↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs) are powerful image encoders, but understanding their internal mechanisms remains challenging. Existing methods struggle to interpret ViT components beyond CLIP models due to diverse attention mechanisms and varied architectural designs, hindering detailed model analysis and optimization. This limitation restricts the potential for applications like image retrieval using text and visualizing token importance.
This research introduces a general framework to address these challenges. It leverages automated decomposition of ViT representations and mapping of component contributions to CLIP space for textual interpretation. A novel scoring function ranks components’ importance relative to specific image features. The framework successfully interprets various ViT variants (DeiT, DINO, DINOv2, Swin, MaxViT), revealing insights into component roles for image features and enabling applications such as text-based image retrieval, visualization of token importance heatmaps, and mitigation of spurious correlations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and machine learning as it provides a novel framework for interpreting complex vision transformer models. Its general approach to decomposing and interpreting representations is broadly applicable, advancing mechanistic interpretability in the field and opening new avenues for model analysis and improvement. The work’s focus on understanding model components and mitigating spurious correlations is particularly timely, directly impacting ongoing research efforts.
Visual Insights#
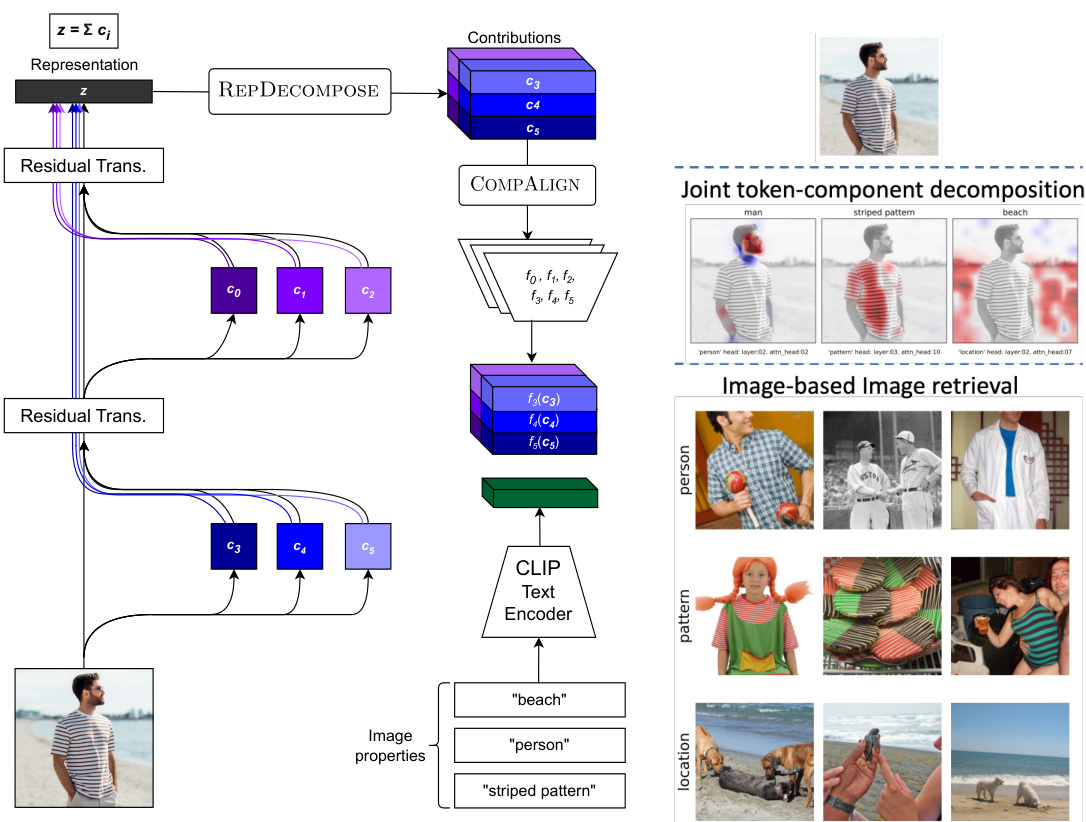
The figure illustrates the workflow of the proposed framework. It consists of two main steps: REPDECOMPOSE and COMPALIGN. REPDECOMPOSE decomposes the final representation into contributions from different model components. COMPALIGN aligns these contributions to CLIP space for interpretation via text. The right side of the figure shows two applications of the framework: visualizing token contributions and image retrieval.
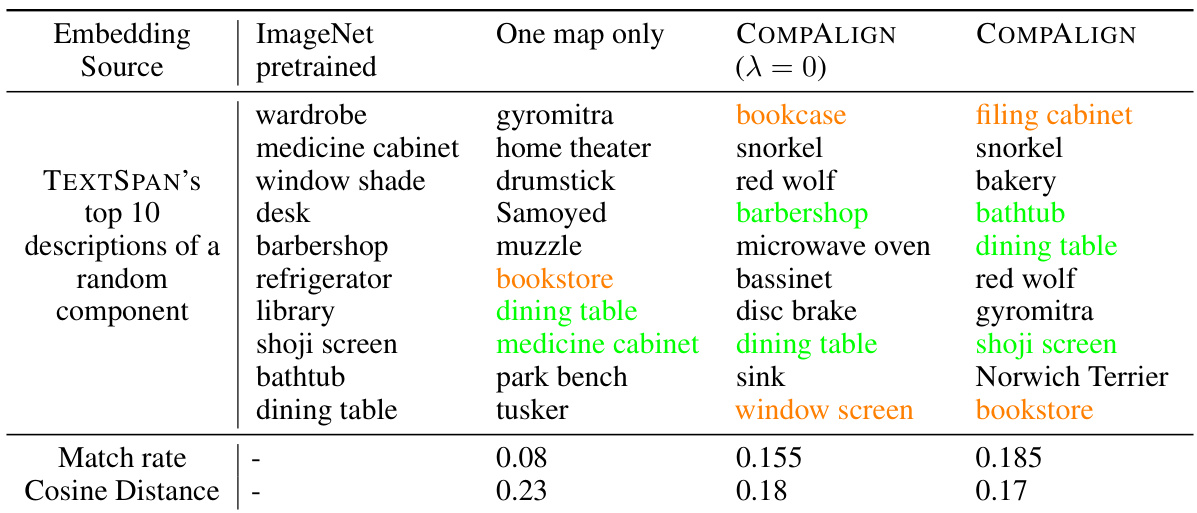
This table compares three different methods for aligning the representation space of a pre-trained DeiT-B/16 model with CLIP’s image representation space. The methods are: using only one linear map, COMPALIGN without orthogonality regularization (λ = 0), and COMPALIGN with orthogonality regularization. The table shows the top 10 descriptions generated by each method for a random component, highlighting exact matches (green) and approximate matches (orange) against ImageNet’s pre-trained embeddings. Finally, it reports the average match rate and cosine distance for each method, demonstrating the improved performance of COMPALIGN with orthogonality regularization.
In-depth insights#
ViT Component Roles#
The heading ‘ViT Component Roles’ suggests an investigation into how different components within Vision Transformers (ViTs) contribute to the overall image representation. A comprehensive analysis would likely explore the roles of attention mechanisms, MLP layers, and other architectural elements. The study might dissect individual attention heads, uncovering which features (like shape, texture, or color) each head specializes in. MLP layers could be examined for their function in transforming feature representations. The analysis should address whether components exhibit specialized or overlapping functionalities and whether the interactions between components contribute synergistically to the final representation. Furthermore, the work might assess how component roles vary across different ViT architectures (e.g., DeiT, Swin Transformer), and across pre-training methodologies. Ultimately, understanding ‘ViT Component Roles’ is crucial for improving the interpretability, efficiency, and design of ViTs. Identifying redundant or less-important components could lead to model compression while maintaining performance. The study might also reveal potential biases or spurious correlations embedded within the model’s architecture, enabling researchers to develop mitigation techniques.
CLIP Space Mapping#
The concept of “CLIP Space Mapping” in the context of vision transformer (ViT) interpretation involves aligning the internal representations of a ViT model with the shared image-text embedding space of CLIP. This alignment is crucial because CLIP provides a readily interpretable textual framework for understanding image features. The core idea is to leverage CLIP’s ability to translate image vectors into human-readable text descriptions. This mapping isn’t a straightforward process, as ViTs and CLIP have distinct architectural designs and training objectives. Therefore, techniques such as linear transformations or neural networks are employed to bridge the semantic gap. Successful mapping allows researchers to analyze individual components of a ViT (like attention heads or MLP layers) by projecting their activations into CLIP space and subsequently interpreting them through text. This approach facilitates a deeper understanding of feature encoding within ViTs, revealing which components are responsible for capturing specific visual attributes. Challenges include finding effective mapping functions that preserve the original semantic meaning of the ViT activations and mitigating spurious correlations. The success of CLIP Space Mapping hinges on the quality of the mapping function and the extent to which it successfully transfers meaningful information from the ViT to the CLIP space, providing valuable insights into the complex internal workings of vision transformers.
Feature Scoring#
The concept of ‘Feature Scoring’ in the context of a vision transformer model is crucial for interpretability. It involves quantifying the relevance of individual model components to specific image features. Instead of simply assigning fixed roles to components, this approach uses a continuous scoring mechanism to reflect the nuanced relationship between various model parts and image attributes. This is important because a single component might contribute to multiple features, and vice-versa. A higher score indicates stronger relevance, allowing for a ranked ordering of components based on their contribution to a given feature and facilitating tasks like feature visualization and component selection for specific applications such as image retrieval. This dynamic scoring approach addresses the limitations of simpler methods that assume rigid component-feature mappings, offering a more accurate and comprehensive understanding of the model’s internal workings. The effectiveness of the scoring function is evaluated, possibly by comparing its rankings to a ground truth obtained through manual annotation or other methods like text prompting with CLIP. This rigorous evaluation helps to establish the reliability and validity of the feature scoring method.
Ablation Study#
An ablation study systematically removes or deactivates model components to assess their individual contributions. In the context of vision transformers, this might involve progressively removing layers, attention heads, or MLP blocks. The goal is to understand the impact of each component on the model’s overall performance, often measured by metrics such as ImageNet accuracy or a downstream task’s performance. A well-designed ablation study helps to isolate the effects of specific architectural choices, revealing which components are crucial for achieving good results and which are less critical or even detrimental. The results can inform model simplification, improved efficiency, and a deeper understanding of how different model parts interact to achieve a task. Careful interpretation of ablation results is crucial, however, as the removal of one component may indirectly affect others, leading to complex interactions that can be hard to disentangle. Therefore, the study design must consider possible dependencies between components and employ appropriate experimental controls and metrics to minimize confounding effects. Furthermore, ablation studies can highlight the presence of redundancy in the model, where multiple components contribute similarly to the overall outcome, potentially offering opportunities for optimization. Ablation studies are a valuable tool in the interpretability of models as they highlight the critical components for specific tasks, enabling informed modifications and improving performance.
Future Works#
The paper’s core contribution is a novel framework for decomposing and interpreting image representations in Vision Transformers (ViTs), going beyond the limitations of previous CLIP-based methods. Future work could significantly expand this framework’s capabilities. This includes extending the automated decomposition algorithm to handle more complex architectures, including those with convolutional layers or non-standard attention mechanisms. Addressing higher-order interactions between components is crucial to obtain a more comprehensive understanding of the feature encoding process. The scoring function, while effective, could be enhanced by incorporating more sophisticated methods to address the nuanced relationships between features and components. Expanding the scope to other modalities, such as video or 3D data, would unlock new avenues of investigation and significantly increase the framework’s versatility. Finally, exploring applications beyond image retrieval is important. The framework’s potential for tasks like visual explanation generation, spurious correlation mitigation, and improving model robustness should be thoroughly investigated. By focusing on these areas, the framework’s potential impact can be significantly broadened.
More visual insights#
More on figures

This figure illustrates the workflow of the proposed framework. The left panel shows the two main steps: decomposing the representation into contributions from different components (REPDECOMPOSE) and aligning these contributions to CLIP space for textual interpretation (COMPALIGN). The right panel demonstrates three applications of the framework: visualizing token contributions, image retrieval based on image features, and image retrieval based on text descriptions.
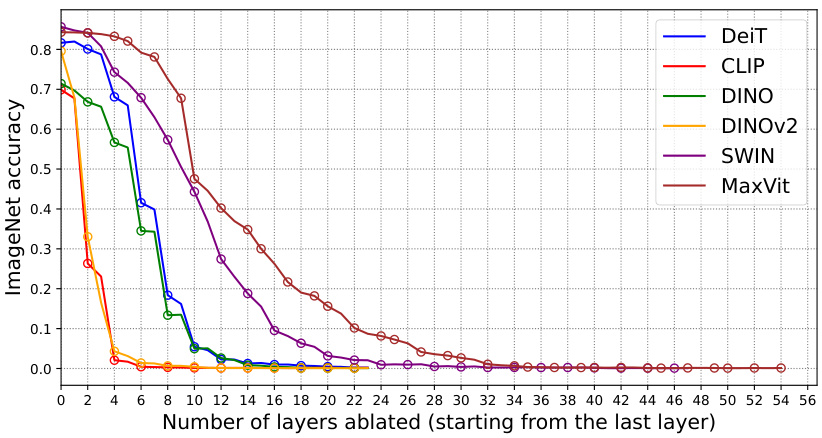
This ablation study shows the impact of removing layers from different vision transformer models on ImageNet classification accuracy. The accuracy is plotted as layers are progressively removed, starting from the last layer. The plot shows how many layers are required to significantly reduce the performance of each model. The different models (DeiT, CLIP, DINO, DINOv2, Swin, MaxVit) show different levels of robustness to layer removal, reflecting architectural differences.

This figure shows the top 3 images retrieved by DeiT components for the features ‘forest’ and ‘beach’. Each column represents images returned by a set of three components, ordered according to their relevance scores for the attribute ’location’. The images demonstrate how the model effectively utilizes component contributions to correctly identify location features in images.

This figure shows the top 3 images retrieved by DeiT components for the location features ‘forest’ and ‘beach’. The images are ordered by the component’s relevance score for the location attribute. Each column represents the combined contribution of three components. The figure demonstrates that the scoring function effectively ranks components by their importance in identifying location features.
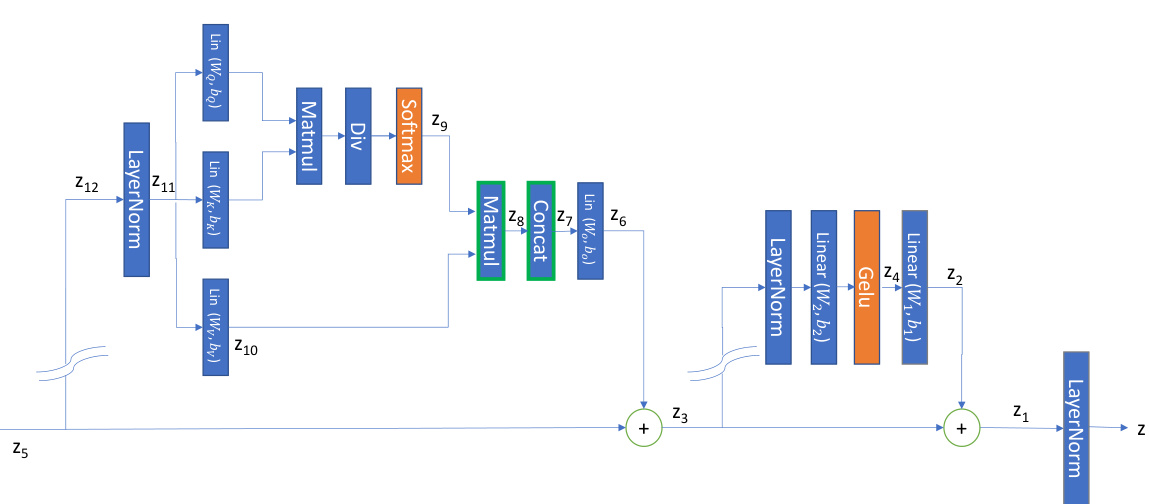
This figure illustrates a simple attention-MLP block in a vanilla Vision Transformer. It shows the flow of tensors (z1, z2,…z12), the linear (blue) and non-linear (orange) operations in the block and the nodes where tensors are reduced along specific dimensions. This visualization helps to understand the step-wise operation of the REPDECOMPOSE algorithm described in the paper, which decomposes a representation into contributions from different model components.

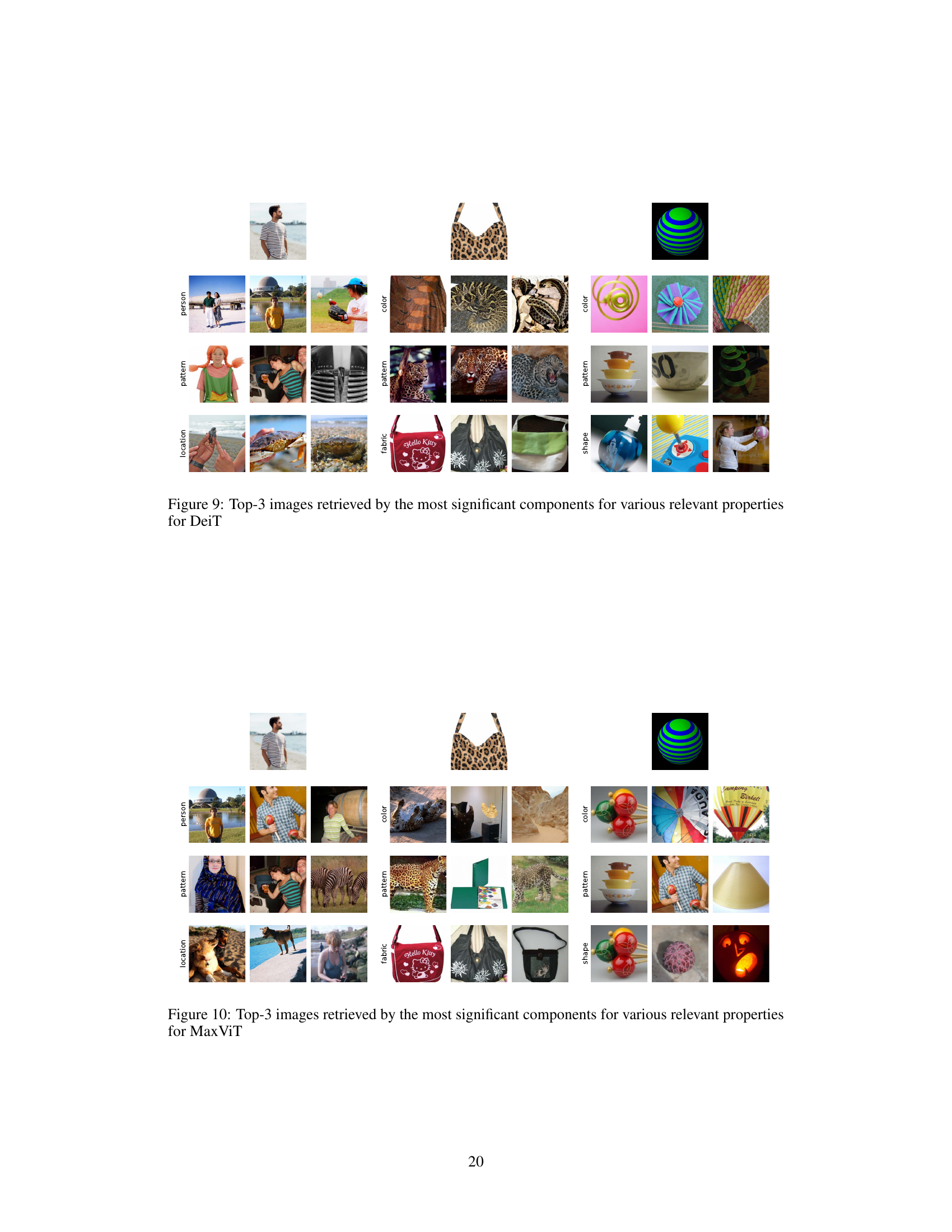
This figure shows the top 3 images retrieved by the most significant components of DINO, DeiT, and Swin models for different features. Each column represents images retrieved for a specific feature (location, pattern, person, fabric, color, shape), and the rows represent the top 3 components. The reference image, on the top, is used as a basis for selecting the components and features. The selection of components is performed by using a scoring function described in the paper to determine which components are most responsive to each feature. The appendix H contains more detailed results.

This figure shows the top 3 images retrieved by the most significant components for different features. The reference image is displayed at the top. The models used are DINO, DeiT, and Swin, and more results are available in Appendix H. The figure demonstrates the ability of the method to retrieve images sharing specific features with the reference image, highlighting the model’s ability to isolate and utilize feature-specific components.

This figure shows the top 3 images retrieved by the most significant components for various features relevant to the reference image for three different vision transformer models: DINO, DeiT, and SWIN. Each column represents images retrieved using a combination of components identified as most relevant to a specific feature (like ’location’, ‘pattern’, etc.) based on the proposed scoring function. The images are ordered by the relevance score, showcasing the models’ ability to retrieve images that visually match the specific characteristics of the reference image.

This figure shows the top 3 images retrieved by the most significant components for various features relevant to the reference image. The reference images are displayed at the top of each column. The models used are DINO, DeiT, and SWIN, each represented by a column. This demonstrates the image-based image retrieval capability of the proposed method, highlighting how different models identify and retrieve images with similar features.
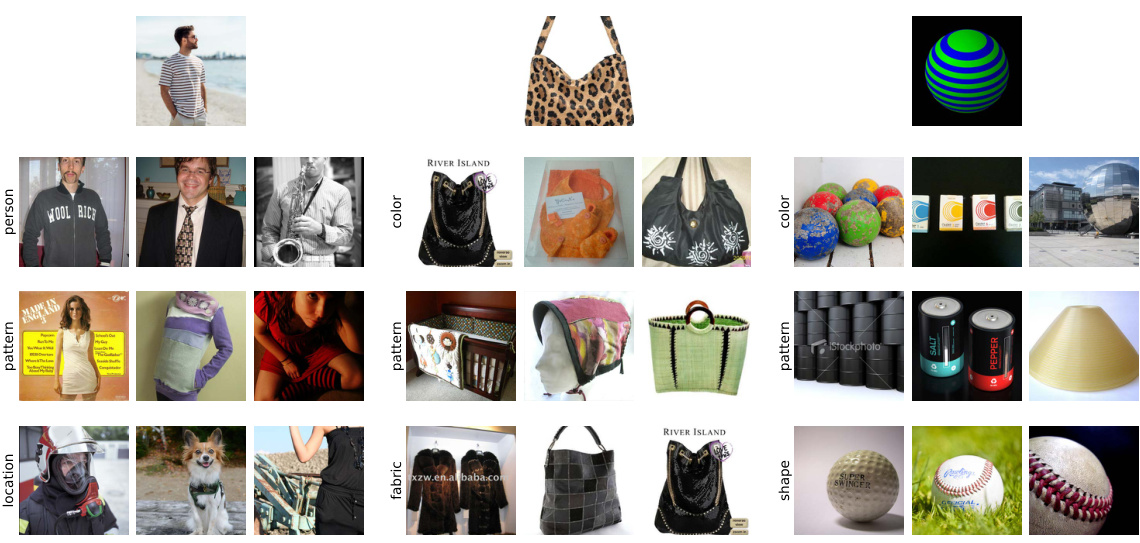
This figure visualizes the results of image-based image retrieval using the proposed framework. For each of three different vision transformer models (DINO, DeiT, and Swin), it shows the top three images retrieved for several different features from a given reference image. The selection of components was based on a scoring function that identifies the components most relevant to each feature. The figure aims to demonstrate the effectiveness of the framework in identifying components capable of retrieving images with specific features.

This figure shows top 3 images retrieved by the most significant components for different image features. The reference image is displayed at the top of each column, and the three columns show results for DINO, DeiT, and Swin Transformer models respectively. Each column shows images that have common features with the reference image. For instance, the first column contains images that feature a person on the beach, similar to the reference image.

The figure visualizes token contributions for CLIP model using heatmaps. Two example images are shown with their corresponding heatmaps for different features. Each heatmap highlights the tokens (parts of the image) that are most relevant to a specific feature like ‘animal’, ’location’, ‘shape’, ‘person’, ‘pattern’, etc. Red indicates positive contribution, blue indicates negative contribution. The layer and attention head contributing the most are also specified.

This figure visualizes the token contributions for the DINO model. It shows heatmaps highlighting the positive (red) and negative (blue) contributions of individual tokens for various features. Two example images are used: one of a camel near pyramids, and the other a man in a striped shirt on a beach. Each image’s heatmaps are displayed alongside the specific feature being highlighted and the attention head/layer responsible. This visualization helps demonstrate how specific tokens within the model contribute to the recognition of certain image features.

The figure visualizes token contributions as heatmaps for two example images using the Swin Transformer model. The heatmaps highlight which image tokens contribute positively (red) or negatively (blue) to the prediction of specific features (e.g., ‘animal,’ ’location,’ ‘shape’). Each heatmap shows the contributions from specific attention heads within different layers, indicating which parts of the image are most important for identifying each feature. The figure helps to understand the model’s internal mechanisms by visualizing how individual components contribute to feature recognition.
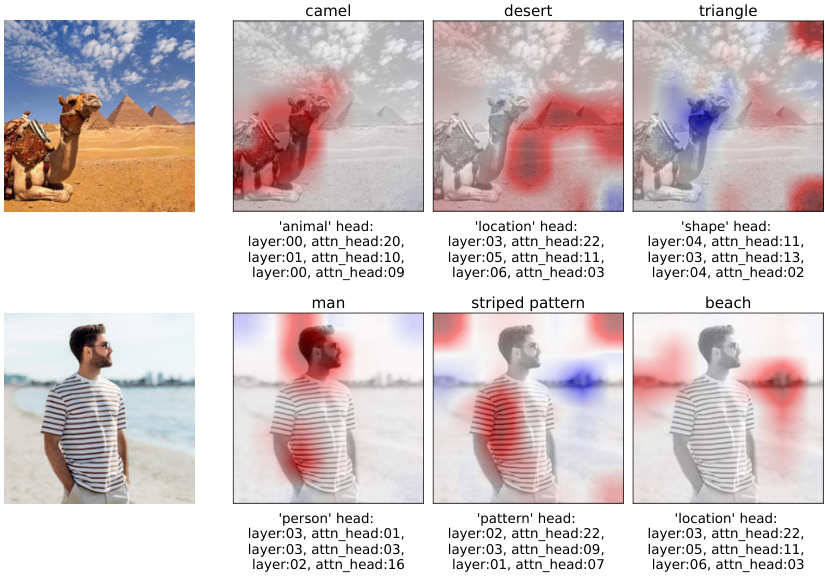
This figure visualizes the token contributions as heatmaps for two example images using the MaxVit model. The heatmaps show which tokens contribute positively (red) or negatively (blue) to the prediction of specific features (e.g., ‘animal’, ’location’, ‘shape’, ‘person’, ‘pattern’). Each heatmap is accompanied by the model components identified as most relevant for that specific feature. The layer and attention head are also displayed for each contribution.
More on tables
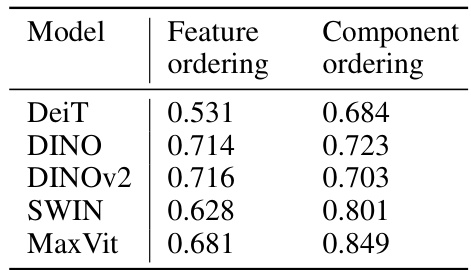
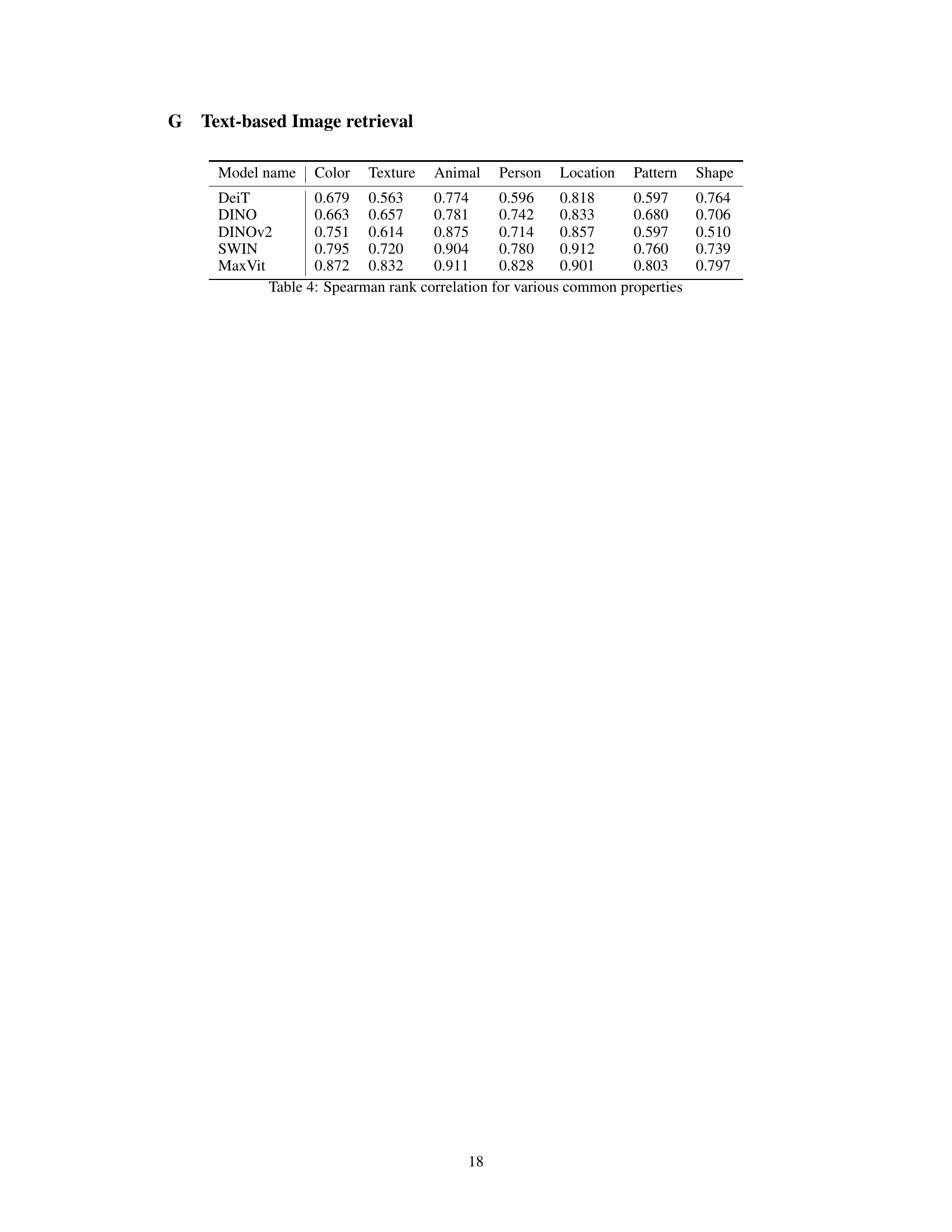
This table presents the Spearman’s rank correlation coefficients, which measure the strength and direction of monotonic association between two ranked variables. In this case, it compares the ranking of components based on a CLIP-derived score (measuring how well they align with CLIP’s image representation space) and a component score based on the importance of a component towards a particular image feature. The average correlation is calculated across various common features (like color, texture, animal, etc.) to gauge the overall consistency between the two ranking methods. Higher values (closer to 1.0) indicate strong agreement between the rankings, suggesting that the proposed scoring function effectively identifies component relevance to image features.
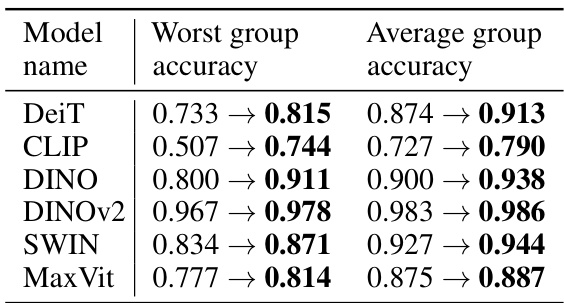
This table presents the results of an ablation study on the Waterbirds dataset. The study aimed to mitigate spurious correlations by removing components identified as relevant to the dataset’s spurious correlation. The table shows the worst-group accuracy and average group accuracy for six different vision transformer models (DeiT, CLIP, DINO, DINOv2, Swin, MaxVit) before and after the ablation of specific components. The improvement in accuracy after ablation demonstrates the effectiveness of the proposed method in reducing spurious correlations and improving the model’s robustness.
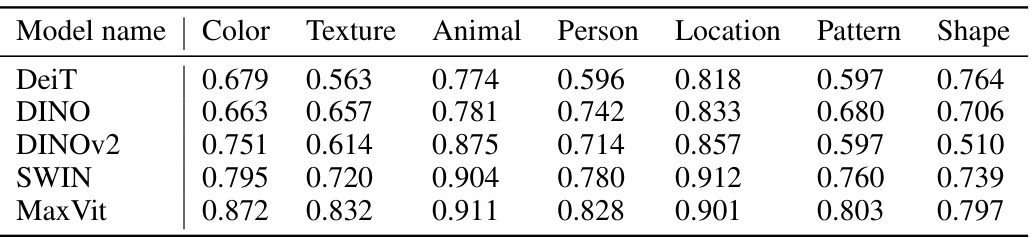
This table presents the Spearman’s rank correlation values between the orderings induced by the CLIP score and the component score for various common image properties. The properties considered are color, texture, animal, person, location, pattern, and shape. The correlations are calculated by averaging over a selection of common features for each model. The models used are DeiT, DINO, DINOv2, Swin, and MaxViT.

This table presents the performance comparison of different zero-shot image segmentation methods on several vision transformer (ViT) models. The methods compared include the proposed decomposition approach and two established baselines: GradCAM and the method by Chefer et al. The evaluation metrics used are pixel accuracy (pixAcc), mean intersection over union (mIoU), and mean average precision (mAP). The results highlight the effectiveness of the proposed approach compared to existing techniques.
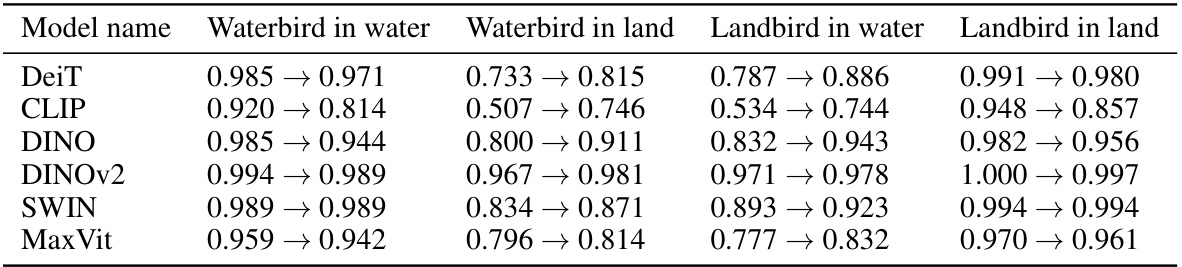
This table presents the group accuracies on the Waterbirds dataset before and after ablating specific model components. The Waterbirds dataset is a synthesized dataset where images of birds are pasted onto backgrounds of either water or land, creating a spurious correlation between the bird type and the background. The ablation experiment aims to mitigate this spurious correlation by selectively removing components identified as contributing to the spurious association. The results show the improvement in the worst-performing group’s accuracy and the overall average group accuracy after this intervention. The table provides a quantitative measure of the effectiveness of the proposed method in reducing the impact of the spurious correlation.
Full paper#