↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current visual foundation models, exemplified by the Segment Anything Model (SAM), demonstrate remarkable versatility but struggle with inherent ambiguity when segmenting uncertain objects, producing varied and granular outputs with slight prompt changes. This inconsistency contradicts the robustness requirement for reliable models, although some existing works attempt to enhance SAM’s prediction consistency. This paper, however, uniquely transforms this limitation into a benefit, particularly for handling inherently ambiguous data.
The researchers introduce A-SAM, a novel optimization framework built on a conditional variational autoencoder that jointly models prompts and object granularity using a latent probability distribution. This allows A-SAM to adapt to and represent real-world ambiguous label distributions. Through extensive experiments, A-SAM demonstrably produces diverse, convincing, and reasonable segmentation results on various scenarios with ambiguity, showcasing remarkable performance. This innovative approach provides a new perspective on managing ambiguity in image segmentation and offers a valuable advancement in the field of vision foundation models.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of foundation models in image segmentation, particularly their sensitivity to ambiguous inputs and the resulting inconsistent outputs. It proposes a novel approach to leverage this ambiguity as an advantage, rather than a limitation, creating more robust and diverse segmentation results. This work significantly advances the state-of-the-art in ambiguous image segmentation and opens up new avenues for research in the design of more robust and reliable computer vision systems.
Visual Insights#

This figure analyzes the inherent ambiguity in the Segment Anything Model (SAM). Part (a) demonstrates how slightly different prompts from multiple experts lead to significantly different segmentation outputs for the same image. Parts (b) and (c) show quantitative results of an experiment on the LIDC dataset. They measure the Intersection over Union (IoU) for various perturbed versions of canonical box prompts. Perturbations include shifts of the prompt box by 5 pixels in different directions and variations in the output granularity of SAM. The results highlight SAM’s high sensitivity to both prompt variations and variations in object granularity.

This table compares the performance of the proposed A-SAM method against several other state-of-the-art prompted segmentation models on four different datasets (LIDC, BRATS, ISBI, and Sim10k). The metrics used for comparison include GED (Generalized Energy Distance), HM-IoU (Hungarian-Matched Intersection over Union), Dmax (Maximum Dice Matching), and Dmean (Average Dice Matching). Lower GED and higher HM-IOU, Dmax, and Dmean values indicate better performance. The results show that A-SAM outperforms the other methods, particularly in terms of HM-IoU and Dmax, indicating improved accuracy and consistency in ambiguous segmentation tasks.
In-depth insights#
Ambiguity in SAM#
The paper delves into the inherent ambiguity within the Segment Anything Model (SAM), a vision foundation model. SAM’s sensitivity to subtle prompt variations is highlighted, showing how minor adjustments can lead to significantly different segmentation outputs. This inconsistency contradicts the desired robustness of a foundational model. Furthermore, SAM’s struggle with objects possessing complex internal structure or varying granularity is discussed; the model tends to generate multiple output candidates rather than a singular definitive result. This behavior is attributed to SAM’s class-agnostic nature, which prevents discerning fine-grained distinctions between objects with differing hierarchical complexity. The authors cleverly reframe these perceived weaknesses as strengths, proposing that SAM’s sensitivity could become an advantage when dealing with inherently ambiguous data, such as those with noisy labels or varying annotation preferences.
A-SAM Framework#
The A-SAM framework, as envisioned, ingeniously tackles the inherent ambiguity problem within the Segment Anything Model (SAM). It cleverly transforms SAM’s sensitivity to prompt variations and object granularity into a strength, probabilistically modeling these ambiguities using a conditional variational autoencoder. This innovative approach allows A-SAM to generate a diverse range of plausible segmentation outputs, mirroring the inherent ambiguity often found in real-world data. The framework jointly models prompt and object granularity using latent probability distributions, enabling adaptable perception of ambiguous label distributions. By introducing context-aware prompt ambiguity modeling and granularity-aware object ambiguity modeling, A-SAM produces controllable, convincing, and reasonable segmentations, surpassing the limitations of deterministic segmentation approaches. This framework’s power lies in its adaptability to inherently ambiguous datasets, opening up new avenues for practical applications needing multiple plausible outputs.
Probabilistic Modeling#
Probabilistic modeling in the context of computer vision, particularly for ambiguous object segmentation, offers a powerful paradigm shift from deterministic approaches. By representing uncertainties inherent in image data and diverse annotations, probabilistic models enhance robustness and provide richer, more informative outputs. This is especially crucial in handling ambiguous scenarios where multiple valid segmentations may exist, unlike traditional methods that usually yield only a single prediction. The ability to capture the distribution of possible segmentations allows for better understanding of the model’s confidence and uncertainty, leading to more reliable and explainable results. A key advantage is the capacity to model ambiguous label distributions adaptively, enabling the system to dynamically adjust to varying degrees of ambiguity inherent in different images and scenarios. This approach yields a set of diverse but reasonable segmentation outcomes, exceeding the limitations of deterministic techniques constrained to singular predictions.
Empirical Results#
The ‘Empirical Results’ section of a research paper is critical for demonstrating the validity and practical significance of the proposed approach. A strong empirical evaluation will include a comprehensive set of experiments on diverse and relevant datasets, employing rigorous methodologies to ensure accuracy and reliability of the results. Careful consideration of experimental design, including control groups, appropriate metrics, and statistical significance testing, is essential to support the claims made in the paper. The presentation of results should be clear, concise, and well-organized, using visualizations such as tables and figures to effectively convey the findings. A thoughtful discussion of the results should interpret the findings in the context of the research question and provide insights into the strengths and limitations of the approach. Crucially, comparing the proposed approach with relevant baselines and state-of-the-art methods is necessary to establish the novelty and impact of the research. By addressing all of these aspects, the ‘Empirical Results’ section provides convincing evidence of the contribution and reliability of the study.
Future Directions#
Future research could explore improving the robustness of SAM to variations in prompts and object granularity, potentially through advanced probabilistic modeling techniques or incorporating more diverse training data. Investigating alternative prompt representations beyond bounding boxes and points, such as natural language descriptions, could enhance the model’s versatility. Exploring methods for handling inherent ambiguity not just as a flaw but as a source of information in certain applications is also crucial, possibly by generating confidence maps alongside segmentations. Further research should also delve into efficiently scaling SAM to handle larger images and videos while maintaining real-time performance, including exploring architectural optimizations or model compression techniques. Finally, examining applications to diverse domains where ambiguous object boundaries are prevalent, like medical imaging or remote sensing, would further validate SAM’s potential and reveal additional challenges and opportunities.
More visual insights#
More on figures

This figure illustrates the training pipeline of the A-SAM framework. It shows how the framework probabilistically models both prompt and object-level ambiguity. The process involves using a prompt encoder and image encoder to generate embeddings which are then input to a Prompt Generation Network (PGN) and an Image Generation Network (IGN). These networks model the latent distribution of prompts and object granularities, respectively. The output of PGN and IGN, along with the SAM embeddings, are used to generate mask outputs which are then compared to the ground truth using a cross-entropy loss. The entire process is optimized using a variational autoencoder approach. Two posterior networks, one for prompts and one for images, are used during training to guide the learning process and ensure the generated distributions are aligned with the ground truth. The model’s ability to generate diverse and reasonable segmentations results from this probabilistic modeling of ambiguity.

This figure presents a qualitative comparison of the proposed A-SAM model with other prompted segmentation methods (SegGPT, SEEM, and SAM) for ambiguous segmentation tasks. It shows the segmentation results for several examples, including the ground truth segmentation labels provided by multiple experts, highlighting how A-SAM handles ambiguities more effectively by generating a range of plausible segmentations instead of a single, potentially inaccurate one. The results from the other methods are shown for comparison, demonstrating limitations in dealing with ambiguous object boundaries and prompt variations.

This figure compares the results of different ambiguous image segmentation methods, including PixelSeg, Mose, and the proposed A-SAM method, with the ground truth. It visually demonstrates the ability of A-SAM to generate multiple plausible segmentations for ambiguous objects, showing a greater variety and accuracy compared to other methods.
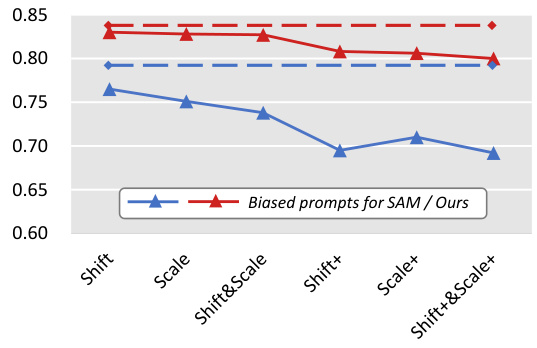
This figure shows the robustness of the proposed A-SAM framework and the baseline SAM model against different prompt perturbations. The x-axis represents the type of perturbation applied to the prompts (Shift, Scale, Shift&Scale, Shift+, Scale+, Shift+&Scale+), while the y-axis shows the Intersection over Union (IoU) metric. The blue line represents the performance of the SAM model, while the red line represents the performance of the A-SAM model. The dashed lines represent the performance of both models under standard prompts, which serves as an upper bound for comparison. The results demonstrate that the A-SAM model is more robust to prompt variations than the SAM model, maintaining a higher IoU even under severe perturbations.

This figure shows a qualitative comparison of the proposed A-SAM model with other prompted segmentation models on ambiguous segmentation tasks. It displays the results of three different models (SegGPT, SEEM, and SAM) compared with the ground truth annotations. Each model’s outputs are shown alongside the corresponding ground truth for three different ambiguous examples. This helps to visually demonstrate the strengths and limitations of each model in handling ambiguous segmentation scenarios.

This figure shows a qualitative comparison of different segmentation models on ambiguous segmentation tasks. It includes three ground truth expert labels for comparison and showcases sampled segmentation masks generated by each model (SAM w/ Box Shift, SEEM w/ Mask Shift, and the proposed A-SAM method). The visual comparison highlights the differences in accuracy and diversity of results between the models.
More on tables
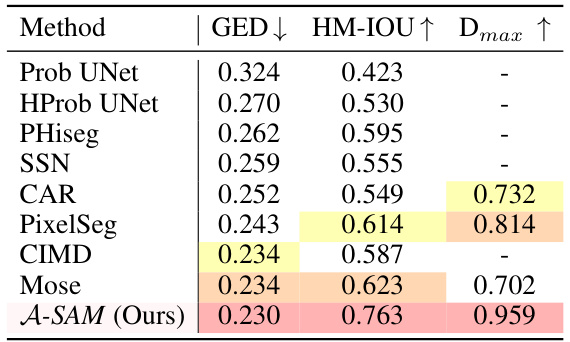
This table presents a quantitative comparison of the proposed A-SAM model against several state-of-the-art methods for ambiguous image segmentation on the ISBI dataset. The metrics used for comparison are GED (Generalized Energy Distance), HM-IOU (Hungarian-Matched Intersection over Union), and Dmax (Maximum Dice Matching). Lower GED values indicate better performance, while higher HM-IOU and Dmax values represent improved segmentation accuracy. The results highlight the superior performance of A-SAM compared to other approaches in achieving both accurate and diverse segmentation outputs, especially in the challenging scenarios involving ambiguity.
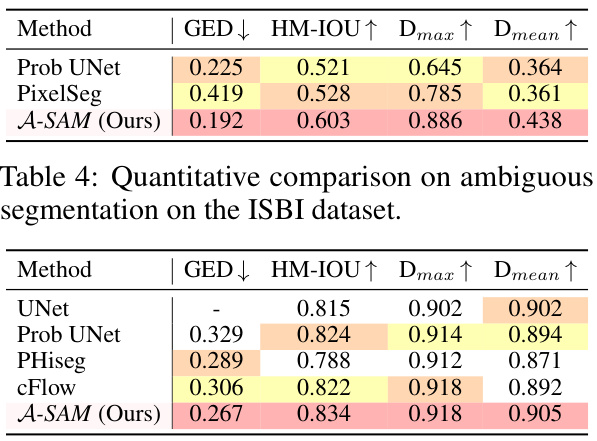
This table presents a quantitative comparison of the proposed A-SAM model against several other methods for ambiguous image segmentation on the ISBI dataset. The metrics used for comparison are GED (Generalized Energy Distance), HM-IOU (Hungarian-Matched Intersection over Union), Dmax (Maximum Dice Matching), and Dmean (Average Dice Matching). Lower GED values indicate better performance, while higher values for HM-IOU, Dmax, and Dmean are preferred. The results show that A-SAM outperforms the other methods across all metrics.

This table presents a quantitative comparison of the proposed A-SAM model with several state-of-the-art ambiguous image segmentation methods on the SIM 10k dataset. The metrics used for comparison are GED (Generalized Energy Distance), HM-IoU (Hungarian-Matched Intersection over Union), Dmax (Maximum Dice Matching), and Dmean (Average Dice Matching). Lower GED, higher HM-IoU, Dmax, and Dmean values indicate better performance. The results show that A-SAM outperforms other methods in terms of these metrics, demonstrating its effectiveness in handling ambiguous segmentations.
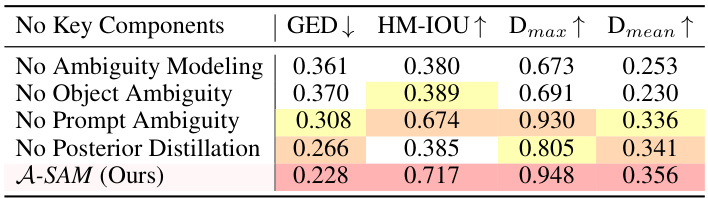
This table presents the results of an ablation study conducted to evaluate the impact of each key component in the proposed A-SAM framework. The study removes one component at a time (No Ambiguity Modeling, No Object Ambiguity, No Prompt Ambiguity, No Posterior Distillation) and compares the performance with the full A-SAM model (A-SAM (Ours)). The performance is measured using four metrics: GED (Generalized Energy Distance), HM-IOU (Hungarian-Matched Intersection over Union), Dmax (Maximum Dice Matching), and Dmean (Average Dice Matching). The results demonstrate the contribution of each component to the overall performance of the A-SAM framework.
Full paper#



















