimation on the NYUv2 dataset. The methods are evaluated using various metrics (δ<1.25, δ<1.25², δ<1.25³, Abs Rel, log10 RMSE), comparing the performance of RSA (the proposed method) against several baselines, including methods that use images or ground truth for scaling. The results show that RSA, especially when trained with multiple datasets, achieves better generalization and comparable performance to the upper bound of fitting relative depth to ground truth.
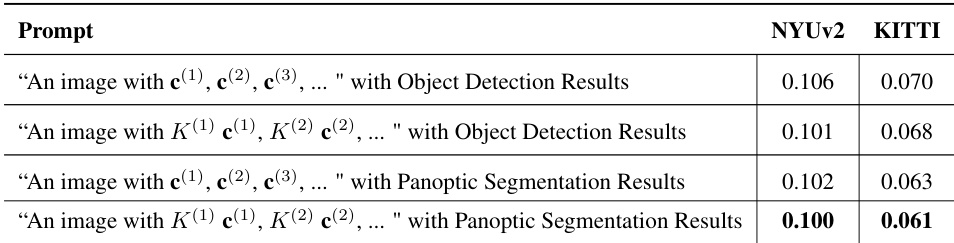
This table shows the impact of different prompt designs on the performance of the RSA model when trained across multiple datasets using the DPT model. Four different prompt types are evaluated: using object detection results with and without instance counts, and using panoptic segmentation results with and without instance counts. The results indicate that incorporating background information via panoptic segmentation generally leads to better performance, especially in outdoor scenes.

This table presents a quantitative comparison of different methods for monocular depth estimation on the NYUv2 dataset. It evaluates various techniques, including RSA (the proposed method), using metrics such as δ<1.25, Abs Rel, log10 RMSE. The table highlights RSA’s superior generalization capabilities when trained on multiple datasets compared to image-based methods and other baselines. Different scaling approaches (global, image, median, linear fit) are also compared, showing the effectiveness of RSA’s approach.
Full paper#