TL;DR#
Large pre-trained vision models, especially Vision Transformers (ViTs), often make errors, particularly when encountering images from underrepresented groups. Correcting these errors without extensive retraining is challenging because randomly adjusting model parameters can have unintended consequences and hurt generalization to similar, but unseen, images. Existing model-editing methods designed for natural language models don’t readily translate to the challenges of computer vision.
This paper introduces a novel method that tackles these challenges. It uses a locate-then-edit approach, where a hypernetwork first identifies the specific model parameters that need adjusting for a given error. This is achieved through meta-learning on CutMix-augmented data, creating pseudo-samples representing variations in image content to improve generalization. Then, it selectively fine-tunes those identified parameters. Experiments on a newly created benchmark show that this method performs better than existing techniques at making targeted edits with minimal impact on other parts of the model, thus demonstrating the improved reliability, generalization and locality of this method.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel model editing method for Vision Transformers (ViTs), a crucial area in computer vision that has seen limited exploration. It addresses the challenges of data efficiency and unintended side effects in model editing by using meta-learning to strategically identify and update parameters. This work provides valuable resources for future research, such as a novel editing benchmark and a more effective approach for editing pre-trained models. The framework enables superior performance while allowing for flexibility in balancing generalization and locality, thereby advancing the broader field of model editing and computer vision.
Visual Insights#

🔼 The figure illustrates the proposed model editing method for Vision Transformers (ViTs). It shows the workflow of locate-then-edit approach. First, the where-to-edit challenge is addressed by meta-learning a hypernetwork on CutMix-augmented data. This hypernetwork generates binary masks which identify a sparse subset of structured model parameters. Then, the how-to-edit problem is solved by fine-tuning the identified parameters using gradient descent. The ViT is used as a feature extractor and a base model. The hypernetwork takes the output of the ViT’s classification head as input and generates the binary mask. The binary mask is then used to select the parameters that will be fine-tuned. The fine-tuned parameters are then used to update the base model.
read the caption
Figure 1: System diagram of the proposed model editing method.
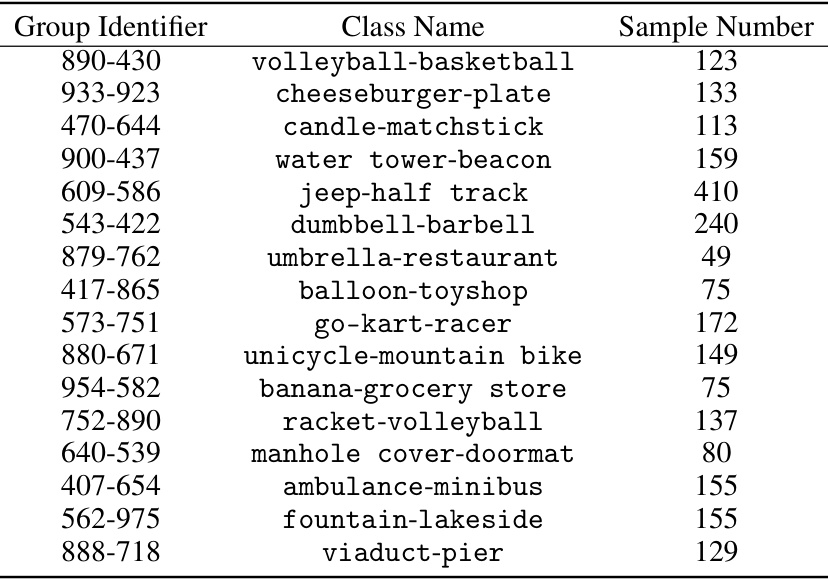
🔼 This table presents statistics for a subset of natural images used in the editing benchmark. Each row represents a group of images categorized based on predictions from two different ViT models (a stronger and a base model). The ‘Group Identifier’ column uses ImageNet-1k category indices. The ‘Class Name’ column shows the prediction of the stronger model first, then the prediction of the base model, separated by a hyphen. The ‘Sample Number’ column indicates the quantity of images within that group.
read the caption
Table A: Statistics of the natural image subset. The first column lists identifiers for each object category in ImageNet-1k. The “Class Name” in the second column is in the format as “prediction by the stronger model”-“prediction by the base model.”
In-depth insights#
Vision Transformer Edit#
Vision Transformer (ViT) editing presents a unique challenge in adapting model editing techniques from Natural Language Processing (NLP) to Computer Vision (CV). Unlike the one-dimensional, discrete data of NLP, ViTs handle high-dimensional, continuous data, requiring spatially aware edits. Moreover, the bidirectional attention mechanism of ViTs differs from the unidirectional attention in many NLP models. A locate-then-edit approach is crucial; meta-learning a hypernetwork to identify parameters responsive to specific failures is key. This hypernetwork learns to generate binary masks pinpointing the optimal subset of parameters to modify, balancing generalization and locality for data-efficient correction. This approach is especially powerful for handling subpopulation shifts where conventional methods might struggle. The method also highlights the need for a robust CV benchmark specifically designed for evaluating model editing techniques, enabling a better understanding of their effectiveness in correcting predictive errors in ViTs.
Meta-Learning Masks#
The concept of ‘Meta-Learning Masks’ suggests a powerful approach to model editing, especially within the context of large vision transformers. It implies a two-stage process: first, meta-learning a hypernetwork to generate masks identifying crucial model parameters; second, using these masks to guide targeted updates. The hypernetwork learns to identify parameters based on a training set of CutMix-augmented data, simulating real-world failures. This approach’s strength lies in its data efficiency and generalization capabilities, addressing the challenge of editing large models while ensuring that changes generalize to similar, unseen inputs. Sparsity constraints are likely incorporated to ensure locality and prevent unintended side effects elsewhere in the model. The effectiveness of this method would be strongly tied to the hypernetwork’s ability to learn generalizable and sparse masks from the augmented training data, as well as the selection of an appropriate editing strategy for the identified parameters. The proposed framework would be particularly useful in domains with limited data, or where retraining is expensive or impractical. A key consideration would be its performance trade-off between generalization, locality and reliability. The success of meta-learning would hinge on the representational capacity of the hypernetwork and the quality of the CutMix augmented data.
Benchmarking ViTs#
Benchmarking Vision Transformers (ViTs) requires a multifaceted approach. A robust benchmark needs to evaluate performance across diverse datasets, encompassing variations in image style, resolution, and object complexity. Subpopulation shift is crucial, testing the model’s ability to generalize beyond the training distribution. Furthermore, metrics beyond standard accuracy should be considered, including robustness to adversarial attacks, efficiency (inference speed and memory usage), and fairness (performance across different demographics within the datasets). The benchmark should also explicitly define evaluation protocols including data splits, preprocessing methods, and hyperparameter settings to ensure reproducibility. Finally, a good benchmark should provide a standard evaluation framework, enabling researchers to easily compare the performance of different ViTs and other vision models. This allows the community to track progress, identify areas for improvement, and ultimately accelerate the advancement of ViT technology.
Localised Editing#
Localised editing in machine learning models focuses on making targeted changes to a model’s parameters to correct specific errors without affecting its performance on unrelated tasks. This is crucial for maintaining model robustness and generalization ability, and it differs significantly from techniques that broadly retrain the entire model. The primary challenge lies in identifying the minimal set of parameters requiring modification, thus localizing the impact of the edit. Effective methods often involve sophisticated techniques like meta-learning or attention mechanisms to pinpoint the relevant parameters, possibly using a sparsity constraint to ensure minimal interference. While data-efficient, localized editing also requires careful consideration of generalization to similar, yet unseen data; therefore, robust evaluation strategies that measure both accuracy and locality of edits are essential. Success in localized editing offers data-efficient model updates, enhances interpretability by shedding light on specific model components responsible for errors, and improves the robustness of large models to unexpected inputs. However, finding optimal parameters and evaluating the tradeoff between localization and generalization remains an active area of research.
Future of ViT Edits#
The future of Vision Transformer (ViT) editing holds immense potential. Current methods, while showing promise, are limited by data requirements and computational costs. Future research should focus on developing more efficient and data-agnostic techniques, such as exploring novel meta-learning architectures and leveraging self-supervised learning strategies. Addressing the generalization and locality challenges remains crucial; new approaches might incorporate advanced regularization techniques or develop more sophisticated ways to identify and manipulate relevant parameters. Incorporating uncertainty estimation could also significantly improve the reliability and safety of ViT edits. Finally, the application of ViT editing to new computer vision tasks, such as video editing and 3D scene understanding, and integration with other emerging models promises to unlock novel capabilities and further expand the scope of this field.
More visual insights#
More on figures

🔼 This figure shows a detailed flowchart of the proposed model editing method. It illustrates the process of using a hypernetwork trained on CutMix-augmented data to generate binary masks indicating which parameters in the Vision Transformer (ViT) should be modified. The system uses a locate-then-edit approach; the hypernetwork identifies the location (‘where’) and then simple fine-tuning adjusts the identified parameters (‘how’). The resulting edited ViT model is expected to improve prediction accuracy while maintaining generalization and locality.
read the caption
Figure 1: System diagram of the proposed model editing method.

🔼 This figure shows the results of editing experiments conducted to determine the optimal location for editing within the ViT model. The left side displays examples of the model’s errors in classifying images, particularly confusing volleyball and basketball. The right side presents a Pareto-optimal curve. This curve illustrates the trade-off between the generalization ability of the model (ability to correctly classify similar images after editing) and locality (how much the edits affect unrelated parts of the model). The results suggest that editing the 8th to 10th feed-forward networks (FFNs) offers the best balance between these two objectives.
read the caption
Figure 2: The left subfigure shows representative editing examples, highlighting the predictive errors of the base ViT when predicting volleyball as basketball. The right subfigure depicts the generalization and locality trade-offs when editing different groups of FFNs or MSAs in the base ViT. It is evident that editing the 8-th to 10-th FFNs achieves the optimal Pareto front.

🔼 This figure shows examples of images used during pre-training and those misclassified by the base ViT model in the proposed editing benchmark. The pre-training examples show volleyball and basketball players, and shovels and paddles. The misclassified examples from the benchmark show instances where the ViT model incorrectly classified volleyball as basketball and shovels as paddles. This highlights the subpopulation shifts introduced in the benchmark, showcasing where the pre-trained model fails.
read the caption
Figure 3: Visual examples seen by the base ViT/B-16 during pre-training, contrasted with visual examples in the proposed editing benchmark as predictive errors of the base ViT/B-16.

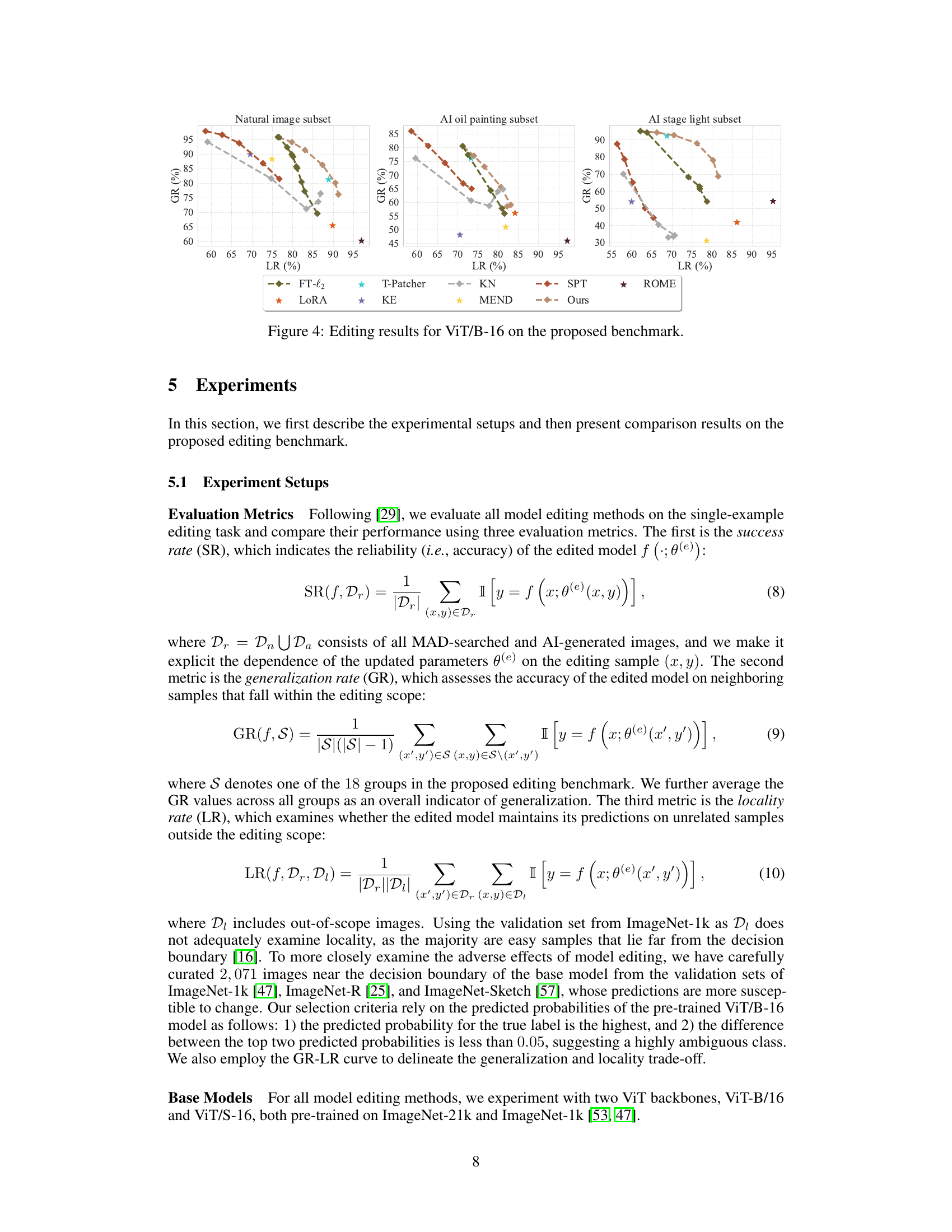
🔼 This figure presents the Pareto front between generalization and locality achieved by different model editing methods on the proposed benchmark using ViT-B-16. The x-axis represents the locality rate (LR), and the y-axis represents the generalization rate (GR). Each curve represents a different method, showing the trade-off between generalization and locality. The proposed method achieves the best Pareto front, indicating superior performance in both generalization and locality compared to other methods.
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.

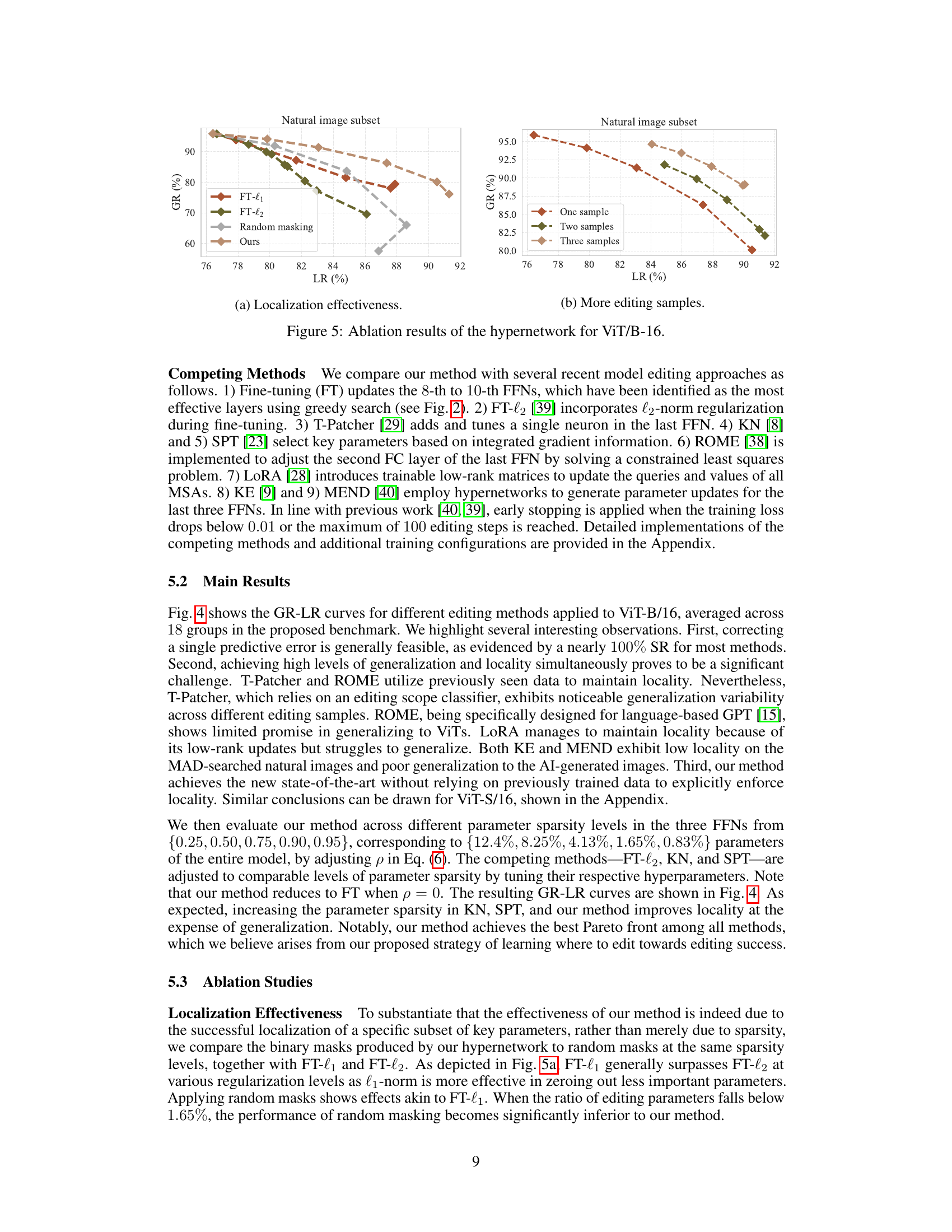
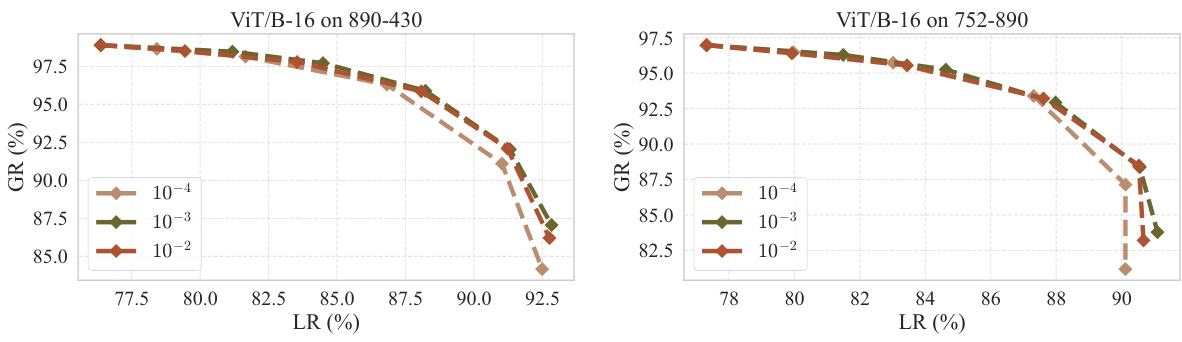
🔼 This figure demonstrates the ablation study on the hypernetwork for ViT/B-16. Specifically, it compares the performance of the proposed method against fine-tuning with L1 and L2 regularization, and random masking, all at various sparsity levels. It shows that the proposed method achieves significantly better results than random masking, particularly at lower sparsity levels, indicating the importance of effective parameter localization. The second graph shows the effect of using multiple samples for editing.
read the caption
Figure 5: Ablation results of the hypernetwork for ViT/B-16.

🔼 This figure shows a flowchart of the model editing process. It starts with CutMix data augmentation, which generates pseudo-samples for training a hypernetwork. The hypernetwork meta-learns to generate binary masks that identify a sparse subset of structured model parameters, responsive to real-world failure samples. Then, the identified parameters are fine-tuned using gradient descent to achieve successful edits. The process is composed of two phases: ‘where-to-edit’ and ‘how-to-edit’, where the ‘where-to-edit’ phase is focused on using a hypernetwork to learn to select important parameters and ‘how-to-edit’ phase uses gradient descent to fine-tune these parameters.
read the caption
Figure 1: System diagram of the proposed model editing method.

🔼 This figure shows the specificity of the parameters identified by the hypernetwork for different editing samples. It visualizes the Intersection over Union (IoU) of the corresponding binary masks at the 0.95 sparsity level for samples within and outside the same groups in the natural image subset. High IoU values within the same group indicate that the hypernetwork identifies parameters relevant to specific error corrections, while low IoU values between groups demonstrate its ability to avoid affecting unrelated parts of the model. This effectively balances generalization and locality.
read the caption
Figure 6: Mask specificity results.

🔼 This figure shows visual examples of the natural image subset used in the editing benchmark. The images are grouped by the prediction discrepancies of two different classifiers. Each group shows images where the base ViT model (Vision Transformer) makes errors, categorized by the stronger model’s prediction and the base ViT’s incorrect prediction. This illustrates the types of subpopulation shifts used to create the benchmark. Part 1 of 2.
read the caption
Figure A: Visual examples in each group of the natural image subset. Part 1/2.

🔼 This figure shows a comparison of images used for pre-training the ViT model versus examples where the model failed in the proposed editing benchmark. The pre-training images show diverse, well-represented object categories, while the benchmark images highlight subpopulation shifts (underrepresented natural images and AI-generated images) that cause the pre-trained model to make incorrect predictions. This demonstrates the limitations of pre-trained ViTs and motivates the need for the model editing technique proposed in the paper.
read the caption
Figure 3: Visual examples seen by the base ViT/B-16 during pre-training, contrasted with visual examples in the proposed editing benchmark as predictive errors of the base ViT/B-16.

🔼 This figure shows visual examples of images generated by an AI model with an oil painting style. The images are part of the AI-generated image subset in the editing benchmark, used to test the model’s ability to generalize to this specific style. Each image displays four versions, showing variations within the same class.
read the caption
Figure C: Visual examples of the AI-generated oil painting images.

🔼 This figure shows visual examples of AI-generated images with a lighting condition shift (i.e., stage light) produced by PUG. The lighting condition shift is one of the subpopulation shifts in the editing benchmark for pre-trained vision transformers proposed in the paper. The images are generated by text-to-image generative models and used to reveal the limitations of pre-trained ViTs for object recognition.
read the caption
Figure D: Visual examples of the AI-generated stage light images.

🔼 This figure shows a detailed illustration of the proposed model editing method, which is broken down into two subproblems: where-to-edit and how-to-edit. The diagram illustrates the workflow, starting with CutMix augmentation on input images, and proceeding through the hypernetwork, feature extraction with ViT, the inner-loop optimization, the outer-loop optimization, a binarization step, and finally, the classification head. The parameters identified by the hypernetwork and updated in the model are clearly highlighted in the diagram.
read the caption
Figure 1: System diagram of the proposed model editing method.
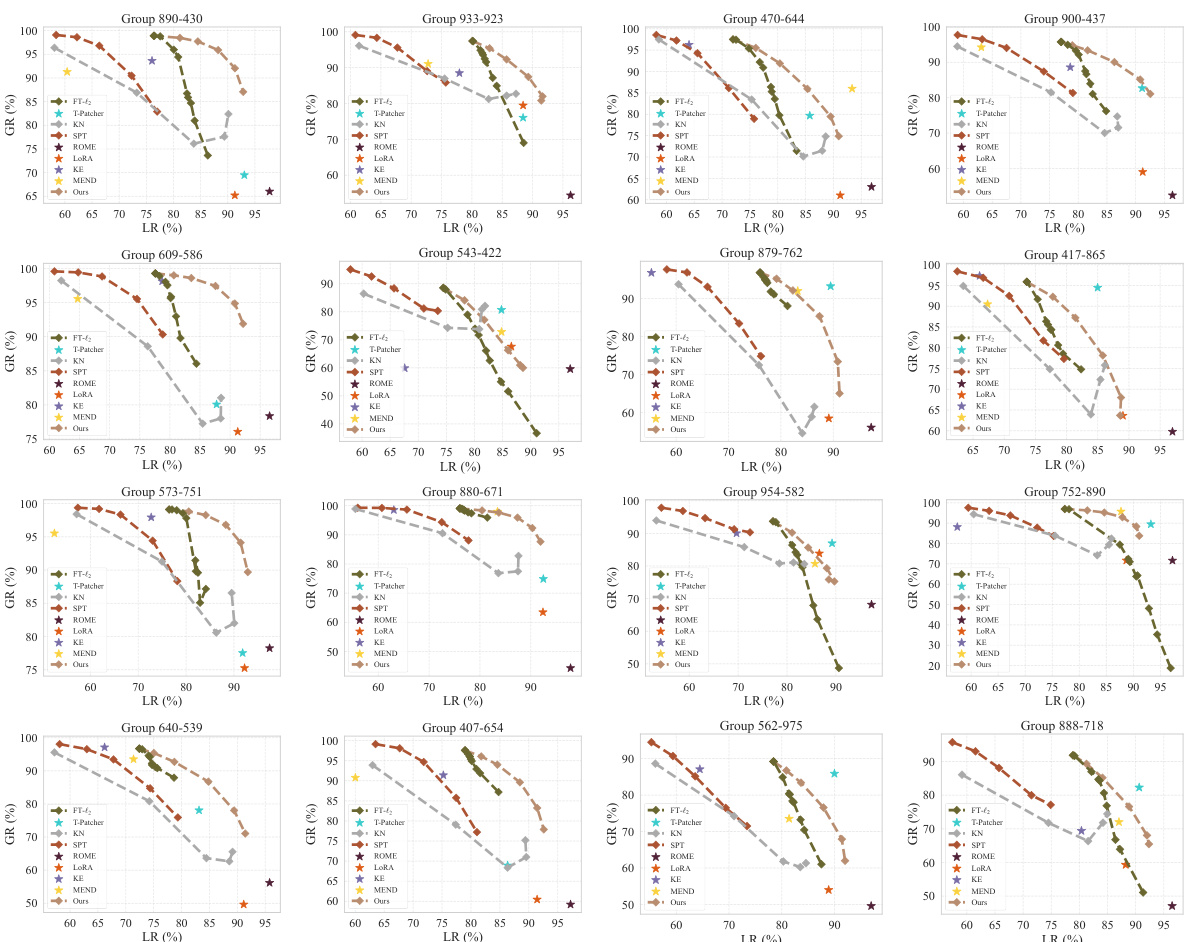
🔼 This figure displays the Pareto front between generalization and locality achieved by different model editing methods applied to the Vision Transformer (ViT/B-16) on the proposed benchmark. The benchmark comprises subpopulation shifts towards natural underrepresented images and AI-generated images. The results showcase the superior performance of the proposed method, achieving the best trade-off between generalization (extending edits to similar samples) and locality (minimizing unintended effects on unrelated samples).
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.

🔼 This figure presents the generalization-locality trade-off of various model editing methods applied to Vision Transformer (ViT) model ViT/B-16. The x-axis represents the locality rate (LR), indicating the model’s performance on unrelated samples after editing, and the y-axis shows the generalization rate (GR), assessing the model’s performance on neighboring samples. Each curve represents a different model editing method, highlighting the balance they achieve between generalization and locality. The Pareto front illustrates the best trade-off between these two criteria. The results are obtained from a proposed benchmark that evaluates editing performance on two subpopulation shifts: natural underrepresented images and AI-generated images.
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.
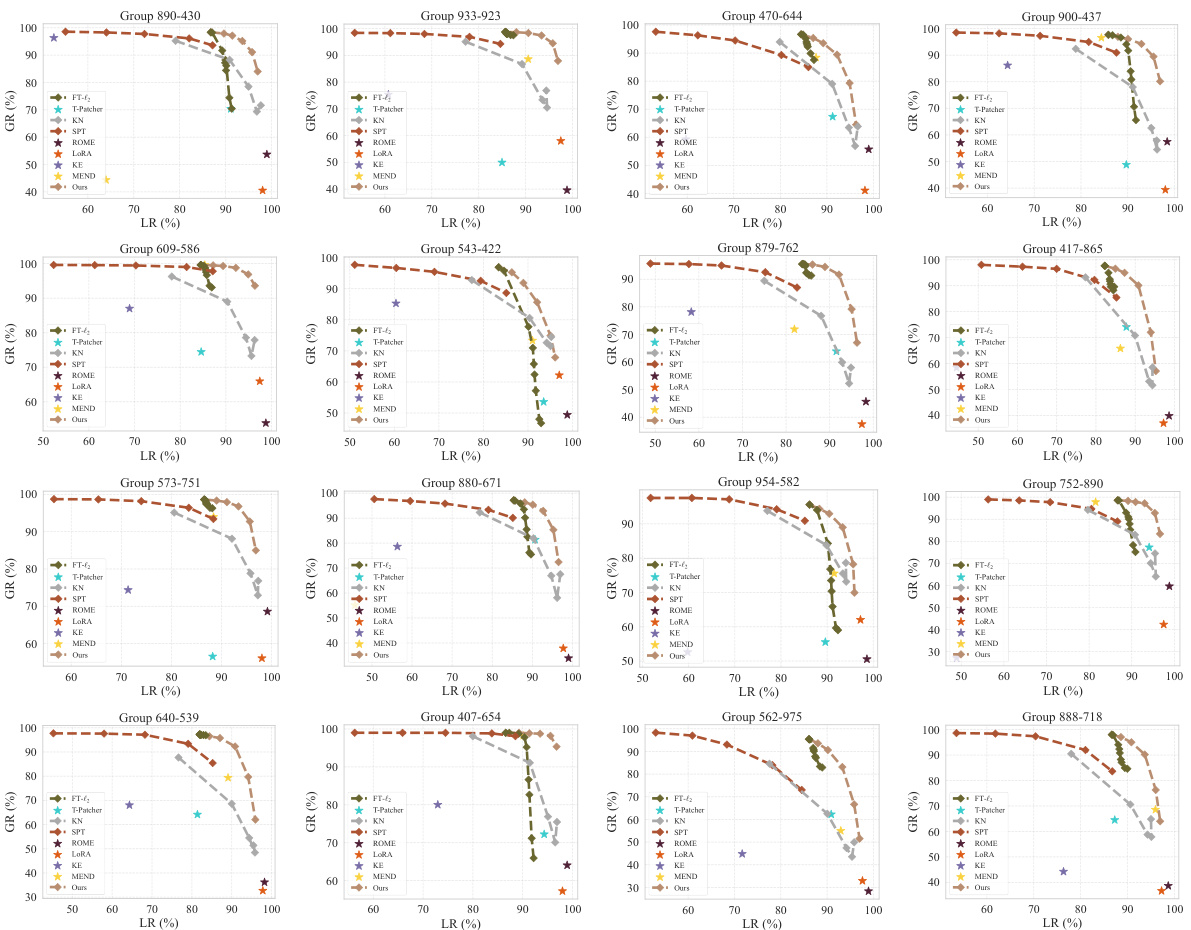
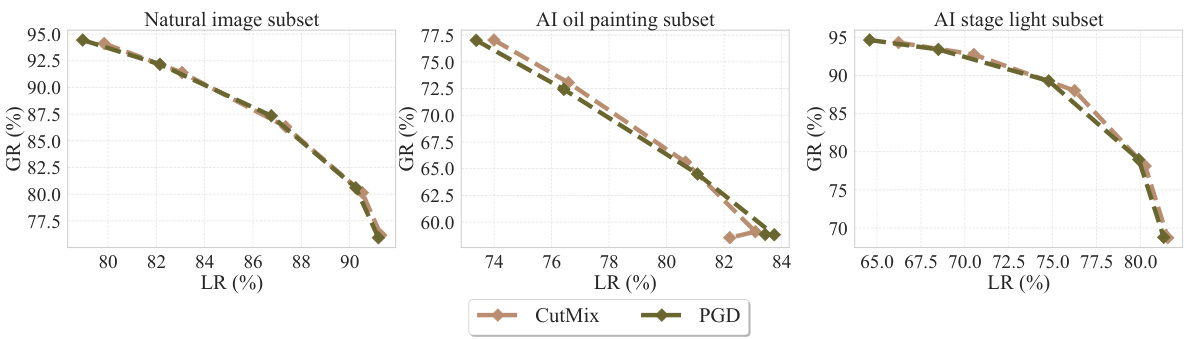
🔼 This figure presents the generalization-locality trade-off curves for various model editing methods applied to the ViT-B/16 model on the proposed benchmark. The benchmark evaluates performance on three subsets: natural images, AI-generated oil paintings, and AI-generated images with stage lighting. The curves show the relationship between generalization rate (GR) and locality rate (LR) for each method, illustrating the balance between editing successfully to neighboring samples and minimizing unwanted impact on other samples. The results highlight that the proposed method achieves the best Pareto front (optimal balance between generalization and locality).
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.

🔼 The figure shows the training curves of the hypernetwork, plotting the mask sparsity and the outer-loop KL divergence against the number of iterations. It illustrates how the mask sparsity increases rapidly at the beginning of training before stabilizing, while the outer-loop KL divergence decreases, suggesting that the hypernetwork effectively learns to locate key parameters for successful edits.
read the caption
Figure H: Training curves of the hypernetwork.
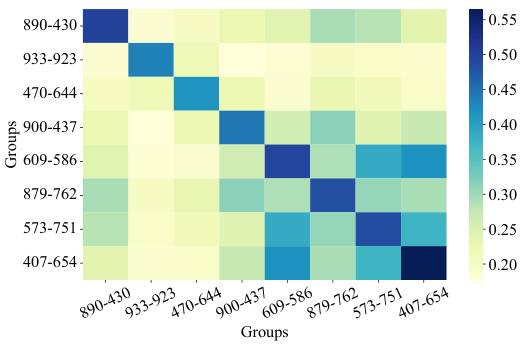
🔼 This figure demonstrates the specificity of the parameters identified by the hypernetwork for different editing samples. (a) shows six representative editing examples from three different groups. (b) shows the Intersection over Union (IoU) of the corresponding binary masks at the 0.95 sparsity level for samples within and outside the same groups in the natural image subset. The higher IoU values within groups indicate that the hypernetwork successfully identifies key parameters needed to correct specific errors, while excluding parameters related to unrelated samples. This demonstrates that the method effectively balances generalization and locality.
read the caption
Figure 6: Mask specificity results.
🔼 This figure shows the Pareto front between generalization and locality achieved by different model editing methods on the proposed benchmark using ViT-B-16. The x-axis represents the locality rate (LR), and the y-axis represents the generalization rate (GR). Each curve represents a different method, with the proposed method achieving the best Pareto front.
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.

🔼 This figure shows the ablation study results on the hypernetwork for ViT-B-16. It compares the performance of the proposed method with random masking, one-sample, two-samples, and three-samples editing. The left graph (a) shows the localization effectiveness, which compares the generalization (GR) and locality (LR) of the different methods. The right graph (b) shows how the performance changes with more editing samples.
read the caption
Figure 5: Ablation results of the hypernetwork for ViT/B-16.

🔼 The figure shows the generalization (GR) and locality (LR) trade-off curves for different model editing methods applied to ViT/S-16. It demonstrates the performance of various methods on the three subsets of the proposed editing benchmark: natural image subset, AI oil painting subset, and AI stage light subset. The results show that the proposed method achieves the best Pareto front between generalization and locality, outperforming other existing methods.
read the caption
Figure F: Editing results for ViT/S-16 on the proposed benchmark.
🔼 This figure shows the Pareto front between generalization and locality for different model editing methods applied to ViT/B-16 on the proposed benchmark. Each curve represents a different method, and the x-axis represents the locality rate (LR), while the y-axis represents the generalization rate (GR). The Pareto front is the set of points such that no other point has a better generalization rate and locality rate simultaneously. The figure shows that the proposed method achieves the best Pareto front among all methods, indicating that it achieves the best trade-off between generalization and locality.
read the caption
Figure 4: Editing results for ViT/B-16 on the proposed benchmark.
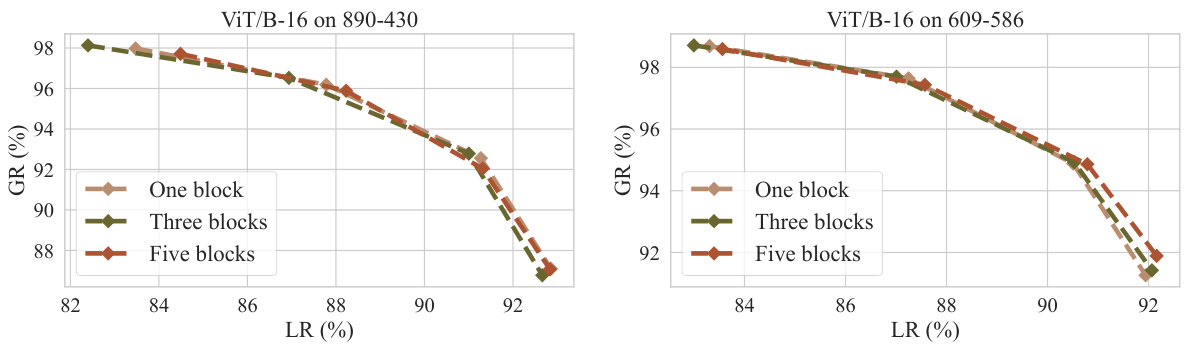
🔼 This figure shows the ablation study on the hypernetwork’s performance by comparing the generalization and locality trade-offs when using the proposed method against using random masking and different numbers of training samples. The results highlight the importance of the learned hypernetwork in achieving a good balance between generalization and locality in model editing for Vision Transformers.
read the caption
Figure 5: Ablation results of the hypernetwork for ViT/B-16.
Full paper#