↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current zero-shot text-to-speech models struggle with generating natural-sounding, multi-speaker dialogues. This is because spontaneous speech contains complex phenomena like overlaps, interjections, and varied speaking styles that are hard to model, and there is a scarcity of high-quality datasets. Existing methods often synthesize each speaker individually then combine them, resulting in unnatural-sounding transitions and a lack of conversational flow.
CoVoMix tackles this problem by simultaneously generating multiple speaker streams from dialogue text, using a flow-matching based acoustic model to mix these audio streams into a single channel, and evaluating the result with new metrics designed for this specific task. The results demonstrate that CoVoMix generates more natural and coherent dialogues with seamless speaker transitions and simultaneous speaker interactions (like laughter). This is a significant contribution because it greatly improves the quality and human-likeness of AI-generated conversations.
Key Takeaways#
Why does it matter?#
This paper is important because it presents CoVoMix, a novel approach to generating human-like multi-talker conversations, addressing a significant challenge in zero-shot speech generation. It introduces a new evaluation metric and paves the way for more realistic and natural-sounding AI conversations. This research directly contributes to the advancement of conversational AI and has strong implications for various applications, including virtual assistants, video game characters, and accessibility tools.
Visual Insights#
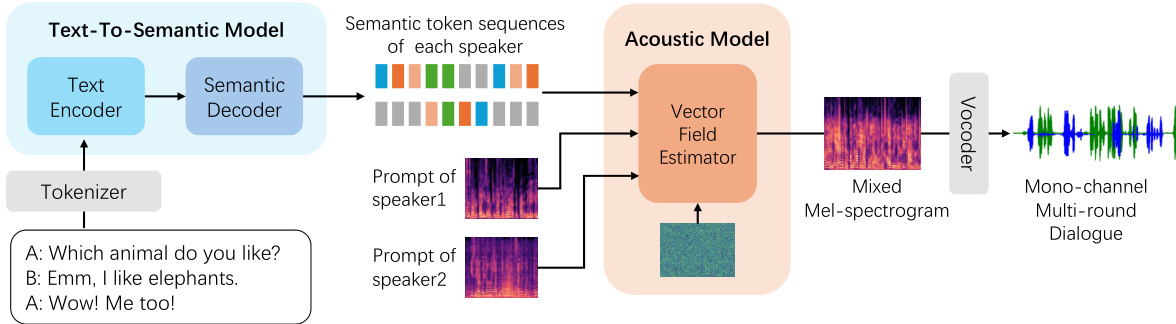
The figure provides a high-level overview of the CoVoMix framework, illustrating its three main components: 1) a multi-stream text-to-semantic model that processes dialogue text and generates separate semantic representations for each speaker; 2) a conditional flow-matching based acoustic model that takes the semantic representations and speaker prompts as input to generate a mixed mel-spectrogram representing the combined speech of all speakers; and 3) a HiFi-GAN vocoder that converts the mel-spectrogram into a final waveform representing the generated speech. The example text shows a simple multi-turn dialogue between two speakers, A and B. The figure clearly depicts the flow of information from text input to final speech output, highlighting the key steps and components of the CoVoMix architecture.
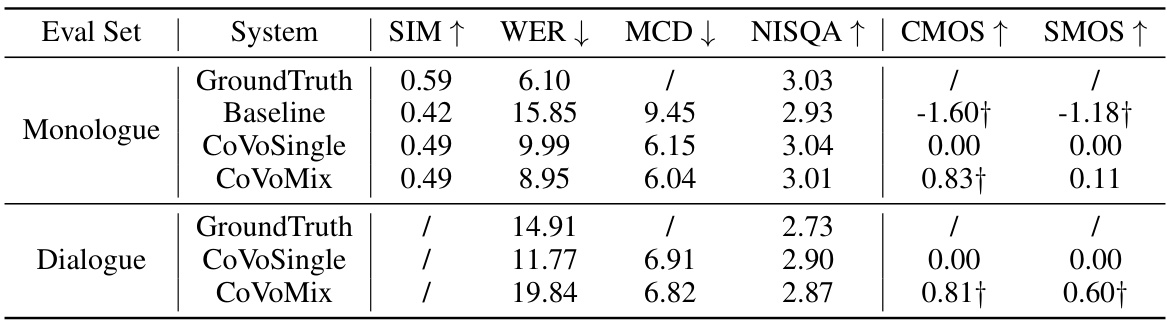
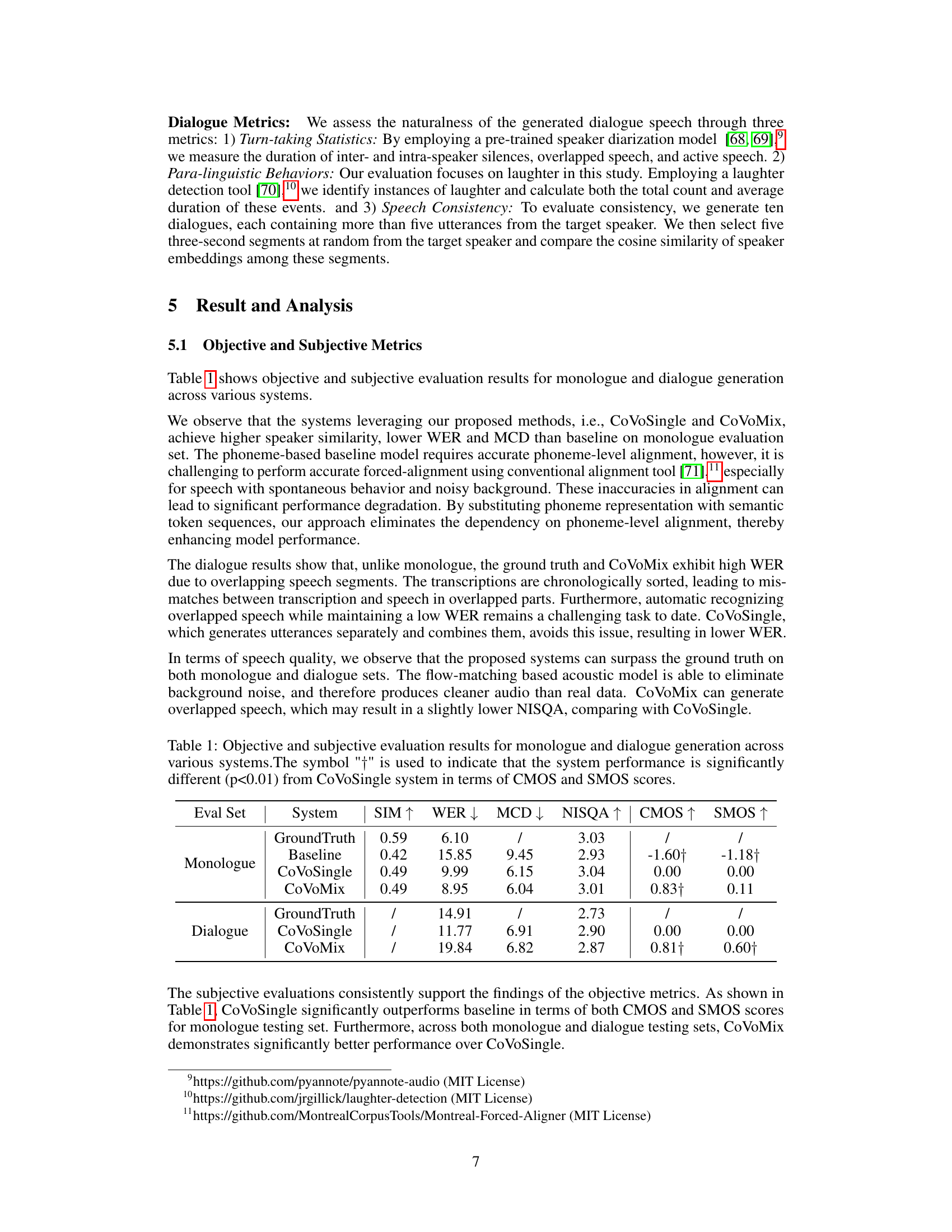
This table presents a comparison of objective and subjective evaluation metrics for different speech generation systems on both monologue and dialogue datasets. The objective metrics include Speaker Similarity (SIM), Word Error Rate (WER), Mel Cepstral Distortion (MCD), and Naturalness and Speech Quality Assessment (NISQA). Subjective metrics consist of Comparative Mean Opinion Score (CMOS) for naturalness and overall flow of conversation, and Speaker Mean Opinion Score (SMOS) to evaluate the consistency of the speaker’s voice. The systems compared are a phoneme-based baseline, CoVoSingle (a system trained on monologue data), and CoVoMix (a system trained on both monologue and dialogue data). The results demonstrate CoVoMix’s superior performance in terms of naturalness, speaker consistency, and overall dialogue flow compared to other methods.
In-depth insights#
Zero-Shot TTS Advance#
Zero-shot text-to-speech (TTS) represents a significant advancement in speech synthesis, enabling the generation of speech in unseen voices using only a text transcript and a short audio sample. This eliminates the need for extensive voice-specific training data, a major hurdle in traditional TTS. Key advances in zero-shot TTS include the use of diffusion models and neural codecs. Diffusion models excel at producing high-fidelity audio, while neural codecs offer efficient representations and generation. The ability to generate spontaneous-style speech, such as casual conversations with overlapping speech and natural pauses, is a key challenge. Existing datasets often lack the diversity and size necessary to train robust models capable of handling these nuances. Future research should focus on creating larger, more diverse datasets and advancing model architectures to better capture the complexities of human-like dialogue. Furthermore, the integration of zero-shot TTS with other technologies, such as speaker diarization and voice conversion, holds exciting potential for creating more realistic and versatile conversational AI systems. Ethical considerations surrounding the potential misuse of such technology, like creating deepfakes, require careful attention. Overall, zero-shot TTS is a rapidly evolving field with the potential to revolutionize various applications, from accessibility tools to interactive virtual assistants.
CoVoMix Framework#
The CoVoMix framework represents a novel approach to zero-shot multi-talker speech generation, focusing on creating human-like conversations. It’s a multi-stage process starting with a multi-stream text-to-semantic model which processes dialogue text and generates discrete semantic token sequences for each speaker, thus enabling simultaneous generation of speech. These token streams are fed into a flow-matching based acoustic model producing a mixed mel-spectrogram. This clever design allows for the natural mixing of voices and overlapping speech, a hallmark of human conversations. Finally, a HiFi-GAN based vocoder converts the mixed mel-spectrogram into waveforms. The use of flow-matching is particularly noteworthy as it enables efficient generation of high-quality speech while handling complexities inherent in multi-speaker interactions. Overall, the framework’s strength lies in its ability to create natural sounding multi-talker dialogues in a zero-shot setting, demonstrating significant advancement in conversational AI.
Multi-Speaker Modeling#
Multi-speaker modeling in speech synthesis presents unique challenges compared to single-speaker systems. The primary difficulty lies in managing the temporal dynamics of multiple speakers, including overlaps, interruptions, and turn-taking. Successful models must accurately predict not only the individual speech segments of each speaker, but also their timing relative to one another. This requires sophisticated mechanisms for modeling speaker-specific characteristics and their interactions. Another key aspect is handling the acoustic mixing of multiple voices, which necessitates a deep understanding of sound propagation and interference. A well-designed system should be able to generate realistic, natural-sounding multi-speaker speech that is free of artifacts due to poorly managed mixing. Zero-shot multi-speaker speech synthesis, where the model can synthesize speech from unseen speakers with limited data, is an even more demanding task. It calls for a more advanced representation that encapsulates speaker identity effectively and can extrapolate to new voices. Approaches could be explored that focus on disentangling speaker identity from content and prosody, allowing for flexible control over the generated speech.
Dialogue Evaluation#
Evaluating dialogue systems presents unique challenges compared to evaluating single-speaker systems. Metrics must go beyond simple accuracy and address the nuances of natural conversation. Turn-taking analysis, measuring the timing and overlap of speaker turns, is crucial. Para-linguistic features, like laughter and interjections, need careful consideration; automatic detection methods must be validated for accuracy. Assessing coherence is vital; metrics should quantify how well the dialogue flows, avoids abrupt transitions, and maintains context. Speaker consistency requires verifying consistent characteristics (voice, style) across a speaker’s turns. Subjective evaluations, involving human judges rating naturalness and engagement, are essential to complement objective metrics. Combining objective and subjective measures provides a more holistic evaluation. Finally, the choice of metrics should depend on the specific goals of the dialogue system, such as generating human-like or task-oriented conversations.
Future Research#
Future research directions stemming from this work on conversational voice mixture generation (CoVoMix) should prioritize addressing the limitations of the current model. Improving the text-to-semantic model to reduce omitted or duplicated words is crucial, potentially through model scaling or incorporating pre-trained models. Addressing the use of a low-quality dataset by employing super-resolution techniques to enhance training data fidelity is vital. Furthermore, exploring the use of alternative acoustic models, beyond the flow-matching approach, could improve both speech quality and naturalness. Investigating alternative techniques to accurately manage overlapped speech during multi-speaker dialogue synthesis is also needed. Finally, extending the research to incorporate diverse languages and cultures, enhancing its generalization capabilities, would expand CoVoMix’s utility and impact. A significant aspect is also assessing the ethical implications and potential risks of this technology, including safeguards against malicious use and techniques to detect synthetic speech. These advancements will drive CoVoMix toward becoming a more robust, reliable, and ethically responsible technology for conversational speech synthesis.
More visual insights#
More on figures

This figure shows an example of how dialogue transcriptions are prepared for the CoVoMix model. The example illustrates how the model handles multiple speakers and various spontaneous behaviors such as laughter. Each utterance is represented by a numbered segment, separated by a special token ‘|’, representing the transition between speakers, and laughter is represented using an emoji. This highlights the process of preparing data that incorporates natural, conversational speech features.

This figure visualizes the distribution of four turn-taking activities in dialogues: intra-speaker pause, inter-speaker silence, overlapped segments, and active speech. It compares the distributions generated by the CoVoMix and CoVoSingle models against the ground truth. The goal is to show how well each model replicates the natural timing and pauses found in human conversations. The blue and green lines represent the median and mean duration of each activity, respectively. A closer match to the ground truth indicates more natural and human-like dialogue generation.

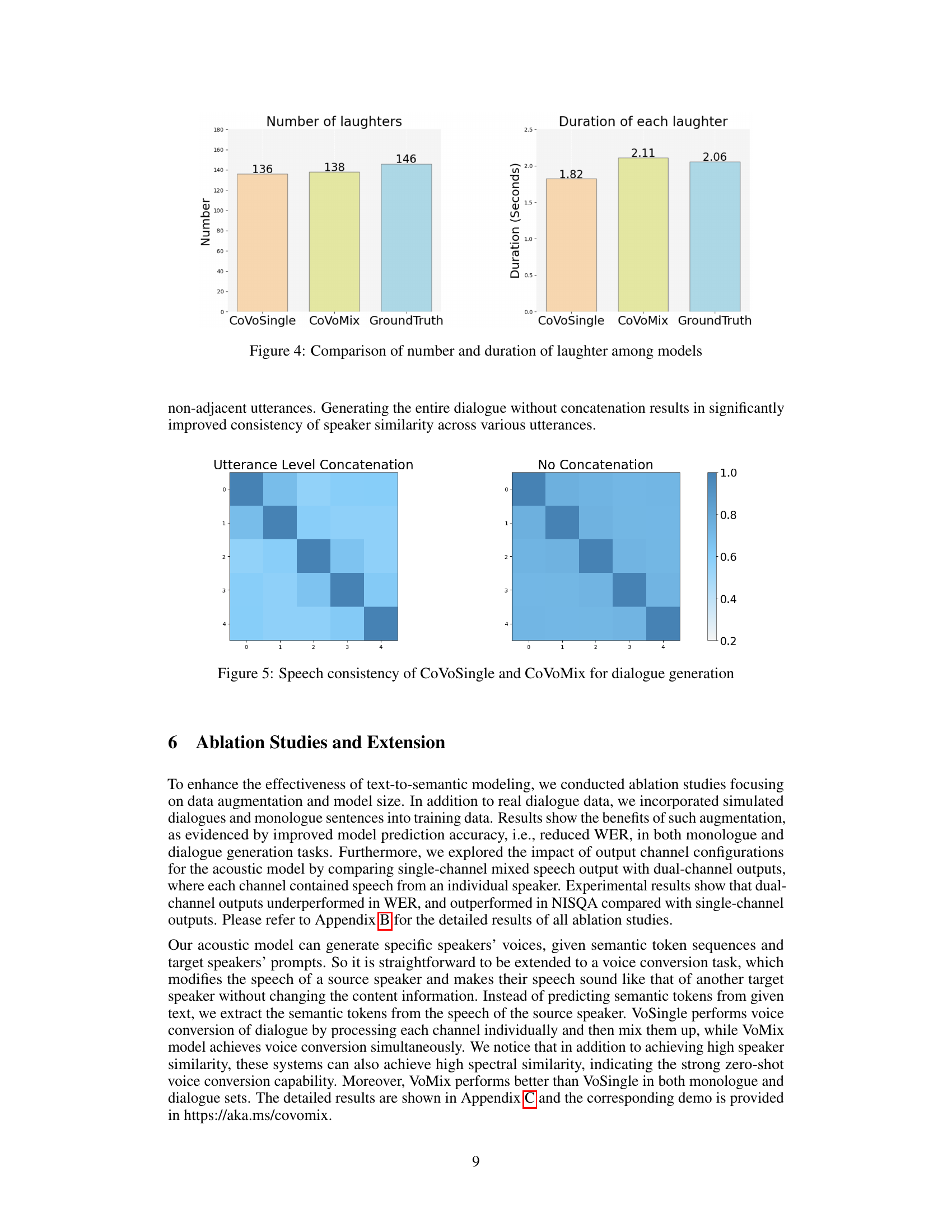
This figure compares the number and duration of laughter instances generated by three different models: CoVoSingle, CoVoMix, and the ground truth. It visually represents the performance of each model in generating human-like laughter, a key aspect of natural and spontaneous speech. The bar charts show that CoVoMix achieves a balance between the number and duration of laughter instances similar to the ground truth, while CoVoSingle generates significantly fewer instances of laughter.

This figure presents a heatmap comparing the speaker consistency between different utterances in dialogues generated by two different methods: CoVoSingle (utterance-level concatenation) and CoVoMix (no concatenation). The heatmaps show the cosine similarity between pairs of utterances. Lighter shades indicate lower speaker similarity, highlighting that utterance-level concatenation in CoVoSingle leads to inconsistent speaker characteristics, whereas CoVoMix, generating the entire dialogue without concatenation, demonstrates significantly improved consistency in speaker characteristics across various utterances.
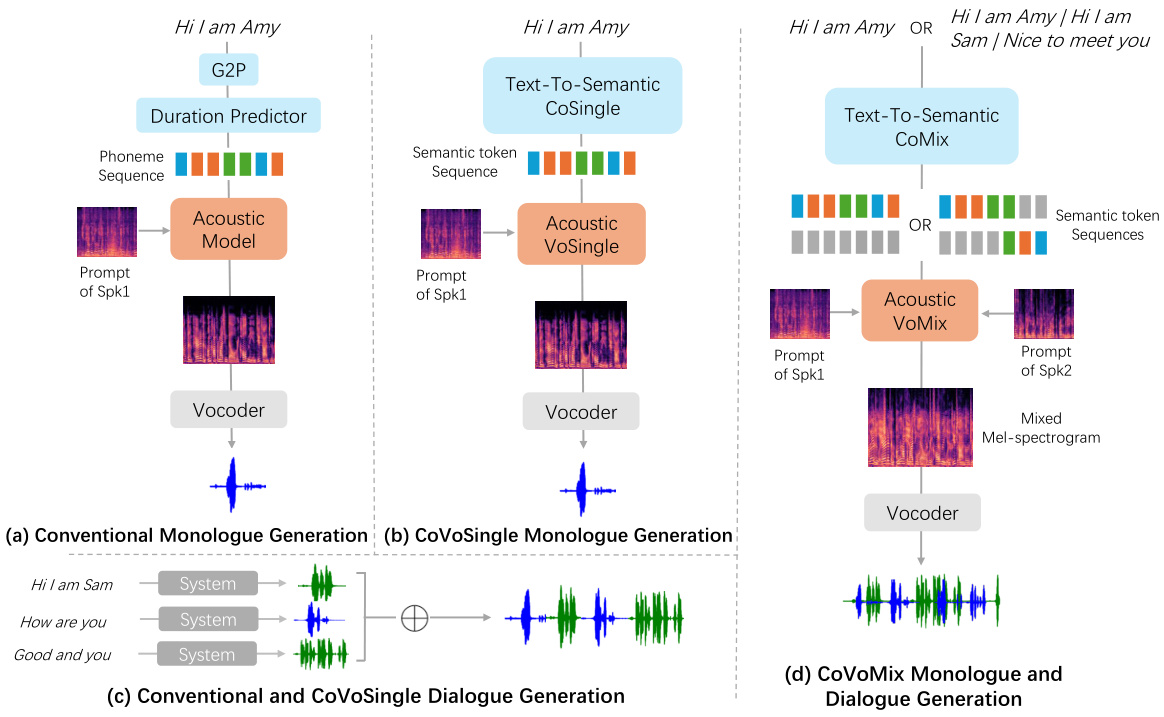
This figure compares four different methods for speech generation: conventional monologue generation using phoneme representation, CoVoSingle monologue generation, conventional and CoVoSingle dialogue generation by concatenating single utterances, and CoVoMix monologue and dialogue generation. The conventional method uses a G2P (grapheme-to-phoneme) conversion and a duration predictor before an acoustic model and vocoder generate speech. CoVoSingle utilizes a text-to-semantic model to generate semantic token sequences, followed by an acoustic model and vocoder. The conventional dialogue method concatenates individual speech segments generated using either the conventional or CoVoSingle methods. CoVoMix, in contrast, uses a multi-stream text-to-semantic model to generate simultaneous semantic tokens for multiple speakers, feeding them to an acoustic model which generates a mixed mel-spectrogram before a vocoder produces the final speech. This figure illustrates the fundamental differences in architecture and functionality between the approaches, highlighting CoVoMix’s ability to handle multi-speaker dialogues in a more sophisticated and natural-sounding manner.

This figure shows the architecture of the text-to-semantic model. It presents two variations: CoSingle and CoMix. CoSingle uses a single-stream decoder to produce a single semantic token sequence, while CoMix uses a multi-stream decoder to generate multiple semantic token sequences, each corresponding to a different speaker in a conversation. This is a crucial element of the CoVoMix system, allowing the model to handle multi-speaker dialogues.

This figure shows the architecture of the acoustic model used in the CoVoMix system. It illustrates the flow-matching process (a) where an ordinary differential equation updates a sample mel-spectrogram towards the target. The model architecture (b) shows how the vector field estimator is used with transformer encoders to generate mixed mel-spectrograms for different configurations: VoSingle (single-speaker), VoMix (mixed), and VoMix-Stereo (stereo).
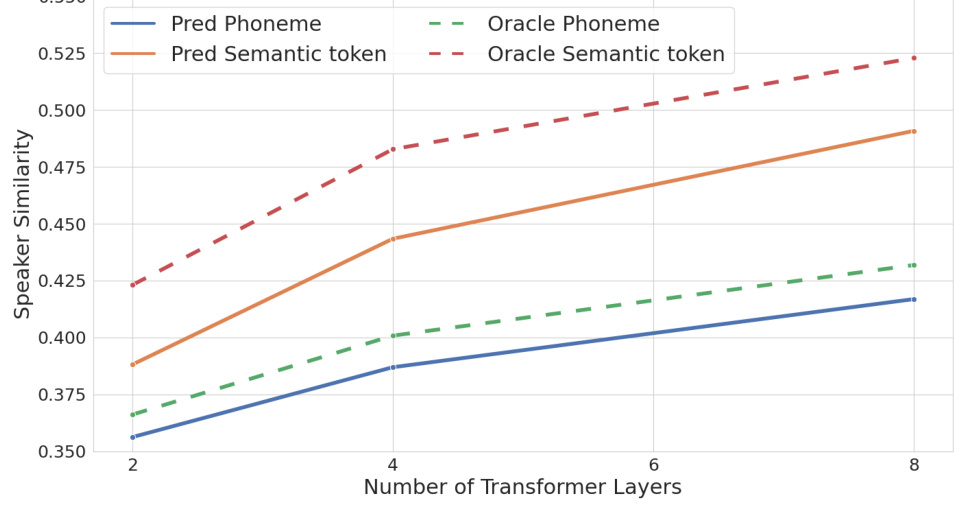
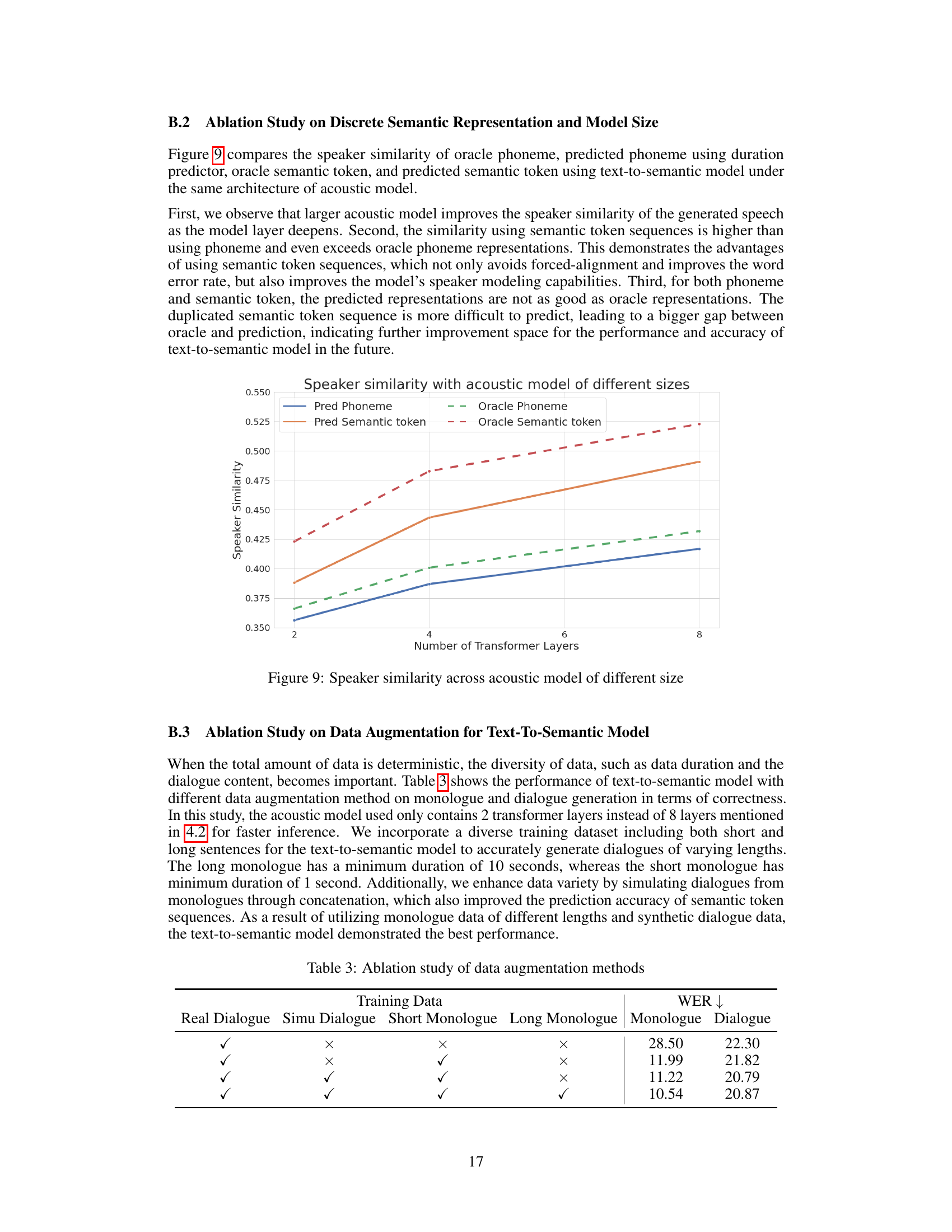
This figure shows the results of ablation study on discrete semantic representation and model size. The x-axis represents the number of transformer layers in the acoustic model, and the y-axis represents the speaker similarity. Four lines are plotted: predicted phoneme, oracle phoneme, predicted semantic token, and oracle semantic token. The results show that larger acoustic models generally improve speaker similarity and that semantic token representations achieve higher similarity than phoneme representations.

This figure provides a high-level overview of the CoVoMix framework. It illustrates the three main components: a multi-stream text-to-semantic model that converts text into multiple streams of semantic tokens, a conditional flow-matching based acoustic model that generates a mixed mel-spectrogram from these token streams, and a HiFi-GAN-based vocoder that produces the final speech waveforms. The figure shows how these components work together to generate human-like, multi-speaker conversations.
More on tables
This table presents a comparison of objective and subjective evaluation metrics for different speech generation systems on both monologue and dialogue tasks. Objective metrics include speaker similarity (SIM), word error rate (WER), mel cepstral distortion (MCD), and naturalness (NISQA). Subjective metrics include naturalness (CMOS) and speaker similarity (SMOS). The table compares the performance of CoVoSingle, CoVoMix, and a baseline system, showing the improvements achieved by the proposed CoVoMix model. The statistical significance of the differences in CMOS and SMOS is also indicated.
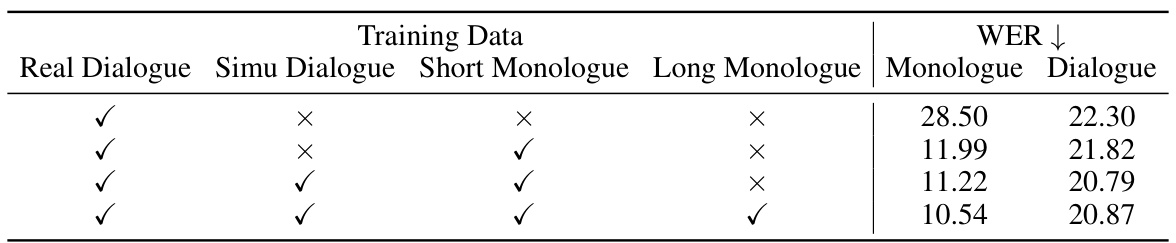
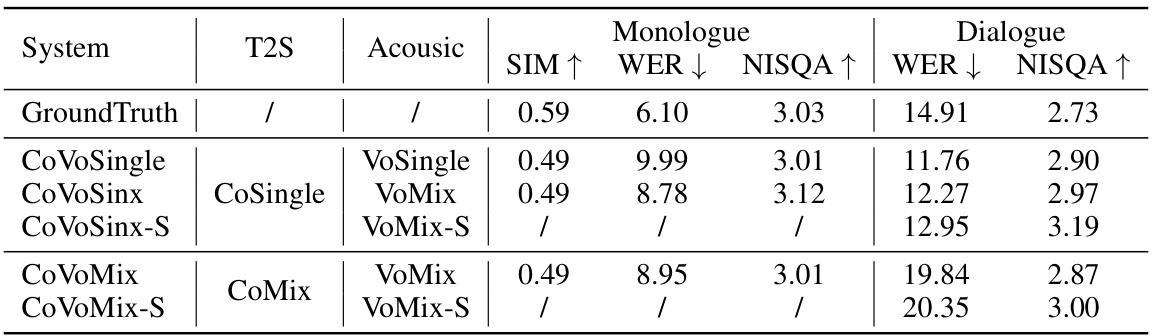
This table presents the objective evaluation results for both monologue and dialogue generation tasks using different combinations of text-to-semantic and acoustic models. It compares the performance of models with single-channel (mono) and dual-channel (stereo) acoustic models. The metrics used include Speaker Similarity (SIM), Word Error Rate (WER), Mel Cepstral Distortion (MCD), and the Naturalness, Intelligibility, and Quality Assessment (NISQA) score. The results show how different model combinations and channel configurations affect the performance on different evaluation metrics.

This table presents the objective evaluation results for voice conversion using two different systems: VoSingle and VoMix. The evaluation is performed on both monologue and dialogue datasets. The metrics used for evaluation are SIM (speaker similarity) and MCD (mel cepstral distortion). The results show that VoMix outperforms VoSingle significantly in terms of both MCD and SIM. The table also uses the symbol ‘+’ to indicate that a statistically significant difference (p<0.01) is observed between the performance of VoMix and VoSingle.

This table presents a comparison of objective and subjective evaluation metrics for different speech generation systems on both monologue and dialogue tasks. Objective metrics include Speaker Similarity (SIM), Word Error Rate (WER), Mel Cepstral Distortion (MCD), and Naturalness, Intelligibility, and Speech Quality (NISQA). Subjective metrics include Comparative Mean Opinion Score (CMOS) for naturalness and seamlessness, and Similarity Mean Opinion Score (SMOS) for speaker similarity. The table shows that CoVoMix generally outperforms CoVoSingle and a phoneme-based baseline, particularly in terms of naturalness and speaker similarity, highlighting the effectiveness of the proposed approach.

This table presents the results of objective evaluations for both monologue and dialogue generation across different systems, using three different random seeds for each system to assess the stability and consistency of the results. The metrics used include Speaker Similarity (SIM), Word Error Rate (WER), Mel Cepstral Distortion (MCD), and Naturalness and Speech Quality (NISQA). Higher SIM and NISQA values indicate better performance, while lower WER and MCD values indicate better performance.

This table presents a comparison of objective and subjective evaluation metrics for different speech generation systems (CoVoSingle, CoVoMix, and a baseline) across both monologue and dialogue datasets. Objective metrics include speaker similarity (SIM), word error rate (WER), mel cepstral distortion (MCD), and naturalness score (NISQA). Subjective metrics encompass naturalness (CMOS) and speaker similarity (SMOS), assessed through human evaluations. The table allows for a comprehensive comparison of the performance of the proposed CoVoMix system against a traditional approach and ground truth data, highlighting its strengths and weaknesses across various aspects of speech generation.

This table presents a comparison of objective and subjective evaluation metrics for different speech generation systems. The systems are evaluated on both monologue and dialogue generation tasks, and the metrics include speaker similarity (SIM), word error rate (WER), mel cepstral distortion (MCD), naturalness score (NISQA), and subjective scores for naturalness (CMOS) and speaker similarity (SMOS). The results provide quantitative and qualitative comparisons across multiple systems, including a baseline model and the proposed CoVoSingle and CoVoMix models.
Full paper#