↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many machine learning models underperform on specific subgroups due to dataset biases. Existing solutions like dataset balancing can be inefficient and require group annotations. This leads to reduced model accuracy and fairness issues.
This research introduces Data Debiasing with Datamodels (D3M), a novel approach that precisely targets and removes only the most harmful training data points causing worst-group performance. D3M and its variation AUTO-D3M significantly improve accuracy on minority groups while maintaining dataset size, surpassing existing methods. The approach requires only test set labels, making it applicable to real-world situations where labeled training data is scarce.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel method to enhance the robustness of machine learning models by addressing the issue of underperformance on minority subgroups. This is important because real-world datasets often exhibit biases that lead to such underperformance. The research also opens avenues for bias discovery in unlabeled datasets, and offers a practical data-centric debiasing technique without requiring extra training data or hyperparameter tuning.
Visual Insights#

This figure illustrates the core idea of the Data Debiasing with Datamodels (D3M) method. It contrasts a naive data balancing approach with the D3M approach. Data balancing attempts to address subgroup performance disparities by removing data from overrepresented groups, potentially sacrificing a significant portion of the dataset. In contrast, D3M identifies and removes specific data points that disproportionately harm the worst-performing group, achieving similar improvements in worst-group accuracy with substantially less data removal. The visualization uses examples of a dataset with spurious correlation between class labels (cat vs. dog) and an extra feature (fur color), showing how D3M can isolate harmful data points without requiring full group annotations.

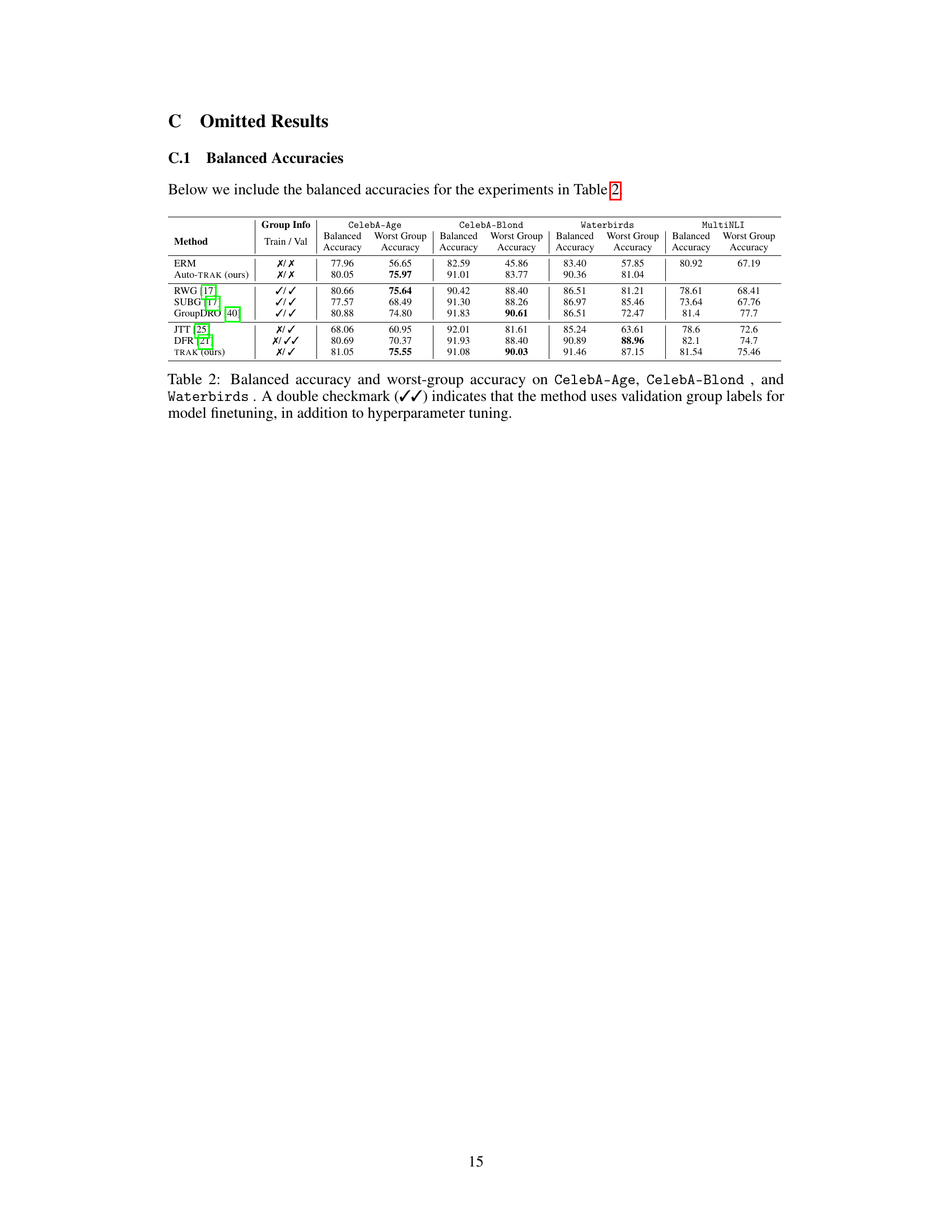
This table compares the worst-group accuracy of different methods on four datasets known to have group biases. The methods vary in the amount of group information they require (full information, partial information, or no information). The results demonstrate the performance of D3M and AUTO-D3M in comparison to other state-of-the-art approaches, highlighting their ability to improve worst-group accuracy with minimal group information or hyperparameter tuning.
In-depth insights#
Debiasing Data#
Debiasing data is a crucial aspect of ensuring fairness and mitigating bias in machine learning models. The core challenge lies in identifying and addressing spurious correlations within the data that can lead models to make unfair or inaccurate predictions for certain subgroups. Effective debiasing techniques often involve data selection, carefully choosing training examples to minimize the impact of harmful biases, or data augmentation, generating additional data points to balance under-represented groups. The selection process can be guided by various metrics quantifying fairness, and sophisticated methods like datamodeling can improve the accuracy of bias identification. While data balancing can improve performance for underperforming groups, it can also remove significant portions of the dataset. Data debiasing methods need to be rigorously evaluated to ensure they achieve their intended purpose without negatively impacting overall model performance or introducing other unintended biases.
D3M Method#
The core of the D3M method lies in its innovative approach to data debiasing. Instead of relying on dataset balancing or complex model modifications, D3M leverages the power of datamodeling to pinpoint specific training examples that disproportionately contribute to worst-group error. By approximating model predictions as functions of training data, D3M quantifies the impact of each training sample on the model’s performance across different subgroups. This allows the method to precisely identify and remove those examples that primarily harm worst-group accuracy, leading to a more robust model without sacrificing overall performance or requiring group annotations during training. This targeted approach to data selection, combined with the datamodeling framework and its efficient methods for computing data attribution, makes D3M highly effective in improving the robustness of machine learning models against biases present in the training data.
Bias Discovery#
Bias discovery in machine learning is crucial for building fair and reliable models. It involves identifying and understanding how biases, whether explicit or implicit, are encoded within datasets and algorithms. Existing work highlights the prevalence of biases in large datasets, reflecting societal prejudices and spurious correlations. Methods for bias detection range from manually inspecting data to employing algorithmic approaches that analyze model predictions or data distributions. Identifying specific training examples that disproportionately contribute to biased model predictions is a significant focus. Furthermore, research explores how algorithmic choices and data augmentation techniques can inadvertently amplify or mitigate existing biases. The development of robust bias detection methods is therefore critical for ensuring fairness and mitigating the societal impacts of biased AI systems. Ultimately, bias discovery is an ongoing process, requiring a multi-faceted approach encompassing data analysis, algorithm scrutiny, and ethical considerations.
ImageNet Case#
The ImageNet case study is crucial as it demonstrates the ability of AUTO-D3M to discover and mitigate biases without relying on pre-defined group annotations. This is a significant advancement because real-world datasets rarely come with such labels. By analyzing the top principal component of the TRAK matrix, the method successfully identifies biases relating to color and co-occurrence, which aligns with previously noted ImageNet issues. The application of AUTO-D3M to four ImageNet classes—tench, cauliflower, strawberries, and red wolf—shows improved worst-group accuracy compared to ERM (Empirical Risk Minimization) without significantly degrading overall ImageNet accuracy. This success highlights the practical utility of AUTO-D3M in identifying and mitigating hidden biases, showcasing its potential as a valuable tool for improving the fairness and robustness of models trained on large-scale, real-world datasets.
Future Work#
Future work in this area could explore several promising directions. Extending D3M to handle more complex biases beyond spurious correlations, such as those arising from confounding factors or intricate interactions between subgroups, is crucial. Developing more sophisticated datamodeling techniques that more accurately capture the complex relationship between training data and model predictions would significantly enhance the method’s effectiveness. Investigating the theoretical guarantees and limitations of D3M in different settings is important to build trust and ensure reliable use. Exploring efficient strategies for handling extremely large datasets is vital for practical applications of D3M. Additionally, research focusing on integrating D3M with other bias mitigation techniques such as adversarial training or fairness-aware learning could lead to more robust and comprehensive solutions. Finally, applying D3M to a wider range of tasks and datasets, especially those with less structured data, will further validate its generalizability and demonstrate its practical value across diverse domains.
More visual insights#
More on figures
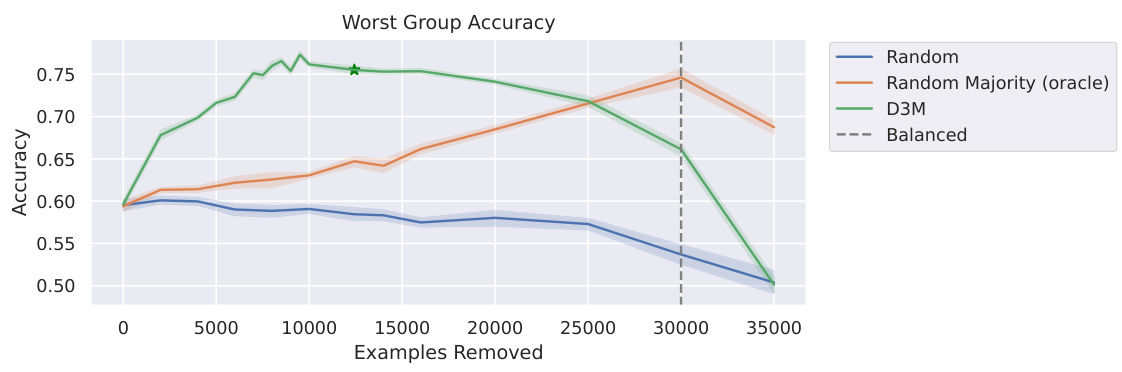
The figure shows the worst-group accuracy on the CelebA-Age dataset as a function of the number of examples removed from the training dataset using four different methods: D3M, random removal, random removal from the majority group, and dataset balancing. The green line represents D3M, which consistently outperforms other methods. The green star indicates the number of examples removed using D3M’s heuristic. The figure highlights D3M’s efficiency in improving worst-group accuracy while maintaining dataset size.

This figure shows examples from subpopulations in the CelebA-Age dataset which the model has identified as having the most negative group alignment scores. The negative scores indicate that these examples disproportionately contribute to the model’s poor performance on the worst-performing group (worst-group accuracy). Many of the images shown have labeling errors which illustrates that some of the model’s inaccuracies are attributable to inconsistencies or errors in the dataset’s labels rather than inherent limitations of the model.
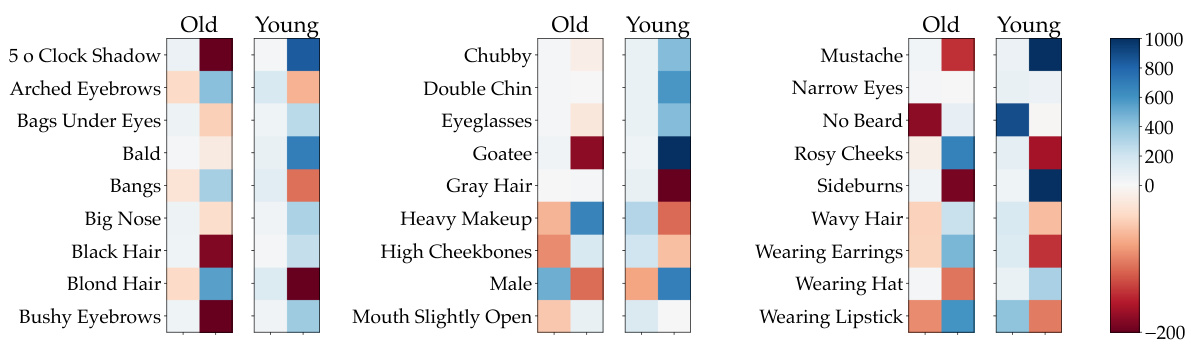
This figure shows the average group alignment scores for different subpopulations within the CelebA-Age dataset. Each subpopulation is defined by a combination of age (old/young) and other attributes (e.g., bushy eyebrows, gray hair). The heatmap visually represents how strongly each subpopulation influences the model’s worst-group accuracy. Subpopulations with highly negative scores are considered to disproportionately contribute to model bias. For example, the subpopulation of ‘young’ individuals with ‘gray hair’ has a strongly negative score, suggesting that these examples may be causing the model to perform poorly on a specific group.

This figure shows example images from four ImageNet classes (Tench, Strawberries, Red Wolf, and Cauliflower) that are most extreme according to the top principal component of the TRAK matrix. The top row displays examples with positive scores, while the bottom row shows examples with negative scores. The figure illustrates how the method identifies biases related to color and co-occurrence within the dataset. For example, Tench images with humans are considered positive, while Tench images without humans are considered negative. This indicates the algorithm detects co-occurrence bias, as the presence or absence of humans affects the classification. Similarly, the other classes show biases related to color variations, or other contextual factors.
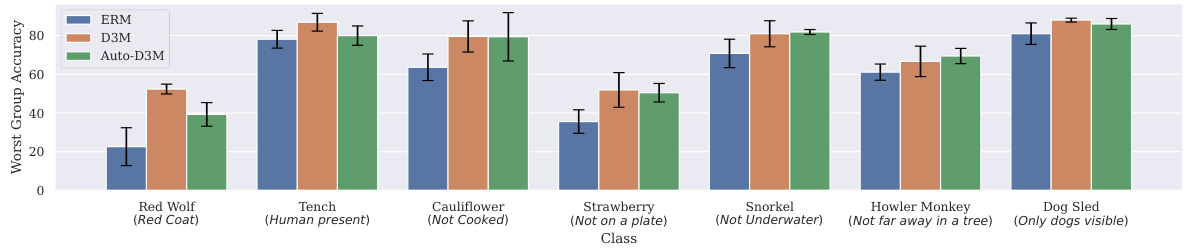
This figure shows the worst-group accuracy for eight ImageNet classes after applying three different methods: ERM (standard Empirical Risk Minimization), D3M (Data Debiasing with Datamodels), and Auto-D3M (automatic version of D3M). Each bar represents a class, and the height of the bar indicates the worst-group accuracy achieved by each method. Error bars illustrate the standard deviation across multiple runs. The results demonstrate that both D3M and Auto-D3M improve worst-group accuracy compared to the baseline ERM, indicating their effectiveness in mitigating biases within the ImageNet dataset. Auto-D3M, notably, achieves this without requiring validation group labels, highlighting its practicality.
More on tables
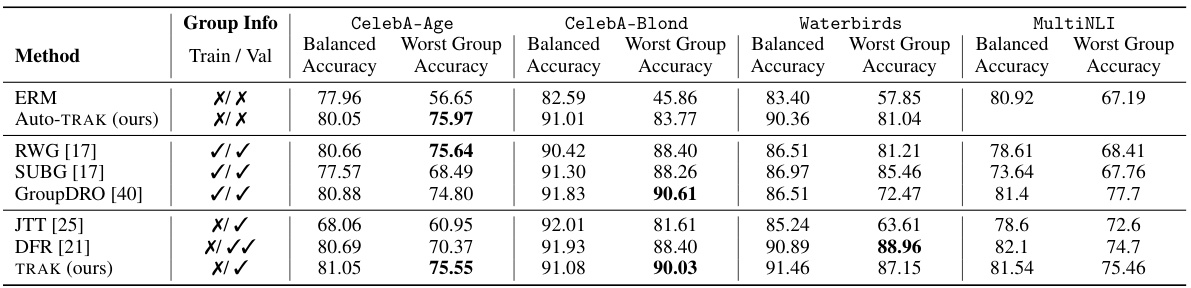
This table presents the worst-group accuracy achieved by different methods on four datasets known for exhibiting group robustness issues. It compares the performance of the proposed D3M method against several baselines, categorized by the availability of training and validation group labels. The results show the effectiveness of D3M in improving worst-group accuracy, especially when compared to methods that lack either training or validation group labels.

This table compares the worst-group accuracy of different methods on four datasets known to exhibit biases against certain subgroups. The methods are compared across three scenarios representing varying levels of access to group labels (full, partial, and no information). The table shows that the proposed D3M method achieves competitive results, even in scenarios where ground-truth training group annotations are not available. The asterisk (*) indicates that some methods used validation group labels for both hyperparameter tuning and finetuning.
Full paper#