↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Named Entity Recognition (NER) is a crucial task in natural language processing, but using large language models (LLMs) for NER often leads to slow inference speeds due to the sequential decoding process. Existing methods, such as using augmented language or structured annotations, face challenges like increased output length or autoregressive dependencies, impacting efficiency. This paper addresses this by proposing PaDeLLM-NER.
PaDeLLM-NER introduces parallel decoding to solve the latency issues. It allows LLMs to generate all label-mention pairs simultaneously, significantly reducing sequence lengths. Experiments demonstrate that PaDeLLM-NER achieves a 1.76 to 10.22 times speedup compared to autoregressive methods, while maintaining or even improving the prediction accuracy. It also shows compatibility with existing frameworks and resources, making it a practical and efficient solution for enhancing LLM-based NER systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) for named entity recognition (NER). It offers a novel approach to significantly speed up inference time, a major bottleneck in LLM-based NER, without sacrificing accuracy. This opens up new avenues for applying LLMs to real-time NER tasks and paves the way for further research in optimizing LLM inference for various NLP tasks.
Visual Insights#
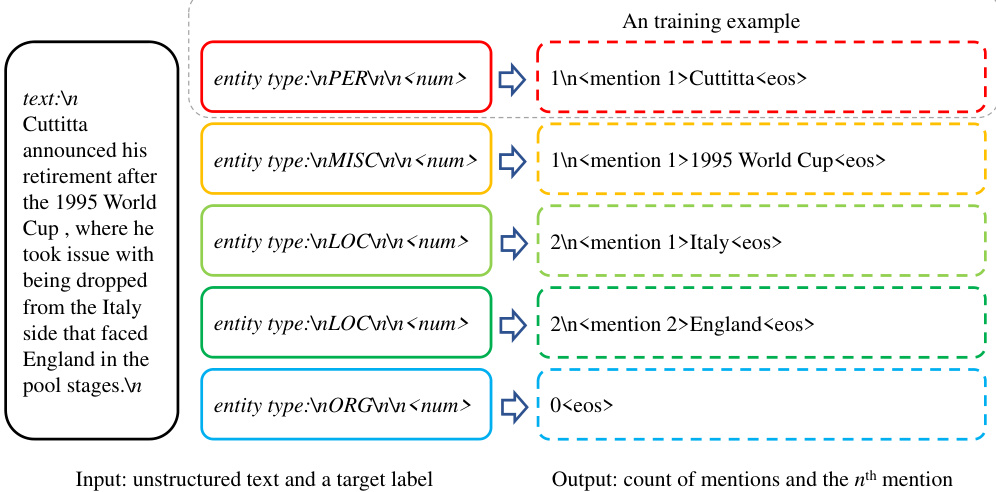
This figure illustrates the training process of PaDeLLM-NER. A single unstructured text containing multiple entities (e.g., Person, Location, Organization) is broken down into multiple training examples. Each example focuses on a single entity type and contains the count of mentions for that type and each mention’s text. This allows for the parallel generation of label-mention pairs during inference, which is the core innovation of the PaDeLLM-NER approach.

This table shows two common formats for representing the output of a named entity recognition (NER) system using large language models (LLMs). The ‘Augmented Language’ format incorporates the original input text along with the NER labels and mentions. The ‘Structured Annotation’ format uses a more concise, structured representation of the labels and mentions. Examples are provided using the CoNLL2003 dataset.
In-depth insights#
Parallel Decoding#
Parallel decoding in large language models (LLMs) for named entity recognition (NER) offers a significant advantage by tackling the inherent sequentiality of autoregressive generation. Traditional autoregressive methods process the input word-by-word, generating each label and mention sequentially, leading to high latency, especially with long sequences. Parallel decoding aims to overcome this limitation by generating all mentions simultaneously, dramatically reducing the inference time. This is achieved by restructuring the model’s training and inference paradigms. The training phase is modified to enable the model to predict the number of mentions for each entity type first, followed by the parallel generation of all mentions. This approach effectively reduces the sequence length required for decoding, enabling faster inference without significant loss of accuracy. The resultant efficiency gain is particularly remarkable in NER tasks due to their inherent need to manage numerous entity label-mention pairs. However, challenges remain, including handling duplicate mentions (which can occur when predictions are made in parallel) and maintaining prediction accuracy across various datasets. The effectiveness of parallel decoding hinges upon carefully managing these trade-offs, ultimately optimizing for speed and precision in NER tasks.
LLM NER Speedup#
The core of this research paper revolves around accelerating Named Entity Recognition (NER) within Large Language Models (LLMs). A significant bottleneck in current LLM-based NER is the inherently sequential decoding process. This paper introduces a novel parallel decoding approach, PaDeLLM-NER, which dramatically improves inference speed. Instead of sequentially generating each label-mention pair, PaDeLLM-NER predicts all pairs simultaneously. This results in significantly shorter sequences, drastically reducing latency. Experiments show a speed increase ranging from 1.76 to 10.22 times compared to traditional autoregressive methods, while maintaining or even surpassing the accuracy of state-of-the-art techniques. This substantial speed enhancement opens exciting possibilities for real-time or low-latency NER applications, where the speed limitations of traditional LLMs have been a major obstacle. The method’s efficacy is demonstrated on both English and Chinese datasets under both zero-shot and supervised settings, further highlighting its versatility and robustness. However, the paper also acknowledges the need for further optimization, particularly in mitigating the effects of multiple GPU usage and duplicate mention resolution. PaDeLLM-NER’s focus on inference speed provides a valuable contribution to the field, potentially accelerating deployment and broadening the applicability of LLMs in real-world NER tasks.
Zero-shot NER#
Zero-shot named entity recognition (NER) represents a significant advancement in natural language processing. It signifies the ability of a model to recognize and classify named entities without any explicit training data for those specific entities. This is a powerful capability, as it eliminates the need for extensive annotation efforts for each new entity type encountered. The key is leveraging the model’s pre-trained knowledge and general language understanding to infer the labels based on context. However, zero-shot NER performance is typically lower than supervised approaches, as the model must rely on broader patterns rather than specific examples. A successful zero-shot NER system needs to be robust and adaptable to a wide variety of contexts and entity types. Furthermore, the choice of prompt engineering and the model’s underlying architecture significantly influence the final performance. The evaluation of such methods often requires careful selection of benchmarks that accurately measure its effectiveness on a variety of unseen data. Future research should focus on improving the robustness and generalization capabilities of zero-shot NER models, potentially through techniques such as advanced prompt engineering, improved model architectures, or the incorporation of knowledge graphs.
Future Enhancements#
Future enhancements for the PaDeLLM-NER model could explore several promising avenues. Improving the deduplication mechanism is crucial; the current method, while effective, can be overly aggressive, potentially discarding valid mentions. A more sophisticated approach, perhaps leveraging contextual information or incorporating a confidence score, could enhance precision. Investigating alternative decoding strategies, beyond the current greedy approach, such as beam search or sampling-based methods, could potentially improve both efficiency and prediction quality. Addressing the limitations of the two-step inference process, particularly the need for multiple training examples derived from a single instance, would streamline the training process. Exploring methods to handle nested NER more effectively within the parallel decoding paradigm remains a key challenge. Finally, further optimization of the model’s architecture and efficient integration with quantization or other latency-reduction techniques would lead to even faster inference. By addressing these aspects, PaDeLLM-NER could become an even more powerful and versatile approach to NER.
Method Limitations#
A thorough analysis of method limitations requires careful consideration of several aspects. Firstly, data limitations should be addressed, exploring whether the dataset used is representative of real-world scenarios and sufficiently large to avoid overfitting or underfitting. Secondly, algorithmic limitations should be examined, analyzing the underlying assumptions, potential biases, and any restrictions on the model’s generalizability. For instance, are there any specific pre-processing steps or architectural choices that limit the model’s applicability to various contexts? Thirdly, computational constraints should be evaluated, assessing the resources required for training and inference, thereby identifying potential scalability bottlenecks. Finally, interpretability and explainability limitations should be considered; does the model’s complexity hinder understanding and result in limited insight into its decision-making process? Addressing these facets critically unveils the method’s strengths and weaknesses, paving the way for future improvements and providing a more comprehensive evaluation of its overall effectiveness.
More visual insights#
More on figures

This figure illustrates the two-step inference process in PaDeLLM-NER. First, the model predicts the number of mentions for each label (Step 1). Then, based on that count, it predicts each mention in parallel (Step 2). Finally, duplicate mentions (predicted for multiple labels) are resolved by choosing the one with the highest probability.

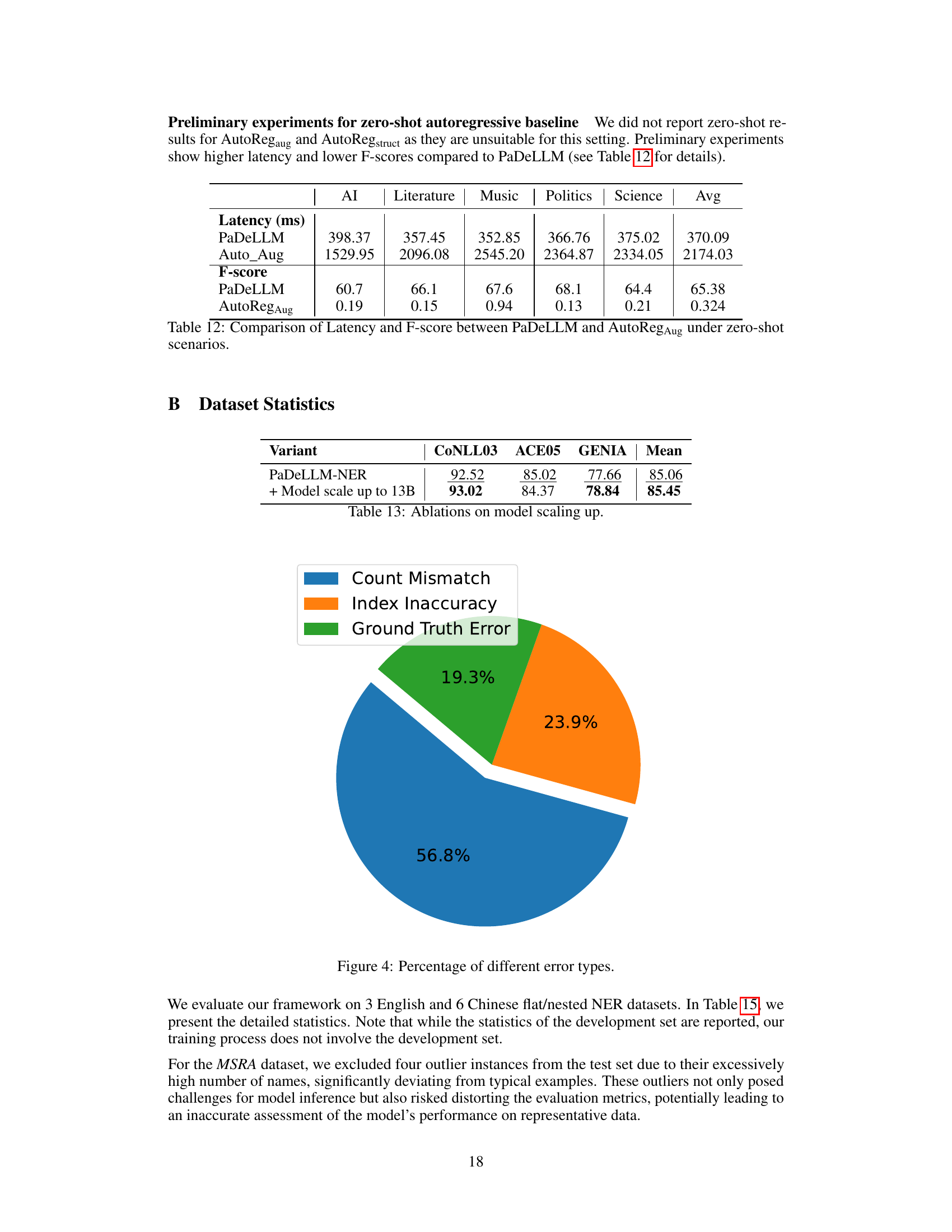
This figure shows the speedup of PaDeLLM-NER compared to autoregressive methods across different datasets. The speedup is calculated by dividing the latency of the baseline autoregressive methods (AutoRegAug and AutoRegstruct) by the latency of PaDeLLM-NER. The results show significant speed improvements for PaDeLLM-NER across all datasets, with speedup factors varying across different datasets. This highlights the efficiency gains of PaDeLLM-NER in reducing inference latency.

This figure shows a breakdown of the error types found in the ACE2005 dataset. The majority (56.8%) of errors are due to incorrect mention counts. A significant portion (23.9%) results from index inaccuracies (incorrect mentions for a given index). Finally, 19.3% of the errors are attributed to inaccuracies in the ground truth data itself.
More on tables

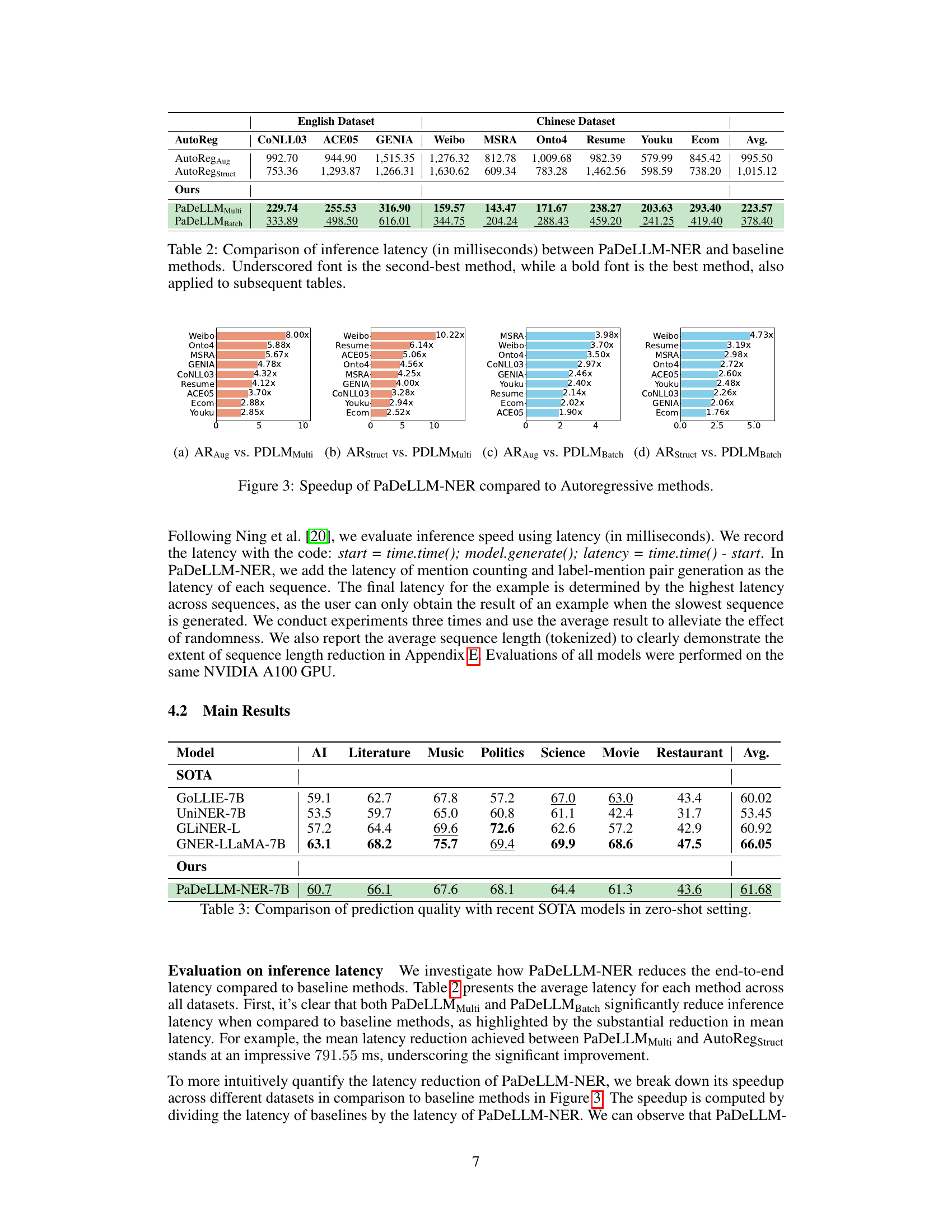
This table compares the inference latency (in milliseconds) of the proposed PaDeLLM-NER model against several baseline methods across various English and Chinese NER datasets. The latency is a measure of how long it takes for the model to generate predictions. The best and second-best performing models are highlighted in bold and underlined fonts, respectively. This provides a direct comparison of the speed improvements achieved by the PaDeLLM-NER method.

This table presents the comparison of prediction quality (using micro F1 score) of the proposed PaDeLLM-NER model against other state-of-the-art (SOTA) models in a zero-shot setting. The comparison is done across various domains, such as AI, Literature, Music, Politics, Science, Movie, and Restaurant, demonstrating the model’s performance in unseen domains without further training.
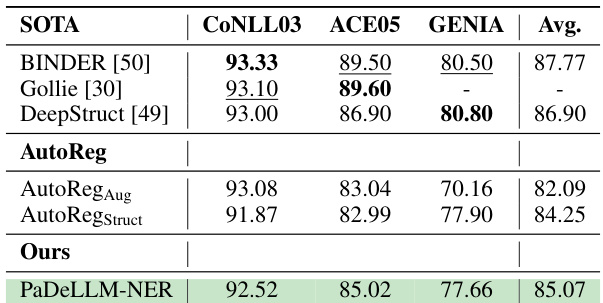
This table compares the prediction quality (micro F-score) of the proposed PaDeLLM-NER method against several state-of-the-art (SOTA) methods on three widely used English supervised named entity recognition (NER) datasets: CoNLL03, ACE05, and GENIA. It showcases the performance of PaDeLLM-NER in a supervised setting, highlighting its ability to achieve competitive results compared to other advanced NER techniques.

This table compares the inference latency (in milliseconds) of the proposed PaDeLLM-NER model against several baseline methods across various English and Chinese NER datasets. The latency represents the time taken for the models to generate predictions. The best and second-best performing methods for each dataset are highlighted in bold and underscored font, respectively.

This table presents the ablation study results on the PaDeLLM-NER model. It shows the performance of the model with different components removed or modified. The variants are: (1) the base PaDeLLM-NER model, (2) PaDeLLM-NER with loss ignoring for text spans, (3) PaDeLLM-NER without de-duplication, and (4) PaDeLLM-NER with reversed de-duplication. The results are presented as micro F1 scores for CoNLL03, ACE05, and GENIA datasets and a mean across these three datasets. The table demonstrates the impact of each component on the overall model performance.
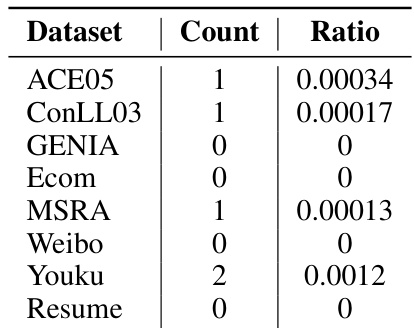
This table shows the number of mentions that appear under multiple labels in the ground truth data for different NER datasets. The ‘Ratio’ column represents the proportion of mentions with this characteristic relative to the total number of mentions in each dataset. It demonstrates the infrequency of this phenomenon, supporting the claim that the de-duplication mechanism is not overly aggressive.
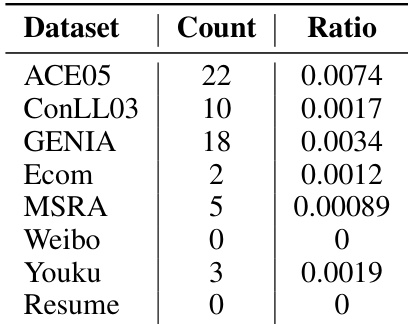
This table presents the number of mentions that appear under multiple labels in the PaDeLLM-NER model’s predictions. It provides a count for each dataset (ACE05, ConLL03, GENIA, Ecom, MSRA, Weibo, Youku, Resume) and calculates the ratio of these mentions to the total number of mentions. This data helps to assess the frequency of duplicate mention predictions and evaluate the effectiveness of the proposed de-duplication strategy.
This table compares the inference latency in milliseconds of PaDeLLM-NER against several baseline methods across various English and Chinese NER datasets. The latency is a measure of how long it takes to process each input sentence. It shows that PaDeLLM-NER significantly reduces inference time compared to the autoregressive baselines. The best and second-best performing methods are highlighted in bold and underlined fonts, respectively.
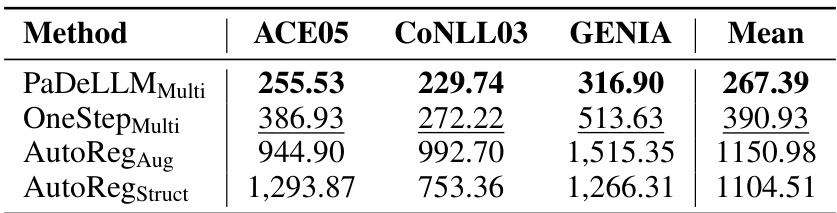
This table compares the inference latency in milliseconds of PaDeLLM-NER against several baseline methods across multiple English and Chinese datasets. It highlights the significant speed improvements achieved by PaDeLLM-NER, indicating its efficiency in NER tasks. The best and second-best performing methods are clearly marked.

This table compares the performance of the proposed PaDeLLM-NER method against other state-of-the-art (SOTA) methods on several widely-used English supervised NER datasets. It shows the micro F1-score, a common metric for NER, achieved by each method, enabling a direct comparison of prediction accuracy.

This table compares the inference latency (in milliseconds) and prediction quality (F-score) of the PaDeLLM-NER model against the AutoRegAug baseline model in zero-shot settings across various domains including AI, Literature, Music, Politics, and Science. It highlights the significant improvement in both latency and F-score achieved by PaDeLLM-NER compared to the traditional autoregressive approach.

This table presents the results of ablations conducted on the model scaling. By increasing the model size from 7B to 13B, the performance on CONLL03 and GENIA datasets improved while showing a slight decrease on ACE05 dataset. The average performance shows a significant improvement from 85.06 to 85.45.

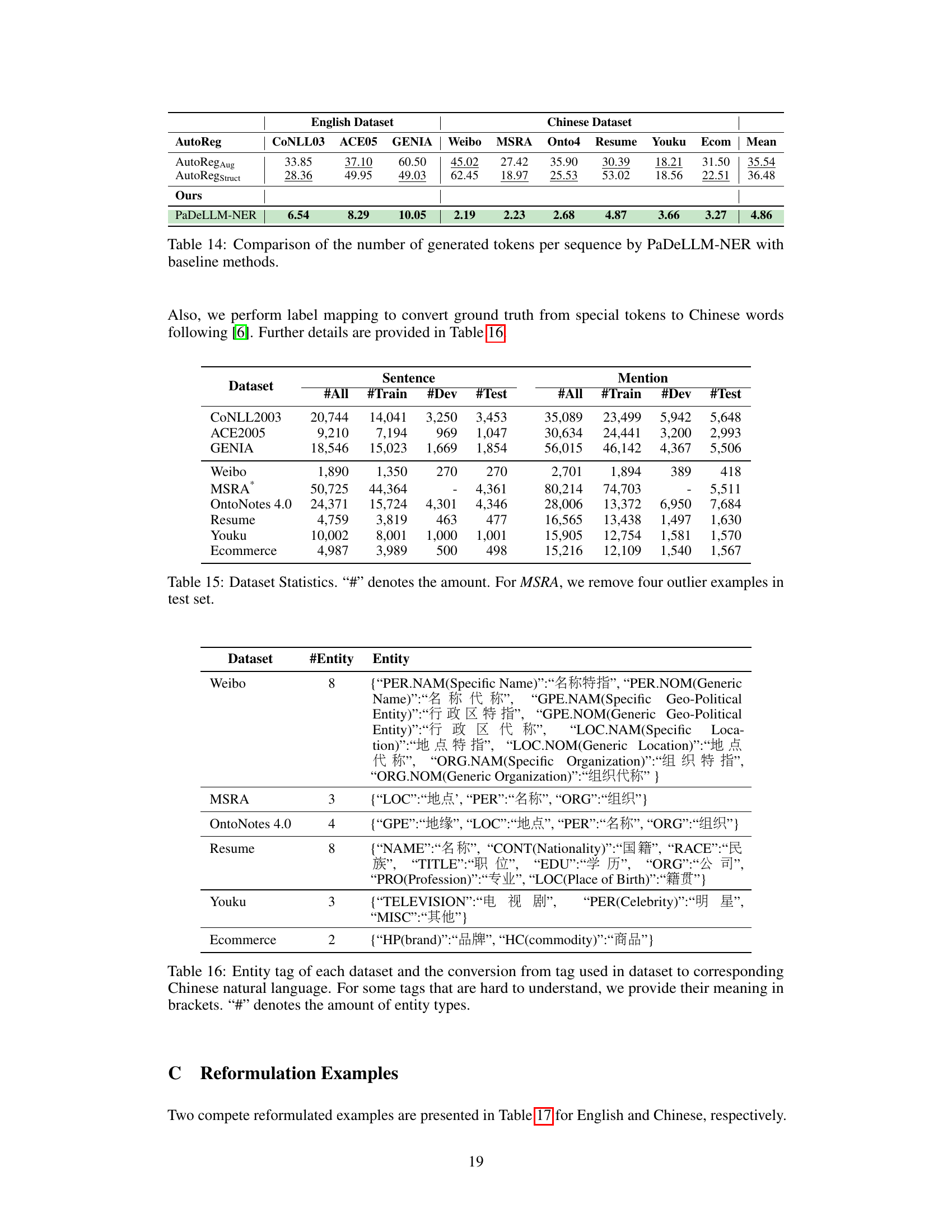
This table compares the average number of generated tokens per sequence for the proposed PaDeLLM-NER model and several baseline methods across various English and Chinese NER datasets. It highlights the significant reduction in the number of tokens generated by PaDeLLM-NER compared to the autoregressive baselines, demonstrating its efficiency in terms of sequence length.
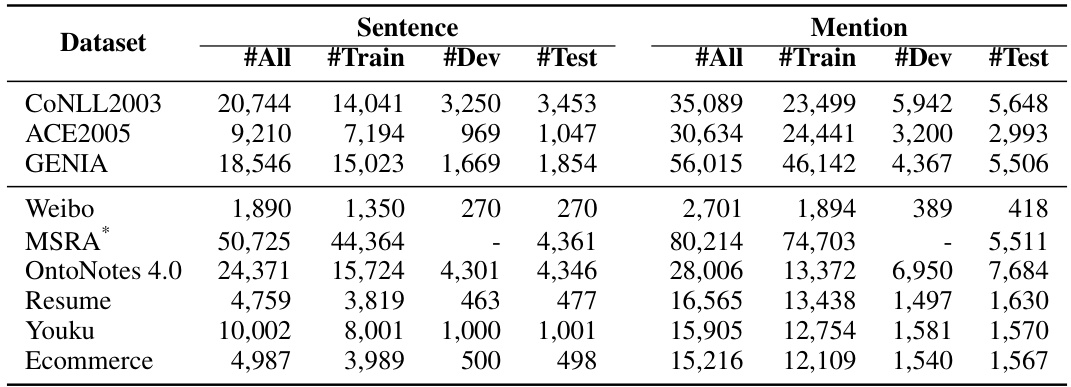
This table compares the inference latency (in milliseconds) of the PaDeLLM-NER model against several baseline methods across various English and Chinese NER datasets. It highlights the significant speedup achieved by PaDeLLM-NER in comparison to traditional autoregressive approaches. The best and second-best performing methods are indicated using bold and underlined fonts, respectively.

This table compares the inference latency, in milliseconds, of the PaDeLLM-NER model against several baseline methods across various English and Chinese datasets. It shows how much faster PaDeLLM-NER is compared to the other methods, highlighting its improved efficiency. The best and second-best performing methods are emphasized in bold and underlined font, respectively, for each dataset and are also used in other relevant tables of the paper.

This table compares the inference latency in milliseconds of the PaDeLLM-NER model against several baseline methods across multiple English and Chinese NER datasets. It highlights the significant speed improvements achieved by PaDeLLM-NER.
This table compares the inference latency in milliseconds of the proposed PaDeLLM-NER method against several baseline methods across various English and Chinese NER datasets. The latency reflects the time taken for the model to generate the output. The best and second-best performing methods for each dataset are highlighted.
Full paper#