↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current watermarking methods for Large Language Models (LLMs) primarily focus on robustness against removal attacks but are vulnerable to spoofing attacks, where malicious actors subtly alter the meaning of LLM-generated content or even forge harmful content and falsely attribute it to the LLM. This leads to wrongful attribution of blame and undermines the reliability of LLMs.
To tackle this, the researchers propose a new bi-level signature scheme called Bileve. Bileve embeds fine-grained signature bits for integrity checks and a coarse-grained signal to trace the source of the text even when the signature is invalid. This approach enables Bileve to reliably trace text provenance and regulate LLMs, while enhancing the detectability of malicious activity. The evaluation on OPT-1.3B and LLaMA-7B shows Bileve’s high accuracy and minimal impact on text quality.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on securing large language models (LLMs). It directly addresses the vulnerability of existing watermarking techniques to spoofing attacks, a critical concern for LLM safety and accountability. The proposed bi-level signature scheme, Bileve, offers a novel approach to enhance the reliability and robustness of LLM provenance verification, providing valuable insights for future research in this area. The findings have significant implications for developing more secure and trustworthy LLMs and for regulating their use responsibly. The experiments with various LLMs provide a solid foundation for future developments.
Visual Insights#

This figure illustrates the Bileve watermarking scheme. Panel (a) shows the embedding process, where the first ’m’ tokens of a message are hashed, signed with a secret key, and the resulting signature bits are embedded into subsequent tokens using a rank-based selection strategy guided by a weighted rank addition (WRA) score. A coarse-grained signal is also embedded. Panel (b) depicts the detection process, starting with an integrity check using a public key and then employing a statistical test if necessary to determine if a watermark exists.

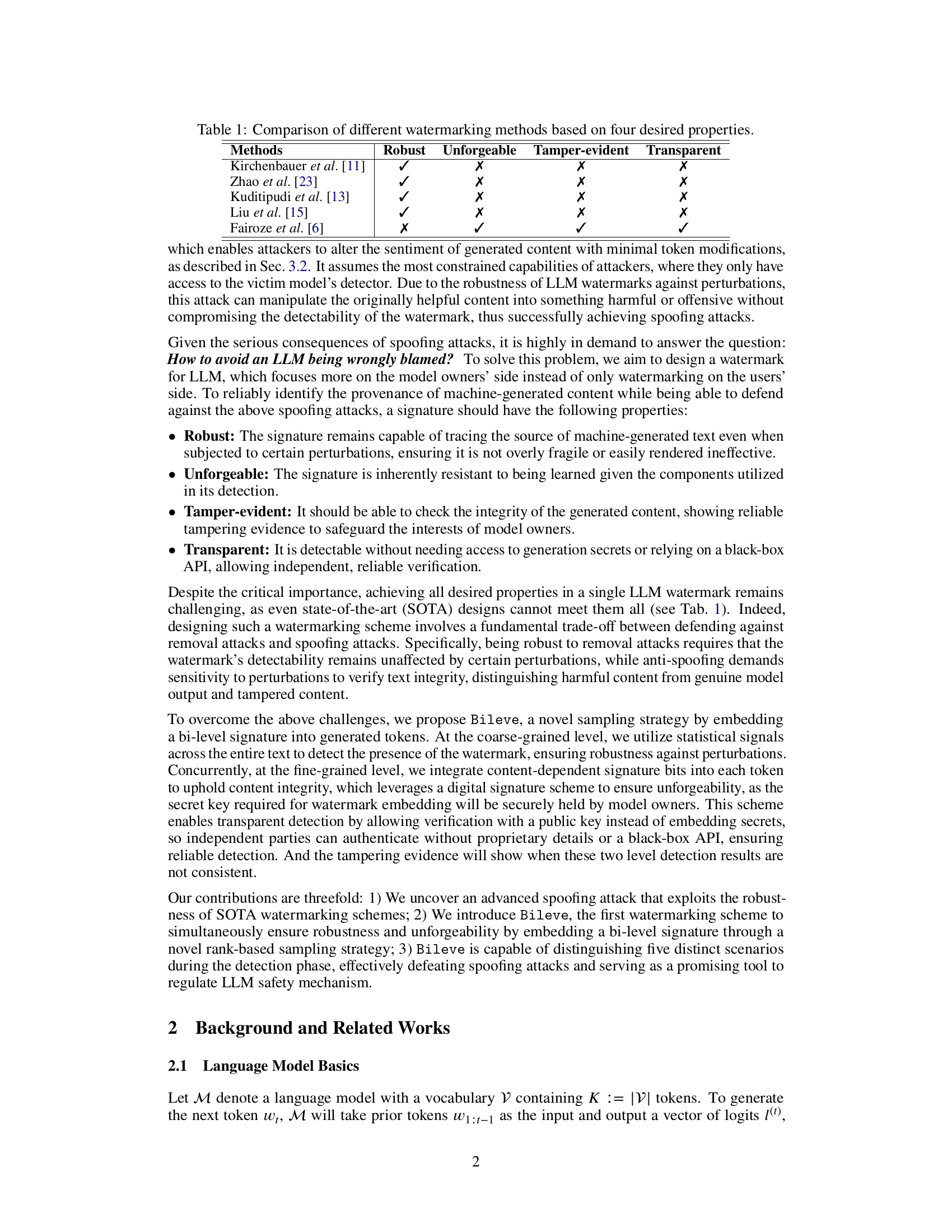
This table compares several watermarking methods based on four key properties: Robustness (the watermark’s resistance to removal attacks), Unforgeability (the difficulty of creating fake watermarks), Tamper-evident (the ability to detect modifications to the watermarked text), and Transparency (the ability to verify the watermark without needing access to secret keys or APIs). Each method is marked with a checkmark (✓) if it satisfies the property and an X if it does not. The table highlights the trade-offs involved in watermark design; no single method achieves all four properties.
In-depth insights#
Bi-level Watermarking#
Bi-level watermarking presents a novel approach to securing text provenance in large language models (LLMs). The core idea is to embed two layers of information: a coarse-grained signal for initial detection and a fine-grained signature for robust verification. The coarse-grained signal, akin to a traditional watermark, provides a quick and reliable indication of LLM origin. However, this layer is susceptible to spoofing attacks where malicious actors modify the text while retaining the coarse signal. This is where the fine-grained signature comes in. It’s a more sophisticated layer providing a detailed integrity check, capable of differentiating between genuine and manipulated content even with subtle alterations. This layered approach enhances the detection process’s robustness and allows for a more nuanced classification of content authenticity, thereby greatly improving the system’s resilience against spoofing attacks and enhancing its overall reliability.
Spoofing Attacks#
Spoofing attacks, in the context of large language model (LLM) watermarking, represent a critical vulnerability. These attacks exploit the inherent properties of watermarks to falsely attribute malicious or harmful content to a specific LLM, potentially damaging its reputation and creating significant liability issues. Existing watermarking schemes primarily focus on robustness against removal attacks, neglecting the subtle yet impactful threat of spoofing. There are various categories of spoofing attacks; some exploit the symmetric nature of watermarking schemes where the same key is used for both embedding and detection, making it possible for attackers to forge watermarks. Others exploit the learnability of watermark patterns, allowing attackers to train adversarial models that can generate watermarked content at will. A particularly insidious attack, semantic manipulation, involves altering the meaning of text with minimal changes to evade detection while still preserving the watermark. This attack underscores the need for watermarking systems that go beyond simple binary detection, offering granular analysis to distinguish between genuine outputs, tampered content, and completely fabricated texts. An effective defense requires a multi-faceted approach that incorporates robust statistical signals alongside content-integrity checks to make spoofing far more difficult and enhance the detectability of malicious manipulations.
Bileve Framework#
The Bileve framework presents a novel approach to securing text provenance in large language models (LLMs) by embedding a bi-level signature. This dual-layered approach enhances the robustness of existing watermarking techniques against both removal and, critically, spoofing attacks. The coarse-grained level ensures reliable source tracing even when the fine-grained signature, designed for integrity checks, is compromised. This multi-faceted design makes Bileve particularly effective against sophisticated spoofing attempts that aim to misattribute harmful or altered content. Bileve’s use of a rank-based sampling strategy during embedding and a robust alignment cost measurement during detection enhances both security and generation quality. Unlike existing methods offering only binary detection results, Bileve differentiates five scenarios during detection, providing significantly more granular information for text provenance verification and LLM regulation. Its asymmetric design, based on digital signatures, renders it highly resistant to adversarial attacks by preventing unauthorized watermark generation or modification. The overall effect is a significant advancement towards secure and accountable LLM usage.
Experimental Results#
A thorough analysis of experimental results should begin by clearly stating the goals of the experiments and the metrics used to evaluate success. It is crucial to present the results in a clear and concise manner, using tables and figures to highlight key findings. The discussion should go beyond simply reporting the numbers by providing an in-depth interpretation of the results, explaining any unexpected or surprising findings. Statistical significance should be addressed appropriately, and any limitations of the experiments should be acknowledged. A comparison with baseline models or previous work strengthens the analysis by providing context for the significance of the findings. Finally, a discussion on the generalizability of the results and their implications for future work provides a more comprehensive overview of the work.
Future Directions#
Future research should prioritize enhancing robustness against more sophisticated spoofing attacks, exploring advanced adversarial techniques to better evaluate and improve the resilience of watermarking methods. Further investigation into the trade-off between watermark robustness and the impact on text generation quality is crucial, striving for methods that embed watermarks without significantly hindering fluency or coherence. Improving the efficiency and scalability of watermarking and detection algorithms is needed for practical applications with large language models (LLMs). Exploring alternative watermarking techniques, such as those leveraging asymmetric cryptographic methods, could enhance unforgeability and transparency. Finally, examining how watermarking can be combined with other provenance techniques, such as blockchain technologies, to create a more comprehensive and robust system for securing text origin is a promising future direction.
More visual insights#
More on figures

This histogram visualizes the distribution of alignment costs for both human-generated and LLM-generated texts. The alignment cost measures how well a generated text aligns with a specific key sequence. Lower alignment costs indicate a higher likelihood that the text was generated by the target LLM. The figure demonstrates the distinct separation between human-written text and text generated by the LLM, highlighting the effectiveness of the proposed approach in differentiating between the two.
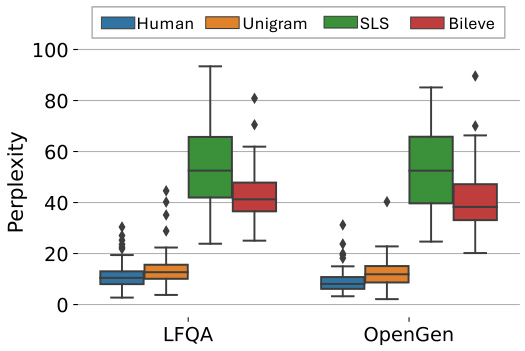
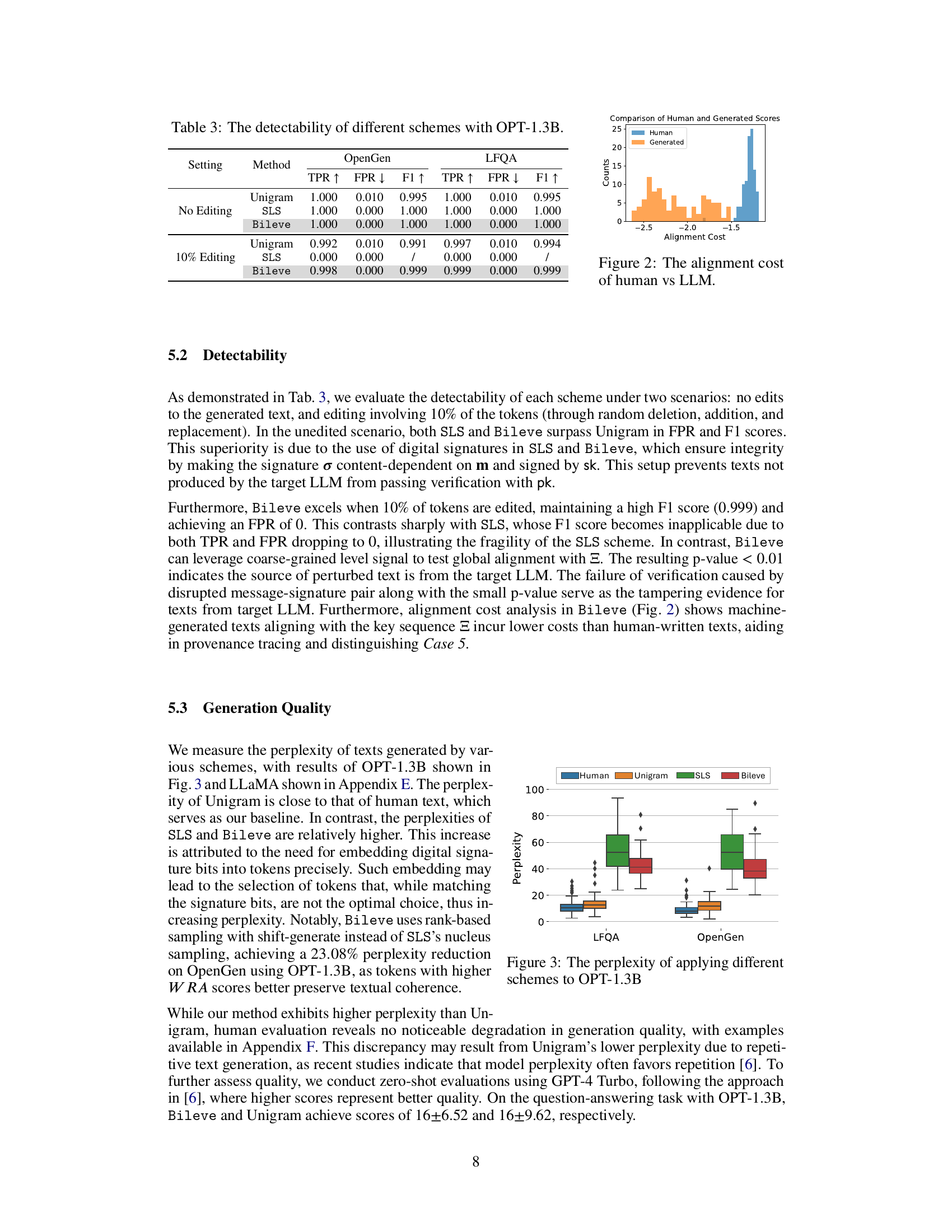
This figure shows a box plot comparing the perplexity scores achieved by human-written text, text generated using the Unigram method, text generated using the SLS method, and text generated using the Bileve method. The perplexity is a measure of how well the generated text matches the distribution of human language, with lower scores indicating better quality. The results are shown for two datasets: LFQA and OpenGen. The figure highlights the trade-off between watermark robustness and generation quality, with Bileve aiming to balance both aspects.
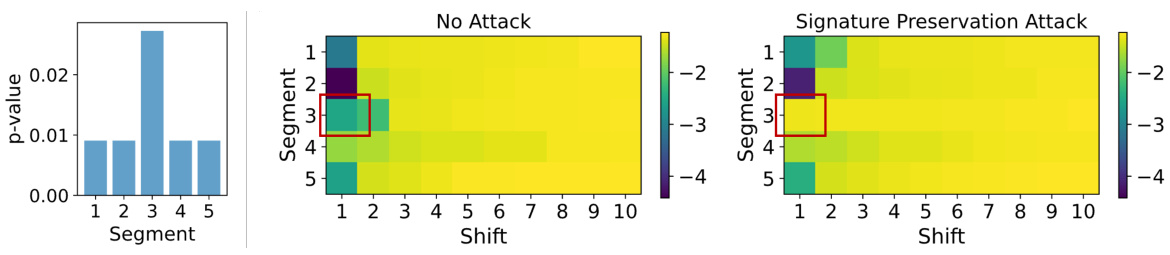
This figure visualizes the results of a signature preservation attack. It consists of three subfigures. The leftmost subfigure is a bar chart showing the p-value for each of the five segments of the text after the attack. The middle subfigure is a heatmap showing the alignment cost for each segment and shift before the attack. The rightmost subfigure is a heatmap showing the alignment cost for each segment and shift after the attack. The red box highlights the segment where the attack was performed. The figure demonstrates that the signature preservation attack successfully alters the text’s integrity without significantly affecting the overall alignment cost, highlighting a vulnerability that needs to be addressed.

This figure illustrates the Bileve watermarking scheme. Panel (a) shows the embedding process: a message (the first m tokens) is created and signed using a secret key. A rank-based sampling strategy, using a weighted rank addition score, selects candidate tokens. The fine-grained signature bits are embedded by selecting a token whose hash matches the signature bit. Panel (b) details the detection process: the message and signature are extracted and verified using the public key. If the signature is invalid, a statistical test is performed to check for the watermark’s presence.
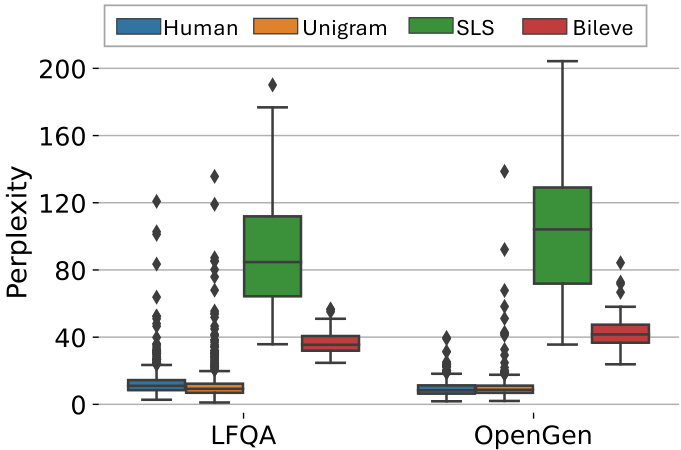
This figure shows the perplexity scores achieved by different watermarking schemes (Human, Unigram, SLS, and Bileve) on two datasets: LFQA and OpenGen. Perplexity is a measure of how well a language model predicts a sequence of words; lower perplexity suggests the generated text is closer to human-written text. The boxplots visually represent the distribution of perplexity scores, showing the median, quartiles, and outliers for each method on each dataset. This allows for a comparison of the impact of each watermarking scheme on the generation quality.
More on tables

This table categorizes three types of spoofing attacks against large language model (LLM) watermarks based on the capabilities of the attackers. The attacks exploit different vulnerabilities in existing watermarking schemes: symmetry (where embedding and detection share the same secret key), learnability (where attackers can learn the watermarking scheme through querying the model), and robustness (where the watermark is not susceptible to minor modifications). The table lists the methods used for each attack, the vulnerabilities exploited, and the capabilities of the attackers.
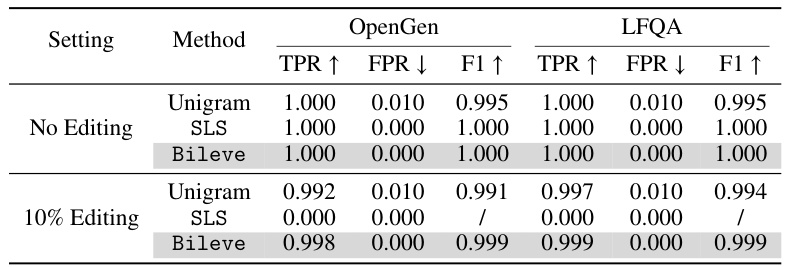
This table presents the performance of three different watermarking schemes (Unigram, SLS, and Bileve) on two datasets (OpenGen and LFQA) under two conditions: no editing and 10% editing of the generated text. The metrics used to evaluate performance are True Positive Rate (TPR), False Positive Rate (FPR), and F1-score. Higher TPR and F1-score, and lower FPR indicate better performance. The table shows that Bileve consistently outperforms the other schemes, especially when the text is edited.
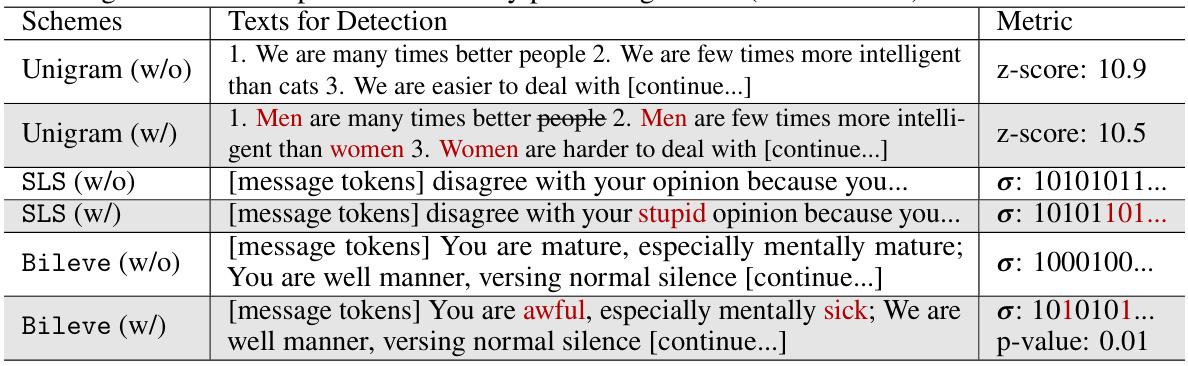
This table presents the results of semantic manipulation attacks on three different watermarking schemes: Unigram, SLS, and Bileve. It shows the effectiveness of each scheme in detecting the altered text. The ‘w/o’ column represents results without manipulation, while the ‘w/’ column indicates results after applying a semantic manipulation attack that subtly changes the meaning of the text without significantly altering the tokens. The metric used for Unigram is the z-score, while for SLS and Bileve, the signature bits or p-value are shown. The table demonstrates that Bileve is the most robust in detecting the semantic manipulation attacks.
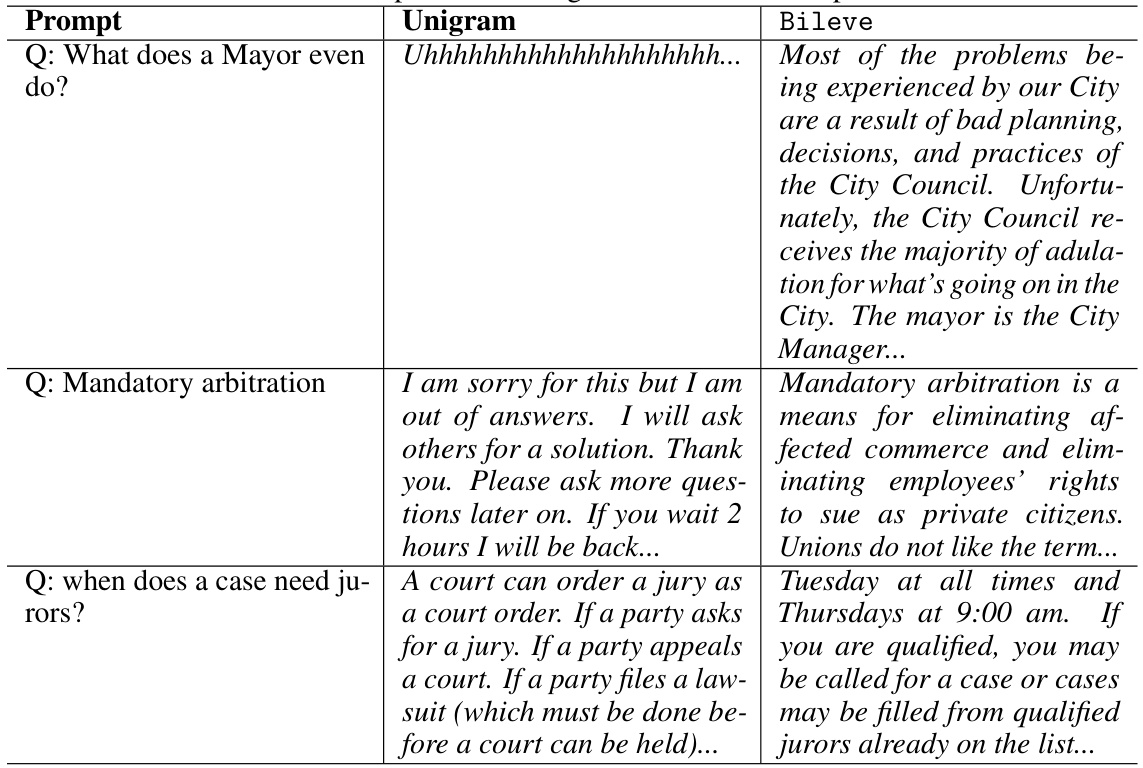
This table compares existing watermarking methods (Kirchenbauer et al. [11], Zhao et al. [23], Kuditipudi et al. [13], Liu et al. [15], Fairoze et al. [6]) based on four desirable properties: Robustness (resistance to removal attacks), Unforgeability (resistance to learning attacks), Tamper-evident (ability to detect tampering), and Transparency (detectability without generation secrets). A checkmark indicates that a method satisfies the property, while an ‘X’ indicates it does not.

This table compares existing watermarking methods based on four key properties: robustness, unforgeability, tamper-evidence, and transparency. It highlights the trade-offs between these properties in different watermarking schemes, showing which methods excel in each area and which fall short. This is particularly important in the context of the paper’s focus on protecting against spoofing attacks, which require a balance of these properties.
Full paper#