TL;DR#
Current LLM post-training methods rely heavily on expensive and time-consuming human evaluations in online chatbot arenas. This presents a significant obstacle to efficient model development and improvement. The manual data curation and online human evaluation processes are major bottlenecks.
WizardArena addresses these issues by simulating offline chatbot arena battles using open-source LLMs. It introduces Arena Learning, an innovative offline training strategy that leverages AI-driven annotations to evaluate and enhance models iteratively. Experiments demonstrate that WizardArena’s rankings closely match those of human-evaluated arenas, showcasing its efficiency and reliability in guiding LLM post-training, leading to significant performance improvements across different training stages.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in large language model (LLM) post-training. It presents WizardArena, a novel offline simulation that significantly reduces the cost and time associated with human-based evaluations and offers a scalable, efficient training method called Arena Learning. This addresses a critical bottleneck in LLM development and opens avenues for more efficient and cost-effective model improvement.
Visual Insights#

🔼 This figure illustrates a running example of the WizardArena system. It shows how two models (A and B) respond to an instruction, and how a judge model determines which response is better. This ranking information is then used to create training data for supervised fine-tuning (SFT) and direct preference optimization (DPO) and proximal policy optimization (PPO). Finally, the Elo ranking system is used to aggregate the results of many such comparisons.
read the caption
Figure 1: Overview of Running Example.
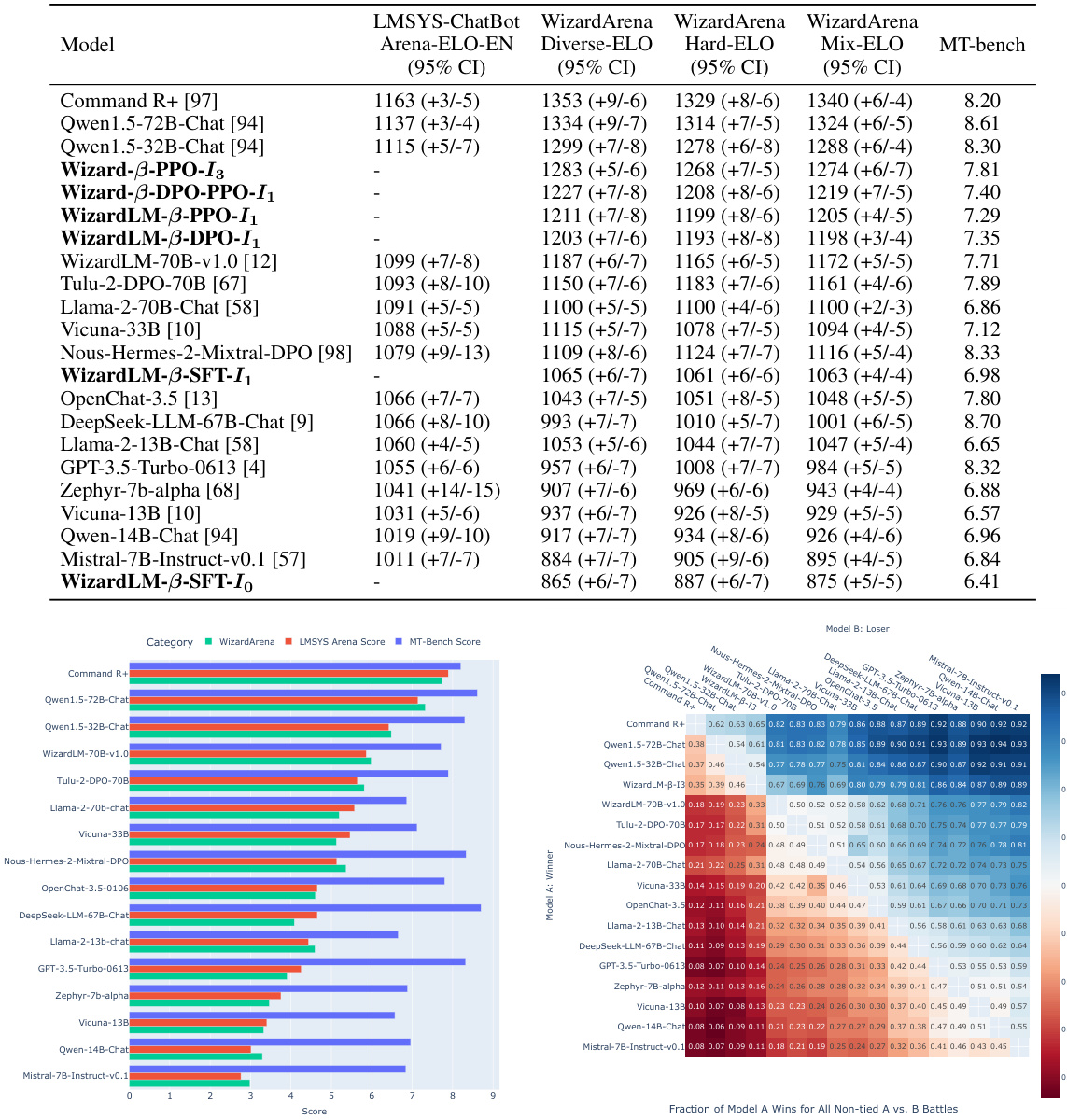
🔼 This table presents a comparison of the Elo rankings of 22 different large language models (LLMs) across five different benchmarks: the English version of the LMSYS ChatBot Arena, MT-Bench, and three variations of the WizardArena offline test set (Offline-Diverse, Offline-Hard, and Offline-Mix). The Elo ranking reflects the relative performance of each model against others in a series of head-to-head comparisons. The table allows for a comprehensive evaluation of model performance across diverse evaluation metrics and benchmarks, highlighting strengths and weaknesses of each model.
read the caption
Table 1: The ELO rankings results of 22 models on LMSYS ChatBot Arena EN, MT-Bench, Offline-Diverse, Offline-Hard, and Offline-Mix (Diverse & Hard).
In-depth insights#
WizardArena: Offline LLMs#
WizardArena simulates a human-judged chatbot arena using only offline LLMs, addressing limitations of existing methods. It introduces Arena Learning, a novel training strategy employing AI-driven annotations to simulate iterative battles among LLMs, continually improving a target model’s performance through techniques like SFT, DPO, and PPO. This approach mitigates the expense and time constraints associated with human evaluation. WizardArena’s offline Elo rankings accurately reflect those of online human arenas, validating its effectiveness as a cost-effective alternative. The paper’s central contribution is the development of a fully AI-powered, scalable method for post-training LLMs, improving performance and efficiency. However, further research could explore the robustness of the judge model and potential biases in the synthetic data generated, especially regarding fairness and ethical implications.
Arena Learning: Training#
Arena Learning, as a training methodology, leverages simulated arena battles among multiple large language models (LLMs). This offline approach avoids the high cost and time constraints of human evaluation. The core idea is to continuously improve a target LLM (WizardLM-β) by pitting it against other state-of-the-art models in a series of simulated conversations. The results of these battles, judged by an AI ‘judge model,’ are used to generate training data. This data then feeds into refinement processes such as supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO), iteratively enhancing WizardLM-β’s performance. The iterative nature of Arena Learning ensures continuous adaptation and improvement, effectively creating a data flywheel. AI-driven annotation of battle results is key to the scalability and efficiency of this method, bypassing the need for manual human evaluation. The efficacy is demonstrated by significant performance improvements in WizardLM-β across various benchmarking metrics after multiple iterative training loops.
Elo Ranking Prediction#
Elo ranking prediction in the context of chatbot arena evaluation presents a significant challenge and opportunity. Accurately predicting Elo rankings without human evaluation is crucial for efficient model development and large-scale comparisons. A robust prediction model requires a sophisticated understanding of conversational dynamics, incorporating features beyond simple win/loss metrics. This might involve analyzing response quality, fluency, coherence, and the strategic interaction between chatbots. Effective feature engineering is essential, potentially incorporating advanced NLP techniques like sentiment analysis, topic modeling, or even game-theoretic approaches to quantify the strategic advantages of different chatbot strategies. Furthermore, the choice of prediction model itself is important. Methods like regression models, ranking algorithms (e.g., RankNet), or even more advanced deep learning models trained on synthetic data could be considered, each offering different strengths and weaknesses. Evaluating the accuracy of Elo ranking predictions would involve comparing predicted rankings to actual human-judged rankings using metrics such as correlation and concordance. The ability to generate accurate predictions could dramatically speed up the iterative model improvement process, enabling the exploration of a significantly broader space of chatbot designs and strategies.
Offline Test Set Design#
Creating a robust offline test set is crucial for evaluating large language models (LLMs) without relying on expensive and time-consuming online human evaluation. A well-designed offline test set should mirror the diversity and complexity of real-world interactions, including various conversational scenarios, lengths of interactions, and levels of difficulty. This requires careful consideration of data sourcing strategies; using diverse existing datasets and potentially augmenting with synthetic data generated by LLMs, while ensuring the quality and lack of bias in the chosen data is critical. Careful stratification or clustering of the test data based on various characteristics of the prompts or conversations can improve the efficiency of the testing process and allow for a more comprehensive evaluation. Furthermore, the selection of appropriate evaluation metrics is essential to capture the nuances of LLM performance; Elo ratings provide a powerful way to rank models against each other, but other metrics may also be incorporated to give a more complete picture of capabilities. By meticulously designing and validating an offline test set, researchers can greatly enhance the reliability, speed and cost-effectiveness of LLM evaluation.
Future Work & Limits#
Future research directions could explore enhancing WizardArena’s evaluation capabilities by incorporating more diverse and challenging evaluation metrics. Improving the judge model’s accuracy and robustness is crucial, perhaps through techniques like reinforcement learning from human feedback or by using ensembles of judge models. Investigating the scalability of Arena Learning for even larger language models and datasets is also essential. Addressing potential biases in the training data generated by Arena Learning is paramount to ensure fairness and prevent the perpetuation of existing societal biases. Finally, the ethical implications of using AI-driven annotations for training should be carefully considered and mitigation strategies developed to minimize potential harm. The limitations of relying solely on simulated offline arenas need to be acknowledged, and methods for validating the results against real-world human evaluations are crucial. Exploring the application of WizardArena to other NLP tasks, such as summarization, translation, and question answering, would extend its impact and usefulness.
More visual insights#
More on figures

🔼 This figure illustrates the overall workflow of the proposed WizardArena and Arena Learning. The left part shows the offline pair-wise battle arena where multiple LLMs compete against each other. The results of these battles are used to generate training data for the target model, WizardLM-β, through three stages: supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO). This iterative process of battle and training continuously improves WizardLM-β’s performance. The right part of the figure shows how WizardArena is used for evaluation, using the Elo ranking system to assess the performance of different models.
read the caption
Figure 2: Overview of Arena Learning post-training data flywheel and WizardArena evaluation.

🔼 This figure compares the performance of 15 popular language models across three different benchmarks: MT-Bench, the normalized LMSYS ChatBot Arena, and the normalized WizardArena. It visually represents the ranking and relative performance of each model on these distinct evaluation metrics, allowing for a comparative analysis of their strengths and weaknesses in various aspects of language understanding and generation. The normalization likely adjusts scores to a common scale, facilitating easier cross-benchmark comparisons.
read the caption
Figure 3: The performance comparison of 15 popular models across MT-Bench, normalized LMSYS ChatBot Arena, and normalized WizardArena.

🔼 This figure illustrates the Arena Learning process, showing how iterative battles between a target model (WizardLM-β) and other state-of-the-art models generate training data. This data is used to improve the target model through supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO). The WizardArena evaluation uses an Elo ranking system to assess model performance based on simulated offline battles.
read the caption
Figure 2: Overview of Arena Learning post-training data flywheel and WizardArena evaluation.
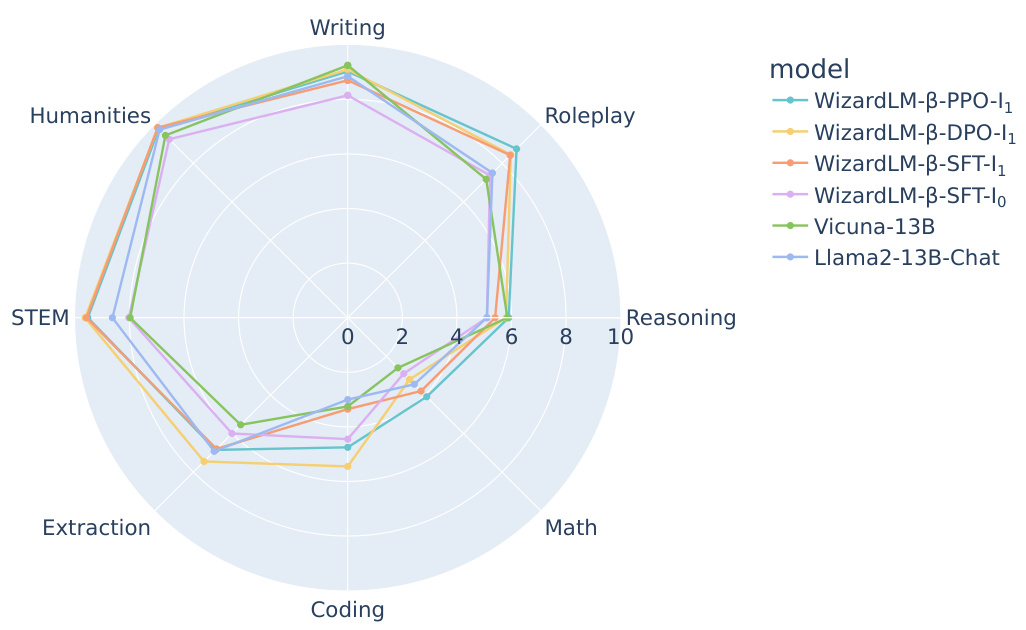
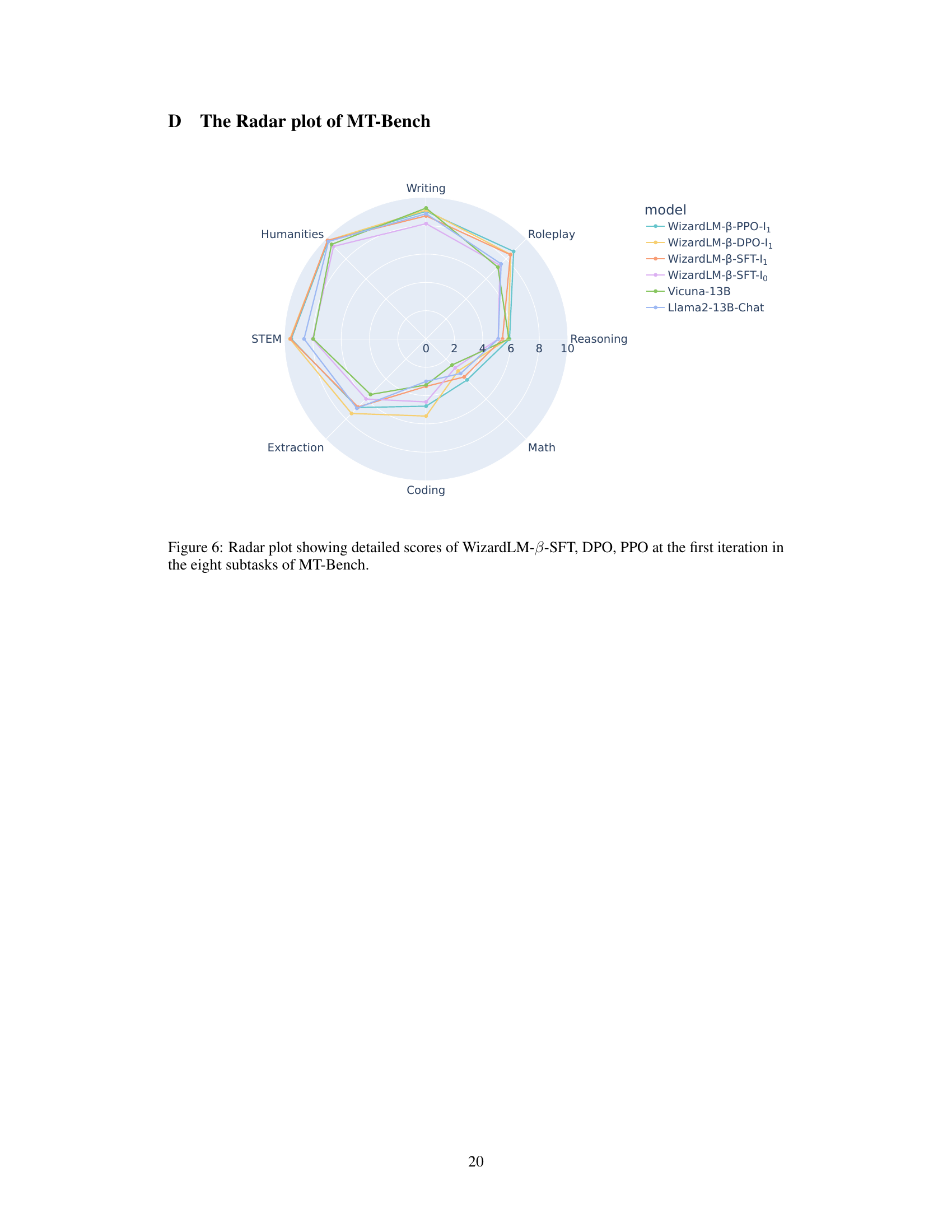
🔼 This radar chart compares the performance of several language models across eight subtasks within the MT-Bench benchmark. The models compared include different versions of WizardLM (trained using Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Proximal Policy Optimization (PPO) methods) as well as Vicuna-13B and Llama2-13B-Chat. Each axis represents a subtask (Humanities, Writing, Roleplay, STEM, Reasoning, Extraction, Coding, Math), and the distance from the center indicates the model’s performance on that subtask. The chart visually illustrates the relative strengths and weaknesses of each model across various types of tasks within the MT-Bench evaluation.
read the caption
Figure 6: Radar plot showing detailed scores of WizardLM-B-SFT, DPO, PPO at the first iteration in the eight subtasks of MT-Bench.
More on tables
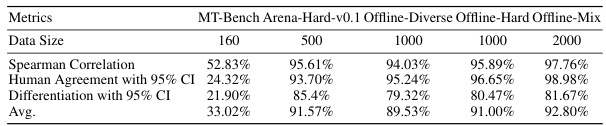
🔼 This table compares the consistency of three different benchmark methods (MT-Bench, Arena-Hard-v1.0, and Offline WizardArena) with the LMSYS ChatBot Arena, a human-evaluated benchmark. It shows the Spearman correlation, human agreement (with 95% confidence interval), and differentiation (also with 95% CI) between each offline method and the LMSYS arena. Higher values indicate better agreement and differentiation, demonstrating how well the offline benchmarks align with human evaluation.
read the caption
Table 2: The consistency of MT-Bench, Arena-Hard-v1.0, and Offline WizardArena compared with the LMSYS ChatBot Arena.
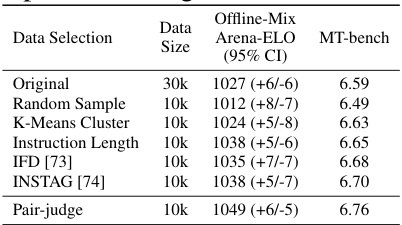
🔼 This table presents the results of an ablation study on different data selection strategies used in the supervised fine-tuning (SFT) stage of the WizardArena training process. It compares the performance of various data selection methods, including a baseline using the original dataset (30k samples), as well as methods that randomly sample 10k samples, use K-Means clustering to select 10k samples, select 10k samples based on instruction length, utilize the IFD and INSTAG methods to select 10k samples each, and finally the pair-judge method (also with 10k samples). The performance is evaluated using two metrics: Offline-Mix Arena ELO (95% Confidence Interval) and MT-bench scores. The goal is to determine which data selection method yields the best model performance.
read the caption
Table 3: Explores data selection strategies for the SFT stage, using 10k samples for each method except for the Original D1.
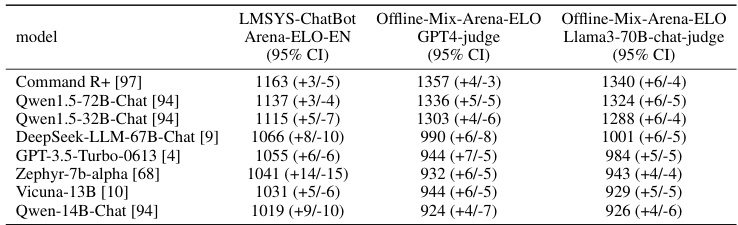
🔼 This table compares the Elo rankings of 22 large language models across five different benchmarks: the English version of the LMSYS ChatBot Arena, MT-Bench, and three variations of the Offline WizardArena (Offline-Diverse, Offline-Hard, and Offline-Mix). The Offline WizardArena benchmarks were created to provide a more cost-effective and scalable alternative to human evaluation. The table shows the Elo scores (with 95% confidence intervals) for each model on each benchmark, allowing for a comparison of model performance across various evaluation metrics.
read the caption
Table 1: The ELO rankings results of 22 models on LMSYS ChatBot Arena EN, MT-Bench, Offline-Diverse, Offline-Hard, and Offline-Mix (Diverse & Hard).
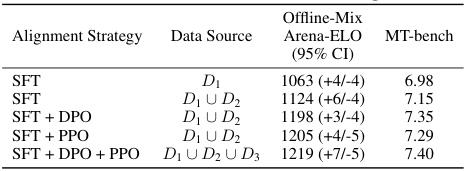
🔼 This table presents the results of an ablation study evaluating the impact of different training strategies (SFT, DPO, PPO) on the model’s performance. It shows the Offline-Mix Arena ELO scores and MT-bench scores achieved after training with different combinations of these strategies and datasets (D1, D1 U D2, D1 U D2 U D3). The results demonstrate how each strategy contributes to the final model performance.
read the caption
Table 5: Explore the impact of different training strategies in the first round during the SFT, DPO, and PPO stages. We utilize three slices of data for SFT, DPO, and PPO training.

🔼 This table presents a comparison of the Elo rankings obtained for 22 different language models across five different benchmark datasets: the English version of the LMSYS ChatBot Arena, MT-Bench, and three variations of the Offline WizardArena (Offline-Diverse, Offline-Hard, and Offline-Mix). The Elo ranking reflects each model’s performance in head-to-head comparisons against other models within each benchmark. The table allows for a comprehensive comparison of model performance across various task types and difficulty levels.
read the caption
Table 1: The ELO rankings results of 22 models on LMSYS ChatBot Arena EN, MT-Bench, Offline-Diverse, Offline-Hard, and Offline-Mix (Diverse & Hard).
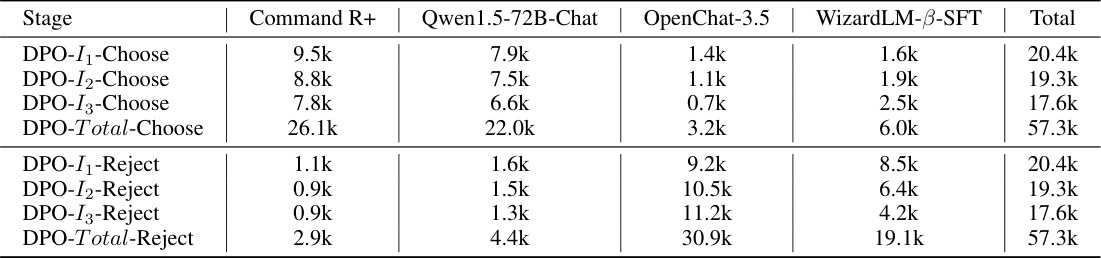
🔼 This table shows the number of ‘Choose’ and ‘Reject’ responses selected from each battle model (Command R+, Qwen1.5-72B-Chat, OpenChat-3.5, and WizardLM-β-SFT) during each of the three rounds (DPO-I1, DPO-I2, DPO-I3) of the direct preference optimization (DPO) training stage. The total number of ‘Choose’ and ‘Reject’ responses for each model across all three rounds is also presented. The data is used for the DPO training of the WizardLM-β model.
read the caption
Table 7: Explore the quantity of Choose and Reject responses for each battle model across various rounds during the DPO stages.
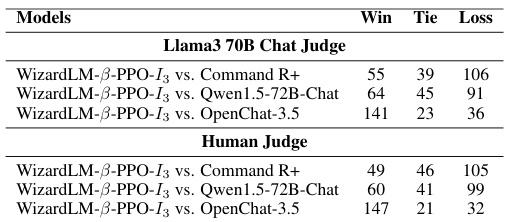
🔼 This table presents a comparison of the ELO rankings of 22 large language models across five different benchmarks: the English version of the LMSYS ChatBot Arena, MT-Bench, and three variations of the offline WizardArena (Offline-Diverse, Offline-Hard, and Offline-Mix). The Offline-WizardArena benchmarks were created to simulate the online human evaluation of chatbots, offering a cost-effective and scalable alternative. The table allows for the assessment of model performance consistency across different benchmarks and reveals whether certain models excel in specific areas (e.g., diverse tasks vs. hard tasks).
read the caption
Table 1: The ELO rankings results of 22 models on LMSYS ChatBot Arena EN, MT-Bench, Offline-Diverse, Offline-Hard, and Offline-Mix (Diverse & Hard).
Full paper#