↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Web-scale visual entity recognition struggles due to limited high-quality training data. Existing methods often produce noisy datasets with mismatched image content and entities, hindering model accuracy. This paper introduces a novel approach that leverages a multimodal large language model (LLM) to curate a high-quality dataset. Instead of directly using the LLM for annotation, which was found suboptimal, the researchers prompt the LLM to reason about potential entity labels using contextual information like Wikipedia pages and image captions, thus increasing annotation accuracy. The LLM also generates question-answer pairs and detailed descriptions to enrich the dataset.
This innovative methodology produced significant improvements in visual entity recognition tasks. The automatically curated data yielded state-of-the-art results on web-scale benchmarks such as OVEN, demonstrating a substantial improvement in model accuracy. The high-quality training data also enabled the use of smaller models, making the approach more computationally efficient. Overall, the study highlights the importance of high-quality training data and the power of LLMs as tools for data augmentation in visual entity recognition.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and related fields because it directly addresses the critical challenge of data scarcity in web-scale visual entity recognition. By introducing a novel LLM-driven data curation method resulting in a high-quality dataset, it provides a strong foundation for future research and improvements in model accuracy. This work also opens new avenues for exploring the potential of large language models in data augmentation and generating high-quality training data for other visual tasks. The methodology and findings are relevant to current research trends focusing on improving the accuracy and robustness of visual entity recognition models, especially on large-scale datasets.
Visual Insights#

This figure shows two examples where existing visual entity recognition datasets fail. In (a), an image of a residential building is wrongly labeled as ‘Negative equity’ due to an irrelevant caption. In (b), a fish image is incorrectly labeled as a moth due to an inaccurate caption-entity match. The authors propose a new method using a multimodal Large Language Model (LLM) to solve this, which includes verifying and correcting candidate entities, generating rationales explaining image-entity relationships, and creating diverse question-answer pairs to enhance the dataset.
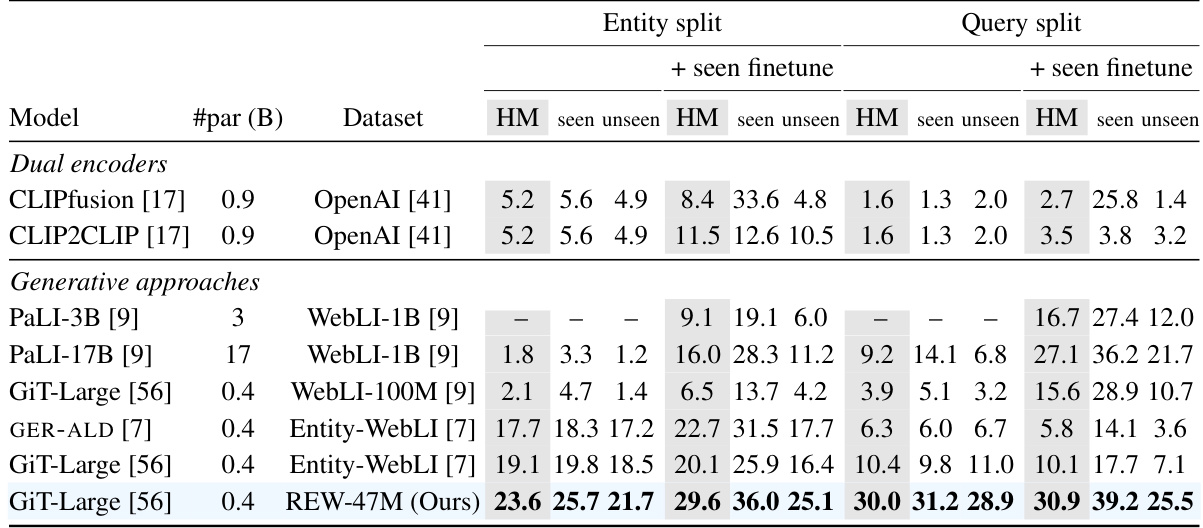
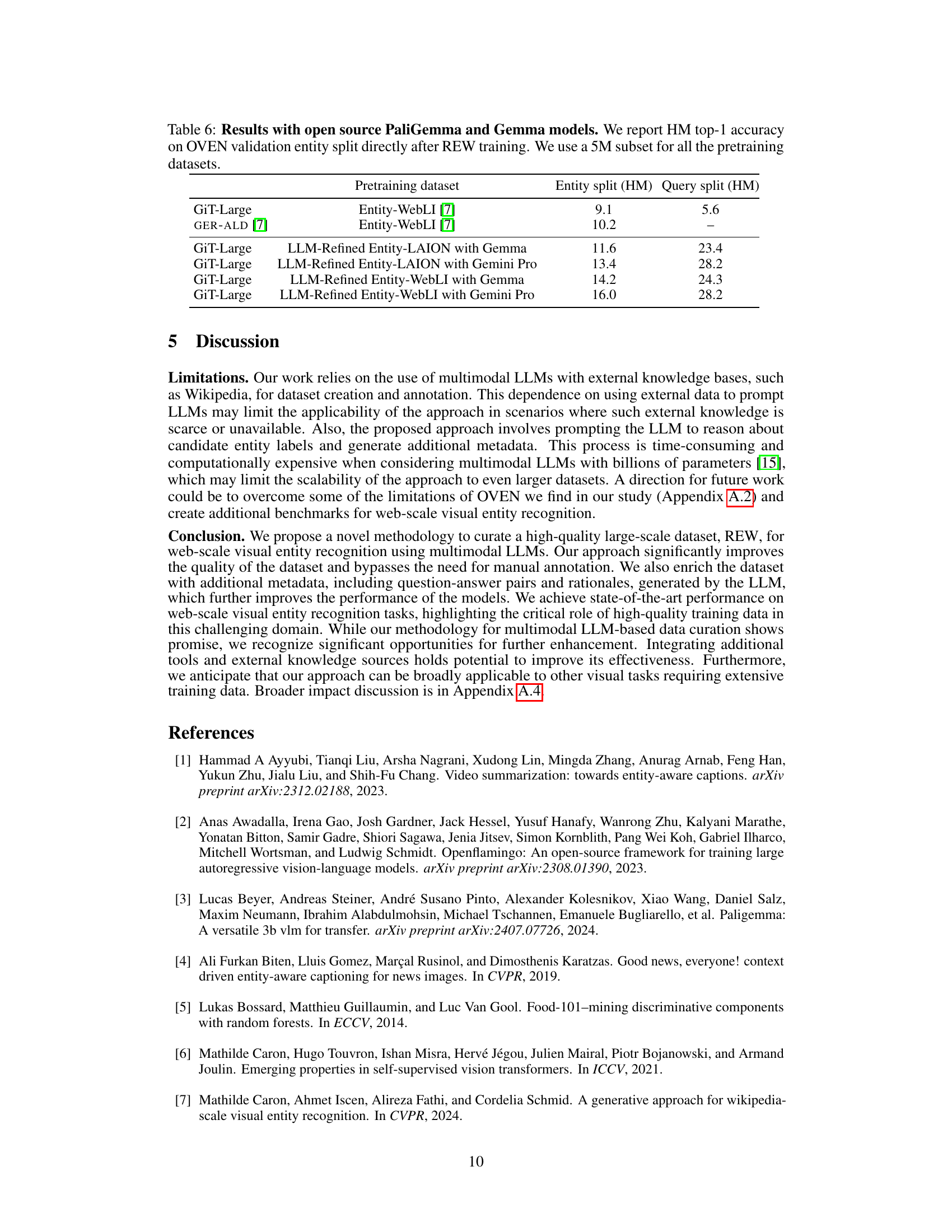
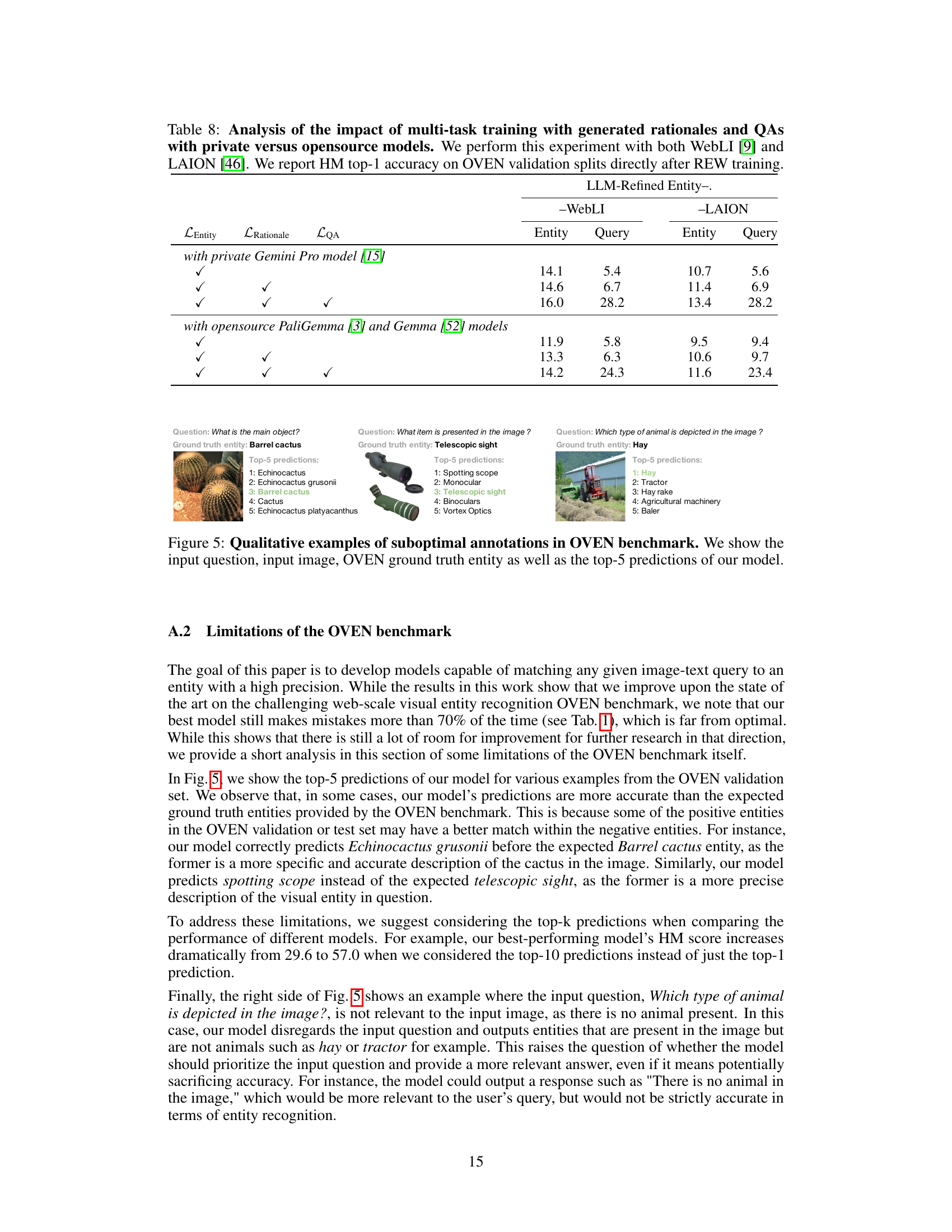
This table compares the performance of different models on the Open-domain Visual Entity recognitioN (OVEN) benchmark. It shows the harmonic mean (HM) of top-1 accuracy for both seen and unseen entities, before and after fine-tuning on the OVEN training set. The table also provides information on model architectures, the number of parameters, and the training datasets used for each model.
In-depth insights#
LLM Data Curation#
LLM data curation represents a significant advancement in leveraging large language models (LLMs) for data augmentation and improvement. The core idea is to use the LLM not as a direct annotator, but as a sophisticated verification and refinement tool. This approach addresses inherent limitations of directly relying on LLMs for labeling, which often results in noisy or inaccurate annotations. By incorporating contextual information such as Wikipedia entries and original image captions, the LLM can reason about potential entity labels and their relationship to the image, producing significantly improved annotations. The methodology also includes generating detailed rationales and question-answer pairs, enriching the dataset and improving model performance and understanding. This multi-faceted approach not only enhances data quality but also leads to improved generalizability of downstream models trained on this refined dataset. The use of a multimodal LLM facilitates this more effective labeling process and the ability to consider rich visual and textual features. This method demonstrates the potential of LLMs as powerful tools for augmenting data and tackling challenges such as the lack of high-quality training data that often hinder progress in web-scale visual entity recognition.
Multimodal LLM Prompting#
Effective multimodal LLM prompting is crucial for leveraging their potential in visual entity recognition. The core idea revolves around carefully crafting prompts that guide the LLM to perform specific tasks, such as verifying entity labels, generating rationales, and creating question-answer pairs. Directly using LLM outputs for annotation proves suboptimal, highlighting the need for a more sophisticated approach. Instead, prompting the LLM to reason about candidate labels by accessing additional context, like Wikipedia or image captions, significantly improves accuracy and reliability. This strategy transforms the LLM into a verification and correction tool rather than a mere labeler. The inclusion of rationales enhances model performance and offers valuable insights. Question-answer pair generation further enriches the dataset by providing diverse perspectives on the images and their associated entities, ultimately making the training data richer and more robust, addressing the limitations of existing datasets and leading to improved web-scale visual entity recognition models.
OVEN Benchmark Results#
The OVEN benchmark results section would be crucial for evaluating the proposed LLM-driven data approach for web-scale visual entity recognition. It would detail the performance of models trained on the automatically curated dataset against those trained on existing methods. Key metrics would include top-1 accuracy and harmonic mean (HM) across seen and unseen entity splits. High-quality curated data resulting in improved performance, particularly on challenging unseen entities, would be a strong indicator of success. The results should highlight the comparative performance gains achieved on both the entity and query splits, demonstrating the effectiveness of the approach across various entity recognition complexities. Significant improvement over state-of-the-art baselines would be a key takeaway. The section should also show comparisons to different model sizes, revealing the balance between model complexity and data quality. Finally, robustness tests under various conditions, such as using different LLMs or base image-caption datasets, would demonstrate the reliability and generalizability of the approach.
Ablation Study Analysis#
An ablation study systematically removes components of a model or system to assess their individual contributions. In this context, an ablation study on a visual entity recognition model might involve removing features like the multimodal LLM, rationales, or question-answer pairs, individually or in combination, to understand their impact on the model’s performance. Key insights from such a study would reveal which components are essential for high-quality results and which ones might be redundant or even detrimental. The analysis would likely quantify the impact of each removed component (e.g., using metrics such as accuracy or F1-score) and might visually present the results as bar charts or tables. A thorough ablation study helps to optimize the model architecture and dataset by identifying the most valuable features while eliminating less effective ones, ultimately leading to a more efficient and potentially more accurate model.
Future Research#
Future research directions stemming from this work could explore improving the LLM-based data curation process, perhaps by incorporating more sophisticated reasoning methods or external knowledge sources to refine entity assignments and rationale generation. Investigating the effectiveness of other LLM architectures beyond those tested here could reveal further performance gains. Addressing the limitations of the OVEN benchmark would also be a fruitful area of exploration, especially regarding the issues of ambiguous image-text matches and imbalanced class representation. Finally, extending this method to other visual tasks such as visual question answering or visual relationship detection could uncover its broader applicability and impact, allowing for high-quality data generation across a wider range of computer vision problems.
More visual insights#
More on figures
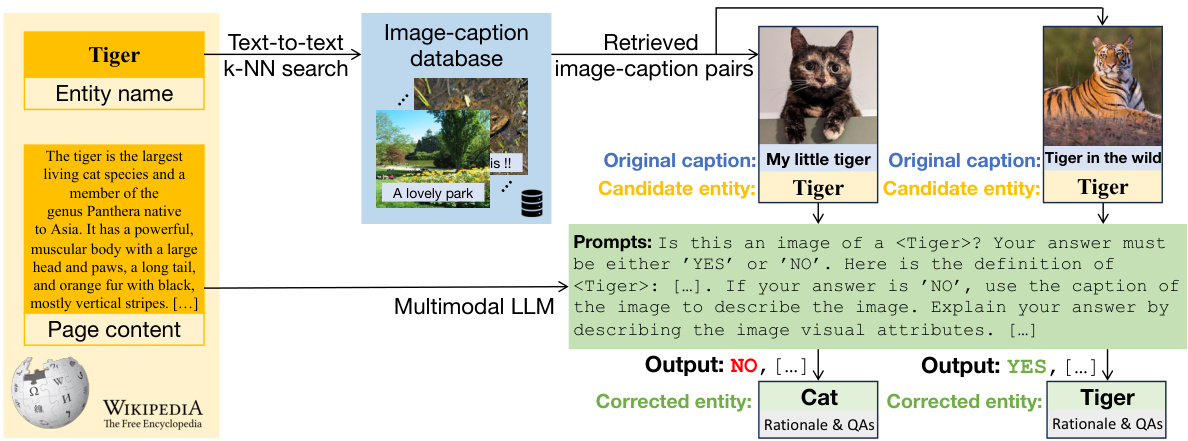
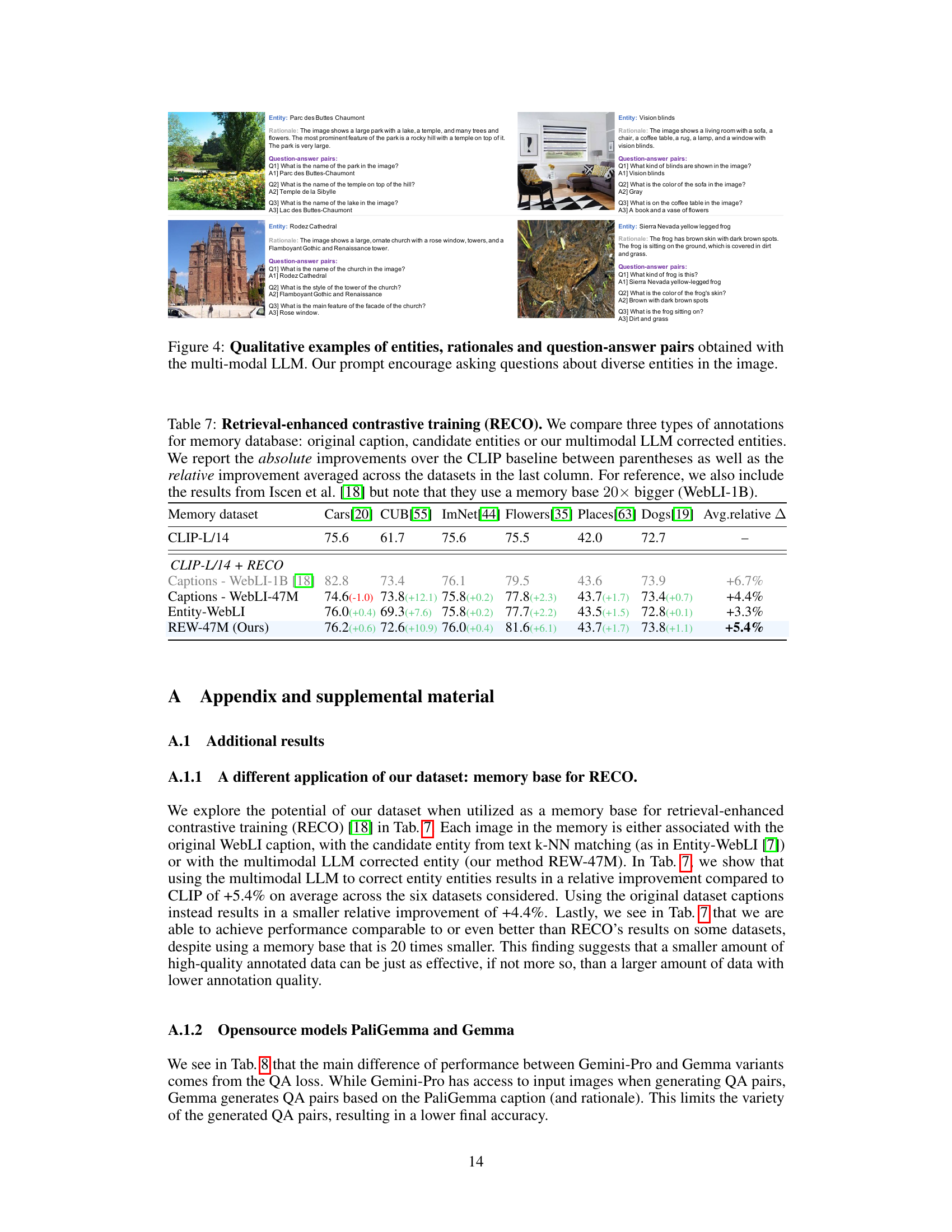
This figure illustrates the proposed LLM-Refined Entity-WebLI (REW) dataset creation method. It shows how a multimodal Large Language Model (LLM) is used to refine an existing dataset (Entity-WebLI) by verifying and correcting entity labels. The LLM accesses image captions, Wikipedia content, and prompts to reason about potential entity labels, resulting in more accurate annotations. The LLM also generates visually grounded rationales and question-answer pairs to further enrich the dataset.

This figure shows two examples where the visual entity recognition dataset of Caron et al. [7] fails. In (a), an image of a building is incorrectly labeled ‘Negative equity’ due to an irrelevant caption. In (b), the caption is incorrectly matched with a different animal species. The authors propose a new method using a multimodal LLM to correct these errors by providing additional context and enriching the dataset with rationales and question-answer pairs.

This figure shows examples where the multimodal LLM, with and without access to Wikipedia and original captions, makes incorrect corrections. It highlights how access to additional context significantly improves the accuracy of entity correction. The examples illustrate cases of hallucination, overly generic outputs, and situations where the LLM corrects an already correct entity. It also shows that only using the original caption as a target also leads to suboptimal performance.

This figure showcases two examples where the visual entity recognition dataset from Caron et al. [7] fails. The first example shows an image of a building incorrectly linked to the entity ‘Negative equity’ due to an irrelevant caption. The second shows an image of a fish incorrectly matched with a moth’s entity name. The authors’ proposed method addresses these issues by using a multimodal LLM to verify and correct candidate entities, while enriching the dataset with rationales and question-answer pairs.

This figure illustrates the proposed LLM-Refined Entity-WebLI (REW) dataset creation method. It shows how a multimodal LLM is used to verify and correct entity labels from the Entity-WebLI dataset by accessing additional context (like Wikipedia pages). The LLM also generates rationales (explanations) and question-answer pairs to enrich the dataset, improving the accuracy and detail of the annotations.
This figure illustrates the LLM-Refined Entity-WebLI (REW) dataset creation process. It shows how a multimodal LLM is used to refine the existing Entity-WebLI dataset by verifying and correcting Wikipedia entities associated with images. The LLM also generates rationales (explanations) and question-answer pairs to enrich the dataset, improving the connection between images and their associated entities.
More on tables

This table presents the results of a zero-shot transfer learning experiment on fine-grained image classification datasets. The authors used several pre-trained generative models (GiT-Large) trained on different datasets (WebLI-100M, Entity-WebLI, REW-47M) and evaluated their performance on five different fine-grained datasets (Flowers, Sun397, Food, Aircraft, Sports100). The table shows the top-1 accuracy for each model and dataset combination, highlighting the impact of different training data on transfer learning performance. The key takeaway is that using the automatically curated dataset (REW-47M) created by their proposed method leads to superior zero-shot transfer performance compared to models trained on existing datasets.
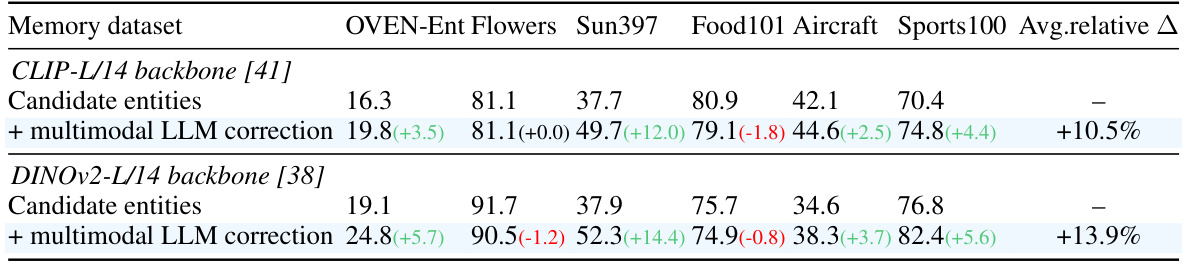
This table presents the results of visual matching experiments using two different visual backbones (CLIP-L/14 and DINOv2-L/14). The experiments compare the performance of visual matching when using two types of annotations for the memory database: candidate entities (from the original dataset) and multimodal LLM-corrected entities (refined using the model’s approach). The table shows top-1 accuracy for each dataset, along with the absolute and relative improvements achieved by using the LLM-corrected entities.

This table shows the impact of using a multimodal LLM for entity verification and correction on the performance of a visual entity recognition model. Four different approaches are compared, varying whether the LLM is used for direct entity prediction, or for correction of initial entity candidates, and whether the LLM has access to additional context (Wikipedia and original caption). The results demonstrate that using the LLM for correction, especially with access to additional context, significantly improves accuracy.
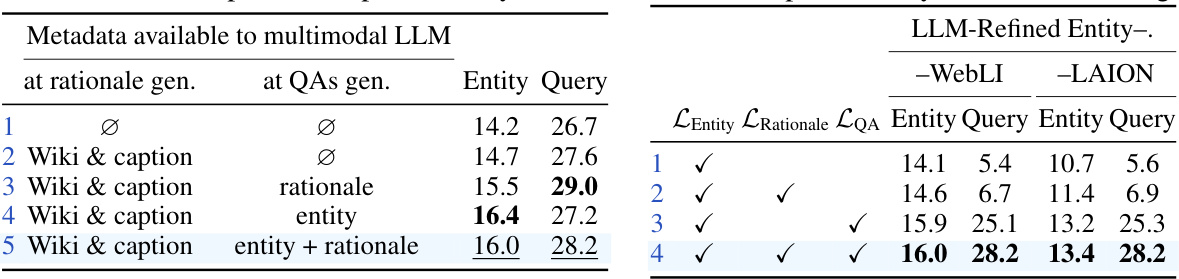
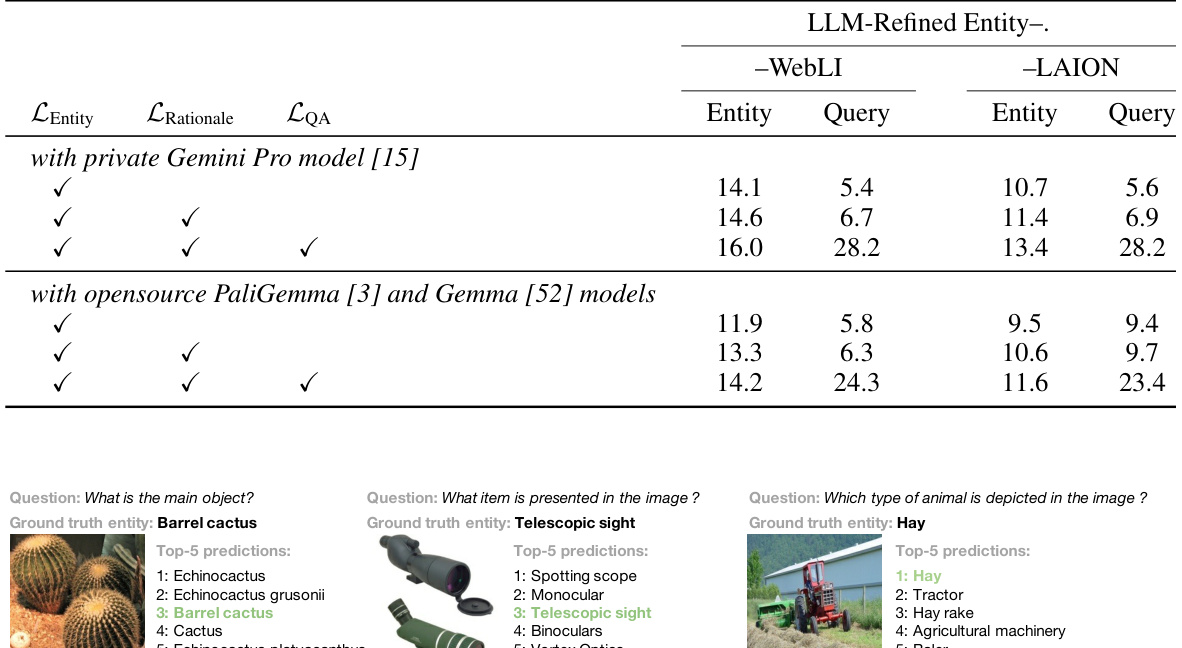
This table presents the results of an ablation study to investigate the impact of using a multimodal LLM to generate rationales and question-answer pairs for web-scale visual entity recognition. The left side shows the impact of different metadata provided to the LLM during rationale and QA generation on the OVEN validation set performance. The right side demonstrates the robustness of multi-task training with the generated data by comparing results using two different base image-caption datasets, WebLI and LAION, showing consistent improvements when including rationales and QAs in the training.

This table compares the performance of models trained on different datasets using two open-source LLMs, PaliGemma and Gemma, against the state-of-the-art results. It showcases the impact of using the LLM-refined datasets (REW) on model performance in the entity and query split of the OVEN benchmark.
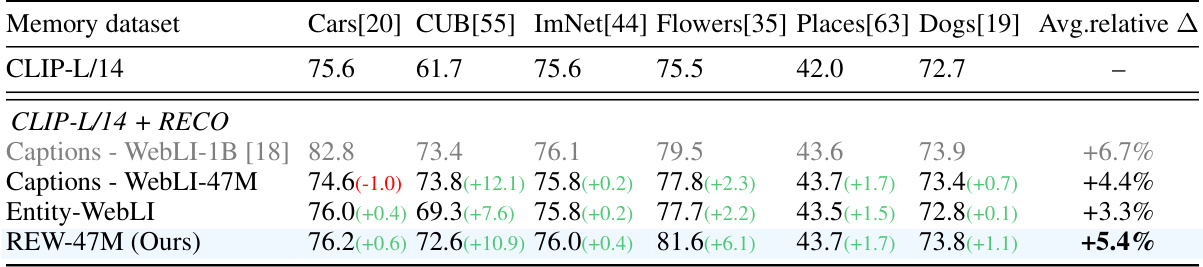
This table compares the performance of Retrieval-enhanced contrastive training (RECO) using three different types of annotations for the memory database: original captions, candidate entities from Entity-WebLI, and corrected entities from the proposed REW dataset. The table shows top-1 accuracy on six fine-grained image classification datasets (Cars, CUB, ImNet, Flowers, Places, Dogs). Absolute and relative improvements over a CLIP-L/14 baseline are reported, along with a comparison to previous RECO results using a much larger memory database.

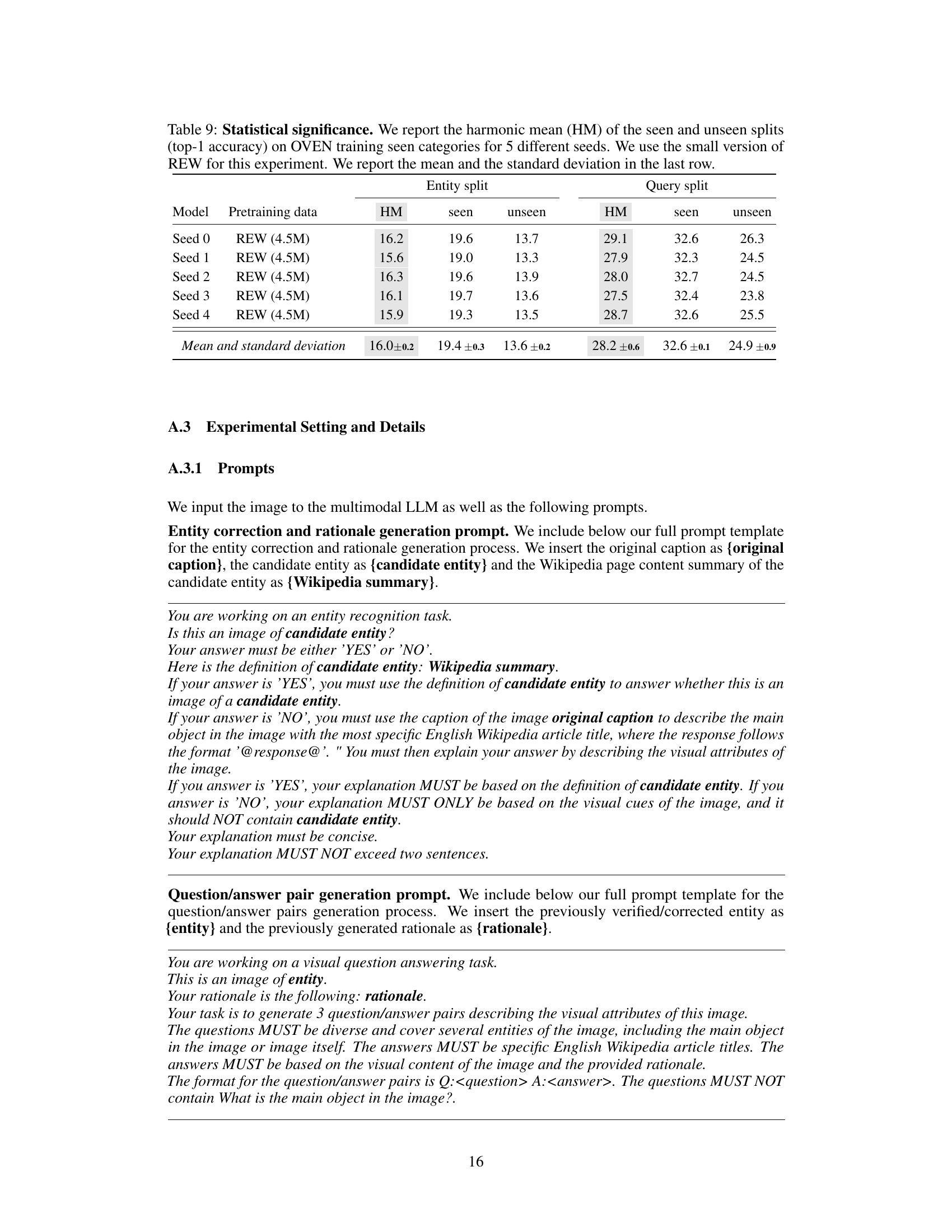
This table shows the statistical significance of the experiments by running the model training five times with different random seeds. The table reports the harmonic mean (HM) of top-1 accuracy on the OVEN training seen categories for both the entity and query splits, showing the mean and standard deviation of the results.
Full paper#