↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep neural networks often struggle with domain generalization, especially due to a tendency to rely on simple, easily learnable patterns (frequency shortcuts) rather than actual semantic information. This “simplicity bias” leads to poor performance on unseen data. Existing data augmentation techniques, while attempting to improve performance, ironically reinforce this tendency by increasing the usage of frequency shortcuts.
This research tackles this issue by directly manipulating the statistical structure of the dataset in the Fourier domain. The authors propose two novel data augmentation techniques—Adversarial Amplitude Uncertainty Augmentation (AAUA) and Adversarial Amplitude Dropout (AAD)—designed to adaptively adjust the learning difficulty of different frequency components, thus actively preventing the model from focusing on frequency shortcuts. These methods are shown to significantly improve the model’s generalization abilities across various benchmarks, effectively addressing the simplicity bias and the limitations of earlier data augmentation strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in domain generalization due to its novel approach to combat frequency simplicity bias. It directly addresses the limitations of previous data augmentation techniques by proposing effective methods to manipulate dataset frequency characteristics, thereby improving generalization performance. This opens new avenues for research in understanding and mitigating shortcut learning in deep neural networks, enhancing the robustness and generalizability of AI models.
Visual Insights#
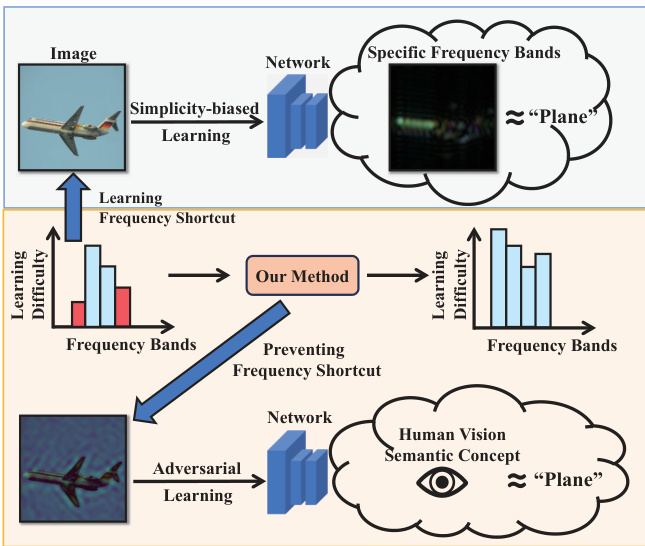
The figure illustrates the problem of frequency simplicity bias in deep learning models for image classification. Models tend to focus on easily identifiable frequency patterns rather than semantic information, leading to poor generalization. The authors’ proposed method addresses this by dynamically adjusting the learning difficulty of different frequency components, preventing models from relying on simple frequency shortcuts and promoting learning based on more robust, semantic information.
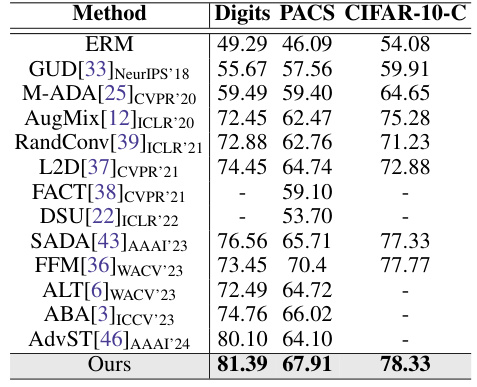
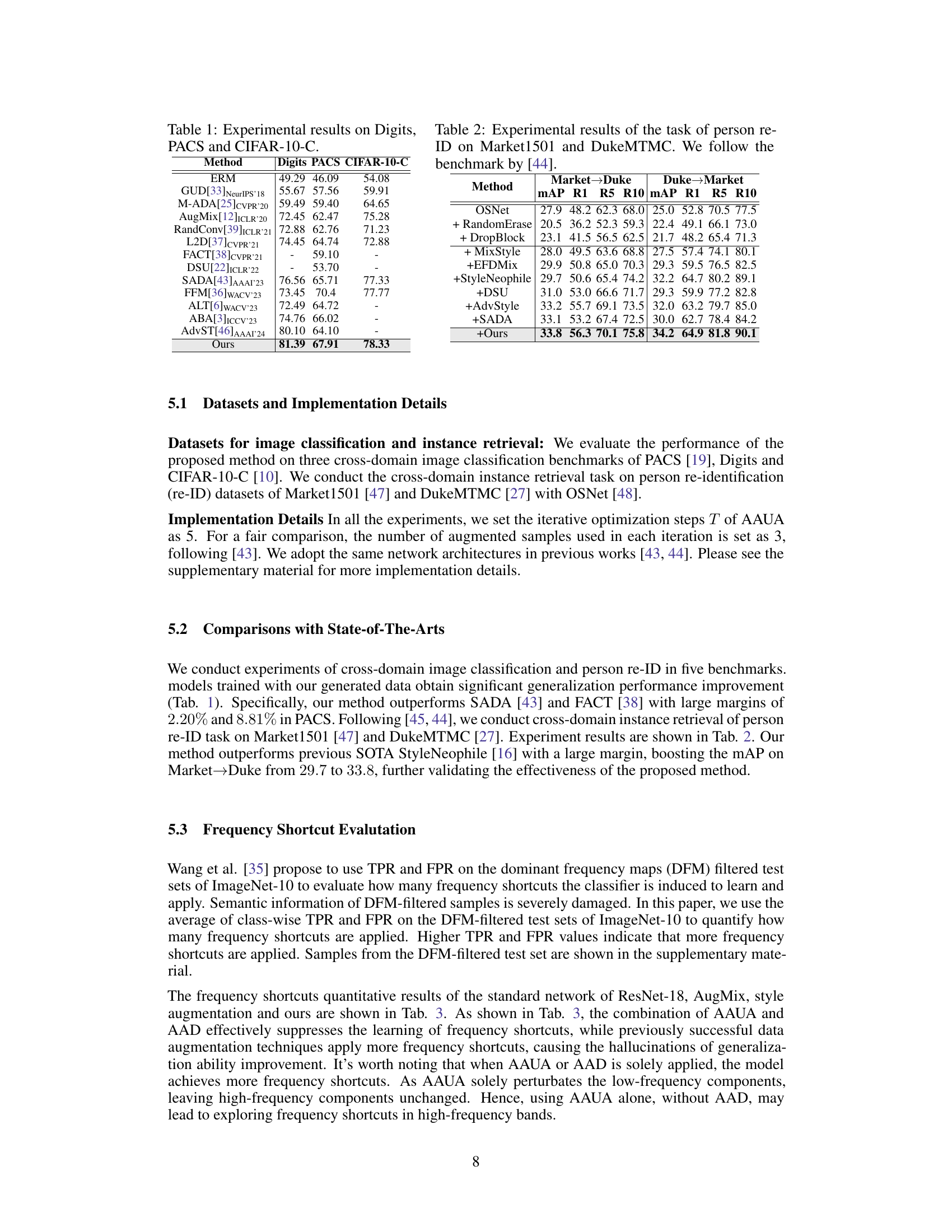
This table presents a comparison of the proposed method’s performance against several state-of-the-art domain generalization methods on three benchmark datasets: Digits, PACS, and CIFAR-10-C. Each dataset presents unique challenges for domain generalization, and the results demonstrate the effectiveness of the proposed approach in improving generalization performance across these diverse datasets. The table shows accuracy scores for each method on each dataset, allowing for a direct comparison of their relative strengths and weaknesses.
In-depth insights#
Frequency Bias#
Frequency bias in deep learning models refers to the tendency of these models to prioritize learning from lower spatial frequencies present in the input data, often at the expense of higher frequencies that might contain crucial details. This phenomenon, also known as spectral bias, arises from the optimization process itself, where the model learns simpler solutions with lower-frequency patterns earlier in training. This bias can significantly impact the model’s generalization ability, as it might lead to an overreliance on these readily available low-frequency features, creating an inability to adapt effectively to unseen data with varying frequency characteristics. This effect is exacerbated when the dataset exhibits a strong frequency-based correlation to the labels (frequency shortcuts). Consequently, mitigating frequency bias is crucial for enhancing model robustness and generalization. While data augmentation techniques have been previously employed to tackle this issue, studies suggest that these methods inadvertently encourage the use of more frequency shortcuts, thereby highlighting the need for more sophisticated approaches. Future research must investigate methods that address the underlying causes of frequency bias in the optimization process, rather than only focusing on symptom mitigation, potentially by exploring more advanced regularization strategies or altering the optimization landscape to encourage a balanced consideration of all frequency bands.
AAUA & AAD#
The proposed adversarial frequency augmentation modules, AAUA and AAD, represent a novel approach to combatting frequency simplicity bias in domain generalization. AAUA (Adversarial Amplitude Uncertainty Augmentation) injects adversarial noise into low-frequency components, leveraging instance normalization to create aggressive augmentations and disrupt the dataset’s structure. This prevents over-reliance on easily learned, yet non-generalizable, low-frequency patterns. AAD (Adversarial Amplitude Dropout) complements AAUA by addressing potential overfitting to high-frequency noise. It uses gradients to identify and selectively drop highly dependent frequency components, further enhancing generalization. The combined effect is a dynamic and adaptive modification of the frequency characteristics of the dataset, forcing the model to rely less on spurious correlations and more on semantic information, leading to improved generalization performance in various domain generalization tasks.
Shortcut Learning#
Shortcut learning in deep neural networks is a significant concern, as models may prioritize easily learned, superficial patterns (shortcuts) over genuine semantic understanding. This simplicity bias can lead to impressive performance on training data but catastrophic failure when encountering unseen data, hindering generalization. Frequency shortcuts, a specific type of shortcut, exploit statistical regularities in the data’s frequency domain, rather than true semantic information. Data augmentation techniques, while sometimes improving overall performance, often inadvertently enhance these frequency shortcuts, leading to illusory gains in generalization. Therefore, combating shortcut learning requires not merely improving overall accuracy, but strategically targeting and disrupting these shortcut-learning behaviors by analyzing and manipulating the data’s frequency characteristics. Effective solutions must go beyond simple data augmentation and should focus on understanding how models leverage frequency components for classification, paving the way for robust domain generalization.
Generalization#
The concept of generalization within machine learning, especially deep learning, is central to the paper’s investigation. The core problem addressed is the poor generalization ability of neural networks when encountering data from unseen domains (domain generalization). This is particularly challenging in single-source domain generalization (SDG) scenarios where only one source domain is available for training. The authors argue that this limitation stems from a simplicity-bias in the learning process, leading models to over-rely on specific frequency components (frequency shortcuts) rather than semantic information. This shortcut learning behavior significantly hinders the model’s ability to generalize to new, unseen data. Therefore, the proposed solution focuses on combating this simplicity bias by manipulating the frequency characteristics of the training data through novel data augmentation techniques. The goal is to dynamically influence the network’s learning behavior, thereby reducing reliance on frequency shortcuts and promoting true generalization to unseen target domains. This approach leverages a data-driven perspective, modifying the statistical structure of the dataset in the Fourier domain to directly impact the learning process and prevent shortcut learning.
Future Work#
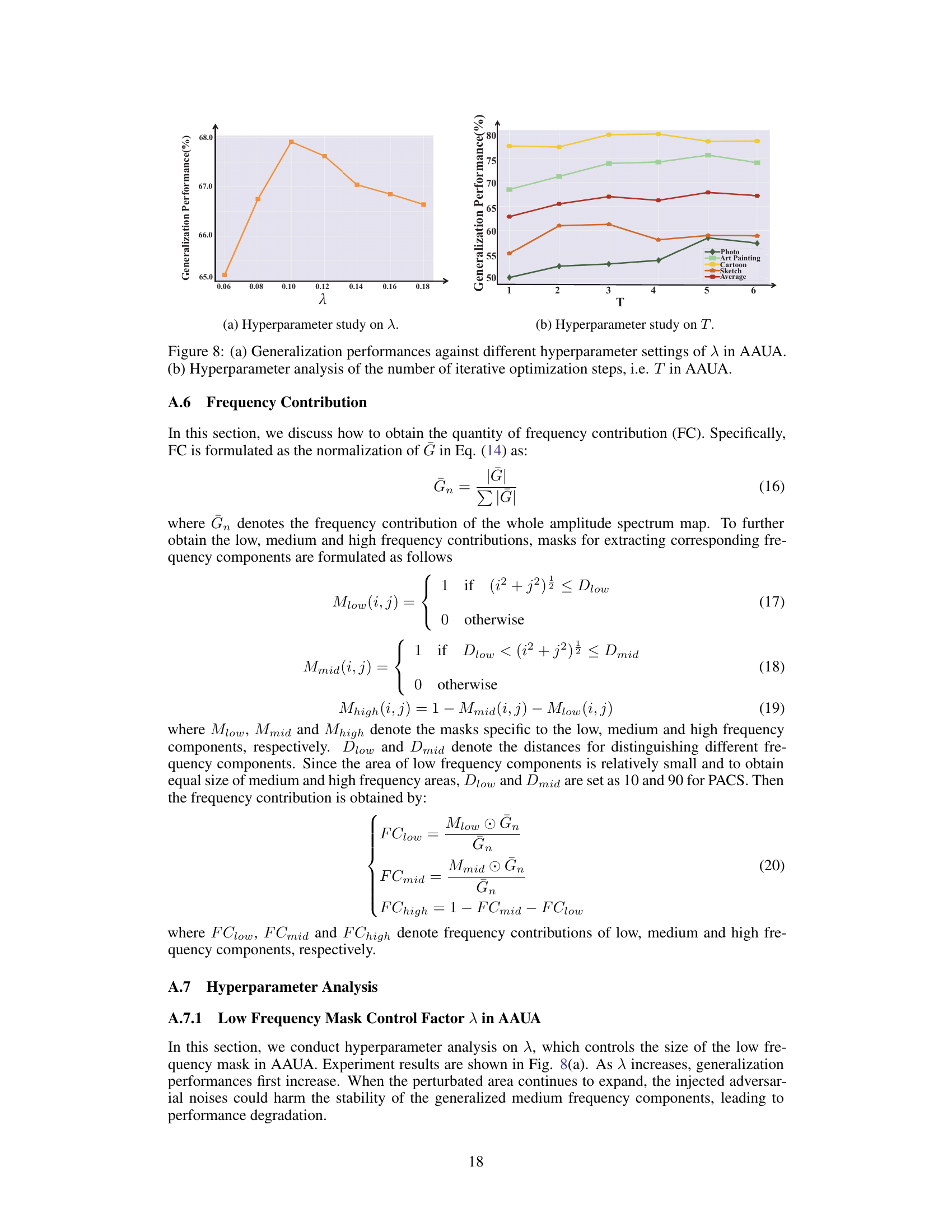
The paper’s core contribution addresses the limitations of current domain generalization methods, which often rely on easily-learned frequency shortcuts rather than semantic understanding. Future work could explore more sophisticated techniques to directly identify and mitigate these shortcuts. This might involve developing methods to explicitly detect and penalize the use of frequency-based features during training, perhaps through novel loss functions or regularization techniques. Another crucial area is extending the approach to handle more complex datasets and broader range of domain generalization tasks beyond image classification and person re-identification. Robustness analysis is also essential. The current methods’ sensitivity to hyperparameter tuning needs further investigation, aiming to develop more robust and less sensitive methods. Finally, theoretical investigations into the interplay between dataset frequency characteristics, model architecture and the emergence of frequency shortcuts would yield valuable insights into effective mitigation strategies.
More visual insights#
More on figures
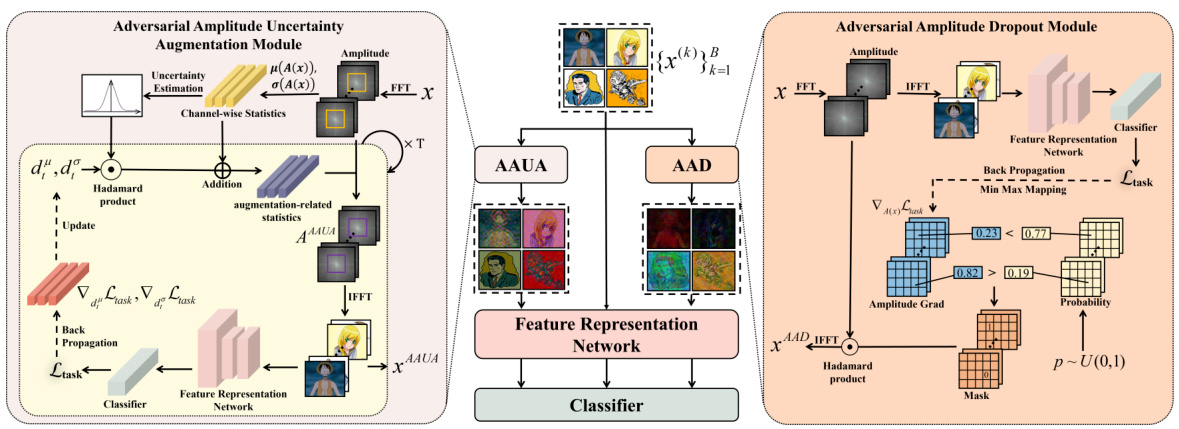
This figure illustrates the two proposed adversarial frequency augmentation modules: Adversarial Amplitude Uncertainty Augmentation (AAUA) and Adversarial Amplitude Dropout (AAD). AAUA injects adversarial noises into the low-frequency components to modify the frequency spectrum of the dataset structure and prevent the learning of frequency shortcuts. AAD utilizes adversarial gradients to estimate the model’s frequency characteristics and adaptively masks the over-reliance frequency bands to further prevent frequency shortcut learning. Both modules dynamically adjust the frequency characteristics of the dataset, aiming to influence the learning behavior of the model and mitigate shortcut learning. The figure shows the detailed architecture and working of each module, including input image, FFT, channel-wise statistics, Hadamard product, IFFT, classifier, and backpropagation steps.
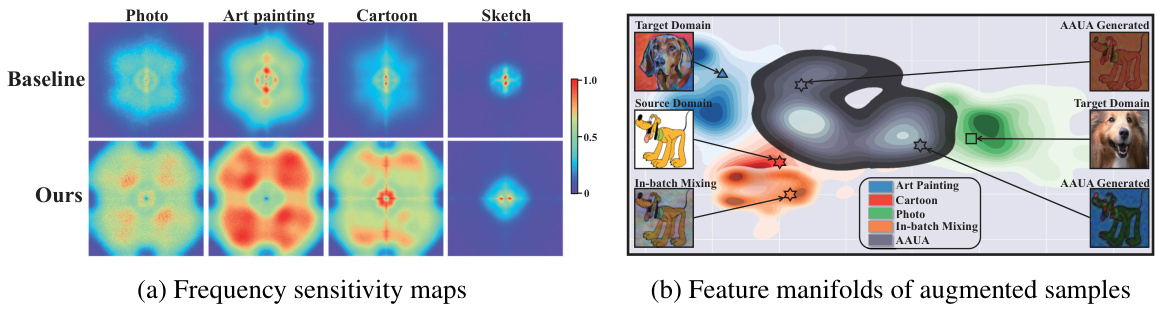
This figure shows the frequency sensitivity maps of a model trained with and without the proposed method. The left panel (a) shows that the model trained without the proposed method focuses on low frequencies, while the model trained with the proposed method focuses on both low and high frequencies. The right panel (b) shows the feature manifolds of augmented samples generated by different methods. The proposed method generates more diverse augmented samples, which improves the model’s generalization ability.
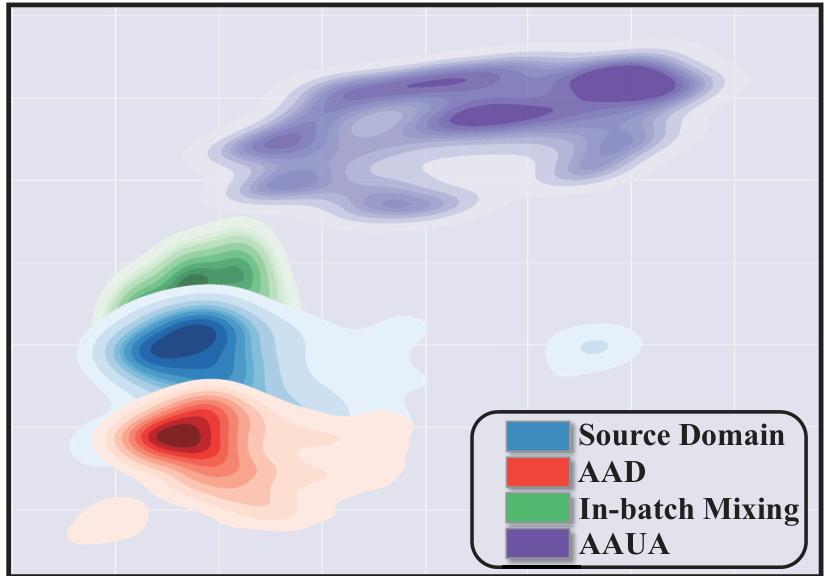
This figure visualizes the feature manifolds of images from the source domain and those augmented by different methods: AAD (Adversarial Amplitude Dropout), in-batch mixing, and AAUA (Adversarial Amplitude Uncertainty Augmentation). t-SNE (t-distributed Stochastic Neighbor Embedding) is used to reduce the dimensionality of the feature space for visualization. The figure shows how the different augmentation methods affect the distribution of features. The goal is to demonstrate that the proposed AAUA method explores a broader augmentation space compared to traditional methods, potentially leading to improved generalization.

This figure shows the frequency sensitivity maps and feature manifolds to demonstrate the impact of the proposed method on model’s learning behavior. The left panel (a) visualizes the model’s sensitivity to different frequency components in both source and target domains. The right panel (b) visualizes the feature manifolds of augmented samples generated by the proposed method, showing how the method effectively manipulates the frequency characteristics of the data and influences the model’s learning behavior.

This figure shows the architecture of the two proposed adversarial frequency augmentation modules: Adversarial Amplitude Uncertainty Augmentation (AAUA) and Adversarial Amplitude Dropout (AAD). AAUA adds uncertainty to the amplitude of low-frequency components to prevent models from relying on simple solutions, while AAD drops amplitude of specific frequency components to prevent shortcut learning. Both modules are designed to work together to dynamically adjust the frequency characteristics of the dataset and prevent the model from using frequency shortcuts.

This figure shows example images from the ImageNet-10 dataset. The left column displays the original images. The right column displays the same images after being filtered to remove dominant frequency components (DFM-filtered). The filtering process aims to eliminate shortcut learning by neural networks, which often over-rely on easily distinguishable visual cues rather than semantic content. The blurring effect in the DFM-filtered images illustrates the removal of those easily identifiable high-frequency components.
This figure illustrates the two proposed adversarial frequency augmentation modules: Adversarial Amplitude Uncertainty Augmentation (AAUA) and Adversarial Amplitude Dropout (AAD). AAUA injects adversarial noise into low-frequency components to disrupt the dataset structure and prevent shortcut learning. AAD uses gradients to identify and drop highly dependent high-frequency components, further preventing shortcut learning. Both modules dynamically modify the frequency characteristics, aiming to manipulate the model’s learning behavior and enhance generalization performance. The modules are designed to work collaboratively and adaptively, ultimately helping prevent the learning of frequency shortcuts.
More on tables
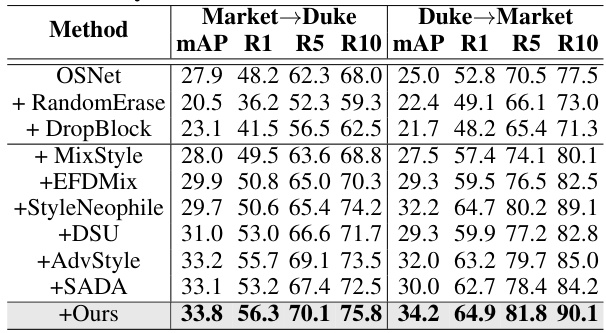
This table presents the experimental results for person re-identification (re-ID) task on two benchmark datasets: Market1501 and DukeMTMC. The results compare the proposed method’s performance against several state-of-the-art (SOTA) techniques. The metrics used for evaluation are mean Average Precision (mAP), Rank-1 (R1), Rank-5 (R5), and Rank-10 (R10) accuracy. The table shows the performance of each method on both the Market->Duke and Duke->Market cross-domain settings.
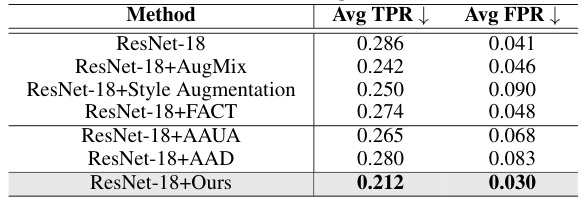
This table presents a quantitative evaluation of frequency shortcuts using the metrics Average True Positive Rate (Avg TPR) and Average False Positive Rate (Avg FPR) on a DFM-filtered test set of ImageNet-10. It compares different methods: a ResNet-18 baseline, ResNet-18 with AugMix, ResNet-18 with Style Augmentation, ResNet-18 with FACT, ResNet-18 with AAUA, ResNet-18 with AAD, and finally, ResNet-18 with the proposed method (Ours). Lower Avg TPR and Avg FPR values indicate fewer frequency shortcuts.
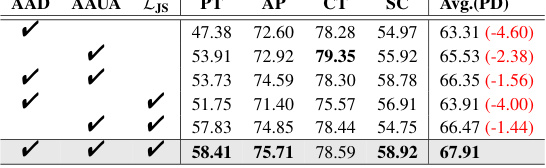
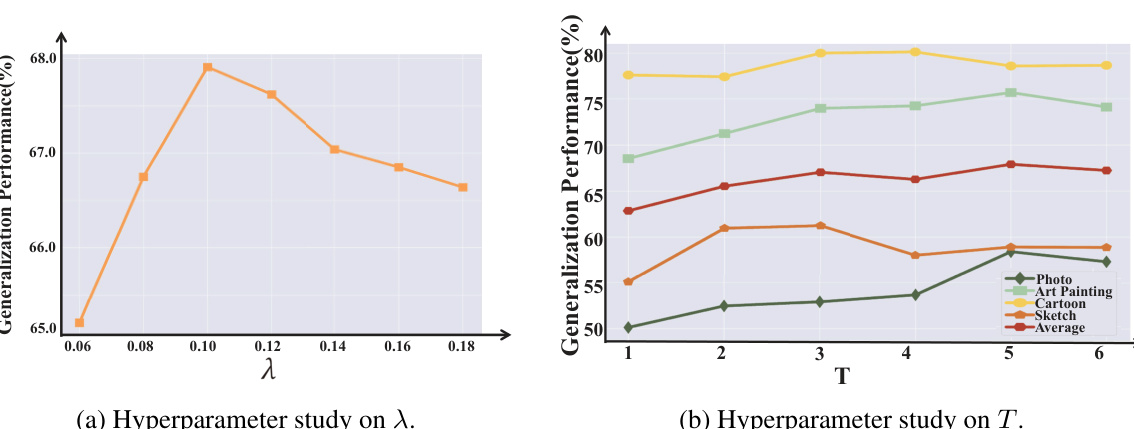
This table presents the results of ablation studies performed on the PACS dataset to evaluate the contribution of each component of the proposed method. The method combines adversarial amplitude uncertainty augmentation (AAUA), adversarial amplitude dropout (AAD), and a Jensen-Shannon divergence consistency loss (LJS). The table shows the performance (average precision across four classes) when one or more components are removed from the full method. The PD column indicates the performance degradation compared to using all components. The results demonstrate the impact of each component on the overall performance.
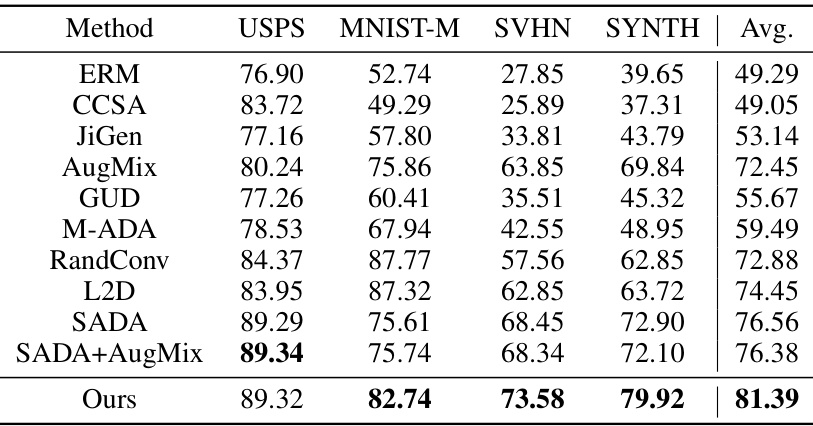
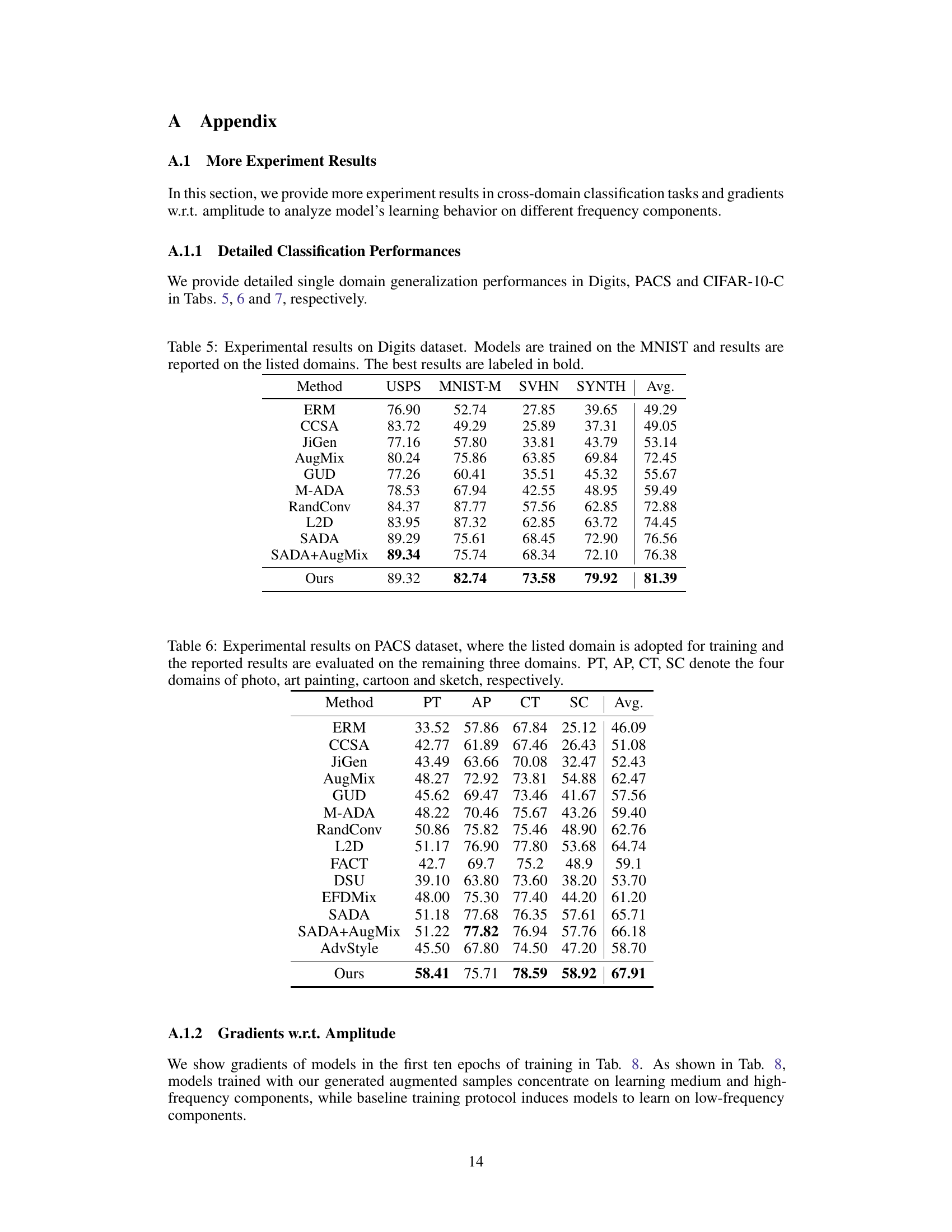
This table presents the performance comparison of different domain generalization methods on the Digits dataset. The models were trained on the MNIST dataset and evaluated on USPS, MNIST-M, SVHN, and SYNTH datasets. The average performance across these datasets is also provided. The best performing method for each dataset is highlighted in bold. The table shows the average accuracy for each method across the four target domains.

This table presents the experimental results on the PACS dataset for cross-domain image classification. The model is trained on one of the four domains (photo, art painting, cartoon, sketch) and then evaluated on the remaining three domains. The average performance across all four domains is also reported for each method.
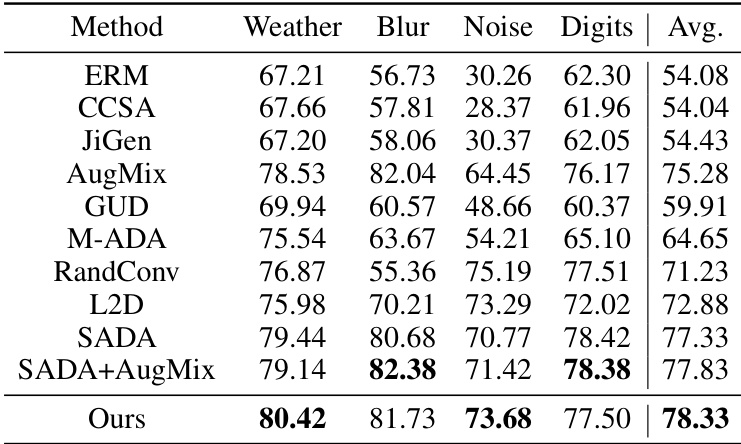
This table presents the average accuracy of different domain generalization methods on the CIFAR-10-C dataset. CIFAR-10-C is a benchmark dataset for evaluating robustness to common corruptions. Models are trained on the standard CIFAR-10 dataset and tested on CIFAR-10-C images corrupted by various types of noise (weather, blur, noise). The results show the performance of various methods (ERM, CCSA, JiGen, AugMix, GUD, M-ADA, RandConv, L2D, SADA, SADA+AugMix, and the proposed method ‘Ours’) across different corruption types. The ‘Avg.’ column shows the average performance across all four corruption types.
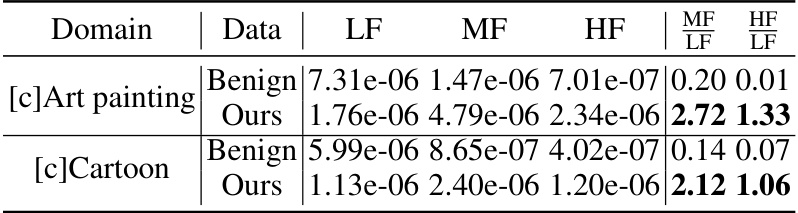
This table shows the mean of the absolute values of backward gradients on different frequency components (low, medium, and high frequencies) of the amplitude spectrum maps for the first ten epochs of training. A higher value indicates that more gradients were used to learn that specific frequency component. The data is from a pre-trained ResNet-18 model. The table helps to visualize how the model focuses its learning across different frequencies.
Full paper#