↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Training diffusion models to sample from complex distributions is challenging, particularly for high-dimensional spaces or multimodal distributions. Existing methods like simulation-based variational approaches and off-policy methods have limitations in efficiency, stability, and reproducibility. Benchmarking is inconsistent, hindering comparative analysis and progress.
This paper introduces a novel exploration strategy for off-policy training of diffusion models. It leverages local search in the target space combined with a replay buffer to improve sample quality. Furthermore, a unified library is presented for different diffusion-structured samplers, including simulation-based methods and continuous generative flow networks, enabling robust benchmarking and identifying the strengths and limitations of existing techniques. The proposed method demonstrates enhanced performance across various target distributions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with diffusion models and amortized inference. It addresses reproducibility issues in the field by providing a unified library and benchmark, and introduces novel exploration strategies improving sample quality. The findings directly impact the development of more efficient and robust sampling methods for complex distributions, relevant to many applications in machine learning and beyond.
Visual Insights#
This figure compares the sampling results of various diffusion models on the 32-dimensional Manywell distribution. The different models are trained using different algorithms, including the authors’ proposed method incorporating a replay buffer and local search. The plots show two-dimensional projections of the resulting samples, illustrating the impact of the different training methods on the quality and diversity of the samples generated. The authors’ method, as evidenced by the image, is shown to prevent mode collapse, a common problem with diffusion models where the samples cluster around a few modes instead of covering the entire distribution.
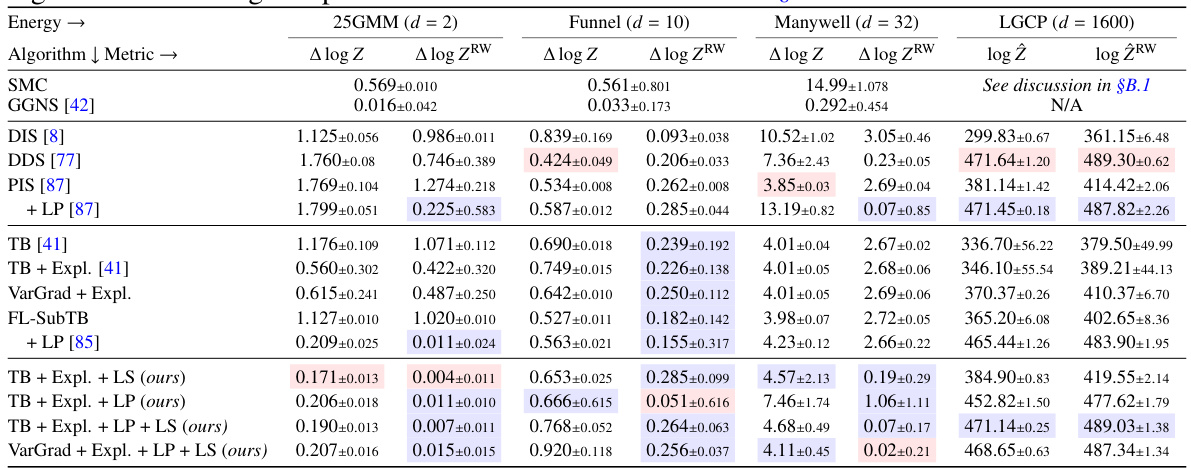
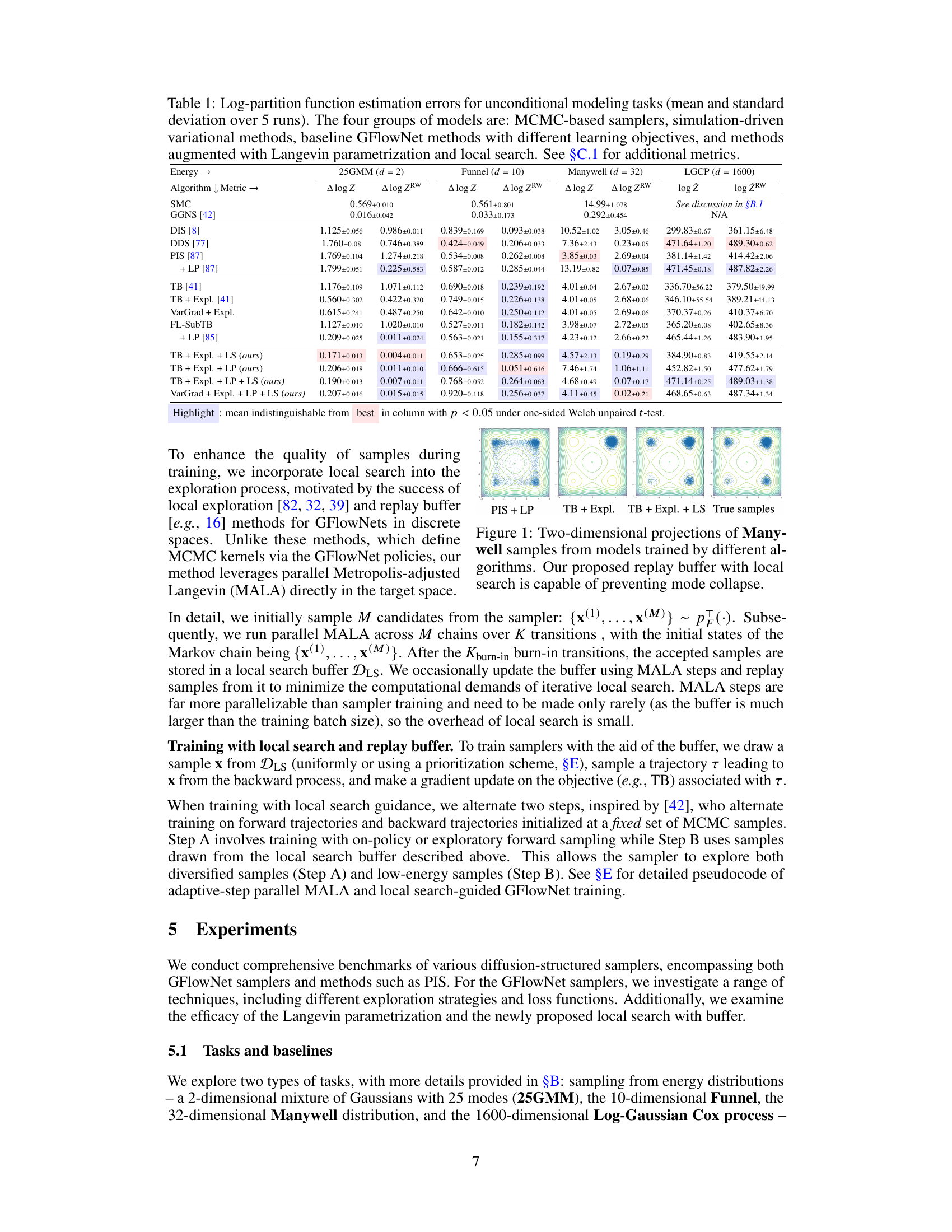
This table presents the results of log-partition function estimation for four different types of energy functions using various sampling methods. The methods are grouped into MCMC-based samplers, simulation-driven variational methods, baseline GFlowNets, and GFlowNets with enhancements (Langevin parametrization and local search). The table shows the mean and standard deviation over 5 runs for each method and energy function. Additional metrics can be found in section C.1 of the paper.
In-depth insights#
Off-policy Diffusion#
Off-policy diffusion methods represent a significant advancement in training diffusion models, particularly for scenarios where direct sampling from the target distribution is computationally expensive or intractable. The core idea is to leverage experience from a behavior policy, rather than relying solely on samples generated from the current diffusion model. This allows for more efficient exploration of the state space and faster convergence during training. However, off-policy training introduces challenges related to credit assignment, as the behavior policy’s actions may not perfectly align with the target distribution’s characteristics. The paper explores various methods to address credit assignment problems by proposing novel exploration strategies such as local search with replay buffers to improve sample quality and proposing gradient-based corrections that helps in guiding the learning process. The work also highlights the need for careful benchmarking and reproducibility in the field, providing a unified library to facilitate comparative analysis of different off-policy diffusion methods. A key takeaway is that the combination of efficient exploration techniques and robust credit assignment strategies is crucial to unlock the full potential of off-policy diffusion models.
GFlowNet Training#
GFlowNet training presents a unique challenge in the realm of probabilistic modeling. Unlike traditional methods that directly optimize likelihood, GFlowNets frame sampling as a sequential decision-making process, leveraging reinforcement learning principles. Off-policy training, a key advantage, allows learning from trajectories generated by diverse policies, enhancing exploration and robustness. Credit assignment remains a crucial hurdle, as propagating learning signals effectively across sequential steps is non-trivial. The paper explores several techniques, including partial trajectory information and gradient-based methods to improve exploration and credit assignment. Local search, a novel approach proposed, uses parallel MALA in the target space with a replay buffer to enhance sample quality, particularly in complex, high-dimensional distributions. These techniques address inherent difficulties in training GFlowNets and contribute significantly to the field’s advancement.
Local Search Boost#
A ‘Local Search Boost’ in the context of a research paper likely refers to a technique that enhances the exploration capabilities of a search algorithm, particularly within a complex search space. This could involve augmenting existing methods with a local search component, which operates iteratively in a small neighborhood around a current candidate solution to refine its quality. The benefit is a more effective exploration of promising areas, potentially discovering high-quality solutions that would be missed by a purely global search strategy. The boost could be achieved through various mechanisms, such as incorporating a replay buffer to store and reuse promising solutions encountered previously, or leveraging parallel explorations using multiple local searches concurrently. This would improve both efficiency and effectiveness, preventing premature convergence on suboptimal solutions. The implementation details would vary depending on the context of the algorithm. However, the core idea involves incorporating localized, iterative refinement to enhance the exploration process in search algorithms, thereby improving the quality of the found solutions. Careful consideration of parameters controlling the local search (e.g., search radius, iteration count) is vital to balance the trade-off between intensive local exploration and broader space coverage. The evaluation of such a boost would require careful experimental design, comparing its performance against baseline methods across different problem instances and metrics.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the effectiveness of improved off-policy training methods for diffusion samplers. Careful selection of target distributions with varying complexity and dimensionality is needed to ensure comprehensive evaluation. The analysis should compare the proposed methods against existing state-of-the-art techniques, including both on-policy and off-policy approaches, using multiple evaluation metrics that measure not just sampling efficiency but also the accuracy and mode coverage of samples. A key aspect is the reproducibility of the results, which should be ensured via clear documentation and public release of code and data. The analysis should also investigate the effect of hyperparameter choices on performance to provide insights into practical usability. Benchmarking should go beyond simple quantitative metrics to include qualitative analysis of sample quality using visualization techniques. By addressing these elements, a thoughtful benchmark analysis can provide valuable insights into the strengths and weaknesses of different off-policy training methods and guide future research directions.
Future Directions#
Future research could explore extending the framework to handle more complex data modalities, such as images and time series. Another promising area is developing more efficient exploration strategies to reduce the computational cost of training, potentially through the use of advanced reinforcement learning techniques or improved sampling methods. Furthermore, investigating alternative loss functions and optimization algorithms might improve the quality and speed of learning. Finally, a theoretical analysis of the continuous-time limit of the algorithms would provide deeper insights into their behavior and could inspire new improvements.
More visual insights#
More on figures
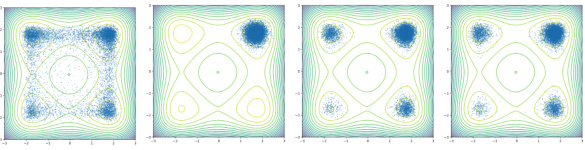
This figure displays two-dimensional projections of samples generated from the Manywell distribution using different sampling methods. The visualizations show the effectiveness of the proposed method (replay buffer with local search) in preventing mode collapse, a common issue in generative modeling where the model fails to capture the diversity of the target distribution. The figure allows a visual comparison of the sample distributions obtained with various algorithms, highlighting the improved mode coverage and reduced mode collapse achieved by incorporating the proposed replay buffer and local search strategy.

This figure shows the impact of different exploration strategies on the performance of diffusion models trained using the trajectory balance (TB) objective on a 25-dimensional Gaussian Mixture Model (25GMM). The x-axis represents the exploration rate, and the y-axis represents the estimated log partition function (log Z). Two lines are shown: one for models trained with constant exploration and another for models trained with decaying exploration. The results indicate that while exploration is beneficial for discovering multiple modes, allowing it to decay over time improves the model’s ability to accurately estimate the partition function by focusing the model’s capacity on higher-probability regions of the target distribution.
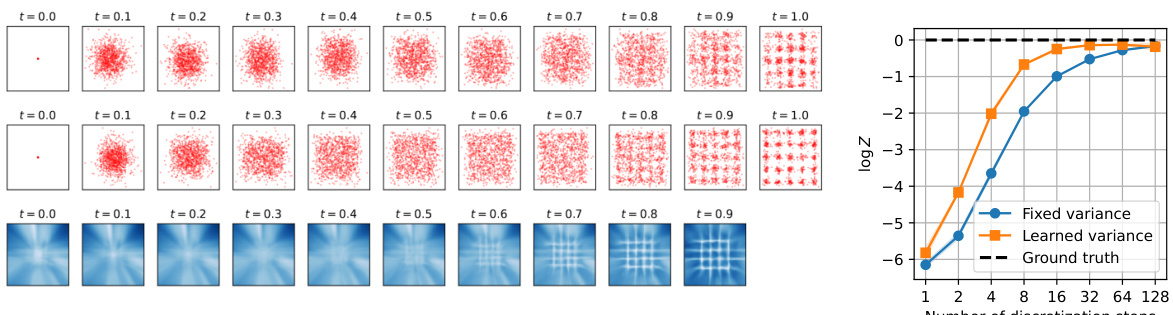
This figure compares the performance of 10-step samplers with fixed and learned forward policy variance on the 25GMM energy. The left panel shows the distribution of samples at different time steps for both models, highlighting how learning the variance allows the model to capture the modes more sharply. The right panel shows how learning the policy variance leads to similar results with fewer steps.

This figure shows two-dimensional projections of samples generated from the 32-dimensional Manywell distribution using different sampling methods. The goal is to visualize the performance of various sampling algorithms in capturing the multiple modes of the distribution. The figure demonstrates that the proposed method, which uses a replay buffer and local search, effectively prevents the model from collapsing to a single mode, thus improving sample quality compared to other methods.
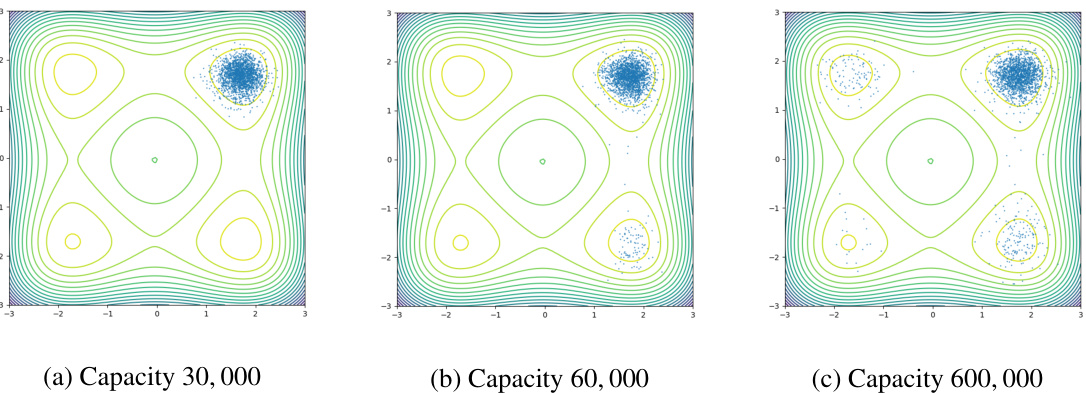
This figure shows the impact of replay buffer capacity on the sample quality of three different samplers. Each subplot displays 2000 samples generated by a sampler trained with a different buffer capacity (30,000, 60,000, and 600,000). The increase in buffer capacity leads to better exploration of the target distribution’s modes, as evidenced by the increased number of modes captured in the samples. This supports the claim that a larger replay buffer enhances the sampler’s ability to recall and utilize past low-energy samples.

This figure presents an ablation study on two aspects of the local search algorithm used in the paper: the use of a prioritized replay buffer and the dynamic adjustment of the step size. The left subplot (a) shows that prioritized sampling, where samples with higher ranks (based on their unnormalized target density) are more likely to be selected, leads to faster convergence than uniform sampling. The right subplot (b) demonstrates that dynamically adjusting the step size to maintain a target acceptance rate of 0.574 (theoretically optimal for high-dimensional MALA) outperforms using a fixed step size. This ablation study highlights the effectiveness of these techniques in improving the performance of the local search method.
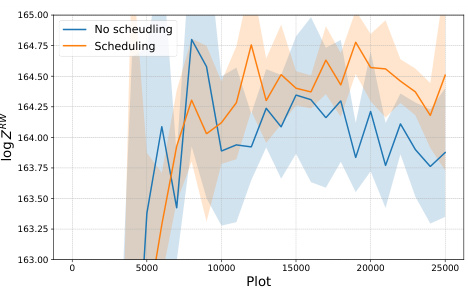
This figure presents the ablation study results for two hyperparameters of the proposed local search method: the prioritized replay buffer and the dynamically adjusted step size. The left subplot (a) compares the performance of prioritized sampling (using the rank-based approach) against uniform sampling. The right subplot (b) shows the impact of dynamically adjusting the step size (η) to maintain an optimal acceptance rate (0.574) compared to using a fixed step size (η = 0.01). The plots show the log ZRW (log partition function with importance weights) across 25,000 training iterations, revealing that both techniques lead to significant performance improvements.
More on tables
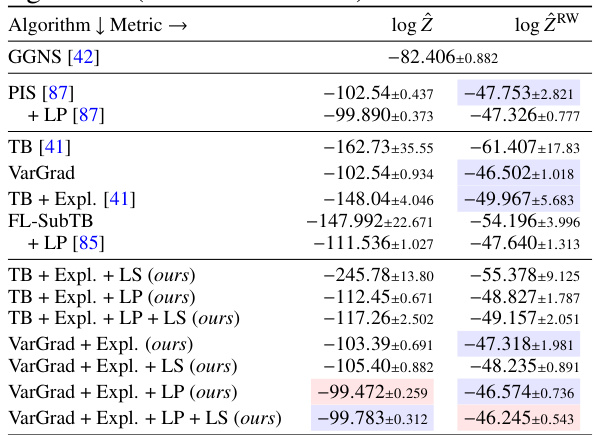
This table presents the results of log-partition function estimation for four groups of models on unconditional modeling tasks. The models are compared using mean and standard deviation of the error over 5 runs. The four groups of models are MCMC-based samplers, simulation-driven variational methods, baseline GFlowNets, and GFlowNets enhanced with Langevin parametrization and local search. Additional metrics are detailed in section C.1 of the paper.

This table presents the results of log-partition function estimation for four different types of models on four different datasets. It compares MCMC methods, simulation-based variational inference methods, and GFlowNet methods (with and without enhancements like Langevin parametrization and local search). The table shows the mean and standard deviation of the log-partition function estimate over five runs for each method and dataset. Additional metrics are available in section C.1 of the paper.

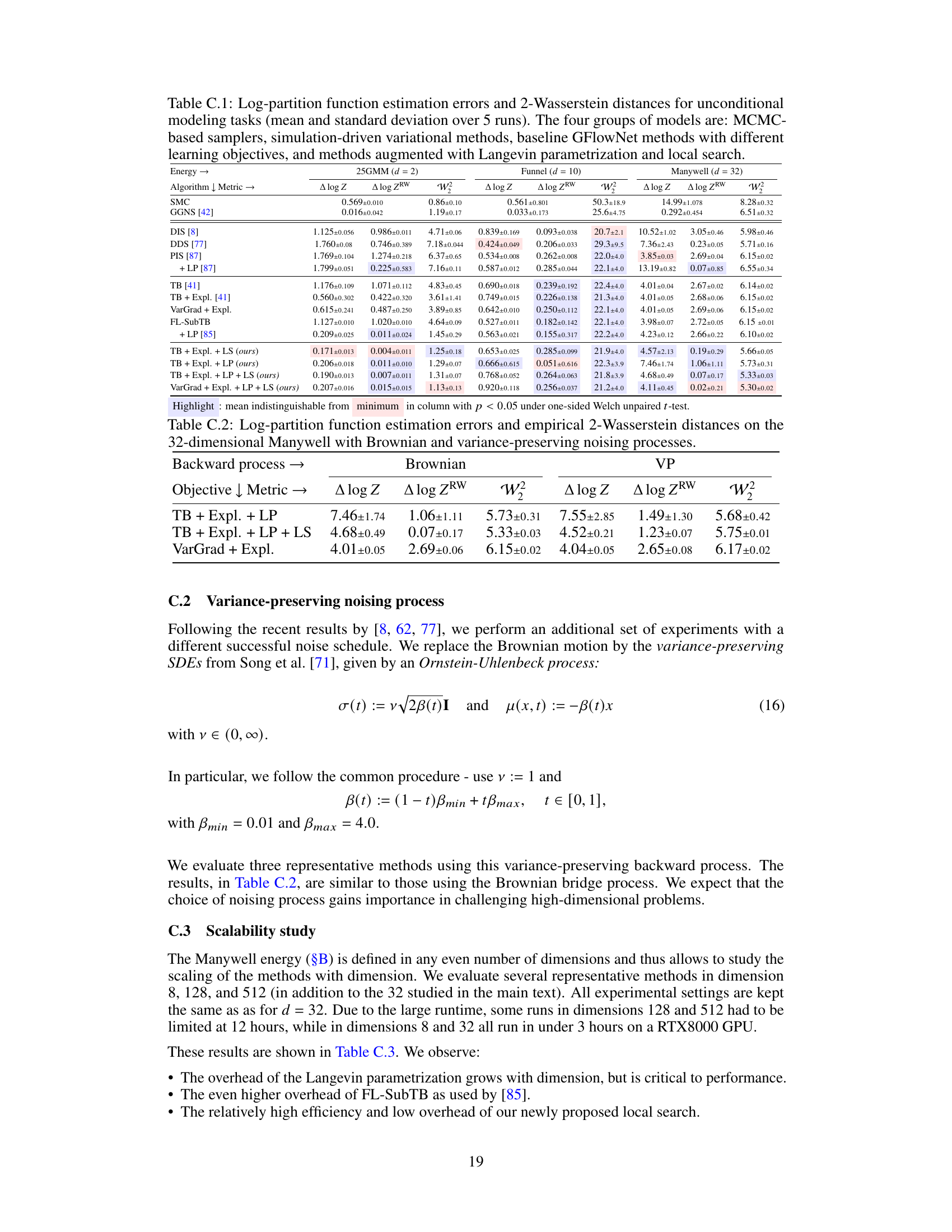
This table presents a comprehensive comparison of various sampling methods’ performance on four different tasks: 25GMM, Funnel, Manywell, and LGCP. The methods are categorized into four groups: MCMC-based samplers, simulation-driven variational methods, GFlowNet methods with different objectives, and enhanced GFlowNet methods incorporating Langevin parametrization and local search. The table shows the log-partition function estimation errors (both standard and importance-weighted) and the 2-Wasserstein distance, offering a multi-faceted evaluation of each method’s sampling accuracy and efficiency.
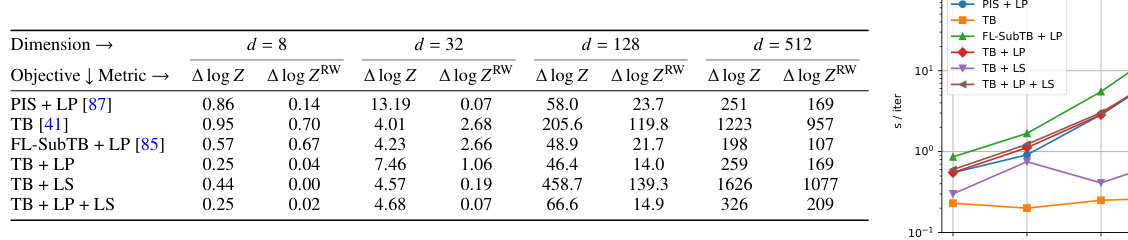
This table presents the results of a scalability study conducted on the Manywell energy function, evaluating the performance of various samplers across different dimensions (d = 8, 32, 128, 512). The metrics presented include the log-partition function estimation error (both standard and importance weighted), and the time per training iteration on a RTX8000 GPU. This allows assessing how the performance and computational cost of different approaches scale as dimensionality increases.

This table presents the results of log-partition function estimation for four different types of models on four different tasks. The models are categorized into MCMC-based samplers, simulation-driven variational methods, baseline GFlowNets, and GFlowNets with enhancements. The tasks are 2D Gaussian Mixture Model, 10D Funnel, 32D Manywell, and 1600D Log-Gaussian Cox Process. The table shows mean and standard deviation over 5 runs for each model and task. Additional metrics are available in section C.1.

This table presents the log-partition function estimation errors for four groups of models on unconditional modeling tasks. The models are compared using mean and standard deviation over 5 runs. The four model groups are MCMC-based samplers, simulation-driven variational methods, baseline GFlowNet methods (with different learning objectives), and GFlowNet methods augmented with Langevin parametrization and local search. Additional metrics are available in section C.1 of the paper.
Full paper#