↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current multimodal large language models (MLLMs) excel at answering questions but struggle with asking insightful questions and assessing the accuracy of answers. This is a significant limitation, as these abilities are crucial for comprehensive understanding and learning. The existing VQA datasets mainly focus on the answering aspect, neglecting the potential of incorporating question-asking and assessment into the training process.
To overcome this, the researchers developed LOVA³, a framework that introduces two new training tasks: GenQA (question generation) and EvalQA (answer evaluation). GenQA uses various datasets to train the model to generate diverse question-answer pairs from images, while EvalQA introduces a new benchmark, EvalQABench, with 64,000 training samples and 5,000 testing samples to evaluate the ability of the model to assess question-answer correctness. The results demonstrate consistent performance gains across various datasets, highlighting the importance of incorporating question asking and assessment into the training of MLLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of current multimodal large language models (MLLMs) by enhancing their abilities to ask and assess questions, leading to improved multimodal understanding and performance. This is highly relevant to the current trend of developing more comprehensive and intelligent MLLMs and introduces the novel EvalQABench benchmark, which opens new avenues for future research. The proposed LOVA³ framework provides a practical and effective method for training more robust and intelligent MLLMs.
Visual Insights#

This figure compares the performance of LLaVA1.5 and the proposed LOVA³ model on three key abilities: Visual Question Answering (VQA), Question Generation (GenQA), and Question Evaluation (EvalQA). It highlights that while LLaVA1.5 is strong at answering questions, it struggles with generating accurate questions and assessing the correctness of existing question-answer pairs. The example demonstrates LOVA³’s superior ability in these tasks.
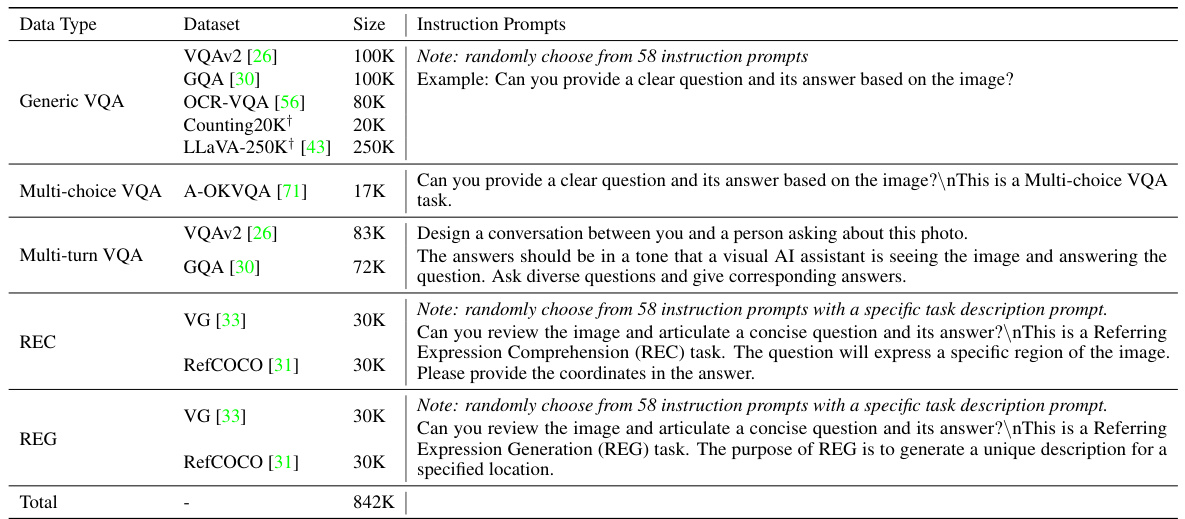
This table presents a breakdown of the datasets used for the GenQA task in the LOVA³ framework. It categorizes datasets based on their data type (Generic VQA, Multi-choice VQA, Multi-turn VQA, REC, REG), provides the dataset name and size, and includes example instruction prompts used for data generation. The table helps illustrate the diversity of data sources and task types incorporated into the GenQA training process to enhance the model’s ability to generate high-quality question-answer pairs from images.
In-depth insights#
Visual Questioning#
Visual Question Answering (VQA) research has primarily focused on the ability of models to answer questions about images. Visual Questioning, however, represents a significant advancement by shifting the focus to the generation of insightful questions about images. This capability is crucial for deeper multimodal understanding and more effective learning. By enabling models to ask relevant questions, we unlock the potential for more interactive and exploratory interactions with visual data. Effective visual questioning hinges on understanding the nuances of visual information and identifying knowledge gaps. This entails not just generating grammatically correct questions, but questions that are meaningful, diverse, and contextually appropriate. Furthermore, evaluating the quality of generated questions presents a significant challenge that requires the development of new metrics. Success in visual questioning would bridge the gap between passive information retrieval and active knowledge construction, transforming how we interact with and learn from images.
LOVA³ Framework#
The LOVA³ framework is a novel approach to enhance multimodal large language models (MLLMs) by incorporating question generation (GenQA) and question assessment (EvalQA) capabilities alongside traditional visual question answering (VQA). GenQA fosters the ability of the MLLM to generate diverse and informative question-answer pairs from a single image, promoting deeper multimodal understanding. This is achieved through a collection of multimodal foundational tasks, including VQAv2 and GQA. EvalQA introduces a new benchmark, EvalQABench, to evaluate the correctness of visual question-answer triplets, thereby improving the overall accuracy and robustness of the MLLM. The framework’s effectiveness is validated through experiments on various multimodal datasets, demonstrating consistent performance gains, showcasing the importance of these additional tasks for achieving comprehensive intelligence in MLLMs. The inclusion of GenQA and EvalQA tasks is pivotal, moving beyond traditional question answering towards a more holistic understanding of visual data, similar to human learning processes. The creation of EvalQABench addresses a crucial gap in existing benchmarks by focusing on the ability to evaluate the quality and correctness of VQA pairs, further highlighting the framework’s contribution to the field.
EvalQABench#
EvalQABench, as a proposed benchmark for evaluating visual question answering (VQA) models, addresses a critical gap in existing benchmarks by focusing on the assessment of question-answer pairs. Its innovative approach of using a multimodal model (Fuyu-8B) to automatically generate negative answers, combined with human refinement, is efficient and addresses the scarcity of suitable datasets. The inclusion of feedback alongside the “yes/no” correctness labels enhances learning and provides crucial insights. The detailed analysis of the benchmark, including distribution across question types and error analysis, ensures rigorous assessment. EvalQABench’s novel design pushes the boundaries of VQA evaluation, moving beyond simple accuracy metrics to a more comprehensive assessment of the model’s understanding. While relying on existing VQA datasets for ground truth data might introduce some bias, this limitation is acknowledged and the resulting benchmark is expected to contribute significantly to future VQA research.
Multimodal Gains#
The concept of “Multimodal Gains” in a research paper would explore how combining multiple modalities (like text, images, audio) improves performance over using a single modality. A thoughtful analysis would investigate specific gains observed—were there improvements in accuracy, efficiency, or robustness? What types of multimodal tasks benefited most? The discussion should delve into the underlying reasons for these gains. Does the fusion of information reduce ambiguity? Does it enable the model to learn more complex relationships or handle more nuanced inputs? A deeper dive might compare different multimodal fusion techniques to understand which strategies are most effective. Finally, it is crucial to consider the limitations and challenges of multimodal approaches. Does the increased complexity introduce new forms of error or bias? Are there computational costs associated with multimodal processing? A thorough investigation will showcase the benefits and challenges of multimodal integration.
Future Work#
Future research directions stemming from this work on LOVA3, a multimodal learning framework enhancing visual question answering, asking, and assessment, could explore several key areas. Expanding the scope of GenQA by incorporating more diverse question types and complex reasoning tasks is crucial. The current work focuses on improving the model’s ability to generate high-quality question-answer pairs, but future work should explore the development of more sophisticated question generation strategies that can adapt to specific contexts and user needs. Improving the robustness and scalability of EvalQABench is also essential. The current benchmark contains a limited number of samples, and its performance could be enhanced by employing more advanced algorithms for negative answer generation and error correction. Finally, and importantly, investigating the limitations of LOVA3 when handling text-centric VQA and mathematical problem-solving tasks is necessary. The existing datasets primarily focus on visual reasoning, leaving room for future exploration into training data that encompasses a wider range of cognitive abilities.
More visual insights#
More on figures

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three key abilities: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each ability, highlighting that LLaVA1.5 performs well on VQA but struggles with GenQA and EvalQA, while LOVA³ shows improved performance across all three tasks. This illustrates the need for enhancing MLLMs with the abilities to ask and assess questions, in addition to answering them.

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three key visual question answering tasks: answering, asking, and assessment. It demonstrates that while LLaVA1.5 performs well at answering questions given an image, it struggles significantly with generating accurate questions itself and evaluating the correctness of a question-answer pair. The LOVA³ model, in contrast, shows improvement in all three tasks, indicating that incorporating question generation and evaluation into the training process enhances the model’s overall multimodal understanding.

This figure compares the performance of LLaVA1.5 and the proposed LOVA³ model across three key abilities: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It showcases example prompts and responses for each ability, highlighting LLaVA1.5’s strong performance in VQA but its weaknesses in generating accurate and assessing the correctness of questions and answers. This demonstrates the need for enhanced multimodal understanding in LLMs to encompass these additional capabilities.
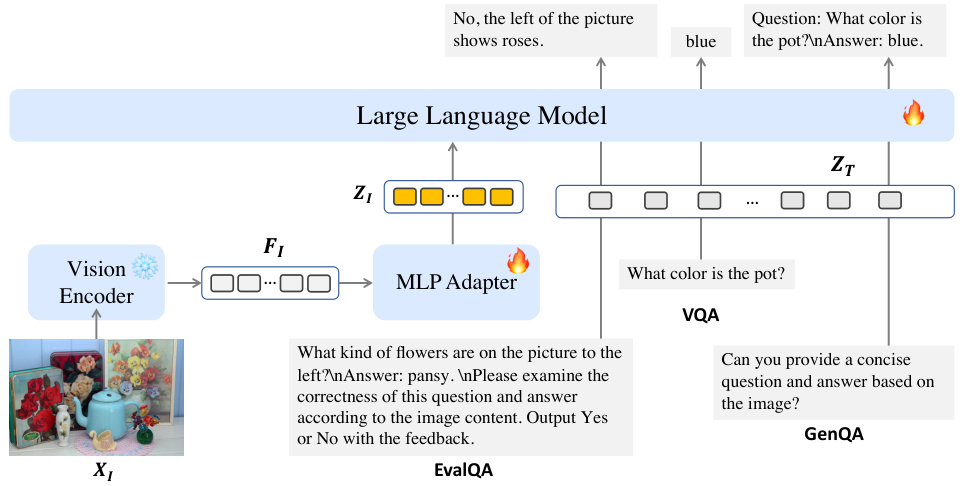
This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three different visual question answering (VQA) tasks: VQA ability (answering questions), GenQA ability (generating questions and answers), and EvalQA ability (evaluating the correctness of question-answer pairs). The results show that while LLaVA1.5 performs well on answering questions, it struggles significantly with generating accurate questions and evaluating the correctness of question-answer pairs. This highlights the importance of the additional questioning and assessment capabilities incorporated into the LOVA³ framework.

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three key tasks: Visual Question Answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each task, highlighting that LLaVA1.5 performs well at answering questions but struggles with generating appropriate and assessing questions and answers. The figure visually demonstrates the need for enhancing MLLMs with questioning and assessment capabilities, which is the core motivation behind the LOVA³ framework.

The figure compares the performance of LLaVA1.5 and the proposed LOVA³ model on three key abilities: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each ability, highlighting that LLaVA1.5, while strong at VQA, struggles with generating accurate questions and evaluating the correctness of question-answer pairs. This demonstrates the need for enhancing MLLMs with the additional capabilities of question generation and assessment.

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three different tasks related to visual question answering: answering, asking, and evaluating. It shows example questions and answers for each task for both models. The results indicate that while LLaVA1.5 performs well at answering questions, it struggles with generating accurate questions and evaluating the correctness of question-answer pairs, highlighting the benefits of the LOVA³ framework.

This figure compares the performance of LLaVA1.5 and the proposed LOVA³ model across three key abilities related to visual question answering: answering questions, generating questions, and evaluating question-answer pairs. It demonstrates that while LLaVA1.5 performs well on answering questions, it is significantly less capable of generating accurate questions and assessing the correctness of provided answers. LOVA³ outperforms LLaVA1.5 on the latter two tasks.
This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three different tasks related to visual question answering: answering questions, generating questions, and evaluating question-answer pairs. The results show that LLaVA1.5 performs well on answering questions, but struggles with question generation and evaluation. Conversely, LOVA³ demonstrates improved performance on all three tasks, indicating the benefits of its approach that incorporates question generation and evaluation into the training process.

The figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three tasks: Visual Question Answering (VQA), Question Generation (GenQA), and Question Assessment (EvalQA). It shows example prompts and responses for each task, highlighting the strengths of LOVA³ in generating accurate questions and evaluating question-answer pairs, whereas LLaVA1.5 primarily excels at answering questions. This demonstrates the value of incorporating question generation and assessment into the multimodal learning process.

The figure compares the performance of LLaVA1.5 and the proposed LOVA³ model on three tasks: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each task, highlighting that while LLaVA1.5 is strong at answering questions, it struggles with generating accurate and relevant questions and assessing the correctness of question-answer pairs. This demonstrates the need for the additional capabilities provided by the LOVA³ framework.

The figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three visual question answering tasks: VQA (answering questions), GenQA (generating questions and answers), and EvalQA (evaluating question-answer pairs). It shows that while LLaVA1.5 performs well on the VQA task, it struggles significantly with the GenQA and EvalQA tasks. This highlights the importance of the additional tasks introduced by LOVA³ in improving comprehensive intelligence in MLLMs.

This figure compares the performance of three abilities (VQA, GenQA, and EvalQA) between LLaVA1.5 and the proposed LOVA³ model. It highlights LLaVA1.5’s strength in answering questions (VQA) while demonstrating its weakness in generating accurate questions (GenQA) and evaluating question-answer pairs (EvalQA). The figure uses a simple example image of donuts and shows how each model responds to different prompts related to answering, asking, and evaluating visual questions. The results visually underscore the need for enhancing MLLMs with questioning and assessment skills, a key motivation for developing LOVA³.

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three tasks: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each task, highlighting that LLaVA1.5 is strong at VQA but weaker at generating and evaluating questions. This illustrates the need for the LOVA³ framework, which aims to improve MLLMs’ abilities in all three areas.

The figure shows a comparison of three abilities (VQA, GenQA, and EvalQA) between the LLaVA1.5 model and the proposed LOVA³ model. It highlights that while LLaVA1.5 performs well on visual question answering (VQA), it struggles with generating accurate questions (GenQA) and evaluating the correctness of question-answer pairs (EvalQA). This illustrates the need for the LOVA³ framework, which aims to improve these additional capabilities of multimodal language models.

The figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three visual question answering tasks: answering, asking, and assessment. For each task, a prompt is given, along with the model’s response and the ground truth. The results show that LLaVA1.5 is good at answering but struggles with generating accurate questions or evaluating the correctness of question-answer pairs. In contrast, LOVA³ performs well on all three tasks.

The figure compares the performance of three abilities (VQA, GenQA, and EvalQA) between LLaVA1.5 and the proposed LOVA³. It shows example prompts and responses for each ability. The goal is to highlight that LLaVA1.5, while strong at answering visual questions, performs poorly when it comes to generating its own questions or evaluating the accuracy of existing question-answer pairs. LOVA³ is presented as a superior alternative capable of handling all three tasks effectively.

The figure compares the performance of LLaVA1.5 and the proposed LOVA³ model on three tasks: Visual Question Answering (VQA), Question Generation (GenQA), and Question Assessment (EvalQA). For each task, an example prompt and the model’s response are given, along with the ground truth. The comparison highlights that while LLaVA1.5 performs well on VQA, it struggles to produce accurate questions and assess the correctness of question-answer pairs, demonstrating the need for the additional capabilities provided by the LOVA³ framework.

The figure shows a comparison of three abilities (VQA, GenQA, and EvalQA) between LLaVA1.5 and the proposed LOVA³. It highlights that while LLaVA1.5 performs well on visual question answering (VQA), it struggles with generating accurate questions (GenQA) and evaluating the correctness of question-answer pairs (EvalQA). This illustrates the need for a more comprehensive approach that incorporates question asking and assessment skills, which is the focus of the LOVA³ framework.

This figure compares the performance of the LLaVA1.5 model and the proposed LOVA³ model on three tasks: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). The image shows example prompts and responses for each task for both models. It highlights LLaVA1.5’s strength in answering questions, but its weakness in asking and evaluating questions. This demonstrates the value of the additional question asking and assessment capabilities added by the LOVA³ framework.

The figure compares the performance of LLaVA1.5 and the proposed LOVA³ model across three key abilities: visual question answering (VQA), question generation (GenQA), and question assessment (EvalQA). It shows example prompts and responses for each ability, highlighting LLaVA1.5’s strength in answering questions but its weakness in generating and evaluating questions based on image content. This demonstrates the need for enhancing MLLMs with the capabilities to ask and assess questions in addition to answering them.
More on tables
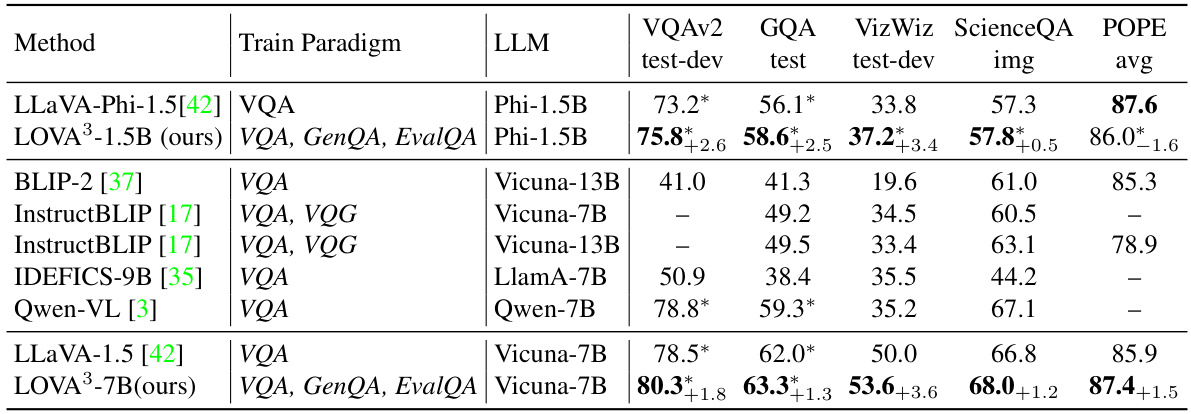
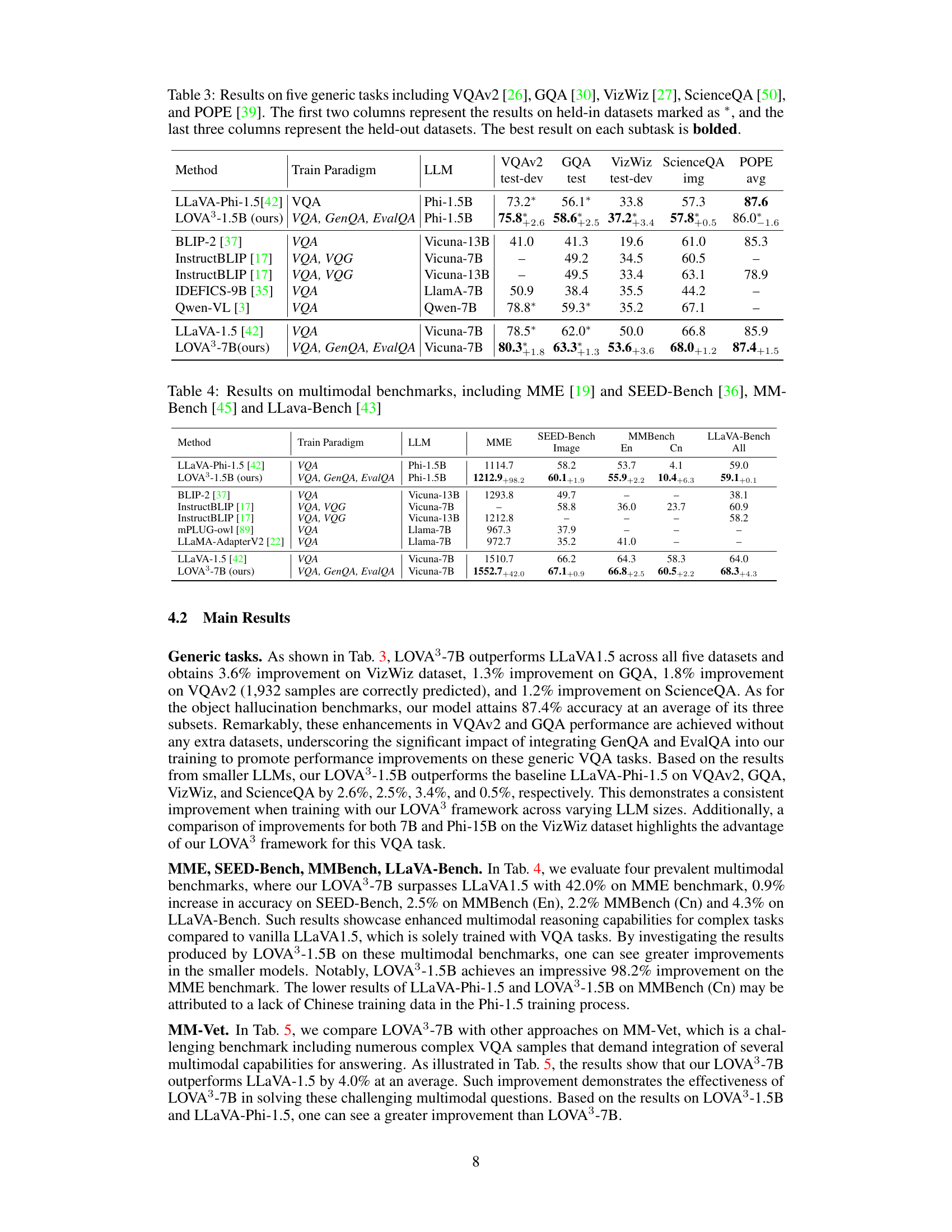
This table presents the results of five generic visual question answering (VQA) tasks comparing the performance of LOVA3 and other state-of-the-art models. The tasks include VQAv2, GQA, VizWiz, ScienceQA, and POPE, each with different characteristics and difficulty levels. The table shows that LOVA3 consistently outperforms other models across all five datasets, demonstrating its effectiveness.
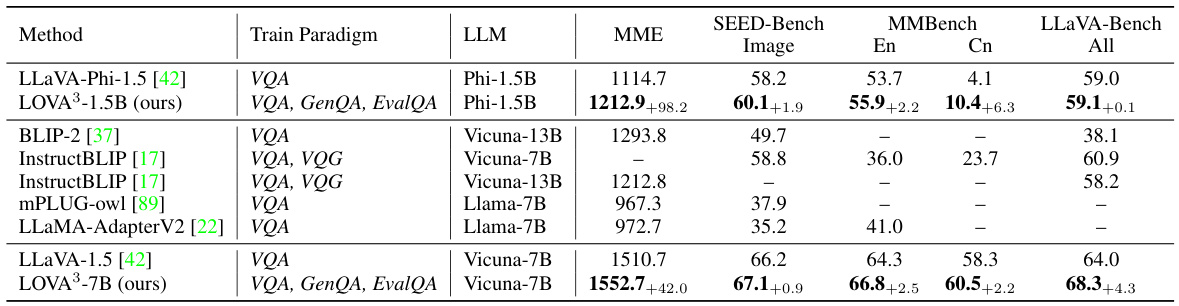
This table presents the results of the LOVA³ model and other state-of-the-art (SOTA) models on four widely used multimodal benchmarks: MME, SEED-Bench, MMBench, and LLaVA-Bench. The table shows the performance of each model on various subtasks within each benchmark, allowing for a comparison of their overall multimodal reasoning capabilities. The inclusion of LOVA³’s results highlights the impact of the proposed training framework on various multimodal reasoning tasks.
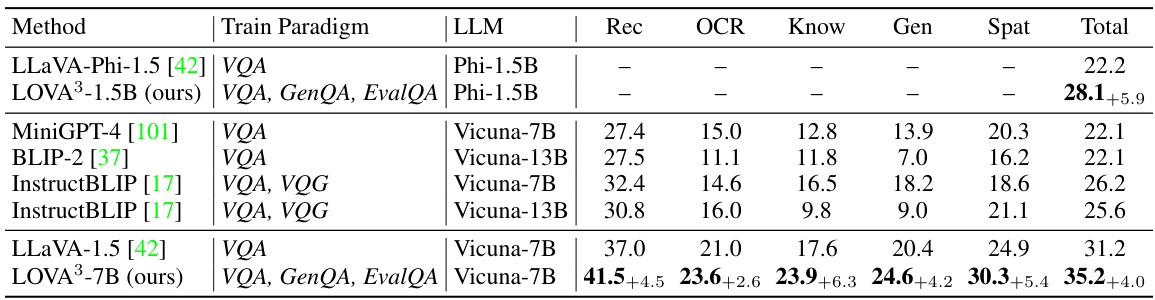
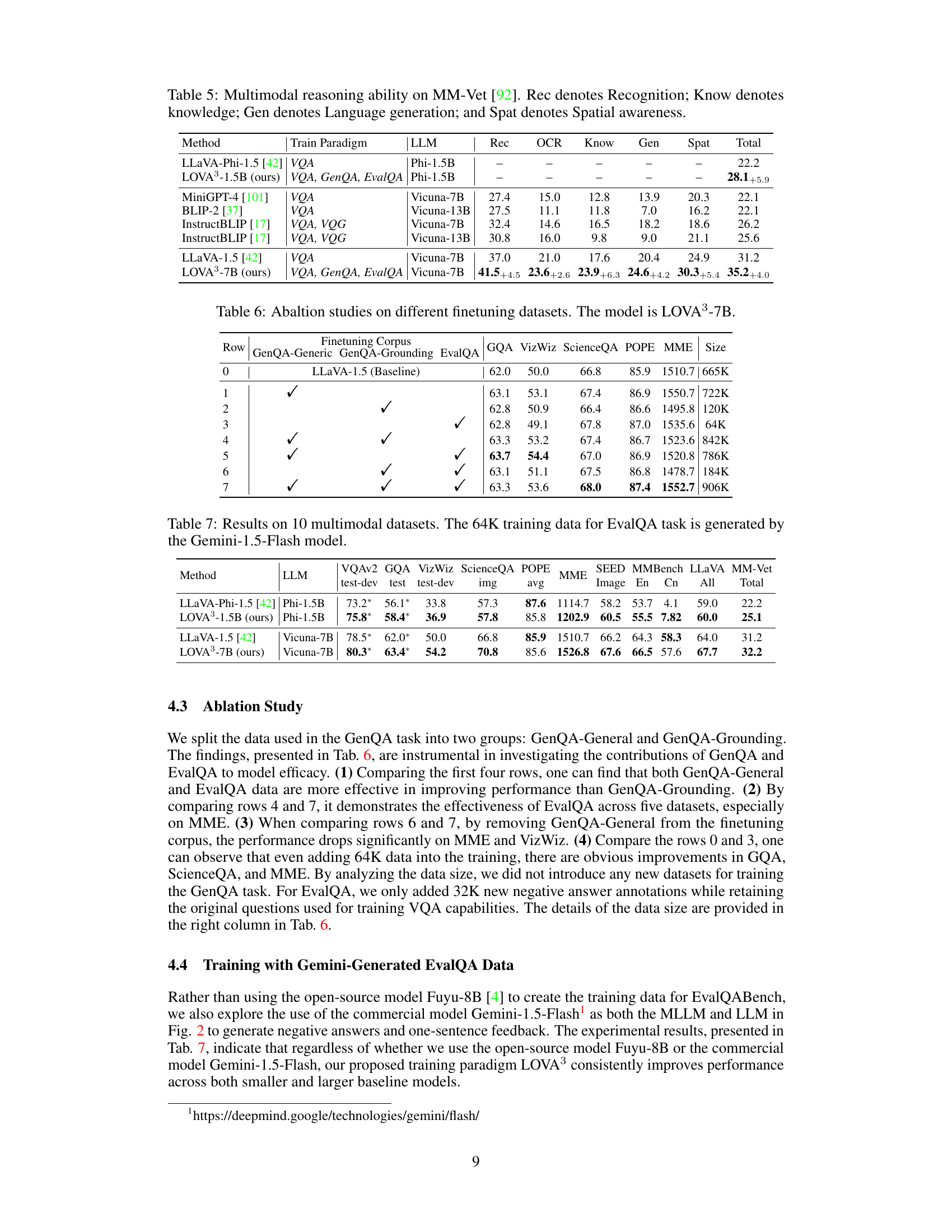
This table presents the results of several multimodal large language models on the MM-Vet benchmark. The MM-Vet benchmark assesses multimodal reasoning capabilities across various sub-tasks. The table shows the performance of each model across different aspects like Recognition, OCR, Knowledge, Generation, and Spatial Awareness. The improvements achieved by LOVA3 over the baseline model are highlighted. The table allows for comparing the relative strengths of different models in various multimodal reasoning tasks.
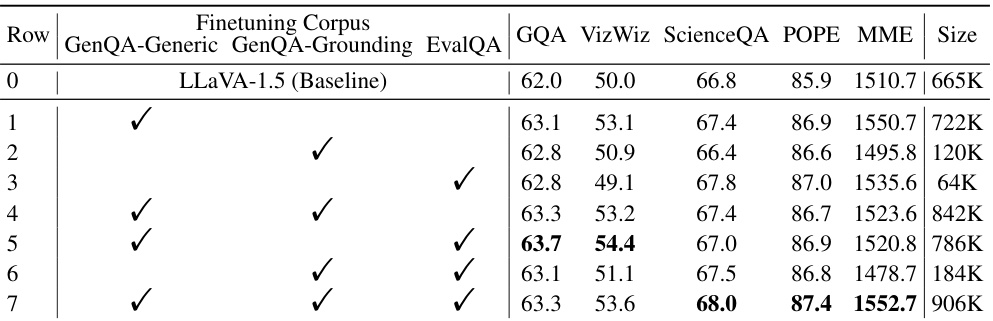
This table presents the results of ablation studies performed on the LOVA³-7B model. It shows the impact of including different combinations of GenQA-Generic, GenQA-Grounding, and EvalQA datasets during model training. The performance is measured across several key multimodal benchmarks (GQA, VizWiz, ScienceQA, POPE, and MME). By comparing the performance across rows, one can observe the effect of each dataset on the overall performance, revealing the contribution of each training task to the final model’s abilities.

This table presents the results of five generic visual question answering (VQA) tasks: VQAv2, GQA, VizWiz, ScienceQA, and POPE. The performance of the LOVA³ model is compared against several other state-of-the-art (SOTA) models. The table is divided into two parts: held-in datasets (marked with *) and held-out datasets. The best result for each task is highlighted in bold. The results demonstrate the improvement achieved by LOVA³ over existing methods on these standard VQA benchmarks.
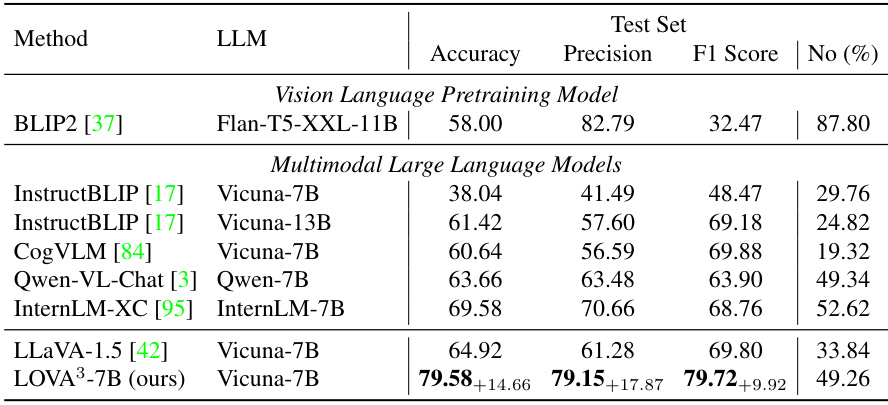
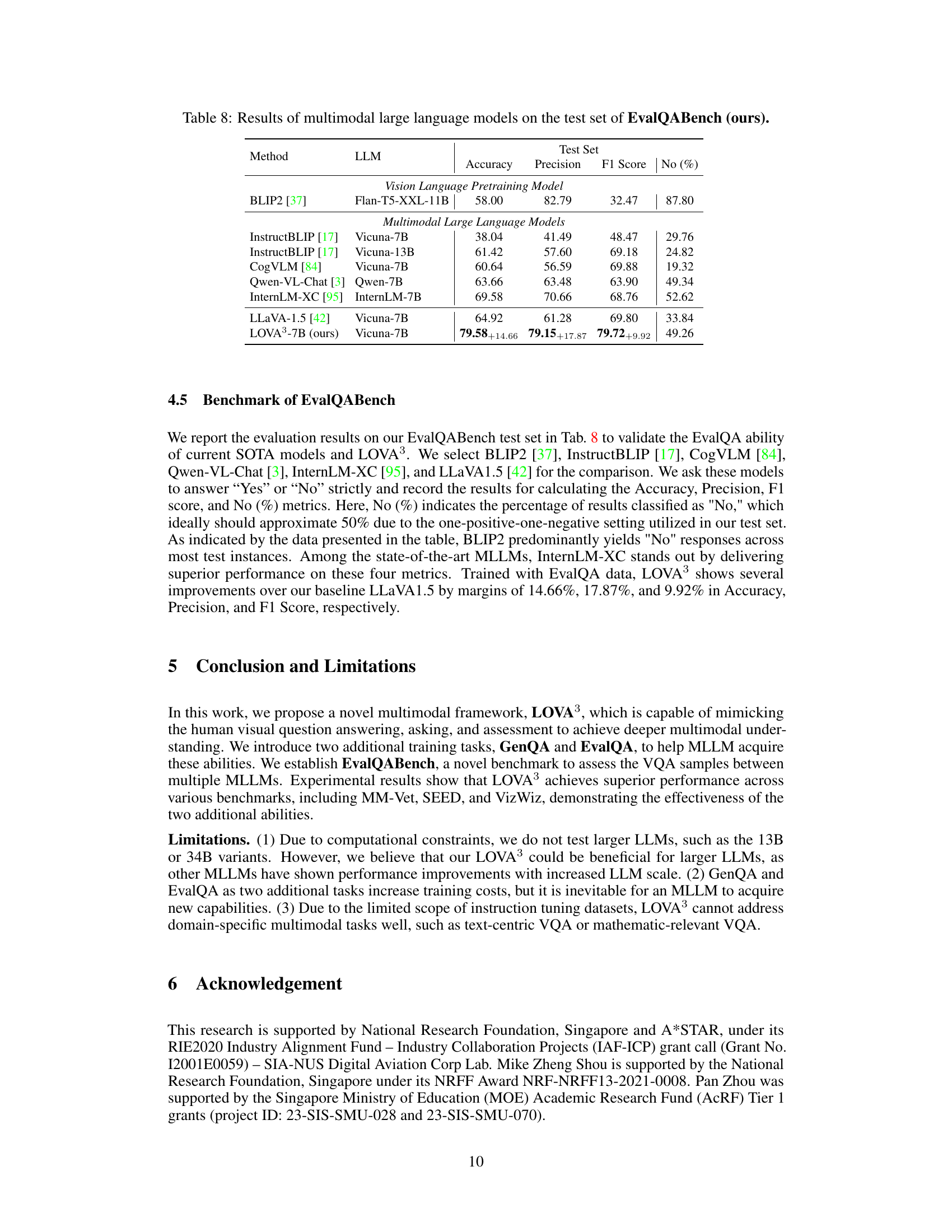
This table presents the performance of various multimodal large language models on the EvalQABench test set, specifically focusing on the models’ ability to assess the correctness of visual question-answer pairs. The metrics used are Accuracy, Precision, F1 Score, and the percentage of ‘No’ answers. The inclusion of the ‘No (%)’ column helps assess the bias of the models towards either positive or negative classifications. The table is organized to compare Vision Language Pretraining Models and Multimodal Large Language Models separately, highlighting the performance difference between them and the improvement achieved by the proposed LOVA³ model.

This table lists the datasets used in the instruction-tuning stage of the LLaVA1.5 model. It shows the name of each dataset, its size (number of samples), and the instructions used to generate the training data. The datasets cover various vision-language tasks, including general VQA (Visual Question Answering), multi-choice VQA, and image captioning, providing a diverse set of training examples for the model.
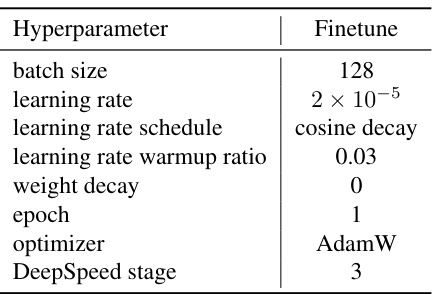
This table shows the hyperparameters used for training the LOVA³ model. The values are identical to those used for training the LLaVA1.5 model, demonstrating a consistent approach in the experimental setup. The hyperparameters include settings related to batch size, learning rate (and its scheduling), warmup ratio, weight decay, number of epochs, the optimizer employed (AdamW), and the DeepSpeed stage.

This table shows the number of samples at each stage of the EvalQABench dataset creation. It starts with 100,000 raw VQA pairs. Then negative answers are generated, manually filtered, and corrected. Feedback is then generated and further filtered. The final count is 41,592 training samples.
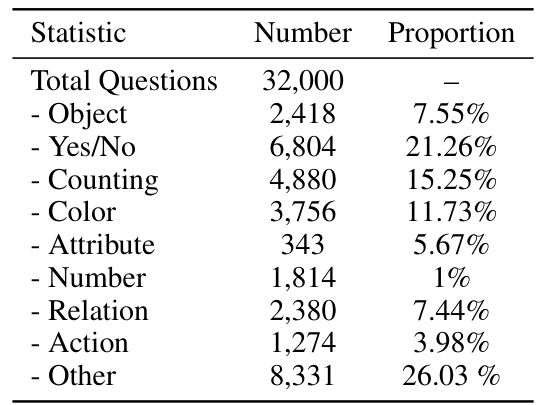
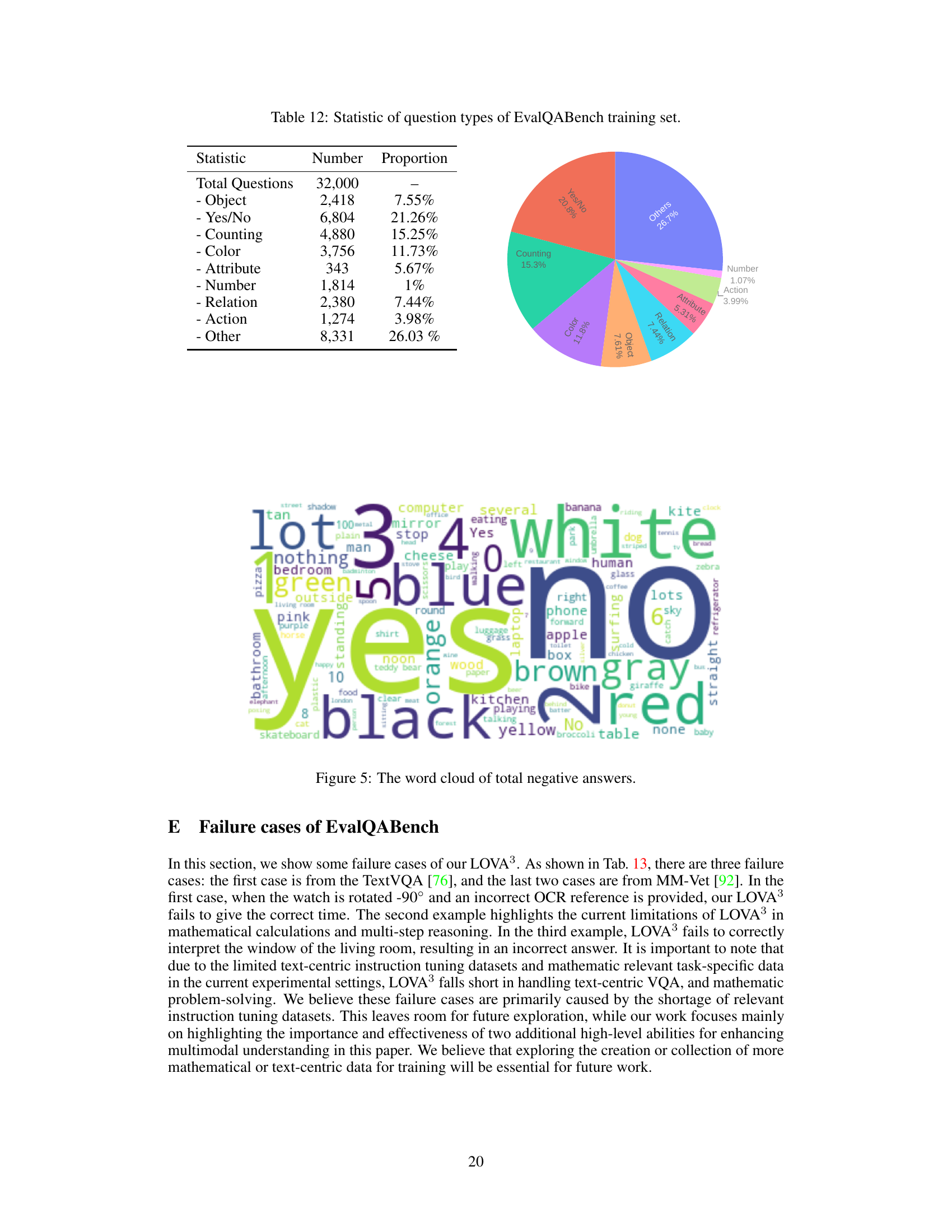
This table presents the statistical distribution of question types within the EvalQABench training dataset. It shows the number and proportion of questions categorized into nine types: Object, Yes/No, Counting, Color, Attribute, Number, Relation, Action, and Other. The ‘Other’ category encompasses diverse question types not easily classified into the other categories.
Full paper#